 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge-guided Open Attribute Value Extraction with Reinforcement Learning
Oct 19, 2020
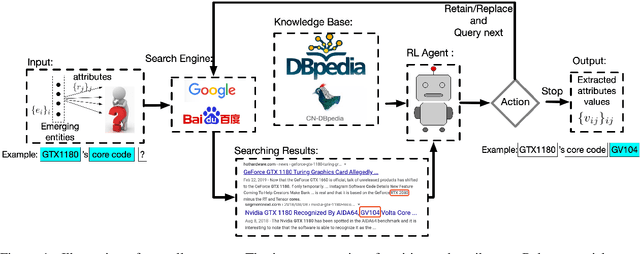
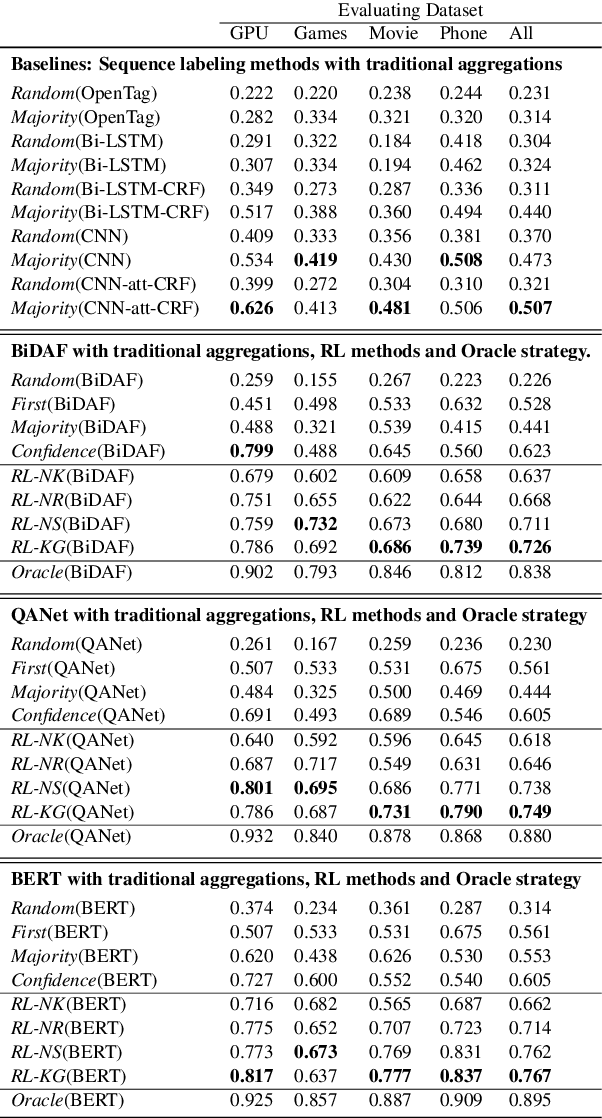
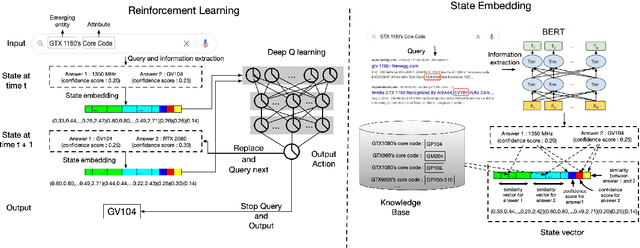

Open attribute value extraction for emerging entities is an important but challenging task. A lot of previous works formulate the problem as a \textit{question-answering} (QA) task. While the collections of articles from web corpus provide updated information about the emerging entities, the retrieved texts can be noisy, irrelevant, thus leading to inaccurate answers. Effectively filtering out noisy articles as well as bad answers is the key to improving extraction accuracy. Knowledge graph (KG), which contains rich, well organized information about entities, provides a good resource to address the challenge. In this work, we propose a knowledge-guided reinforcement learning (RL) framework for open attribute value extraction. Informed by relevant knowledge in KG, we trained a deep Q-network to sequentially compare extracted answers to improve extraction accuracy. The proposed framework is applicable to different information extraction system. Our experimental results show that our method outperforms the baselines by 16.5 - 27.8\%.
