 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extending Isolation Forest for Anomaly Detection in Big Data via K-Means
Apr 27, 2021


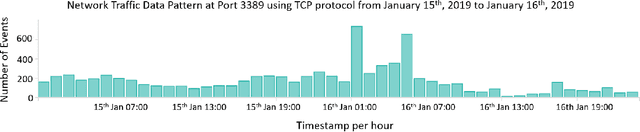

Industrial Information Technology (IT) infrastructures are often vulnerable to cyberattacks. To ensure security to the computer systems in an industrial environment, it is required to build effective intrusion detection systems to monitor the cyber-physical systems (e.g., computer networks) in the industry for malicious activities. This paper aims to build such intrusion detection systems to protect the computer networks from cyberattacks. More specifically, we propose a novel unsupervised machine learning approach that combines the K-Means algorithm with the Isolation Forest for anomaly detection in industrial big data scenarios. Since our objective is to build the intrusion detection system for the big data scenario in the industrial domain, we utilize the Apache Spark framework to implement our proposed model which was trained in large network traffic data (about 123 million instances of network traffic) stored in Elasticsearch. Moreover, we evaluate our proposed model on the live streaming data and find that our proposed system can be used for real-time anomaly detection in the industrial setup. In addition, we address different challenges that we face while training our model on large datasets and explicitly describe how these issues were resolved. Based on our empirical evaluation in different use-cases for anomaly detection in real-world network traffic data, we observe that our proposed system is effective to detect anomalies in big data scenarios. Finally, we evaluate our proposed model on several academic datasets to compare with other models and find that it provides comparable performance with other state-of-the-art approaches.
Learning Graph Structures with Transformer for Multivariate Time Series Anomaly Detection in IoT
Apr 08, 2021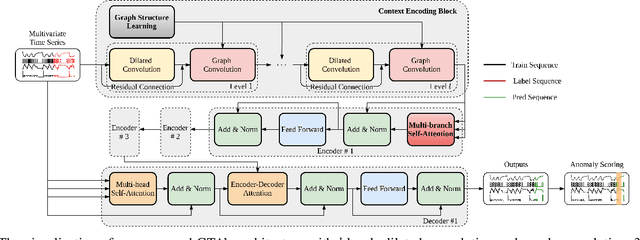
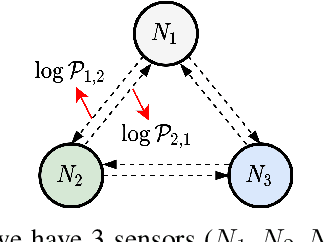
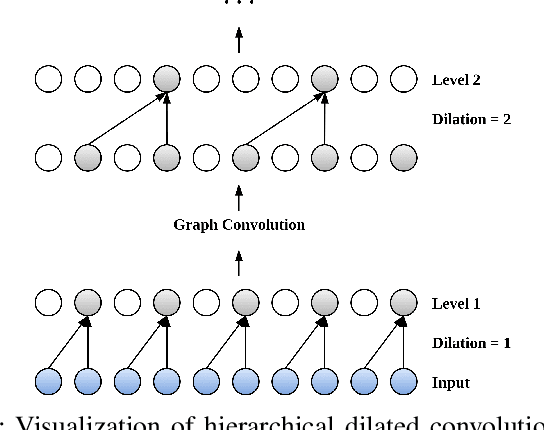
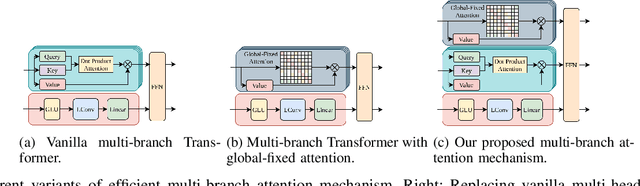
Many real-world IoT systems comprising various internet-connected sensory devices generate substantial amounts of multivariate time series data. Meanwhile, those critical IoT infrastructures, such as smart power grids and water distribution networks, are often targets of cyber-attacks, making anomaly detection of high research value. However, considering the complex topological and nonlinear dependencies that are initially unknown among sensors, modeling such relatedness is inevitable for any efficient and accurate anomaly detection system. Additionally, due to multivariate time series' temporal dependency and stochasticity, their anomaly detection remains a big challenge. This work proposed a novel framework, namely GTA, for multivariate time series anomaly detection by automatically learning a graph structure followed by the graph convolution and modeling the temporal dependency through a Transformer-based architecture. The core idea of learning graph structure is called the connection learning policy based on the Gumbel-softmax sampling strategy to learn bi-directed associations among sensors directly. We also devised a novel graph convolution named Influence Propagation convolution to model the anomaly information flow between graph nodes. Moreover, we proposed a multi-branch attention mechanism to substitute for original multi-head self-attention to overcome the quadratic complexity challenge. The extensive experiments on four public anomaly detection benchmarks further demonstrate our approach's superiority over other state-of-the-arts.
