 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conditional Adversarial Networks for Multi-Domain Text Classification
Feb 19, 2021
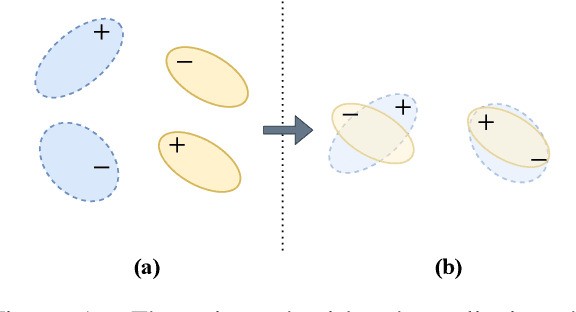

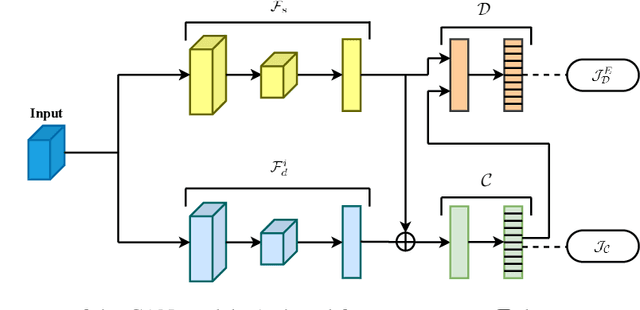
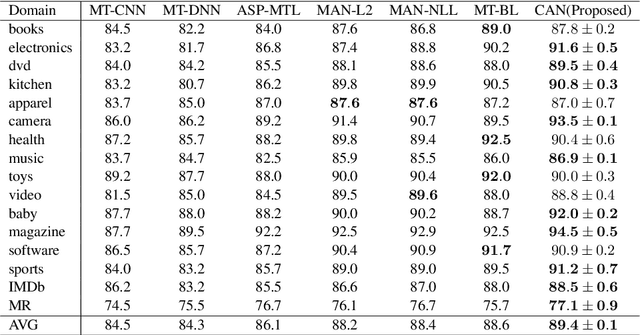
In this paper, we propose conditional adversarial networks (CANs), a framework that explores the relationship between the shared features and the label predictions to impose more discriminability to the shared features, for multi-domain text classification (MDTC). The proposed CAN introduces a conditional domain discriminator to model the domain variance in both shared feature representations and class-aware information simultaneously and adopts entropy conditioning to guarantee the transferability of the shared features. We provide theoretical analysis for the CAN framework, showing that CAN's objective is equivalent to minimizing the total divergence among multiple joint distributions of shared features and label predictions. Therefore, CAN is a theoretically sound adversarial network that discriminates over multiple distributions. Evaluation results on two MDTC benchmarks show that CAN outperforms prior methods. Further experiments demonstrate that CAN has a good ability to generalize learned knowledge to unseen domains.
