 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Natural Language Understanding for Argumentative Dialogue Systems in the Opinion Building Domain
Mar 03, 2021
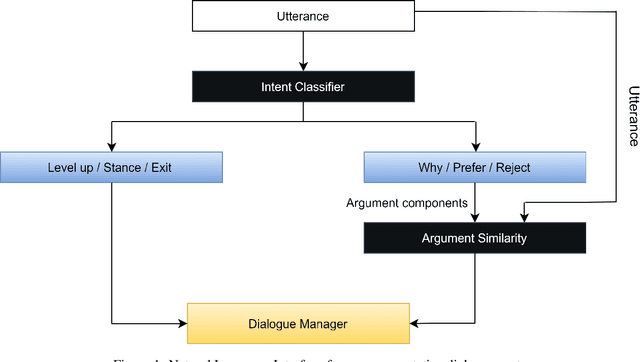

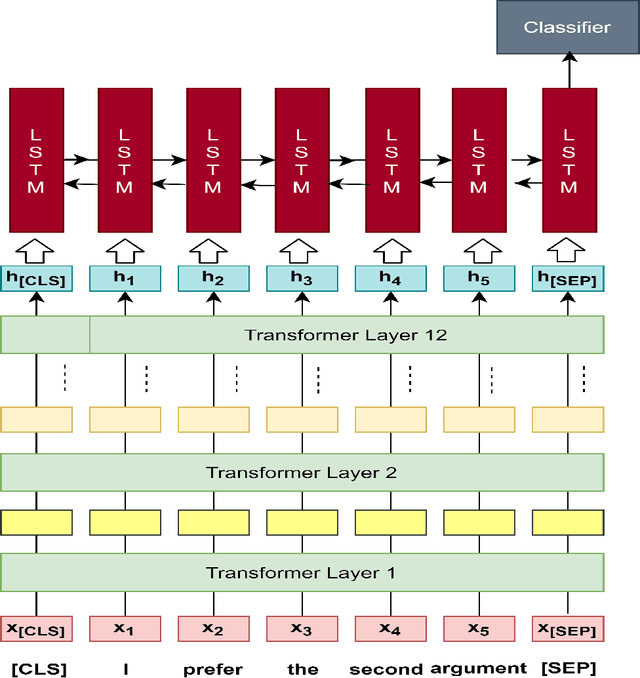

This paper introduces a natural language understanding (NLU) framework for argumentative dialogue systems in the information-seeking and opinion building domain. Our approach distinguishes multiple user intents and identifies system arguments the user refers to in his or her natural language utterances. Our model is applicable in an argumentative dialogue system that allows the user to inform him-/herself about and build his/her opinion towards a controversial topic. In order to evaluate the proposed approach, we collect user utterances for the interaction with the respective system and labeled with intent and reference argument in an extensive online study. The data collection includes multiple topics and two different user types (native speakers from the UK and non-native speakers from China). The evaluation indicates a clear advantage of the utilized techniques over baseline approaches, as well as a robustness of the proposed approach against new topics and different language proficiency as well as cultural background of the user.
