 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting Solution Summaries to Integer Linear Programs under Imperfect Information with Machine Learning
Sep 12, 2018
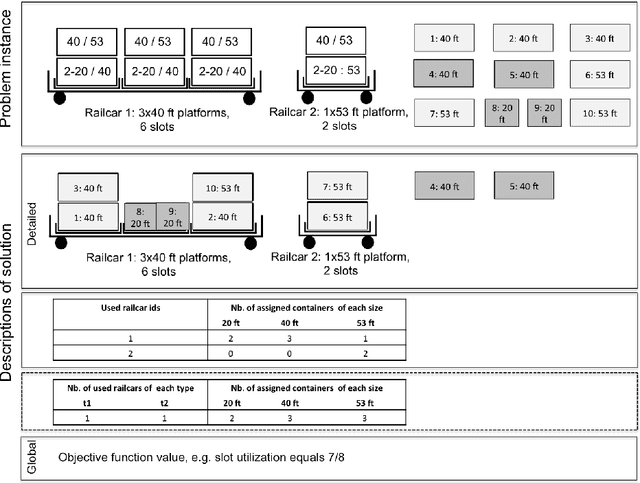
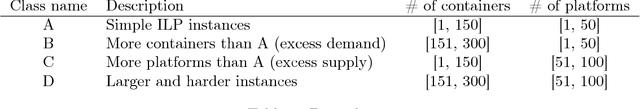
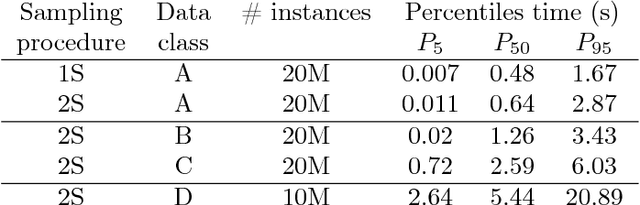
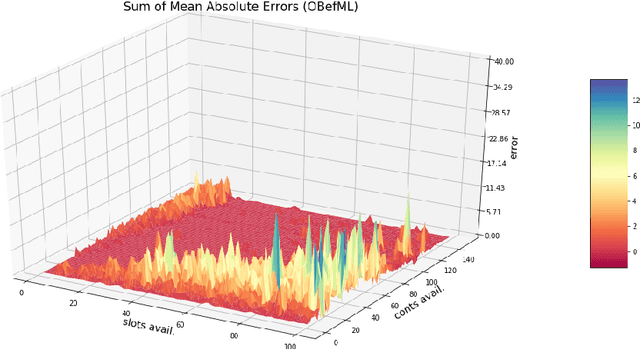
The paper provides a methodological contribution at the intersection of machine learning and operations research. Namely, we propose a methodology to quickly predict solution summaries (i.e., solution descriptions at a given level of detail) to discrete stochastic optimization problems. We approximate the solutions based on supervised learning and the training dataset consists of a large number of deterministic problems that have been solved independently and offline. Uncertainty regarding a missing subset of the inputs is addressed through sampling and aggregation methods. Our motivating application concerns booking decisions of intermodal containers on double-stack trains. Under perfect information, this is the so-called load planning problem and it can be formulated by means of integer linear programming. However, the formulation cannot be used for the application at hand because of the restricted computational budget and unknown container weights. The results show that standard deep learning algorithms allow one to predict descriptions of solutions with high accuracy in very short time (milliseconds or less).
