 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DIVERSE: bayesian Data IntegratiVE learning for precise drug ResponSE prediction
Mar 31, 2021
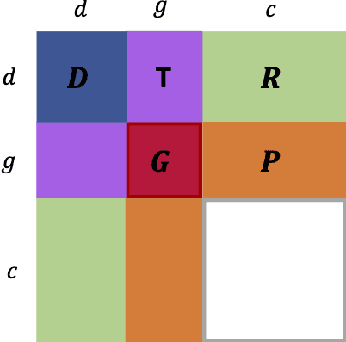
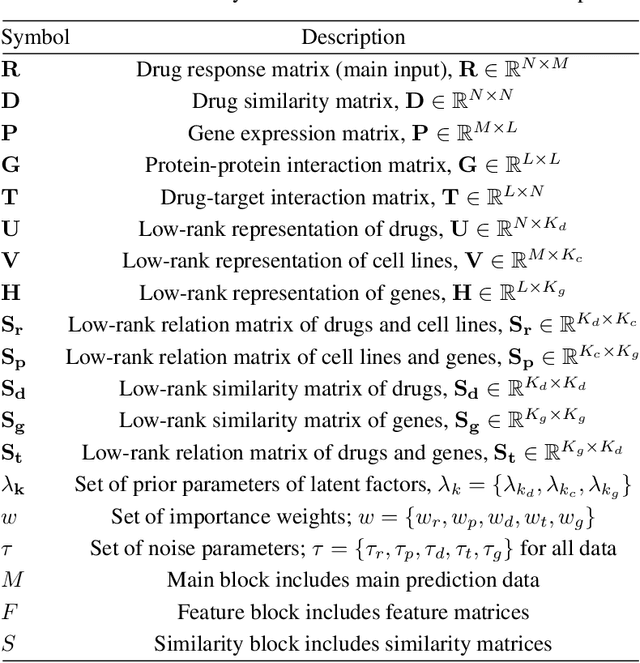
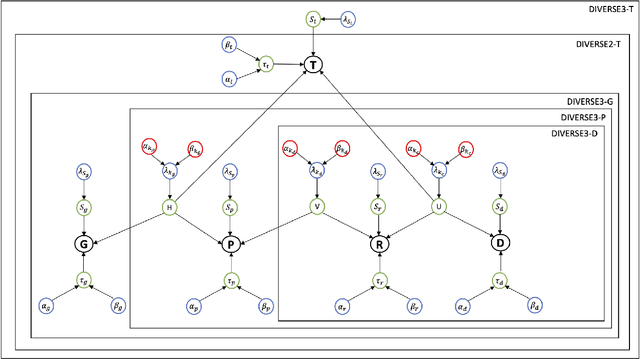
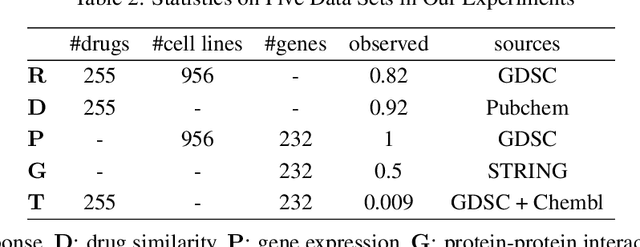
Detecting predictive biomarkers from multi-omics data is important for precision medicine, to improve diagnostics of complex diseases and for better treatments. This needs substantial experimental efforts that are made difficult by the heterogeneity of cell lines and huge cost. An effective solution is to build a computational model over the diverse omics data, including genomic, molecular, and environmental information. However, choosing informative and reliable data sources from among the different types of data is a challenging problem. We propose DIVERSE, a framework of Bayesian importance-weighted tri- and bi-matrix factorization(DIVERSE3 or DIVERSE2) to predict drug responses from data of cell lines, drugs, and gene interactions. DIVERSE integrates the data sources systematically, in a step-wise manner, examining the importance of each added data set in turn. More specifically, we sequentially integrate five different data sets, which have not all been combined in earlier bioinformatic methods for predicting drug responses. Empirical experiments show that DIVERSE clearly outperformed five other methods including three state-of-the-art approaches, under cross-validation, particularly in out-of-matrix prediction, which is closer to the setting of real use cases and more challenging than simpler in-matrix prediction. Additionally, case studies for discovering new drugs further confirmed the performance advantage of DIVERSE.