Joint User Association and Power Allocation in Heterogeneous Ultra Dense Network via Semi-Supervised Representation Learning
Mar 29, 2021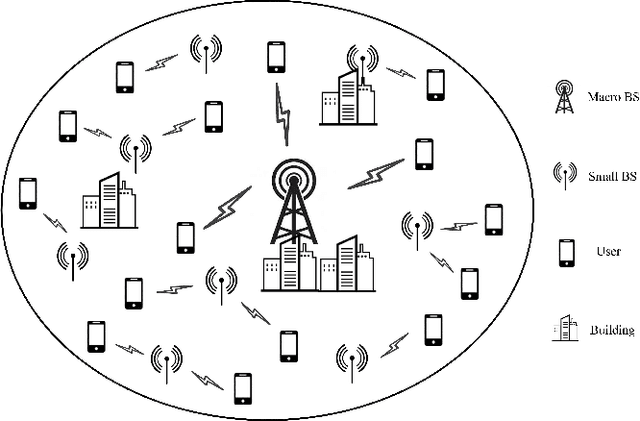
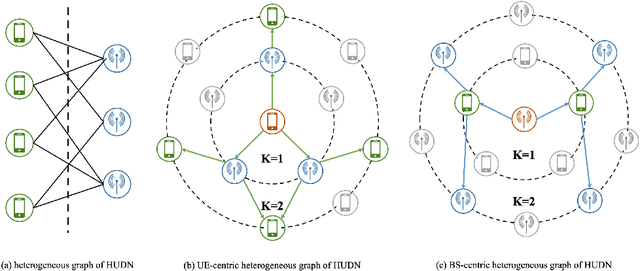
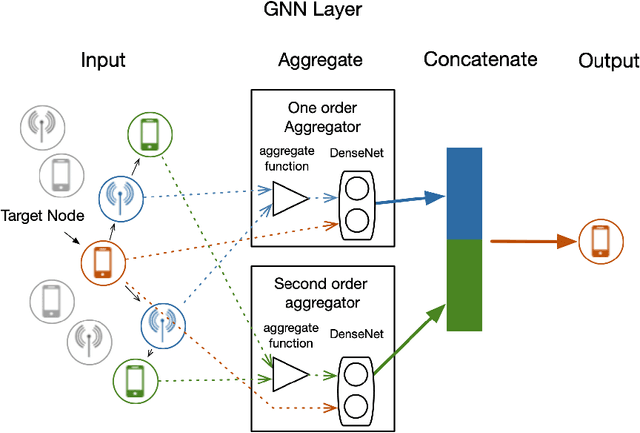
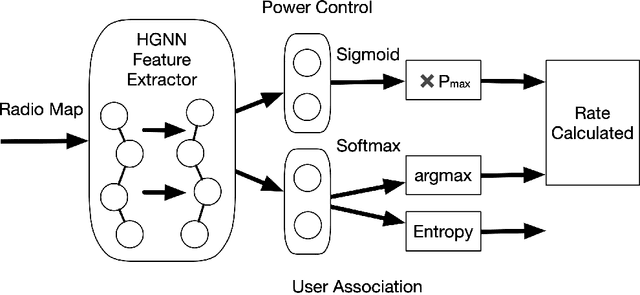
Heterogeneous Ultra-Dense Network (HUDN) is one of the vital networking architectures due to its ability to enable higher connectivity density and ultra-high data rates. Rational user association and power control schedule in HUDN can reduce wireless interference. This paper proposes a novel idea for resolving the joint user association and power control problem: the optimal user association and Base Station transmit power can be represented by channel information. Then, we solve this problem by formulating an optimal representation function. We model the HUDNs as a heterogeneous graph and train a Graph Neural Network (GNN) to approach this representation function by using semi-supervised learning, in which the loss function is composed of the unsupervised part that helps the GNN approach the optimal representation function and the supervised part that utilizes the previous experience to reduce useless exploration. We separate the learning process into two parts, the generalization-representation learning (GRL) part and the specialization-representation learning (SRL) part, which train the GNN for learning representation for generalized scenario quasi-static user distribution scenario, respectively. Simulation results demonstrate that the proposed GRL-based solution has higher computational efficiency than the traditional optimization algorithm, and the performance of SRL outperforms the GRL.
