 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multiview and Multiclass Image Segmentation using Deep Learning in Fetal Echocardiography
Mar 23, 2021
Congenital heart disease (CHD) is the most common congenital abnormality associated with birth defects in the United States. Despite training efforts and substantial advancement in ultrasound technology over the past years, CHD remains an abnormality that is frequently missed during prenatal ultrasonography. Therefore, computer-aided detection of CHD can play a critical role in prenatal care by improving screening and diagnosis. Since many CHDs involve structural abnormalities, automatic segmentation of anatomical structures is an important step in the analysis of fetal echocardiograms. While existing methods mainly focus on the four-chamber view with a small number of structures, here we present a more comprehensive deep learning segmentation framework covering 14 anatomical structures in both three-vessel trachea and four-chamber views. Specifically, our framework enhances the V-Net with spatial dropout, group normalization, and deep supervision to train a segmentation model that can be applied on both views regardless of abnormalities. By identifying the pitfall of using the Dice loss when some labels are unavailable in some images, this framework integrates information from multiple views and is robust to missing structures due to anatomical anomalies, achieving an average Dice score of 79%.
Spillover Algorithm: A Decentralized Coordination Approach for Multi-Robot Production Planning in Open Shared Factories
Jan 23, 2021
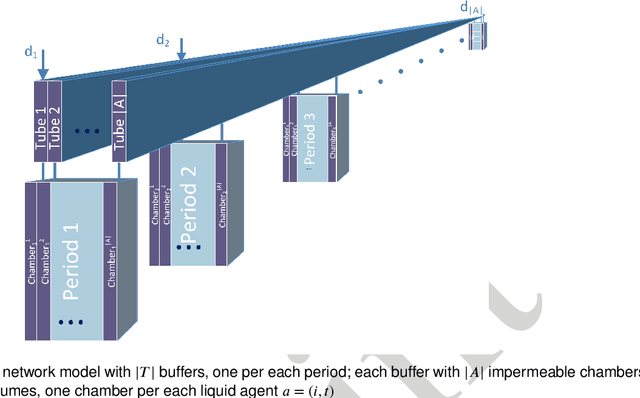

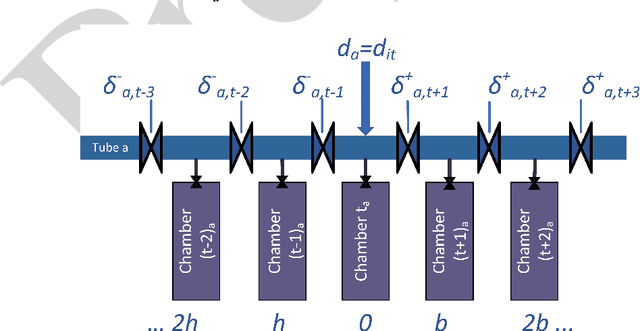
Open and shared manufacturing factories typically dispose of a limited number of robots that should be properly allocated to tasks in time and space for an effective and efficient system performance. In particular, we deal with the dynamic capacitated production planning problem with sequence independent setup costs where quantities of products to manufacture and location of robots need to be determined at consecutive periods within a given time horizon and products can be anticipated or backordered related to the demand period. We consider a decentralized multi-agent variant of this problem in an open factory setting with multiple owners of robots as well as different owners of the items to be produced, both considered self-interested and individually rational. Existing solution approaches to the classic constrained lot-sizing problem are centralized exact methods that require sharing of global knowledge of all the participants' private and sensitive information and are not applicable in the described multi-agent context. Therefore, we propose a computationally efficient decentralized approach based on the spillover effect that solves this NP-hard problem by distributing decisions in an intrinsically decentralized multi-agent system environment while protecting private and sensitive information. To the best of our knowledge, this is the first decentralized algorithm for the solution of the studied problem in intrinsically decentralized environments where production resources and/or products are owned by multiple stakeholders with possibly conflicting objectives. To show its efficiency, the performance of the Spillover Algorithm is benchmarked against state-of-the-art commercial solver CPLEX 12.8.
