 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OAG-BERT: Pre-train Heterogeneous Entity-augmented Academic Language Models
Mar 23, 2021
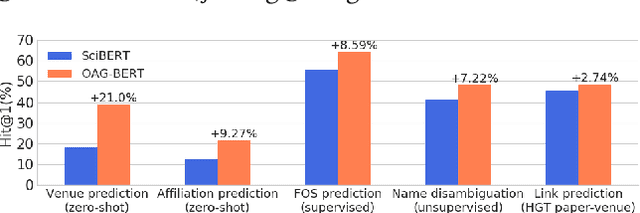
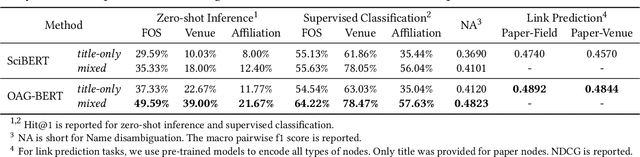
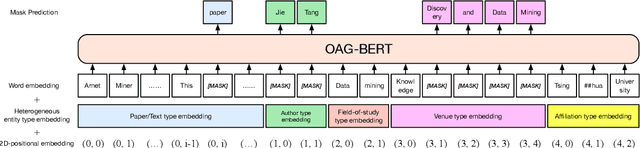
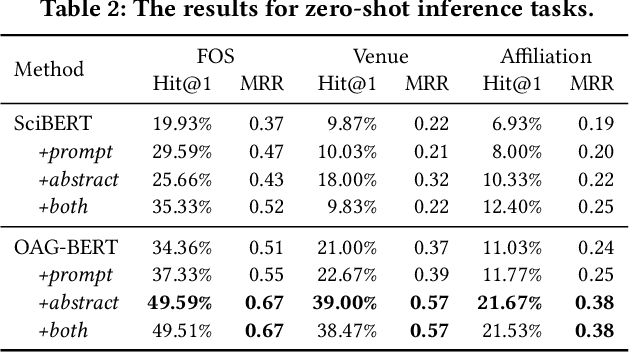
To enrich language models with domain knowledge is crucial but difficult. Based on the world's largest public academic graph Open Academic Graph (OAG), we pre-train an academic language model, namely OAG-BERT, which integrates massive heterogeneous entities including paper, author, concept, venue, and affiliation. To better endow OAG-BERT with the ability to capture entity information, we develop novel pre-training strategies including heterogeneous entity type embedding, entity-aware 2D positional encoding, and span-aware entity masking. For zero-shot inference, we design a special decoding strategy to allow OAG-BERT to generate entity names from scratch. We evaluate the OAG-BERT on various downstream academic tasks, including NLP benchmarks, zero-shot entity inference, heterogeneous graph link prediction, and author name disambiguation. Results demonstrate the effectiveness of the proposed pre-training approach to both comprehending academic texts and modeling