DRL-FAS: A Novel Framework Based on Deep Reinforcement Learning for Face Anti-Spoofing
Sep 16, 2020
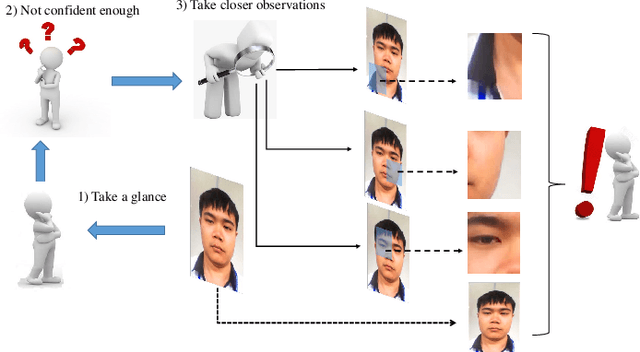
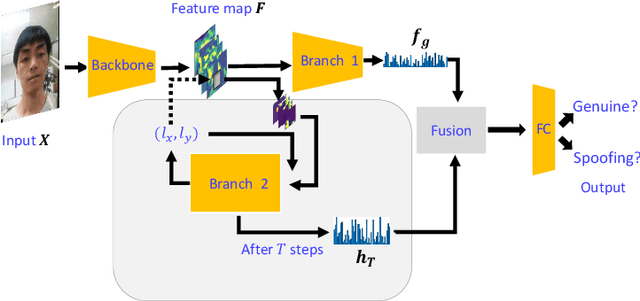
Inspired by the philosophy employed by human beings to determine whether a presented face example is genuine or not, i.e., to glance at the example globally first and then carefully observe the local regions to gain more discriminative information, for the face anti-spoofing problem, we propose a novel framework based on the Convolutional Neural Network (CNN) and the Recurrent Neural Network (RNN). In particular, we model the behavior of exploring face-spoofing-related information from image sub-patches by leveraging deep reinforcement learning. We further introduce a recurrent mechanism to learn representations of local information sequentially from the explored sub-patches with an RNN. Finally, for the classification purpose, we fuse the local information with the global one, which can be learned from the original input image through a CNN. Moreover, we conduct extensive experiments, including ablation study and visualization analysis, to evaluate our proposed framework on various public databases. The experiment results show that our method can generally achieve state-of-the-art performance among all scenarios, demonstrating its effectiveness.
Learning Defense Transformers for Counterattacking Adversarial Examples
Mar 13, 2021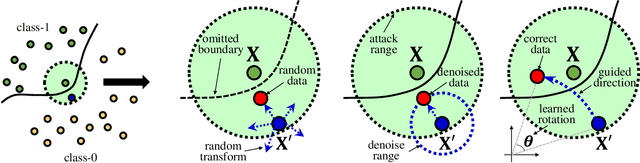
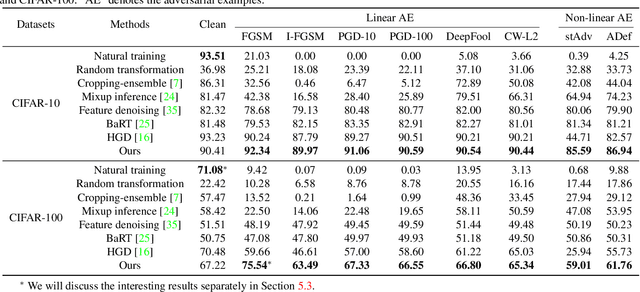
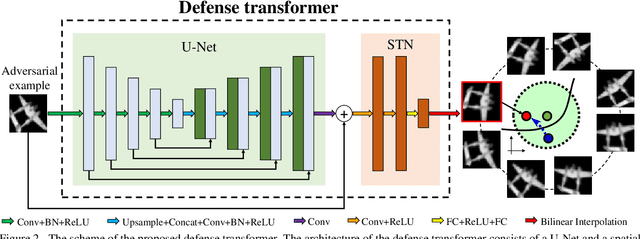
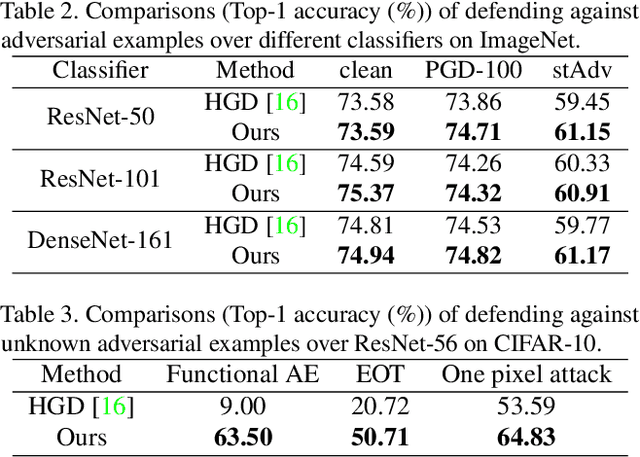
Deep neural networks (DNNs) are vulnerable to adversarial examples with small perturbations. Adversarial defense thus has been an important means which improves the robustness of DNNs by defending against adversarial examples. Existing defense methods focus on some specific types of adversarial examples and may fail to defend well in real-world applications. In practice, we may face many types of attacks where the exact type of adversarial examples in real-world applications can be even unknown. In this paper, motivated by that adversarial examples are more likely to appear near the classification boundary, we study adversarial examples from a new perspective that whether we can defend against adversarial examples by pulling them back to the original clean distribution. We theoretically and empirically verify the existence of defense affine transformations that restore adversarial examples. Relying on this, we learn a defense transformer to counterattack the adversarial examples by parameterizing the affine transformations and exploiting the boundary information of DNNs. Extensive experiments on both toy and real-world datasets demonstrate the effectiveness and generalization of our defense transformer.
