 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Drifting Features: Detection and evaluation in the context of automatic RRLs identification in VVV
May 06, 2021
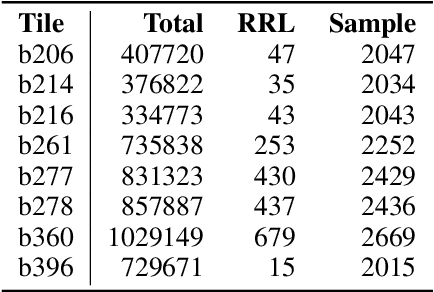
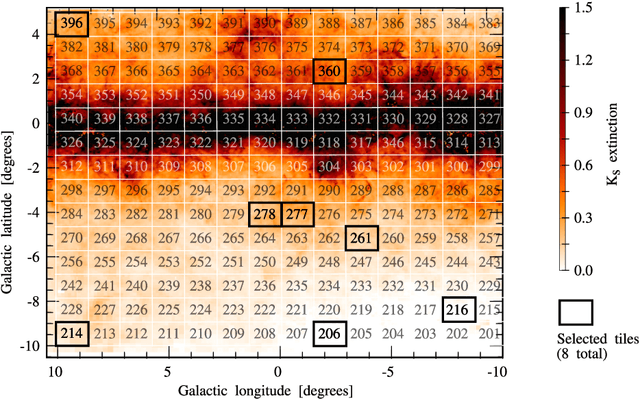
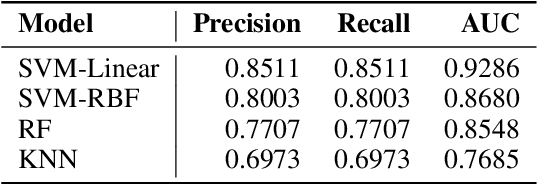
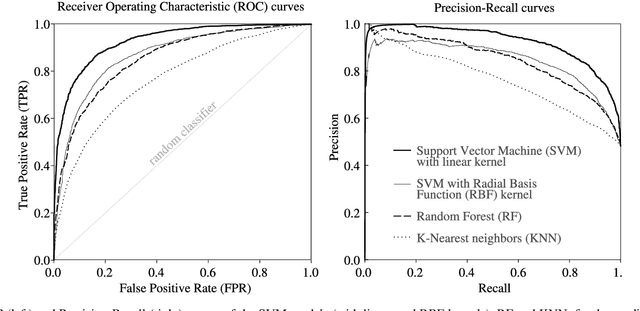
As most of the modern astronomical sky surveys produce data faster than humans can analyze it, Machine Learning (ML) has become a central tool in Astronomy. Modern ML methods can be characterized as highly resistant to some experimental errors. However, small changes on the data over long distances or long periods of time, which cannot be easily detected by statistical methods, can be harmful to these methods. We develop a new strategy to cope with this problem, also using ML methods in an innovative way, to identify these potentially harmful features. We introduce and discuss the notion of Drifting Features, related with small changes in the properties as measured in the data features. We use the identification of RRLs in VVV based on an earlier work and introduce a method for detecting Drifting Features. Our method forces a classifier to learn the tile of origin of diverse sources (mostly stellar 'point sources'), and select the features more relevant to the task of finding candidates to Drifting Features. We show that this method can efficiently identify a reduced set of features that contains useful information about the tile of origin of the sources. For our particular example of detecting RRLs in VVV, we find that Drifting Features are mostly related to color indices. On the other hand, we show that, even if we have a clear set of Drifting Features in our problem, they are mostly insensitive to the identification of RRLs. Drifting Features can be efficiently identified using ML methods. However, in our example, removing Drifting Features does not improve the identification of RRLs.
