 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hierarchical Metadata-Aware Document Categorization under Weak Supervision
Oct 26, 2020

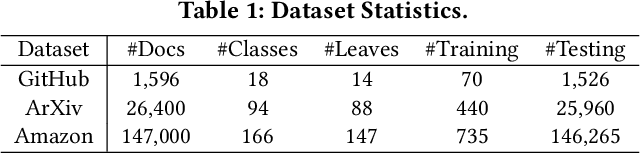
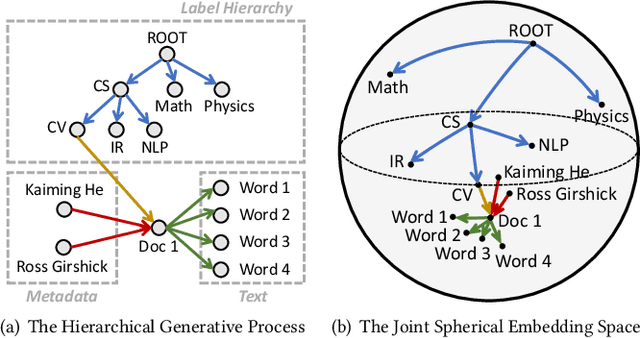
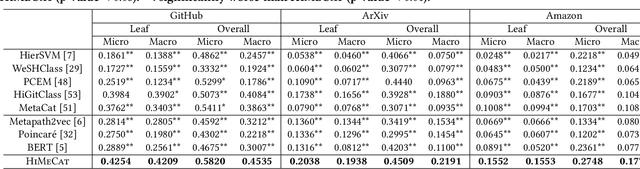
Categorizing documents into a given label hierarchy is intuitively appealing due to the ubiquity of hierarchical topic structures in massive text corpora. Although related studies have achieved satisfying performance in fully supervised hierarchical document classification, they usually require massive human-annotated training data and only utilize text information. However, in many domains, (1) annotations are quite expensive where very few training samples can be acquired; (2) documents are accompanied by metadata information. Hence, this paper studies how to integrate the label hierarchy, metadata, and text signals for document categorization under weak supervision. We develop HiMeCat, an embedding-based generative framework for our task. Specifically, we propose a novel joint representation learning module that allows simultaneous modeling of category dependencies, metadata information and textual semantics, and we introduce a data augmentation module that hierarchically synthesizes training documents to complement the original, small-scale training set. Our experiments demonstrate a consistent improvement of HiMeCat over competitive baselines and validate the contribution of our representation learning and data augmentation modules.
A Simple and Efficient Multi-task Network for 3D Object Detection and Road Understanding
Mar 06, 2021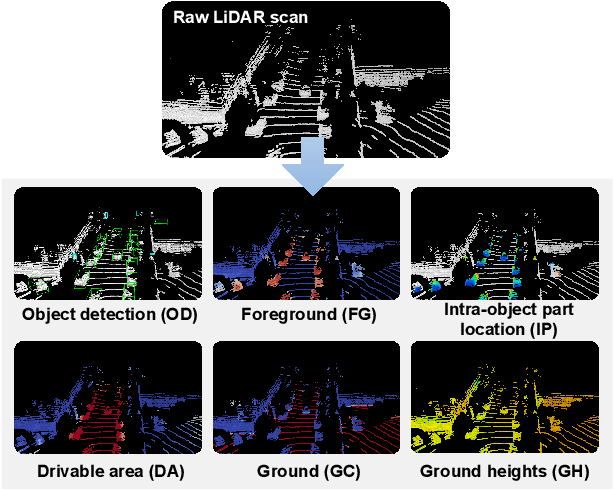
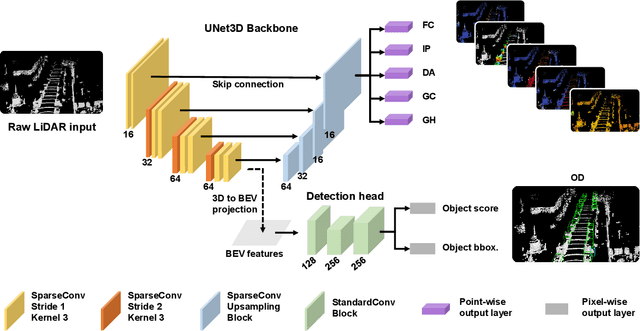
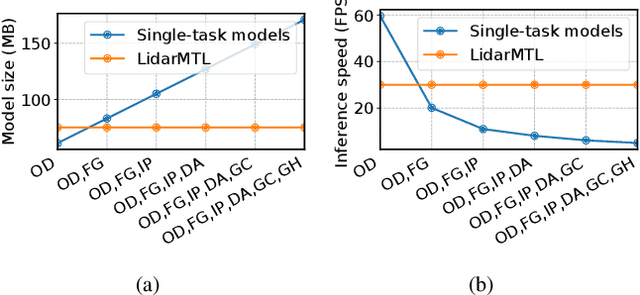
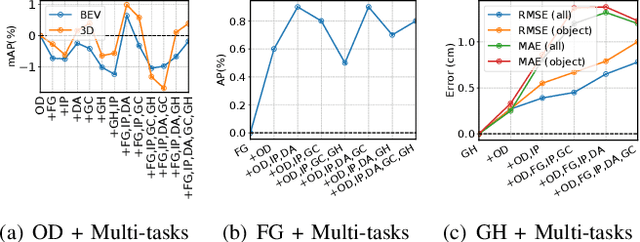
Detecting dynamic objects and predicting static road information such as drivable areas and ground heights are crucial for safe autonomous driving. Previous works studied each perception task separately, and lacked a collective quantitative analysis. In this work, we show that it is possible to perform all perception