 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal Bilinear Encoding Network of Audio-Visual Features at Low Sampling Rates
Dec 18, 2020
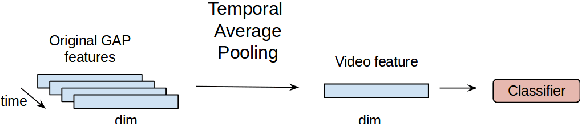

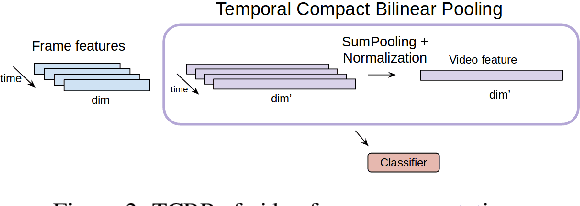
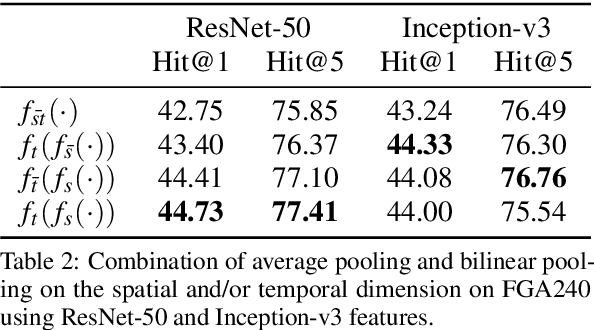
Current deep learning based video classification architectures are typically trained end-to-end on large volumes of data and require extensive computational resources. This paper aims to exploit audio-visual information in video classification with a 1 frame per second sampling rate. We propose Temporal Bilinear Encoding Networks (TBEN) for encoding both audio and visual long range temporal information using bilinear pooling and demonstrate bilinear pooling is better than average pooling on the temporal dimension for videos with low sampling rate. We also embed the label hierarchy in TBEN to further improve the robustness of the classifier. Experiments on the FGA240 fine-grained classification dataset using TBEN achieve a new state-of-the-art (hit@1=47.95%). We also exploit the possibility of incorporating TBEN with multiple decoupled modalities like visual semantic and motion features: experiments on UCF101 sampled at 1 FPS achieve close to state-of-the-art accuracy (hit@1=91.03%) while requiring significantly less computational resources than competing approaches for both training and prediction.
Targeted aspect based multimodal sentiment analysis:an attention capsule extraction and multi-head fusion network
Mar 13, 2021
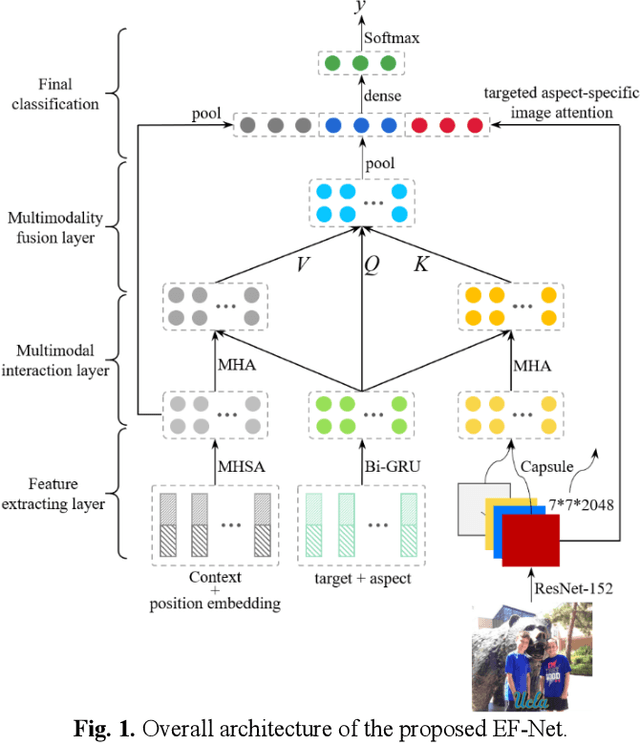
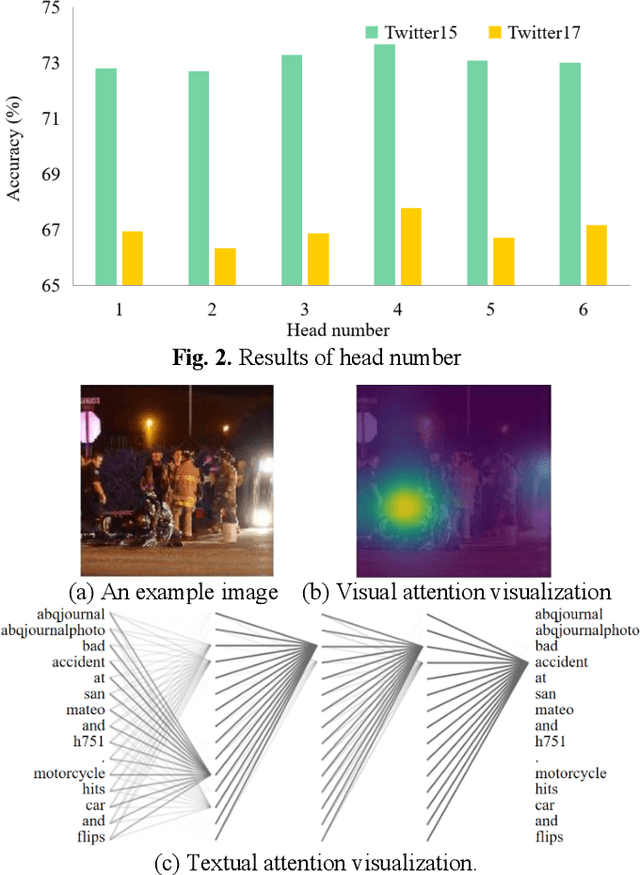
