 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Opinion-aware Answer Generation for Review-driven Question Answering in E-Commerce
Aug 28, 2020
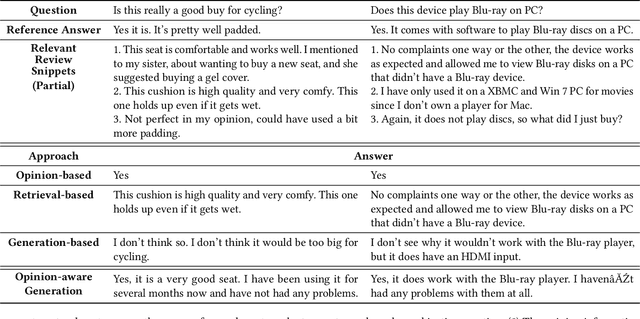
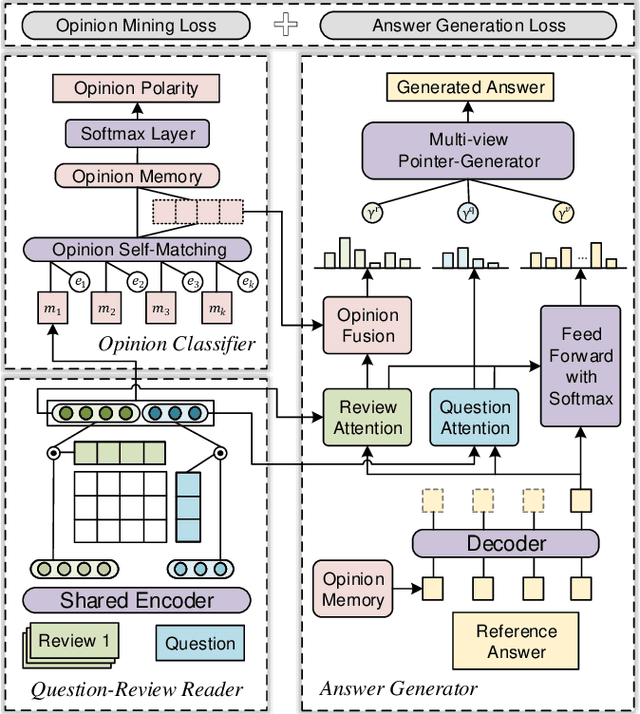
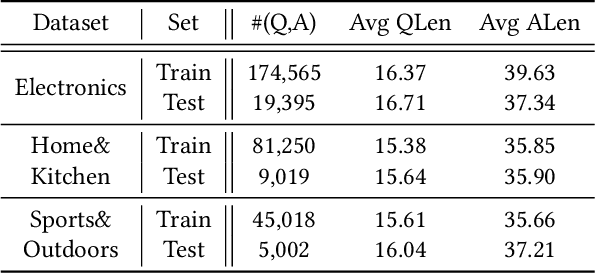
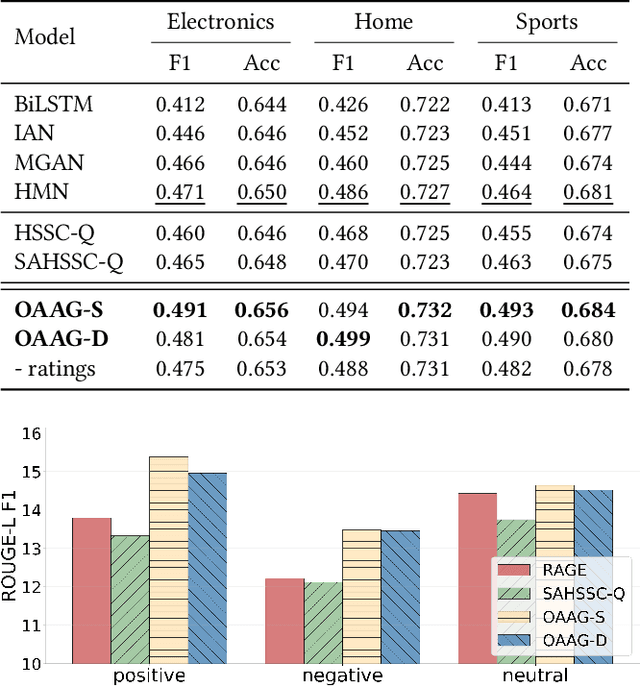
Product-related question answering (QA) is an important but challenging task in E-Commerce. It leads to a great demand on automatic review-driven QA, which aims at providing instant responses towards user-posted questions based on diverse product reviews. Nevertheless, the rich information about personal opinions in product reviews, which is essential to answer those product-specific questions, is underutilized in current generation-based review-driven QA studies. There are two main challenges when exploiting the opinion information from the reviews to facilitate the opinion-aware answer generation: (i) jointly modeling opinionated and interrelated information between the question and reviews to capture important information for answer generation, (ii) aggregating diverse opinion information to uncover the common opinion towards the given question. In this paper, we tackle opinion-aware answer generation by jointly learning answer generation and opinion mining tasks with a unified model. Two kinds of opinion fusion strategies, namely, static and dynamic fusion, are proposed to distill and aggregate important opinion information learned from the opinion mining task into the answer generation process. Then a multi-view pointer-generator network is employed to generate opinion-aware answers for a given product-related question. Experimental results show that our method achieves superior performance in real-world E-Commerce QA datasets, and effectively generate opinionated and informative answers.