Multimodal Learning for Hateful Memes Detection
Dec 06, 2020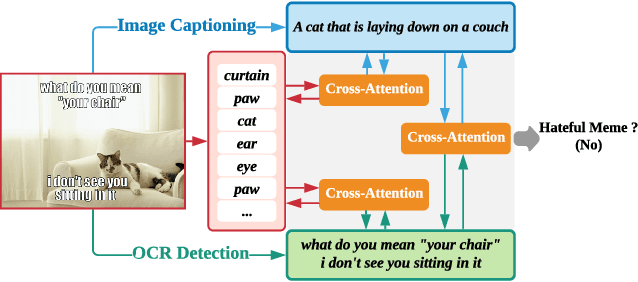
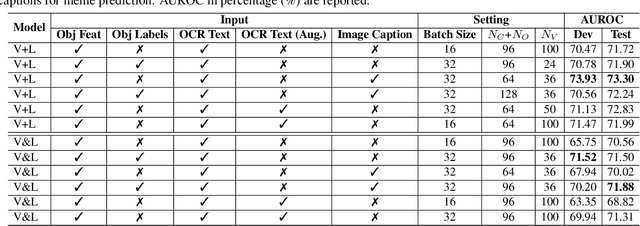
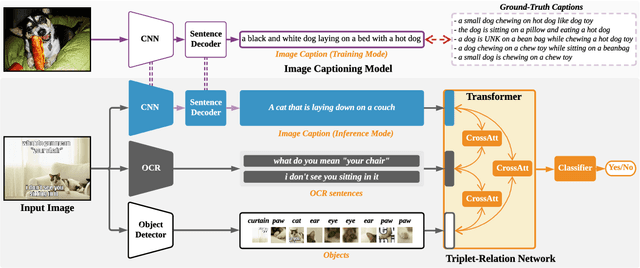

Memes are used for spreading ideas through social networks. Although most memes are created for humor, some memes become hateful under the combination of pictures and text. Automatically detecting the hateful memes can help reduce their harmful social impact. Unlike the conventional multimodal tasks, where the visual and textual information is semantically aligned, the challenge of hateful memes detection lies in its unique multimodal information. The image and text in memes are weakly aligned or even irrelevant, which requires the model to understand the content and perform reasoning over multiple modalities. In this paper, we focus on multimodal hateful memes detection and propose a novel method that incorporates the image captioning process into the memes detection process. We conduct extensive experiments on multimodal meme datasets and illustrated the effectiveness of our approach. Our model achieves promising results on the Hateful Memes Detection Challenge.
Towards a Unified Approach to Single Image Deraining and Dehazing
Mar 26, 2021
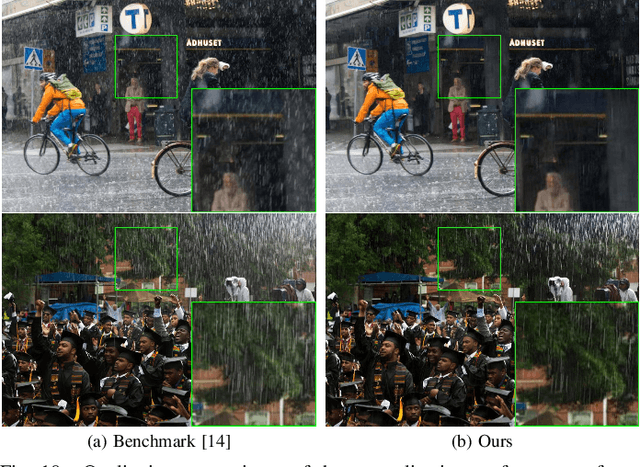
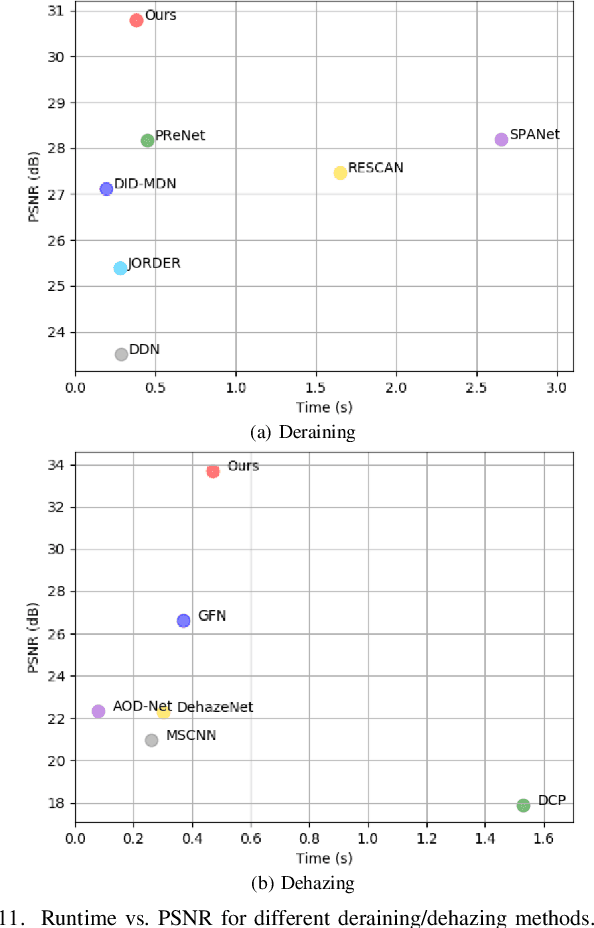
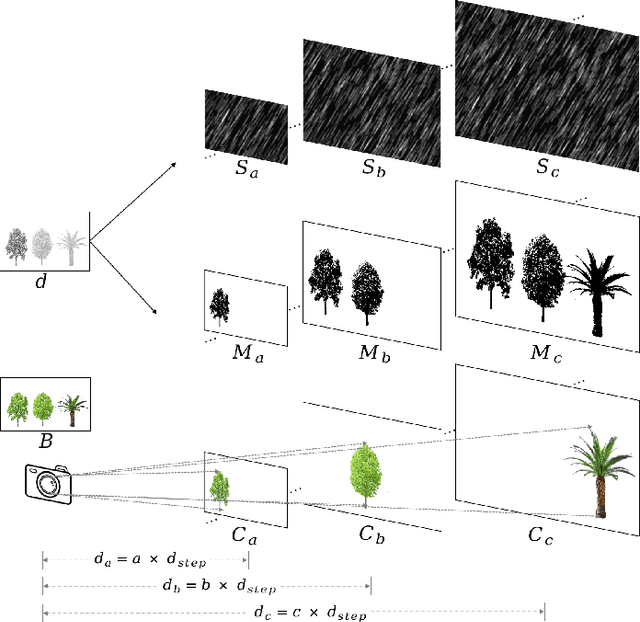
We develop a new physical model for the rain effect and show that the well-known atmosphere scattering model (ASM) for the haze effect naturally emerges as its homogeneous continuous limit. Via depth-aware fusion of multi-layer rain streaks according to the camera imaging mechanism, the new model can better capture the sophisticated non-deterministic degradation