knowledge from heterogeneous entities. OAG-BERT has been deployed to multiple real-world applications, such as reviewer recommendations and paper tagging in the AMiner system. It is also available to the public through the CogDL package.
Persian Ezafe Recognition Using Transformers and Its Role in Part-Of-Speech Tagging
Oct 04, 2020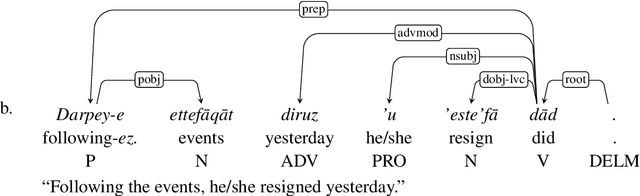
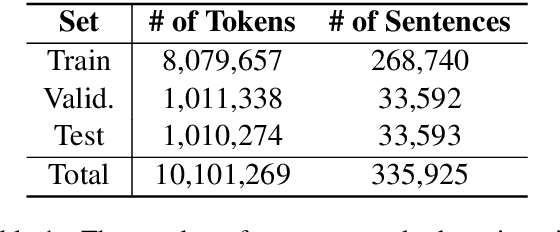
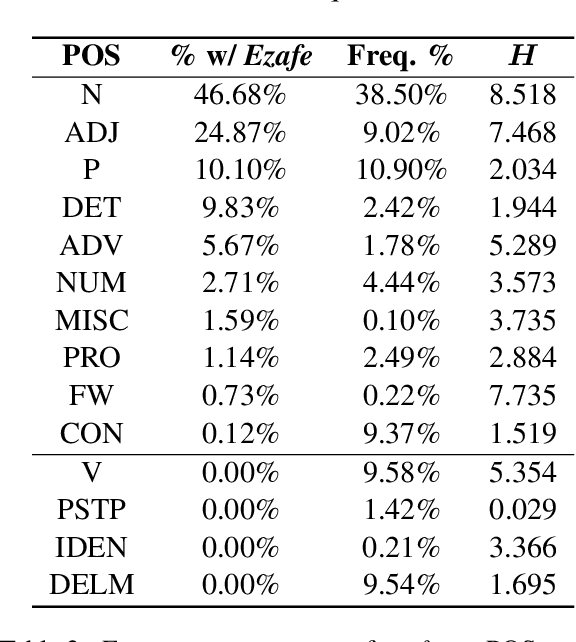
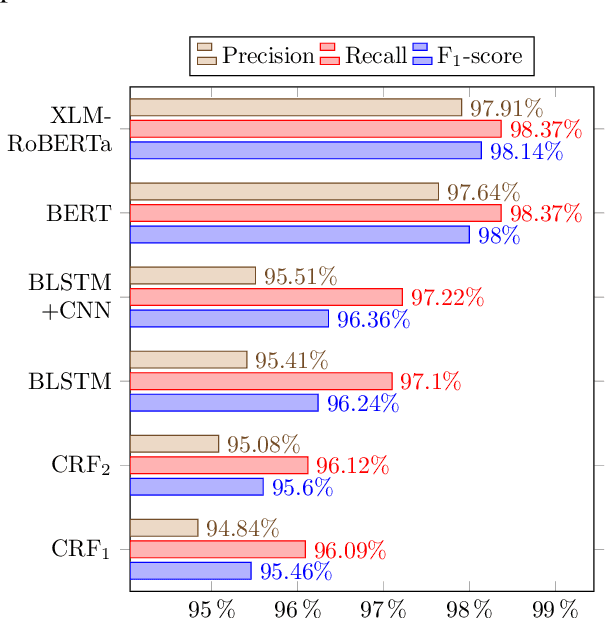
Ezafe is a grammatical particle in some Iranian languages that links two words together. Regardless of the important information it conveys, it is almost always not indicated in Persian script, resulting in mistakes in reading complex sentences and errors in natural language processing tasks. In this paper, we experiment with different machine learning methods to achieve state-of-the-art results in the task of ezafe recognition. Transformer-based methods, BERT and XLMRoBERTa, achieve the best results, the latter achieving 2.68% F1-score more than the previous state-of-the-art. We, moreover, use ezafe information to improve Persian part-of-speech tagging results and show that such information will not be useful to transformer-based methods and explain why that might be the case.