Within-Document Event Coreference with BERT-Based Contextualized Representations
Feb 15, 2021
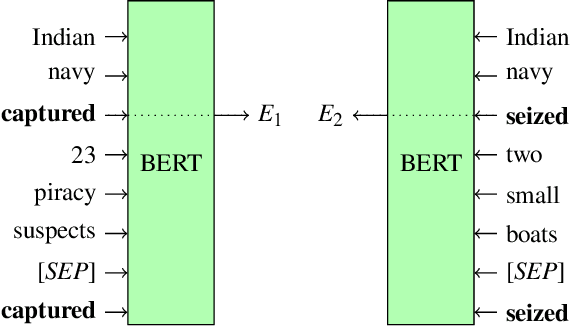
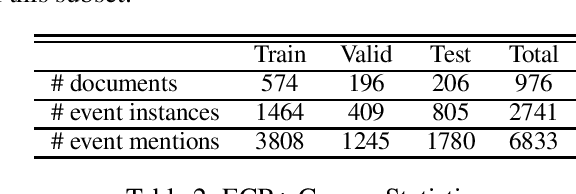
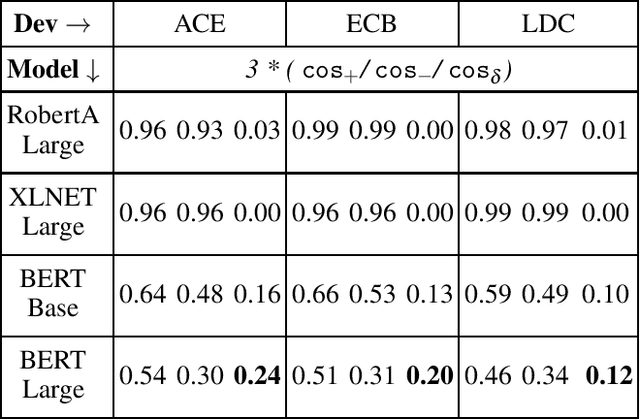
Event coreference continues to be a challenging problem in information extraction. With the absence of any external knowledge bases for events, coreference becomes a clustering task that relies on effective representations of the context in which event mentions appear. Recent advances in contextualized language representations have proven successful in many tasks, however, their use in event linking been limited. Here we present a three part approach that (1) uses representations derived from a pretrained BERT model to (2) train a neural classifier to (3) drive a simple clustering algorithm to create coreference chains. We achieve state of the art results with this model on two standard datasets for within-document event coreference task and establish a new standard on a third newer dataset.
2-Step Sparse-View CT Reconstruction with a Domain-Specific Perceptual Network
Dec 08, 2020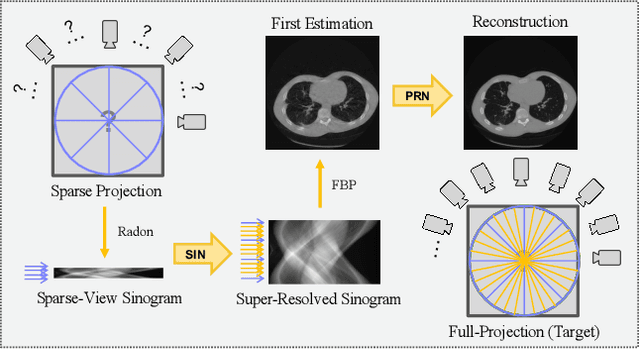
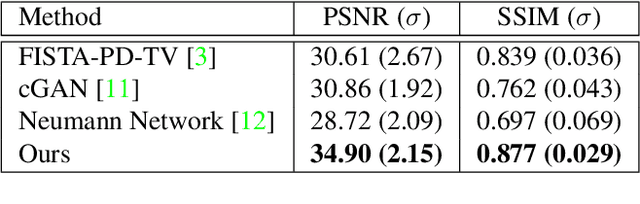
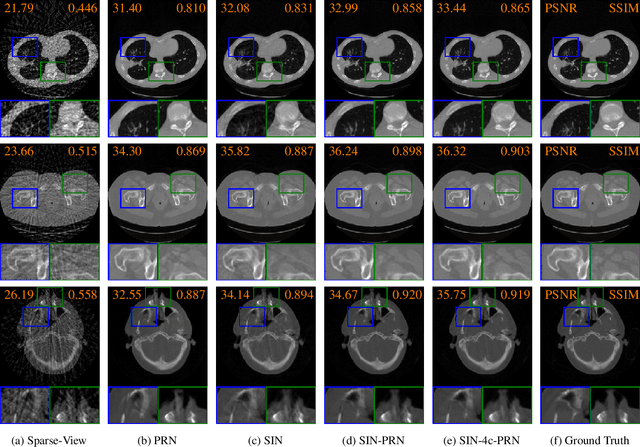
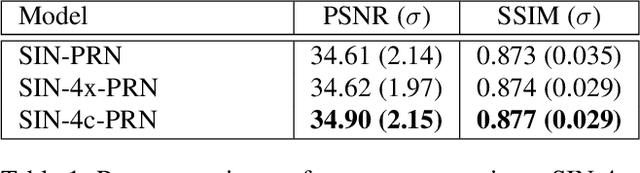
Computed tomography is widely used to examine internal structures in a non-destructive manner. To obtain high-quality reconstructions, one typically has to acquire a densely sampled trajectory to avoid angular undersampling. However, many scenarios require a sparse-view measurement leading to streak-artifacts if unaccounted for. Current methods do not make full use of the domain-specific information, and hence fail to provide reliable reconstructions for highly undersampled data. We present a novel framework for sparse-view tomography by decoupling the reconstruction into two steps: First, we overcome its ill-posedness using a super-resolution network, SIN, trained on the sparse projections. The intermediate result allows for a closed-form tomographic reconstruction