DeepTag: An Unsupervised Deep Learning Method for Motion Tracking on Cardiac Tagging Magnetic Resonance Images
Mar 13, 2021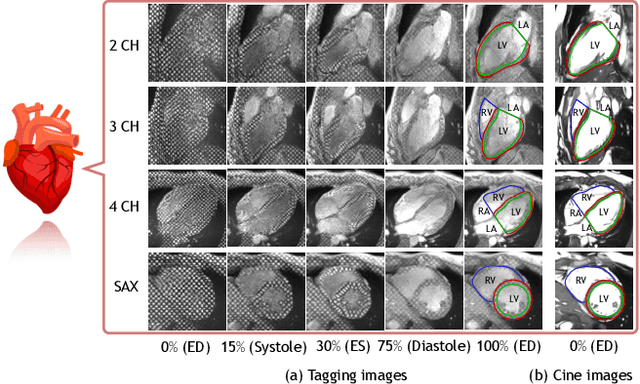
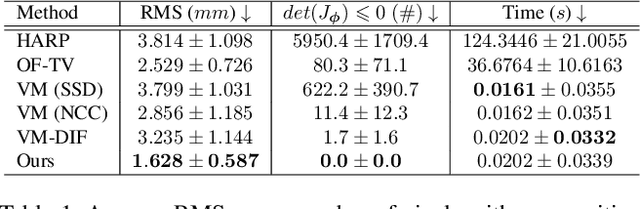
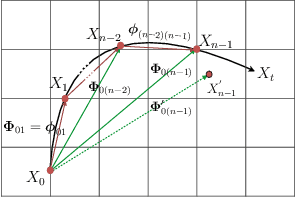
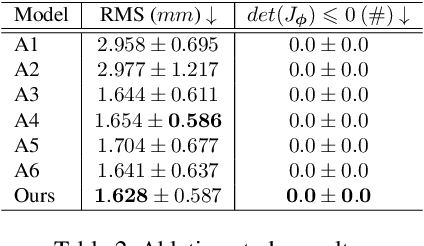
Cardiac tagging magnetic resonance imaging (t-MRI) is the gold standard for regional myocardium deformation and cardiac strain estimation. However, this technique has not been widely used in clinical diagnosis, as a result of the difficulty of motion tracking encountered with t-MRI images. In this paper, we propose a novel deep learning-based fully unsupervised method for in vivo motion tracking on t-MRI images. We first estimate the motion field (INF) between any two consecutive t-MRI frames by a bi-directional generative diffeomorphic registration neural network. Using this result, we then estimate the Lagrangian motion field between the reference frame and any other frame through a differentiable composition layer. By utilizing temporal information to perform reasonable estimations on spatio-temporal motion fields, this novel method provides a useful solution for motion tracking and image registration in dynamic medical imaging. Our method has been validated on a representative clinical t-MRI dataset; the experimental results show that our method is superior to conventional motion tracking methods in terms of landmark tracking accuracy and inference efficiency.