Human Perception Modeling for Automatic Natural Image Matting
Mar 31, 2021
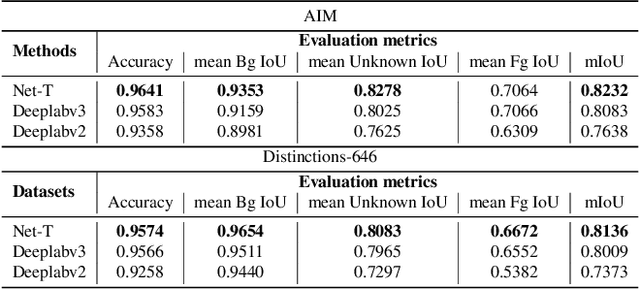
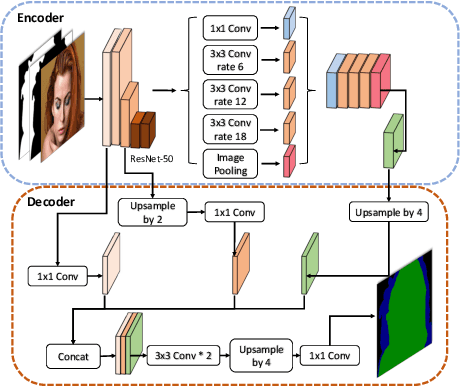

Natural image matting aims to precisely separate foreground objects from background using alpha matte. Fully automatic natural image matting without external annotation is quite challenging. Well-performed matting methods usually require accurate handcrafted trimap as extra input, which is labor-intensive and time-consuming, while the performance of automatic trimap generation method of dilating foreground segmentation fluctuates with segmentation quality. In this paper, we argue that how to handle trade-off of additional information input is a major issue in automatic matting, which we decompose into two subtasks: trimap and alpha estimation. By leveraging easily-accessible coarse annotations and modeling alpha matte handmade process of capturing rough foreground/background/transition boundary and carving delicate details in transition region, we propose an intuitively-designed trimap-free two-stage matting approach without additional annotations, e.g. trimap and background image. Specifically, given an image and its coarse foreground segmentation, Trimap Generation Network estimates probabilities of foreground, unknown, and background regions to guide alpha feature flow of our proposed Non-Local Matting network, which is equipped with trimap-guided global aggregation attention block. Experimental results show that our matting algorithm has competitive performance with current state-of-the-art methods in both trimap-free and trimap-needed aspects.
Low-Rank Isomap Algorithm
Mar 06, 2021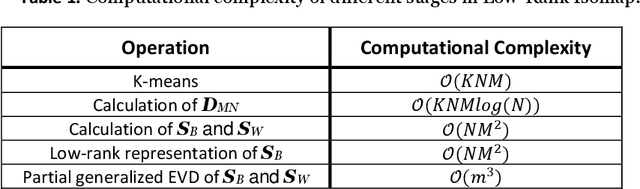


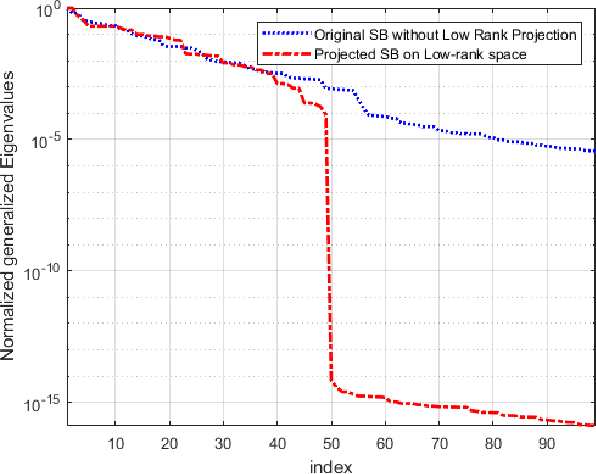
The Isomap is a well-known nonlinear dimensionality reduction method that highly suffers from computational complexity. Its computational complexity mainly arises from two stages; a) embedding a full graph on the data in the ambient space, and b) a complete eigenvalue decomposition. Although the reduction of the computational complexity of the graphing stage has been investigated, yet the eigenvalue decomposition stage remains a bottleneck in the problem. In this paper, we propose the Low-Rank Isomap algorithm by introducing a projection operator on the embedded graph from the ambient space to a low-rank latent space to facilitate applying the partial eigenvalue decomposition. This approach leads to reducing the complexity of Isomap to a linear order while preserving the structural information during the dimensionality reduction process. The superiority of the Low-Rank Isomap algorithm compared to some state-of-art algorithms is experimentally verified on facial image clustering in terms of speed and accuracy.