Learn-to-Race: A Multimodal Control Environment for Autonomous Racing
Mar 31, 2021
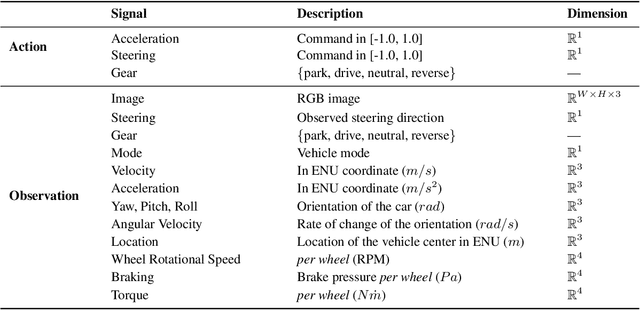
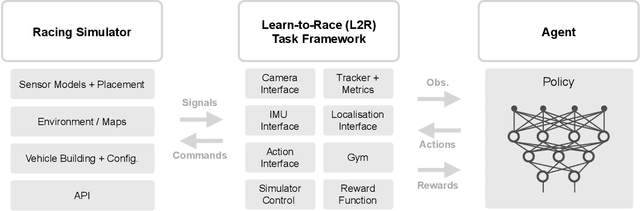

Existing research on autonomous driving primarily focuses on urban driving, which is insufficient for characterising the complex driving behaviour underlying high-speed racing. At the same time, existing racing simulation frameworks struggle in capturing realism, with respect to visual rendering, vehicular dynamics, and task objectives, inhibiting the transfer of learning agents to real-world contexts. We introduce a new environment, where agents Learn-to-Race (L2R) in simulated competition-style racing, using multimodal information--from virtual cameras to a comprehensive array of inertial measurement sensors. Our environment, which includes a simulator and an interfacing training framework, accurately models vehicle dynamics and racing conditions. In this paper, we release the Arrival simulator for autonomous racing. Next, we propose the L2R task with challenging metrics, inspired by learning-to-drive challenges, Formula-style racing, and multimodal trajectory prediction for autonomous driving. Additionally, we provide the L2R framework suite, facilitating simulated racing on high-precision models of real-world tracks, such as the famed Thruxton Circuit and the Las Vegas Motor Speedway. Finally, we provide an official L2R task dataset of expert demonstrations, as well as a series of baseline experiments and reference implementations. We make all code available: https://github.com/hermgerm29/learn-to-race
Two-Level K-FAC Preconditioning for Deep Learning
Nov 10, 2020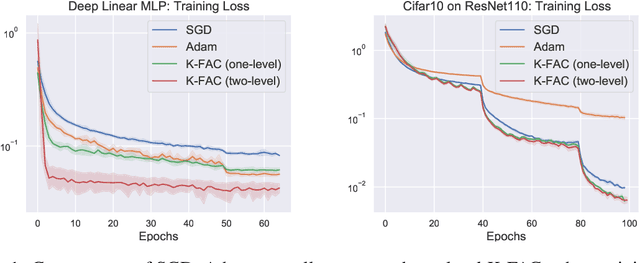
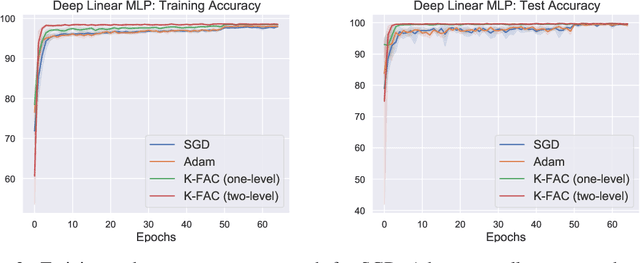
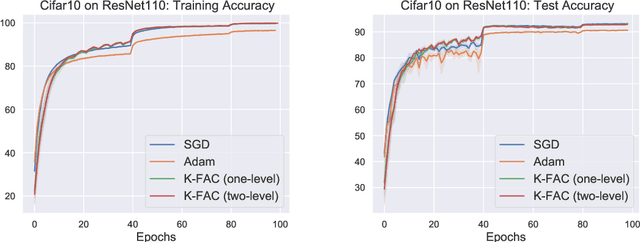
In the context of deep learning, many optimization methods use gradient covariance information in order to accelerate the convergence of Stochastic Gradient Descent. In particular, starting with Adagrad, a seemingly endless line of research advocates the use of diagonal approximations of the so-called empirical Fisher matrix in stochastic gradient-based algorithms, with the most prominent one arguably being Adam. However, in recent years, several works cast doubt on the theoretical basis of preconditioning with the empirical Fisher matrix, and it has been shown that more sophisticated approximations of the actual Fisher matrix more closely resemble the theoretically well-motivated Natural Gradient Descent. One particularly successful variant of such methods is the so-called K-FAC optimizer, which uses a Kronecker-factored block-diagonal Fisher approximation as preconditioner. In this work, drawing inspiration from two-level domain decomposition methods used as preconditioners in the field of scientific computing, we extend K-FAC by enriching it with off-diagonal (i.e. global) curvature information in a computationally efficient way. We achieve this by adding a coarse-space correction term to the preconditioner, which captures the global Fisher information matrix at a coarser scale. We present a small set of experimental results suggesting improved convergence behaviour of our proposed method.
