 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Digital rock reconstruction with user-defined properties using conditional generative adversarial networks
Nov 29, 2020
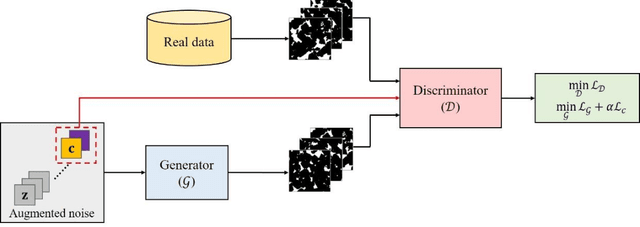
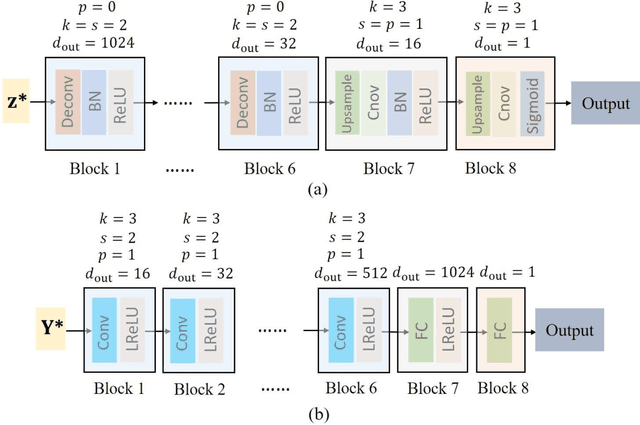

Uncertainty is ubiquitous with flow in subsurface rocks because of their inherent heterogeneity and lack of in-situ measurements. To complete uncertainty analysis in a multi-scale manner, it is a prerequisite to provide sufficient rock samples. Even though the advent of digital rock technology offers opportunities to reproduce rocks, it still cannot be utilized to provide massive samples due to its high cost, thus leading to the development of diversified mathematical methods. Among them, two-point statistics (TPS) and multi-point statistics (MPS) are commonly utilized, which feature incorporating low-order and high-order statistical information, respectively. Recently, generative adversarial networks (GANs) are becoming increasingly popular since they can reproduce training images with excellent visual and consequent geologic realism. However, standard GANs can only incorporate information from data, while leaving no interface for user-defined properties, and thus may limit the diversity of reconstructed samples. In this study, we propose conditional GANs for digital rock reconstruction, aiming to reproduce samples not only similar to the real training data, but also satisfying user-specified properties. In fact, the proposed framework can realize the targets of MPS and TPS simultaneously by incorporating high-order information directly from rock images with the GANs scheme, while preserving low-order counterparts through conditioning. We conduct three reconstruction experiments, and the results demonstrate that rock type, rock porosity, and correlation length can be successfully conditioned to affect the reconstructed rock images. Furthermore, in contrast to existing GANs, the proposed conditioning enables learning of multiple rock types simultaneously, and thus invisibly saves the computational cost.
DRL-FAS: A Novel Framework Based on Deep Reinforcement Learning for Face Anti-Spoofing
Sep 18, 2020
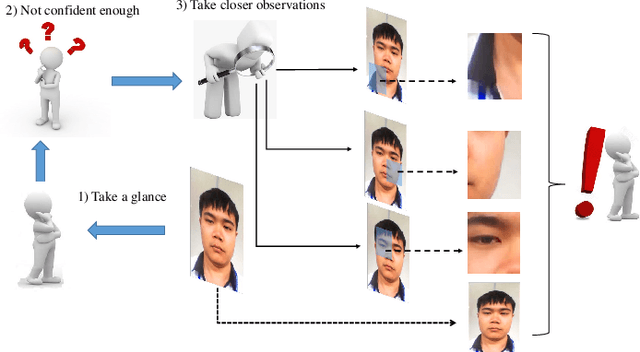
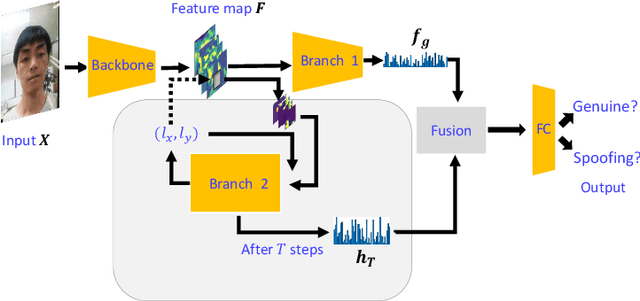
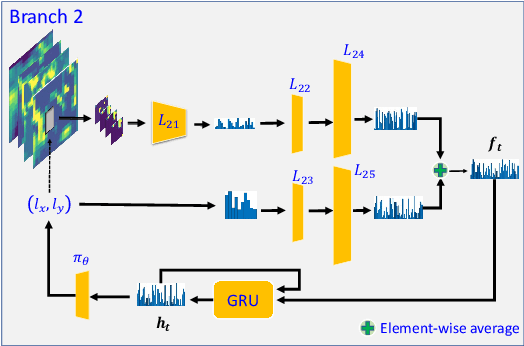