Variable Name Recovery in Decompiled Binary Code using Constrained Masked Language Modeling
Mar 23, 2021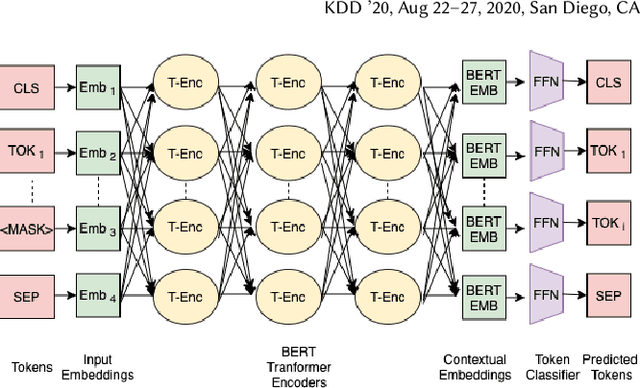
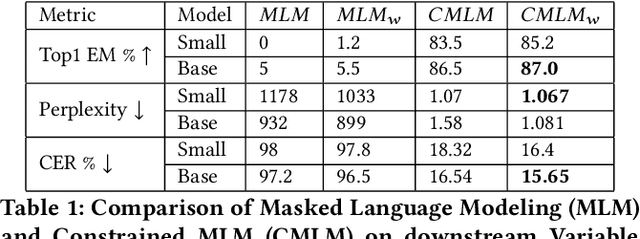
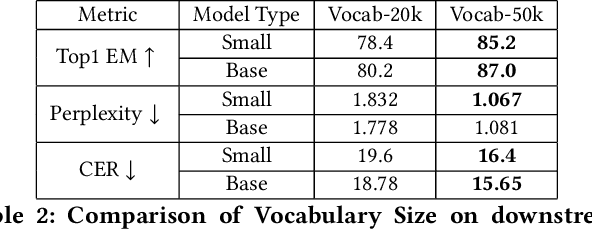
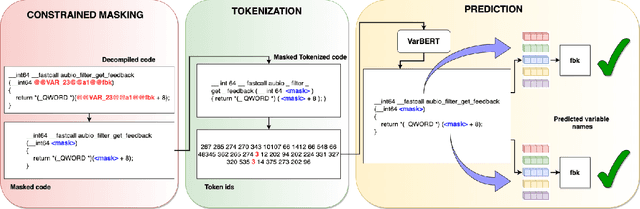
Decompilation is the procedure of transforming binary programs into a high-level representation, such as source code, for human analysts to examine. While modern decompilers can reconstruct and recover much information that is discarded during compilation, inferring variable names is still extremely difficult. Inspired by recent advances in natural language processing, we propose a novel solution to infer variable names in decompiled code based on Masked Language Modeling, Byte-Pair Encoding, and neural architectures such as Transformers and BERT. Our solution takes \textit{raw} decompiler output, the less semantically meaningful code, as input, and enriches it using our proposed \textit{finetuning} technique, Constrained Masked Language Modeling. Using Constrained Masked Language Modeling introduces the challenge of predicting the number of masked tokens for the original variable name. We address this \textit{count of token prediction} challenge with our post-processing algorithm. Compared to the state-of-the-art approaches, our trained VarBERT model is simpler and of much better performance. We evaluated our model on an existing large-scale data set with 164,632 binaries and showed that it can predict variable names identical to the ones present in the original source code up to 84.15\% of the time.
