 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Feature Regularization: Self-Feature Distillation Without Teacher Models
Mar 17, 2021

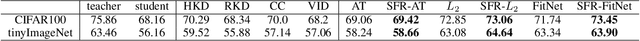
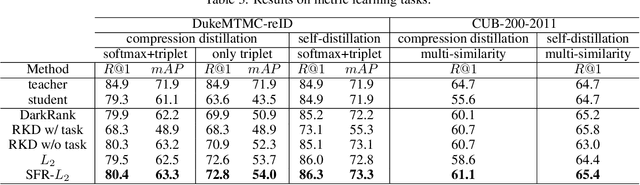
Knowledge distillation is the process of transferring the knowledge from a large model to a small model. In this process, the small model learns the generalization ability of the large model and retains the performance close to that of the large model. Knowledge distillation provides a training means to migrate the knowledge of models, facilitating model deployment and speeding up inference. However, previous distillation methods require pre-trained teacher models, which still bring computational and storage overheads. In this paper, a novel general training framework called Self-Feature Regularization~(SFR) is proposed, which uses features in the deep layers to supervise feature learning in the shallow layers, retains more semantic information. Specifically, we firstly use EMD-l2 loss to match local features and a many-to-one approach to distill features more intensively in the channel dimension. Then dynamic label smoothing is used in the output layer to achieve better performance. Experiments further show the effectiveness of our proposed framework.
DPlis: Boosting Utility of Differentially Private Deep Learning via Randomized Smoothing
Mar 02, 2021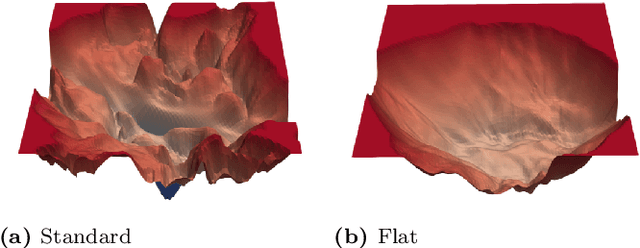
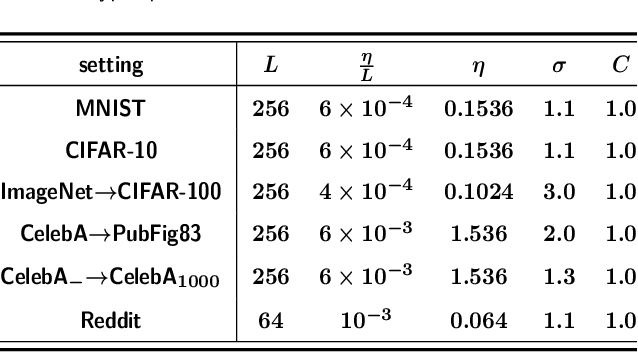
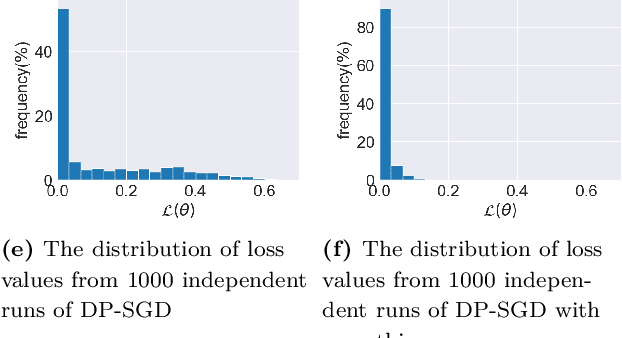
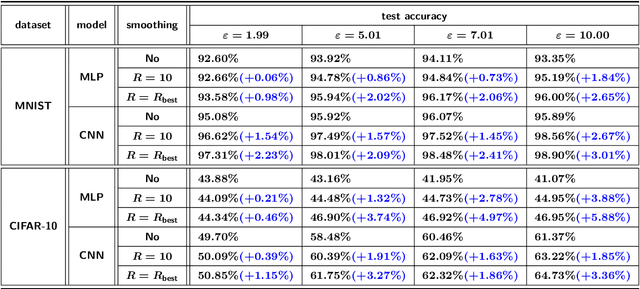
Deep learning techniques have achieved remarkable performance in wide-ranging tasks. However, when trained on privacy-sensitive datasets, the model parameters may expose private information in training data. Prior attempts for differentially private training, although offering rigorous privacy guarantees, lead to much lower model performance than the non-private ones. Besides, different runs of the same training algorithm produce models with large performance variance. To address these issues, we propose DPlis--Differentially Private Learning wIth Smoothing. The core idea of DPlis is to construct a smooth loss function that favors noise-resilient models lying in large flat regions of the loss landscape. We provide theoretical justification for the utility improvements of DPlis. Extensive experiments also demonstrate that DPlis can effectively boost model quality and training stability under a given privacy budget.