tasks via a simple and efficient multi-task network. Our proposed network, LidarMTL, takes raw LiDAR point cloud as inputs, and predicts six perception outputs for 3D object detection and road understanding. The network is based on an encoder-decoder architecture with 3D sparse convolution and deconvolution operations. Extensive experiments verify the proposed method with competitive accuracies compared to state-of-the-art object detectors and other task-specific networks. LidarMTL is also leveraged for online localization. Code and pre-trained model have been made available at https://github.com/frankfengdi/LidarMTL.
Focal points and their implications for Möbius Transforms and Dempster-Shafer Theory
Nov 12, 2020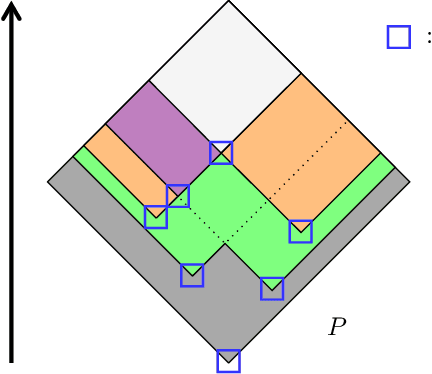
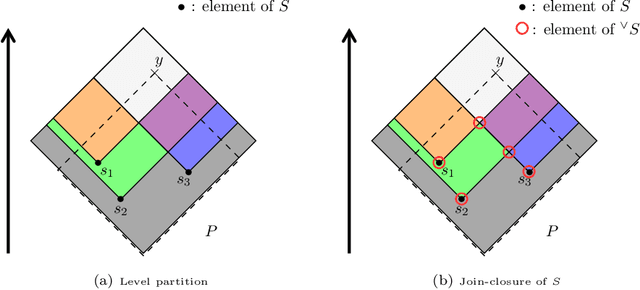
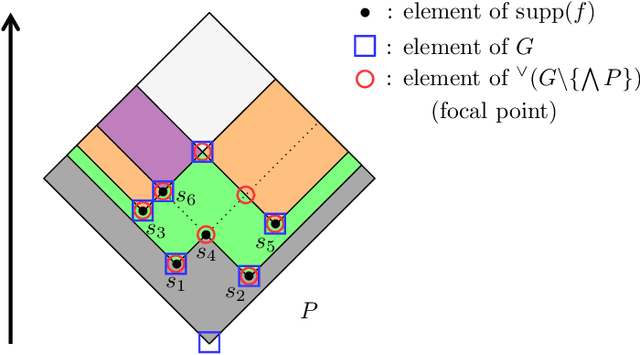
Dempster-Shafer Theory (DST) generalizes Bayesian probability theory, offering useful additional information, but suffers from a much higher computational burden. A lot of work has been done to reduce the time complexity of information fusion with Dempster's rule, which is a pointwise multiplication of two zeta transforms, and optimal general algorithms have been found to get the complete definition of these transforms. Yet, it is shown in this paper that the zeta transform and its inverse, the M\"obius transform, can be exactly simplified, fitting the quantity of information contained in belief functions. Beyond that, this simplification actually works for any function on any partially ordered set. It relies on a new notion that we call focal point and that constitutes the smallest domain on which both the zeta and M\"obius transforms can be defined. We demonstrate the interest of these general results for DST, not only for the reduction in complexity of most transformations between belief representations and their fusion, but also for theoretical purposes. Indeed, we provide a new generalization of the conjunctive decomposition of evidence and formulas uncovering how each decomposition weight is tied to the corresponding mass function.