The NPU System for the 2020 Personalized Voice Trigger Challenge
Feb 26, 2021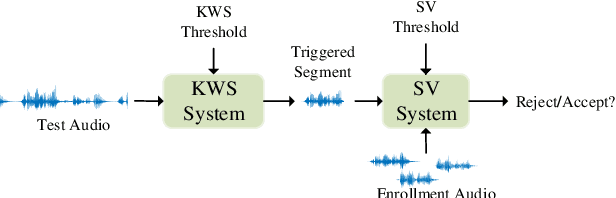
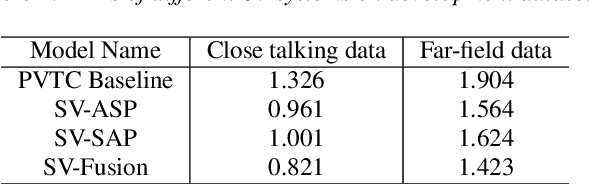
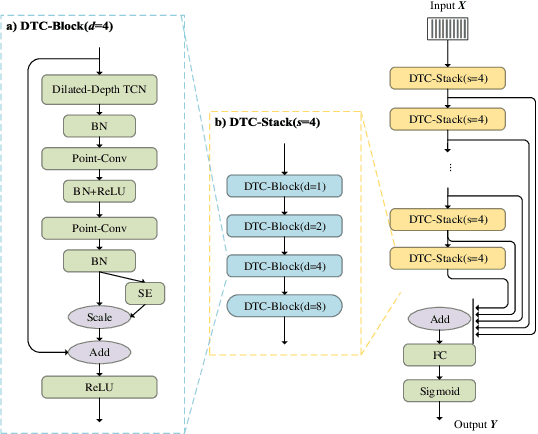

This paper describes the system developed by the NPU team for the 2020 personalized voice trigger challenge. Our submitted system consists of two independently trained subsystems: a small footprint keyword spotting (KWS) system and a speaker verification (SV) system. For the KWS system, a multi-scale dilated temporal convolutional (MDTC) network is proposed to detect wake-up word (WuW). For SV system, Write something here. The KWS predicts posterior probabilities of whether an audio utterance contains WuW and estimates the location of WuW at the same time. When the posterior probability ofWuW reaches a predefined threshold, the identity information of triggered segment is determined by the SV system. On evaluation dataset, our submitted system obtains detection costs of 0.081and 0.091 in close talking and far-field tasks, respectively.