Medical Entity Disambiguation Using Graph Neural Networks
Apr 03, 2021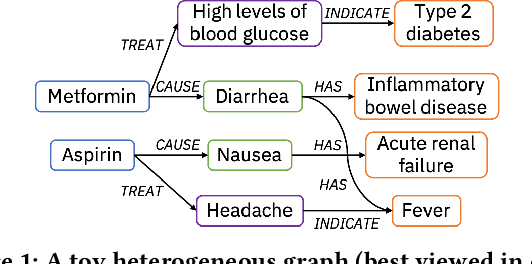
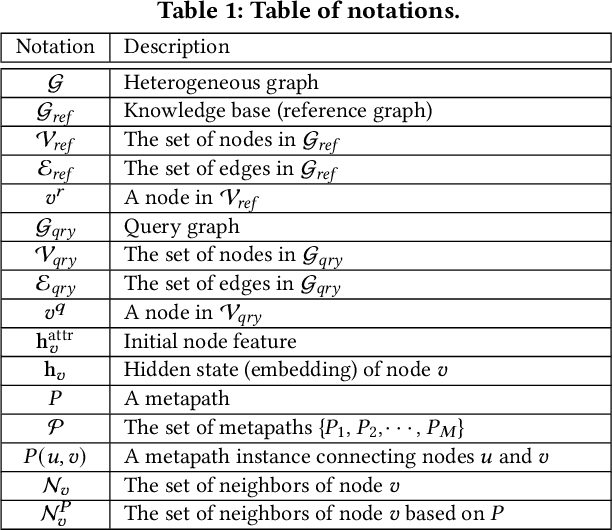
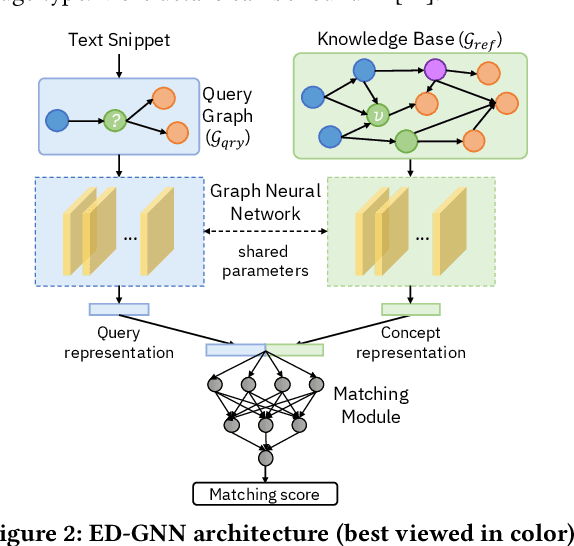
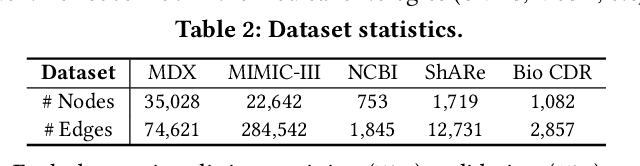
Medical knowledge bases (KBs), distilled from biomedical literature and regulatory actions, are expected to provide high-quality information to facilitate clinical decision making. Entity disambiguation (also referred to as entity linking) is considered as an essential task in unlocking the wealth of such medical KBs. However, existing medical entity disambiguation methods are not adequate due to word discrepancies between the entities in the KB and the text snippets in the source documents. Recently, graph neural networks (GNNs) have proven to be very effective and provide state-of-the-art results for many real-world applications with graph-structured data. In this paper, we introduce ED-GNN based on three representative GNNs (GraphSAGE, R-GCN, and MAGNN) for medical entity disambiguation. We develop two optimization techniques to fine-tune and improve ED-GNN. First, we introduce a novel strategy to represent entities that are mentioned in text snippets as a query graph. Second, we design an effective negative sampling strategy that identifies hard negative samples to improve the model's disambiguation capability. Compared to the best performing state-of-the-art solutions, our ED-GNN offers an average improvement of 7.3% in terms of F1 score on five real-world datasets.
