 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Adaptive Receiver for Underwater Acoustic Full-Duplex Communication with Joint Tracking of the Remote and Self-Interference Channels
Mar 11, 2021
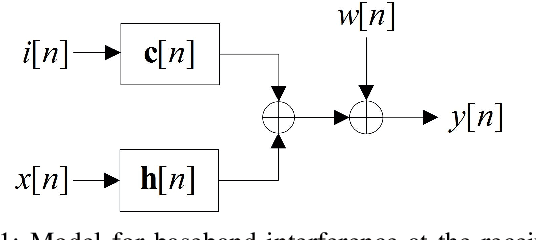
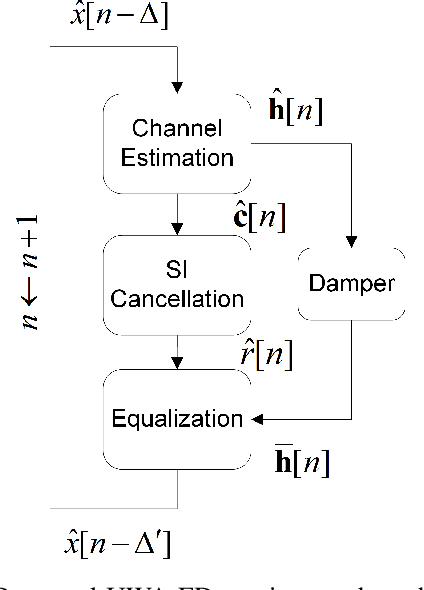
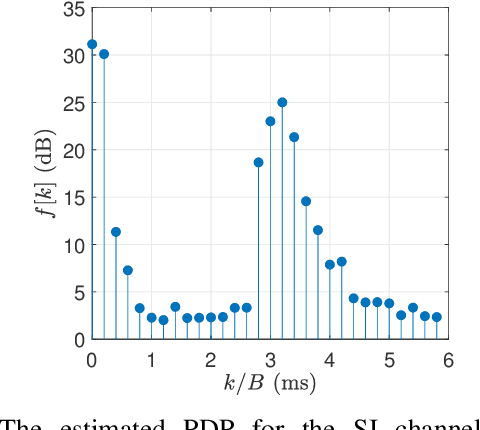
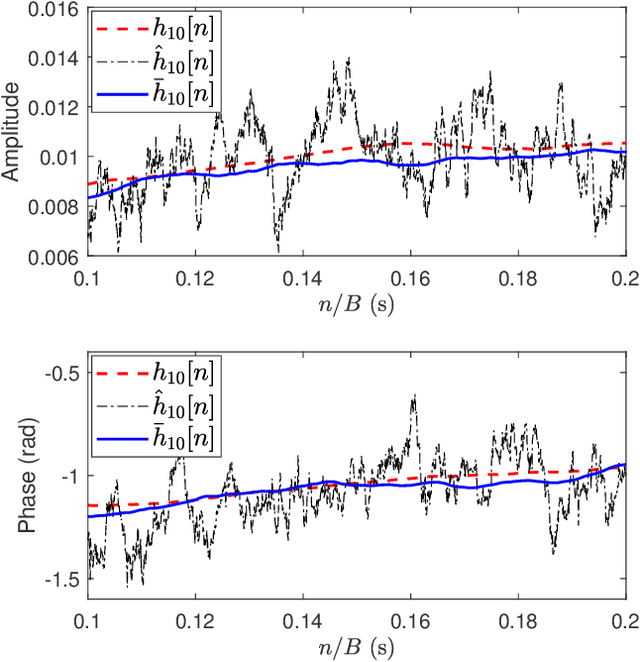
Full-duplex (FD) communication is a promising candidate to address the data rate limitations in underwater acoustic (UWA) channels. Because of transmission at the same time and on the same frequency band, the signal from the local transmitter creates self-interference (SI) that contaminates the signal from the remote transmitter. At the local receiver, channel state information for both the SI and remote channels is required to remove the SI and equalize the SI-free signal, respectively. However, because of the rapid time-variations of the UWA environment, real-time tracking of the channels is necessary. In this paper, we propose a receiver for UWA-FD communication in which the variations of the SI and remote channels are jointly tracked by using a recursive least squares (RLS) algorithm fed by feedback from the previously detected data symbols. Because of the joint channel estimation, SI cancellation is more successful compared to UWA-FD receivers with separate channel estimators. In addition, due to providing a real-time channel tracking without the need for frequent training sequences, the bandwidth efficiency is preserved in the proposed receiver.
