 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AxonNet: A self-supervised Deep Neural Network for Intravoxel Structure Estimation from DW-MRI
Mar 19, 2021
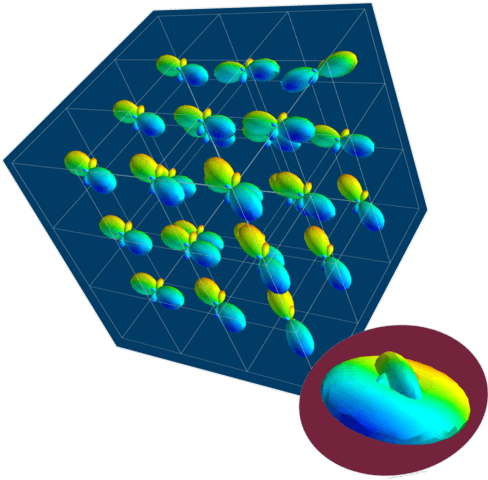
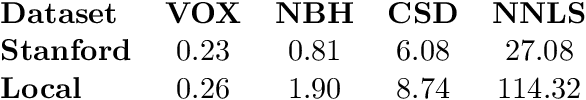
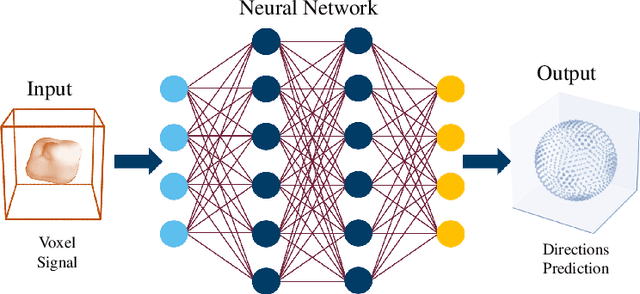
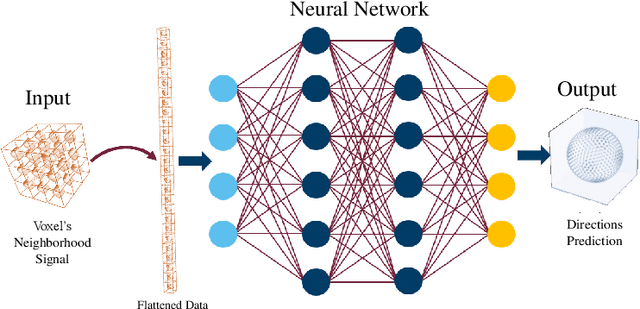
We present a method for estimating intravoxel parameters from a DW-MRI based on deep learning techniques. We show that neural networks (DNNs) have the potential to extract information from diffusion-weighted signals to reconstruct cerebral tracts. We present two DNN models: one that estimates the axonal structure in the form of a voxel and the other to calculate the structure of the central voxel using the voxel neighborhood. Our methods are based on a proposed parameter representation suitable for the problem. Since it is practically impossible to have real tagged data for any acquisition protocol, we used a self-supervised strategy. Experiments with synthetic data and real data show that our approach is competitive, and the computational times show that our approach is faster than the SOTA methods, even if training times are considered. This computational advantage increases if we consider the prediction of multiple images with the same acquisition protocol.