patterns commonly seen in real rainy images. We also propose a Densely Scale-Connected Attentive Network (DSCAN) that is suitable for both deraining and dehazing tasks. Our design alleviates the bottleneck issue existent in conventional multi-scale networks and enables more effective information exchange and aggregation. Extensive experimental results demonstrate that the proposed DSCAN is able to deliver superior derained/dehazed results on both synthetic and real images as compared to the state-of-the-art. Moreover, it is shown that for our DSCAN, the synthetic dataset built using the new physical model yields better generalization performance on real images in comparison with the existing datasets based on over-simplified models.
Bilingual Dictionary-based Language Model Pretraining for Neural Machine Translation
Mar 12, 2021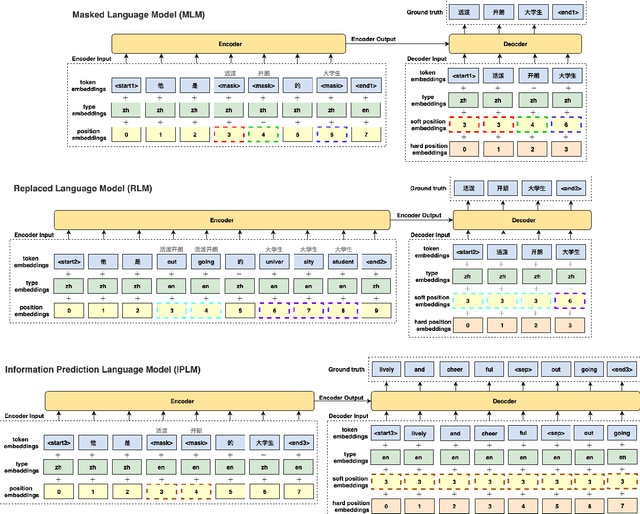
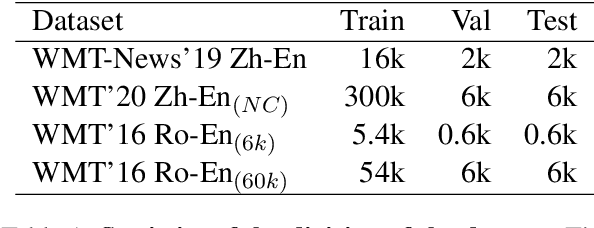
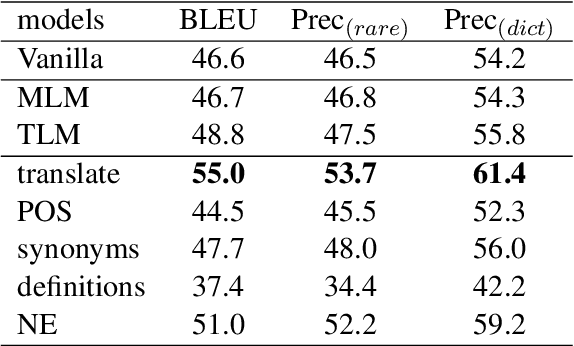
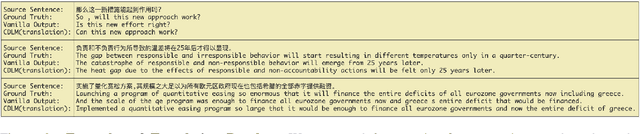
Recent studies have demonstrated a perceivable improvement on the performance of neural machine translation by applying cross-lingual language model pretraining (Lample and Conneau, 2019), especially the Translation Language Modeling (TLM). To alleviate the need for expensive parallel corpora by TLM, in this work, we incorporate the translation information from dictionaries into the pretraining process and propose a novel Bilingual Dictionary-based Language Model (BDLM). We evaluate our BDLM in Chinese, English, and Romanian. For Chinese-English, we obtained a 55.0 BLEU on WMT-News19 (Tiedemann, 2012) and a 24.3 BLEU on WMT20 news-commentary, outperforming the Vanilla Transformer (Vaswani et al., 2017) by