Multimodal sentiment analysis has currently identified its significance in a variety of domains. For the purpose of sentiment analysis, different aspects of distinguishing modalities, which correspond to one target, are processed and analyzed. In this work, we propose the targeted aspect-based multimodal sentiment analysis (TABMSA) for the first time. Furthermore, an attention capsule extraction and multi-head fusion network (EF-Net) on the task of TABMSA is devised. The multi-head attention (MHA) based network and the ResNet-152 are employed to deal with texts and images, respectively. The integration of MHA and capsule network aims to capture the interaction among the multimodal inputs. In addition to the targeted aspect, the information from the context and the image is also incorporated for sentiment delivered. We evaluate the proposed model on two manually annotated datasets. the experimental results demonstrate the effectiveness of our proposed model for this new task.
Relation Clustering in Narrative Knowledge Graphs
Nov 27, 2020

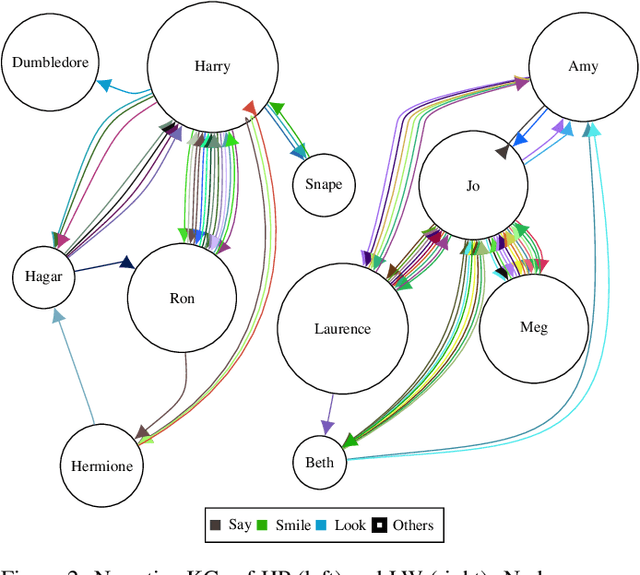
When coping with literary texts such as novels or short stories, the extraction of structured information in the form of a knowledge graph might be hindered by the huge number of possible relations between the entities corresponding to the characters in the novel and the consequent hurdles in gathering supervised information about them. Such issue is addressed here as an unsupervised task empowered by transformers: relational sentences in the original text are embedded (with SBERT) and clustered in order to merge together semantically similar relations. All the sentences in the same cluster are finally summarized (with BART) and a descriptive label extracted from the summary. Preliminary tests show that such clustering might successfully detect similar relations, and provide a valuable preprocessing for semi-supervised approaches.