Reinforcement Learning with Prototypical Representations
Feb 22, 2021
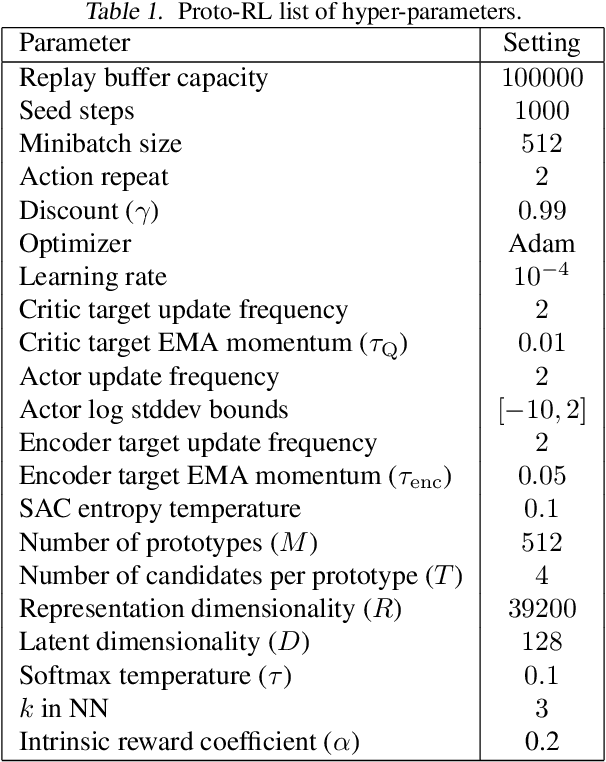
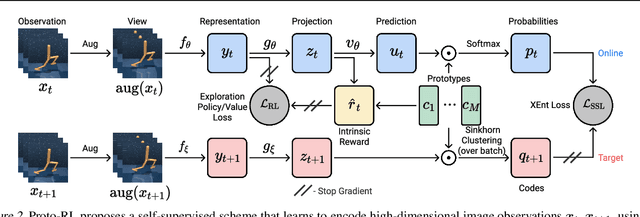
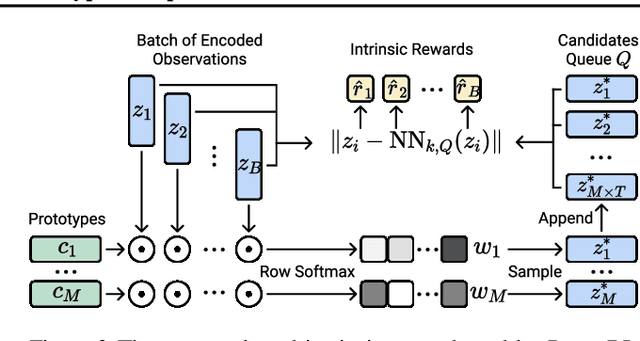
Learning effective representations in image-based environments is crucial for sample efficient Reinforcement Learning (RL). Unfortunately, in RL, representation learning is confounded with the exploratory experience of the agent -- learning a useful representation requires diverse data, while effective exploration is only possible with coherent representations. Furthermore, we would like to learn representations that not only generalize across tasks but also accelerate downstream exploration for efficient task-specific training. To address these challenges we propose Proto-RL, a self-supervised framework that ties representation learning with exploration through prototypical representations. These prototypes simultaneously serve as a summarization of the exploratory experience of an agent as well as a basis for representing observations. We pre-train these task-agnostic representations and prototypes on environments without downstream task information. This enables state-of-the-art downstream policy learning on a set of difficult continuous control tasks.
A Survey on Multimodal Disinformation Detection
Mar 13, 2021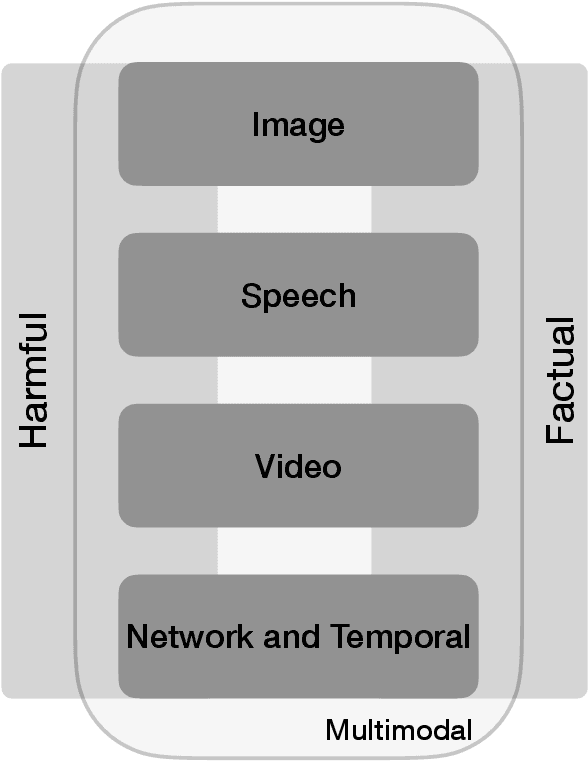
Recent years have witnessed the proliferation of fake news, propaganda, misinformation, and disinformation online. While initially this was mostly about textual content, over time images and videos gained popularity, as they are much easier to consume, attract much more attention, and spread further than simple text. As a result, researchers started targeting different modalities and combinations thereof. As different modalities are studied in different research communities, with insufficient interaction, here we offer a survey that explores the state-of-the-art on multimodal disinformation detection covering various combinations of modalities: text, images, audio, video, network structure, and temporal information. Moreover, while some studies focused on factuality, others investigated how harmful the content is. While these two components in the definition of disinformation -- (i) factuality and (ii) harmfulness, are equally important, they are typically studied in isolation. Thus, we argue for the need to tackle disinformation detection by taking into account multiple modalities as well as both factuality and harmfulness, in the same framework. Finally, we discuss current challenges and future research directions.