"How to rate a video game?" - A prediction system for video games based on multimodal information
May 29, 2018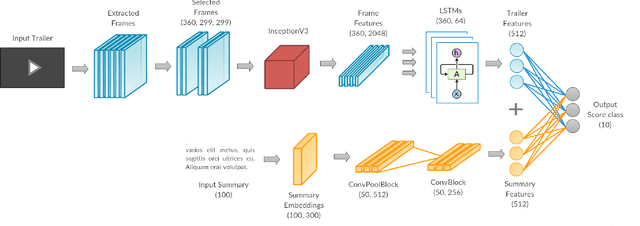
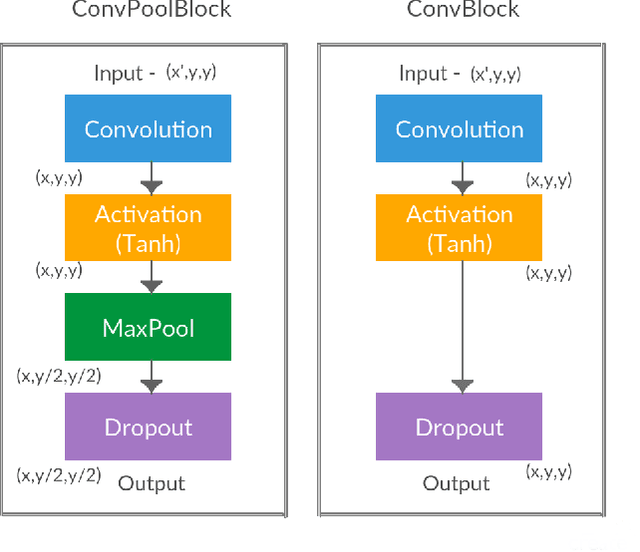

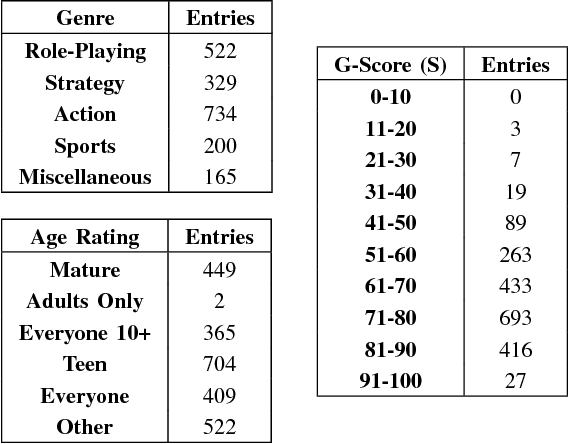
Video games have become an integral part of most people's lives in recent times. This led to an abundance of data related to video games being shared online. However, this comes with issues such as incorrect ratings, reviews or anything that is being shared. Recommendation systems are powerful tools that help users by providing them with meaningful recommendations. A straightforward approach would be to predict the scores of video games based on other information related to the game. It could be used as a means to validate user-submitted ratings as well as provide recommendations. This work provides a method to predict the G-Score, that defines how good a video game is, from its trailer (video) and summary (text). We first propose models to predict the G-Score based on the trailer alone (unimodal). Later on, we show that considering information from multiple modalities helps the models perform better compared to using information from videos alone. Since we couldn't find any suitable multimodal video game dataset, we created our own dataset named VGD (Video Game Dataset) and provide it along with this work. The approach mentioned here can be generalized to other multimodal datasets such as movie trailers and summaries etc. Towards the end, we talk about the shortcomings of the work and some methods to overcome them.
3D Registration of Curves and Surfaces using Local Differential Information
Apr 02, 2018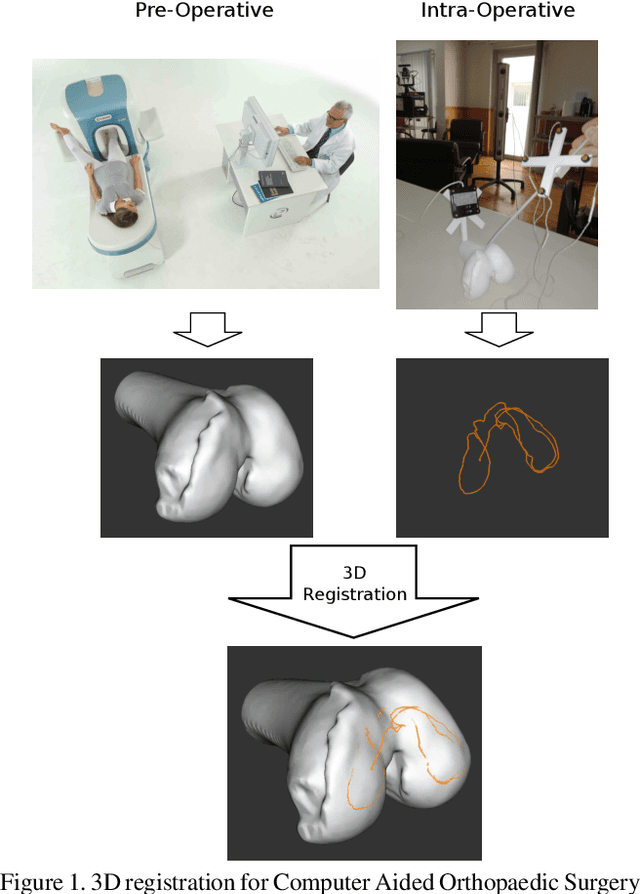
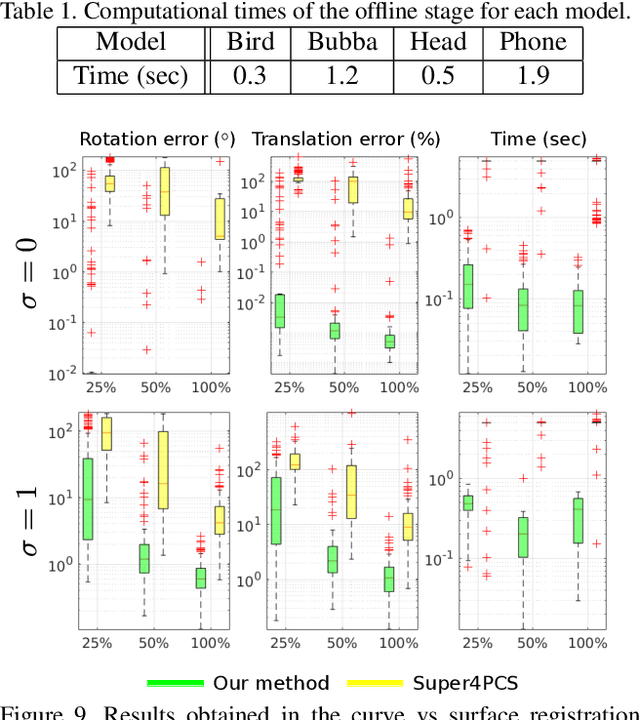

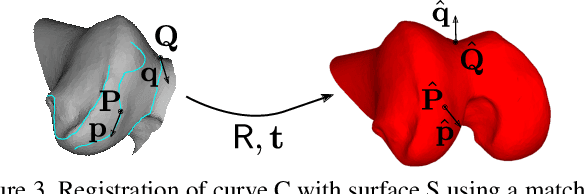