ELF-VC: Efficient Learned Flexible-Rate Video Coding
Apr 29, 2021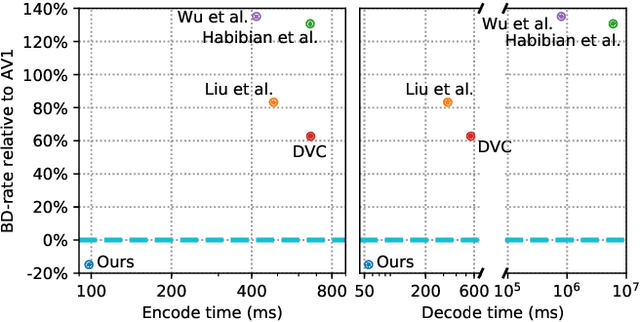
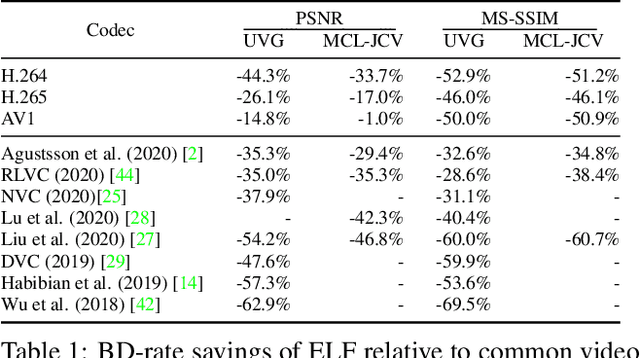
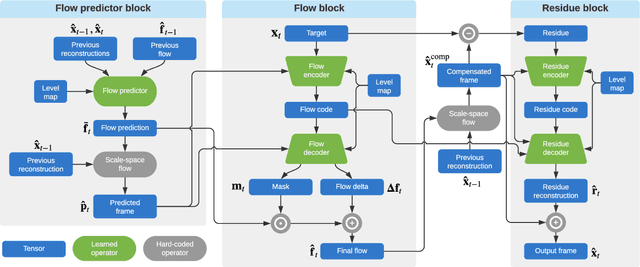

While learned video codecs have demonstrated great promise, they have yet to achieve sufficient efficiency for practical deployment. In this work, we propose several novel ideas for learned video compression which allow for improved performance for the low-latency mode (I- and P-frames only) along with a considerable increase in computational efficiency. In this setting, for natural videos our approach compares favorably across the entire R-D curve under metrics PSNR, MS-SSIM and VMAF against all mainstream video standards (H.264, H.265, AV1) and all ML codecs. At the same time, our approach runs at least 5x faster and has fewer parameters than all ML codecs which report these figures. Our contributions include a flexible-rate framework allowing a single model to cover a large and dense range of bitrates, at a negligible increase in computation and parameter count; an efficient backbone optimized for ML-based codecs; and a novel in-loop flow prediction scheme which leverages prior information towards more efficient compression. We benchmark our method, which we call ELF-VC (Efficient, Learned and Flexible Video Coding) on popular video test sets UVG and MCL-JCV under metrics PSNR, MS-SSIM and VMAF. For example, on UVG under PSNR, it reduces the BD-rate by 44% against H.264, 26% against H.265, 15% against AV1, and 35% against the current best ML codec. At the same time, on an NVIDIA Titan V GPU our approach encodes/decodes VGA at 49/91 FPS, HD 720 at 19/35 FPS, and HD 1080 at 10/18 FPS.