aDWI-BIDS: an extension to the brain imaging data structure for advanced diffusion weighted imaging
Mar 26, 2021

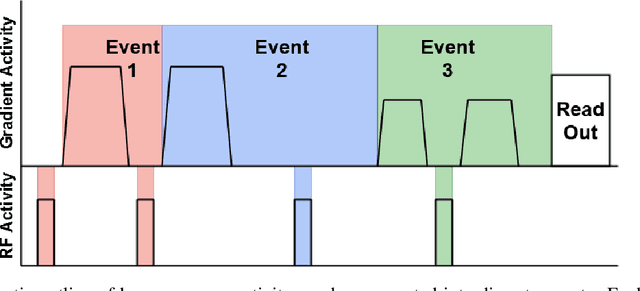
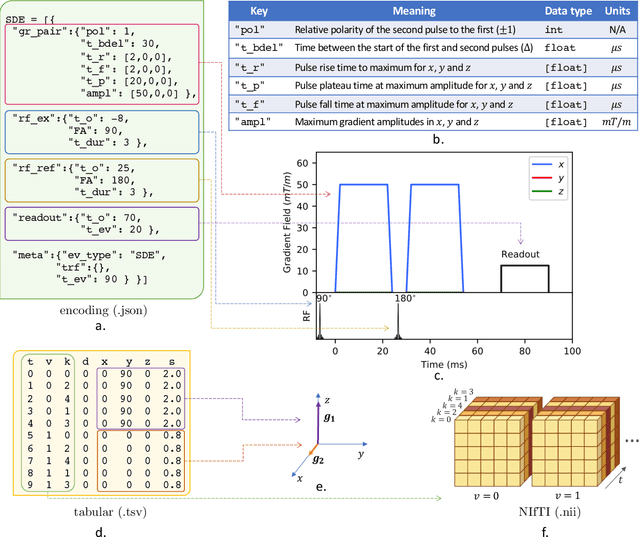
Diffusion weighted imaging techniques permit us to infer microstructural detail in biological tissue in vivo and noninvasively. Modern sequences are based on advanced diffusion encoding schemes, allowing probing of more revealing measures of tissue microstructure than the standard apparent diffusion coefficient or fractional anisotropy. Though these methods may result in faster or more revealing acquisitions, they generally demand prior knowledge of sequence-specific parameters for which there is no accepted sharing standard. Here, we present a metadata labelling scheme suitable for the needs of developers and users within the diffusion neuroimaging community alike: a lightweight, unambiguous parametric map relaying acqusition parameters. This extensible scheme supports a wide spectrum of diffusion encoding methods, from single diffusion encoding to highly complex sequences involving arbitrary gradient waveforms. Built under the brain imaging data structure (BIDS), it allows storage of advanced diffusion MRI data comprehensively alongside any other neuroimaging information, facilitating processing pipelines and multimodal analyses. We illustrate the usefulness of this BIDS-extension with a range of example data, and discuss the extension's impact on pre- and post-processing software.
