 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A De-raining semantic segmentation network for real-time foreground segmentation
Apr 16, 2021
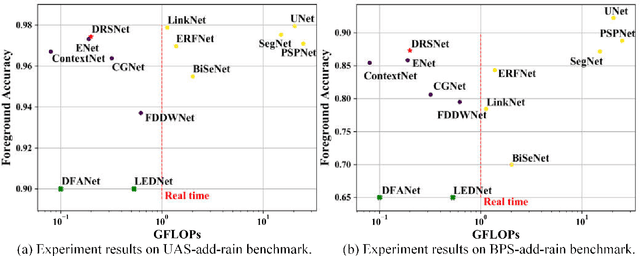

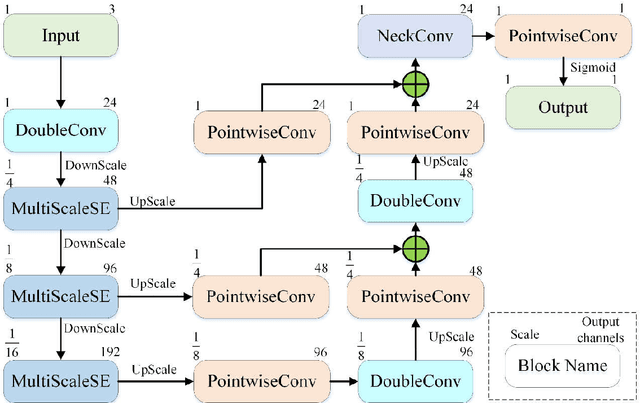
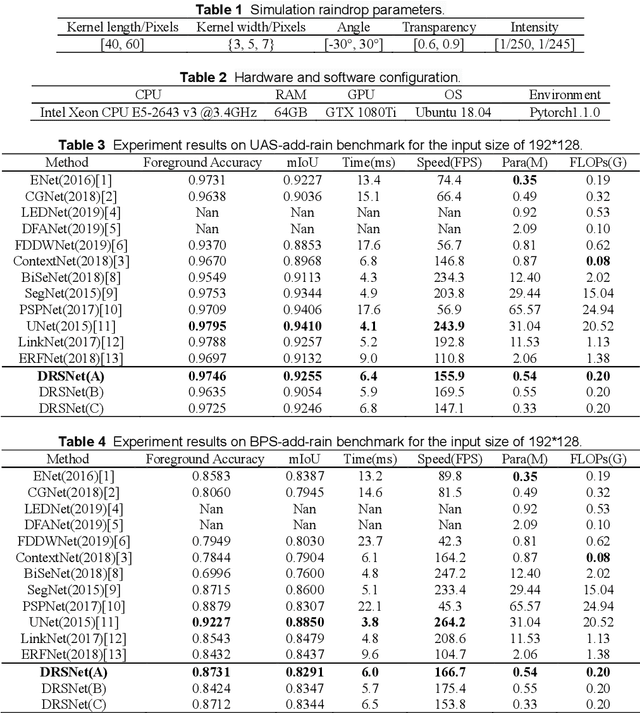
Few researches have been proposed specifically for real-time semantic segmentation in rainy environments. However, the demand in this area is huge and it is challenging for lightweight networks. Therefore, this paper proposes a lightweight network which is specially designed for the foreground segmentation in rainy environments, named De-raining Semantic Segmentation Network (DRSNet). By analyzing the characteristics of raindrops, the MultiScaleSE Block is targetedly designed to encode the input image, it uses multi-scale dilated convolutions to increase the receptive field, and SE attention mechanism to learn the weights of each channels. In order to combine semantic information between different encoder and decoder layers, it is proposed to use Asymmetric Skip, that is, the higher semantic layer of encoder employs bilinear interpolation and the output passes through pointwise convolution, then added element-wise to the lower semantic layer of decoder. According to the control experiments, the performances of MultiScaleSE Block and Asymmetric Skip compared with SEResNet18 and Symmetric Skip respectively are improved to a certain degree on the Foreground Accuracy index. The parameters and the floating point of operations (FLOPs) of DRSNet is only 0.54M and 0.20GFLOPs separately. The state-of-the-art results and real-time performances are achieved on both the UESTC all-day Scenery add rain (UAS-add-rain) and the Baidu People Segmentation add rain (BPS-add-rain) benchmarks with the input sizes of 192*128, 384*256 and 768*512. The speed of DRSNet exceeds all the networks within 1GFLOPs, and Foreground Accuracy index is also the best among the similar magnitude networks on both benchmarks.
