 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LARNet: Lie Algebra Residual Network for Profile Face Recognition
Mar 15, 2021
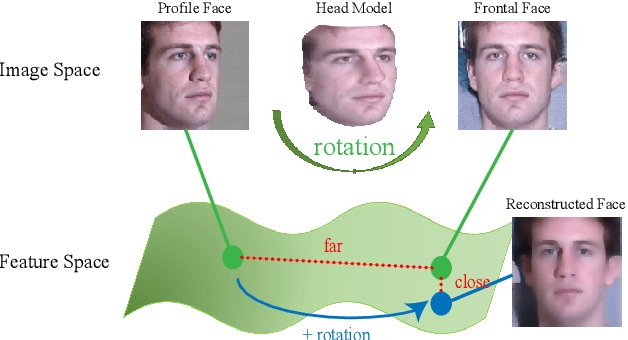
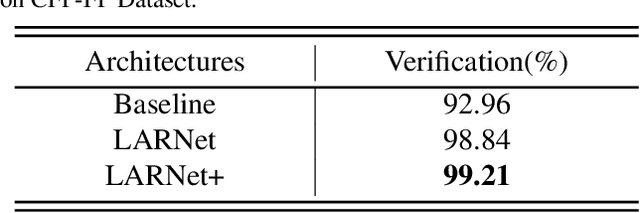
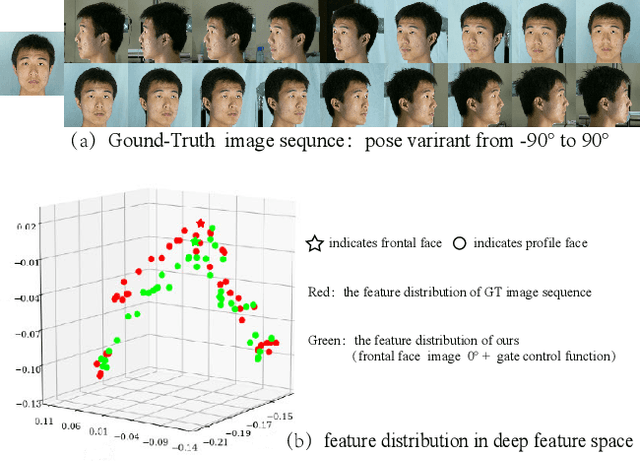

Due to large variations between profile and frontal faces, profile-based face recognition remains as a tremendous challenge in many practical vision scenarios. Traditional techniques address this challenge either by synthesizing frontal faces or by pose-invariants learning. In this paper, we propose a novel method with Lie algebra theory to explore how face rotation in the 3D space affects the deep feature generation process of convolutional neural networks (CNNs). We prove that face rotation in the image space is equivalent to an additive residual component in the feature space of CNNs, which is determined solely by the rotation. Based on this theoretical finding, we further design a Lie algebraic residual network (LARNet) for tackling profile-based face recognition. Our LARNet consists of a residual subnet for decoding rotation information from input face images, and a gating subnet to learn rotation magnitude for controlling the number of residual components contributing to the feature learning process. Comprehensive experimental evaluations on frontal-profile face datasets and general face recognition datasets demonstrate that our method consistently outperforms the state-of-the-arts.
Over-the-Air Statistical Estimation
Mar 06, 2021We study schemes and lower bounds for distributed minimax statistical estimation over a Gaussian multiple-access channel (MAC) under squared error loss, in a framework combining statistical estimation and wireless communication. First, we develop "analog" joint estimation-communication schemes that exploit the superposition property of the Gaussian MAC and we characterize their risk in terms of the number of nodes and dimension of the parameter space. Then, we derive information-theoretic lower bounds on the minimax risk of any estimation scheme restricted to communicate the samples over a given number of uses of the channel and show that the risk achieved by our proposed schemes is within a logarithmic factor of these lower bounds. We compare both achievability and lower bound results to previous "digital" lower bounds, where nodes transmit errorless bits at the Shannon capacity of the MAC, showing that estimation schemes that leverage the physical layer offer a drastic reduction in estimation error over digital schemes relying on a physical-layer abstraction.
Understanding Chinese Video and Language via Contrastive Multimodal Pre-Training
Apr 19, 2021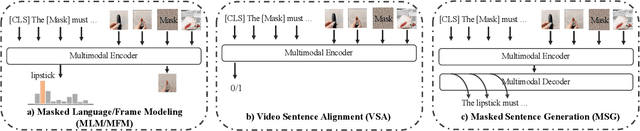
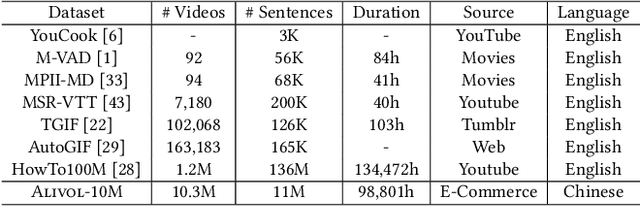