Combating Mode Collapse in GAN training: An Empirical Analysis using Hessian Eigenvalues
Dec 17, 2020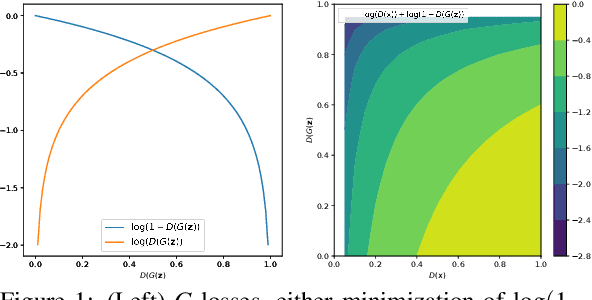
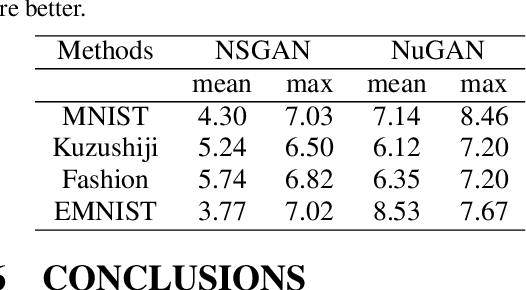
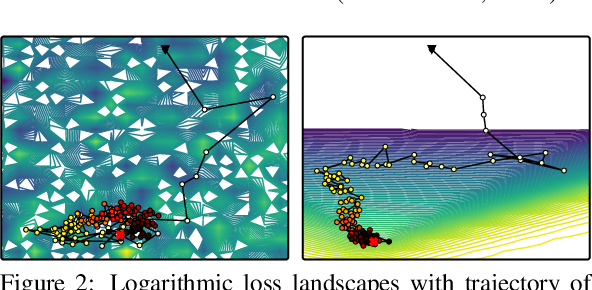
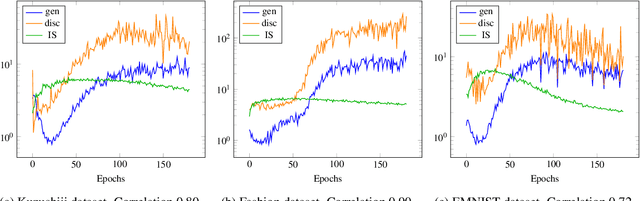
Generative adversarial networks (GANs) provide state-of-the-art results in image generation. However, despite being so powerful, they still remain very challenging to train. This is in particular caused by their highly non-convex optimization space leading to a number of instabilities. Among them, mode collapse stands out as one of the most daunting ones. This undesirable event occurs when the model can only fit a few modes of the data distribution, while ignoring the majority of them. In this work, we combat mode collapse using second-order gradient information. To do so, we analyse the loss surface through its Hessian eigenvalues, and show that mode collapse is related to the convergence towards sharp minima. In particular, we observe how the eigenvalues of the $G$ are directly correlated with the occurrence of mode collapse. Finally, motivated by these findings, we design a new optimization algorithm called nudged-Adam (NuGAN) that uses spectral information to overcome mode collapse, leading to empirically more stable convergence properties.
Adversarial Shape Learning for Building Extraction in VHR Remote Sensing Images
Mar 17, 2021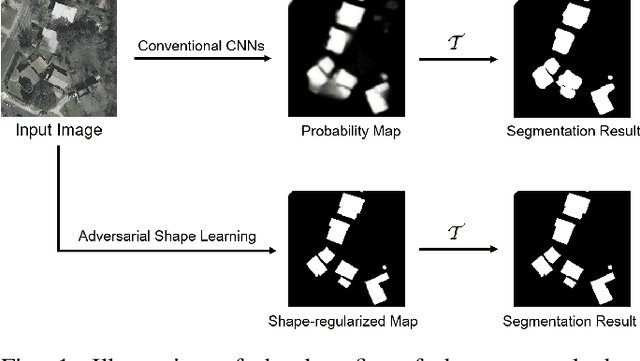
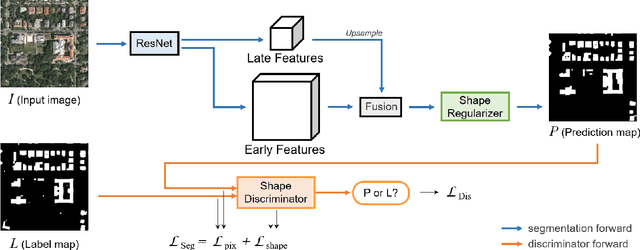
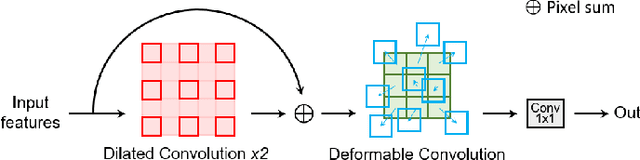
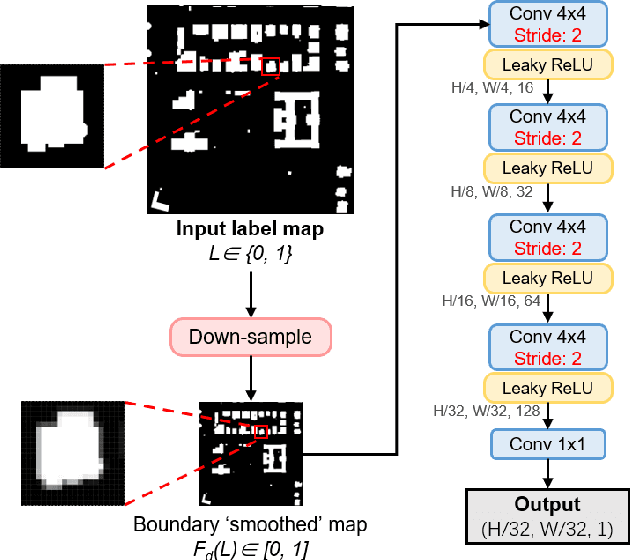
Building extraction in VHR RSIs remains to be a challenging task due to occlusion and boundary ambiguity problems. Although conventional convolutional neural networks (CNNs) based methods are capable of exploiting local texture and context information, they fail to capture the