more than 8.4 BLEU and 2.3 BLEU, respectively. According to our results, the BDLM also has advantages on convergence speed and predicting rare words. The increase in BLEU for WMT16 Romanian-English also shows its effectiveness in low-resources language translation.
InversionNet3D: Efficient and Scalable Learning for 3D Full Waveform Inversion
Mar 25, 2021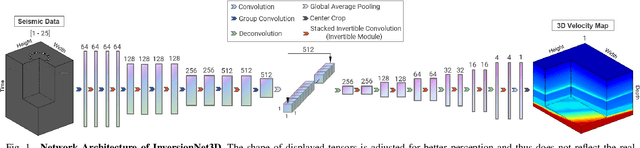
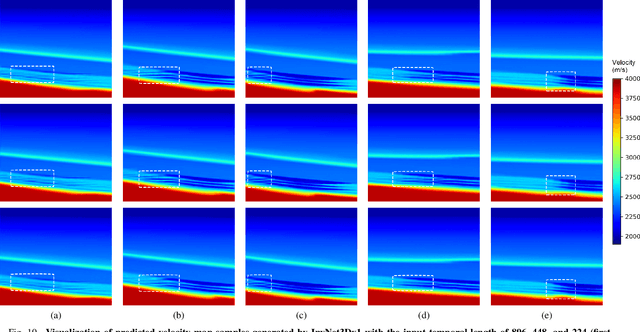
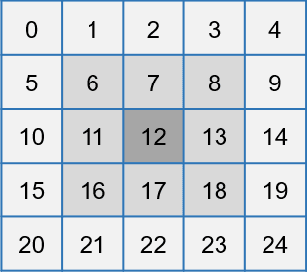
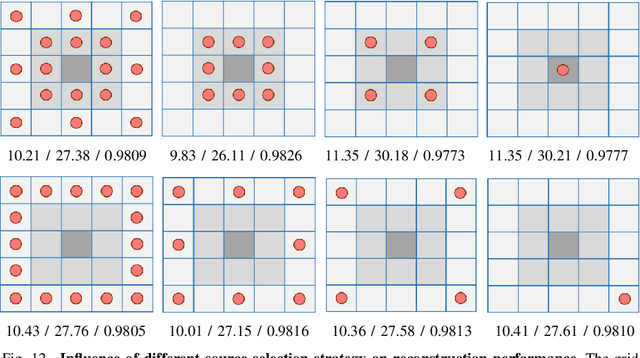
Recent progress in the use of deep learning for Full Waveform Inversion (FWI) has demonstrated the advantage of data-driven methods over traditional physics-based approaches in terms of reconstruction accuracy and computational efficiency. However, due to high computational complexity and large memory consumption, the reconstruction of 3D high-resolution velocity maps via deep networks is still a great challenge. In this paper, we present InversionNet3D, an efficient and scalable encoder-decoder network for 3D FWI. The proposed method employs group convolution in the encoder to establish an effective hierarchy for learning information from multiple sources while cutting down unnecessary parameters and operations at the same time. The introduction of invertible layers further reduces the memory consumption of intermediate features during training and thus enables the development of deeper networks with more layers and higher capacity as required by different application scenarios. Experiments on the 3D Kimberlina dataset demonstrate that InversionNet3D achieves state-of-the-art reconstruction performance with lower computational cost and lower memory footprint compared to the baseline.