Topological Data Analysis of copy number alterations in cancer
Nov 22, 2020
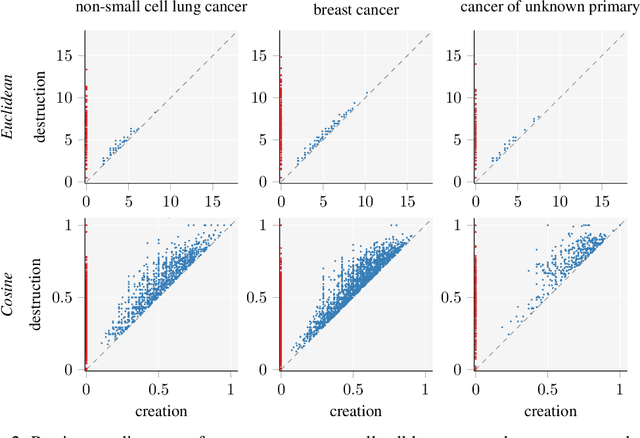
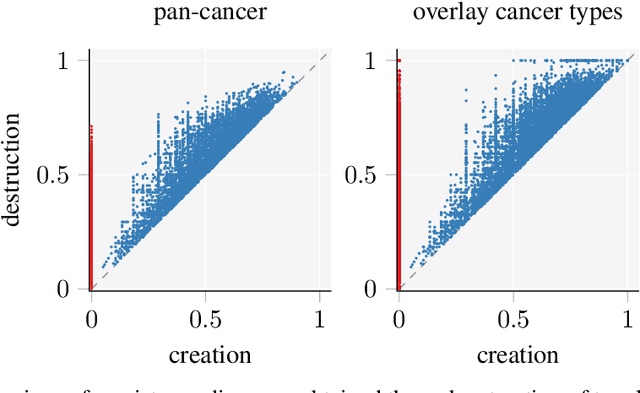
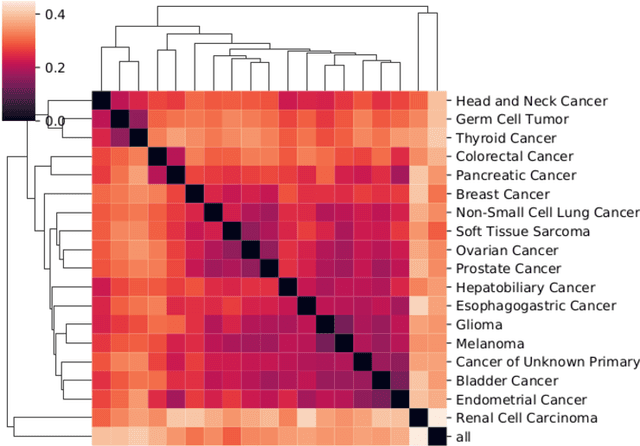
Identifying subgroups and properties of cancer biopsy samples is a crucial step towards obtaining precise diagnoses and being able to perform personalized treatment of cancer patients. Recent data collections provide a comprehensive characterization of cancer cell data, including genetic data on copy number alterations (CNAs). We explore the potential to capture information contained in cancer genomic information using a novel topology-based approach that encodes each cancer sample as a persistence diagram of topological features, i.e., high-dimensional voids represented in the data. We find that this technique has the potential to extract meaningful low-dimensional representations in cancer somatic genetic data and demonstrate the viability of some applications on finding substructures in cancer data as well as comparing similarity of cancer types.
MOAI: A methodology for evaluating the impact of indoor airflow in the transmission of COVID-19
Mar 31, 2021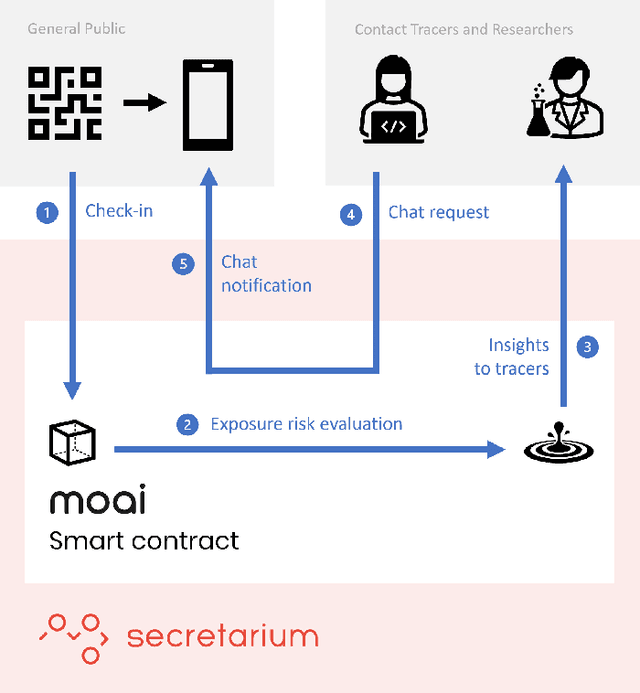
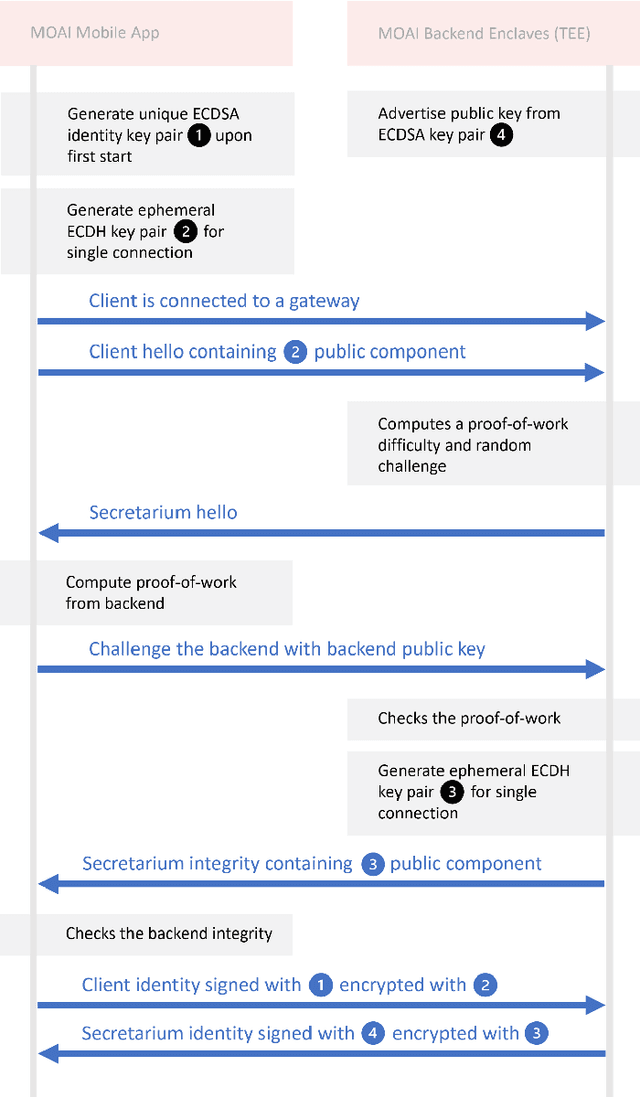
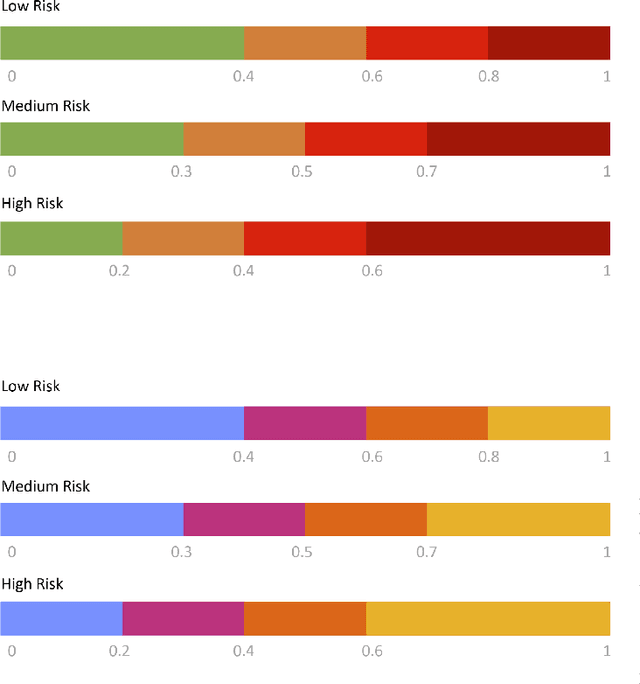