Geospatial Transformations for Ground-Based Sky Imaging Systems
Mar 02, 2021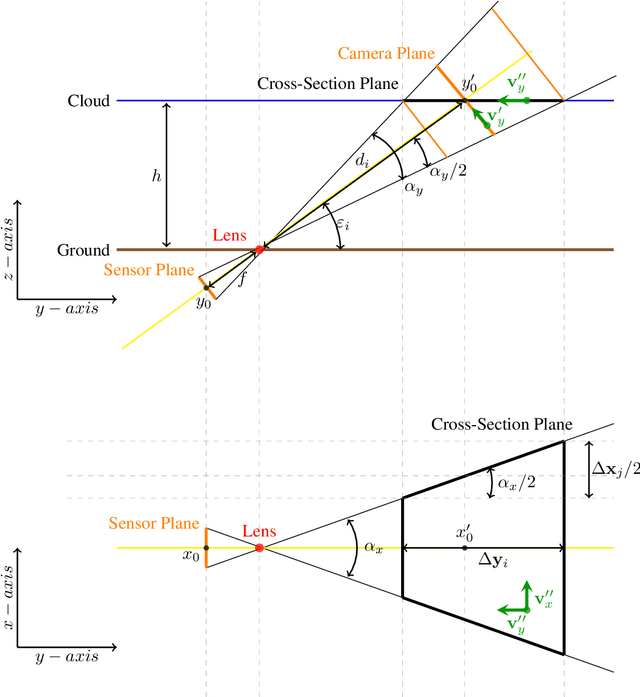
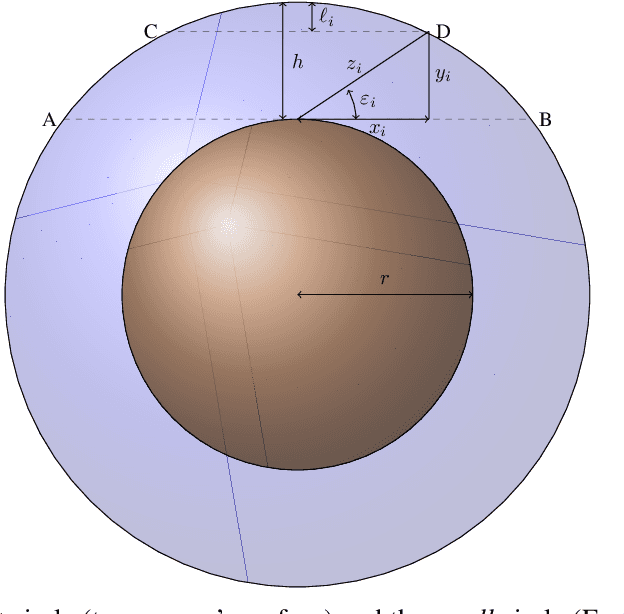
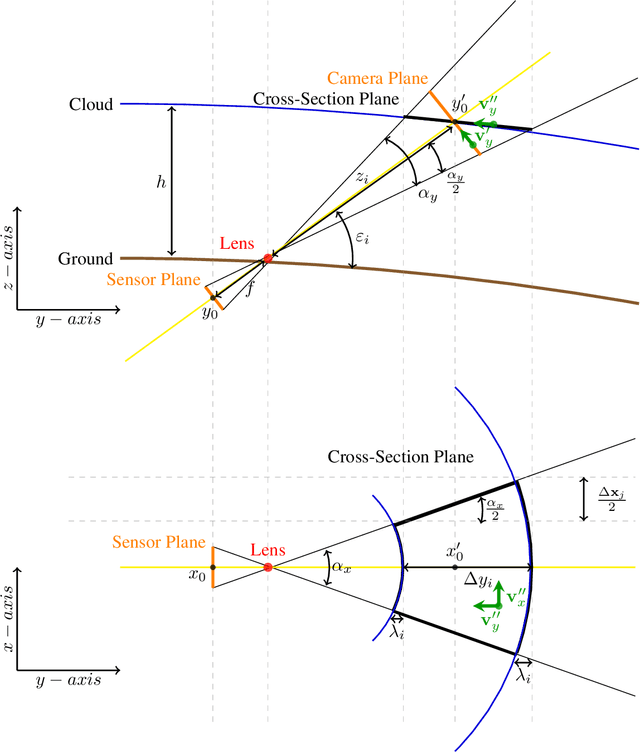

Sky imaging systems use lenses to acquire images concentrating light beams in an imager. The light beams received by the imager have an elevation angle with respect to the normal of the device. This produces that the pixels in an image contain information from different areas of the sky within imaging system Field Of View (FOV). The area of the field of view contained in the pixels increases as the elevation angle of the incident light beams decreases. When the sky imaging system are mounted on a solar tracker the angle of incidence of the light beams varies along time. This investigation introduces a transformation that projects the original euclidean frame of the plane of the imager to the geospatial frame of the sky imaging system field of view.