* 7 pages, 7 figures
AutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
Mar 11, 2021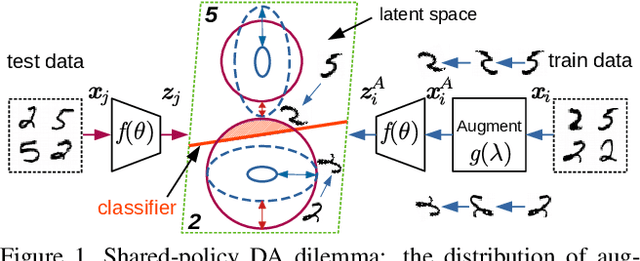
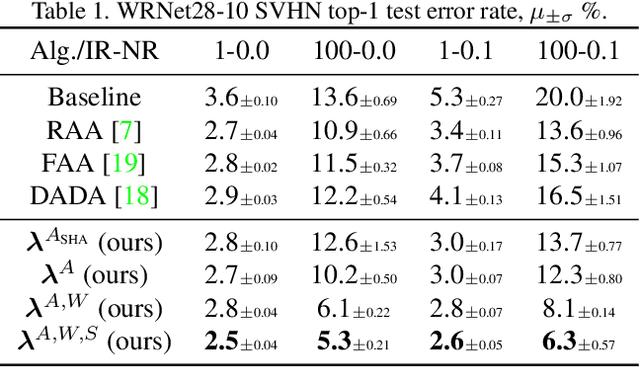

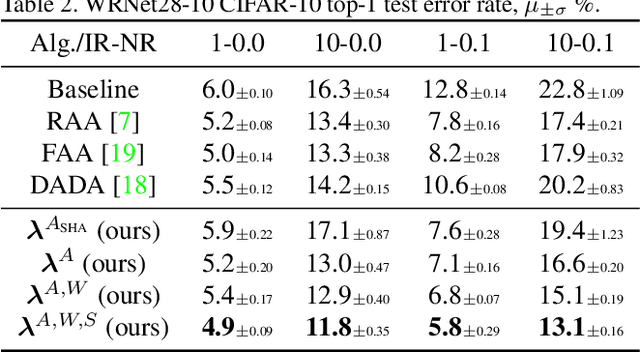
AutoAugment has sparked an interest in automated augmentation methods for deep learning models. These methods estimate image transformation policies for train data that improve generalization to test data. While recent papers evolved in the direction of decreasing policy search complexity, we show that those methods are not robust when applied to biased and noisy data. To overcome these limitations, we reformulate AutoAugment as a generalized automated dataset optimization (AutoDO) task that minimizes the distribution shift between test data and distorted train dataset. In our AutoDO model, we explicitly estimate a set of per-point hyperparameters to flexibly change distribution of train data. In particular, we include hyperparameters for augmentation, loss weights, and soft-labels that are jointly estimated using implicit differentiation. We develop a theoretical probabilistic interpretation of this framework using Fisher information and show that its complexity scales linearly with the dataset size. Our experiments on SVHN, CIFAR-10/100, and ImageNet classification show up to 9.3% improvement for biased datasets with label noise compared to prior methods and, importantly, up to 36.6% gain for underrepresented SVHN classes.