A novel joint points and silhouette-based method to estimate 3D human pose and shape
Dec 11, 2020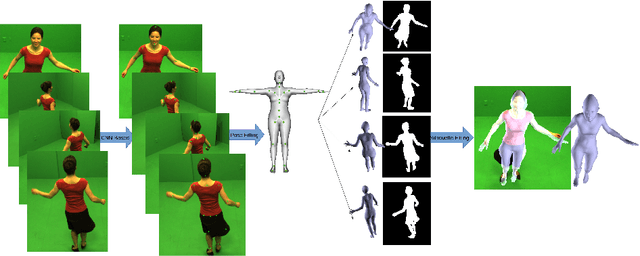
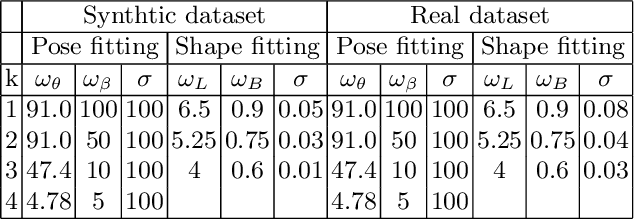
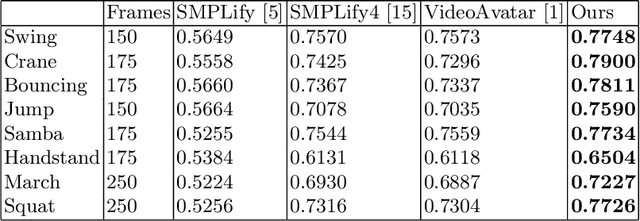
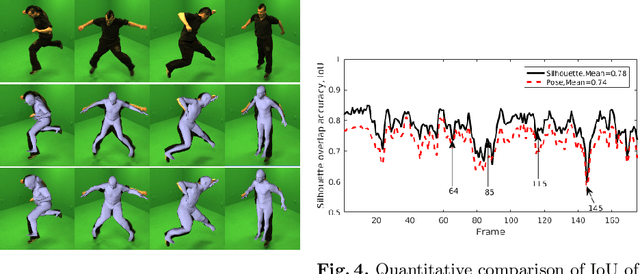
This paper presents a novel method for 3D human pose and shape estimation from images with sparse views, using joint points and silhouettes, based on a parametric model. Firstly, the parametric model is fitted to the joint points estimated by deep learning-based human pose estimation. Then, we extract the correspondence between the parametric model of pose fitting and silhouettes on 2D and 3D space. A novel energy function based on the correspondence is built and minimized to fit parametric model to the silhouettes. Our approach uses sufficient shape information because the energy function of silhouettes is built from both 2D and 3D space. This also means that our method only needs images from sparse views, which balances data used and the required prior information. Results on synthetic data and real data demonstrate the competitive performance of our approach on pose and shape estimation of the human body.
Does the Magic of BERT Apply to Medical Code Assignment? A Quantitative Study
Mar 11, 2021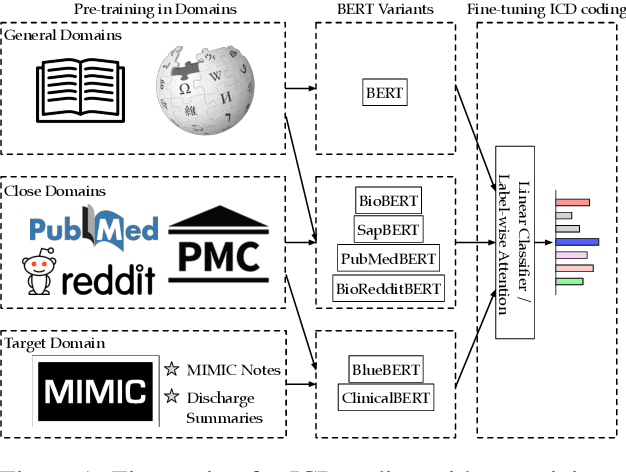
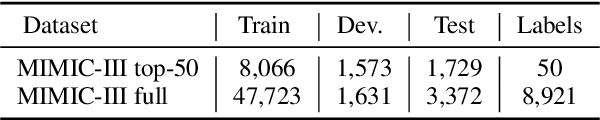
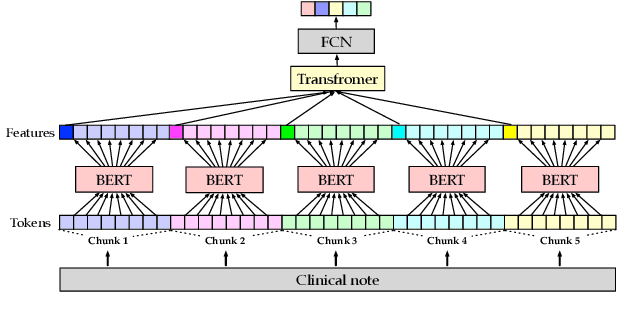
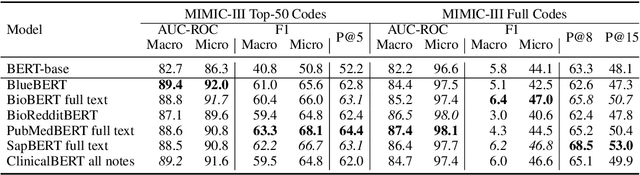
Unsupervised pretraining is an integral part of many natural language processing systems, and transfer learning with language models has achieved remarkable results in many downstream tasks. In the clinical application of medical code assignment, diagnosis and procedure codes are inferred from lengthy clinical notes such as hospital discharge