with preserved details and highly reduced streak-artifacts. Second, a refinement network, PRN, trained on the reconstructions reduces any remaining artifacts. We further propose a light-weight variant of the perceptual-loss that enhances domain-specific information, boosting restoration accuracy. Our experiments demonstrate an improvement over current solutions by 4 dB.
Symmetry reduction for deep reinforcement learning active control of chaotic spatiotemporal dynamics
Apr 09, 2021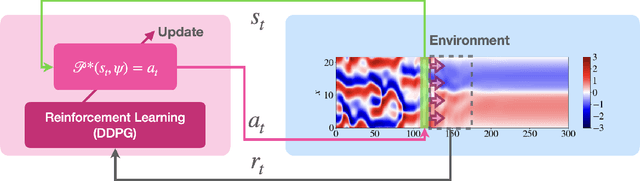
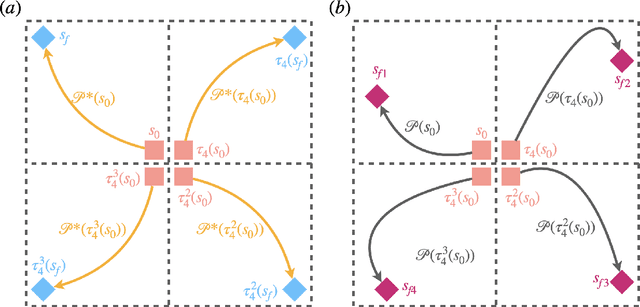
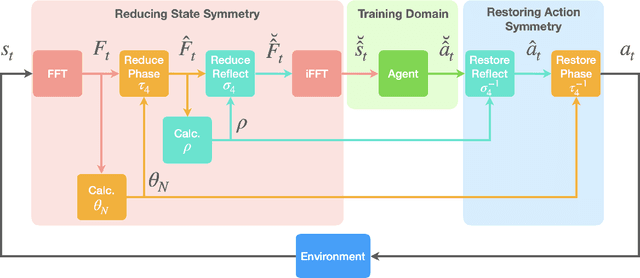
Deep reinforcement learning (RL) is a data-driven, model-free method capable of discovering complex control strategies for macroscopic objectives in high-dimensional systems, making its application towards flow control promising. Many systems of flow control interest possess symmetries that, when neglected, can significantly inhibit the learning and performance of a naive deep RL approach. Using a test-bed consisting of the Kuramoto-Sivashinsky Equation (KSE), equally spaced actuators, and a goal of minimizing dissipation and power cost, we demonstrate that by moving the deep RL problem to a symmetry-reduced space, we can alleviate limitations inherent in the naive application of deep RL. We demonstrate that symmetry-reduced deep RL yields improved data efficiency as well as improved control policy efficacy compared to policies found by naive deep RL. Interestingly, the policy learned by the the symmetry aware control agent drives the system toward an equilibrium state of the forced KSE that is connected by continuation to an equilibrium of the unforced KSE, despite having been given no explicit information regarding its existence. I.e., to achieve its goal, the RL algorithm discovers and stabilizes an equilibrium state of the system. Finally, we demonstrate that the symmetry-reduced control policy is robust to observation and actuation signal noise, as well as to system parameters it has not observed before.
Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
Dec 08, 2020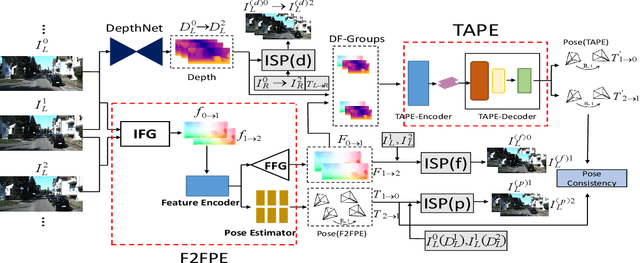
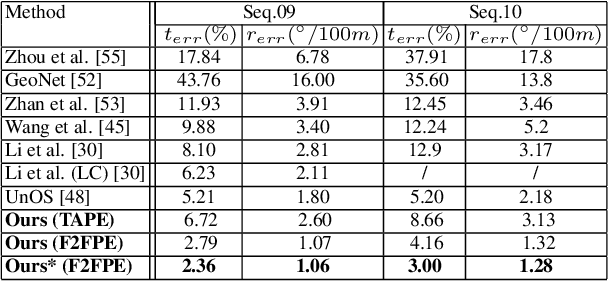
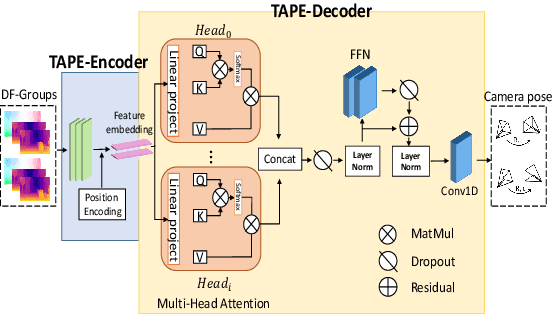
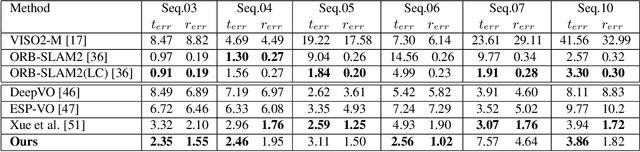
Existing unsupervised visual odometry (VO) methods either match pairwise images or integrate the temporal information using recurrent neural networks over a long sequence of images. They are either not accurate, time-consuming in training or error accumulative. In this paper, we propose a method consisting of two camera pose estimators that deal with the information from pairwise images and a short sequence of images respectively. For image sequences, a Transformer-like structure is adopted to build a geometry model over a local temporal window, referred to as Transformer-based Auxiliary Pose Estimator (TAPE). Meanwhile, a Flow-to-Flow Pose Estimator (F2FPE) is proposed to exploit the relationship between pairwise images. The two estimators are constrained through a simple yet effective consistency loss in training. Empirical evaluation has shown that the proposed method outperforms the state-of-the-art unsupervised learning-based methods by a large margin and performs comparably to supervised and traditional ones on the KITTI and Malaga dataset.
BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond
Dec 03, 2020

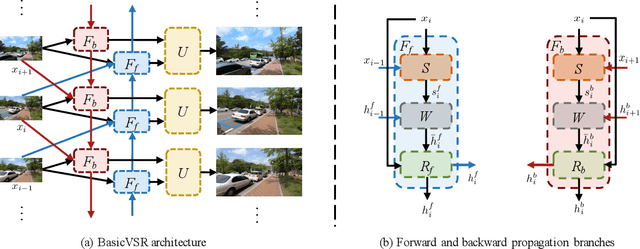
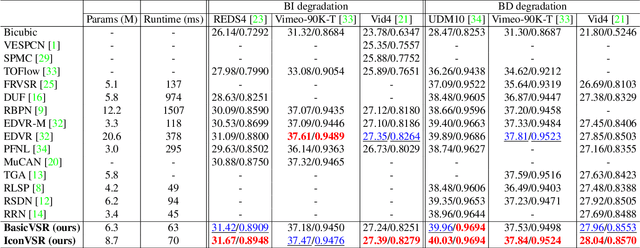
Video super-resolution (VSR) approaches tend to have more components than the image counterparts as they need to exploit the additional temporal dimension. Complex designs are not uncommon. In this study, we wish to untangle the knots and reconsider some most essential components for VSR guided by four basic functionalities, i.e., Propagation, Alignment, Aggregation, and Upsampling. By reusing some existing components added with minimal redesigns, we show a succinct pipeline, BasicVSR, that achieves appealing improvements in terms of speed and restoration quality in comparison to many state-of-the-art algorithms. We conduct systematic analysis to explain how such gain can be obtained and discuss the pitfalls. We further show the extensibility of BasicVSR by presenting an information-refill mechanism and a coupled propagation scheme to facilitate information aggregation. The BasicVSR and its extension, IconVSR, can serve as strong baselines for future VSR approaches.
Relationship-based Neural Baby Talk
Mar 08, 2021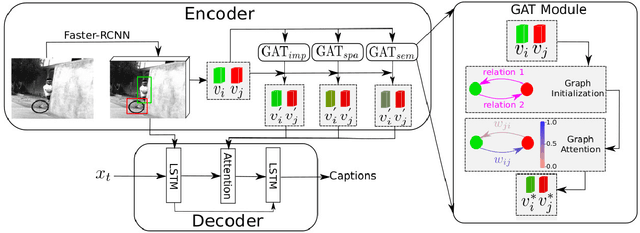
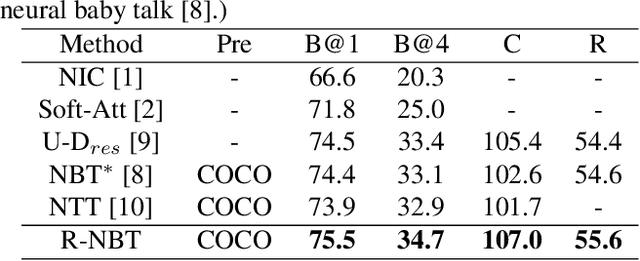
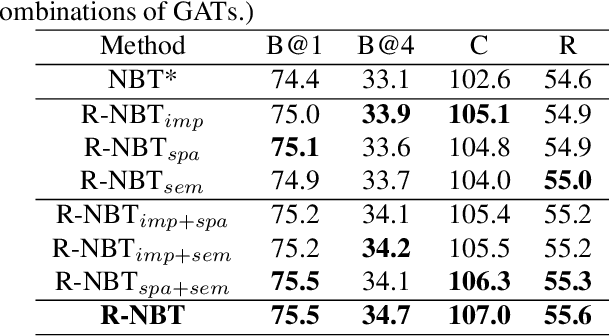

Understanding interactions between objects in an image is an important element for generating captions. In this paper, we propose a relationship-based neural baby talk (R-NBT) model to comprehensively investigate several types of pairwise object interactions by encoding each image via three different relationship-based graph attention networks (GATs). We study three main relationships: \textit{spatial relationships} to explore geometric interactions, \textit{semantic relationships} to extract semantic interactions, and \textit{implicit relationships} to capture hidden information that could not be modelled explicitly as above. We construct three relationship graphs with the objects in an image as nodes, and the mutual relationships of pairwise objects as edges. By exploring features of neighbouring regions individually via GATs, we integrate different types of relationships into visual features of each node. Experiments on COCO dataset show that our proposed R-NBT model outperforms state-of-the-art models trained on COCO dataset in three image caption generation tasks.