Time-Series Imputation with Wasserstein Interpolation for Optimal Look-Ahead-Bias and Variance Tradeoff
Feb 25, 2021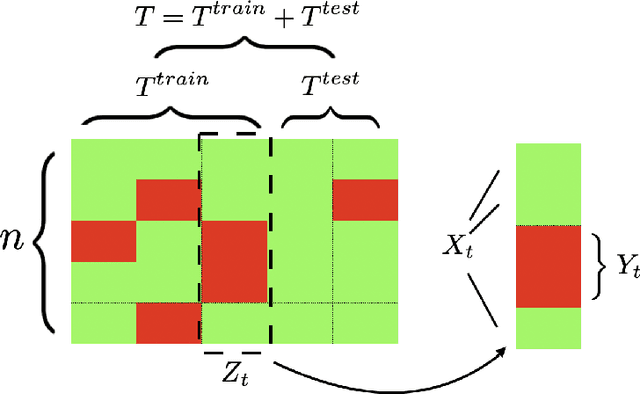
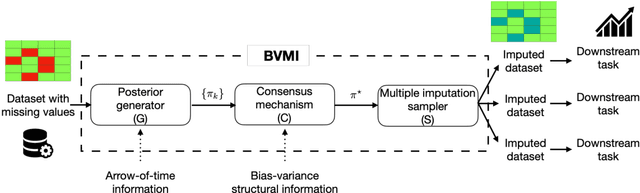
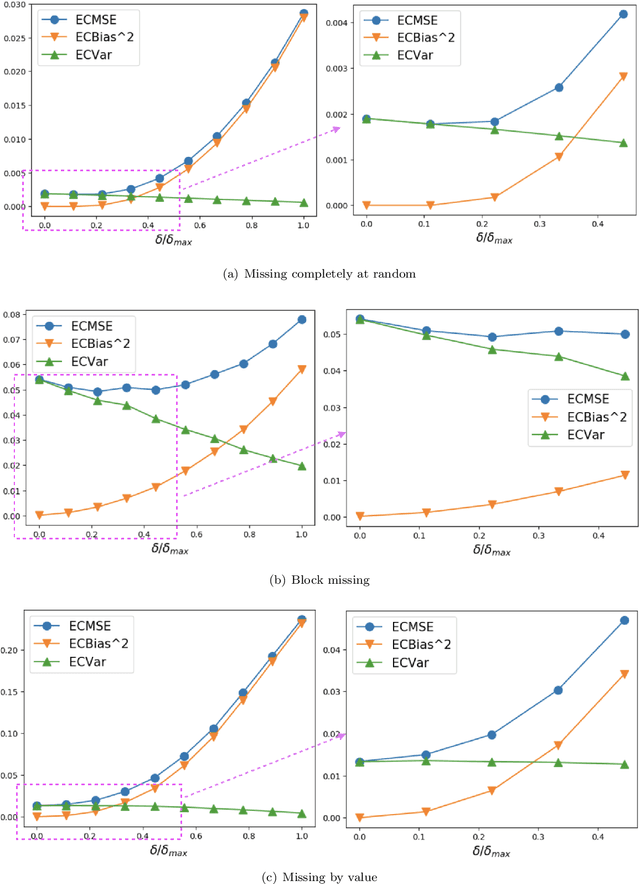
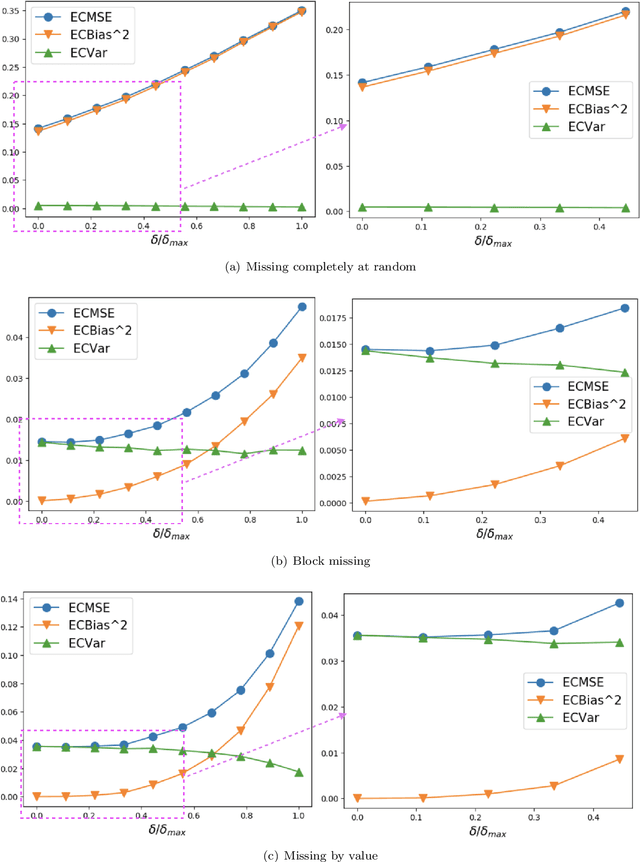
Missing time-series data is a prevalent practical problem. Imputation methods in time-series data often are applied to the full panel data with the purpose of training a model for a downstream out-of-sample task. For example, in finance, imputation of missing returns may be applied prior to training a portfolio optimization model. Unfortunately, this practice may result in a look-ahead-bias in the future performance on the downstream task. There is an inherent trade-off between the look-ahead-bias of using the full data set for imputation and the larger variance in the imputation from using only the training data. By connecting layers of information revealed in time, we propose a Bayesian posterior consensus distribution which optimally controls the variance and look-ahead-bias trade-off in the imputation. We demonstrate the benefit of our methodology both in synthetic and real financial data.