Hybrid Relay-Reflecting Intelligent Surface-Aided Wireless Communications: Opportunities, Challenges, and Future Perspectives
Apr 05, 2021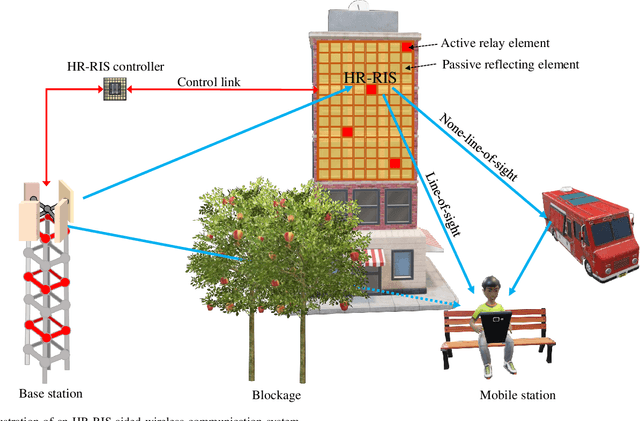
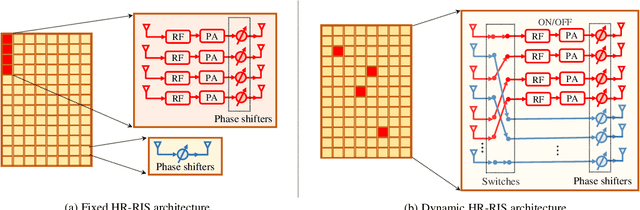
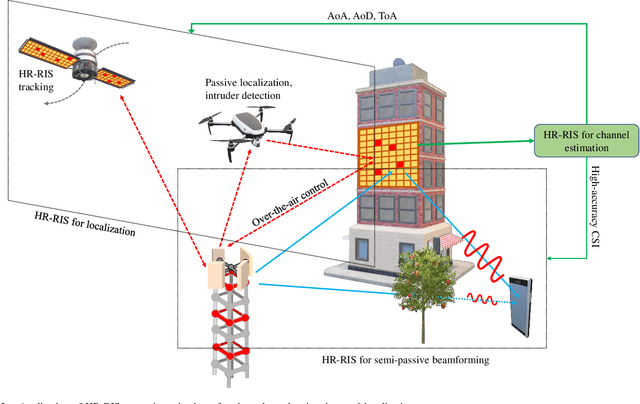
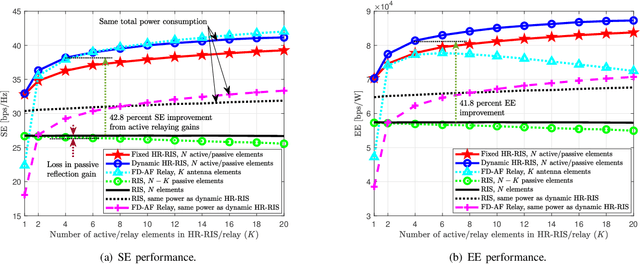
Reconfigurable intelligent surfaces (RISs) have emerged as a cost- and energy-efficient technology that can customize and program the physical propagation environment by reflecting radio waves in preferred directions. However, the purely passive reflection of RISs not only limits the end-to-end channel beamforming gains, but also hinders the acquisition of accurate channel state information for the phase control at RISs. In this paper, we provide an overview of a hybrid relay-reflecting intelligent surface (HR-RIS) architecture, in which only a few elements are active and connected to power amplifiers and radio frequency chains. The introduction of a small number of active elements enables a remarkable system performance improvement which can also compensate for losses due to hardware impairments such as the deployment of limited-resolution phase shifters. Particularly, the active processing facilitates efficient channel estimation and localization at HR-RISs. We present two practical architectures for HR-RISs, namely, fixed and dynamic HR-RISs, and discuss their applications to beamforming, channel estimation, and localization. The benefits, key challenges, and future research directions for HR-RIS-aided communications are also highlighted. Numerical results for an exemplary deployment scenario show that HR-RISs with only four active elements can attain up to 42.8 percent and 41.8 percent improvement in spectral efficiency and energy efficiency, respectively, compared with conventional RISs.