Causal Hidden Markov Model for Time Series Disease Forecasting
Mar 30, 2021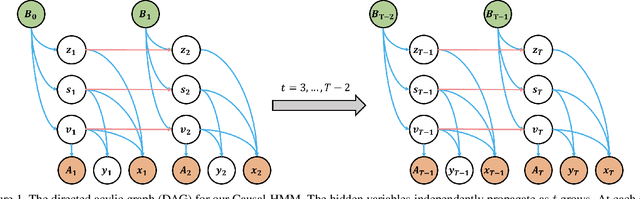
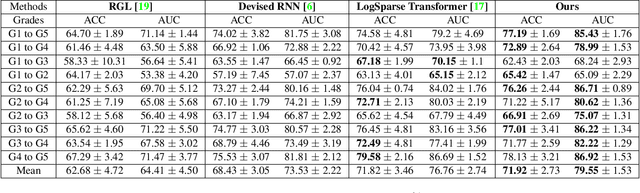
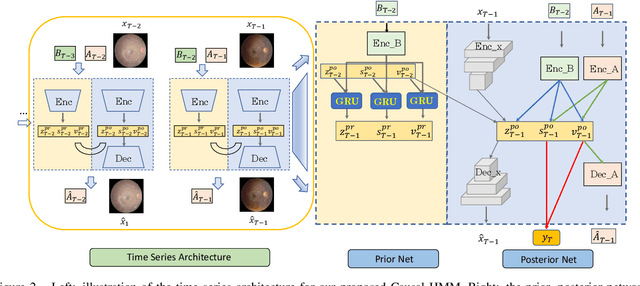
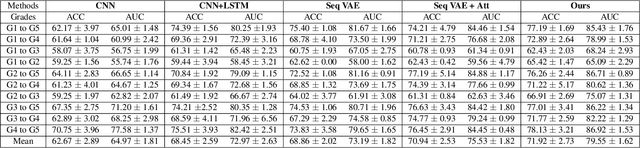
We propose a causal hidden Markov model to achieve robust prediction of irreversible disease at an early stage, which is safety-critical and vital for medical treatment in early stages. Specifically, we introduce the hidden variables which propagate to generate medical data at each time step. To avoid learning spurious correlation (e.g., confounding bias), we explicitly separate these hidden variables into three parts: a) the disease (clinical)-related part; b) the disease (non-clinical)-related part; c) others, with only a),b) causally related to the disease however c) may contain spurious correlations (with the disease) inherited from the data provided. With personal attributes and the disease label respectively provided as side information and supervision, we prove that these disease-related hidden variables can be disentangled from others, implying the avoidance of spurious correlation for generalization to medical data from other (out-of-) distributions. Guaranteed by this result, we propose a sequential variational auto-encoder with a reformulated objective function. We apply our model to the early prediction of peripapillary atrophy and achieve promising results on out-of-distribution test data. Further, the ablation study empirically shows the effectiveness of each component in our method. And the visualization shows the accurate identification of lesion regions from others.