Inspired by the philosophy employed by human beings to determine whether a presented face example is genuine or not, i.e., to glance at the example globally first and then carefully observe the local regions to gain more discriminative information, for the face anti-spoofing problem, we propose a novel framework based on the Convolutional Neural Network (CNN) and the Recurrent Neural Network (RNN). In particular, we model the behavior of exploring face-spoofing-related information from image sub-patches by leveraging deep reinforcement learning. We further introduce a recurrent mechanism to learn representations of local information sequentially from the explored sub-patches with an RNN. Finally, for the classification purpose, we fuse the local information with the global one, which can be learned from the original input image through a CNN. Moreover, we conduct extensive experiments, including ablation study and visualization analysis, to evaluate our proposed framework on various public databases. The experiment results show that our method can generally achieve state-of-the-art performance among all scenarios, demonstrating its effectiveness.
Natural Language Understanding for Argumentative Dialogue Systems in the Opinion Building Domain
Mar 03, 2021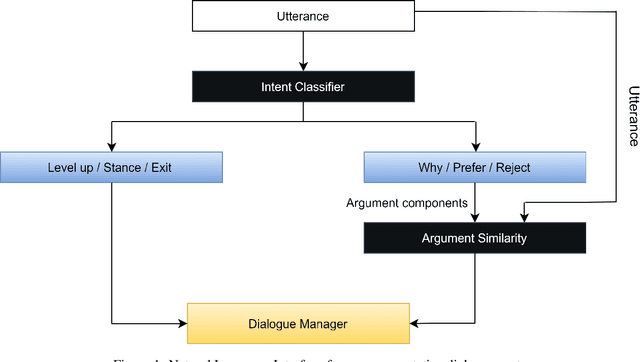

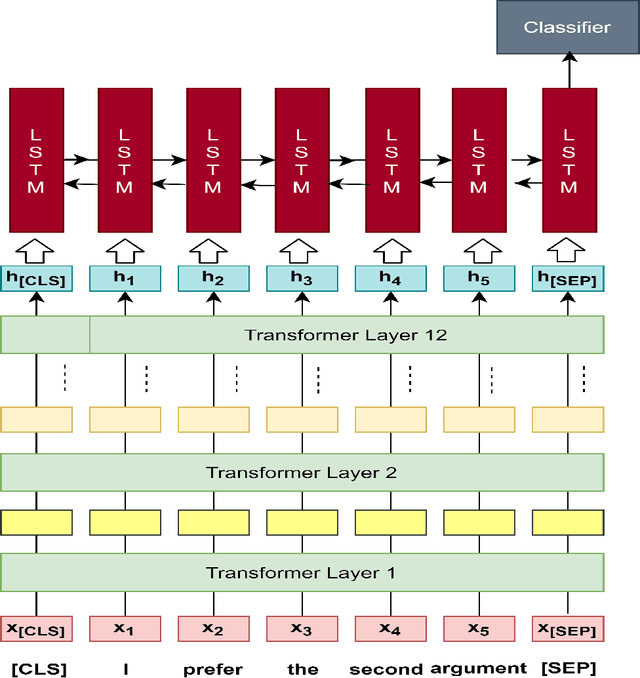

This paper introduces a natural language understanding (NLU) framework for argumentative dialogue systems in the information-seeking and opinion building domain. Our approach distinguishes multiple user intents and identifies system arguments the user refers to in his or her natural language utterances. Our model is applicable in an argumentative dialogue system that allows the user to inform him-/herself about and build his/her opinion towards a controversial topic. In order to evaluate the proposed approach, we collect user utterances for the interaction with the respective system and labeled with intent and reference argument in an extensive online study. The data collection includes multiple topics and two different user types (native speakers from the UK and non-native speakers from China). The evaluation indicates a clear advantage of the utilized techniques over baseline approaches, as well as a robustness of the proposed approach against new topics and different language proficiency as well as cultural background of the user.