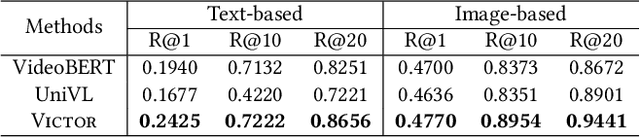
The pre-trained neural models have recently achieved impressive performances in understanding multimodal content. However, it is still very challenging to pre-train neural models for video and language understanding, especially for Chinese video-language data, due to the following reasons. Firstly, existing video-language pre-training algorithms mainly focus on the co-occurrence of words and video frames, but ignore other valuable semantic and structure information of video-language content, e.g., sequential order and spatiotemporal relationships. Secondly, there exist conflicts between video sentence alignment and other proxy tasks. Thirdly, there is a lack of large-scale and high-quality Chinese video-language datasets (e.g., including 10 million unique videos), which are the fundamental success conditions for pre-training techniques. In this work, we propose a novel video-language understanding framework named VICTOR, which stands for VIdeo-language understanding via Contrastive mulTimOdal pRe-training. Besides general proxy tasks such as masked language modeling, VICTOR constructs several novel proxy tasks under the contrastive learning paradigm, making the model be more robust and able to capture more complex multimodal semantic and structural relationships from different perspectives. VICTOR is trained on a large-scale Chinese video-language dataset, including over 10 million complete videos with corresponding high-quality textual descriptions. We apply the pre-trained VICTOR model to a series of downstream applications and demonstrate its superior performances, comparing against the state-of-the-art pre-training methods such as VideoBERT and UniVL. The codes and trained checkpoints will be publicly available to nourish further developments of the research community.
FlowMOT: 3D Multi-Object Tracking by Scene Flow Association
Dec 15, 2020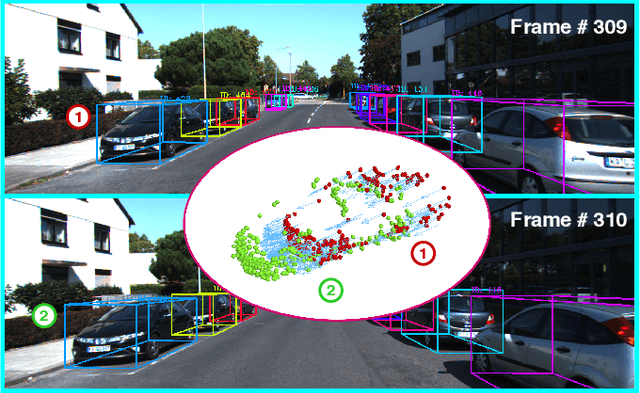
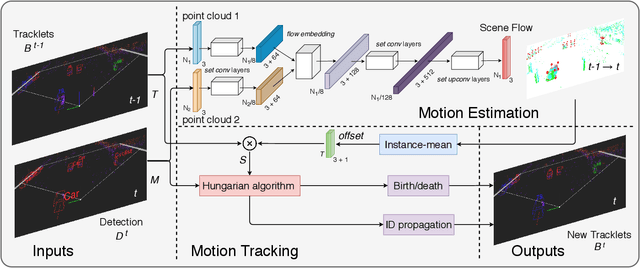
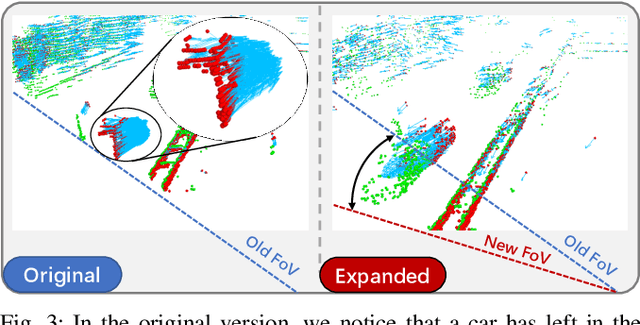