From Point to Space: 3D Moving Human Pose Estimation Using Commodity WiFi
Dec 28, 2020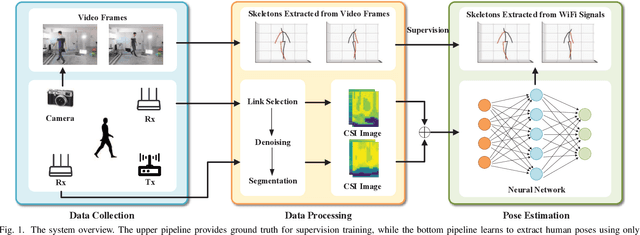

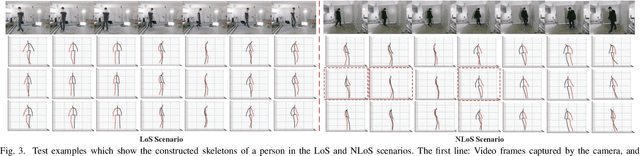
In this paper, we present Wi-Mose, the first 3D moving human pose estimation system using commodity WiFi. Previous WiFi-based works have achieved 2D and 3D pose estimation. These solutions either capture poses from one perspective or construct poses of people who are at a fixed point, preventing their wide adoption in daily scenarios. To reconstruct 3D poses of people who move throughout the space rather than a fixed point, we fuse the amplitude and phase into Channel State Information (CSI) images which can provide both pose and position information. Besides, we design a neural network to extract features that are only associated with poses from CSI images and then convert the features into key-point coordinates. Experimental results show that Wi-Mose can localize key-point with 29.7mm and 37.8mm Procrustes analysis Mean Per Joint Position Error (P-MPJPE) in the Line of Sight (LoS) and Non-Line of Sight (NLoS) scenarios, respectively, achieving higher performance than the state-of-the-art method. The results indicate that Wi-Mose can capture high-precision 3D human poses throughout the space.
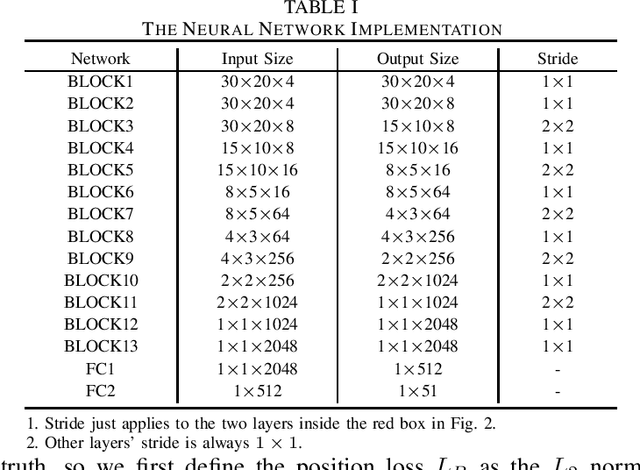
Memory Capacity of Neural Turing Machines with Matrix Representation
Apr 11, 2021
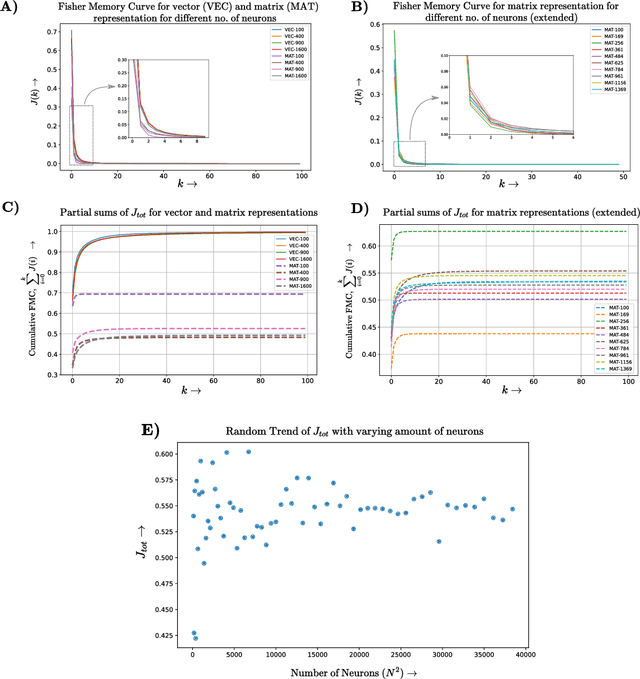
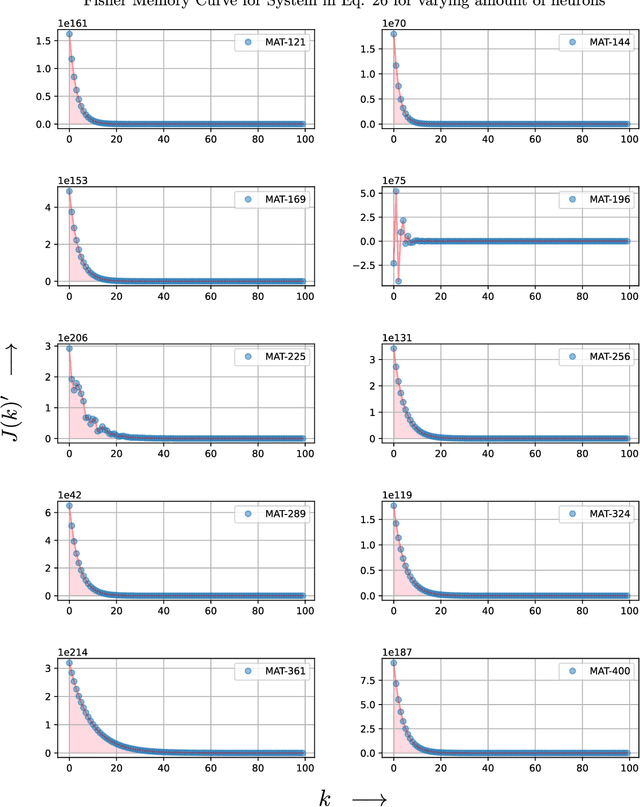