The fundamental limits of sparse linear regression with sublinear sparsity
Feb 03, 2021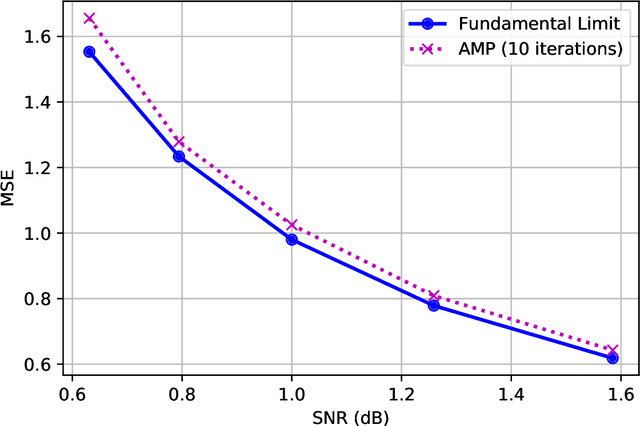
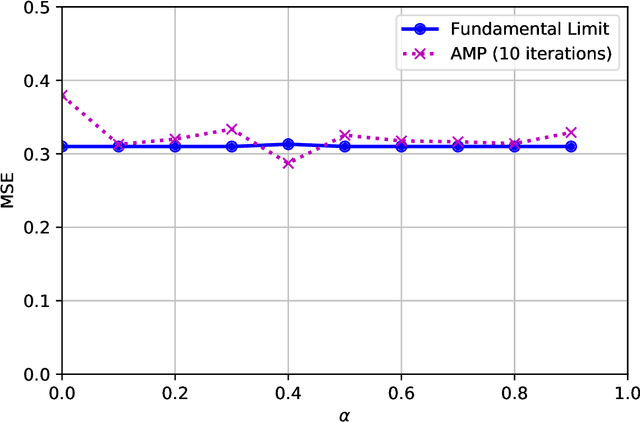
We establish exact asymptotic expressions for the normalized mutual information and minimum mean-square-error (MMSE) of sparse linear regression in the sub-linear sparsity regime. Our result is achieved by a simple generalization of the adaptive interpolation method in Bayesian inference for linear regimes to sub-linear ones. A modification of the well-known approximate message passing algorithm to approach the MMSE fundamental limit is also proposed. Our results show that the traditional linear assumption between the signal dimension and number of observations in the replica and adaptive interpolation methods is not necessary for sparse signals. They also show how to modify the existing well-known AMP algorithms for linear regimes to sub-linear ones.