SupMMD: A Sentence Importance Model for Extractive Summarization using Maximum Mean Discrepancy
Oct 06, 2020
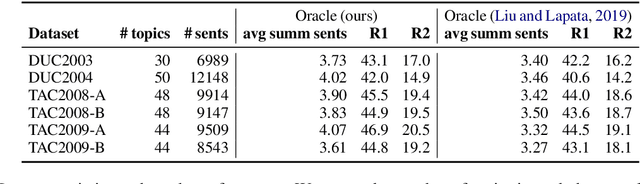
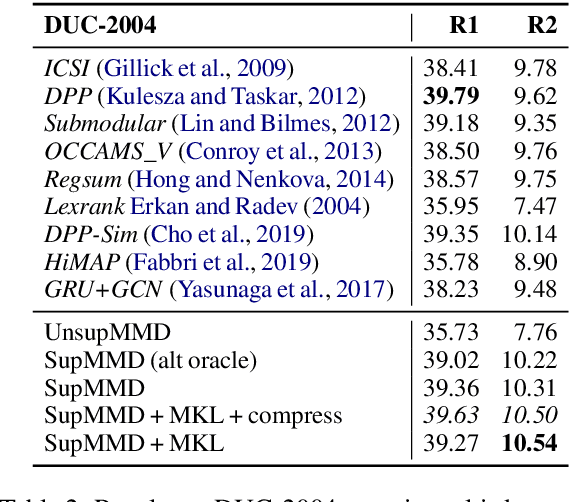

Most work on multi-document summarization has focused on generic summarization of information present in each individual document set. However, the under-explored setting of update summarization, where the goal is to identify the new information present in each set, is of equal practical interest (e.g., presenting readers with updates on an evolving news topic). In this work, we present SupMMD, a novel technique for generic and update summarization based on the maximum mean discrepancy from kernel two-sample testing. SupMMD combines both supervised learning for salience and unsupervised learning for coverage and diversity. Further, we adapt multiple kernel learning to make use of similarity across multiple information sources (e.g., text features and knowledge based concepts). We show the efficacy of SupMMD in both generic and update summarization tasks by meeting or exceeding the current state-of-the-art on the DUC-2004 and TAC-2009 datasets.
* 15 pages
A Computed Tomography Vertebral Segmentation Dataset with Anatomical Variations and Multi-Vendor Scanner Data
Mar 10, 2021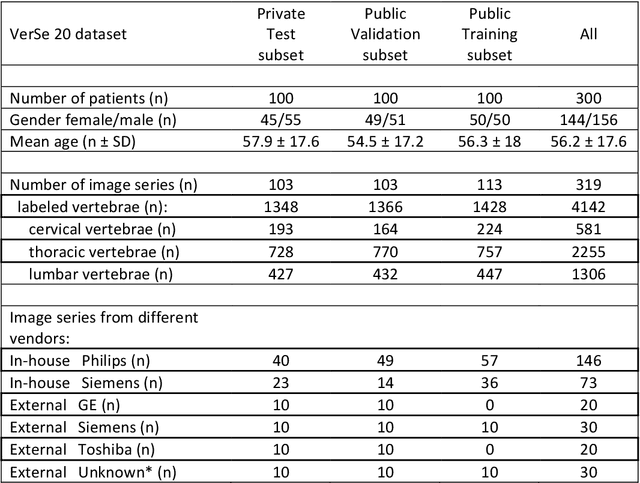
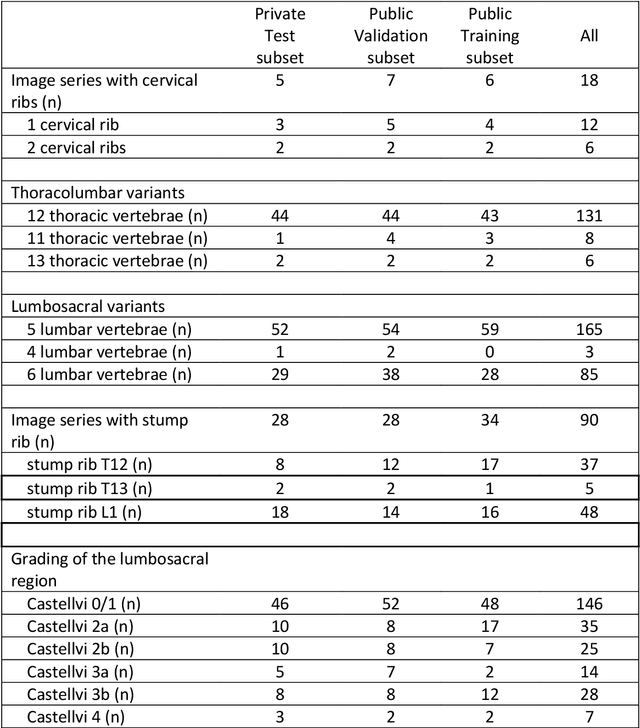
With the advent of deep learning algorithms, fully automated radiological image analysis is within reach. In spine imaging, several atlas- and shape-based as well as deep learning segmentation algorithms have been proposed, allowing for subsequent automated analysis of morphology and pathology. The first Large Scale Vertebrae Segmentation Challenge (VerSe 2019) showed that these perform well on normal anatomy, but fail in variants not frequently present in the training dataset. Building on that experience, we report on the largely increased VerSe 2020 dataset and results from the second iteration of the VerSe challenge (MICCAI 2020, Lima, Peru). VerSe 2020 comprises annotated spine computed tomography (CT) images from 300 subjects with 4142 fully visualized and annotated vertebrae, collected across multiple centres from four different scanner manufacturers, enriched with cases that exhibit anatomical variants such as enumeration abnormalities (n=77) and transitional vertebrae (n=161). Metadata includes vertebral labelling information, voxel-level segmentation masks obtained with a human-machine hybrid algorithm and anatomical ratings, to enable the development and benchmarking of robust and accurate segmentation algorithms.