An End-to-end Model for Entity-level Relation Extraction using Multi-instance Learning
Feb 11, 2021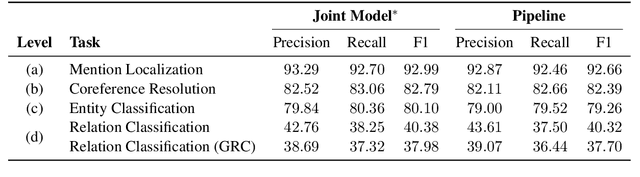
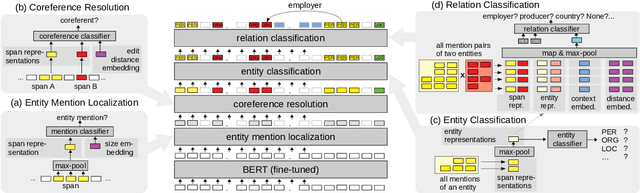
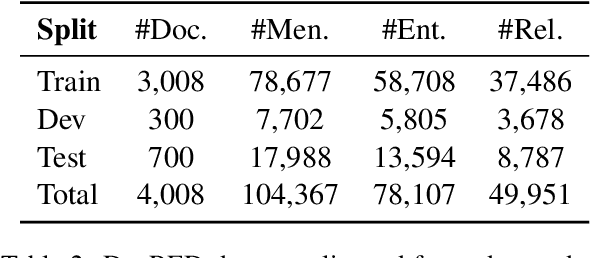
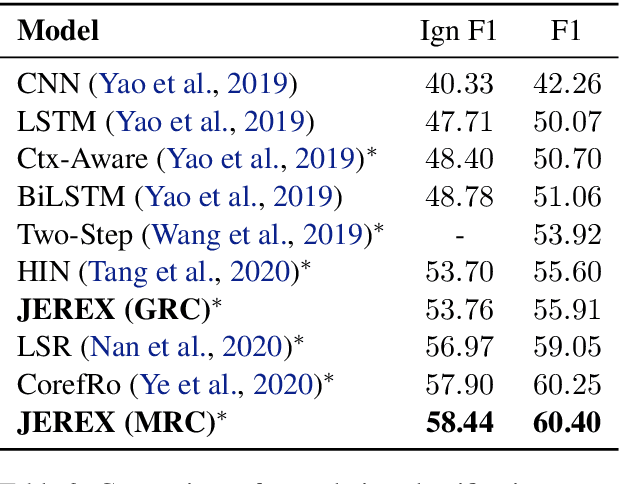
We present a joint model for entity-level relation extraction from documents. In contrast to other approaches - which focus on local intra-sentence mention pairs and thus require annotations on mention level - our model operates on entity level. To do so, a multi-task approach is followed that builds upon coreference resolution and gathers relevant signals via multi-instance learning with multi-level representations combining global entity and local mention information. We achieve state-of-the-art relation extraction results on the DocRED dataset and report the first entity-level end-to-end relation extraction results for future reference. Finally, our experimental results suggest that a joint approach is on par with task-specific learning, though more efficient due to shared parameters and training steps.