Driver Behavior Extraction from Videos in Naturalistic Driving Datasets with 3D ConvNets
Nov 30, 2020
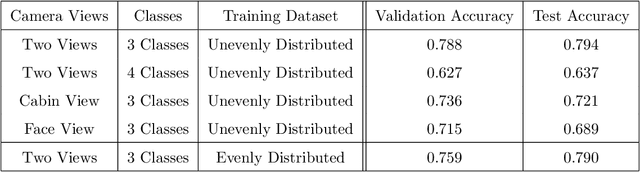

Naturalistic driving data (NDD) is an important source of information to understand crash causation and human factors and to further develop crash avoidance countermeasures. Videos recorded while driving are often included in such datasets. While there is often a large amount of video data in NDD, only a small portion of them can be annotated by human coders and used for research, which underuses all video data. In this paper, we explored a computer vision method to automatically extract the information we need from videos. More specifically, we developed a 3D ConvNet algorithm to automatically extract cell-phone-related behaviors from videos. The experiments show that our method can extract chunks from videos, most of which (~79%) contain the automatically labeled cell phone behaviors. In conjunction with human review of the extracted chunks, this approach can find cell-phone-related driver behaviors much more efficiently than simply viewing video.
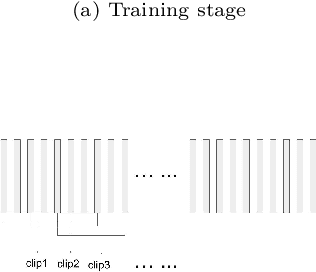
PFRL: Pose-Free Reinforcement Learning for 6D Pose Estimation
Feb 24, 2021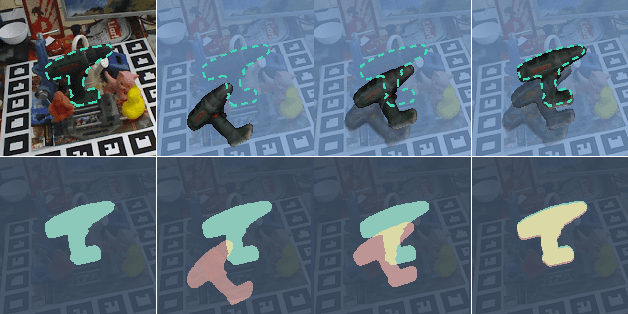
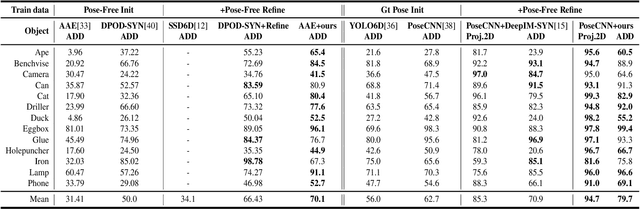
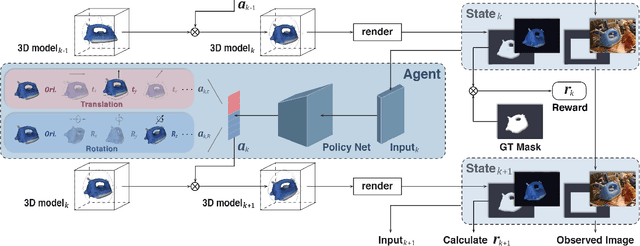
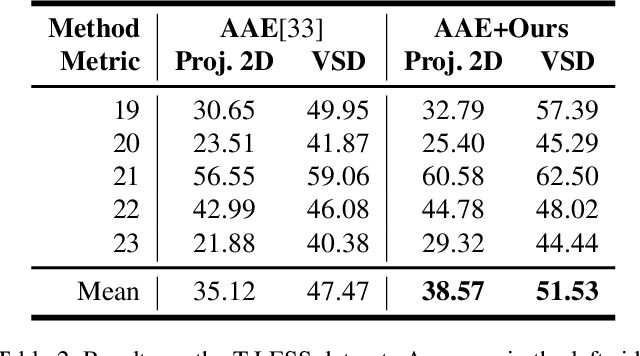
6D pose estimation from a single RGB image is a challenging and vital task in computer vision. The current mainstream deep model methods resort to 2D images annotated with real-world ground-truth 6D object poses, whose collection is fairly cumbersome and expensive, even unavailable in many cases. In this work, to get rid of the burden of 6D annotations, we formulate the 6D pose refinement as a Markov Decision Process and impose on the reinforcement learning approach with only 2D image annotations as weakly-supervised 6D pose information, via a delicate reward definition and a composite reinforced optimization method for efficient and effective policy training. Experiments on LINEMOD and T-LESS datasets demonstrate that our Pose-Free approach is able to achieve state-of-the-art performance compared with the methods without using real-world ground-truth 6D pose labels.