summaries. However, it is not clear if pretrained models are useful for medical code prediction without further architecture engineering. This paper conducts a comprehensive quantitative analysis of various contextualized language models' performance, pretrained in different domains, for medical code assignment from clinical notes. We propose a hierarchical fine-tuning architecture to capture interactions between distant words and adopt label-wise attention to exploit label information. Contrary to current trends, we demonstrate that a carefully trained classical CNN outperforms attention-based models on a MIMIC-III subset with frequent codes. Our empirical findings suggest directions for improving the medical code assignment application.
Leveraging Public Data for Practical Private Query Release
Feb 17, 2021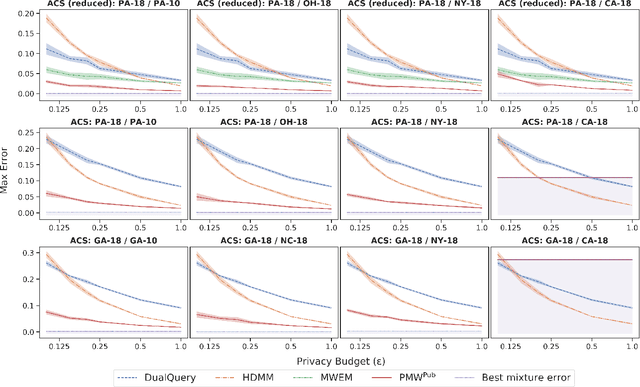
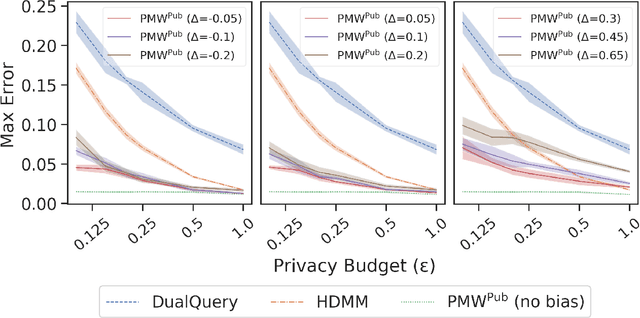
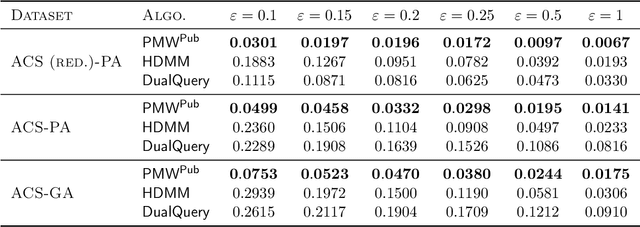
In many statistical problems, incorporating priors can significantly improve performance. However, the use of prior knowledge in differentially private query release has remained underexplored, despite such priors commonly being available in the form of public datasets, such as previous US Census releases. With the goal of releasing statistics about a private dataset, we present PMW^Pub, which -- unlike existing baselines -- leverages public data drawn from a related distribution as prior information. We provide a theoretical analysis and an empirical evaluation on the American Community Survey (ACS) and ADULT datasets, which shows that our method outperforms state-of-the-art methods. Furthermore, PMW^Pub scales well to high-dimensional data domains, where running many existing methods would be computationally infeasible.