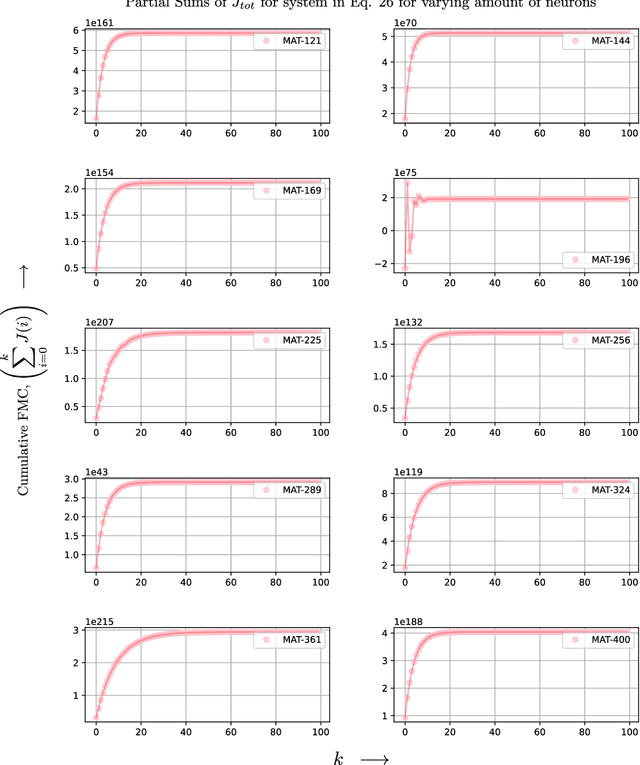
It is well known that recurrent neural networks (RNNs) faced limitations in learning long-term dependencies that have been addressed by memory structures in long short-term memory (LSTM) networks. Matrix neural networks feature matrix representation which inherently preserves the spatial structure of data and has the potential to provide better memory structures when compared to canonical neural networks that use vector representation. Neural Turing machines (NTMs) are novel RNNs that implement notion of programmable computers with neural network controllers to feature algorithms that have copying, sorting, and associative recall tasks. In this paper, we study the augmentation of memory capacity with a matrix representation of RNNs and NTMs (MatNTMs). We investigate if matrix representation has a better memory capacity than the vector representations in conventional neural networks. We use a probabilistic model of the memory capacity using Fisher information and investigate how the memory capacity for matrix representation networks are limited under various constraints, and in general, without any constraints. In the case of memory capacity without any constraints, we found that the upper bound on memory capacity to be $N^2$ for an $N\times N$ state matrix. The results from our experiments using synthetic algorithmic tasks show that MatNTMs have a better learning capacity when compared to its counterparts.