A Learnable Self-supervised Task for Unsupervised Domain Adaptation on Point Clouds
Apr 12, 2021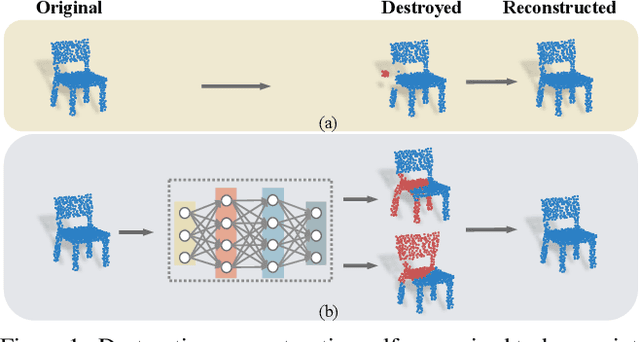
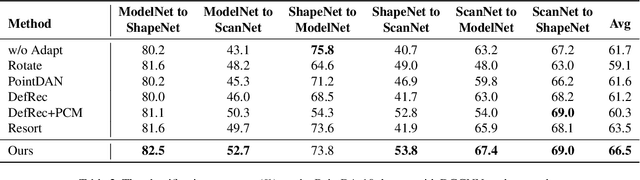
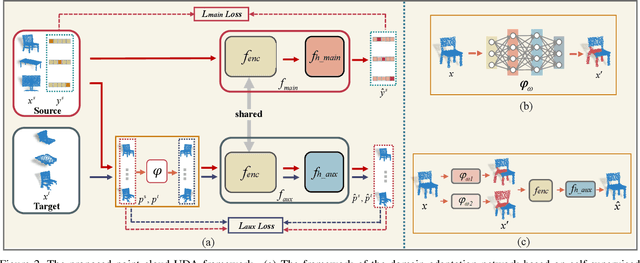
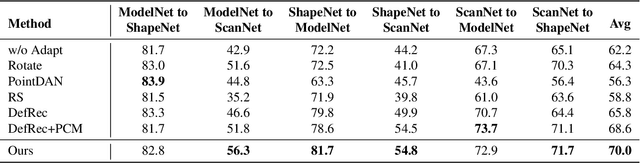
Deep neural networks have achieved promising performance in supervised point cloud applications, but manual annotation is extremely expensive and time-consuming in supervised learning schemes. Unsupervised domain adaptation (UDA) addresses this problem by training a model with only labeled data in the source domain but making the model generalize well in the target domain. Existing studies show that self-supervised learning using both source and target domain data can help improve the adaptability of trained models, but they all rely on hand-crafted designs of the self-supervised tasks. In this paper, we propose a learnable self-supervised task and integrate it into a self-supervision-based point cloud UDA architecture. Specifically, we propose a learnable nonlinear transformation that transforms a part of a point cloud to generate abundant and complicated point clouds while retaining the original semantic information, and the proposed self-supervised task is to reconstruct the original point cloud from the transformed ones. In the UDA architecture, an encoder is shared between the networks for the self-supervised task and the main task of point cloud classification or segmentation, so that the encoder can be trained to extract features suitable for both the source and the target domain data. Experiments on PointDA-10 and PointSegDA datasets show that the proposed method achieves new state-of-the-art performance on both classification and segmentation tasks of point cloud UDA. Code will be made publicly available.
Mutually exciting point process graphs for modelling dynamic networks