Location-aware Single Image Reflection Removal
Dec 13, 2020
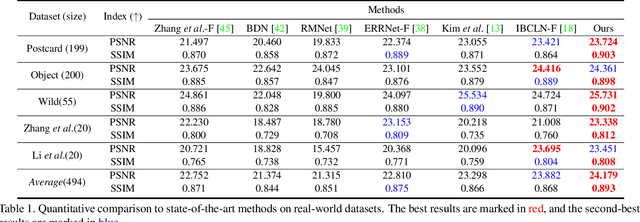
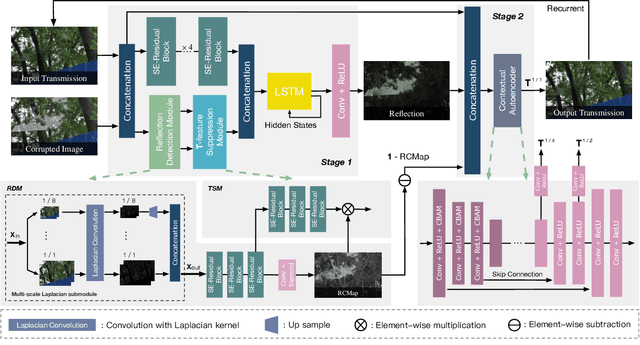
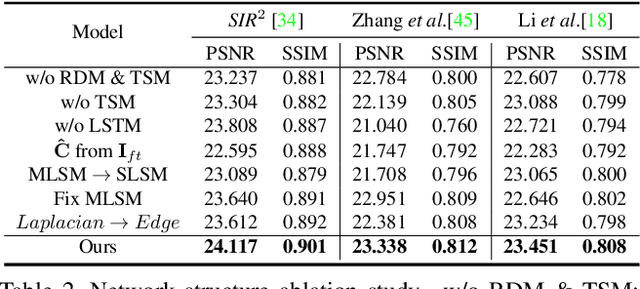
This paper proposes a novel location-aware deep learning-based single image reflection removal method. Our network has a reflection detection module to regress a probabilistic reflection confidence map, taking multi-scale Laplacian features as inputs. This probabilistic map tells whether a region is reflection-dominated or transmission-dominated. The novelty is that we use the reflection confidence map as the cues for the network to learn how to encode the reflection information adaptively and control the feature flow when predicting reflection and transmission layers. The integration of location information into the network significantly improves the quality of reflection removal results. Besides, a set of learnable Laplacian kernel parameters is introduced to facilitate the extraction of discriminative Laplacian features for reflection detection. We design our network as a recurrent network to progressively refine each iteration's reflection removal results. Extensive experiments verify the superior performance of the proposed method over state-of-the-art approaches.
Meta Graph Attention on Heterogeneous Graph with Node-Edge Co-evolution
Oct 09, 2020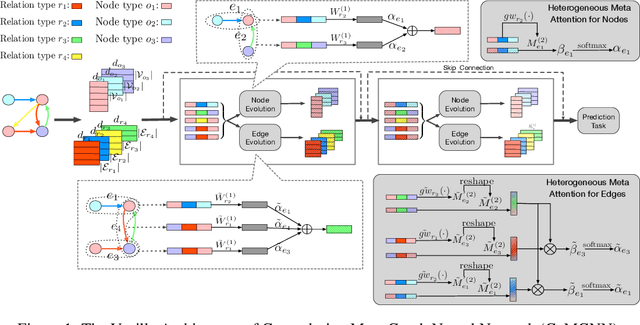
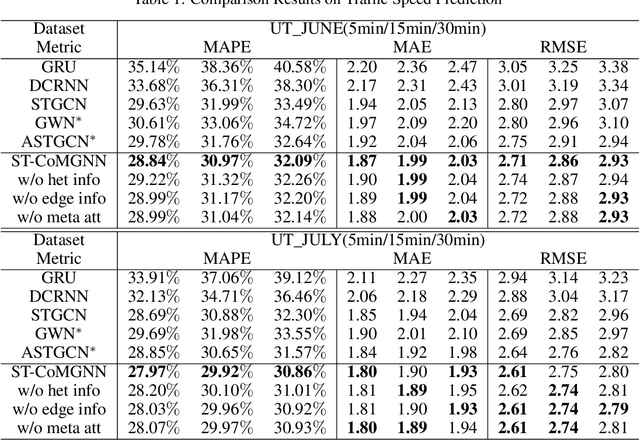
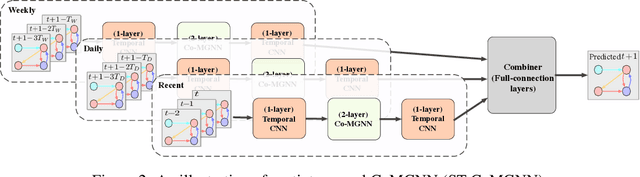
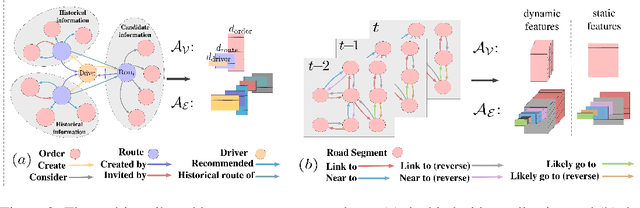
Graph neural networks have become an important tool for modeling structured data. In many real-world systems, intricate hidden information may exist, e.g., heterogeneity in nodes/edges, static node/edge attributes, and spatiotemporal node/edge features. However, most existing methods only take part of the information into consideration. In this paper, we present the Co-evolved Meta Graph Neural Network (CoMGNN), which applies meta graph