shape patterns of buildings, which is a necessary constraint in the human recognition. In this context, we propose an adversarial shape learning network (ASLNet) to model the building shape patterns, thus improving the accuracy of building segmentation. In the proposed ASLNet, we introduce the adversarial learning strategy to explicitly model the shape constraints, as well as a CNN shape regularizer to strengthen the embedding of shape features. To assess the geometric accuracy of building segmentation results, we further introduced several object-based assessment metrics. Experiments on two open benchmark datasets show that the proposed ASLNet improves both the pixel-based accuracy and the object-based measurements by a large margin. The code is available at: https://github.com/ggsDing/ASLNet
Distributed Client-Server Optimization for SLAM with Limited On-Device Resources
Mar 26, 2021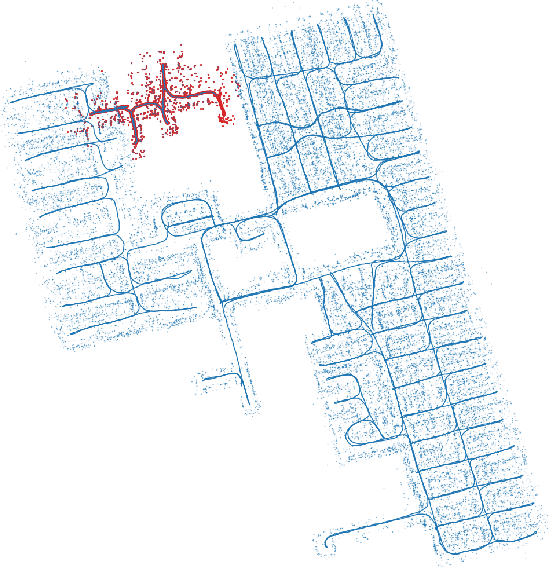
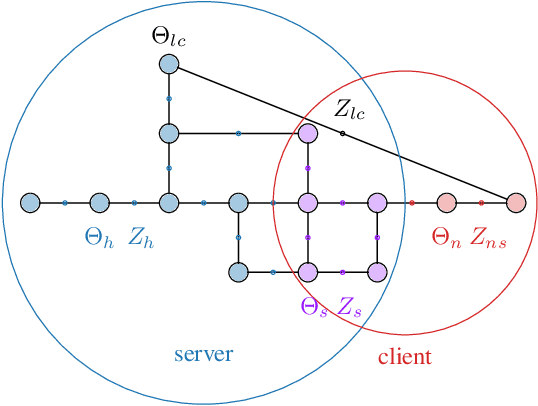
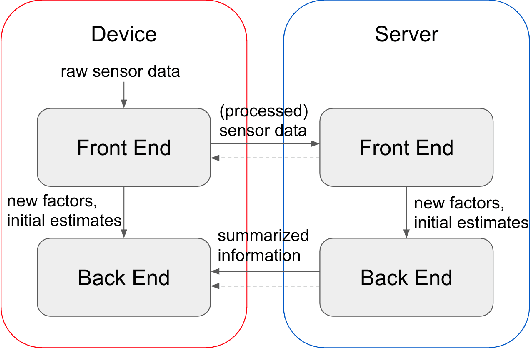
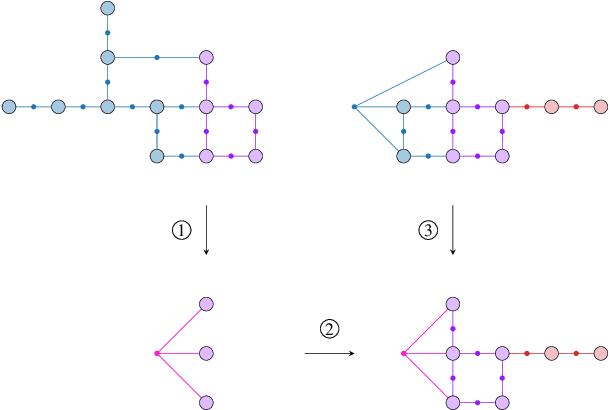
Simultaneous localization and mapping (SLAM) is a crucial functionality for exploration robots and virtual/augmented reality (VR/AR) devices. However, some of such devices with limited resources cannot afford the computational or memory cost to run full SLAM algorithms. We propose a general client-server SLAM optimization framework that achieves accurate real-time state estimation on the device with low requirements of on-board resources. The resource-limited device (the client) only works on a small part of the map, and the rest of the map is processed by the server. By sending the summarized information of the rest of map to the client, the on-device state estimation is more accurate. Further improvement of accuracy is achieved in the presence of on-device early loop closures, which enables reloading useful variables from the server to the client. Experimental results from both synthetic and real-world datasets demonstrate that the proposed optimization framework achieves accurate estimation in real-time with limited computation and memory budget of the device.