XOR QA: Cross-lingual Open-Retrieval Question Answering
Oct 24, 2020
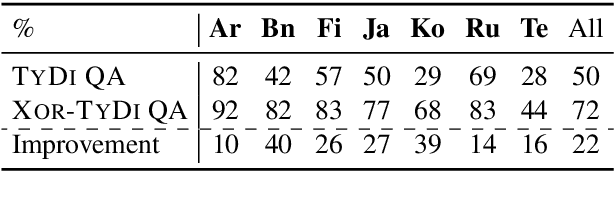
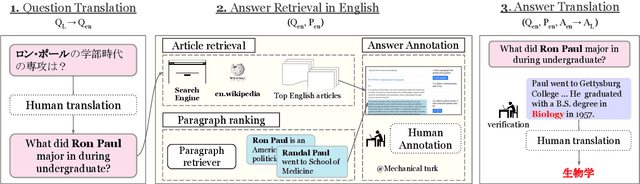
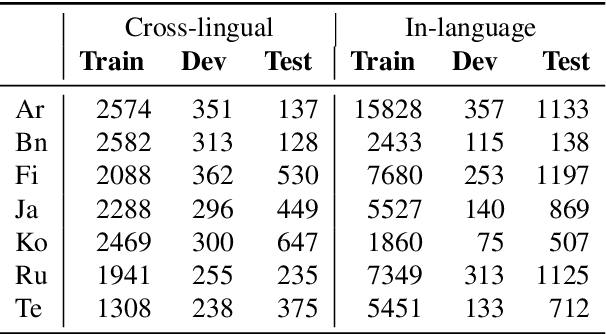
Multilingual question answering tasks typically assume answers exist in the same language as the question. Yet in practice, many languages face both information scarcity---where languages have few reference articles---and information asymmetry---where questions reference concepts from other cultures. This work extends open-retrieval question answering to a cross-lingual setting enabling questions from one language to be answered via answer content from another language. We construct a large-scale dataset built on questions from TyDi QA lacking same-language answers. Our task formulation, called Cross-lingual Open Retrieval Question Answering (XOR QA), includes 40k information-seeking questions from across 7 diverse non-English languages. Based on this dataset, we introduce three new tasks that involve cross-lingual document retrieval using multi-lingual and English resources. We establish baselines with state-of-the-art machine translation systems and cross-lingual pretrained models. Experimental results suggest that XOR QA is a challenging task that will facilitate the development of novel techniques for multilingual question answering. Our data and code are available at https://nlp.cs.washington.edu/xorqa.
Domain adaptation based self-correction model for COVID-19 infection segmentation in CT images
Apr 20, 2021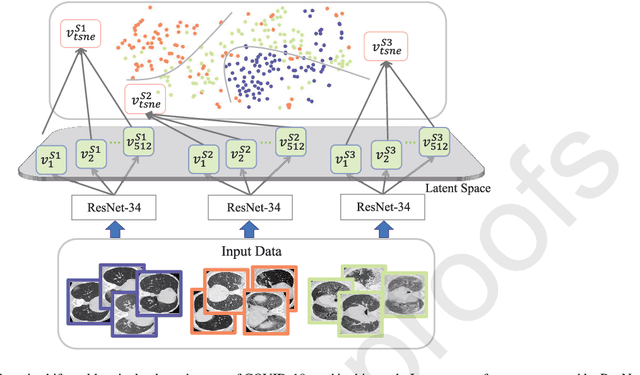
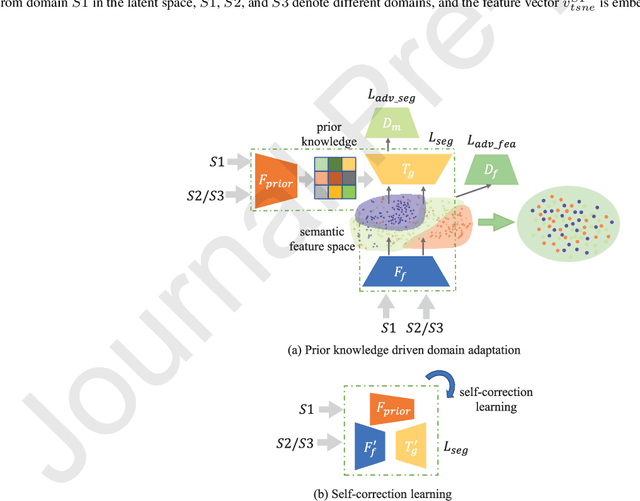
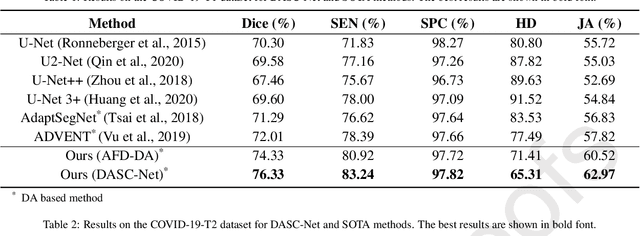
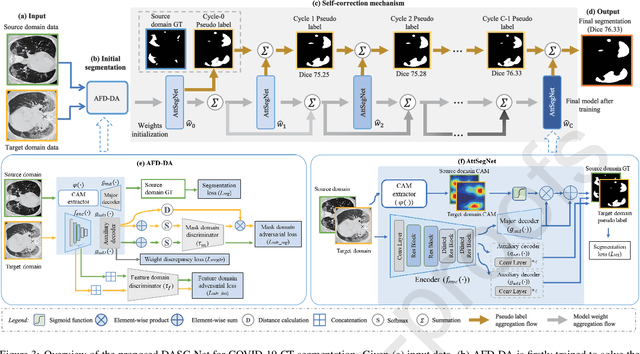