Node Proximity Is All You Need: Unified Structural and Positional Node and Graph Embedding
Feb 26, 2021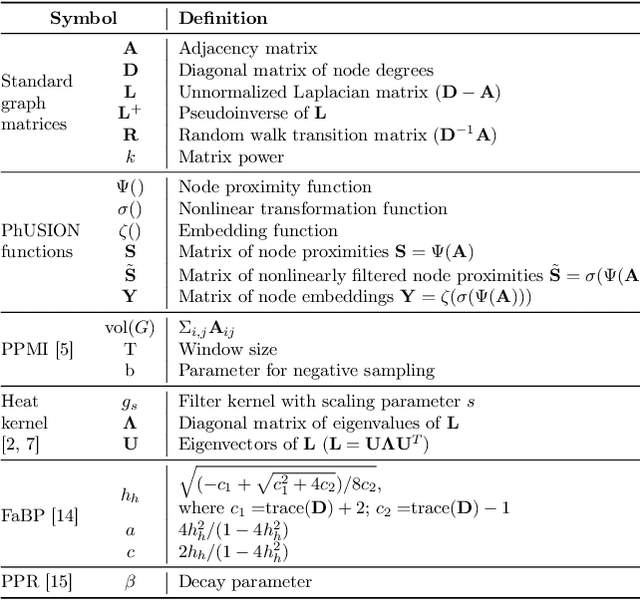
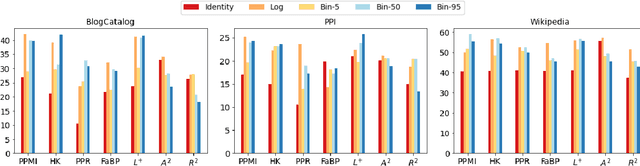
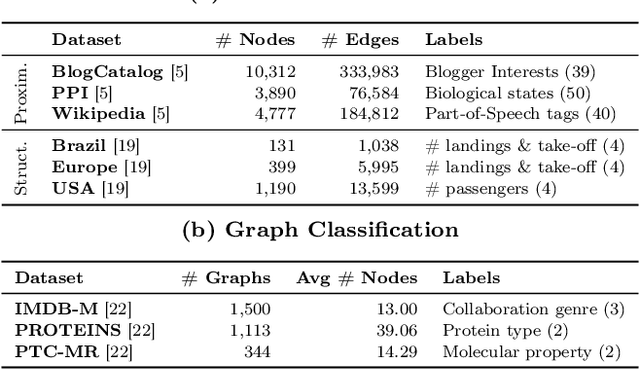
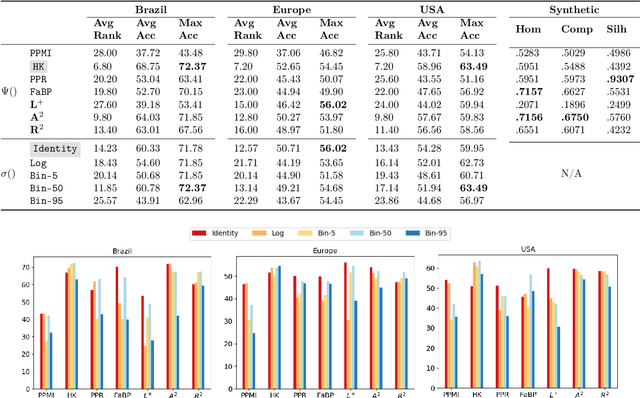
While most network embedding techniques model the relative positions of nodes in a network, recently there has been significant interest in structural embeddings that model node role equivalences, irrespective of their distances to any specific nodes. We present PhUSION, a proximity-based unified framework for computing structural and positional node embeddings, which leverages well-established methods for calculating node proximity scores. Clarifying a point of contention in the literature, we show which step of PhUSION produces the different kinds of embeddings and what steps can be used by both. Moreover, by aggregating the PhUSION node embeddings, we obtain graph-level features that model information lost by previous graph feature learning and kernel methods. In a comprehensive empirical study with over 10 datasets, 4 tasks, and 35 methods, we systematically reveal successful design choices for node and graph-level machine learning with embeddings.