Detecting Media Bias in News Articles using Gaussian Bias Distributions
Oct 20, 2020
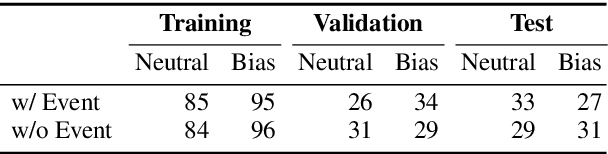
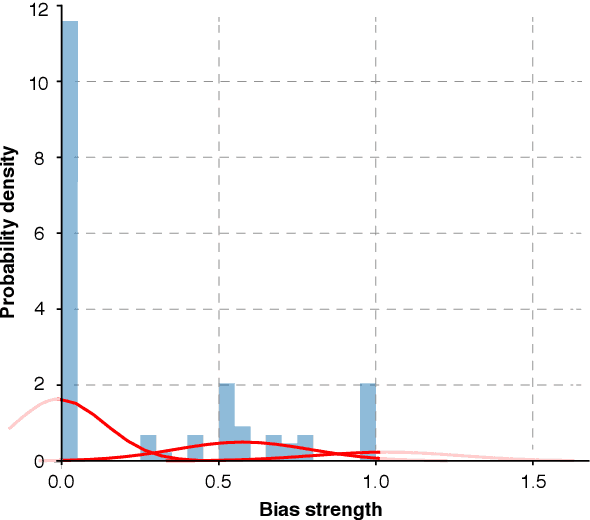
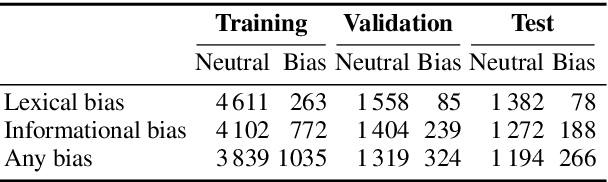
Media plays an important role in shaping public opinion. Biased media can influence people in undesirable directions and hence should be unmasked as such. We observe that featurebased and neural text classification approaches which rely only on the distribution of low-level lexical information fail to detect media bias. This weakness becomes most noticeable for articles on new events, where words appear in new contexts and hence their "bias predictiveness" is unclear. In this paper, we therefore study how second-order information about biased statements in an article helps to improve detection effectiveness. In particular, we utilize the probability distributions of the frequency, positions, and sequential order of lexical and informational sentence-level bias in a Gaussian Mixture Model. On an existing media bias dataset, we find that the frequency and positions of biased statements strongly impact article-level bias, whereas their exact sequential order is secondary. Using a standard model for sentence-level bias detection, we provide empirical evidence that article-level bias detectors that use second-order information clearly outperform those without.
Optimizing Dense Retrieval Model Training with Hard Negatives
Apr 16, 2021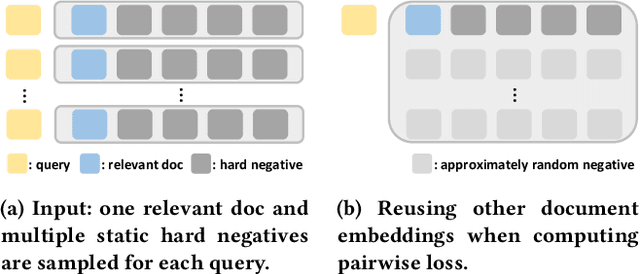
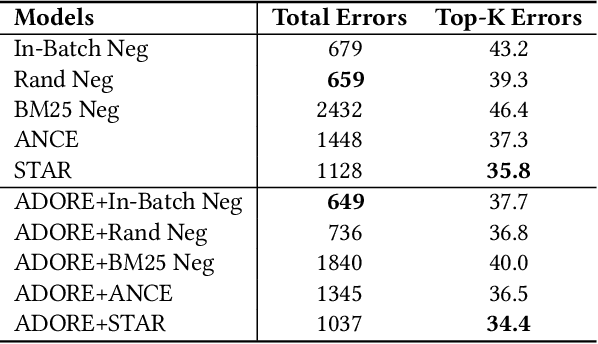
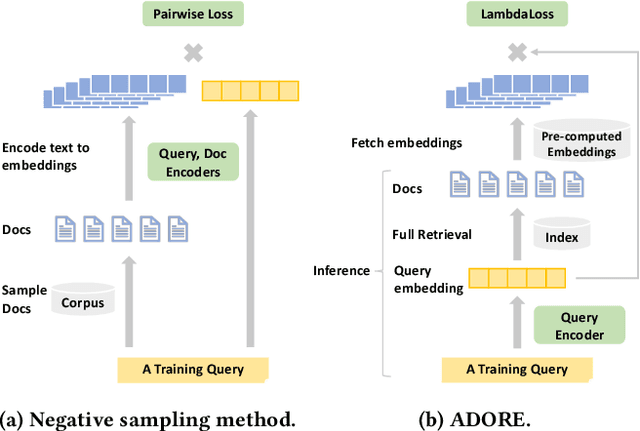
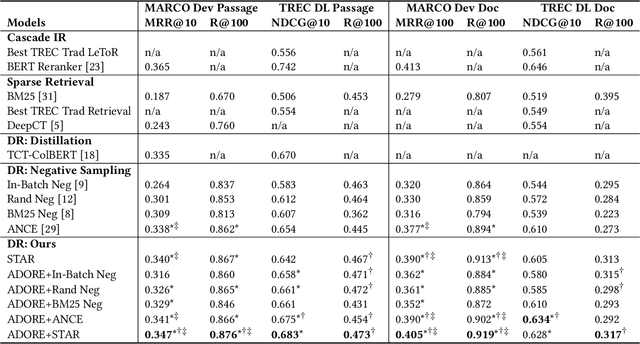
Ranking has always been one of the top concerns in information retrieval researches. For decades, the lexical matching signal has dominated the ad-hoc retrieval process, but solely using this signal in retrieval may cause the vocabulary mismatch problem. In recent years, with the development of representation learning techniques, many researchers turn to Dense Retrieval (DR) models for better ranking performance. Although several existing DR models have already obtained promising results, their performance improvement heavily relies on the sampling of training examples. Many effective sampling strategies are not efficient enough for practical usage, and for most of them, there still lacks theoretical analysis in how and why performance improvement happens. To shed light on these research questions, we theoretically investigate different training strategies for DR models and try