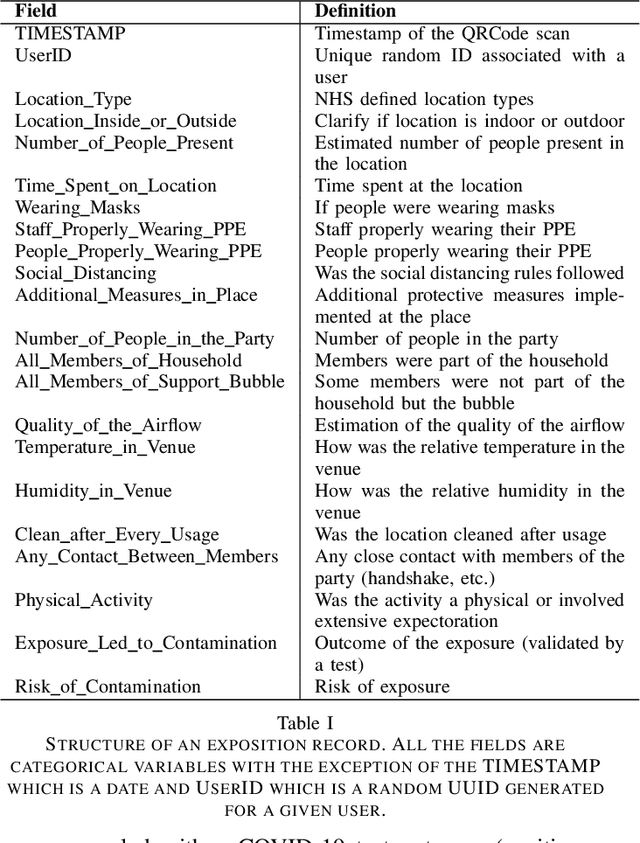
Epidemiology models play a key role in understanding and responding to the COVID-19 pandemic. In order to build those models, scientists need to understand contributing factors and their relative importance. A large strand of literature has identified the importance of airflow to mitigate droplets and far-field aerosol transmission risks. However, the specific factors contributing to higher or lower contamination in various settings have not been clearly defined and quantified. As part of the MOAI project (https://moaiapp.com), we are developing a privacy-preserving test and trace app to enable infection cluster investigators to get in touch with patients without having to know their identity. This approach allows involving users in the fight against the pandemic by contributing additional information in the form of anonymous research questionnaires. We first describe how the questionnaire was designed, and the synthetic data was generated based on a review we carried out on the latest available literature. We then present a model to evaluate the risk exposition of a user for a given setting. We finally propose a temporal addition to the model to evaluate the risk exposure over time for a given user.