Extracting a Knowledge Base of Mechanisms from COVID-19 Papers
Oct 08, 2020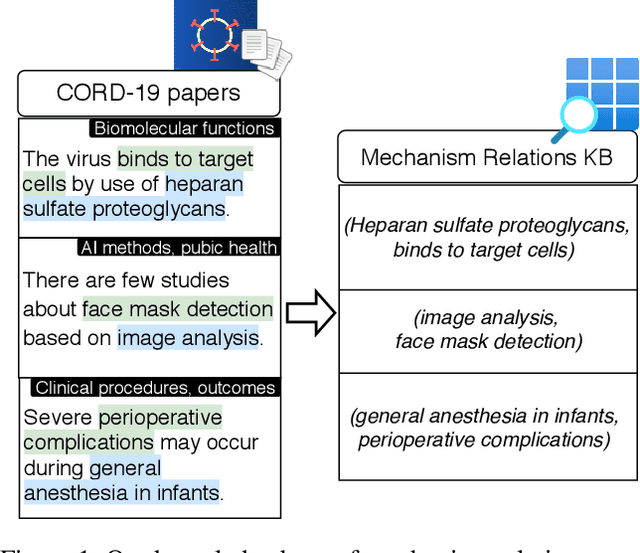
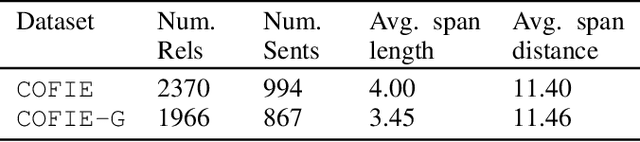

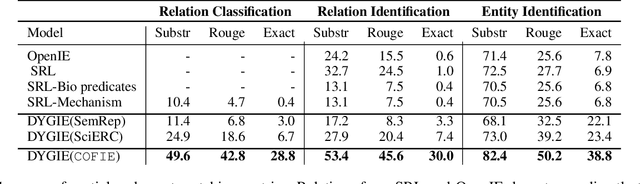
The urgency of mitigating COVID-19 has spawned a large and diverse body of scientific literature that is challenging for researchers to navigate. This explosion of information has stimulated interest in automated tools to help identify useful knowledge. We have pursued the use of methods for extracting diverse forms of mechanism relations from the natural language of scientific papers. We seek to identify concepts in COVID-19 and related literature which represent activities, functions, associations and causal relations, ranging from cellular processes to economic impacts. We formulate a broad, coarse-grained schema targeting mechanism relations between open, free-form entities. Our approach strikes a balance between expressivity and breadth that supports generalization across diverse concepts. We curate a dataset of scientific papers annotated according to our novel schema. Using an information extraction model trained on this new corpus, we construct a knowledge base (KB) of 2M mechanism relations, which we make publicly available. Our model is able to extract relations at an F1 at least twice that of baselines such as open IE or related scientific IE systems. We conduct experiments examining the ability of our system to retrieve relevant information on viral mechanisms of action, and on applications of AI to COVID-19 research. In both cases, our system identifies relevant information from our automatically-constructed knowledge base with high precision.