Predicting Intensive Care Unit Length of Stay and Mortality Using Patient Vital Signs: Machine Learning Model Development and Validation
May 05, 2021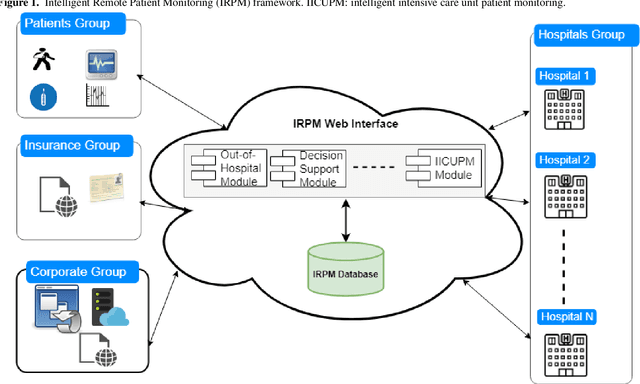

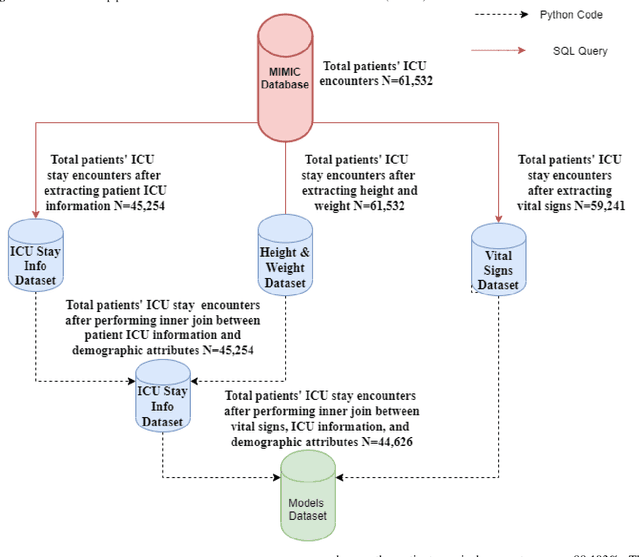

Patient monitoring is vital in all stages of care. We here report the development and validation of ICU length of stay and mortality prediction models. The models will be used in an intelligent ICU patient monitoring module of an Intelligent Remote Patient Monitoring (IRPM) framework that monitors the health status of patients, and generates timely alerts, maneuver guidance, or reports when adverse medical conditions are predicted. We utilized the publicly available Medical Information Mart for Intensive Care (MIMIC) database to extract ICU stay data for adult patients to build two prediction models: one for mortality prediction and another for ICU length of stay. For the mortality model, we applied six commonly used machine learning (ML) binary classification algorithms for predicting the discharge status (survived or not). For the length of stay model, we applied the same six ML algorithms for binary classification using the median patient population ICU stay of 2.64 days. For the regression-based classification, we used two ML algorithms for predicting the number of days. We built two variations of each prediction model: one using 12 baseline demographic and vital sign features, and the other based on our proposed quantiles approach, in which we use 21 extra features engineered from the baseline vital sign features, including their modified means, standard deviations, and quantile percentages. We could perform predictive modeling with minimal features while maintaining reasonable performance using the quantiles approach. The best accuracy achieved in the mortality model was approximately 89% using the random forest algorithm. The highest accuracy achieved in the length of stay model, based on the population median ICU stay (2.64 days), was approximately 65% using the random forest algorithm.