SaNet: Scale-aware neural Network for Parsing Multiple Spatial Resolution Aerial Images
Mar 14, 2021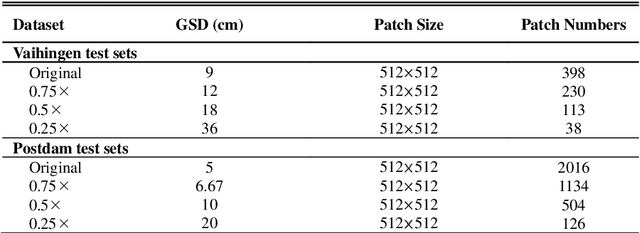


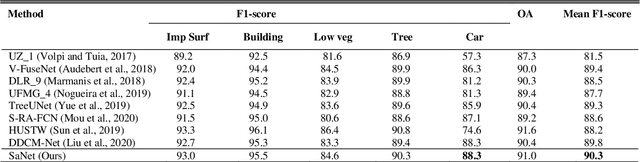
Assigning the geospatial objects of aerial images with categorical information at the pixel-level is a basic task in urban scene understanding. However, the huge differencc in remote sensing sensors makes the acqured aerial images in multiple spatial resolution (MSR), which brings two issues: the increased scale variation of geospatial objects and informative feature loss as spatial resolution drops. To address the two issues, we propose a novel scale-aware neural network (SaNet) for parsing MSR aerial images. For coping with the imbalanced segmentation quality between larger and smaller objects caused by the scale variation, the SaNet deploys a densely connected feature network (DCFPN) module to capture quality multi-scale context with large receptive fields. To alleviate the informative feature loss, a SFR module is incorporated into the network to learn scale-invariant features with spatial relation enhancement. Extensive experimental results on the ISPRS Vaihingen 2D Dataset and ISPRS Potsdam 2D Dataset demonstrate the outstanding cross-resolution segmentation ability of the proposed SaNet compared to other state-of-the-art networks.
Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order Pooling
Nov 30, 2020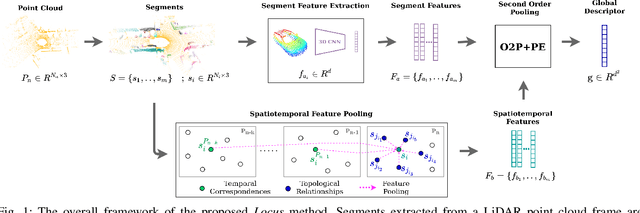
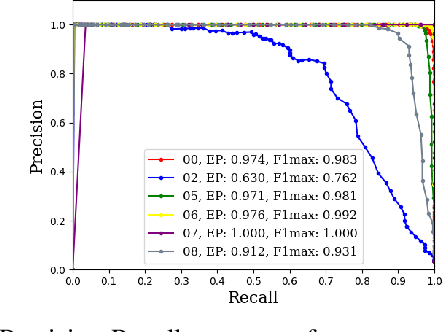
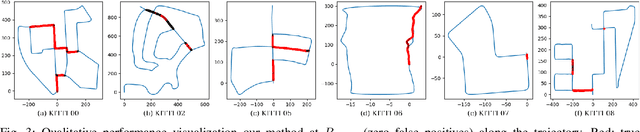
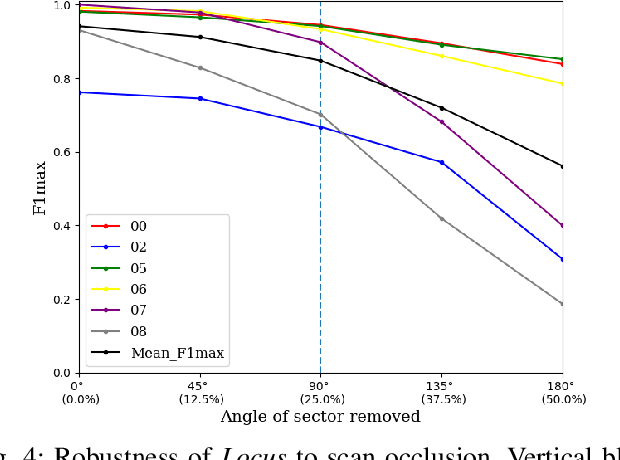
Place Recognition (PR) enables the estimation of a globally consistent map and trajectory by providing non-local constraints in Simultaneous Localisation and Mapping (SLAM). This paper presents Locus, a novel place recognition method using 3D LiDAR point clouds in large-scale environments. We propose a novel method for extracting and encoding topological and temporal information related to components in a scene and demonstrate how the inclusion of this auxiliary information in place description leads to more robust and discriminative scene representations. Second-order pooling along with a non-linear transform is used to aggregate these multi-level features to generate a fixed-length global descriptor, which is invariant to the permutation of input features. The proposed method outperforms state-of-the-art methods on the KITTI dataset. Furthermore, Locus is demonstrated to be robust across several challenging situations such as occlusions and viewpoint changes.