Trimming the Independent Fat: Sufficient Statistics, Mutual Information, and Predictability from Effective Channel States
Feb 07, 2017
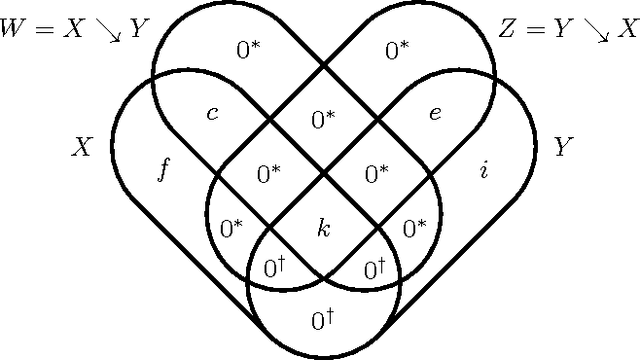
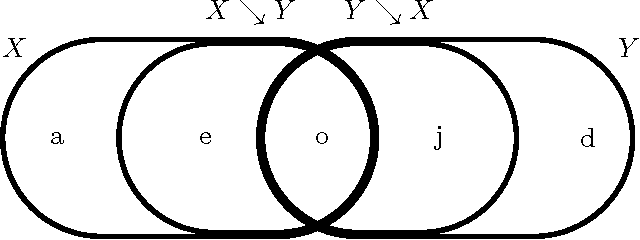
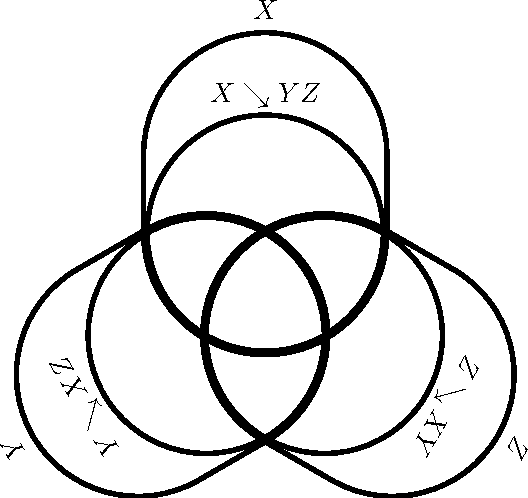
One of the most fundamental questions one can ask about a pair of random variables X and Y is the value of their mutual information. Unfortunately, this task is often stymied by the extremely large dimension of the variables. We might hope to replace each variable by a lower-dimensional representation that preserves the relationship with the other variable. The theoretically ideal implementation is the use of minimal sufficient statistics, where it is well-known that either X or Y can be replaced by their minimal sufficient statistic about the other while preserving the mutual information. While intuitively reasonable, it is not obvious or straightforward that both variables can be replaced simultaneously. We demonstrate that this is in fact possible: the information X's minimal sufficient statistic preserves about Y is exactly the information that Y's minimal sufficient statistic preserves about X. As an important corollary, we consider the case where one variable is a stochastic process' past and the other its future and the present is viewed as a memoryful channel. In this case, the mutual information is the channel transmission rate between the channel's effective states. That is, the past-future mutual information (the excess entropy) is the amount of information about the future that can be predicted using the past. Translating our result about minimal sufficient statistics, this is equivalent to the mutual information between the forward- and reverse-time causal states of computational mechanics. We close by discussing multivariate extensions to this use of minimal sufficient statistics.