Smartphone Impostor Detection with Behavioral Data Privacy and Minimalist Hardware Support
Mar 17, 2021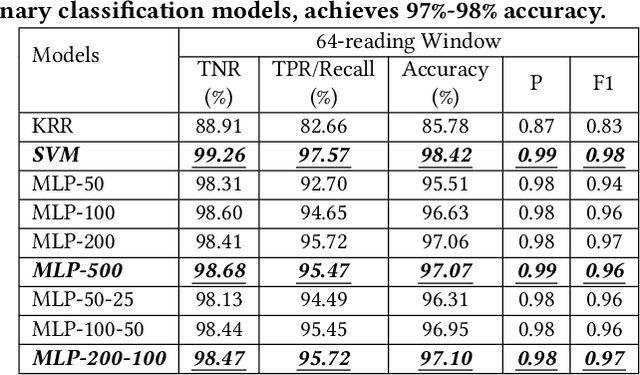
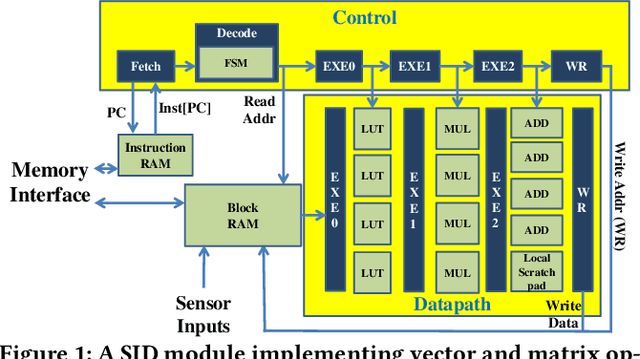
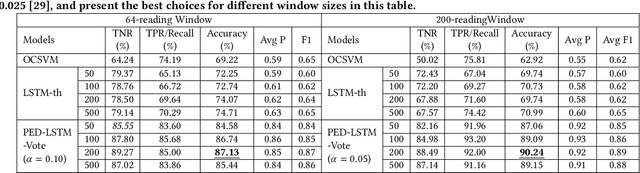
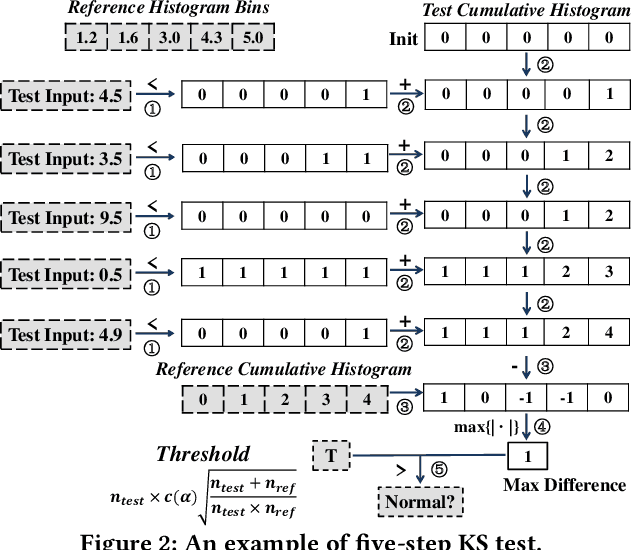
Impostors are attackers who take over a smartphone and gain access to the legitimate user's confidential and private information. This paper proposes a defense-in-depth mechanism to detect impostors quickly with simple Deep Learning algorithms, which can achieve better detection accuracy than the best prior work which used Machine Learning algorithms requiring computation of multiple features. Different from previous work, we then consider protecting the privacy of a user's behavioral (sensor) data by not exposing it outside the smartphone. For this scenario, we propose a Recurrent Neural Network (RNN) based Deep Learning algorithm that uses only the legitimate user's sensor data to learn his/her normal behavior. We propose to use Prediction Error Distribution (PED) to enhance the detection accuracy. We also show how a minimalist hardware module, dubbed SID for Smartphone Impostor Detector, can be designed and integrated into smartphones for self-contained impostor detection. Experimental results show that SID can support real-time impostor detection, at a very low hardware cost and energy consumption, compared to other RNN accelerators.