Towards Fully Automated Manga Translation
Dec 28, 2020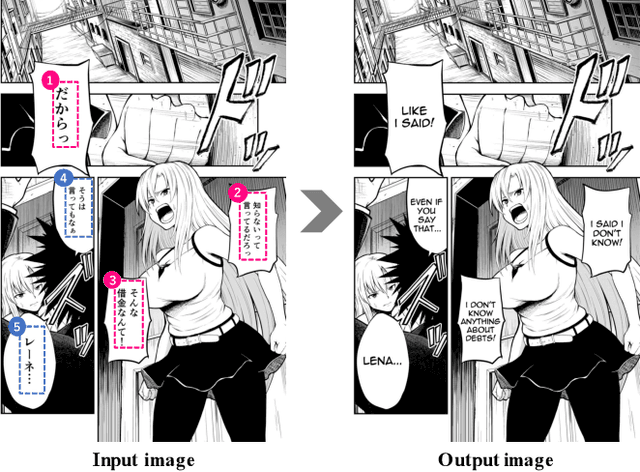
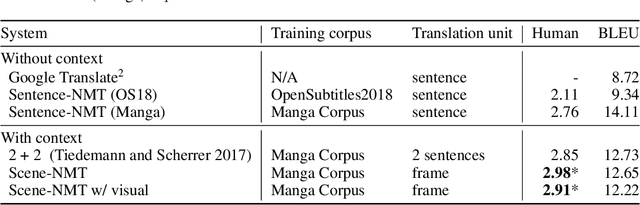
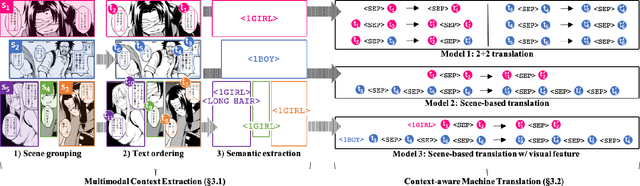
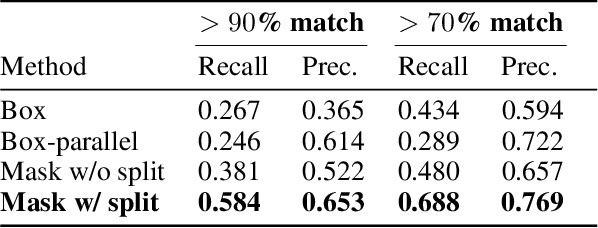
We tackle the problem of machine translation of manga, Japanese comics. Manga translation involves two important problems in machine translation: context-aware and multimodal translation. Since text and images are mixed up in an unstructured fashion in Manga, obtaining context from the image is essential for manga translation. However, it is still an open problem how to extract context from image and integrate into MT models. In addition, corpus and benchmarks to train and evaluate such model is currently unavailable. In this paper, we make the following four contributions that establishes the foundation of manga translation research. First, we propose multimodal context-aware translation framework. We are the first to incorporate context information obtained from manga image. It enables us to translate texts in speech bubbles that cannot be translated without using context information (e.g., texts in other speech bubbles, gender of speakers, etc.). Second, for training the model, we propose the approach to automatic corpus construction from pairs of original manga and their translations, by which large parallel corpus can be constructed without any manual labeling. Third, we created a new benchmark to evaluate manga translation. Finally, on top of our proposed methods, we devised a first comprehensive system for fully automated manga translation.