This article presents for the first time a global method for registering 3D curves with 3D surfaces without requiring an initialization. The algorithm works with 2-tuples point+vector that consist in pairs of points augmented with the information of their tangents or normals. A closed-form solution for determining the alignment transformation from a pair of matching 2-tuples is proposed. In addition, the set of necessary conditions for two 2-tuples to match is derived. This allows fast search of correspondences that are used in an hypothesise-and-test framework for accomplishing global registration. Comparative experiments demonstrate that the proposed algorithm is the first effective solution for curve vs surface registration, with the method achieving accurate alignment in situations of small overlap and large percentage of outliers in a fraction of a second. The proposed framework is extended to the cases of curve vs curve and surface vs surface registration, with the former being particularly relevant since it is also a largely unsolved problem.
Design of a vision based range bearing and heading system for robot swarms
Mar 14, 2021An essential problem of swarm robotics is how members of the swarm knows the positions of other robots. The main aim of this research is to develop a cost-effective and simple vision-based system to detect the range, bearing, and heading of the robots inside a swarm using a multi-purpose passive landmark. A small Zumo robot equipped with Raspberry Pi, PiCamera is utilized for the implementation of the algorithm, and different kinds of multipurpose passive landmarks with nonsymmetrical patterns, which give reliable information about the range, bearing and heading in a single unit, are designed. By comparing the recorded features obtained from image analysis of the landmark through systematical experimentation and the actual measurements, correlations are obtained, and algorithms converting those features into range, bearing and heading are designed. The reliability and accuracy of algorithms are tested and errors are found within an acceptable range.