* 23 Pages, 11 Figures, 13 Tables
Painting Outside as Inside: Edge Guided Image Outpainting via Bidirectional Rearrangement with Step-By-Step Learning
Oct 05, 2020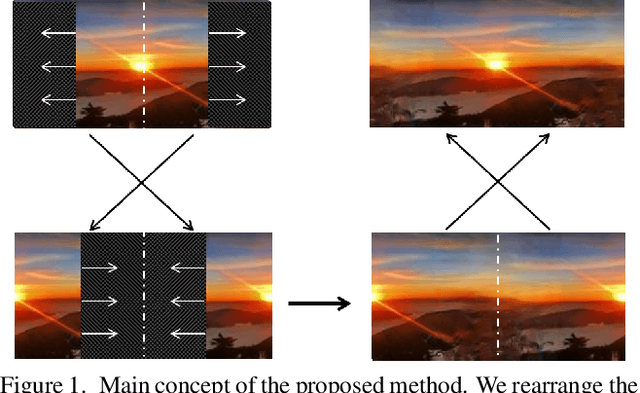
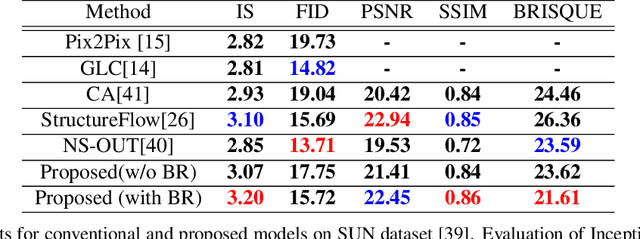
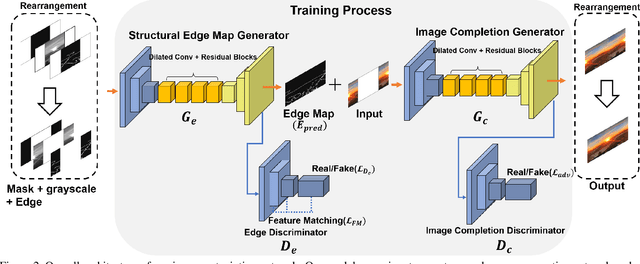
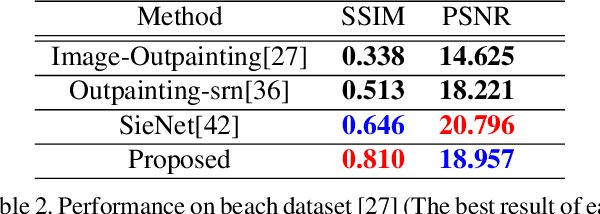
Image outpainting is a very intriguing problem as the outside of a given image can be continuously filled by considering as the context of the image. This task has two main challenges. The first is to maintain the spatial consistency in contents of generated regions and the original input. The second is to generate a high-quality large image with a small amount of adjacent information. Conventional image outpainting methods generate inconsistent, blurry, and repeated pixels. To alleviate the difficulty of an outpainting problem, we propose a novel image outpainting method using bidirectional boundary region rearrangement. We rearrange the image to benefit from the image inpainting task by reflecting more directional information. The bidirectional boundary region rearrangement enables the generation of the missing region using bidirectional information similar to that of the image inpainting task, thereby generating the higher quality than the conventional methods using unidirectional information. Moreover, we use the edge map generator that considers images as original input with structural information and hallucinates the edges of unknown regions to generate the image. Our proposed method is compared with other state-of-the-art outpainting and inpainting methods both qualitatively and quantitatively. We further compared and evaluated them using BRISQUE, one of the No-Reference image quality assessment (IQA) metrics, to evaluate the naturalness of the output. The experimental results demonstrate that our method outperforms other methods and generates new images with 360{\deg}panoramic characteristics.