Enhanced Spatio-Temporal Interaction Learning for Video Deraining: A Faster and Better Framework
Mar 23, 2021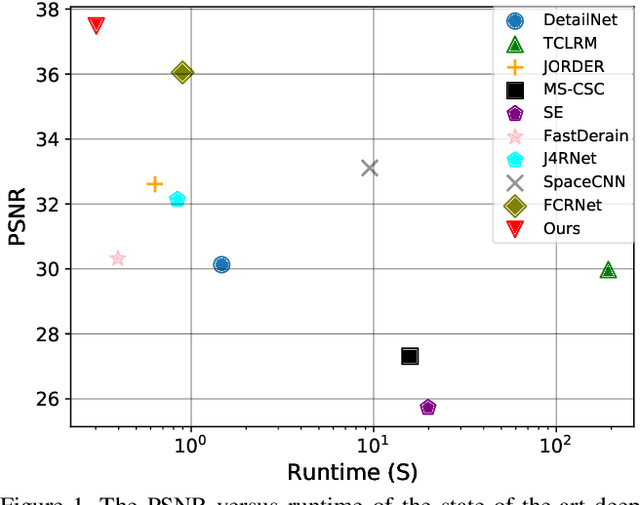
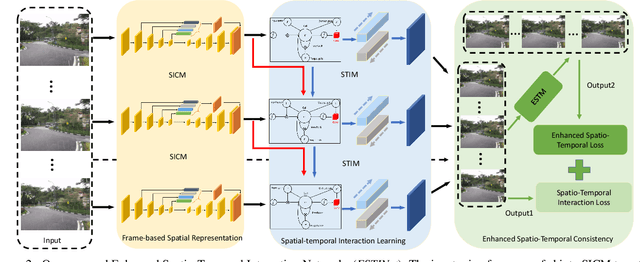
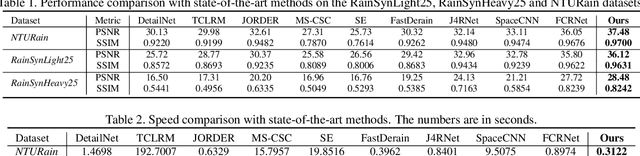
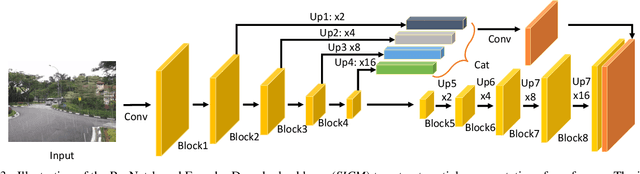
Video deraining is an important task in computer vision as the unwanted rain hampers the visibility of videos and deteriorates the robustness of most outdoor vision systems. Despite the significant success which has been achieved for video deraining recently, two major challenges remain: 1) how to exploit the vast information among continuous frames to extract powerful spatio-temporal features across both the spatial and temporal domains, and 2) how to restore high-quality derained videos with a high-speed approach. In this paper, we present a new end-to-end video deraining framework, named Enhanced Spatio-Temporal Interaction Network (ESTINet), which considerably boosts current state-of-the-art video deraining quality and speed. The ESTINet takes the advantage of deep residual networks and convolutional long short-term memory, which can capture the spatial features and temporal correlations among continuing frames at the cost of very little computational source. Extensive experiments on three public datasets show that the proposed ESTINet can achieve faster speed than the competitors, while maintaining better performance than the state-of-the-art methods.