Regularized Recovery by Multi-order Partial Hypergraph Total Variation
Feb 19, 2021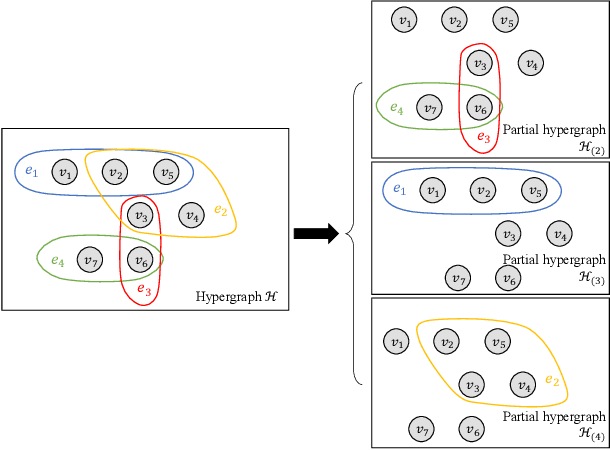
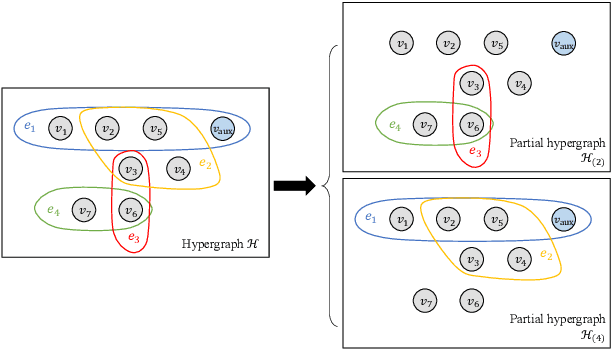
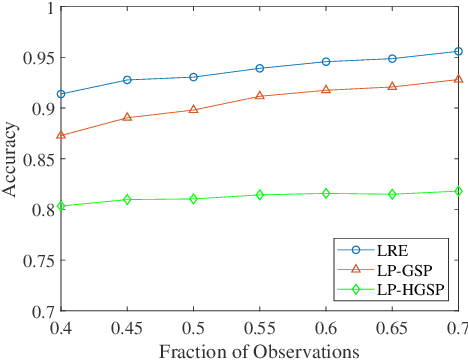
Capturing complex high-order interactions among data is an important task in many scenarios. A common way to model high-order interactions is to use hypergraphs whose topology can be mathematically represented by tensors. Existing methods use a fixed-order tensor to describe the topology of the whole hypergraph, which ignores the divergence of different-order interactions. In this work, we take this divergence into consideration, and propose a multi-order hypergraph Laplacian and the corresponding total variation. Taking this total variation as a regularization term, we can utilize the topology information contained by it to smooth the hypergraph signal. This can help distinguish different-order interactions and represent high-order interactions accurately.
Graph Embedding for Recommendation against Attribute Inference Attacks
Jan 29, 2021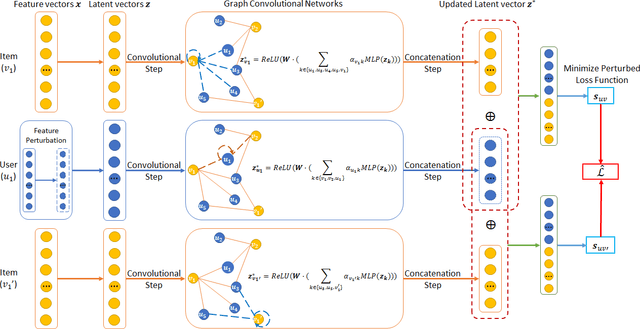
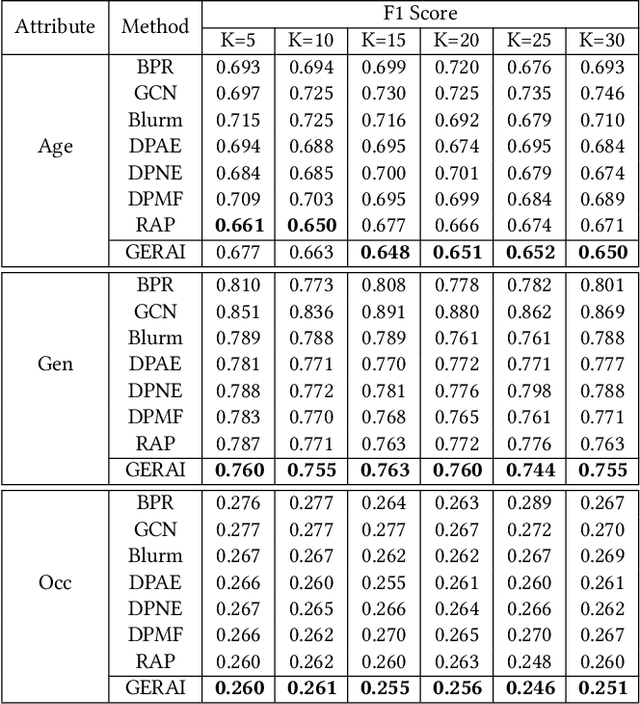
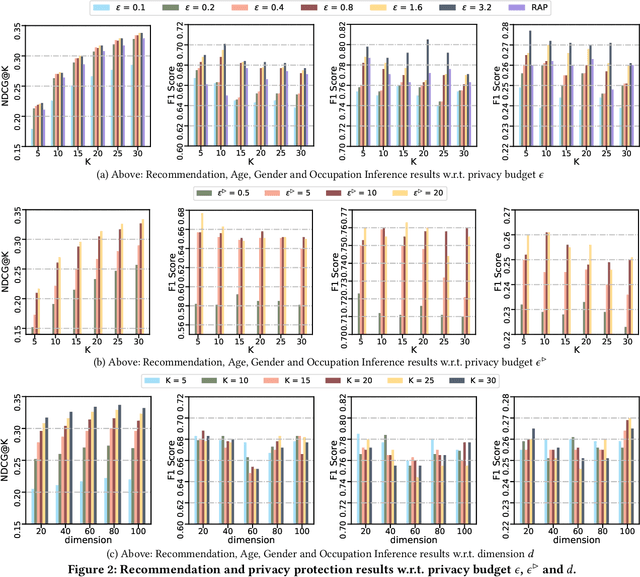
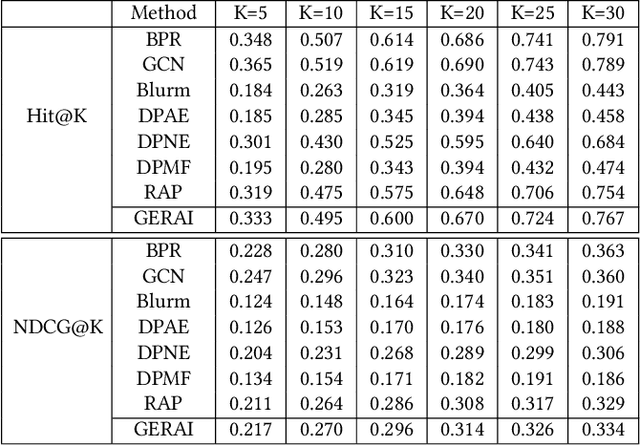
In recent years, recommender systems play a pivotal role in helping users identify the most suitable items that satisfy personal preferences. As user-item interactions can be naturally modelled as graph-structured data, variants of graph convolutional networks (GCNs) have become a well-established building block in the latest recommenders. Due to the wide utilization of sensitive user profile data, existing recommendation paradigms are likely to expose users to the threat of privacy breach, and GCN-based recommenders are no exception. Apart from the leakage of raw user data, the fragility of current recommenders under inference attacks offers malicious attackers a backdoor to estimate users' private attributes via their behavioral footprints and the recommendation results. However, little attention has been paid to developing recommender systems that can defend such attribute inference attacks, and existing works achieve attack resistance by either sacrificing considerable recommendation accuracy or only covering specific attack models or protected information. In our paper, we propose GERAI, a novel differentially private graph convolutional network to address such limitations. Specifically, in GERAI, we bind the information perturbation mechanism in differential privacy with the recommendation capability of graph convolutional networks. Furthermore, based on local differential privacy and functional mechanism, we innovatively devise a dual-stage encryption paradigm to simultaneously enforce privacy guarantee on users' sensitive features and the model optimization process. Extensive experiments show the superiority of GERAI in terms of its resistance to attribute inference attacks and recommendation effectiveness.