Cross-lingual Word Sense Disambiguation using mBERT Embeddings with Syntactic Dependencies
Dec 09, 2020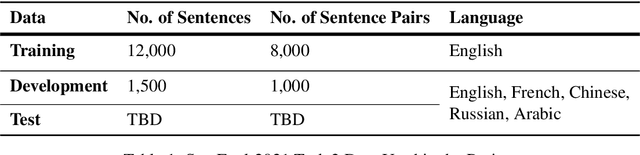
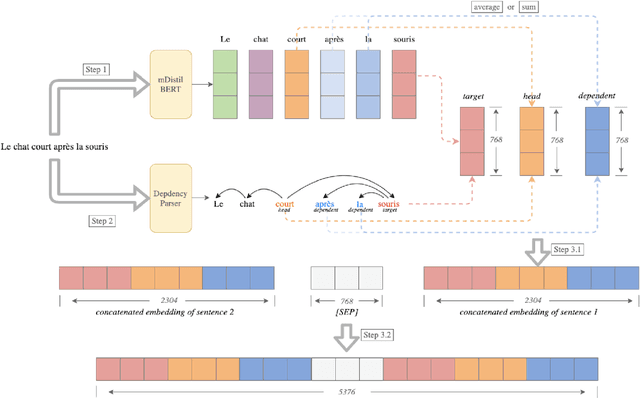
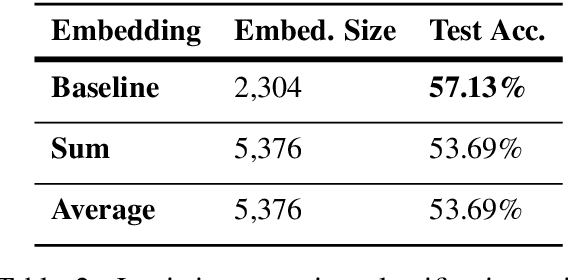
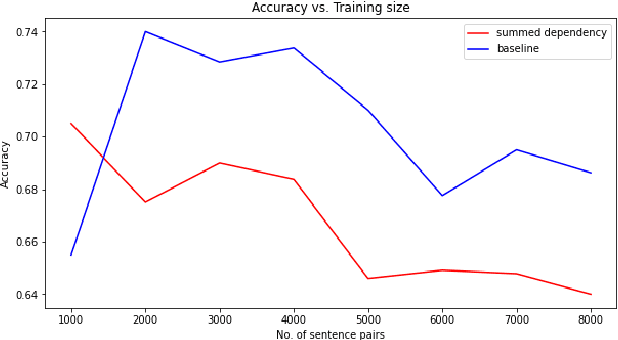
Cross-lingual word sense disambiguation (WSD) tackles the challenge of disambiguating ambiguous words across languages given context. The pre-trained BERT embedding model has been proven to be effective in extracting contextual information of words, and have been incorporated as features into many state-of-the-art WSD systems. In order to investigate how syntactic information can be added into the BERT embeddings to result in both semantics- and syntax-incorporated word embeddings, this project proposes the concatenated embeddings by producing dependency parse tress and encoding the relative relationships of words into the input embeddings. Two methods are also proposed to reduce the size of the concatenated embeddings. The experimental results show that the high dimensionality of the syntax-incorporated embeddings constitute an obstacle for the classification task, which needs to be further addressed in future studies.