attention to heterogeneous graphs with co-evolution of node and edge states. We further propose a spatiotemporal adaption of CoMGNN (ST-CoMGNN) for modeling spatiotemporal patterns on nodes and edges. We conduct experiments on two large-scale real-world datasets. Experimental results show that our models significantly outperform the state-of-the-art methods, demonstrating the effectiveness of encoding diverse information from different aspects.
Predicting the Reproducibility of Social and Behavioral Science Papers Using Supervised Learning Models
Apr 08, 2021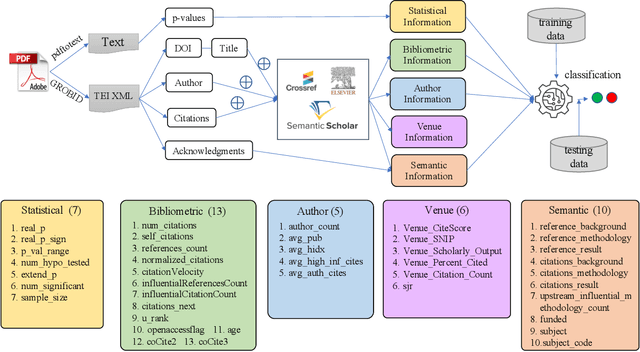
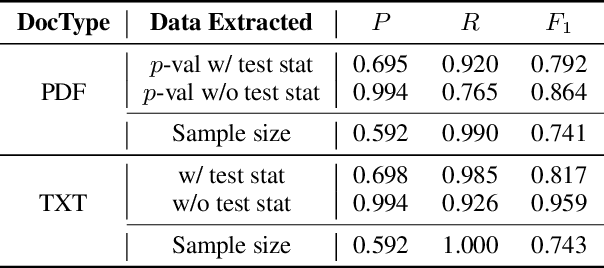
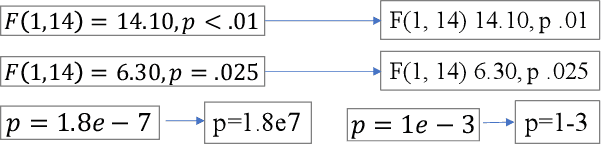
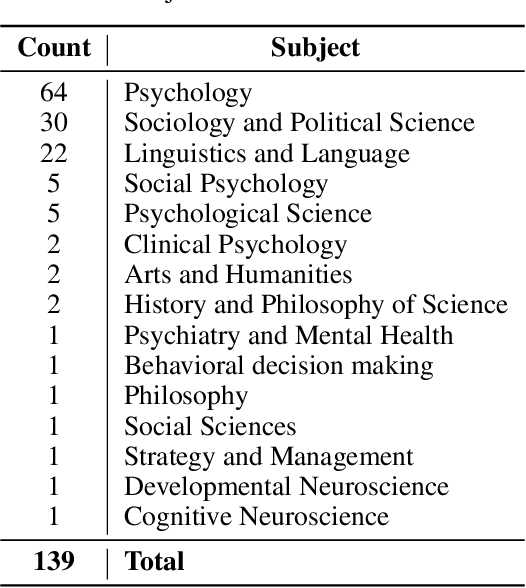
In recent years, significant effort has been invested verifying the reproducibility and robustness of research claims in social and behavioral sciences (SBS), much of which has involved resource-intensive replication projects. In this paper, we investigate prediction of the reproducibility of SBS papers using machine learning methods based on a set of features. We propose a framework that extracts five types of features from scholarly work that can be used to support assessments of reproducibility of published research claims. Bibliometric features, venue features, and author features are collected from public APIs or extracted using open source machine learning libraries with customized parsers. Statistical features, such as p-values, are extracted by recognizing patterns in the body text. Semantic features, such as funding information, are obtained from public APIs or are extracted using natural language processing models. We analyze pairwise correlations between individual features and their importance for predicting a set of human-assessed ground truth labels. In doing so, we identify a subset of 9 top features that play relatively more important roles in predicting the reproducibility of SBS papers in our corpus. Results are verified by comparing performances of 10 supervised predictive classifiers trained on different sets of features.