SST-GNN: Simplified Spatio-temporal Traffic forecasting model using Graph Neural Network
Mar 31, 2021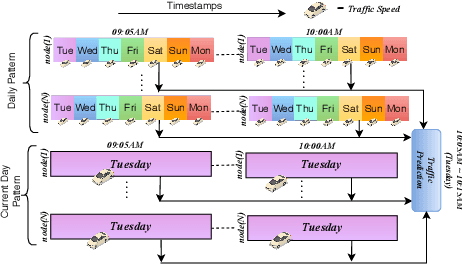
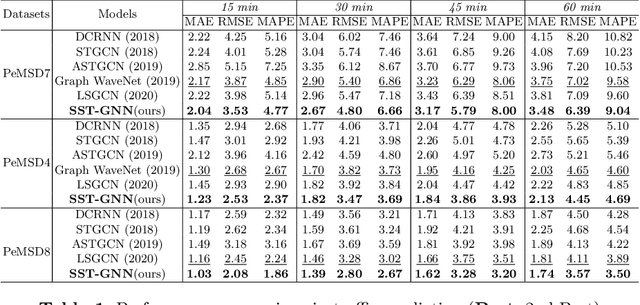
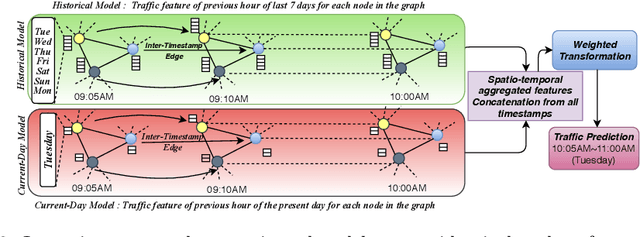

To capture spatial relationships and temporal dynamics in traffic data, spatio-temporal models for traffic forecasting have drawn significant attention in recent years. Most of the recent works employed graph neural networks(GNN) with multiple layers to capture the spatial dependency. However, road junctions with different hop-distance can carry distinct traffic information which should be exploited separately but existing multi-layer GNNs are incompetent to discriminate between their impact. Again, to capture the temporal interrelationship, recurrent neural networks are common in state-of-the-art approaches that often fail to capture long-range dependencies. Furthermore, traffic data shows repeated patterns in a daily or weekly period which should be addressed explicitly. To address these limitations, we have designed a Simplified Spatio-temporal Traffic forecasting GNN(SST-GNN) that effectively encodes the spatial dependency by separately aggregating different neighborhood representations rather than with multiple layers and capture the temporal dependency with a simple yet effective weighted spatio-temporal aggregation mechanism. We capture the periodic traffic patterns by using a novel position encoding scheme with historical and current data in two different models. With extensive experimental analysis, we have shown that our model has significantly outperformed the state-of-the-art models on three real-world traffic datasets from the Performance Measurement System (PeMS).