Recent Advances in Deep Learning-based Dialogue Systems
May 13, 2021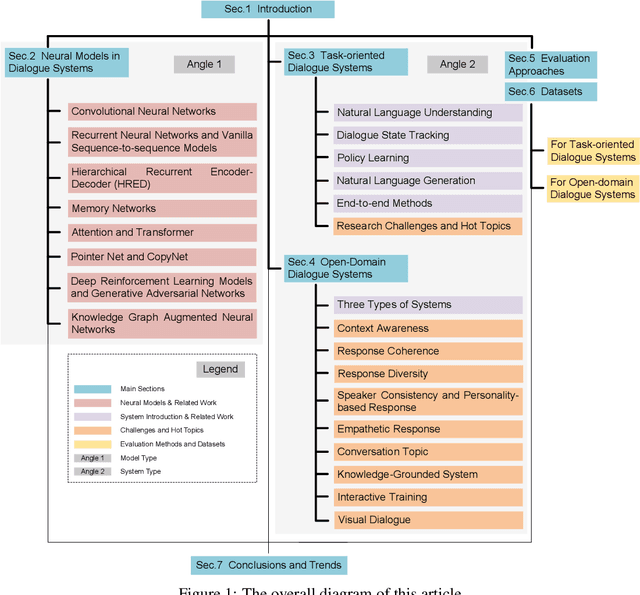
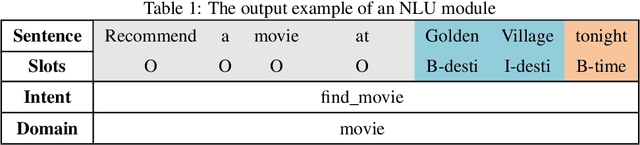
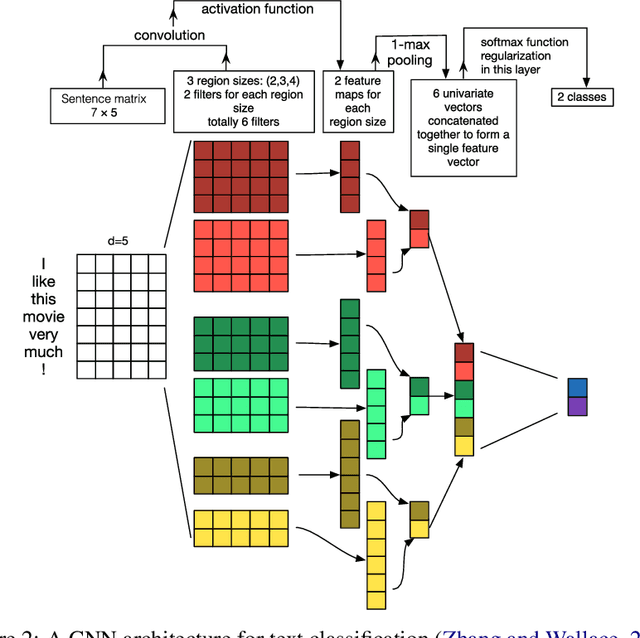
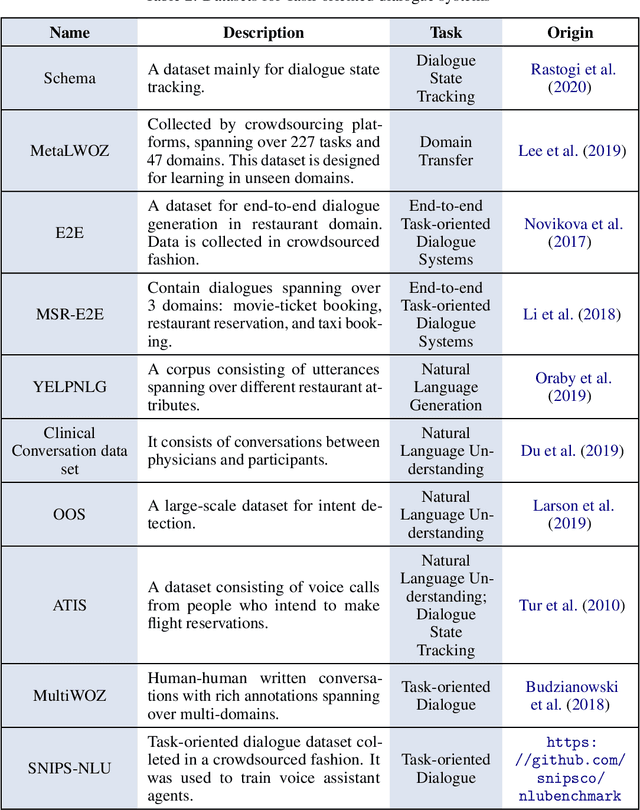
Dialogue systems are a popular Natural Language Processing (NLP) task as it is promising in real-life applications. It is also a complicated task since many NLP tasks deserving study are involved. As a result, a multitude of novel works on this task are carried out, and most of them are deep learning-based due to the outstanding performance. In this survey, we mainly focus on the deep learning-based dialogue systems. We comprehensively review state-of-the-art research outcomes in dialogue systems and analyze them from two angles: model type and system type. Specifically, from the angle of model type, we discuss the principles, characteristics, and applications of different models that are widely used in dialogue systems. This will help researchers acquaint these models and see how they are applied in state-of-the-art frameworks, which is rather helpful when designing a new dialogue system. From the angle of system type, we discuss task-oriented and open-domain dialogue systems as two streams of research, providing insight into the hot topics related. Furthermore, we comprehensively review the evaluation methods and datasets for dialogue systems to pave the way for future research. Finally, some possible research trends are identified based on the recent research outcomes. To the best of our knowledge, this survey is the most comprehensive and up-to-date one at present in the