* 6 pages, 4 figures; http://csc.ucdavis.edu/~cmg/compmech/pubs/mcs.htm
Entanglement Diagnostics for Efficient Quantum Computation
Feb 24, 2021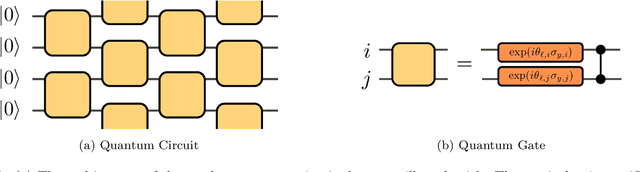
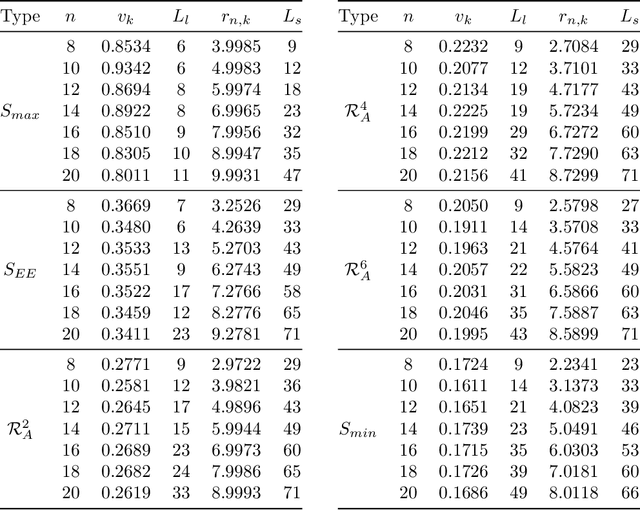
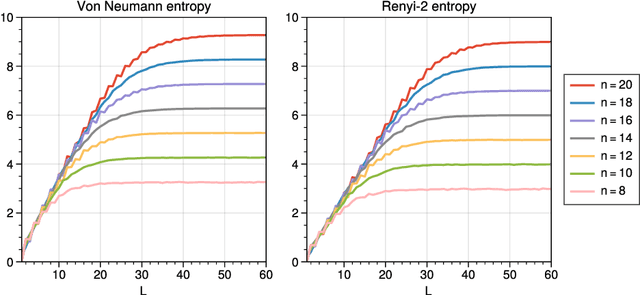
We consider information spreading measures in randomly initialized variational quantum circuits and construct entanglement diagnostics for efficient quantum/classical hybrid computations. Following the Renyi entropies of the random circuit's reduced density matrix, we divide the number of circuit layers into two separate regions with a transitioning zone between them. We identify the high-performance region for solving optimization problems encoded in the cost function of k-local Hamiltonians. We consider three example Hamiltonians, i.e., the nearest-neighbor transverse-field Ising model, the long-range transverse-field Ising model and the Sachdev-Ye-Kitaev model. By analyzing the qualitative and quantitative differences in the respective optimization processes, we demonstrate that the entanglement measures are robust diagnostics that are highly correlated with the optimization performance. We study the advantage of entanglement diagnostics for different circuit architectures and the impact of changing the parameter space dimensionality while maintaining its entanglement structure.