Back-tracing Representative Points for Voting-based 3D Object Detection in Point Clouds
Apr 14, 2021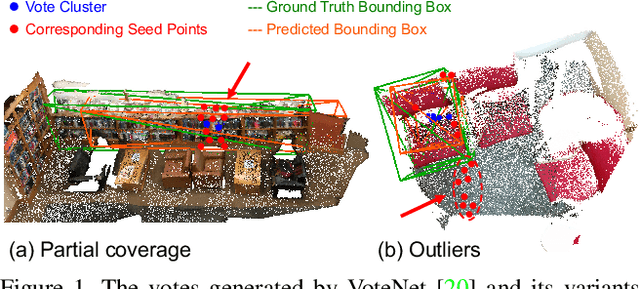
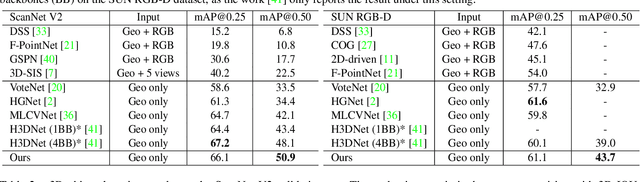
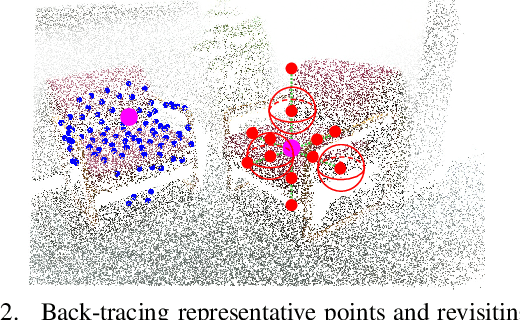

3D object detection in point clouds is a challenging vision task that benefits various applications for understanding the 3D visual world. Lots of recent research focuses on how to exploit end-to-end trainable Hough voting for generating object proposals. However, the current voting strategy can only receive partial votes from the surfaces of potential objects together with severe outlier votes from the cluttered backgrounds, which hampers full utilization of the information from the input point clouds. Inspired by the back-tracing strategy in the conventional Hough voting methods, in this work, we introduce a new 3D object detection method, named as Back-tracing Representative Points Network (BRNet), which generatively back-traces the representative points from the vote centers and also revisits complementary seed points around these generated points, so as to better capture the fine local structural features surrounding the potential objects from the raw point clouds. Therefore, this bottom-up and then top-down strategy in our BRNet enforces mutual consistency between the predicted vote centers and the raw surface points and thus achieves more reliable and flexible object localization and class prediction results. Our BRNet is simple but effective, which significantly outperforms the state-of-the-art methods on two large-scale point cloud datasets, ScanNet V2 (+7.5% in terms of mAP@0.50) and SUN RGB-D (+4.7% in terms of mAP@0.50), while it is still lightweight and efficient. Code will be available at https://github.com/cheng052/BRNet.
MONAH: Multi-Modal Narratives for Humans to analyze conversations