3D coherent x-ray imaging via deep convolutional neural networks
Feb 26, 2021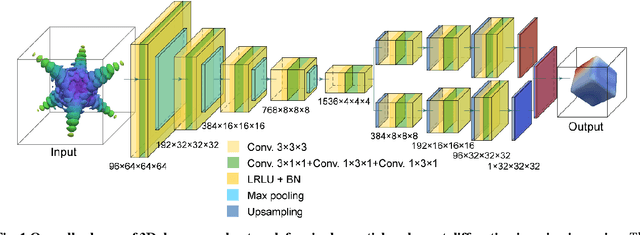
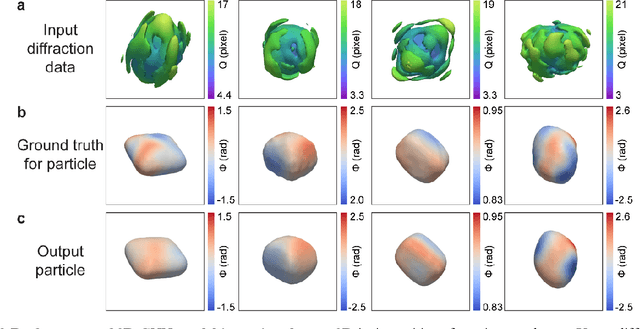
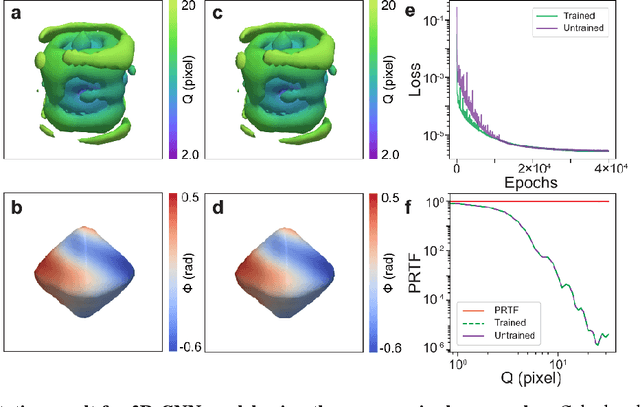
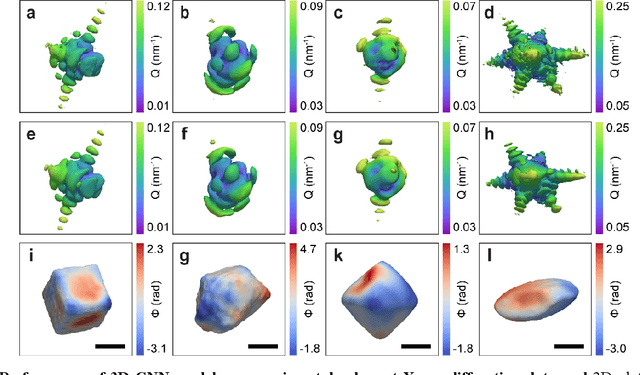
As a critical component of coherent X-ray diffraction imaging (CDI), phase retrieval has been extensively applied in X-ray structural science to recover the 3D morphological information inside measured particles. Despite meeting all the oversampling requirements of Sayre and Shannon, current phase retrieval approaches still have trouble achieving a unique inversion of experimental data in the presence of noise. Here, we propose to overcome this limitation by incorporating a 3D Machine Learning (ML) model combining (optional) supervised training with unsupervised refinement. The trained ML model can rapidly provide an immediate result with high accuracy, which will benefit real-time experiments. More significantly, the Neural Network model can be used without any prior training to learn the missing phases of an image based on minimization of an appropriate loss function alone. We demonstrate significantly improved performance with experimental Bragg CDI data over traditional iterative phase retrieval algorithms.
