 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Quadruple Augmented Pyramid Network for Multi-class COVID-19 Segmentation via CT
Mar 09, 2021
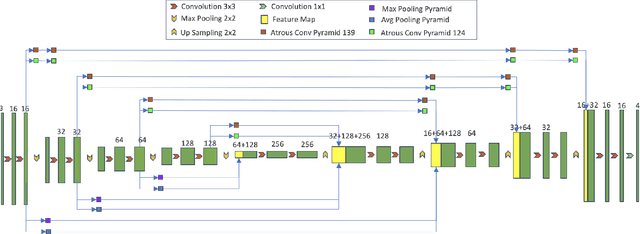
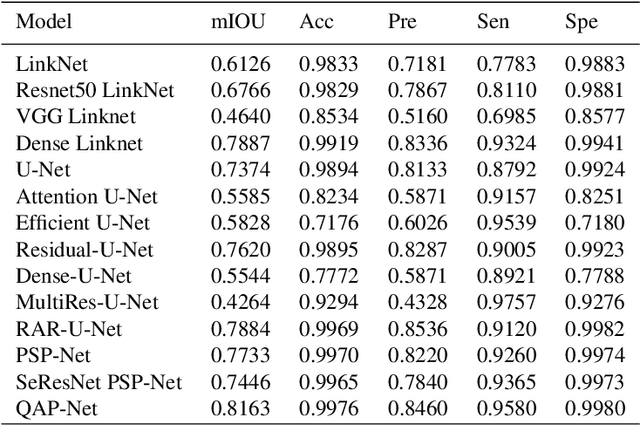
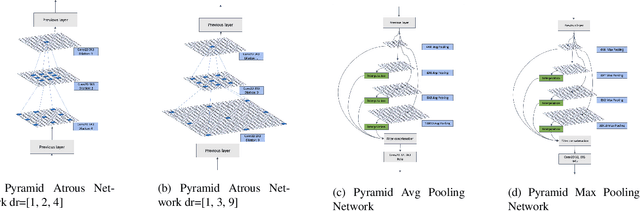
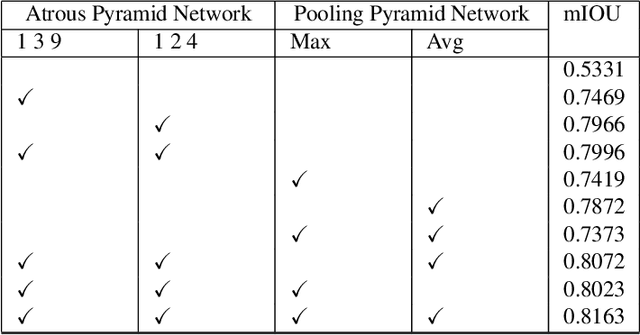
COVID-19, a new strain of coronavirus disease, has been one of the most serious and infectious disease in the world. Chest CT is essential in prognostication, diagnosing this disease, and assessing the complication. In this paper, a multi-class COVID-19 CT segmentation is proposed aiming at helping radiologists estimate the extent of effected lung volume. We utilized four augmented pyramid networks on an encoder-decoder segmentation framework. Quadruple Augmented Pyramid Network (QAP-Net) not only enable CNN capture features from variation size of CT images, but also act as spatial interconnections and down-sampling to transfer sufficient feature information for semantic segmentation. Experimental results achieve competitive performance in segmentation with the Dice of 0.8163, which outperforms other state-of-the-art methods, demonstrating the proposed framework can segments of consolidation as well as glass, ground area via COVID-19 chest CT efficiently and accurately.
Fundamental Limits on the Maximum Deviations in Control Systems: How Short Can Distribution Tails be Made by Feedback?
Feb 02, 2021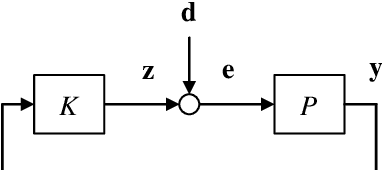
This paper is on the application of information theory to the analysis of fundamental lower bounds on the maximum deviations in feedback control systems, where the plant is linear time-invariant while the controller can generically be any causal functions as long as it stabilizes the plant. It is seen in general that the lower bounds are characterized by the unstable poles (or nonminimum-phase zeros) of the plant as well as the conditional entropy of the disturbance. Such bounds provide fundamental limits on how short the distribution tails in control systems can be made by feedback.