Feb 11, 2021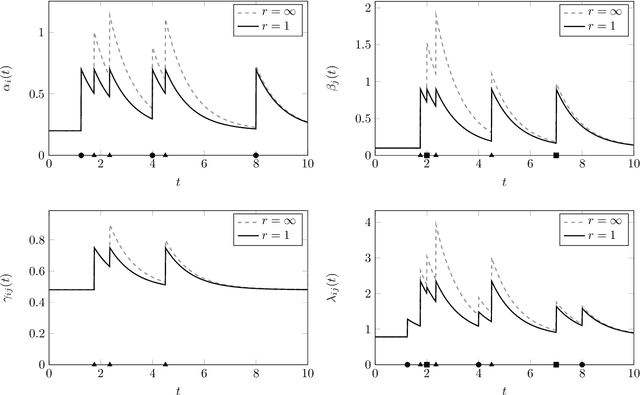
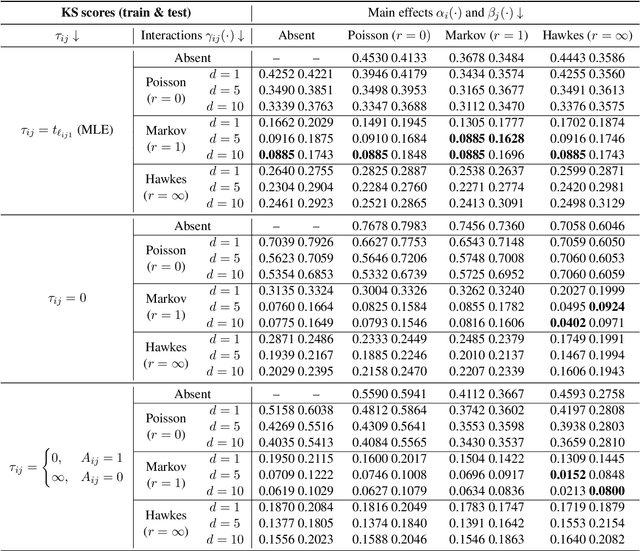
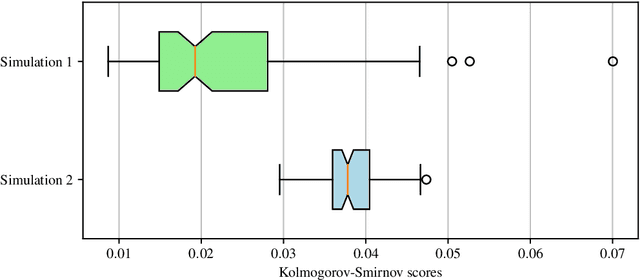
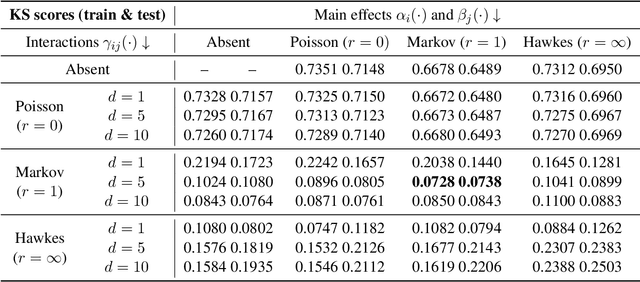
A new class of models for dynamic networks is proposed, called mutually exciting point process graphs (MEG), motivated by a practical application in computer network security. MEG is a scalable network-wide statistical model for point processes with dyadic marks, which can be used for anomaly detection when assessing the significance of previously unobserved connections. The model combines mutually exciting point processes to estimate dependencies between events and latent space models to infer relationships between the nodes. The intensity functions for each network edge are parameterised exclusively by node-specific parameters, which allows information to be shared across the network. Fast inferential procedures using modern gradient ascent algorithms are exploited. The model is tested on simulated graphs and real world computer network datasets, demonstrating excellent performance.
Information Pursuit: A Bayesian Framework for Sequential Scene Parsing
Jan 09, 2017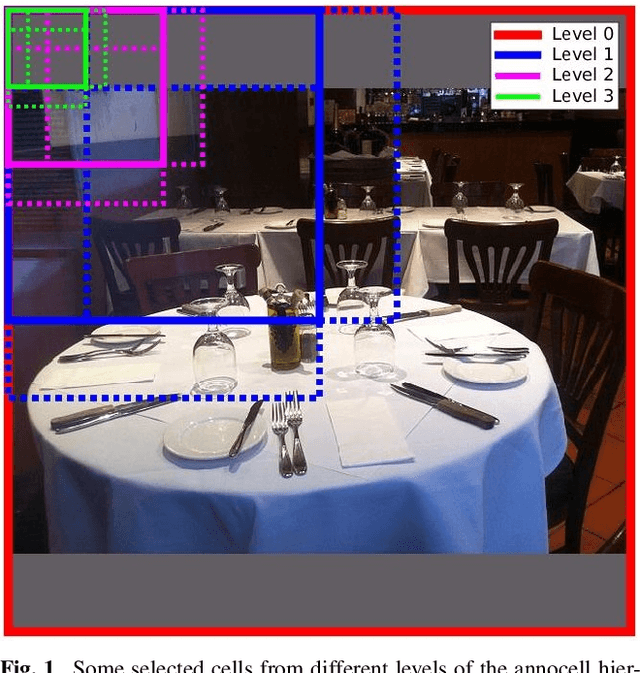
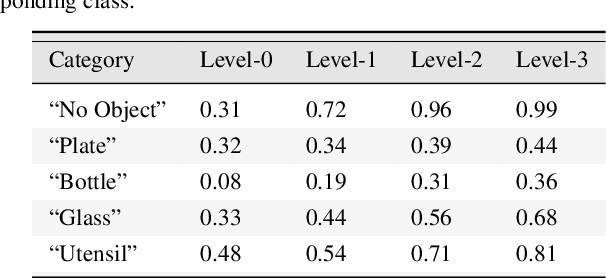

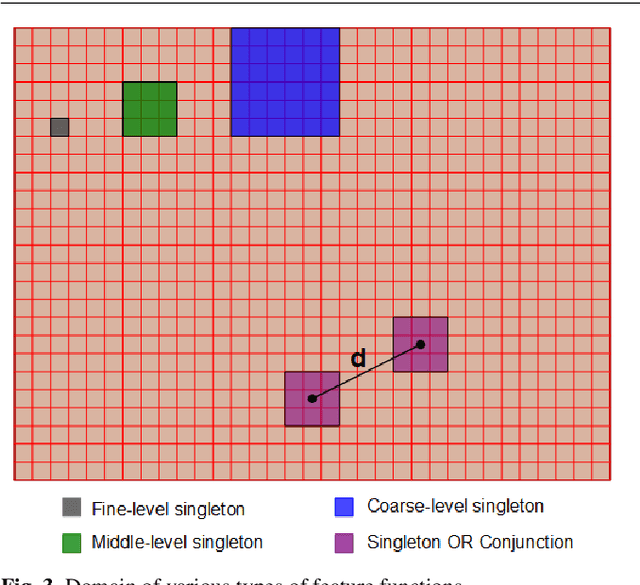
Despite enormous progress in object detection and classification, the problem of incorporating expected contextual relationships among object instances into modern recognition systems remains a key challenge. In this work we propose Information Pursuit, a Bayesian framework for scene parsing that combines prior models for the geometry of the scene and the spatial arrangement of objects instances with a data model for the output of high-level image classifiers trained to answer specific questions about the scene. In the proposed