A Graph Total Variation Regularized Softmax for Text Generation
Jan 01, 2021

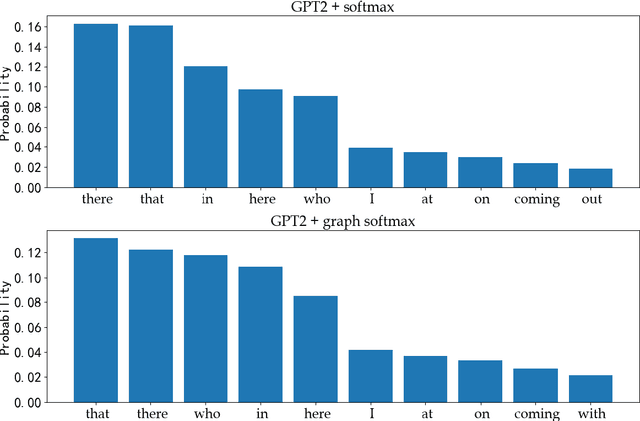
The softmax operator is one of the most important functions in machine learning models. When applying neural networks to multi-category classification, the correlations among different categories are often ignored. For example, in text generation, a language model makes a choice of each new word based only on the former selection of its context. In this scenario, the link statistics information of concurrent words based on a corpus (an analogy of the natural way of expression) is also valuable in choosing the next word, which can help to improve the sentence's fluency and smoothness. To fully explore such important information, we propose a graph softmax function for text generation. It is expected that the final classification result would be dominated by both the language model and graphical text relationships among words. We use a graph total variation term to regularize softmax so as to incorporate the concurrent relationship into the language model. The total variation of the generated words should be small locally. We apply the proposed graph softmax to GPT2 for the text generation task. Experimental results demonstrate that the proposed graph softmax achieves better BLEU and perplexity than softmax. Human testers can also easily distinguish the text generated by the graph softmax or softmax.
A Dynamic Battery State-of-Health Forecasting Model for Electric Trucks: Li-Ion Batteries Case-Study
Mar 30, 2021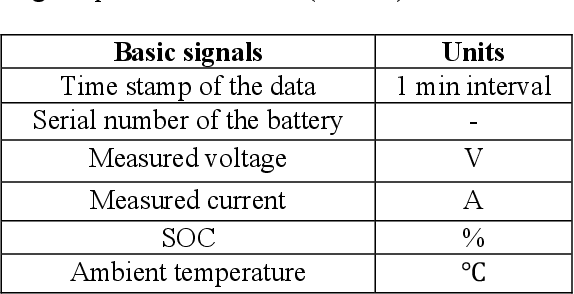
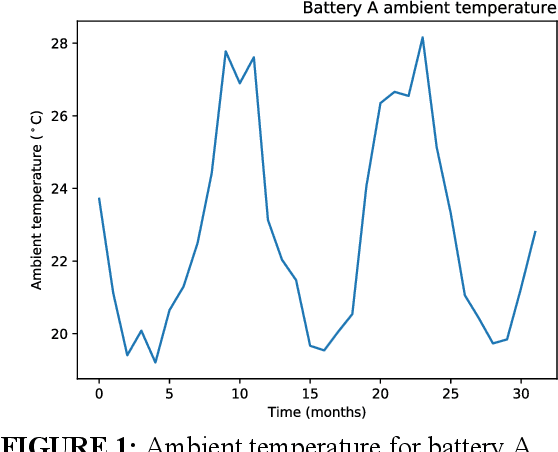
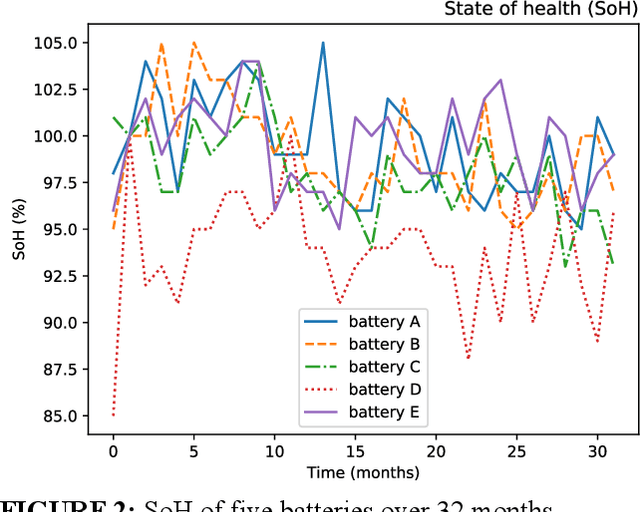