Distributed Learning and Democratic Embeddings: Polynomial-Time Source Coding Schemes Can Achieve Minimax Lower Bounds for Distributed Gradient Descent under Communication Constraints
Mar 13, 2021
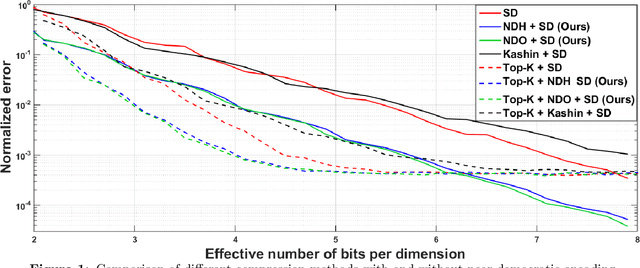
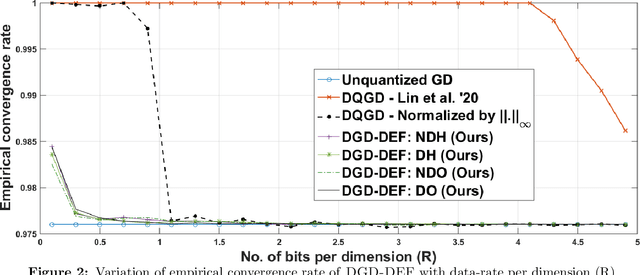
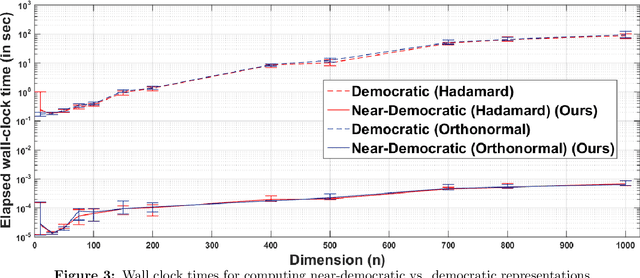
In this work, we consider the distributed optimization setting where information exchange between the computation nodes and the parameter server is subject to a maximum bit-budget. We first consider the problem of compressing a vector in the n-dimensional Euclidean space, subject to a bit-budget of R-bits per dimension, for which we introduce Democratic and Near-Democratic source-coding schemes. We show that these coding schemes are (near) optimal in the sense that the covering efficiency of the resulting quantizer is either dimension independent, or has a very weak logarithmic dependence. Subsequently, we propose a distributed optimization algorithm: DGD-DEF, which employs our proposed coding strategy, and achieves the minimax optimal convergence rate to within (near) constant factors for a class of communication-constrained distributed optimization algorithms. Furthermore, we extend the utility of our proposed source coding scheme by showing that it can remarkably improve the performance when used in conjunction with other compression schemes. We validate our theoretical claims through numerical simulations. Keywords: Fast democratic (Kashin) embeddings, Distributed optimization, Data-rate constraint, Quantized gradient descent, Error feedback.
Comparison of Possibilistic Fuzzy Local Information C-Means and Possibilistic K-Nearest Neighbors for Synthetic Aperture Sonar Image Segmentation
Apr 01, 2019Synthetic aperture sonar (SAS) imagery can generate high resolution images of the seafloor. Thus, segmentation algorithms can be used to partition the images into different seafloor environments. In this paper, we compare two possibilistic segmentation approaches. Possibilistic approaches allow for the ability to detect novel or outlier environments as well as well known classes. The Possibilistic Fuzzy Local Information C-Means (PFLICM) algorithm has been previously applied to segment SAS imagery. Additionally, the Possibilistic K-Nearest Neighbors (PKNN) algorithm has been used in other domains such as landmine detection and hyperspectral imagery. In this paper, we compare the segmentation performance of a semi-supervised approach using PFLICM and a supervised method using Possibilistic K-NN. We include final segmentation results on multiple SAS images and a quantitative assessment of each algorithm.