Most end-to-end Multi-Object Tracking (MOT) methods face the problems of low accuracy and poor generalization ability. Although traditional filter-based methods can achieve better results, they are difficult to be endowed with optimal hyperparameters and often fail in varying scenarios. To alleviate these drawbacks, we propose a LiDAR-based 3D MOT framework named FlowMOT, which integrates point-wise motion information into the traditional matching algorithm, enhancing the robustness of the data association. We firstly utilize a scene flow estimation network to obtain implicit motion information between two adjacent frames and calculate the predicted detection for each old tracklet in the previous frame. Then we use Hungarian algorithm to generate optimal matching relations with the ID propagation strategy to finish the tracking task. Experiments on KITTI MOT dataset show that our approach outperforms recent end-to-end methods and achieves competitive performance with the state-of-the-art filter-based method. In addition, ours can work steadily in the various-speed scenes where the filter-based methods may fail.
Video Reconstruction by Spatio-Temporal Fusion of Blurred-Coded Image Pair
Oct 20, 2020
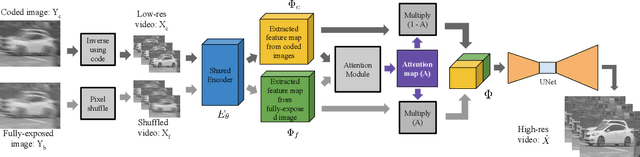
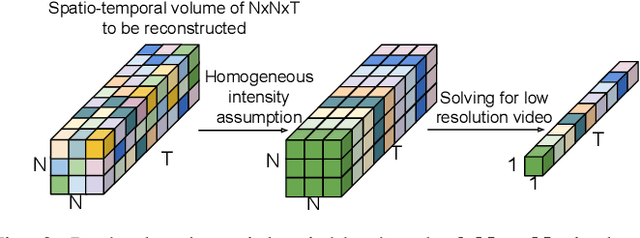

Learning-based methods have enabled the recovery of a video sequence from a single motion-blurred image or a single coded exposure image. Recovering video from a single motion-blurred image is a very ill-posed problem and the recovered video usually has many artifacts. In addition to this, the direction of motion is lost and it results in motion ambiguity. However, it has the advantage of fully preserving the information in the static parts of the scene. The traditional coded exposure framework is better-posed but it only samples a fraction of the space-time volume, which is at best 50% of the space-time volume. Here, we propose to use the complementary information present in the fully-exposed (blurred) image along with the coded exposure image to recover a high fidelity video without any motion ambiguity. Our framework consists of a shared encoder followed by an attention module to selectively combine the spatial information from the fully-exposed image with the temporal information from the coded image, which is then super-resolved to recover a non-ambiguous high-quality video. The input to our algorithm is a fully-exposed and coded image pair. Such an acquisition system already exists in the form of a Coded-two-bucket (C2B) camera. We demonstrate that our proposed deep learning approach using blurred-coded image pair produces much better results than those from just a blurred image or just a coded image.
Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone
Mar 31, 2021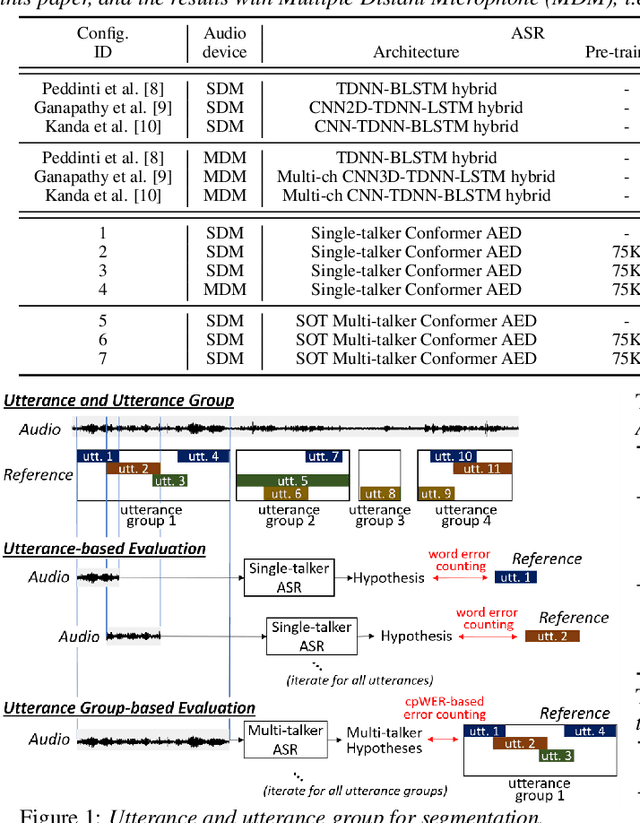