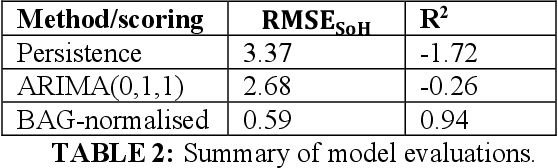
It is of extreme importance to monitor and manage the battery health to enhance the performance and decrease the maintenance cost of operating electric vehicles. This paper concerns the machine-learning-enabled state-of-health (SoH) prognosis for Li-ion batteries in electric trucks, where they are used as energy sources. The paper proposes methods to calculate SoH and cycle life for the battery packs. We propose autoregressive integrated modeling average (ARIMA) and supervised learning (bagging with decision tree as the base estimator; BAG) for forecasting the battery SoH in order to maximize the battery availability for forklift operations. As the use of data-driven methods for battery prognostics is increasing, we demonstrate the capabilities of ARIMA and under circumstances when there is little prior information available about the batteries. For this work, we had a unique data set of 31 lithium-ion battery packs from forklifts in commercial operations. On the one hand, results indicate that the developed ARIMA model provided relevant tools to analyze the data from several batteries. On the other hand, BAG model results suggest that the developed supervised learning model using decision trees as base estimator yields better forecast accuracy in the presence of large variation in data for one battery.
* This paper has first been published at the Proceedings of the ASME 2020 International Mechanical Engineering Congress and Exposition IMECE2020 held on November 16-19, 2020, Portland, OR, USA
Weakly supervised segmentation with cross-modality equivariant constraints
Apr 06, 2021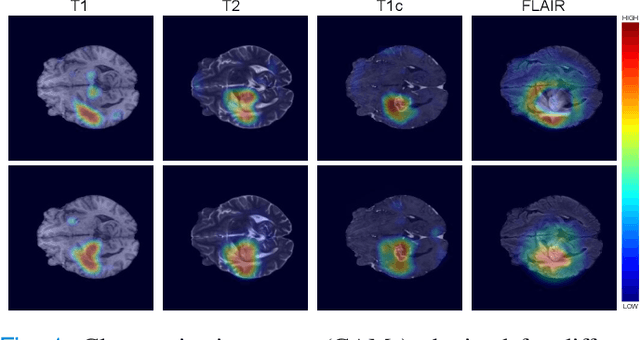