PURSUhInT: In Search of Informative Hint Points Based on Layer Clustering for Knowledge Distillation
Feb 26, 2021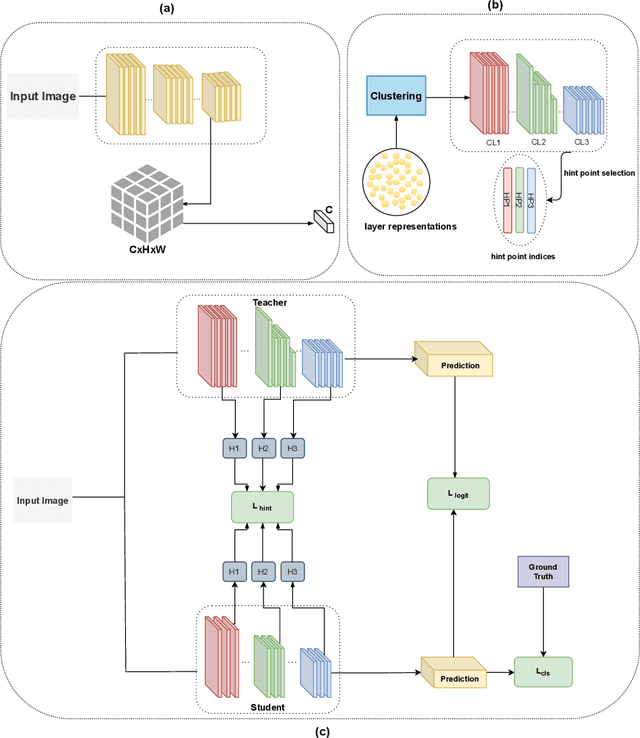
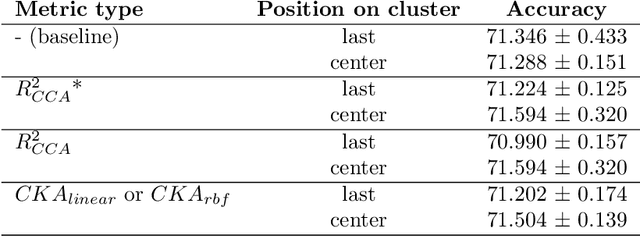
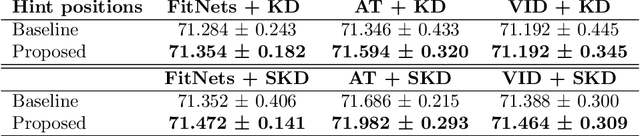
We propose a novel knowledge distillation methodology for compressing deep neural networks. One of the most efficient methods for knowledge distillation is hint distillation, where the student model is injected with information (hints) from several different layers of the teacher model. Although the selection of hint points can drastically alter the compression performance, there is no systematic approach for selecting them, other than brute-force hyper-parameter search. We propose a clustering based hint selection methodology, where the layers of teacher model are clustered with respect to several metrics and the cluster centers are used as the hint points. The proposed approach is validated in CIFAR-100 dataset, where ResNet-110 network was used as the teacher model. Our results show that hint points selected by our algorithm results in superior compression performance with respect to state-of-the-art knowledge distillation algorithms on the same student models and datasets.