Symbolic AI for XAI: Evaluating LFIT Inductive Programming for Fair and Explainable Automatic Recruitment
Dec 01, 2020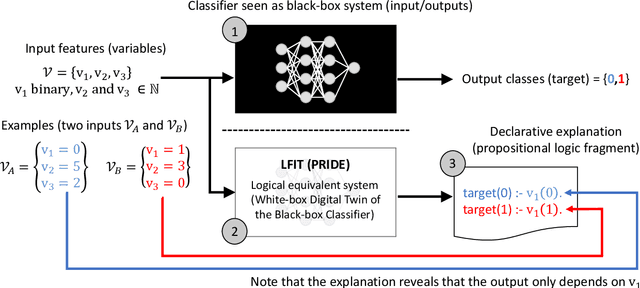
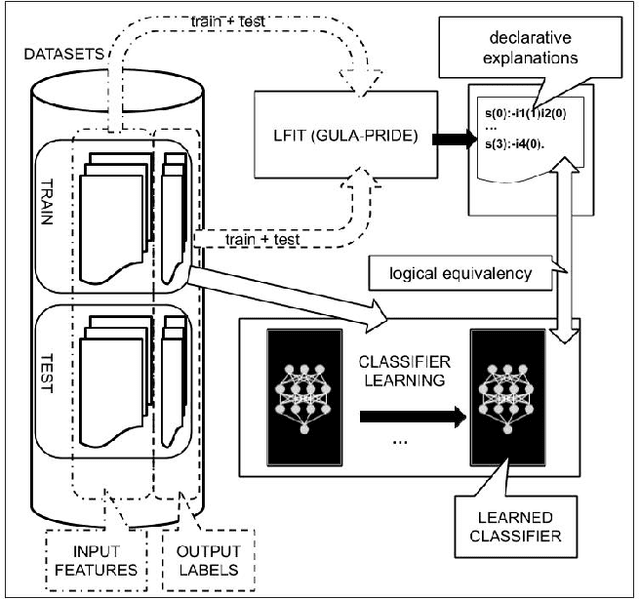
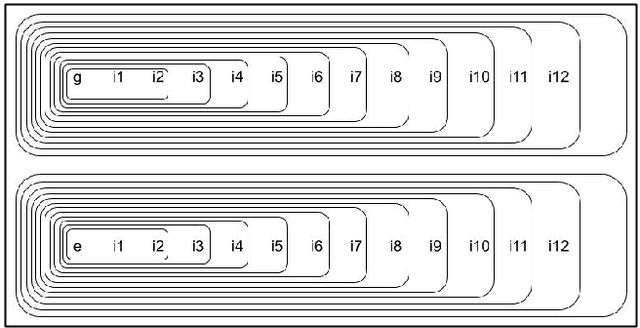
Machine learning methods are growing in relevance for biometrics and personal information processing in domains such as forensics, e-health, recruitment, and e-learning. In these domains, white-box (human-readable) explanations of systems built on machine learning methods can become crucial. Inductive Logic Programming (ILP) is a subfield of symbolic AI aimed to automatically learn declarative theories about the process of data. Learning from Interpretation Transition (LFIT) is an ILP technique that can learn a propositional logic theory equivalent to a given black-box system (under certain conditions). The present work takes a first step to a general methodology to incorporate accurate declarative explanations to classic machine learning by checking the viability of LFIT in a specific AI application scenario: fair recruitment based on an automatic tool generated with machine learning methods for ranking Curricula Vitae that incorporates soft biometric information (gender and ethnicity). We show the expressiveness of LFIT for this specific problem and propose a scheme that can be applicable to other domains.