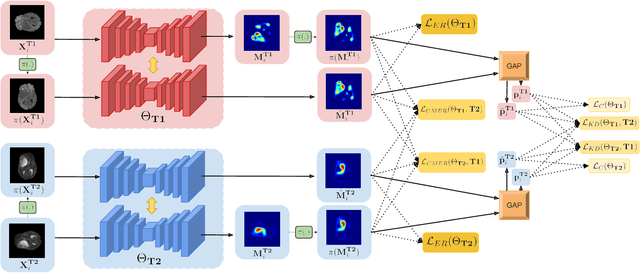
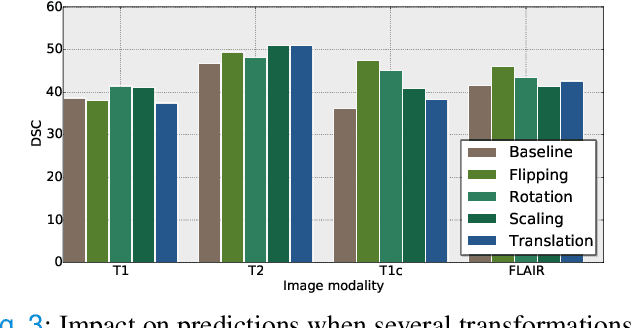
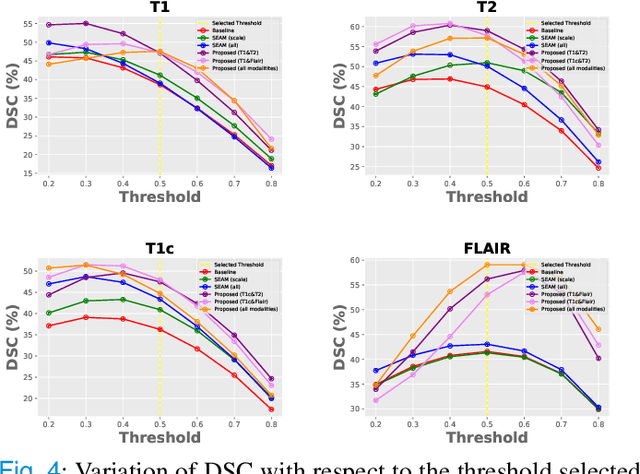
Weakly supervised learning has emerged as an appealing alternative to alleviate the need for large labeled datasets in semantic segmentation. Most current approaches exploit class activation maps (CAMs), which can be generated from image-level annotations. Nevertheless, resulting maps have been demonstrated to be highly discriminant, failing to serve as optimal proxy pixel-level labels. We present a novel learning strategy that leverages self-supervision in a multi-modal image scenario to significantly enhance original CAMs. In particular, the proposed method is based on two observations. First, the learning of fully-supervised segmentation networks implicitly imposes equivariance by means of data augmentation, whereas this implicit constraint disappears on CAMs generated with image tags. And second, the commonalities between image modalities can be employed as an efficient self-supervisory signal, correcting the inconsistency shown by CAMs obtained across multiple modalities. To effectively train our model, we integrate a novel loss function that includes a within-modality and a cross-modality equivariant term to explicitly impose these constraints during training. In addition, we add a KL-divergence on the class prediction distributions to facilitate the information exchange between modalities, which, combined with the equivariant regularizers further improves the performance of our model. Exhaustive experiments on the popular multi-modal BRATS dataset demonstrate that our approach outperforms relevant recent literature under the same learning conditions.