DEAAN: Disentangled Embedding and Adversarial Adaptation Network for Robust Speaker Representation Learning
Dec 12, 2020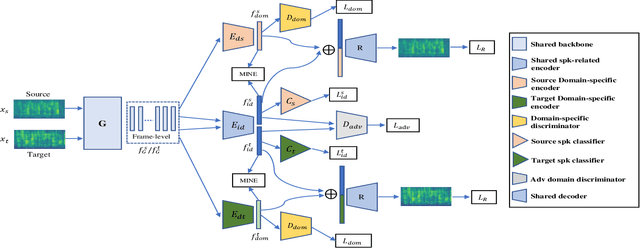
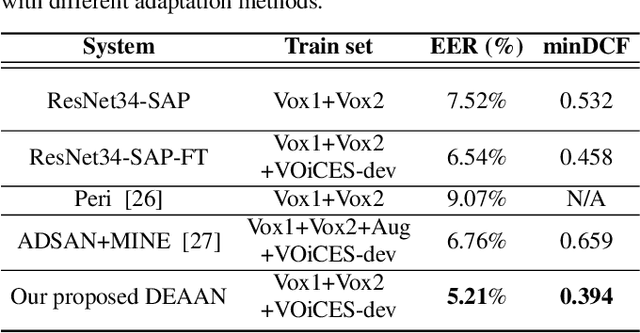
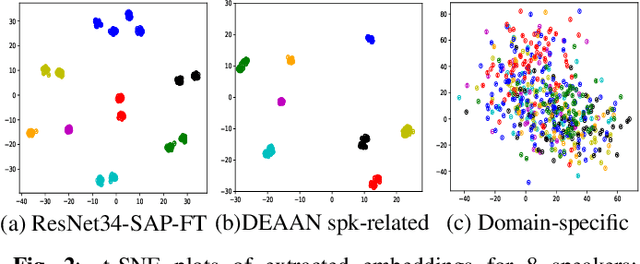
Despite speaker verification has achieved significant performance improvement with the development of deep neural networks, domain mismatch is still a challenging problem in this field. In this study, we propose a novel framework to disentangle speaker-related and domain-specific features and apply domain adaptation on the speaker-related feature space solely. Instead of performing domain adaptation directly on the feature space where domain information is not removed, using disentanglement can efficiently boost adaptation performance. To be specific, our model's input speech from the source and target domains is first encoded into different latent feature spaces. The adversarial domain adaptation is conducted on the shared speaker-related feature space to encourage the property of domain-invariance. Further, we minimize the mutual information between speaker-related and domain-specific features for both domains to enforce the disentanglement. Experimental results on the VOiCES dataset demonstrate that our proposed framework can effectively generate more speaker-discriminative and domain-invariant speaker representations with a relative 20.3% reduction of EER compared to the original ResNet-based system.
3D coherent x-ray imaging via deep convolutional neural networks
Feb 26, 2021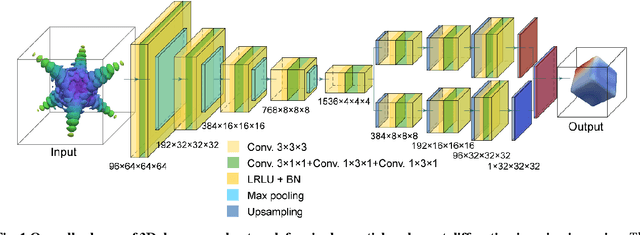
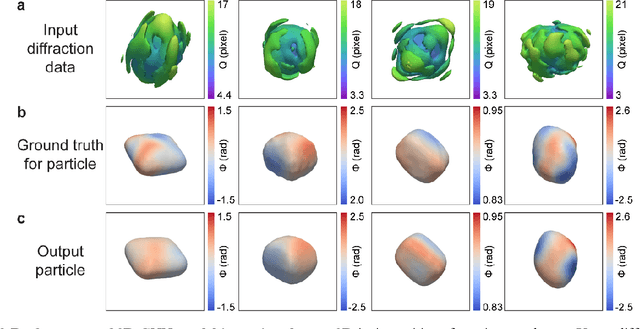
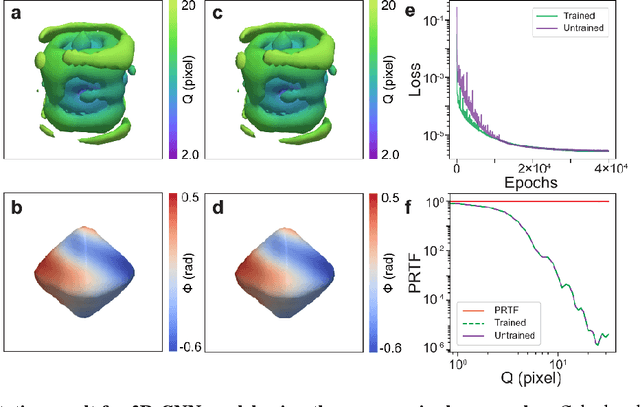
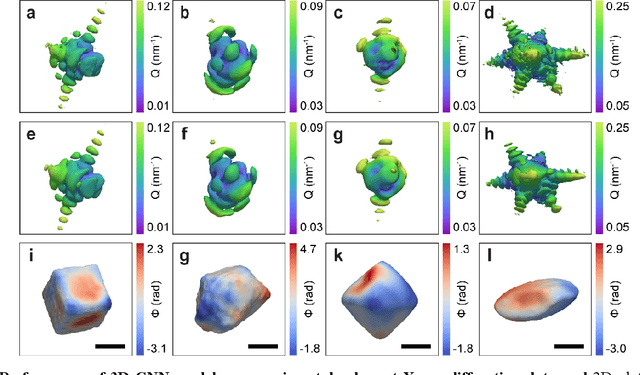
As a critical component of coherent X-ray diffraction imaging (CDI), phase retrieval has been extensively applied in X-ray structural science to recover the 3D morphological information inside measured particles. Despite meeting all the oversampling requirements of Sayre and Shannon, current phase retrieval approaches still have trouble achieving a unique inversion of