Skimming and Scanning for Untrimmed Video Action Recognition
Apr 21, 2021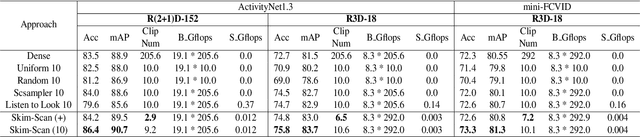
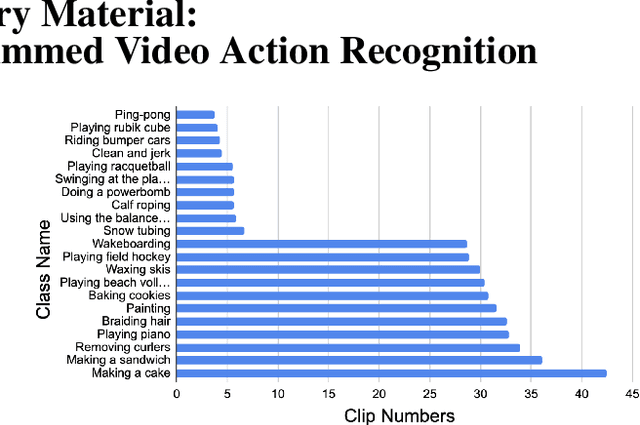
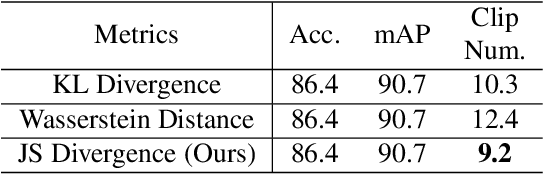
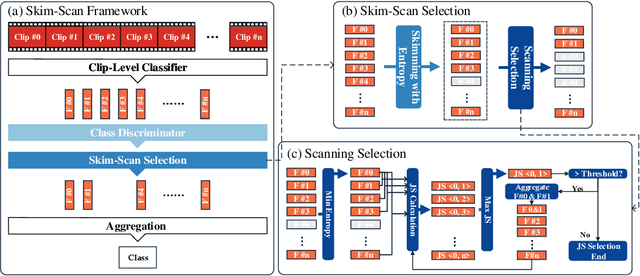
Video action recognition (VAR) is a primary task of video understanding, and untrimmed videos are more common in real-life scenes. Untrimmed videos have redundant and diverse clips containing contextual information, so sampling dense clips is essential. Recently, some works attempt to train a generic model to select the N most representative clips. However, it is difficult to model the complex relations from intra-class clips and inter-class videos within a single model and fixed selected number, and the entanglement of multiple relations is also hard to explain. Thus, instead of "only look once", we argue "divide and conquer" strategy will be more suitable in untrimmed VAR. Inspired by the speed reading mechanism, we propose a simple yet effective clip-level solution based on skim-scan techniques. Specifically, the proposed Skim-Scan framework first skims the entire video and drops those uninformative and misleading clips. For the remaining clips, it scans clips with diverse features gradually to drop redundant clips but cover essential content. The above strategies can adaptively select the necessary clips according to the difficulty of the different videos. To trade off the computational complexity and performance, we observe the similar statistical expression between lightweight and heavy networks, thus it supports us to explore the combination of them. Comprehensive experiments are performed on ActivityNet and mini-FCVID datasets, and results demonstrate that our solution surpasses the state-of-the-art performance in terms of both accuracy and efficiency.