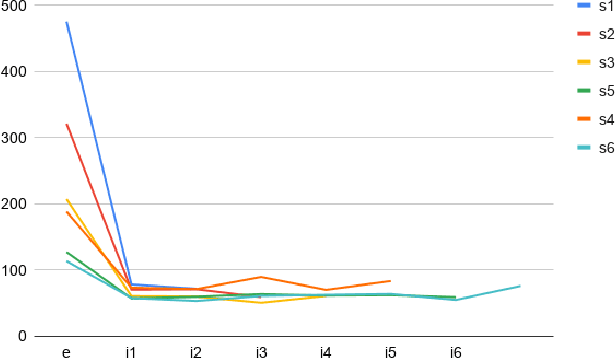
Discovering dependencies in complex physical systems using Neural Networks
Jan 27, 2021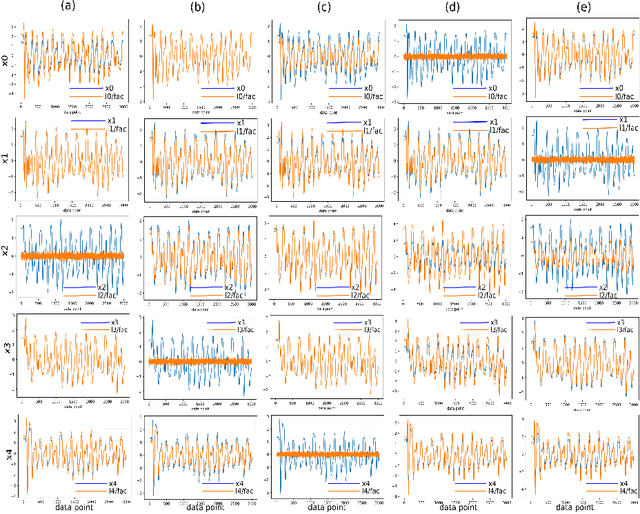
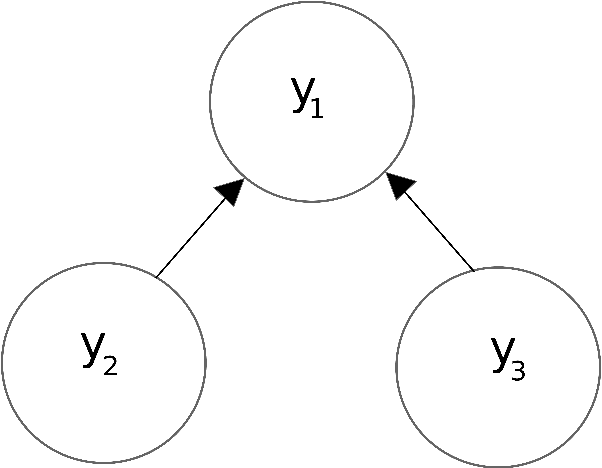
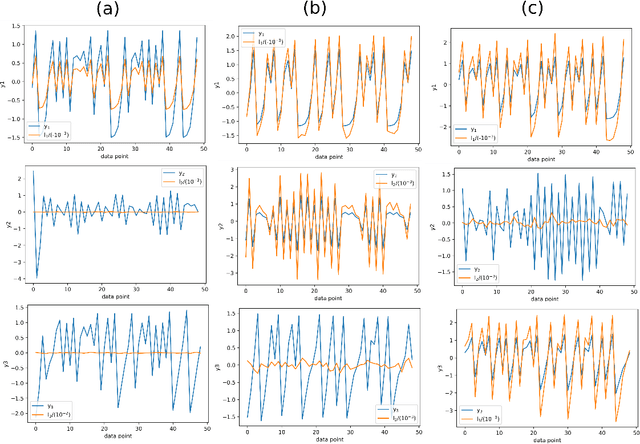
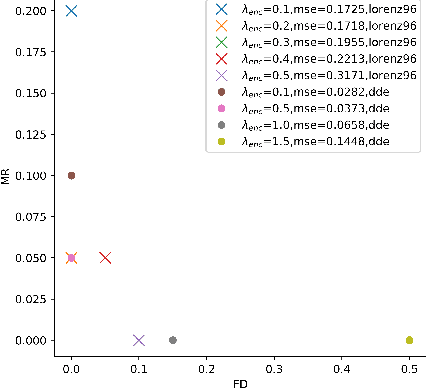
In todays age of data, discovering relationships between different variables is an interesting and a challenging problem. This problem becomes even more critical with regards to complex dynamical systems like weather forecasting and econometric models, which can show highly non-linear behavior. A method based on mutual information and deep neural networks is proposed as a versatile framework for discovering non-linear relationships ranging from functional dependencies to causality. We demonstrate the application of this method to actual multivariable non-linear dynamical systems. We also show that this method can find relationships even for datasets with small number of datapoints, as is often the case with empirical data.