experimental data in the presence of noise. Here, we propose to overcome this limitation by incorporating a 3D Machine Learning (ML) model combining (optional) supervised training with unsupervised refinement. The trained ML model can rapidly provide an immediate result with high accuracy, which will benefit real-time experiments. More significantly, the Neural Network model can be used without any prior training to learn the missing phases of an image based on minimization of an appropriate loss function alone. We demonstrate significantly improved performance with experimental Bragg CDI data over traditional iterative phase retrieval algorithms.
A Learned Compact and Editable Light Field Representation
Mar 21, 2021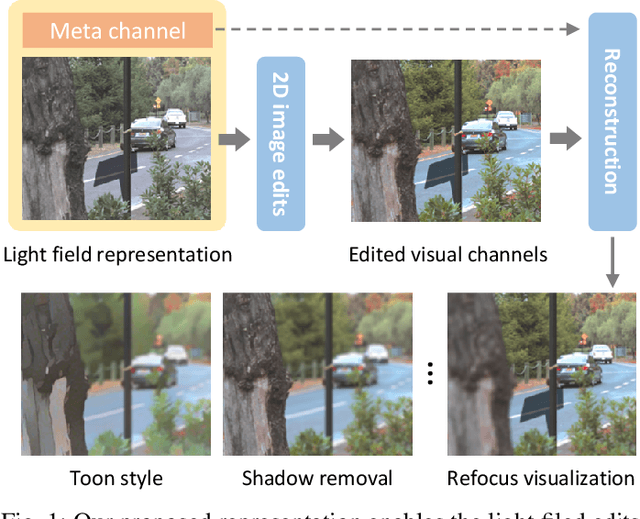



Light fields are 4D scene representation typically structured as arrays of views, or several directional samples per pixel in a single view. This highly correlated structure is not very efficient to transmit and manipulate (especially for editing), though. To tackle these problems, we present a novel compact and editable light field representation, consisting of a set of visual channels (i.e. the central RGB view) and a complementary meta channel that encodes the residual geometric and appearance information. The visual channels in this representation can be edited using existing 2D image editing tools, before accurately reconstructing the whole edited light field back. We propose to learn this representation via an autoencoder framework, consisting of an encoder for learning the representation, and a decoder for reconstructing the light field. To handle the challenging occlusions and propagation of edits, we specifically designed an editing-aware decoding network and its associated training strategy, so that the edits to the visual channels can be consistently propagated to the whole light field upon reconstruction.Experimental results show that our proposed method outperforms related existing methods in reconstruction accuracy, and achieves visually pleasant performance in editing propagation.