On the Assessment of Benchmark Suites for Algorithm Comparison
Apr 15, 2021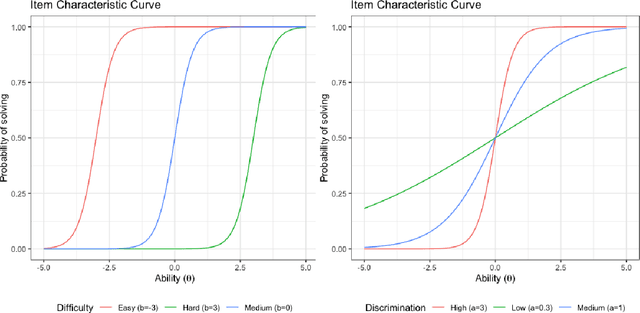
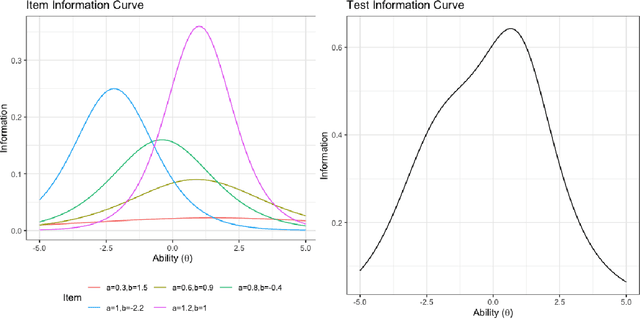
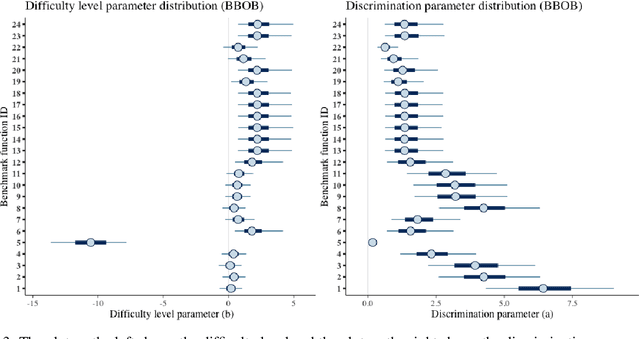
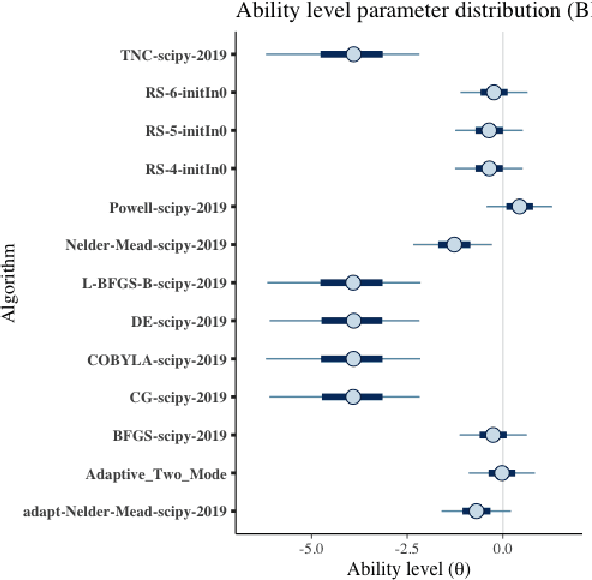
Benchmark suites, i.e. a collection of benchmark functions, are widely used in the comparison of black-box optimization algorithms. Over the years, research has identified many desired qualities for benchmark suites, such as diverse topology, different difficulties, scalability, representativeness of real-world problems among others. However, while the topology characteristics have been subjected to previous studies, there is no study that has statistically evaluated the difficulty level of benchmark functions, how well they discriminate optimization algorithms and how suitable is a benchmark suite for algorithm comparison. In this paper, we propose the use of an item response theory (IRT) model, the Bayesian two-parameter logistic model for multiple attempts, to statistically evaluate these aspects with respect to the empirical success rate of algorithms. With this model, we can assess the difficulty level of each benchmark, how well they discriminate different algorithms, the ability score of an algorithm, and how much information the benchmark suite adds in the estimation of the ability scores. We demonstrate the use of this model in two well-known benchmark suites, the Black-Box Optimization Benchmark (BBOB) for continuous optimization and the Pseudo Boolean Optimization (PBO) for discrete optimization. We found that most benchmark functions of BBOB suite have high difficulty levels (compared to the optimization algorithms) and low discrimination. For the PBO, most functions have good discrimination parameters but are often considered too easy. We discuss potential uses of IRT in benchmarking, including its use to improve the design of benchmark suites, to measure multiple aspects of the algorithms, and to design adaptive suites.