Transcribing meetings containing overlapped speech with only a single distant microphone (SDM) has been one of the most challenging problems for automatic speech recognition (ASR). While various approaches have been proposed, all previous studies on the monaural overlapped speech recognition problem were based on either simulation data or small-scale real data. In this paper, we extensively investigate a two-step approach where we first pre-train a serialized output training (SOT)-based multi-talker ASR by using large-scale simulation data and then fine-tune the model with a small amount of real meeting data. Experiments are conducted by utilizing 75 thousand (K) hours of our internal single-talker recording to simulate a total of 900K hours of multi-talker audio segments for supervised pre-training. With fine-tuning on the 70 hours of the AMI-SDM training data, our SOT ASR model achieves a word error rate (WER) of 21.2% for the AMI-SDM evaluation set while automatically counting speakers in each test segment. This result is not only significantly better than the previous state-of-the-art WER of 36.4% with oracle utterance boundary information but also better than a result by a similarly fine-tuned single-talker ASR model applied to beamformed audio.
An efficient representation of chronological events in medical texts
Oct 24, 2020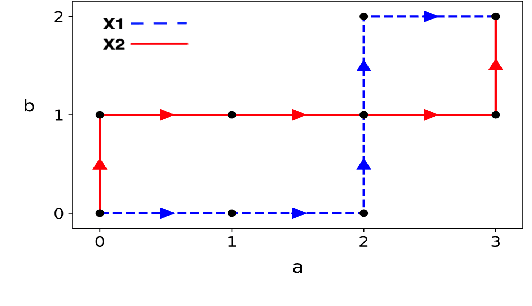
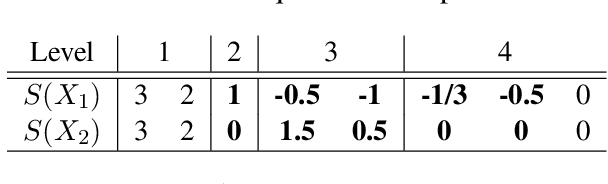

In this work we addressed the problem of capturing sequential information contained in longitudinal electronic health records (EHRs). Clinical notes, which is a particular type of EHR data, are a rich source of information and practitioners often develop clever solutions how to maximise the sequential information contained in free-texts. We proposed a systematic methodology for learning from chronological events available in clinical notes. The proposed methodological {\it path signature} framework creates a non-parametric hierarchical representation of sequential events of any type and can be used as features for downstream statistical learning tasks. The methodology was developed and externally validated using the largest in the UK secondary care mental health EHR data on a specific task of predicting survival risk of patients diagnosed with Alzheimer's disease. The signature-based model was compared to a common survival random forest model. Our results showed a 15.4$\%$ increase of risk prediction AUC at the time point of 20 months after the first admission to a specialist memory clinic and the signature method outperformed the baseline mixed-effects model by 13.2 $\%$.
A clinical validation of VinDr-CXR, an AI system for detecting abnormal chest radiographs
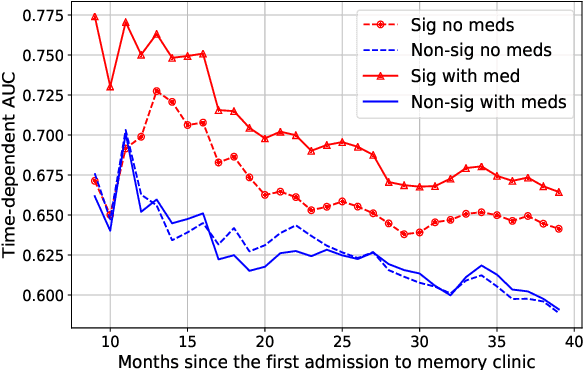
Apr 07, 2021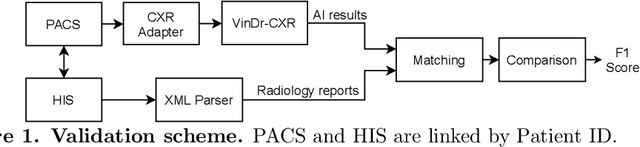