PURSUhInT: In Search of Informative Hint Points Based on Layer Clustering for Knowledge Distillation
Feb 26, 2021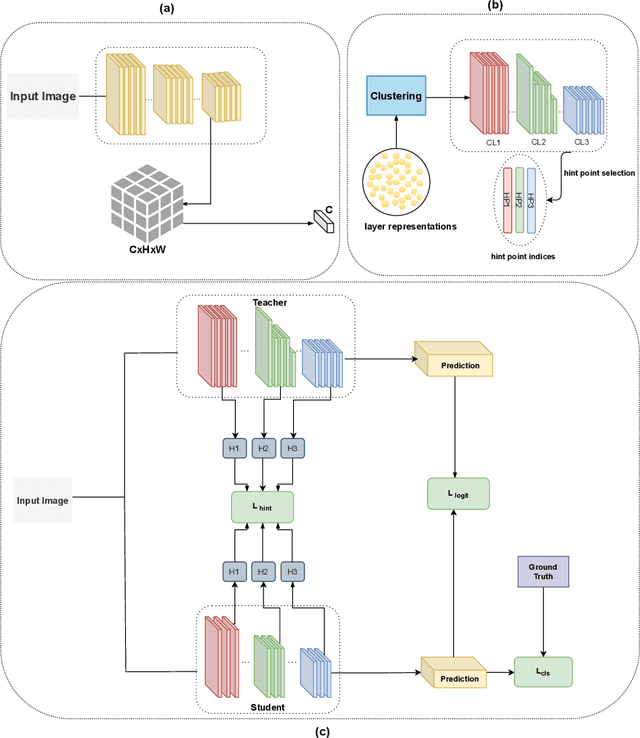
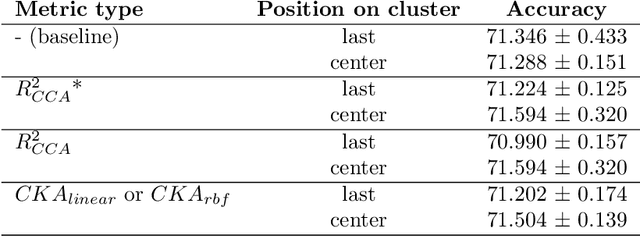
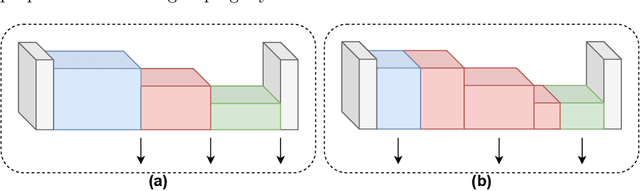
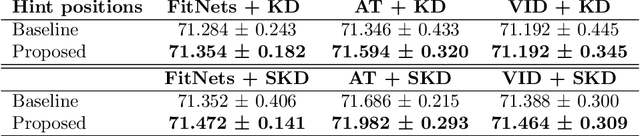
We propose a novel knowledge distillation methodology for compressing deep neural networks. One of the most efficient methods for knowledge distillation is hint distillation, where the student model is injected with information (hints) from several different layers of the teacher model. Although the selection of hint points can drastically alter the compression performance, there is no systematic approach for selecting them, other than brute-force hyper-parameter search. We propose a clustering based hint selection methodology, where the layers of teacher model are clustered with respect to several metrics and the cluster centers are used as the hint points. The proposed approach is validated in CIFAR-100 dataset, where ResNet-110 network was used as the teacher model. Our results show that hint points selected by our algorithm results in superior compression performance with respect to state-of-the-art knowledge distillation algorithms on the same student models and datasets.