Influencing Reinforcement Learning through Natural Language Guidance
Apr 11, 2021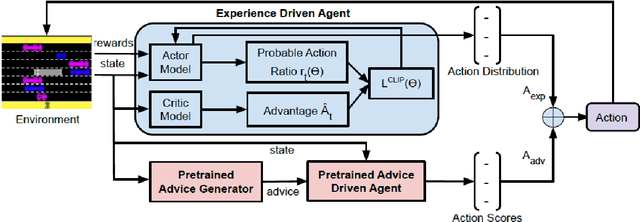
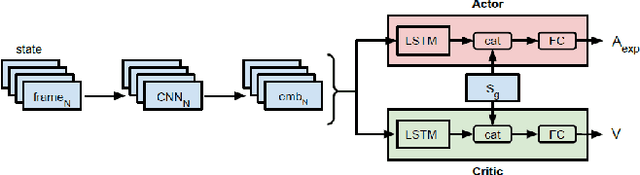
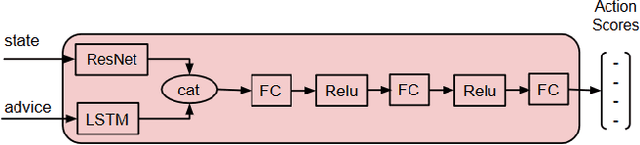

Interactive reinforcement learning agents use human feedback or instruction to help them learn in complex environments. Often, this feedback comes in the form of a discrete signal that is either positive or negative. While informative, this information can be difficult to generalize on its own. In this work, we explore how natural language advice can be used to provide a richer feedback signal to a reinforcement learning agent by extending policy shaping, a well-known Interactive reinforcement learning technique. Usually policy shaping employs a human feedback policy to help an agent to learn more about how to achieve its goal. In our case, we replace this human feedback policy with policy generated based on natural language advice. We aim to inspect if the generated natural language reasoning provides support to a deep reinforcement learning agent to decide its actions successfully in any given environment. So, we design our model with three networks: first one is the experience driven, next is the advice generator and third one is the advice driven. While the experience driven reinforcement learning agent chooses its actions being influenced by the environmental reward, the advice driven neural network with generated feedback by the advice generator for any new state selects its actions to assist the reinforcement learning agent to better policy shaping.