Discovering key topics from short, real-world medical inquiries via natural language processing and unsupervised learning
Dec 08, 2020
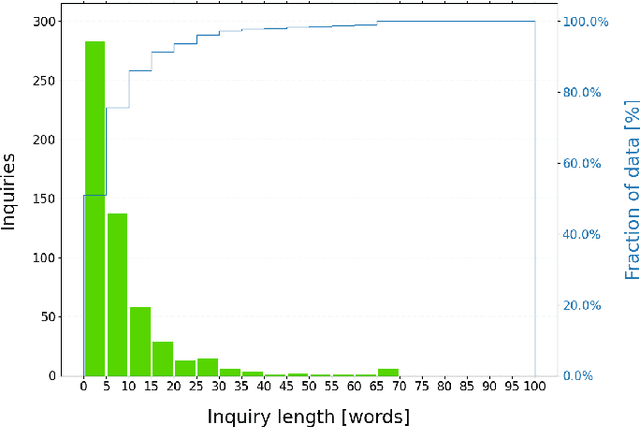
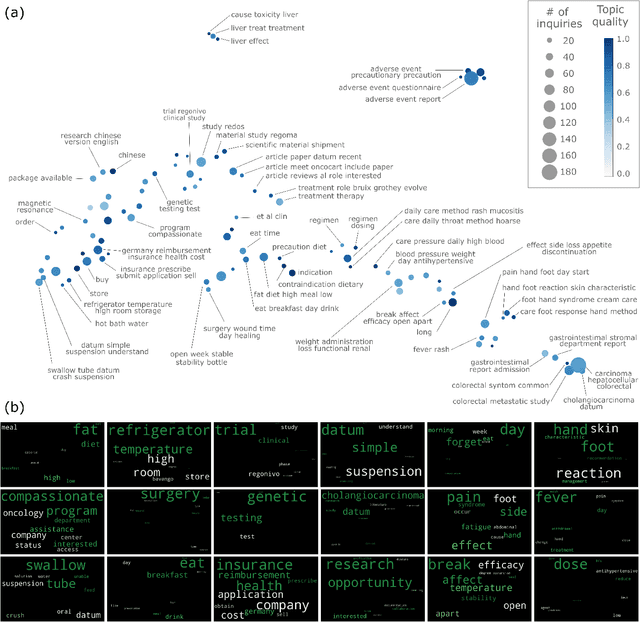
Millions of unsolicited medical inquiries are received by pharmaceutical companies every year. It has been hypothesized that these inquiries represent a treasure trove of information, potentially giving insight into matters regarding medicinal products and the associated medical treatments. However, due to the large volume and specialized nature of the inquiries, it is difficult to perform timely, recurrent, and comprehensive analyses. Here, we propose a machine learning approach based on natural language processing and unsupervised learning to automatically discover key topics in real-world medical inquiries from customers. This approach does not require ontologies nor annotations. The discovered topics are meaningful and medically relevant, as judged by medical information specialists, thus demonstrating that unsolicited medical inquiries are a source of valuable customer insights. Our work paves the way for the machine-learning-driven analysis of medical inquiries in the pharmaceutical industry, which ultimately aims at improving patient care.