area of dialogue systems and dialogue-related tasks, extensively covering the popular frameworks, topics, and datasets. Keywords: Dialogue Systems, Chatbots, Conversational AI, Task-oriented, Open Domain, Chit-chat, Question Answering, Artificial Intelligence, Natural Language Processing, Information Retrieval, Deep Learning, Neural Networks, CNN, RNN, Hierarchical Recurrent Encoder-Decoder, Memory Networks, Attention, Transformer, Pointer Net, CopyNet, Reinforcement Learning, GANs, Knowledge Graph, Survey, Review
Semantic Analysis for Automated Evaluation of the Potential Impact of Research Articles
Apr 26, 2021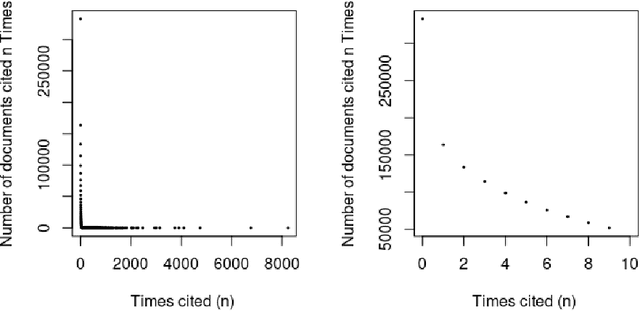
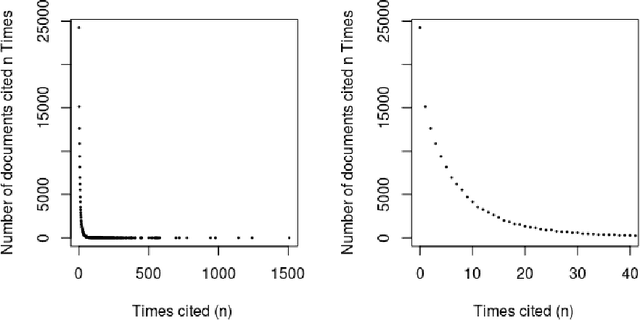
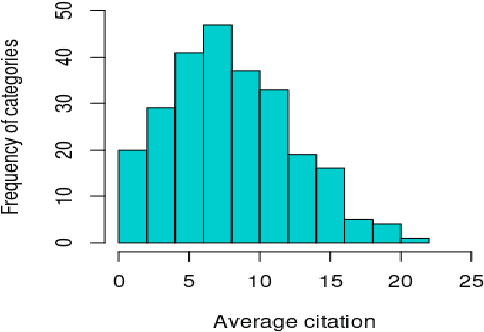
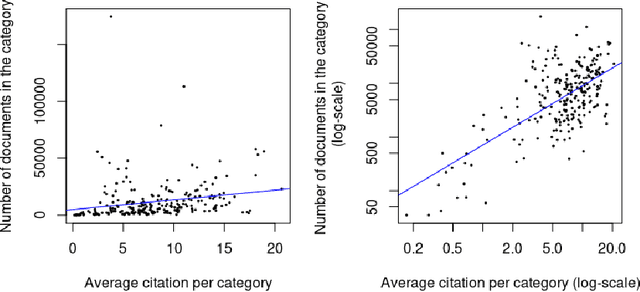
Can the analysis of the semantics of words used in the text of a scientific paper predict its future impact measured by citations? This study details examples of automated text classification that achieved 80% success rate in distinguishing between highly-cited and little-cited articles. Automated intelligent systems allow the identification of promising works that could become influential in the scientific community. The problems of quantifying the meaning of texts and representation of human language have been clear since the inception of Natural Language Processing. This paper presents a novel method for vector representation of text meaning based on information theory and show how this informational semantics is used for text classification on the basis of the Leicester Scientific Corpus. We describe the experimental framework used