Long time-series NDVI reconstruction in cloud-prone regions via spatio-temporal tensor completion
Feb 04, 2021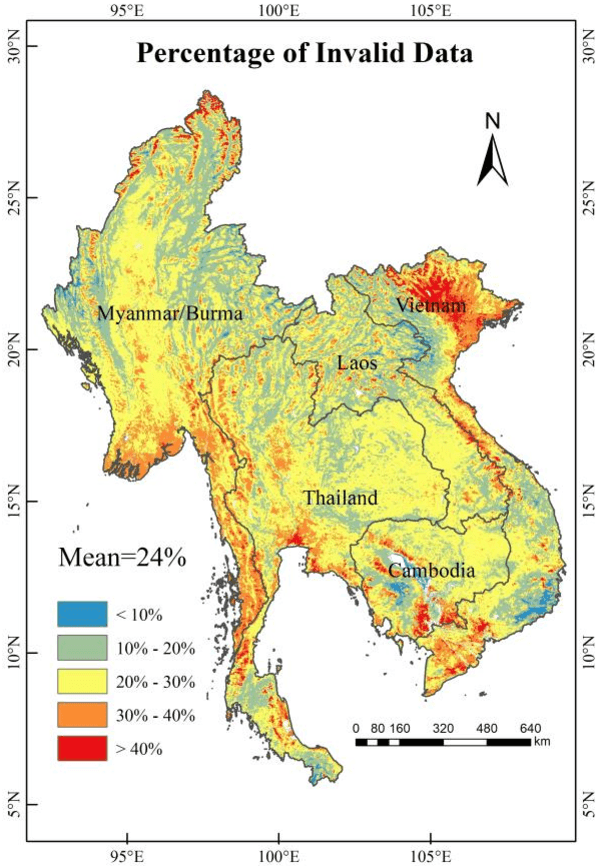

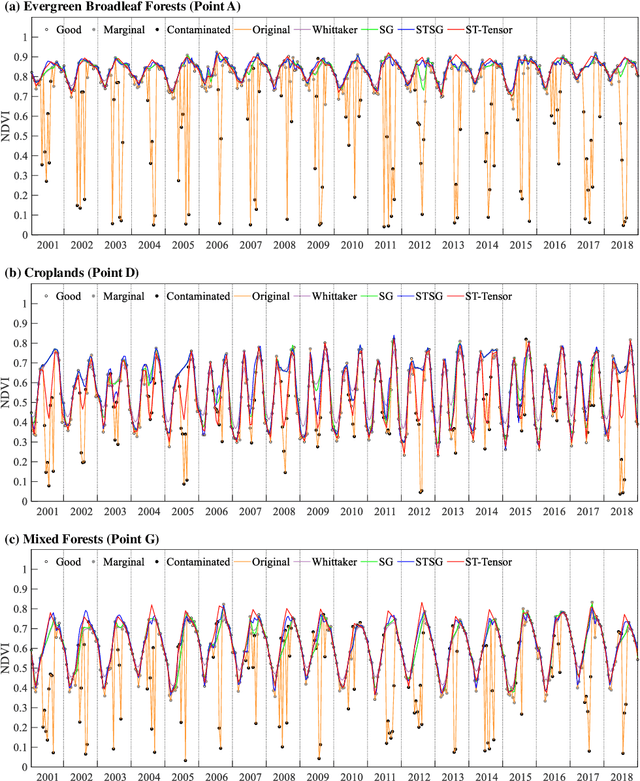
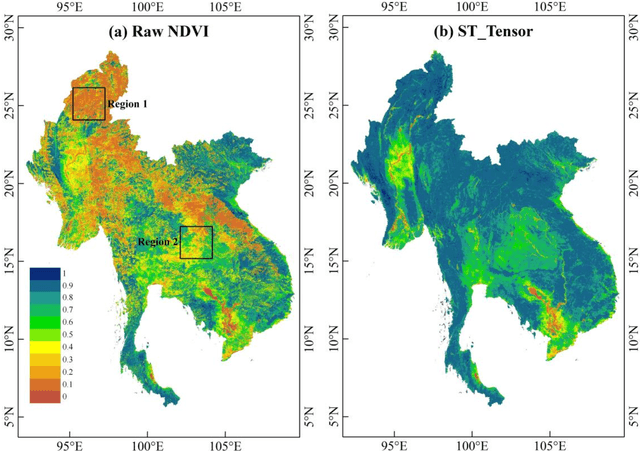
The applications of Normalized Difference Vegetation Index (NDVI) time-series data are inevitably hampered by cloud-induced gaps and noise. Although numerous reconstruction methods have been developed, they have not effectively addressed the issues associated with large gaps in the time series over cloudy and rainy regions, due to the insufficient utilization of the spatial and temporal correlations. In this paper, an adaptive Spatio-Temporal Tensor Completion method (termed ST-Tensor) method is proposed to reconstruct long-term NDVI time series in cloud-prone regions, by making full use of the multi-dimensional spatio-temporal information simultaneously. For this purpose, a highly-correlated tensor is built by considering the correlations among the spatial neighbors, inter-annual variations, and periodic characteristics, in order to reconstruct the missing information via an adaptive-weighted low-rank tensor completion model. An iterative l1 trend filtering method is then implemented to eliminate the residual temporal noise. This new method was tested using MODIS 16-day composite NDVI products from 2001 to 2018 obtained in the region of Mainland Southeast Asia, where the rainy climate commonly induces large gaps and noise in the data. The qualitative and quantitative results indicate that the ST-Tensor method is more