to explain why hard negative sampling performs better than random sampling. Through the analysis, we also find that there are many potential risks in static hard negative sampling, which is employed by many existing training methods. Therefore, we propose two training strategies named a Stable Training Algorithm for dense Retrieval (STAR) and a query-side training Algorithm for Directly Optimizing Ranking pErformance (ADORE), respectively. STAR improves the stability of DR training process by introducing random negatives. ADORE replaces the widely-adopted static hard negative sampling method with a dynamic one to directly optimize the ranking performance. Experimental results on two publicly available retrieval benchmark datasets show that either strategy gains significant improvements over existing competitive baselines and a combination of them leads to the best performance.
Duality-Gated Mutual Condition Network for RGBT Tracking
Nov 14, 2020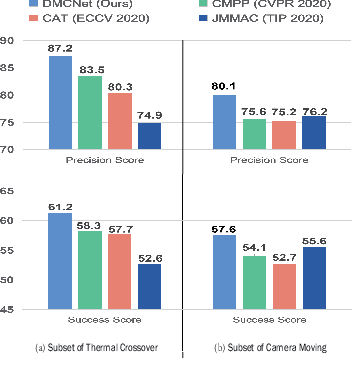
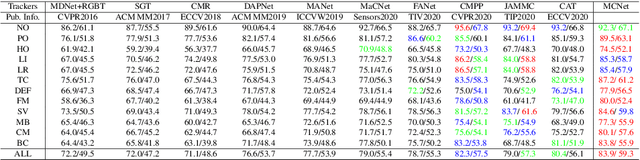

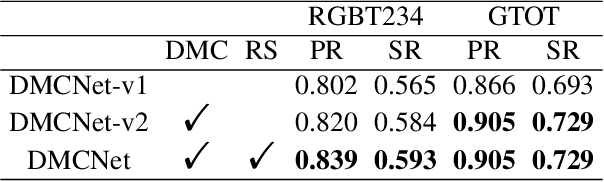
Low-quality modalities contain not only a lot of noisy information but also some discriminative features in RGBT tracking. However, the potentials of low-quality modalities are not well explored in existing RGBT tracking algorithms. In this work, we propose a novel duality-gated mutual condition network to fully exploit the discriminative information of all modalities while suppressing the effects of data noise. In specific, we design a mutual condition module, which takes the discriminative information of a modality as the condition to guide feature learning of target appearance in another modality. Such module can effectively enhance target representations and suppress useless features of all modalities even in the presence of low-quality modalities. To improve the quality of conditions and further reduce data noise, we propose a duality-gated mechanism in the mutual condition module. To deal with the tracking failure caused by sudden camera motion, which often occurs in RGBT tracking, we design a resampling strategy based on optical flow algorithms. It does not increase much computational cost since we perform optical flow calculation only when the model prediction is unreliable and then execute resampling when the sudden camera motion is detected. Extensive experiments on three RGBT tracking benchmark datasets show that our method performs favorably against the state-of-the-art tracking algorithms.