The capability of generalization to unseen domains is crucial for deep learning models when considering real-world scenarios. However, current available medical image datasets, such as those for COVID-19 CT images, have large variations of infections and domain shift problems. To address this issue, we propose a prior knowledge driven domain adaptation and a dual-domain enhanced self-correction learning scheme. Based on the novel learning schemes, a domain adaptation based self-correction model (DASC-Net) is proposed for COVID-19 infection segmentation on CT images. DASC-Net consists of a novel attention and feature domain enhanced domain adaptation model (AFD-DA) to solve the domain shifts and a self-correction learning process to refine segmentation results. The innovations in AFD-DA include an image-level activation feature extractor with attention to lung abnormalities and a multi-level discrimination module for hierarchical feature domain alignment. The proposed self-correction learning process adaptively aggregates the learned model and corresponding pseudo labels for the propagation of aligned source and target domain information to alleviate the overfitting to noises caused by pseudo labels. Extensive experiments over three publicly available COVID-19 CT datasets demonstrate that DASC-Net consistently outperforms state-of-the-art segmentation, domain shift, and coronavirus infection segmentation methods. Ablation analysis further shows the effectiveness of the major components in our model. The DASC-Net enriches the theory of domain adaptation and self-correction learning in medical imaging and can be generalized to multi-site COVID-19 infection segmentation on CT images for clinical deployment.