GA-SVM for Evaluating Heroin Consumption Risk
Mar 23, 2021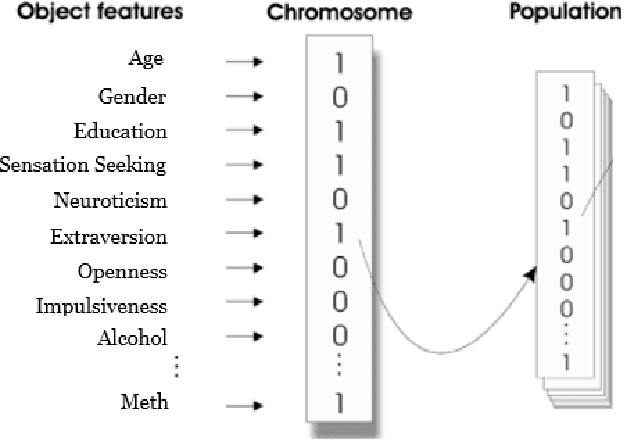
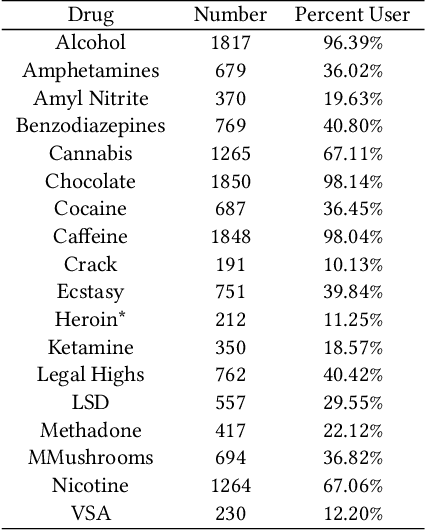
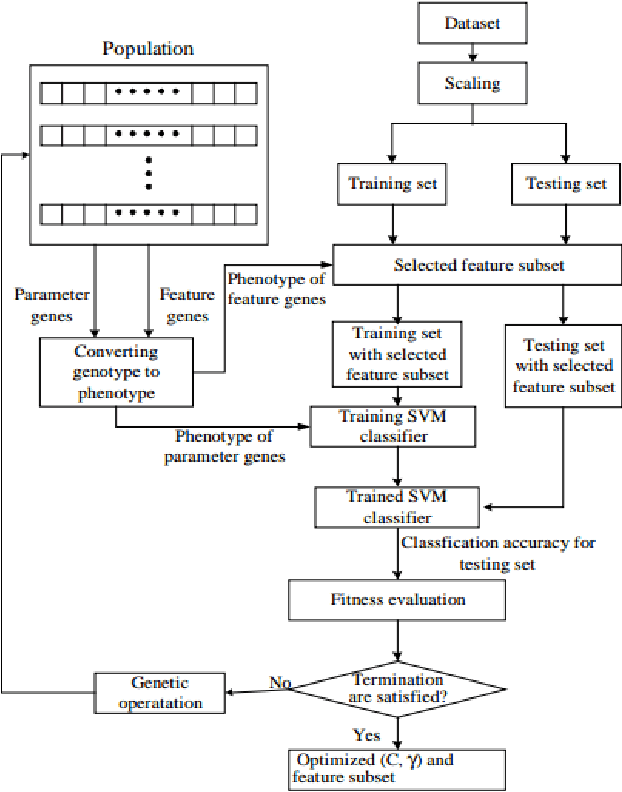
There were over 70,000 drug overdose deaths in the USA in 2017. Almost half of those involved the use of Opioids such as Heroin. This research supports efforts to combat the Opioid Epidemic by further understanding factors that lead to Heroin consumption. Previous research has debated the cause of Heroin addiction, with some explaining the phenomenon as a transition from prescription Opioids, and others pointing to various psycho-social factors. This research used self-reported information about personality, demographics and drug consumption behavior to predict Heroin consumption. By applying a Support Vector Machine algorithm optimized with a Genetic Algorithm (GA-SVM Hybrid) to simultaneously identify predictive features and model parameters, this research produced several models that were more accurate in predicting Heroin use than those produced in previous studies. Although all factors had predictive power, these results showed that consumption of other drugs (both prescription and illicit) were stronger predictors of Heroin use than psycho-social factors. The use of prescription drugs as a strong predictor of Heroin use is an important though disturbing discovery but that can help combat Heroin use.
Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling
Dec 14, 2020
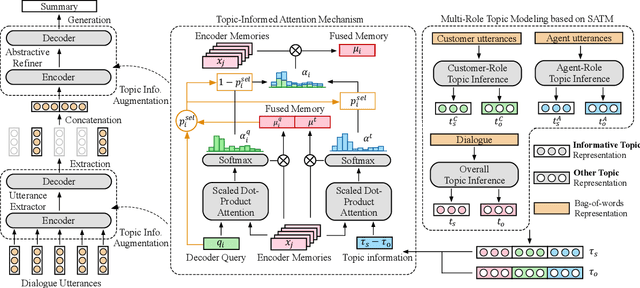
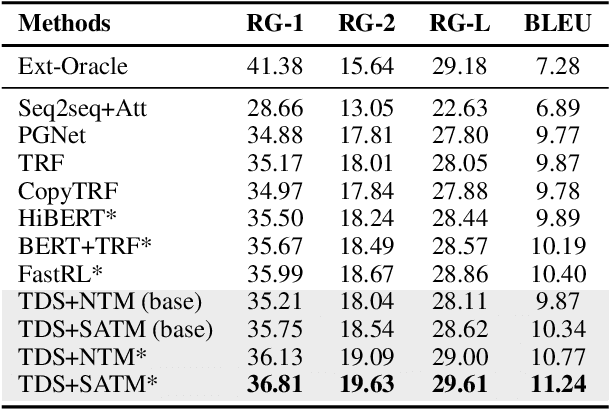
In a customer service system, dialogue summarization can boost service efficiency by automatically creating summaries for long spoken dialogues in which customers and agents try to address issues about specific topics. In this work, we focus on topic-oriented dialogue summarization, which generates highly abstractive summaries that preserve the main ideas from dialogues. In spoken dialogues, abundant dialogue noise and common semantics could obscure the underlying informative content, making the general topic modeling approaches difficult to apply. In addition, for customer service, role-specific information matters and is an indispensable part of a summary. To effectively perform topic modeling on dialogues and capture multi-role information, in this work we propose a novel topic-augmented two-stage dialogue summarizer (TDS) jointly with a saliency-aware neural topic model (SATM) for topic-oriented summarization of customer service dialogues. Comprehensive studies on a real-world Chinese customer service dataset demonstrated the superiority of our method against several strong baselines.
Characterizing Trust and Resilience in Distributed Consensus for Cyberphysical Systems
Mar 09, 2021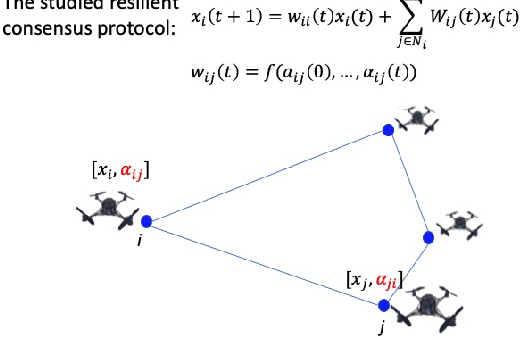
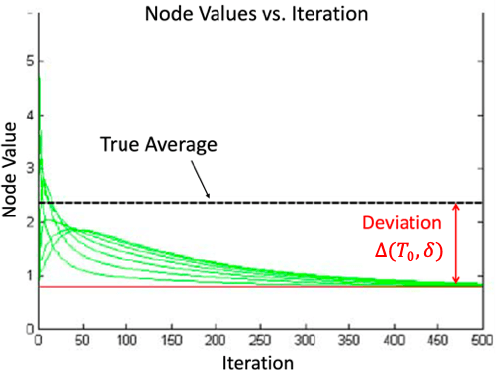
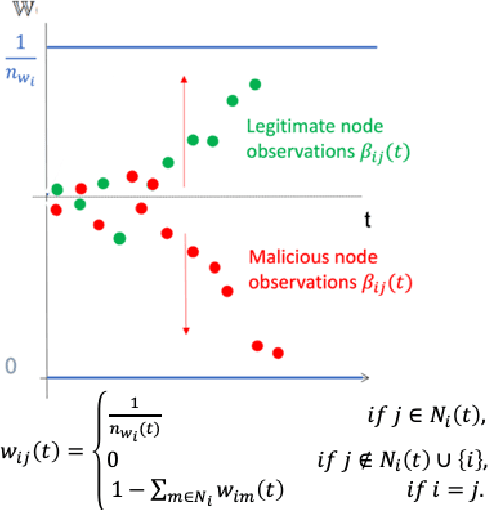
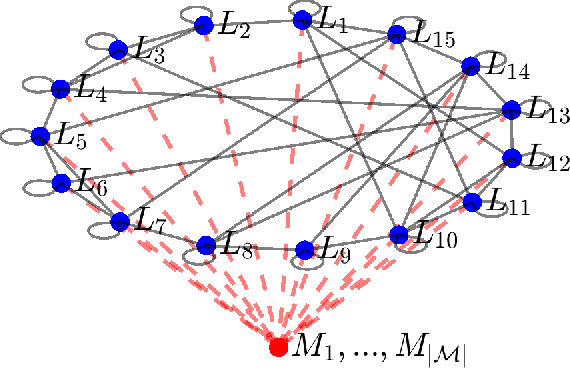
This work considers the problem of resilient consensus where stochastic values of trust between agents are available. Specifically, we derive a unified mathematical framework to characterize convergence, deviation of the consensus from the true consensus value, and expected convergence rate, when there exists additional information of trust between agents. We show that under certain conditions on the stochastic trust values and consensus protocol: 1) almost sure convergence to a common limit value is possible even when malicious agents constitute more than half of the network connectivity, 2) the deviation of the converged