framework, the scene interpretation is progressively refined as evidence accumulates from the answers to a sequence of questions. At each step, we choose the question to maximize the mutual information between the new answer and the full interpretation given the current evidence obtained from previous inquiries. We also propose a method for learning the parameters of the model from synthesized, annotated scenes obtained by top-down sampling from an easy-to-learn generative scene model. Finally, we introduce a database of annotated indoor scenes of dining room tables, which we use to evaluate the proposed approach.
BayesPerf: Minimizing Performance Monitoring Errors Using Bayesian Statistics
Feb 22, 2021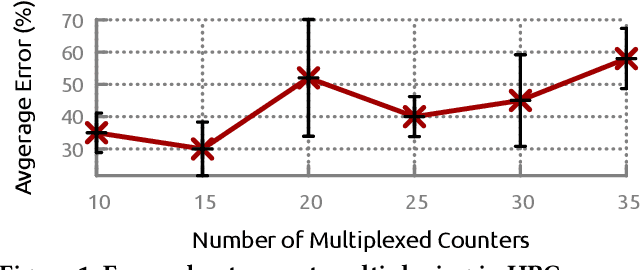
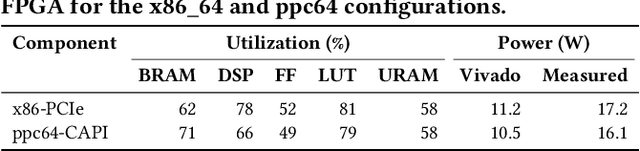
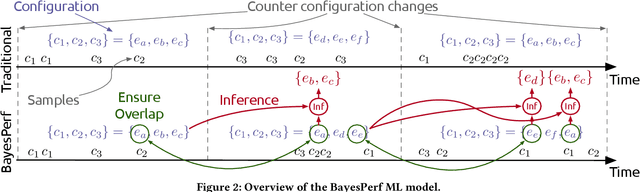
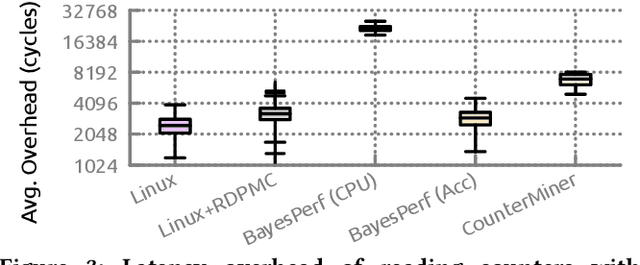
Hardware performance counters (HPCs) that measure low-level architectural and microarchitectural events provide dynamic contextual information about the state of the system. However, HPC measurements are error-prone due to non determinism (e.g., undercounting due to event multiplexing, or OS interrupt-handling behaviors). In this paper, we present BayesPerf, a system for quantifying uncertainty in HPC measurements by using a domain-driven Bayesian model that captures microarchitectural relationships between HPCs to jointly infer their values as probability distributions. We provide the design and implementation of an accelerator that allows for low-latency and low-power inference of the BayesPerf model for x86 and ppc64 CPUs. BayesPerf reduces the average error in HPC measurements from 40.1% to 7.6% when events are being multiplexed. The value of BayesPerf in real-time decision-making is illustrated with a simple example of scheduling of PCIe transfers.