Risk & returns around FOMC press conferences: a novel perspective from computer vision
Dec 11, 2020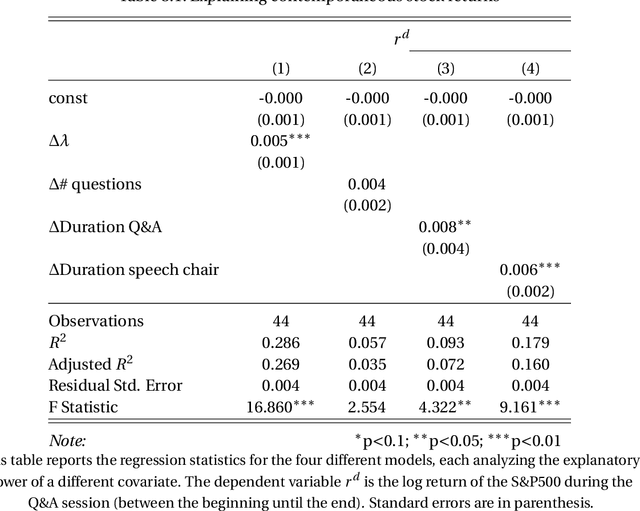
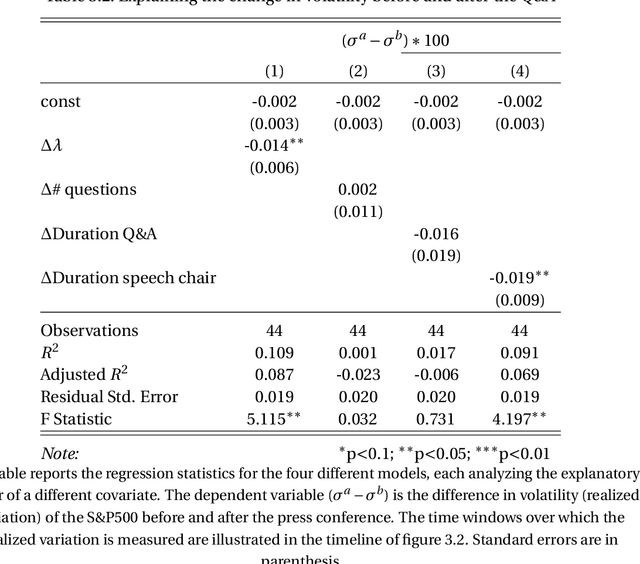

I propose a new tool to characterize the resolution of uncertainty around FOMC press conferences. It relies on the construction of a measure capturing the level of discussion complexity between the Fed Chair and reporters during the Q&A sessions. I show that complex discussions are associated with higher equity returns and a drop in realized volatility. The method creates an attention score by quantifying how much the Chair needs to rely on reading internal documents to be able to answer a question. This is accomplished by building a novel dataset of video images of the press conferences and leveraging recent deep learning algorithms from computer vision. This alternative data provides new information on nonverbal communication that cannot be extracted from the widely analyzed FOMC transcripts. This paper can be seen as a proof of concept that certain videos contain valuable information for the study of financial markets.
Self-Feature Regularization: Self-Feature Distillation Without Teacher Models
Mar 16, 2021
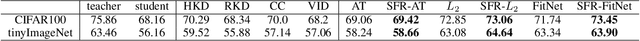
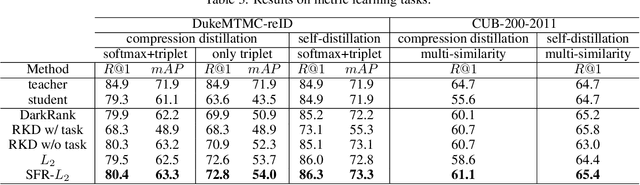
Knowledge distillation is the process of transferring the knowledge from a large model to a small model. In this process, the small model learns the generalization ability of the large model and retains the performance close to that of the large model. Knowledge distillation provides a training means to migrate the knowledge of models, facilitating model deployment and speeding up inference. However, previous distillation methods require pre-trained teacher models, which still bring computational and storage overheads. In this paper, a novel general training framework called Self-Feature Regularization~(SFR) is proposed, which uses features in the deep layers to supervise feature learning in the shallow layers, retains more semantic information. Specifically, we firstly use EMD-l2 loss to match local features and a many-to-one approach to distill features more intensively in the channel dimension. Then dynamic label smoothing is used in the output layer to achieve better performance. Experiments further show the effectiveness of our proposed framework.