Hyperspectral Image Super-Resolution in Arbitrary Input-Output Band Settings
Mar 19, 2021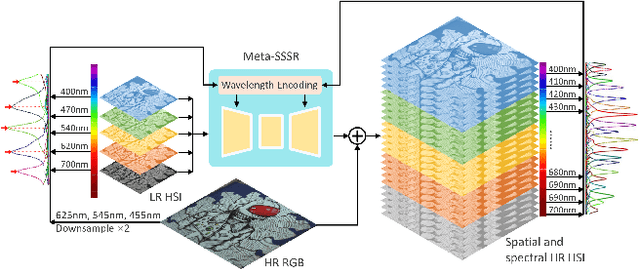
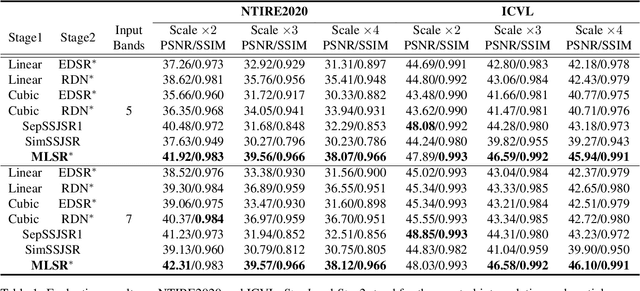
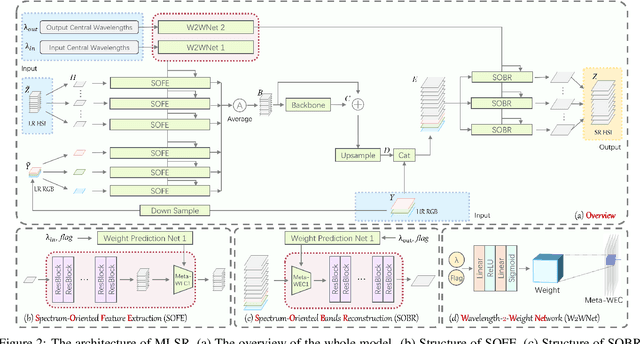

Hyperspectral images (HSIs) with narrow spectral bands can capture rich spectral information, making them suitable for many computer vision tasks. One of the fundamental limitations of HSI is its low spatial resolution, and several recent works on super-resolution(SR) have been proposed to tackle this challenge. However, due to HSI cameras' diversity, different cameras capture images with different spectral response functions and the number of total channels. The existing HSI datasets are usually small and consequently insufficient for modeling. We propose a Meta-Learning-Based Super-Resolution(MLSR) model, which can take in HSI images at an arbitrary number of input bands' peak wavelengths and generate super-resolved HSIs with an arbitrary number of output bands' peak wavelengths. We artificially create sub-datasets by sampling the bands from NTIRE2020 and ICVL datasets to simulate the cross-dataset settings and perform HSI SR with spectral interpolation and extrapolation on them. We train a single MLSR model for all sub-datasets and train dedicated baseline models for each sub-dataset. The results show the proposed model has the same level or better performance compared to the-state-of-the-art HSI SR methods.
A Biased Graph Neural Network Sampler with Near-Optimal Regret
Mar 01, 2021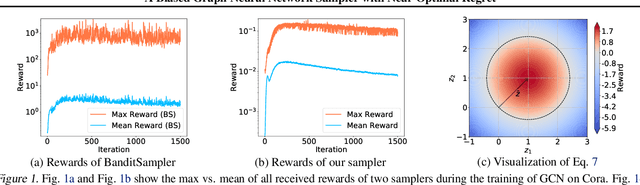

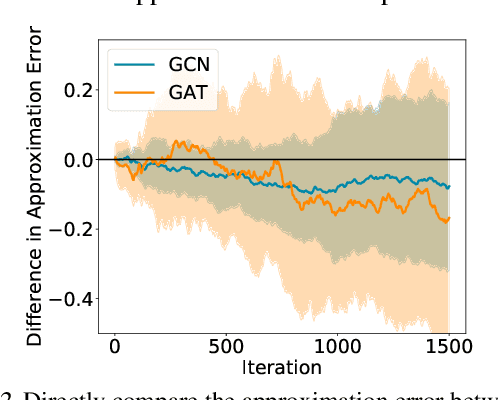

Graph neural networks (GNN) have recently emerged as a vehicle for applying deep network architectures to graph and relational data. However, given the increasing size of industrial datasets, in many practical situations, the message passing computations required for sharing information across GNN layers are no longer scalable. Although various sampling methods have been introduced to approximate full-graph training within a tractable budget, there remain unresolved complications such as high variances and limited theoretical guarantees. To address these issues, we build upon existing work and treat GNN neighbor sampling as a multi-armed bandit problem but with a newly-designed reward function that introduces some degree of bias designed to reduce variance and avoid unstable, possibly-unbounded payouts. And unlike prior bandit-GNN use cases, the resulting policy leads to near-optimal regret while accounting for the GNN training dynamics introduced by SGD. From a practical standpoint, this translates into lower variance estimates and competitive or superior test accuracy across several benchmarks.