to evaluate the impact of scientific articles through their informational semantics. Our interest is in citation classification to discover how important semantics of texts are in predicting the citation count. We propose the semantics of texts as an important factor for citation prediction. For each article, our system extracts the abstract of paper, represents the words of the abstract as vectors in Meaning Space, automatically analyses the distribution of scientific categories (Web of Science categories) within the text of abstract, and then classifies papers according to citation counts (highly-cited, little-cited). We show that an informational approach to representing the meaning of a text has offered a way to effectively predict the scientific impact of research papers.
MultiModalQA: Complex Question Answering over Text, Tables and Images
Apr 13, 2021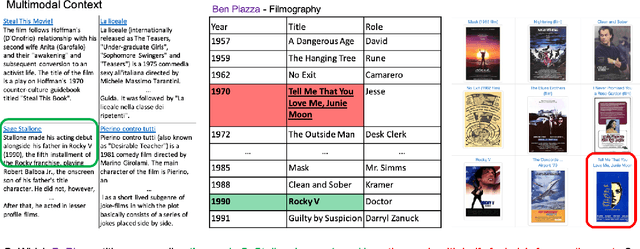
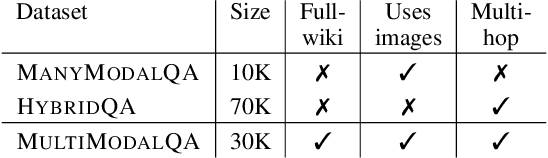

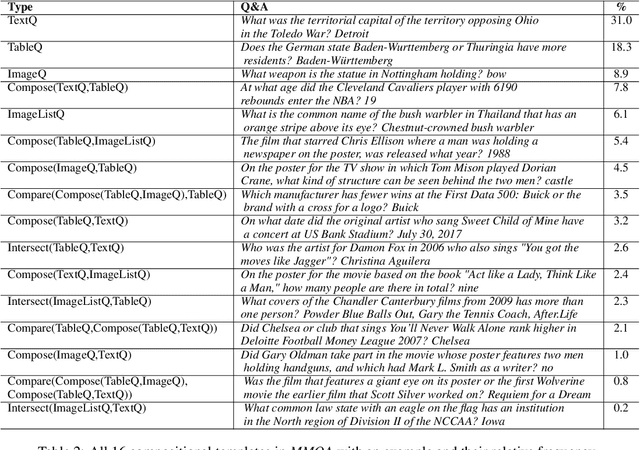
When answering complex questions, people can seamlessly combine information from visual, textual and tabular sources. While interest in models that reason over multiple pieces of evidence has surged in recent years, there has been relatively little work on question answering models that reason across multiple modalities. In this paper, we present MultiModalQA(MMQA): a challenging question answering dataset that requires joint reasoning over text, tables and images. We create MMQA using a new framework for generating complex multi-modal questions at scale, harvesting tables from Wikipedia, and attaching images and text paragraphs