Extending Isolation Forest for Anomaly Detection in Big Data via K-Means
Apr 27, 2021

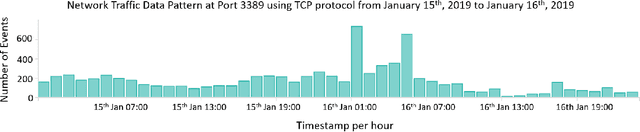

Industrial Information Technology (IT) infrastructures are often vulnerable to cyberattacks. To ensure security to the computer systems in an industrial environment, it is required to build effective intrusion detection systems to monitor the cyber-physical systems (e.g., computer networks) in the industry for malicious activities. This paper aims to build such intrusion detection systems to protect the computer networks from cyberattacks. More specifically, we propose a novel unsupervised machine learning approach that combines the K-Means algorithm with the Isolation Forest for anomaly detection in industrial big data scenarios. Since our objective is to build the intrusion detection system for the big data scenario in the industrial domain, we utilize the Apache Spark framework to implement our proposed model which was trained in large network traffic data (about 123 million instances of network traffic) stored in Elasticsearch. Moreover, we evaluate our proposed model on the live streaming data and find that our proposed system can be used for real-time anomaly detection in the industrial setup. In addition, we address different challenges that we face while training our model on large datasets and explicitly describe how these issues were resolved. Based on our empirical evaluation in different use-cases for anomaly detection in real-world network traffic data, we observe that our proposed system is effective to detect anomalies in big data scenarios. Finally, we evaluate our proposed model on several academic datasets to compare with other models and find that it provides comparable performance with other state-of-the-art approaches.
Meta Graph Attention on Heterogeneous Graph with Node-Edge Co-evolution
Oct 09, 2020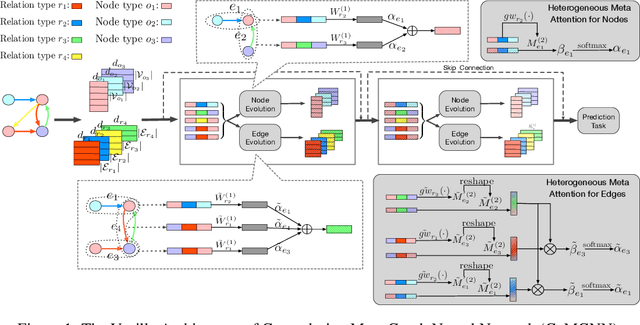
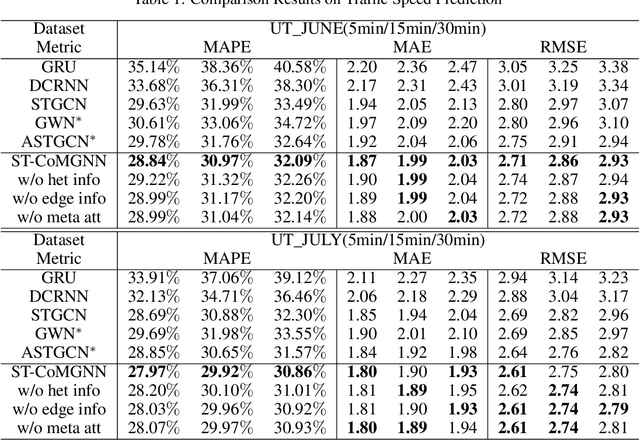
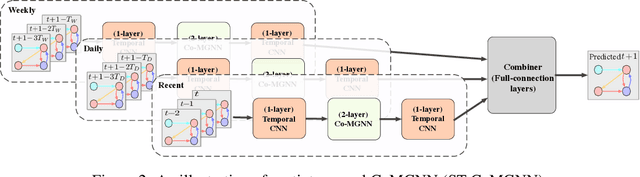
Graph neural networks have become an important tool for modeling structured data. In many real-world systems, intricate hidden information may exist, e.g., heterogeneity in nodes/edges, static node/edge attributes, and spatiotemporal node/edge features. However, most existing methods only take part of the information into consideration. In this paper, we present the Co-evolved Meta Graph Neural Network (CoMGNN), which applies meta graph attention to heterogeneous graphs with co-evolution of node and edge states. We further propose a spatiotemporal adaption of CoMGNN (ST-CoMGNN) for modeling spatiotemporal patterns on nodes and edges. We conduct experiments on two large-scale real-world datasets. Experimental results show that our models significantly outperform the state-of-the-art methods, demonstrating the effectiveness of encoding diverse information from different aspects.