Optimization meets Big Data: A survey
Feb 03, 2021This paper reviews recent advances in big data optimization, providing the state-of-art of this emerging field. The main focus in this review are optimization techniques being applied in big data analysis environments. Integer linear programming, coordinate descent methods, alternating direction method of multipliers, simulation optimization and metaheuristics like evolutionary and genetic algorithms, particle swarm optimization, differential evolution, fireworks, bat, firefly and cuckoo search algorithms implementations are reviewed and discussed. The relation between big data optimization and software engineering topics like information work-flow styles, software architectures, and software framework is discussed. Comparative analysis in platforms being used in big data optimization environments are highlighted in order to bring a state-or-art of possible architectures and topologies.
SupMMD: A Sentence Importance Model for Extractive Summarization using Maximum Mean Discrepancy
Oct 06, 2020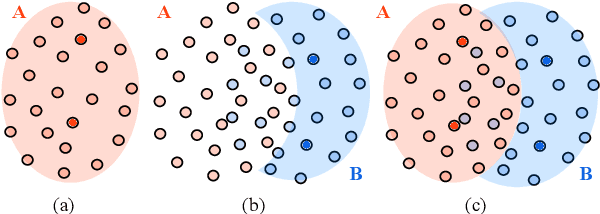
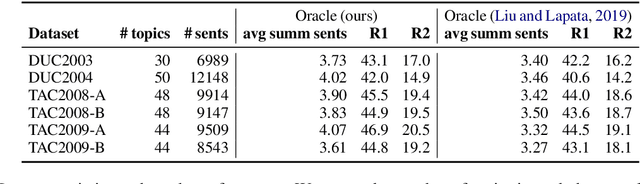
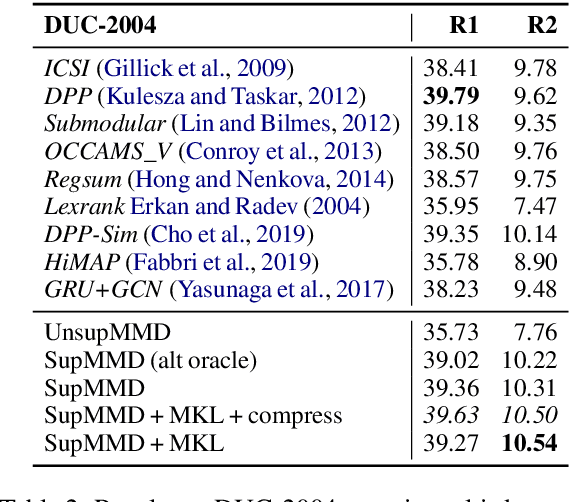

Most work on multi-document summarization has focused on generic summarization of information present in each individual document set. However, the under-explored setting of update summarization, where the goal is to identify the new information present in each set, is of equal practical interest (e.g., presenting readers with updates on an evolving news topic). In this work, we present SupMMD, a novel technique for generic and update summarization based on the maximum mean discrepancy from kernel two-sample testing. SupMMD combines both supervised learning for salience and unsupervised learning for coverage and diversity. Further, we adapt multiple kernel learning to make use of similarity across multiple information sources (e.g., text features and knowledge based concepts). We show the efficacy of SupMMD in both generic and update summarization tasks by meeting or exceeding the current state-of-the-art on the DUC-2004 and TAC-2009 datasets.