Homonym Identification using BERT -- Using a Clustering Approach
Jan 07, 2021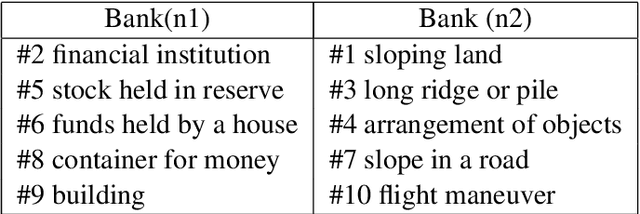
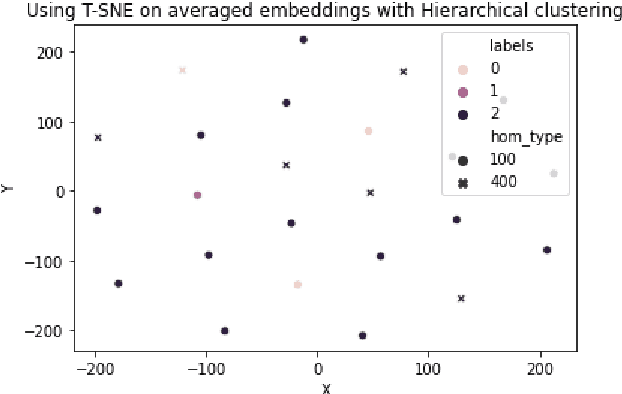
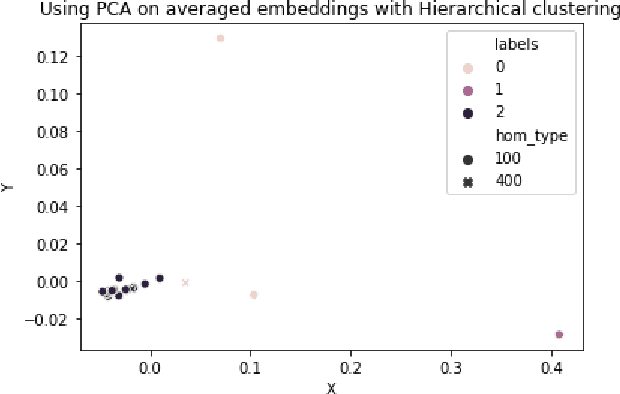
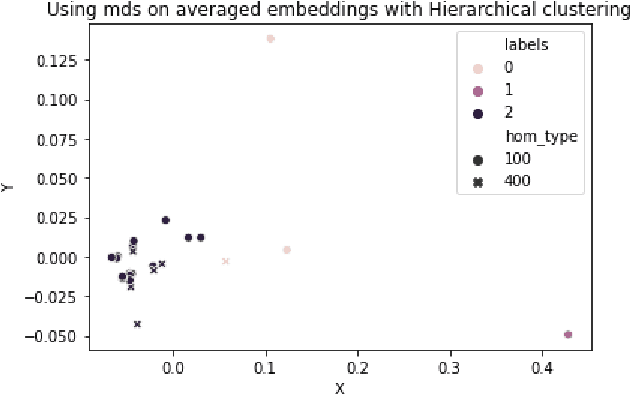
Homonym identification is important for WSD that require coarse-grained partitions of senses. The goal of this project is to determine whether contextual information is sufficient for identifying a homonymous word. To capture the context, BERT embeddings are used as opposed to Word2Vec, which conflates senses into one vector. SemCor is leveraged to retrieve the embeddings. Various clustering algorithms are applied to the embeddings. Finally, the embeddings are visualized in a lower-dimensional space to understand the feasibility of the clustering process.