limit, from the case where there is no attack, i.e., the true consensus value, can be bounded with probability that approaches 1 exponentially, and 3) correct classification of malicious and legitimate agents can be attained in finite time almost surely. Further, the expected convergence rate decays exponentially with the quality of the trust observations between agents.
The emergence of visual semantics through communication games
Jan 25, 2021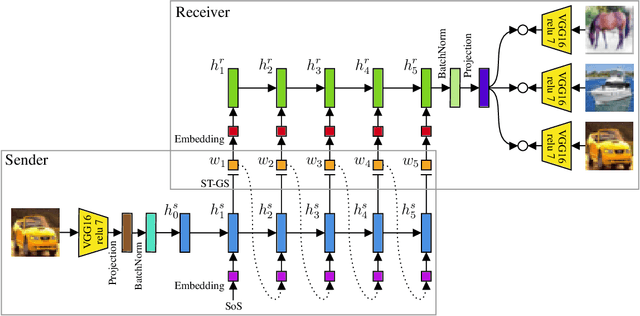

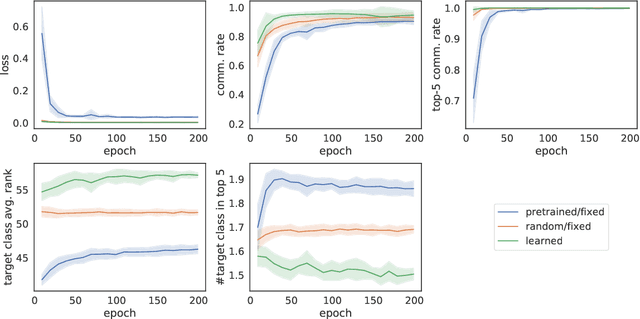
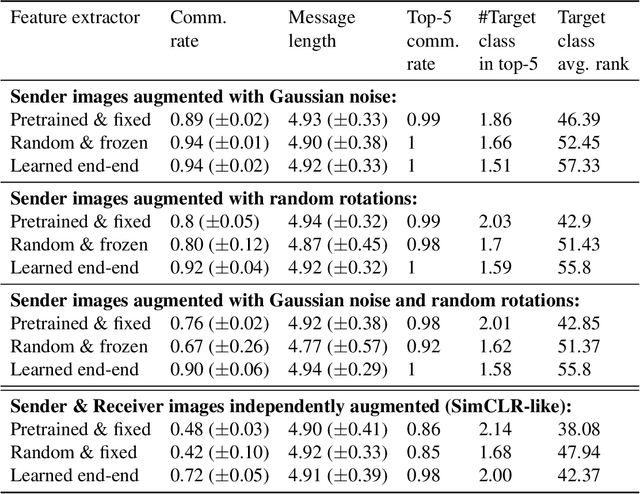
The emergence of communication systems between agents which learn to play referential signalling games with realistic images has attracted a lot of attention recently. The majority of work has focused on using fixed, pretrained image feature extraction networks which potentially bias the information the agents learn to communicate. In this work, we consider a signalling game setting in which a `sender' agent must communicate the information about an image to a `receiver' who must select the correct image from many distractors. We investigate the effect of the feature extractor's weights and of the task being solved on the visual semantics learned by the models. We first demonstrate to what extent the use of pretrained feature extraction networks inductively bias the visual semantics conveyed by emergent communication channel and quantify the visual semantics that are induced. We then go on to explore ways in which inductive biases can be introduced to encourage the emergence of semantically meaningful communication without the need for any form of supervised pretraining of the visual feature extractor. We impose various augmentations to the input images and additional tasks in the game with the aim to induce visual representations which capture conceptual properties of images. Through our experiments, we demonstrate that communication systems which capture visual semantics can be learned in a completely self-supervised manner by playing the right types of game. Our work bridges a gap between emergent communication research and self-supervised feature learning.