Jan 18, 2021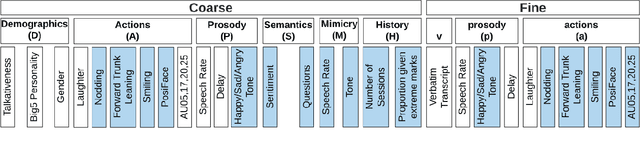
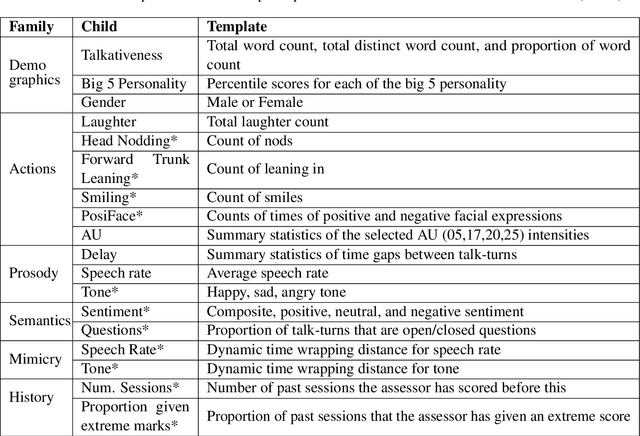
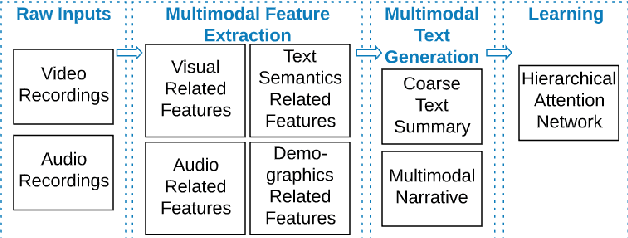
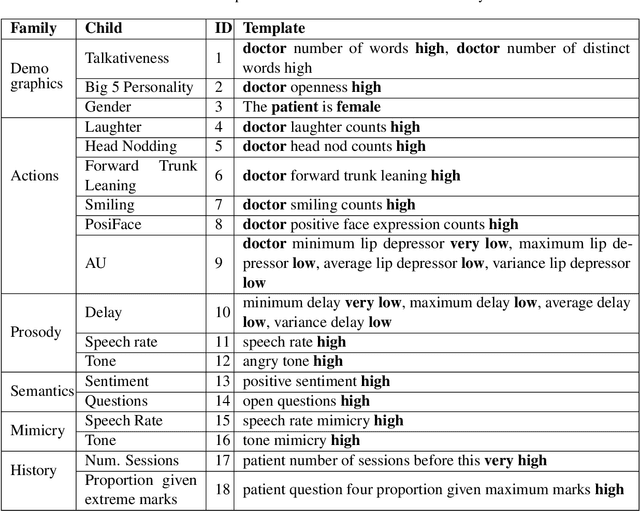
In conversational analyses, humans manually weave multimodal information into the transcripts, which is significantly time-consuming. We introduce a system that automatically expands the verbatim transcripts of video-recorded conversations using multimodal data streams. This system uses a set of preprocessing rules to weave multimodal annotations into the verbatim transcripts and promote interpretability. Our feature engineering contributions are two-fold: firstly, we identify the range of multimodal features relevant to detect rapport-building; secondly, we expand the range of multimodal annotations and show that the expansion leads to statistically significant improvements in detecting rapport-building.
Semi-Supervised Information-Maximization Clustering
May 01, 2013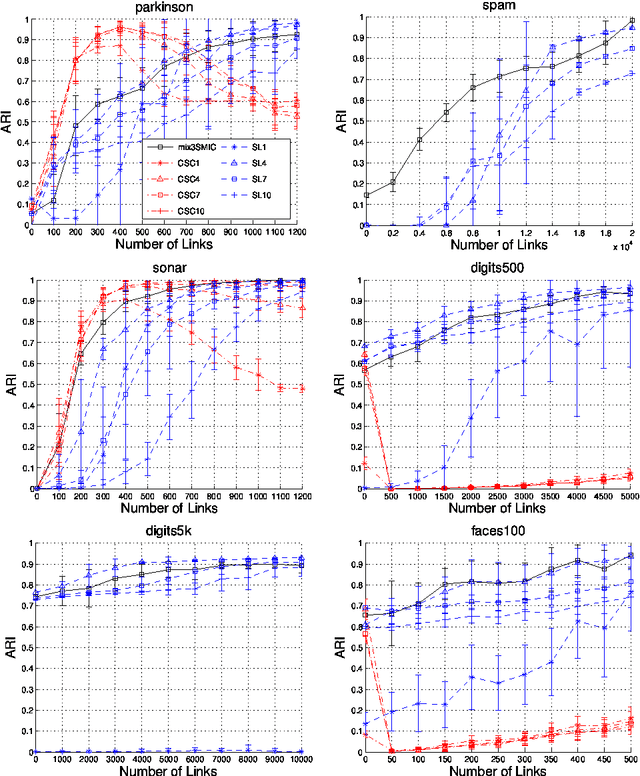
Semi-supervised clustering aims to introduce prior knowledge in the decision process of a clustering algorithm. In this paper, we propose a novel semi-supervised clustering algorithm based on the information-maximization principle. The proposed method is an extension of a previous unsupervised information-maximization clustering algorithm based on squared-loss mutual information to effectively incorporate must-links and cannot-links. The proposed method is computationally efficient because the clustering solution can be obtained analytically via eigendecomposition. Furthermore, the proposed method allows systematic optimization of tuning parameters such as the kernel width, given the degree of belief in the must-links and cannot-links. The usefulness of the proposed method is demonstrated through experiments.