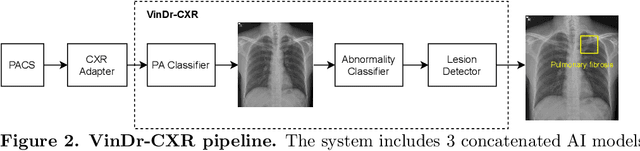

Computer-Aided Diagnosis (CAD) systems for chest radiographs using artificial intelligence (AI) have recently shown a great potential as a second opinion for radiologists. The performances of such systems, however, were mostly evaluated on a fixed dataset in a retrospective manner and, thus, far from the real performances in clinical practice. In this work, we demonstrate a mechanism for validating an AI-based system for detecting abnormalities on X-ray scans, VinDr-CXR, at the Phu Tho General Hospital - a provincial hospital in the North of Vietnam. The AI system was directly integrated into the Picture Archiving and Communication System (PACS) of the hospital after being trained on a fixed annotated dataset from other sources. The performance of the system was prospectively measured by matching and comparing the AI results with the radiology reports of 6,285 chest X-ray examinations extracted from the Hospital Information System (HIS) over the last two months of 2020. The normal/abnormal status of a radiology report was determined by a set of rules and served as the ground truth. Our system achieves an F1 score - the harmonic average of the recall and the precision - of 0.653 (95% CI 0.635, 0.671) for detecting any abnormalities on chest X-rays. Despite a significant drop from the in-lab performance, this result establishes a high level of confidence in applying such a system in real-life situations.
Inferring Graph Signal Translations as Invariant Transformations for Classification Tasks
Feb 18, 2021


The field of Graph Signal Processing (GSP) has proposed tools to generalize harmonic analysis to complex domains represented through graphs. Among these tools are translations, which are required to define many others. Most works propose to define translations using solely the graph structure (i.e. edges). Such a problem is ill-posed in general as a graph conveys information about neighborhood but not about directions. In this paper, we propose to infer translations as edge-constrained operations that make a supervised classification problem invariant using a deep learning framework. As such, our methodology uses both the graph structure and labeled signals to infer translations. We perform experiments with regular 2D images and abstract hyperlink networks to show the effectiveness of the proposed methodology in inferring meaningful translations for signals supported on graphs.
Meta-Learning an Inference Algorithm for Probabilistic Programs
Mar 01, 2021
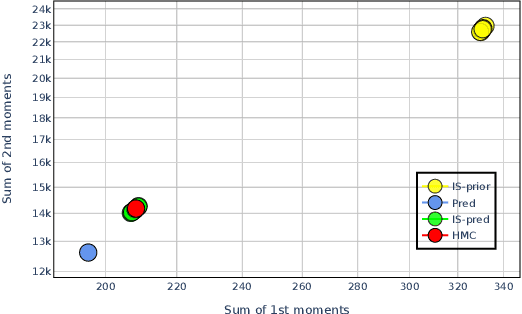
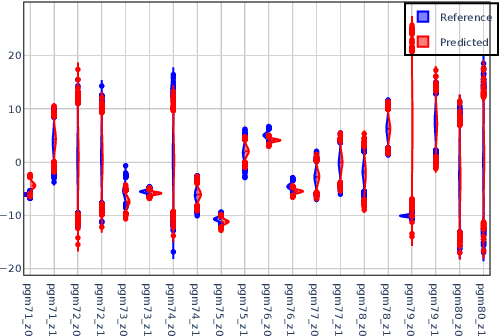
We present a meta-algorithm for learning a posterior-inference algorithm for restricted probabilistic programs. Our meta-algorithm takes a training set of probabilistic programs that describe models with observations, and attempts to learn an efficient method for inferring the posterior of a similar program. A key feature of our approach is the use of what we call a white-box inference algorithm that extracts information directly from model descriptions themselves, given as programs in a probabilistic programming language. Concretely, our white-box inference algorithm is equipped with multiple neural networks, one for each type of atomic command in the language, and computes an approximate posterior of a given probabilistic program by analysing individual atomic commands in the program using these networks. The parameters of these networks are then learnt from a training set by our meta-algorithm. Our empirical evaluation for six model classes shows the promise of our approach.