Heterogeneous Federated Learning
Aug 15, 2020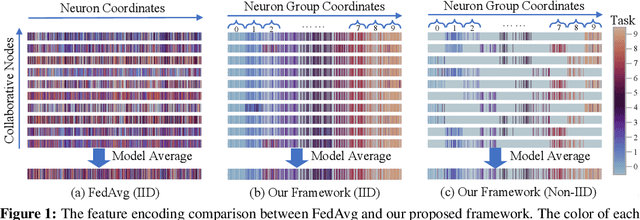
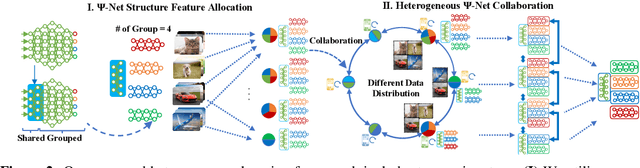
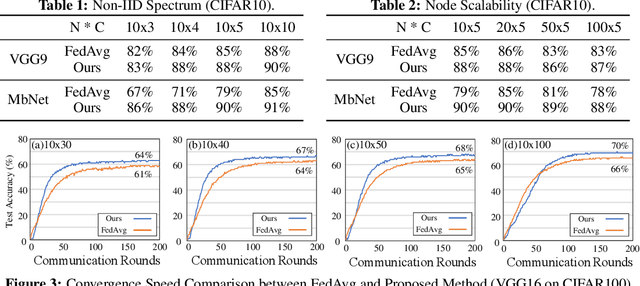
Federated learning learns from scattered data by fusing collaborative models from local nodes. However, due to chaotic information distribution, the model fusion may suffer from structural misalignment with regard to unmatched parameters. In this work, we propose a novel federated learning framework to resolve this issue by establishing a firm structure-information alignment across collaborative models. Specifically, we design a feature-oriented regulation method ({$\Psi$-Net}) to ensure explicit feature information allocation in different neural network structures. Applying this regulating method to collaborative models, matchable structures with similar feature information can be initialized at the very early training stage. During the federated learning process under either IID or non-IID scenarios, dedicated collaboration schemes further guarantee ordered information distribution with definite structure matching, so as the comprehensive model alignment. Eventually, this framework effectively enhances the federated learning applicability to extensive heterogeneous settings, while providing excellent convergence speed, accuracy, and computation/communication efficiency.
Word2vec Skip-gram Dimensionality Selection via Sequential Normalized Maximum Likelihood
Aug 18, 2020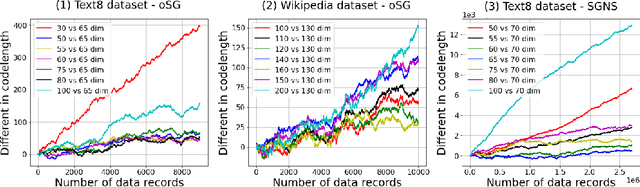

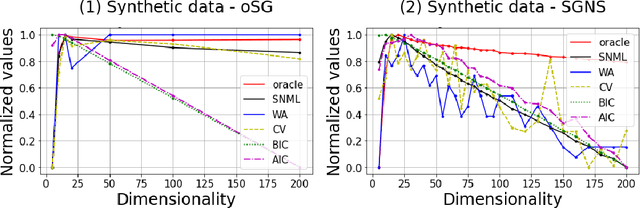
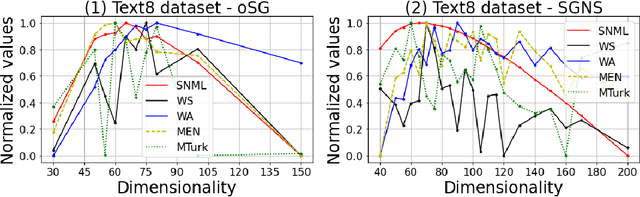
In this paper, we propose a novel information criteria-based approach to select the dimensionality of the word2vec Skip-gram (SG). From the perspective of the probability theory, SG is considered as an implicit probability distribution estimation under the assumption that there exists a true contextual distribution among words. Therefore, we apply information criteria with the aim of selecting the best dimensionality so that the corresponding model can be as close as possible to the true distribution. We examine the following information criteria for the dimensionality selection problem: the Akaike Information Criterion, Bayesian Information Criterion, and Sequential Normalized Maximum Likelihood (SNML) criterion. SNML is the total codelength required for the sequential encoding of a data sequence on the basis of the minimum description length. The proposed approach is applied to both the original SG model and the SG Negative Sampling model to clarify the idea of using information criteria. Additionally, as the original SNML suffers from computational disadvantages, we introduce novel heuristics for its efficient computation. Moreover, we empirically demonstrate that SNML outperforms both BIC and AIC. In comparison with other evaluation methods for word embedding, the dimensionality selected by SNML is significantly closer to the optimal dimensionality obtained by word analogy or word similarity tasks.