Lightweight Convolutional Neural Network with Gaussian-based Grasping Representation for Robotic Grasping Detection
Jan 25, 2021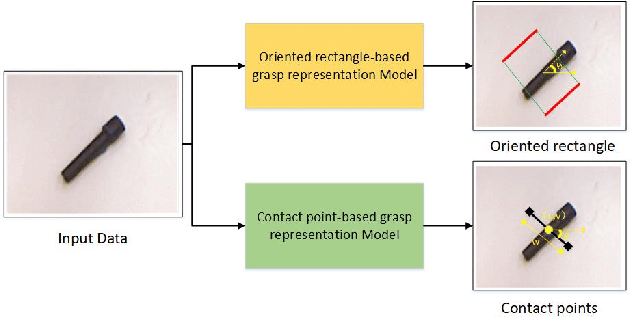
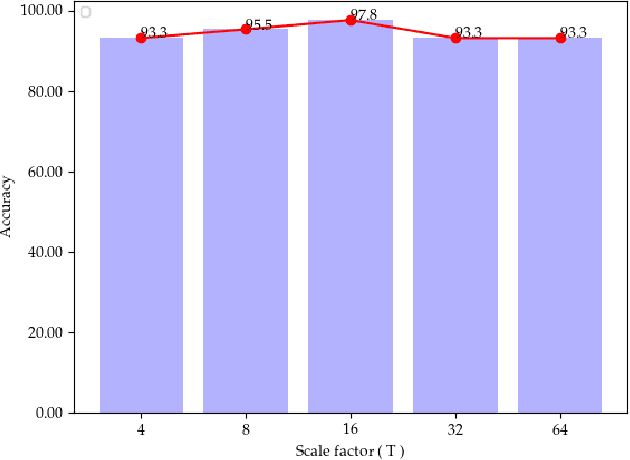


The method of deep learning has achieved excellent results in improving the performance of robotic grasping detection. However, the deep learning methods used in general object detection are not suitable for robotic grasping detection. Current modern object detectors are difficult to strike a balance between high accuracy and fast inference speed. In this paper, we present an efficient and robust fully convolutional neural network model to perform robotic grasping pose estimation from an n-channel input image of the real grasping scene. The proposed network is a lightweight generative architecture for grasping detection in one stage. Specifically, a grasping representation based on Gaussian kernel is introduced to encode training samples, which embodies the principle of maximum central point grasping confidence. Meanwhile, to extract multi-scale information and enhance the feature discriminability, a receptive field block (RFB) is assembled to the bottleneck of our grasping detection architecture. Besides, pixel attention and channel attention are combined to automatically learn to focus on fusing context information of varying shapes and sizes by suppressing the noise feature and highlighting the grasping object feature. Extensive experiments on two public grasping datasets, Cornell and Jacquard demonstrate the state-of-the-art performance of our method in balancing accuracy and inference speed. The network is an order of magnitude smaller than other excellent algorithms while achieving better performance with an accuracy of 98.9$\%$ and 95.6$\%$ on the Cornell and Jacquard datasets, respectively.