A survey on Variational Autoencoders from a GreenAI perspective
Mar 01, 2021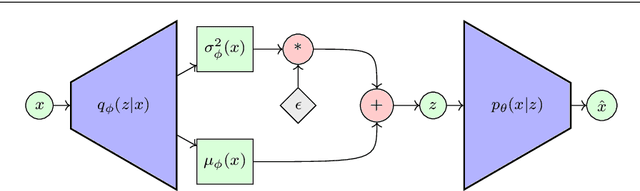
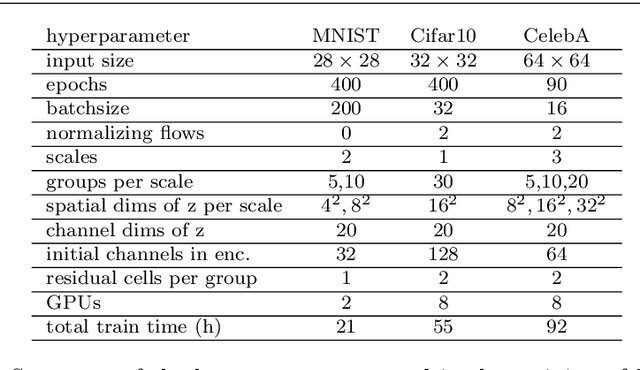
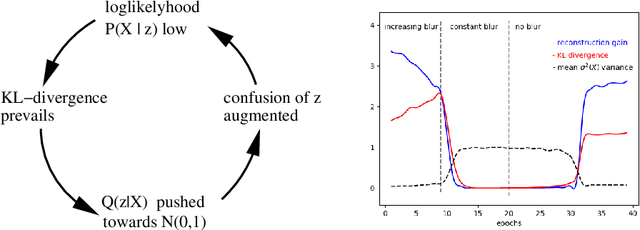
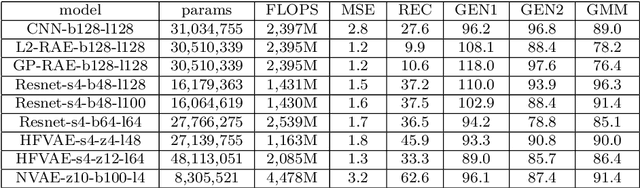
Variational AutoEncoders (VAEs) are powerful generative models that merge elements from statistics and information theory with the flexibility offered by deep neural networks to efficiently solve the generation problem for high dimensional data. The key insight of VAEs is to learn the latent distribution of data in such a way that new meaningful samples can be generated from it. This approach led to tremendous research and variations in the architectural design of VAEs, nourishing the recent field of research known as unsupervised representation learning. In this article, we provide a comparative evaluation of some of the most successful, recent variations of VAEs. We particularly focus the analysis on the energetic efficiency of the different models, in the spirit of the so called Green AI, aiming both to reduce the carbon footprint and the financial cost of generative techniques. For each architecture we provide its mathematical formulation, the ideas underlying its design, a detailed model description, a running implementation and quantitative results.