Transfer Learning based Speech Affect Recognition in Urdu
Mar 05, 2021

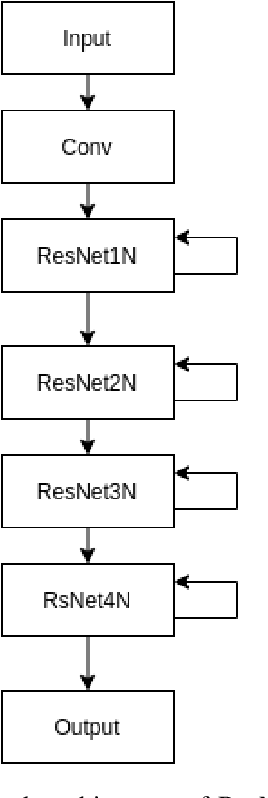
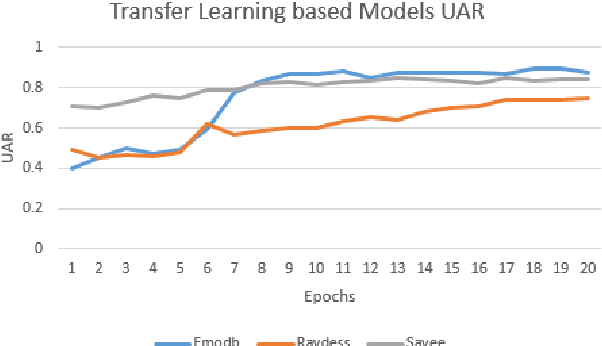
It has been established that Speech Affect Recognition for low resource languages is a difficult task. Here we present a Transfer learning based Speech Affect Recognition approach in which: we pre-train a model for high resource language affect recognition task and fine tune the parameters for low resource language using Deep Residual Network. Here we use standard four data sets to demonstrate that transfer learning can solve the problem of data scarcity for Affect Recognition task. We demonstrate that our approach is efficient by achieving 74.7 percent UAR on RAVDESS as source and Urdu data set as a target. Through an ablation study, we have identified that pre-trained model adds most of the features information, improvement in results and solves less data issues. Using this knowledge, we have also experimented on SAVEE and EMO-DB data set by setting Urdu as target language where only 400 utterances of data is available. This approach achieves high Unweighted Average Recall (UAR) when compared with existing algorithms.
Exploring the social influence of Kaggle virtual community on the M5 competition
Feb 28, 2021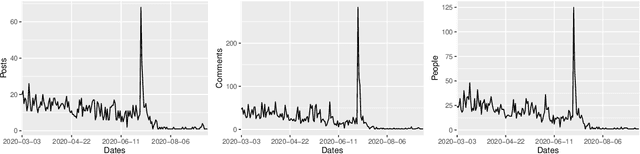
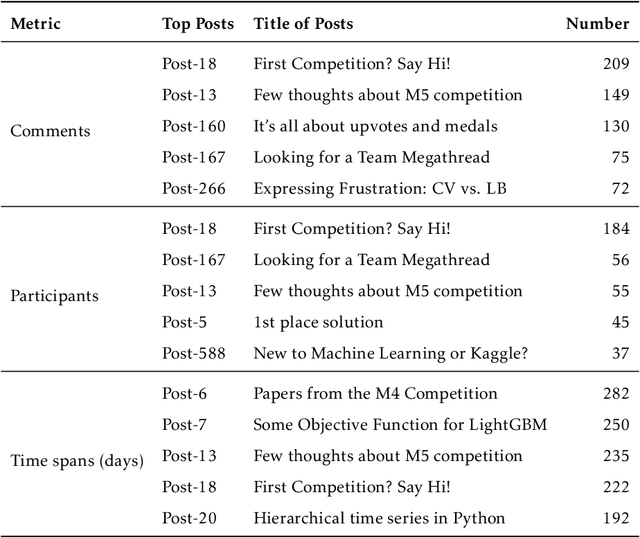
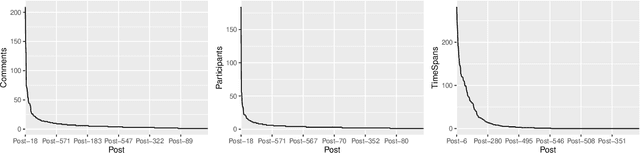

One of the most significant differences of M5 over previous forecasting competitions is that it was held on Kaggle, an online community of data scientists and machine learning practitioners. On the Kaggle platform, people can form virtual communities such as online notebooks and discussions to discuss their models, choice of features, loss functions, etc. This paper aims to study the social influence of virtual communities on the competition. We first study the content of the M5 virtual community by topic modeling and trend analysis. Further, we perform social media analysis to identify the potential relationship network of the virtual community. We find some key roles in the network and study their roles in spreading the LightGBM related information within the network. Overall, this study provides in-depth insights into the dynamic mechanism of the virtual community influence on the participants and has potential implications for future online competitions.