* 15 pages
Relation Schema Induction using Tensor Factorization with Side Information
Nov 16, 2016
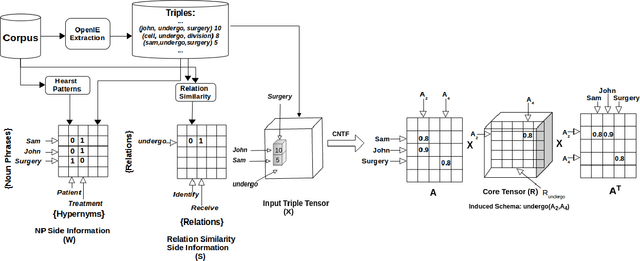

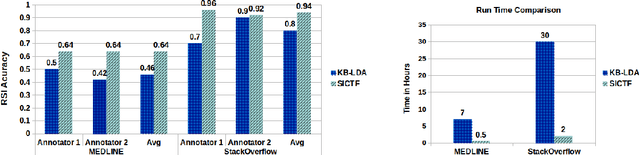
Given a set of documents from a specific domain (e.g., medical research journals), how do we automatically build a Knowledge Graph (KG) for that domain? Automatic identification of relations and their schemas, i.e., type signature of arguments of relations (e.g., undergo(Patient, Surgery)), is an important first step towards this goal. We refer to this problem as Relation Schema Induction (RSI). In this paper, we propose Schema Induction using Coupled Tensor Factorization (SICTF), a novel tensor factorization method for relation schema induction. SICTF factorizes Open Information Extraction (OpenIE) triples extracted from a domain corpus along with additional side information in a principled way to induce relation schemas. To the best of our knowledge, this is the first application of tensor factorization for the RSI problem. Through extensive experiments on multiple real-world datasets, we find that SICTF is not only more accurate than state-of-the-art baselines, but also significantly faster (about 14x faster).
Extracting a Knowledge Base of Mechanisms from COVID-19 Papers
Oct 08, 2020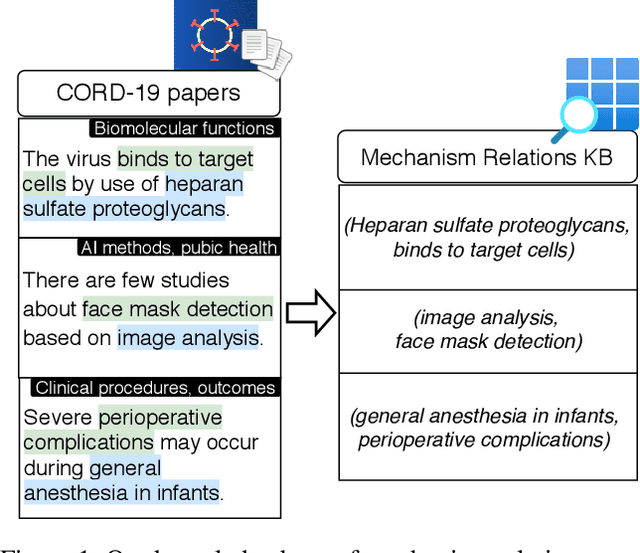

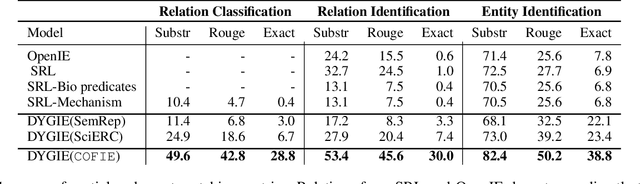
The urgency of mitigating COVID-19 has spawned a large and diverse body of scientific literature that is challenging for researchers to navigate. This explosion of information has stimulated interest in automated tools to help identify useful knowledge. We have pursued the use of methods for extracting diverse forms of mechanism relations from the natural language of scientific papers. We seek to identify concepts in COVID-19 and related literature which represent activities, functions, associations and causal relations, ranging from cellular processes to economic impacts. We formulate a broad, coarse-grained schema targeting mechanism relations between open, free-form entities. Our approach strikes a balance between expressivity and breadth that supports generalization across diverse concepts. We curate a dataset of scientific papers annotated according to our novel schema. Using an information extraction model trained on this new corpus, we construct a knowledge base (KB) of 2M mechanism relations, which we make publicly available. Our model is able to extract relations at an F1 at least twice that of baselines such as open IE or related scientific IE systems. We conduct experiments examining the ability of our system to retrieve relevant information on viral mechanisms of action, and on applications of AI to COVID-19 research. In both cases, our system identifies relevant information from our automatically-constructed knowledge base with high precision.