FGAGT: Flow-Guided Adaptive Graph Tracking
Nov 04, 2020
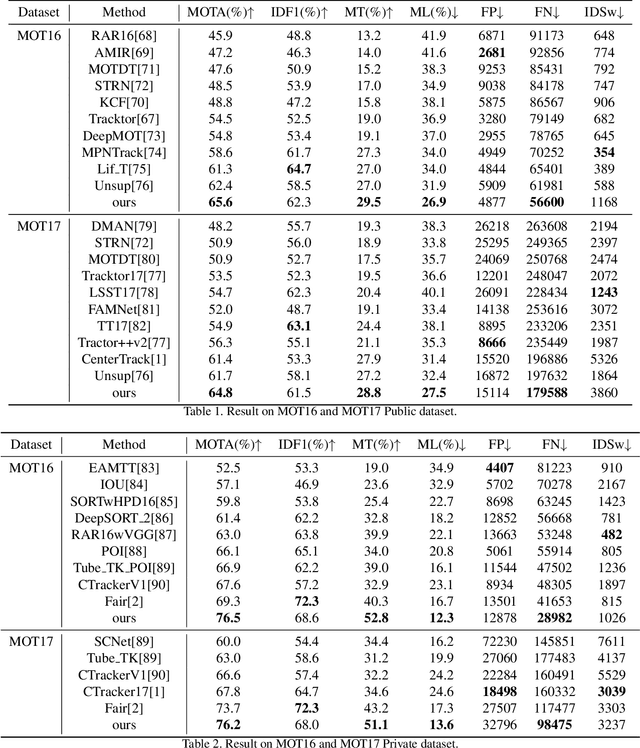
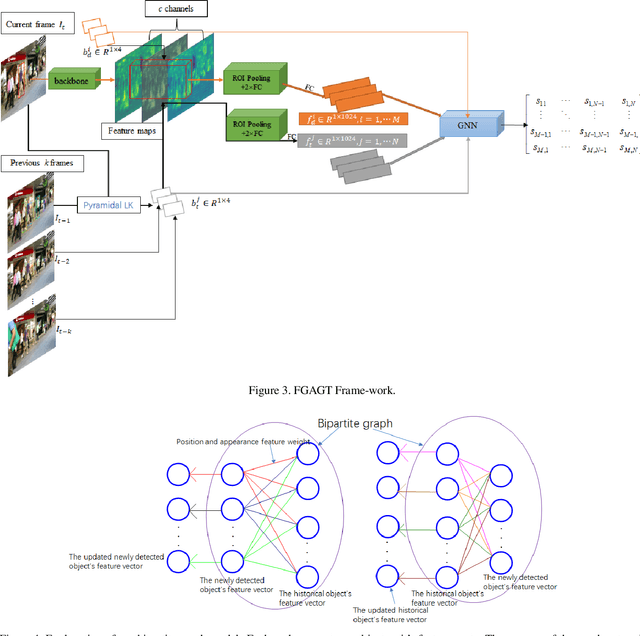
Most previous tracking methods usually use the optical flow method to estimate the position of the historical object in the current frame and then use the linear combination of feature similarity and IOU(Intersection over Union) to perform association matching near the position. However, the features used in these methods are not aligned, i.e., the features of the historical objects are extracted from the historical feature maps, not from the current frame, even the same object may undergo posture, angle, etc. changes during the movement, and even light intensity changes. In addition, most methods only use the appearance information when extracting the feature vector, not the position relationship, nor the feature information of the historical object, so the information is not fully utilized. In order to solve the above problems, we proposed the FGAGT tracker, which uses the optical flow method to predict the center position of the historical object in the current frame and extract the feature vector, so that the feature of the historical object can be aligned with the feature of the object in the current frame. Then these features are input into the graph neural network, and the global Spatio-temporal position and appearance information are integrated to update the feature vectors of all objects. In the training phase, we propose the Balanced MSE LOSS to balance the sample distribution for data association. Experiments show that our method reaches the level of state-of-the-art, where the MOTA index exceeds FairMOT by 2.5 points, and CenterTrack by 8.4 points on the MOT17 dataset, exceeds FairMOT by 1.6 points on the MOT16 dataset. Code will be avaliable.