Location-aware Single Image Reflection Removal
Dec 13, 2020
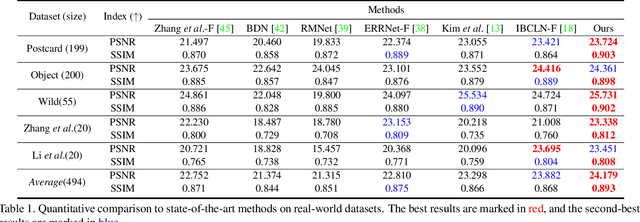
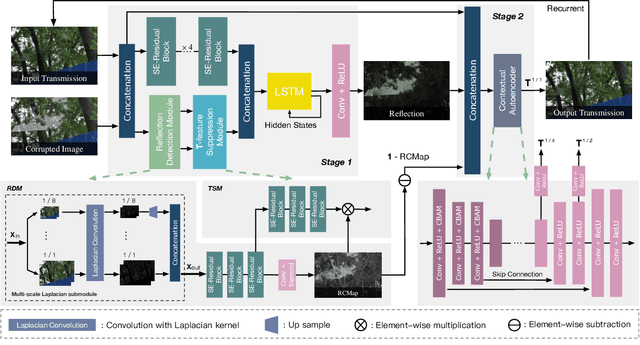
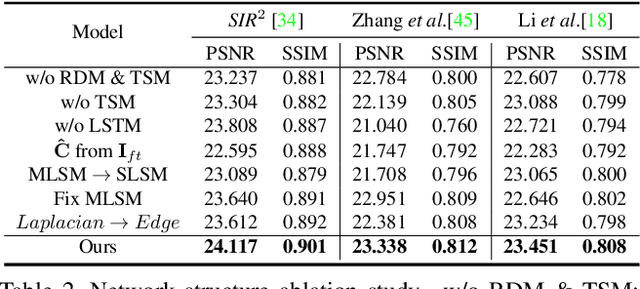
This paper proposes a novel location-aware deep learning-based single image reflection removal method. Our network has a reflection detection module to regress a probabilistic reflection confidence map, taking multi-scale Laplacian features as inputs. This probabilistic map tells whether a region is reflection-dominated or transmission-dominated. The novelty is that we use the reflection confidence map as the cues for the network to learn how to encode the reflection information adaptively and control the feature flow when predicting reflection and transmission layers. The integration of location information into the network significantly improves the quality of reflection removal results. Besides, a set of learnable Laplacian kernel parameters is introduced to facilitate the extraction of discriminative Laplacian features for reflection detection. We design our network as a recurrent network to progressively refine each iteration's reflection removal results. Extensive experiments verify the superior performance of the proposed method over state-of-the-art approaches.
Learning Graph Structures with Transformer for Multivariate Time Series Anomaly Detection in IoT
Apr 08, 2021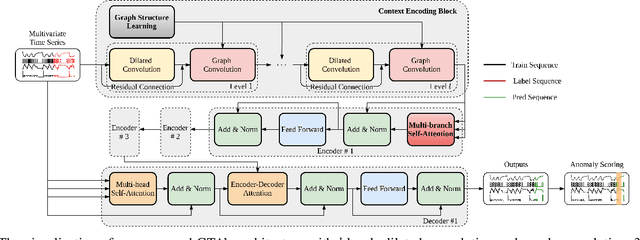
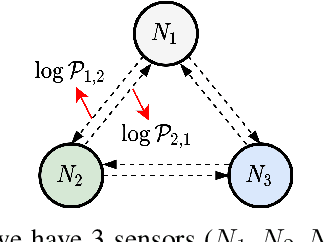
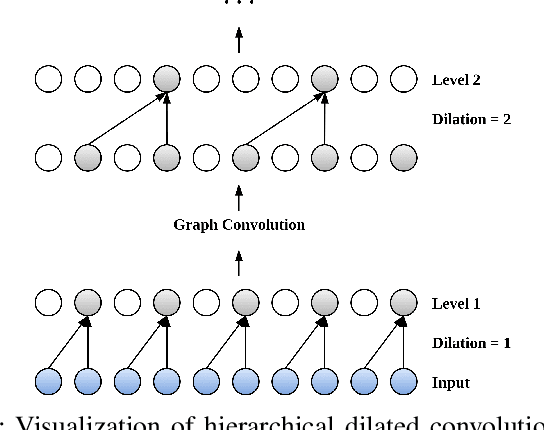
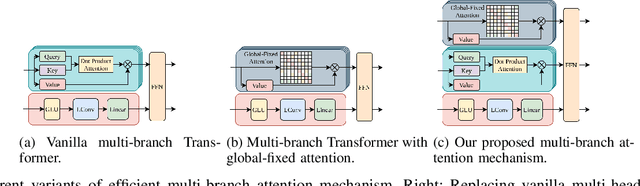
Many real-world IoT systems comprising various internet-connected sensory devices generate substantial amounts of multivariate time series data. Meanwhile, those critical IoT infrastructures, such as smart power grids and water distribution networks, are often targets of cyber-attacks, making anomaly detection of high research value. However, considering the complex topological and nonlinear dependencies that are initially unknown among sensors, modeling such relatedness is inevitable for any efficient and accurate anomaly detection