Federated Multi-armed Bandits with Personalization
Feb 25, 2021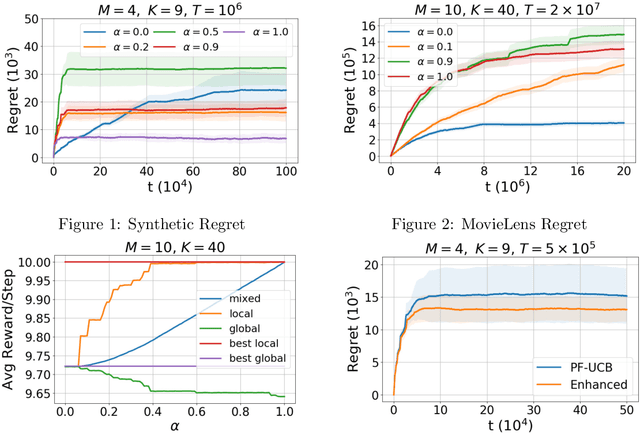
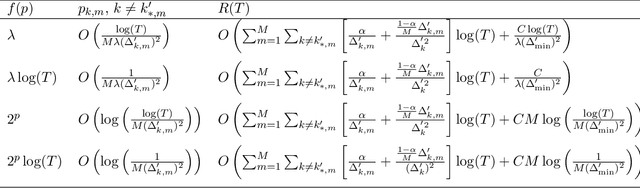
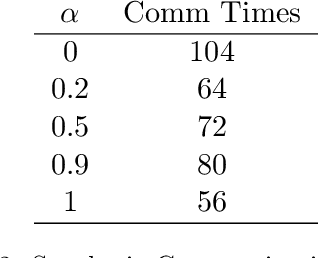
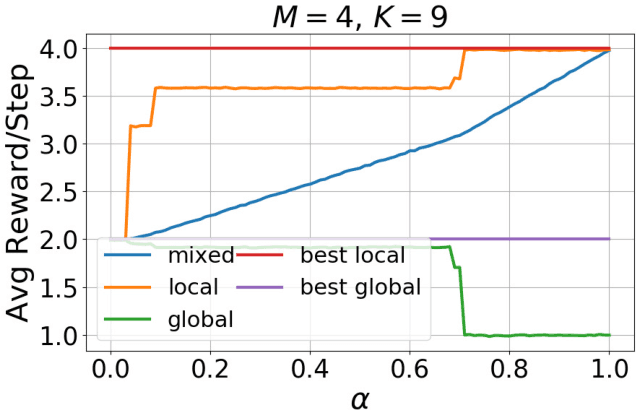
A general framework of personalized federated multi-armed bandits (PF-MAB) is proposed, which is a new bandit paradigm analogous to the federated learning (FL) framework in supervised learning and enjoys the features of FL with personalization. Under the PF-MAB framework, a mixed bandit learning problem that flexibly balances generalization and personalization is studied. A lower bound analysis for the mixed model is presented. We then propose the Personalized Federated Upper Confidence Bound (PF-UCB) algorithm, where the exploration length is chosen carefully to achieve the desired balance of learning the local model and supplying global information for the mixed learning objective. Theoretical analysis proves that PF-UCB achieves an $O(\log(T))$ regret regardless of the degree of personalization, and has a similar instance dependency as the lower bound. Experiments using both synthetic and real-world datasets corroborate the theoretical analysis and demonstrate the effectiveness of the proposed algorithm.