Inferring spatial relations from textual descriptions of images
Feb 01, 2021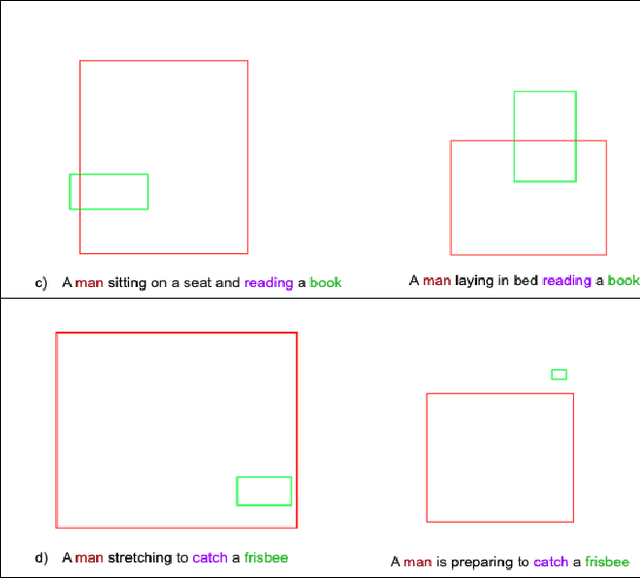



Generating an image from its textual description requires both a certain level of language understanding and common sense knowledge about the spatial relations of the physical entities being described. In this work, we focus on inferring the spatial relation between entities, a key step in the process of composing scenes based on text. More specifically, given a caption containing a mention to a subject and the location and size of the bounding box of that subject, our goal is to predict the location and size of an object mentioned in the caption. Previous work did not use the caption text information, but a manually provided relation holding between the subject and the object. In fact, the used evaluation datasets contain manually annotated ontological triplets but no captions, making the exercise unrealistic: a manual step was required; and systems did not leverage the richer information in captions. Here we present a system that uses the full caption, and Relations in Captions (REC-COCO), a dataset derived from MS-COCO which allows to evaluate spatial relation inference from captions directly. Our experiments show that: (1) it is possible to infer the size and location of an object with respect to a given subject directly from the caption; (2) the use of full text allows to place the object better than using a manually annotated relation. Our work paves the way for systems that, given a caption, decide which entities need to be depicted and their respective location and sizes, in order to then generate the final image.
Health Status Prediction with Local-Global Heterogeneous Behavior Graph
Mar 23, 2021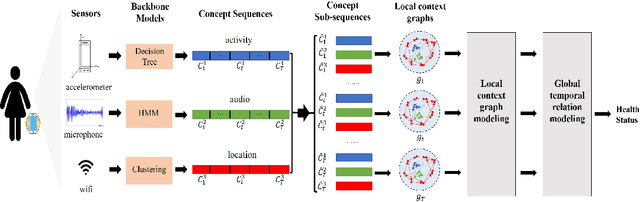

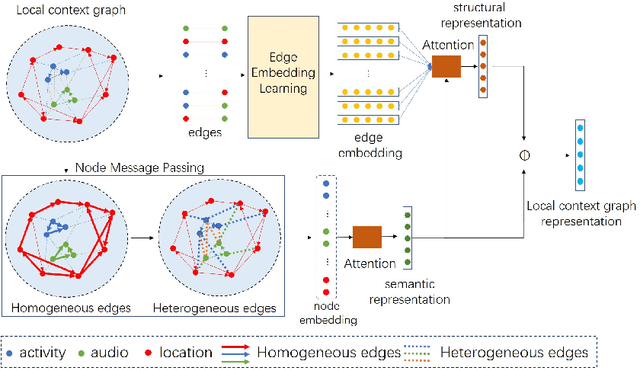
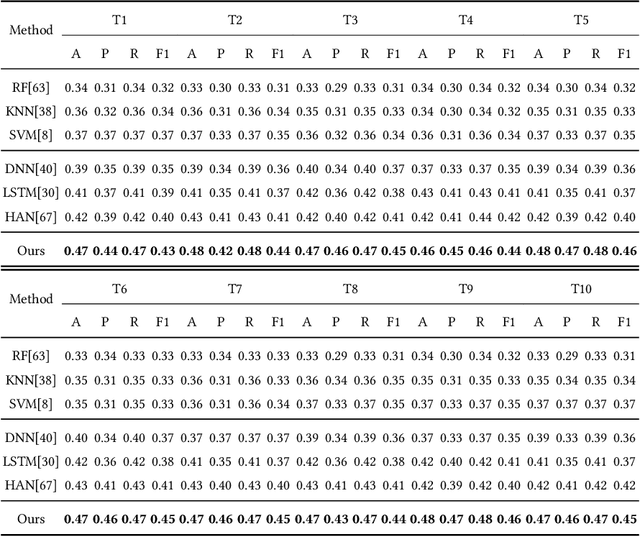
Health management is getting increasing attention all over the world. However, existing health management mainly relies on hospital examination and treatment, which are complicated and untimely. The emerging of mobile devices provides the possibility to manage people's health status in a convenient and instant way. Estimation of health status can be achieved with various kinds of data streams continuously collected from wearable sensors. However, these data streams are multi-source and heterogeneous, containing complex temporal structures with local contextual and global temporal aspects, which makes the feature learning and data joint utilization challenging. We propose to model the behavior-related multi-source data streams with a local-global graph, which contains multiple local context sub-graphs to learn short term local context information with heterogeneous graph neural networks and a global temporal sub-graph to learn long term dependency with self-attention networks. Then health status is predicted based on the structure-aware representation learned from the local-global behavior graph. We take experiments on StudentLife dataset, and extensive results demonstrate the effectiveness of our proposed model.