Multi-Channel and Multi-Microphone Acoustic Echo Cancellation Using A Deep Learning Based Approach
Mar 03, 2021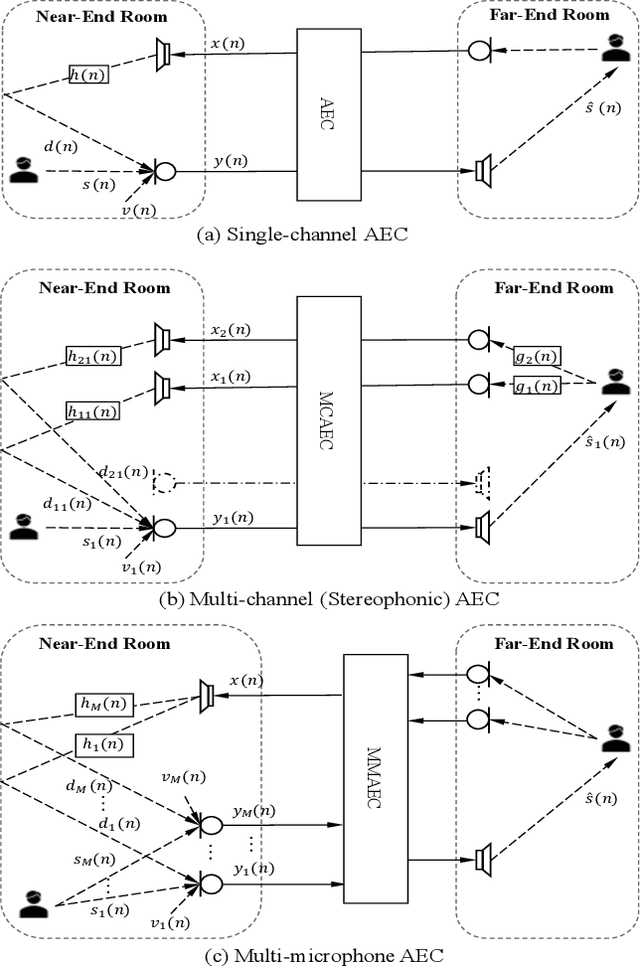
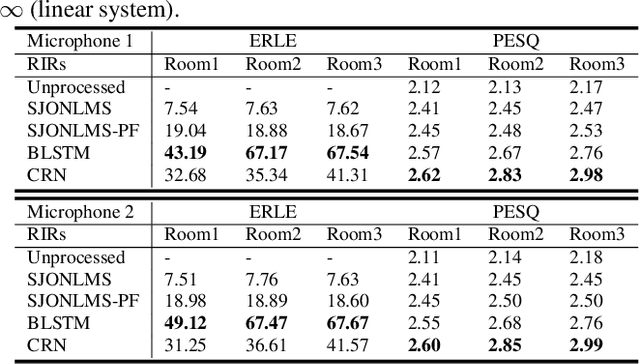
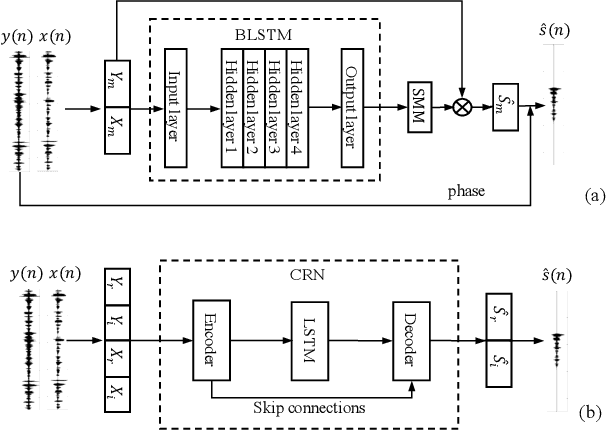
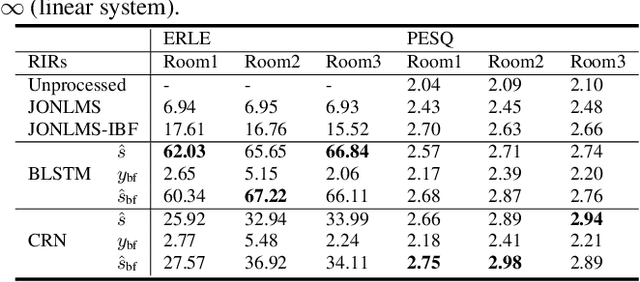
Building on the deep learning based acoustic echo cancellation (AEC) in the single-loudspeaker (single-channel) and single-microphone setup, this paper investigates multi-channel AEC (MCAEC) and multi-microphone AEC (MMAEC). We train a deep neural network (DNN) to predict the near-end speech from microphone signals with far-end signals used as additional information. We find that the deep learning approach avoids the non-uniqueness problem in traditional MCAEC algorithms. For the AEC setup with multiple microphones, rather than employing AEC for each microphone, a single DNN is trained to achieve echo removal for all microphones. Also, combining deep learning based AEC with deep learning based beamforming further improves the system performance. Experimental results show the effectiveness of both bidirectional long short-term memory (BLSTM) and convolutional recurrent network (CRN) based methods for MCAEC and MMAEC. Furthermore, deep learning based methods are capable of removing echo and noise simultaneously and work well in the presence of nonlinear distortions.