Learning to Select External Knowledge with Multi-Scale Negative Sampling
Feb 03, 2021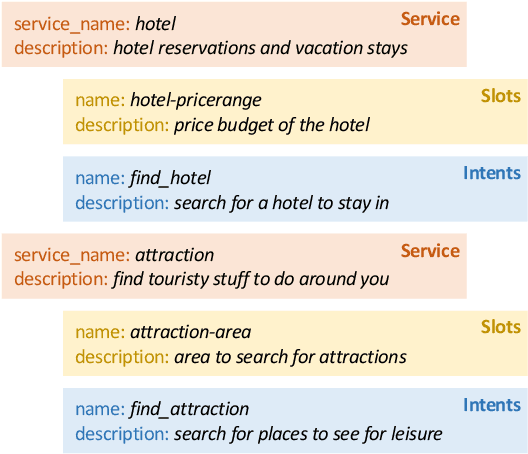
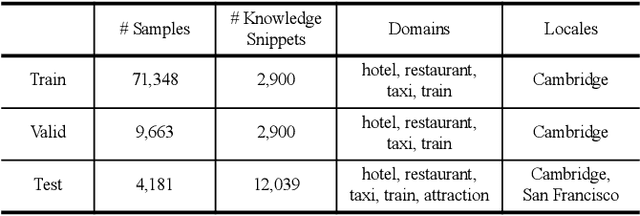
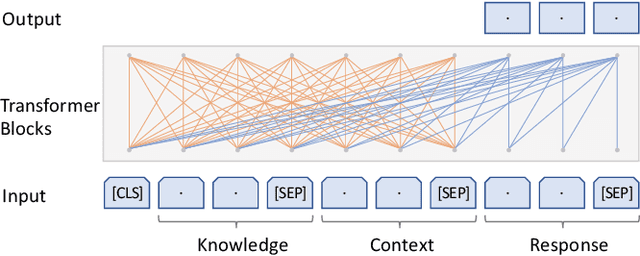
The Track-1 of DSTC9 aims to effectively answer user requests or questions during task-oriented dialogues, which are out of the scope of APIs/DB. By leveraging external knowledge resources, relevant information can be retrieved and encoded into the response generation for these out-of-API-coverage queries. In this work, we have explored several advanced techniques to enhance the utilization of external knowledge and boost the quality of response generation, including schema guided knowledge decision, negatives enhanced knowledge selection, and knowledge grounded response generation. To evaluate the performance of our proposed method, comprehensive experiments have been carried out on the publicly available dataset. Our approach was ranked as the best in human evaluation of DSTC9 Track-1.
Towards Fully Automated Manga Translation
Dec 29, 2020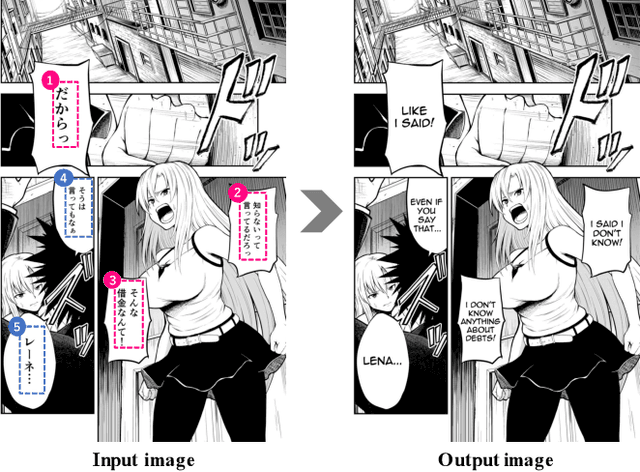
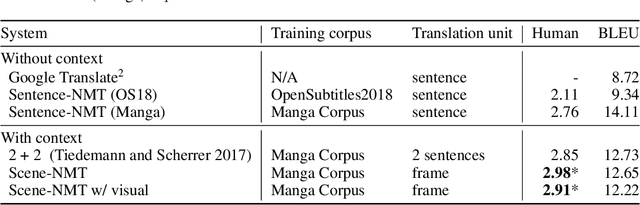
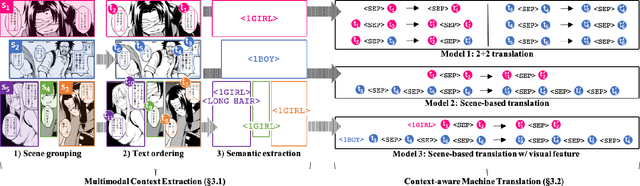
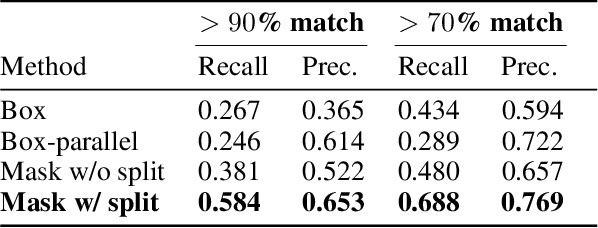
We tackle the problem of machine translation of manga, Japanese comics. Manga translation involves two important problems in machine translation: context-aware and multimodal translation. Since text and images are mixed up in an unstructured fashion in Manga, obtaining context from the image is essential for manga translation. However, it is still an open problem how to extract context from image and integrate into MT models. In addition, corpus and benchmarks to train and evaluate such model is currently unavailable. In this paper, we make the following four contributions that establishes the foundation of manga translation research. First, we propose multimodal context-aware translation