effective than the five previous methods in addressing the different missing data problems, especially the temporally continuous gaps and spatio-temporally continuous gaps. It is also shown that the ST-Tensor method performs better than the other methods in tracking NDVI seasonal trajectories, and is therefore a superior option for generating high-quality long-term NDVI time series for cloud-prone regions.
Multimodal Learning for Hateful Memes Detection
Dec 06, 2020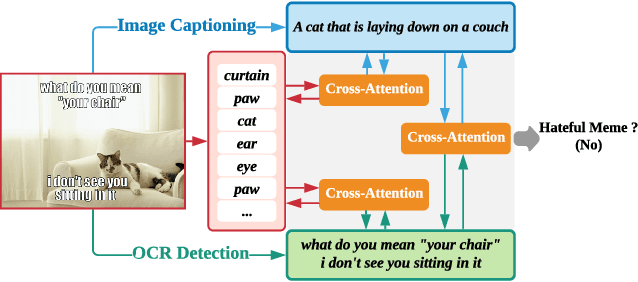
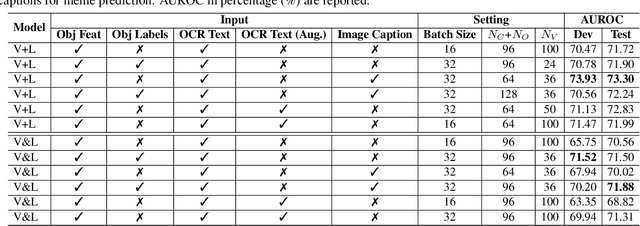
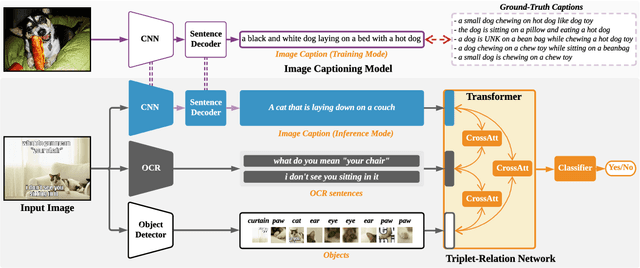

Memes are used for spreading ideas through social networks. Although most memes are created for humor, some memes become hateful under the combination of pictures and text. Automatically detecting the hateful memes can help reduce their harmful social impact. Unlike the conventional multimodal tasks, where the visual and textual information is semantically aligned, the challenge of hateful memes detection lies in its unique multimodal information. The image and text in memes are weakly aligned or even irrelevant, which requires the model to understand the content and perform reasoning over multiple modalities. In this paper, we focus on multimodal hateful memes detection and propose a novel method that incorporates the image captioning process into the memes detection process. We conduct extensive experiments on multimodal meme datasets and illustrated the effectiveness of our approach. Our model achieves promising results on the Hateful Memes Detection Challenge.