system. Additionally, due to multivariate time series' temporal dependency and stochasticity, their anomaly detection remains a big challenge. This work proposed a novel framework, namely GTA, for multivariate time series anomaly detection by automatically learning a graph structure followed by the graph convolution and modeling the temporal dependency through a Transformer-based architecture. The core idea of learning graph structure is called the connection learning policy based on the Gumbel-softmax sampling strategy to learn bi-directed associations among sensors directly. We also devised a novel graph convolution named Influence Propagation convolution to model the anomaly information flow between graph nodes. Moreover, we proposed a multi-branch attention mechanism to substitute for original multi-head self-attention to overcome the quadratic complexity challenge. The extensive experiments on four public anomaly detection benchmarks further demonstrate our approach's superiority over other state-of-the-arts.
The NPU System for the 2020 Personalized Voice Trigger Challenge
Feb 26, 2021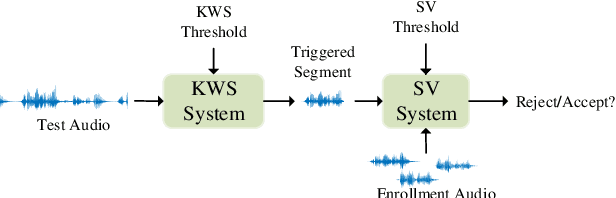
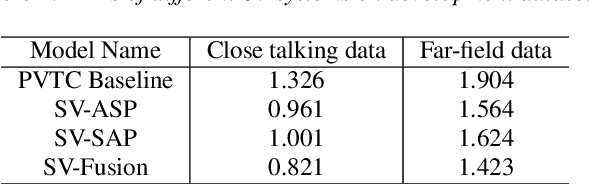
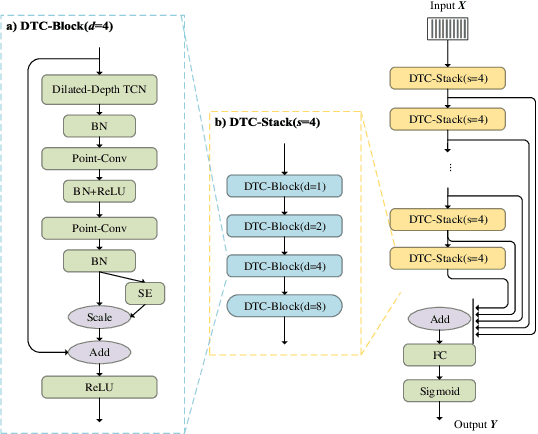

This paper describes the system developed by the NPU team for the 2020 personalized voice trigger challenge. Our submitted system consists of two independently trained subsystems: a small footprint keyword spotting (KWS) system and a speaker verification (SV) system. For the KWS system, a multi-scale dilated temporal convolutional (MDTC) network is proposed to detect wake-up word (WuW). For SV system, Write something here. The KWS predicts posterior probabilities of whether an audio utterance contains WuW and estimates the location of WuW at the same time. When the posterior probability ofWuW reaches a predefined threshold, the identity information of triggered segment is determined by the SV system. On evaluation dataset, our submitted system obtains detection costs of 0.081and 0.091 in close talking and far-field tasks, respectively.