Word2vec Skip-gram Dimensionality Selection via Sequential Normalized Maximum Likelihood
Aug 24, 2020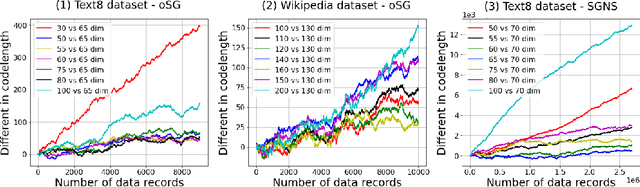

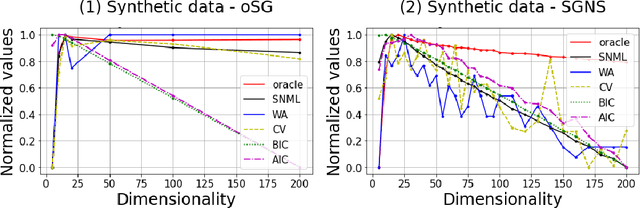
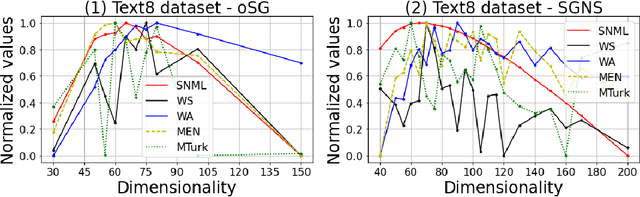
In this paper, we propose a novel information criteria-based approach to select the dimensionality of the word2vec Skip-gram (SG). From the perspective of the probability theory, SG is considered as an implicit probability distribution estimation under the assumption that there exists a true contextual distribution among words. Therefore, we apply information criteria with the aim of selecting the best dimensionality so that the corresponding model can be as close as possible to the true distribution. We examine the following information criteria for the dimensionality selection problem: the Akaike Information Criterion, Bayesian Information Criterion, and Sequential Normalized Maximum Likelihood (SNML) criterion. SNML is the total codelength required for the sequential encoding of a data sequence on the basis of the minimum description length. The proposed approach is applied to both the original SG model and the SG Negative Sampling model to clarify the idea of using information criteria. Additionally, as the original SNML suffers from computational disadvantages, we introduce novel heuristics for its efficient computation. Moreover, we empirically demonstrate that SNML outperforms both BIC and AIC. In comparison with other evaluation methods for word embedding, the dimensionality selected by SNML is significantly closer to the optimal dimensionality obtained by word analogy or word similarity tasks.
Target Guided Emotion Aware Chat Machine
Nov 15, 2020

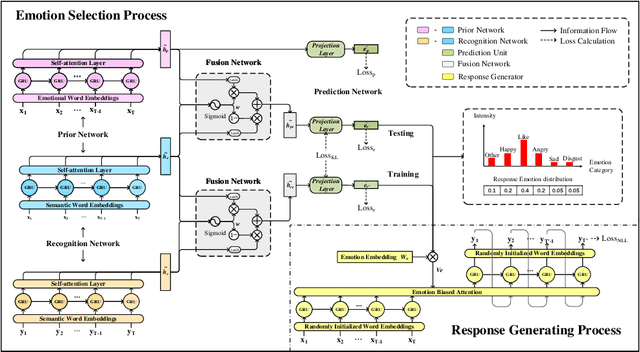
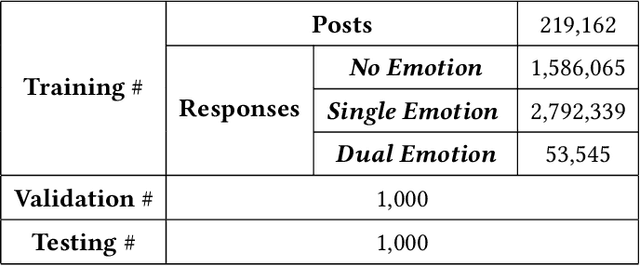
The consistency of a response to a given post at semantic-level and emotional-level is essential for a dialogue system to deliver human-like interactions. However, this challenge is not well addressed in the literature, since most of the approaches neglect the emotional information conveyed by a post while generating responses. This article addresses this problem by proposing a unifed end-to-end neural architecture, which is capable of simultaneously encoding the semantics and the emotions in a post and leverage target information for generating more intelligent responses with appropriately expressed emotions. Extensive experiments on real-world data demonstrate that the proposed method outperforms the state-of-the-art methods in terms of both content coherence and emotion appropriateness.