Learning with Memory-based Virtual Classes for Deep Metric Learning
Mar 31, 2021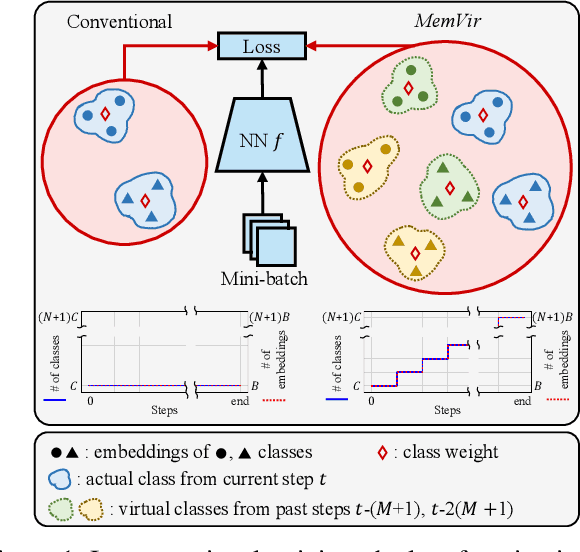
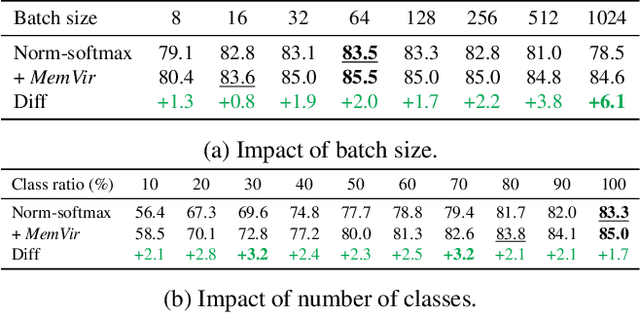
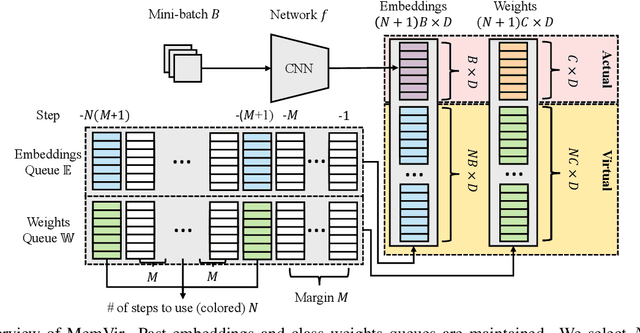
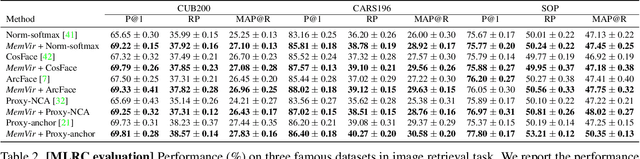
The core of deep metric learning (DML) involves learning visual similarities in high-dimensional embedding space. One of the main challenges is to generalize from seen classes of training data to unseen classes of test data. Recent works have focused on exploiting past embeddings to increase the number of instances for the seen classes. Such methods achieve performance improvement via augmentation, while the strong focus on seen classes still remains. This can be undesirable for DML, where training and test data exhibit entirely different classes. In this work, we present a novel training strategy for DML called MemVir. Unlike previous works, MemVir memorizes both embedding features and class weights to utilize them as additional virtual classes. The exploitation of virtual classes not only utilizes augmented information for training but also alleviates a strong focus on seen classes for better generalization. Moreover, we embed the idea of curriculum learning by slowly adding virtual classes for a gradual increase in learning difficulty, which improves the learning stability as well as the final performance. MemVir can be easily applied to many existing loss functions without any modification. Extensive experimental results on famous benchmarks demonstrate the superiority of MemVir over state-of-the-art competitors. Code of MemVir will be publicly available.
Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration
Mar 31, 2021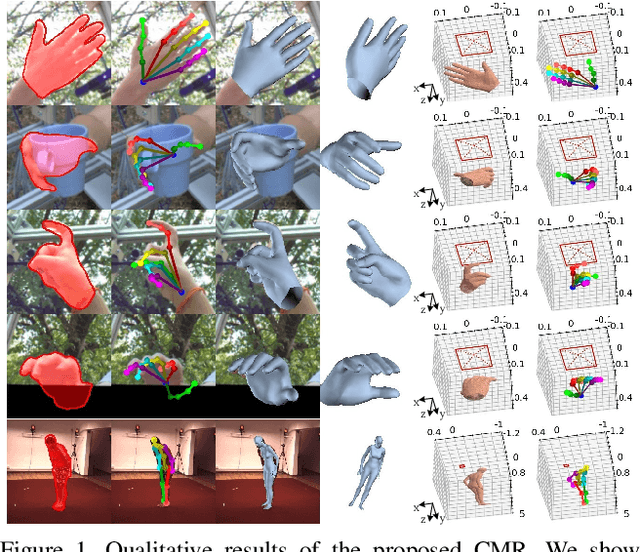
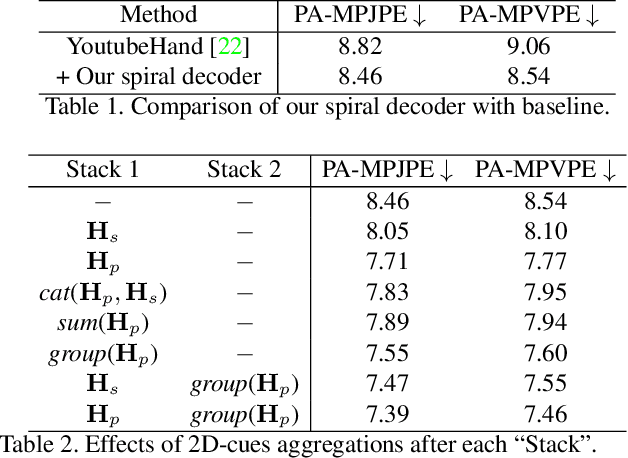
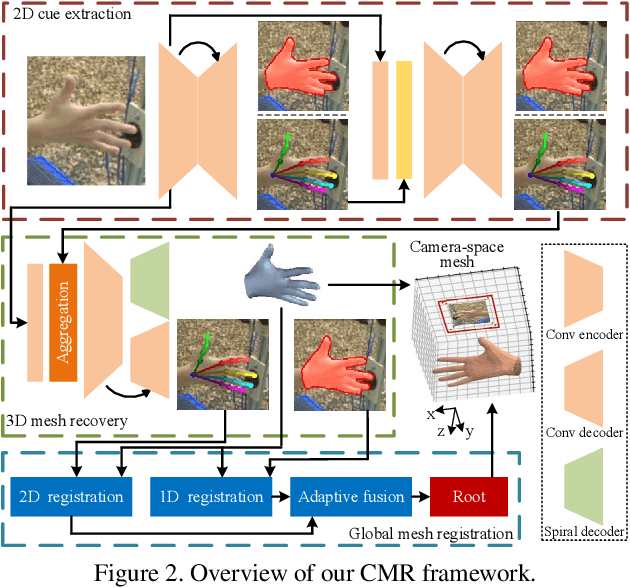
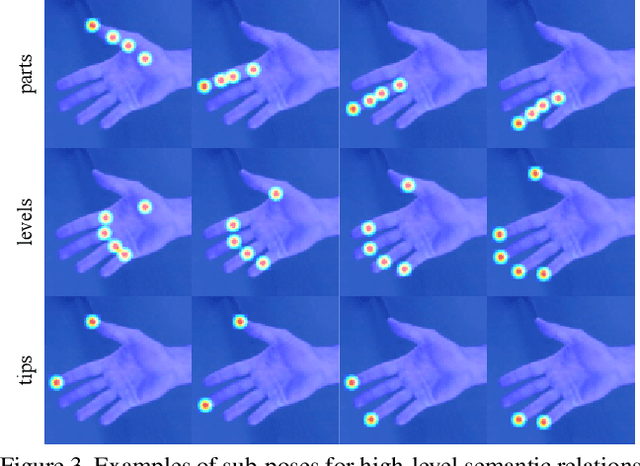
Recent years have witnessed significant progress in 3D hand mesh recovery. Nevertheless, because of the intrinsic 2D-to-3D ambiguity, recovering camera-space 3D information from a single RGB image remains challenging. To tackle this problem, we divide camera-space mesh recovery into two sub-tasks, i.e., root-relative mesh recovery and root recovery. First, joint landmarks and silhouette are extracted from a single input image to provide 2D cues for the 3D tasks. In the root-relative mesh recovery task, we exploit semantic relations among joints to generate a 3D mesh from the extracted 2D cues. Such generated 3D mesh coordinates are expressed relative to a root position, i.e., wrist of the hand. In the root recovery task, the root position is registered to the camera space by aligning the generated 3D mesh back to 2D cues, thereby completing cameraspace 3D mesh recovery. Our pipeline is novel in that (1) it explicitly makes use of known semantic relations among joints and (2) it exploits 1D projections of the silhouette and mesh to achieve robust registration. Extensive experiments on popular datasets such as FreiHAND, RHD, and Human3.6M demonstrate that our approach achieves stateof-the-art performance on both root-relative mesh recovery and root recovery. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.