LUCES: A Dataset for Near-Field Point Light Source Photometric Stereo
Apr 27, 2021


Three-dimensional reconstruction of objects from shading information is a challenging task in computer vision. As most of the approaches facing the Photometric Stereo problem use simplified far-field assumptions, real-world scenarios have essentially more complex physical effects that need to be handled for accurately reconstructing the 3D shape. An increasing number of methods have been proposed to address the problem when point light sources are assumed to be nearby the target object. The proximity of the light sources complicates the modeling of the image formation as the light behaviour requires non-linear parameterisation to describe its propagation and attenuation. To understand the capability of the approaches dealing with this near-field scenario, the literature till now has used synthetically rendered photometric images or minimal and very customised real-world data. In order to fill the gap in evaluating near-field photometric stereo methods, we introduce LUCES the first real-world 'dataset for near-fieLd point light soUrCe photomEtric Stereo' of 14 objects of a varying of materials. A device counting 52 LEDs has been designed to lit each object positioned 10 to 30 centimeters away from the camera. Together with the raw images, in order to evaluate the 3D reconstructions, the dataset includes both normal and depth maps for comparing different features of the retrieved 3D geometry. Furthermore, we evaluate the performance of the latest near-field Photometric Stereo algorithms on the proposed dataset to assess the SOTA method with respect to actual close range effects and object materials.
A Signal-Centric Perspective on the Evolution of Symbolic Communication
Mar 31, 2021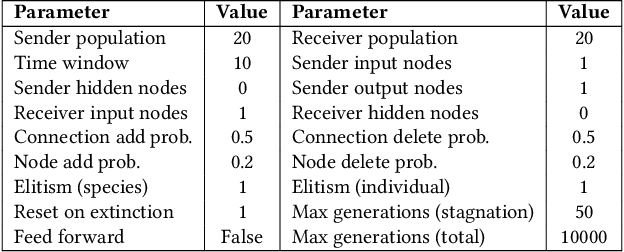
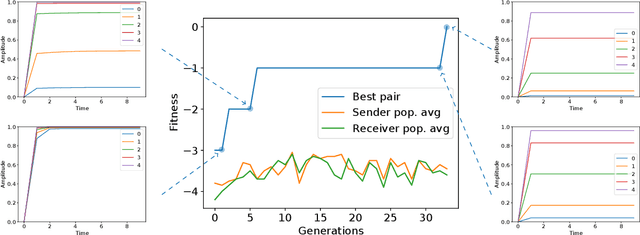
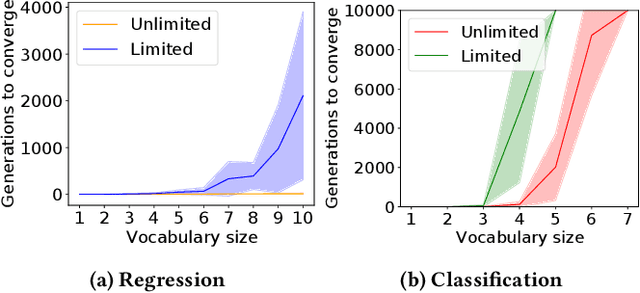
The evolution of symbolic communication is a longstanding open research question in biology. While some theories suggest that it originated from sub-symbolic communication (i.e., iconic or indexical), little experimental evidence exists on how organisms can actually evolve to define a shared set of symbols with unique interpretable meaning, thus being capable of encoding and decoding discrete information. Here, we use a simple synthetic model composed of sender and receiver agents controlled by Continuous-Time Recurrent Neural Networks, which are optimized by means of neuro-evolution. We characterize signal decoding as either regression or classification, with limited and unlimited signal amplitude. First, we show how this choice affects the complexity of the evolutionary search, and leads to different levels of generalization. We then assess the effect of noise, and test the evolved signaling system in a referential game. In various settings, we observe agents evolving to share a dictionary of symbols, with each symbol spontaneously associated to a 1-D unique signal. Finally, we analyze the constellation of signals associated to the evolved signaling systems and note that in most cases these resemble a Pulse Amplitude Modulation system.