DIVERSE: bayesian Data IntegratiVE learning for precise drug ResponSE prediction
Mar 31, 2021
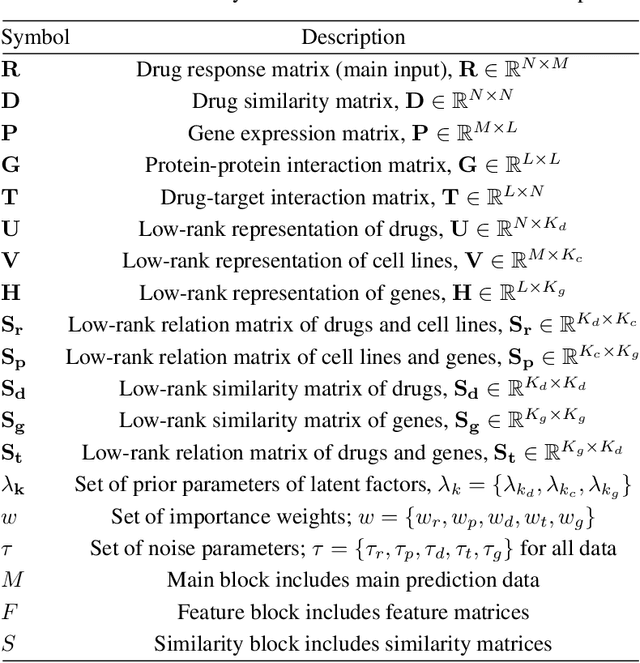
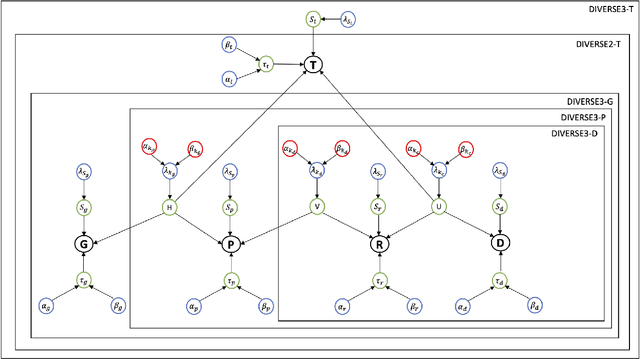
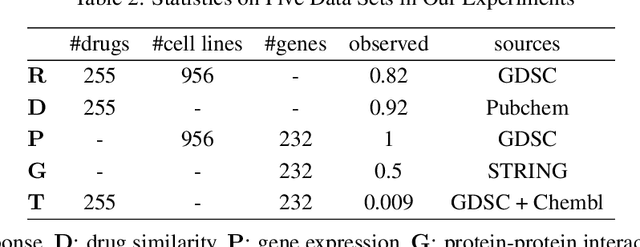
Detecting predictive biomarkers from multi-omics data is important for precision medicine, to improve diagnostics of complex diseases and for better treatments. This needs substantial experimental efforts that are made difficult by the heterogeneity of cell lines and huge cost. An effective solution is to build a computational model over the diverse omics data, including genomic, molecular, and environmental information. However, choosing informative and reliable data sources from among the different types of data is a challenging problem. We propose DIVERSE, a framework of Bayesian importance-weighted tri- and bi-matrix factorization(DIVERSE3 or DIVERSE2) to predict drug responses from data of cell lines, drugs, and gene interactions. DIVERSE integrates the data sources systematically, in a step-wise manner, examining the importance of each added data set in turn. More specifically, we sequentially integrate five different data sets, which have not all been combined in earlier bioinformatic methods for predicting drug responses. Empirical experiments show that DIVERSE clearly outperformed five other methods including three state-of-the-art approaches, under cross-validation, particularly in out-of-matrix prediction, which is closer to the setting of real use cases and more challenging than simpler in-matrix prediction. Additionally, case studies for discovering new drugs further confirmed the performance advantage of DIVERSE.