Neural population geometry: An approach for understanding biological and artificial neural networks
Apr 17, 2021

Advances in experimental neuroscience have transformed our ability to explore the structure and function of neural circuits. At the same time, advances in machine learning have unleashed the remarkable computational power of artificial neural networks (ANNs). While these two fields have different tools and applications, they present a similar challenge: namely, understanding how information is embedded and processed through high-dimensional representations to solve complex tasks. One approach to addressing this challenge is to utilize mathematical and computational tools to analyze the geometry of these high-dimensional representations, i.e., neural population geometry. We review examples of geometrical approaches providing insight into the function of biological and artificial neural networks: representation untangling in perception, a geometric theory of classification capacity, disentanglement and abstraction in cognitive systems, topological representations underlying cognitive maps, dynamic untangling in motor systems, and a dynamical approach to cognition. Together, these findings illustrate an exciting trend at the intersection of machine learning, neuroscience, and geometry, in which neural population geometry provides a useful population-level mechanistic descriptor underlying task implementation. Importantly, geometric descriptions are applicable across sensory modalities, brain regions, network architectures and timescales. Thus, neural population geometry has the potential to unify our understanding of structure and function in biological and artificial neural networks, bridging the gap between single neurons, populations and behavior.
Improving Online Forums Summarization via Unifying Hierarchical Attention Networks with Convolutional Neural Networks
Mar 25, 2021
Online discussion forums are prevalent and easily accessible, thus allowing people to share ideas and opinions by posting messages in the discussion threads. Forum threads that significantly grow in length can become difficult for participants, both newcomers and existing, to grasp main ideas. This study aims to create an automatic text summarizer for online forums to mitigate this problem. We present a framework based on hierarchical attention networks, unifying Bidirectional Long Short-Term Memory (Bi-LSTM) and Convolutional Neural Network (CNN) to build sentence and thread representations for the forum summarization. In this scheme, Bi-LSTM derives a representation that comprises information of the whole sentence and whole thread; whereas, CNN recognizes high-level patterns of dominant units with respect to the sentence and thread context. The attention mechanism is applied on top of CNN to further highlight the high-level representations that capture any important units contributing to a desirable summary. Extensive performance evaluation based on three datasets, two of which are real-life online forums and one is news dataset, reveals that the proposed model outperforms several competitive baselines.
Depth-Adapted CNN for RGB-D cameras
Sep 23, 2020
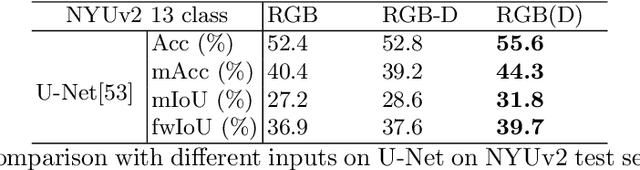
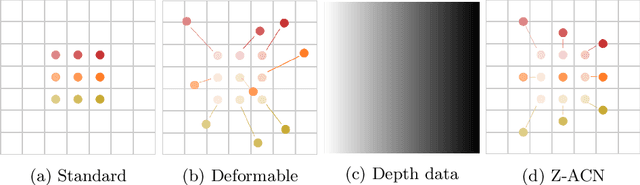
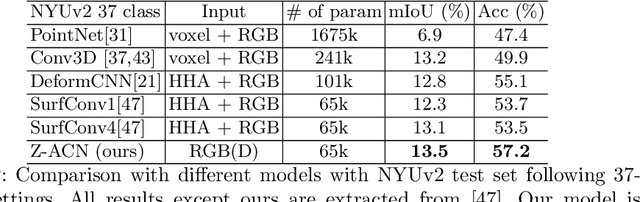
Conventional 2D Convolutional Neural Networks (CNN) extract features from an input image by applying linear filters. These filters compute the spatial coherence by weighting the photometric information on a fixed neighborhood without taking into account the geometric information. We tackle the problem of improving the classical RGB CNN methods by using the depth information provided by the RGB-D cameras. State-of-the-art approaches use depth as an additional channel or image (HHA) or pass from 2D CNN to 3D CNN. This paper proposes a novel and generic procedure to articulate both photometric and geometric information in CNN architecture. The depth data is represented as a 2D offset to adapt spatial sampling locations. The new model presented is invariant to scale and rotation around the X and the Y axis of the camera coordinate system. Moreover, when depth data is constant, our model is equivalent to a regular CNN. Experiments of benchmarks validate the effectiveness of our model.