framework. We are the first to incorporate context information obtained from manga image. It enables us to translate texts in speech bubbles that cannot be translated without using context information (e.g., texts in other speech bubbles, gender of speakers, etc.). Second, for training the model, we propose the approach to automatic corpus construction from pairs of original manga and their translations, by which large parallel corpus can be constructed without any manual labeling. Third, we created a new benchmark to evaluate manga translation. Finally, on top of our proposed methods, we devised a first comprehensive system for fully automated manga translation.
De-STT: De-entaglement of unwanted Nuisances and Biases in Speech to Text System using Adversarial Forgetting
Dec 01, 2020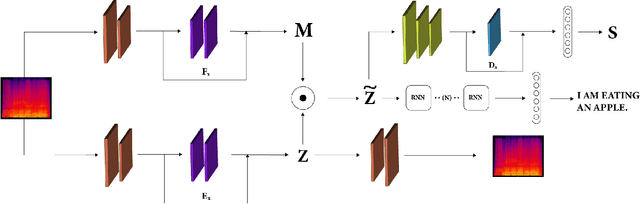

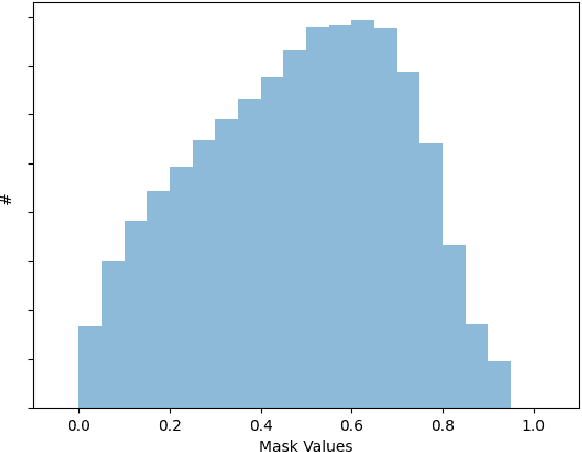
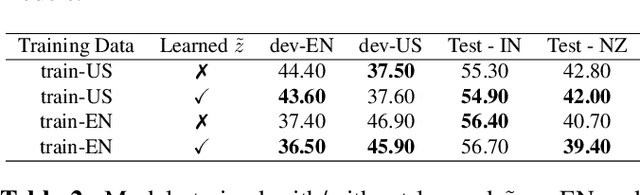
Training robust Speech to Text (STT) system require "tens of thousand" of hours of data. Variability present in the dataset, in the form of unwanted nuisances (noise) and biases (accent, gender or age) is the reason for the need of large datasets to learn general representations, which is unfeasible for low resource languages. A recently proposed deep learning approach to remove these unwanted features, called adversarial forgetting, was able to produce better results on computer vision tasks. Motivated by this, in this paper, we study the effect of de-entangling the accent information from the input speech signal on training STT systems. To this end, we use an information bottleneck architecture based on adversarial forgetting. This training scheme aims to enforce the model to learn general accent invariant speech representations. The trained STT model is tested on two unseen accents in the common voice V1. The results are in favour of STT model trained using the adversarial forgetting scheme.