Persian Ezafe Recognition Using Transformers and Its Role in Part-Of-Speech Tagging
Oct 04, 2020
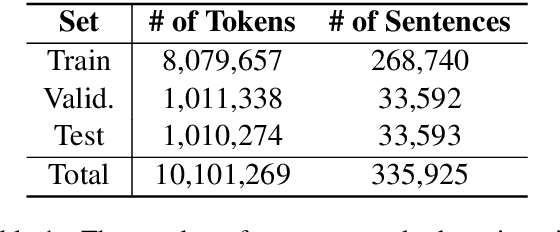
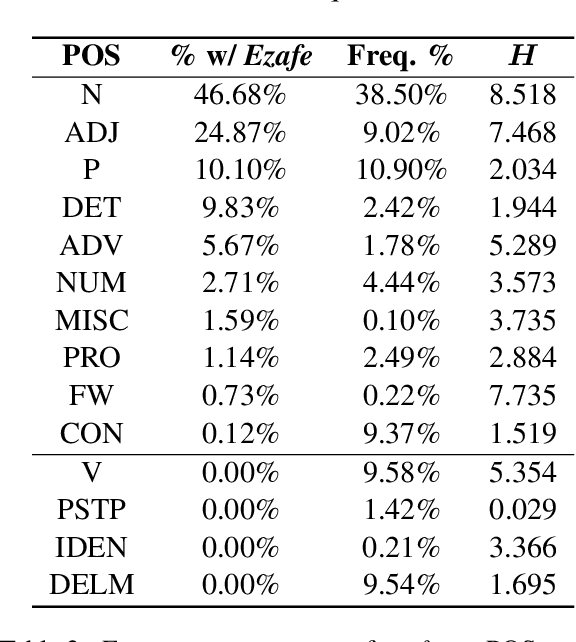
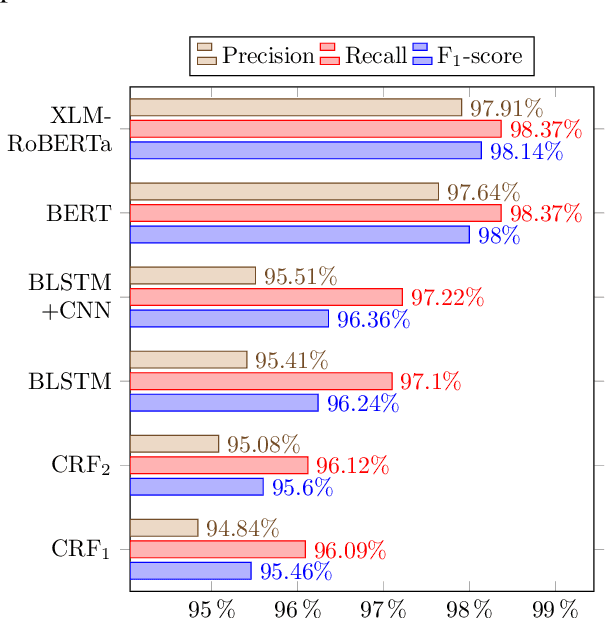
Ezafe is a grammatical particle in some Iranian languages that links two words together. Regardless of the important information it conveys, it is almost always not indicated in Persian script, resulting in mistakes in reading complex sentences and errors in natural language processing tasks. In this paper, we experiment with different machine learning methods to achieve state-of-the-art results in the task of ezafe recognition. Transformer-based methods, BERT and XLMRoBERTa, achieve the best results, the latter achieving 2.68% F1-score more than the previous state-of-the-art. We, moreover, use ezafe information to improve Persian part-of-speech tagging results and show that such information will not be useful to transformer-based methods and explain why that might be the case.