Ptychography Intensity Interferometry Imaging for Dynamic Distant Object
Feb 10, 2021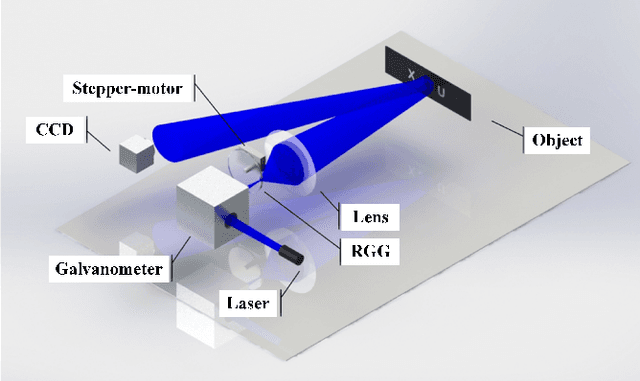



As a promising lensless imaging method for distance objects, intensity interferometry imaging (III) had been suffering from the unreliable phase retrieval process, hindering the development of III for decades. Recently, the introduction of the ptychographic detection in III overcame this challenge, and a method called ptychographic III (PIII) was proposed. We here experimentally demonstrate that PIII can image a dynamic distance object. A reasonable image for the moving object can be retrieved with only two speckle patterns for each probe, and only 10 to 20 iterations are needed. Meanwhile, PIII exhibits robust to the inaccurate information of the probe. Furthermore, PIII successfully recovers the image through a fog obfuscating the imaging light path, under which a conventional camera relying on lenses fails to provide a recognizable image.
Distributed Learning and Democratic Embeddings: Polynomial-Time Source Coding Schemes Can Achieve Minimax Lower Bounds for Distributed Gradient Descent under Communication Constraints
Mar 13, 2021
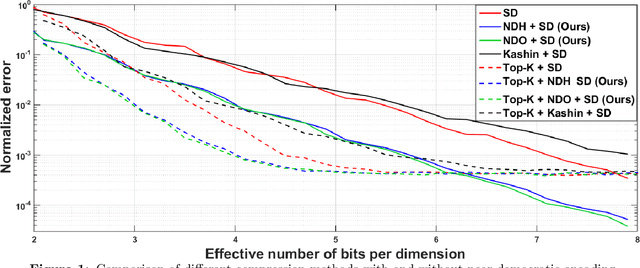
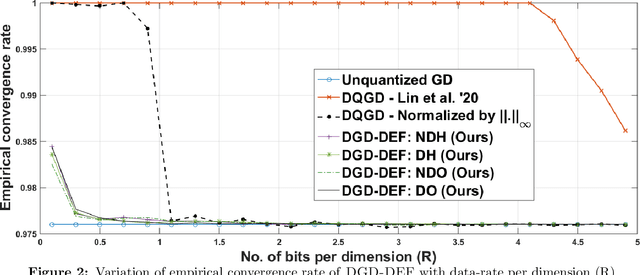
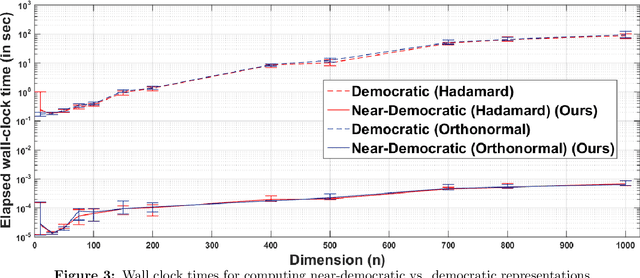
In this work, we consider the distributed optimization setting where information exchange between the computation nodes and the parameter server is subject to a maximum bit-budget. We first consider the problem of compressing a vector in the n-dimensional Euclidean space, subject to a bit-budget of R-bits per dimension, for which we introduce Democratic and Near-Democratic source-coding schemes. We show that these coding schemes are (near) optimal in the sense that the covering efficiency of the resulting quantizer is either dimension independent, or has a very weak logarithmic dependence. Subsequently, we propose a distributed optimization algorithm: DGD-DEF, which employs our proposed coding strategy, and achieves the minimax optimal convergence rate to within (near) constant factors for a class of communication-constrained distributed optimization algorithms. Furthermore, we extend the utility of our proposed source coding scheme by showing that it can remarkably improve the performance when used in conjunction with other compression schemes. We validate our theoretical claims through numerical simulations. Keywords: Fast democratic (Kashin) embeddings, Distributed optimization, Data-rate constraint, Quantized gradient descent, Error feedback.