Localization and Mapping using Instance-specific Mesh Models
Mar 08, 2021
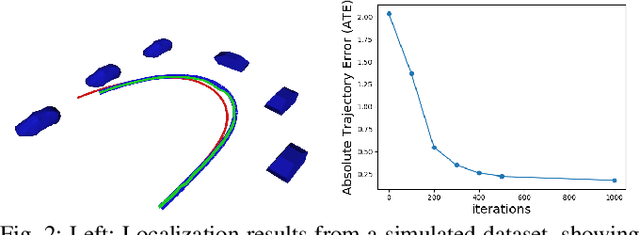
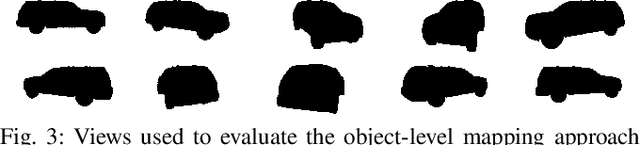
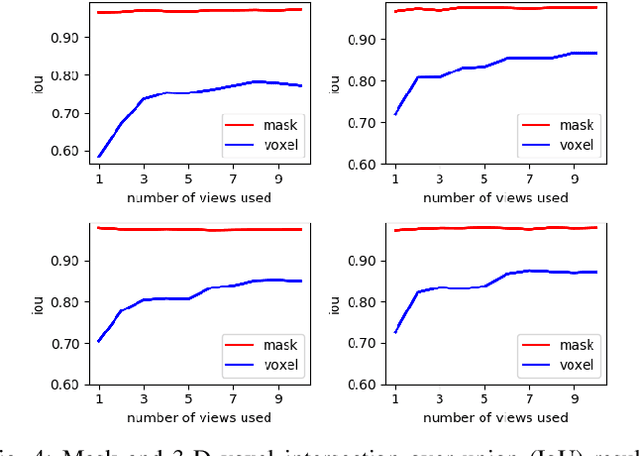
This paper focuses on building semantic maps, containing object poses and shapes, using a monocular camera. This is an important problem because robots need rich understanding of geometry and context if they are to shape the future of transportation, construction, and agriculture. Our contribution is an instance-specific mesh model of object shape that can be optimized online based on semantic information extracted from camera images. Multi-view constraints on the object shape are obtained by detecting objects and extracting category-specific keypoints and segmentation masks. We show that the errors between projections of the mesh model and the observed keypoints and masks can be differentiated in order to obtain accurate instance-specific object shapes. We evaluate the performance of the proposed approach in simulation and on the KITTI dataset by building maps of car poses and shapes.
* 8 pages, 9 figures
Homomorphically Encrypted Linear Contextual Bandit
Mar 17, 2021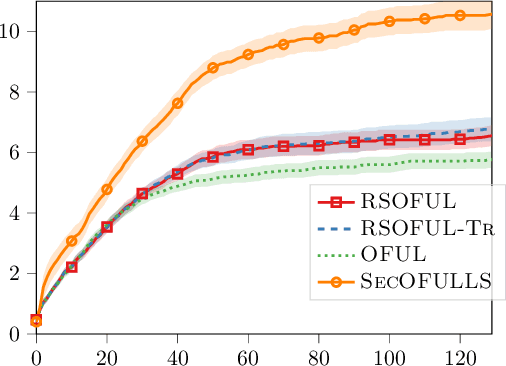
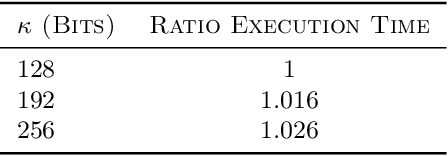
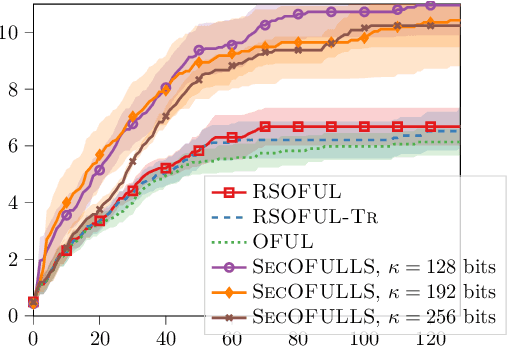
Contextual bandit is a general framework for online learning in sequential decision-making problems that has found application in a large range of domains, including recommendation system, online advertising, clinical trials and many more. A critical aspect of bandit methods is that they require to observe the contexts -- i.e., individual or group-level data -- and the rewards in order to solve the sequential problem. The large deployment in industrial applications has increased interest in methods that preserve the privacy of the users. In this paper, we introduce a privacy-preserving bandit framework based on asymmetric encryption. The bandit algorithm only observes encrypted information (contexts and rewards) and has no ability to decrypt it. Leveraging homomorphic encryption, we show that despite the complexity of the setting, it is possible to learn over encrypted data. We introduce an algorithm that achieves a $\widetilde{O}(d\sqrt{T})$ regret bound in any linear contextual bandit problem, while keeping data encrypted.