Addressing Annotation Imprecision for Tree Crown Delineation Using the RandCrowns Index
May 05, 2021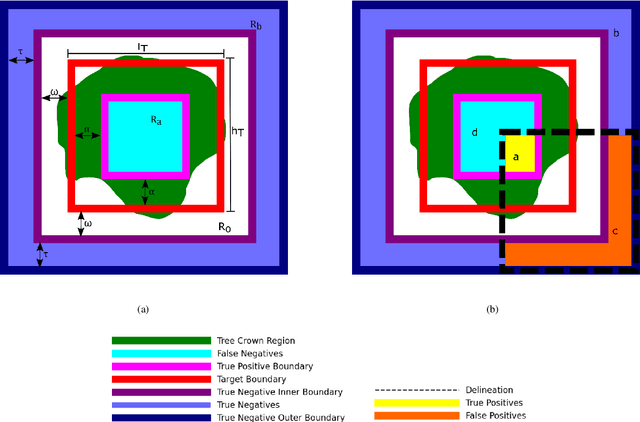
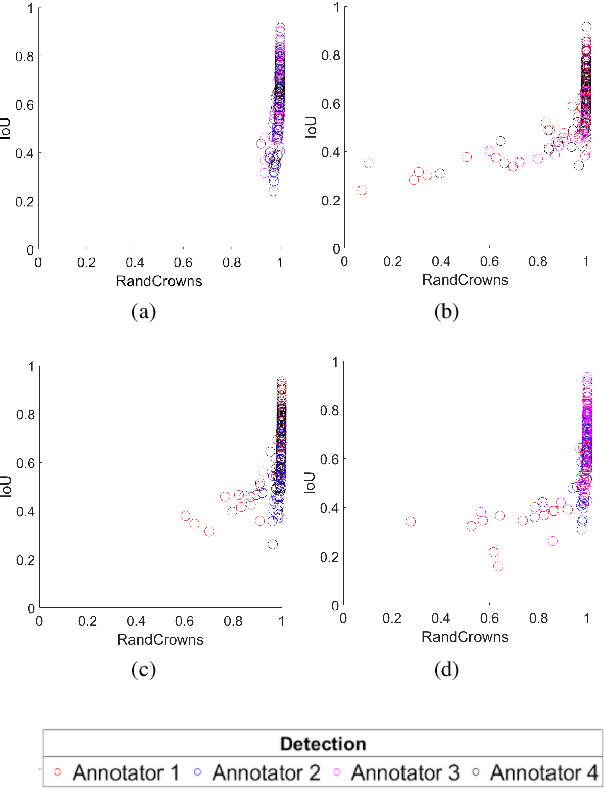


Supervised methods for object delineation in remote sensing require labeled ground-truth data. Gathering sufficient high quality ground-truth data is difficult, especially when the targets are of irregular shape or difficult to distinguish from the background or neighboring objects. Tree crown delineation provides key information from remote sensing images for forestry, ecology, and management. However, tree crowns in remote sensing imagery are often difficult to label and annotate due to irregular shape, overlapping canopies, shadowing, and indistinct edges. There are also multiple approaches to annotation in this field (e.g., rectangular boxes vs. convex polygons) that further contribute to annotation imprecision. However, current evaluation methods do not account for this uncertainty in annotations, and quantitative metrics for evaluation can vary across multiple annotators. We address these limitations using an adaptation of the Rand index for weakly-labeled crown delineation that we call RandCrowns. The RandCrowns metric reformulates the Rand index by adjusting the areas over which each term of the index is computed to account for uncertain and imprecise object delineation labels. Quantitative comparisons to the commonly used intersection over union (Jaccard similarity) method shows a decrease in the variance generated by differences among multiple annotators. Combined with qualitative examples, our results suggest that this RandCrowns metric is more robust for scoring target delineations in the presence of uncertainty and imprecision in annotations that are inherent to tree crown delineation. Although the focus of this paper is on evaluation of tree crown delineations, annotation imprecision is a challenge that is common across remote sensing of the environment (and many computer vision problems in general).