using entities that appear in each table. We then define a formal language that allows us to take questions that can be answered from a single modality, and combine them to generate cross-modal questions. Last, crowdsourcing workers take these automatically-generated questions and rephrase them into more fluent language. We create 29,918 questions through this procedure, and empirically demonstrate the necessity of a multi-modal multi-hop approach to solve our task: our multi-hop model, ImplicitDecomp, achieves an average F1of 51.7 over cross-modal questions, substantially outperforming a strong baseline that achieves 38.2 F1, but still lags significantly behind human performance, which is at 90.1 F1
Semi-Automatic Video Annotation For Object Detection
Jan 24, 2021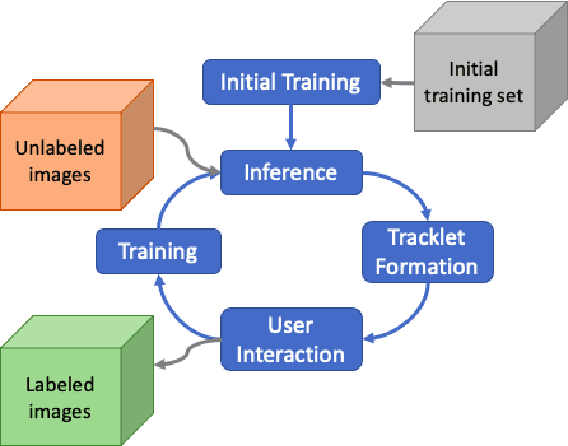
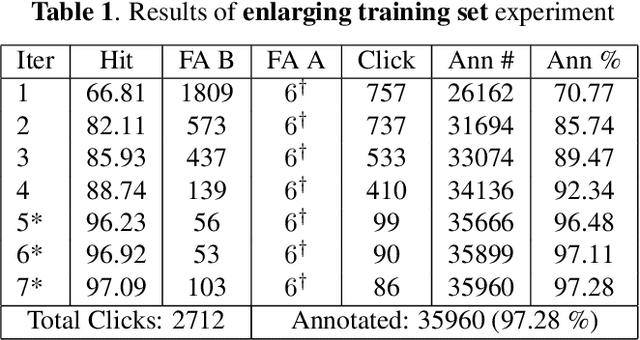

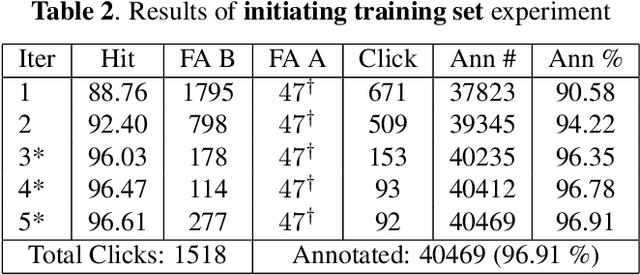
In this study, a semi-automatic video annotation method is proposed which utilizes temporal information to eliminate false-positives with a tracking-by-detection approach by employing multiple hypothesis tracking (MHT). MHT method automatically forms tracklets which are confirmed by human operators to enlarge the training set. A novel incremental learning approach helps to annotate videos in an iterative way. The experiments performed on AUTH Multidrone Dataset reveals that the annotation workload can be reduced up to 96% by the proposed approach.
On the Acceleration of L-BFGS with Second-Order Information and Stochastic Batches
Jul 14, 2018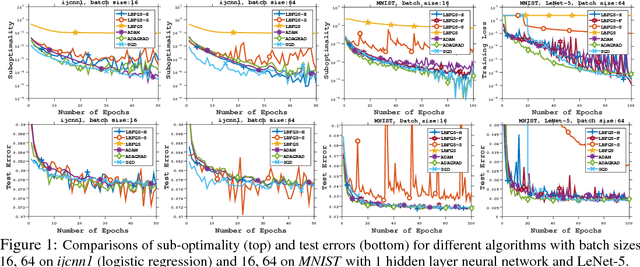
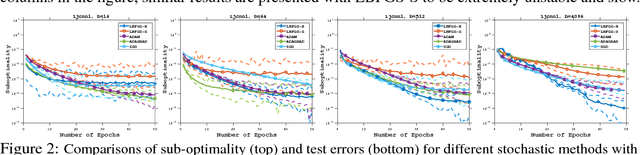
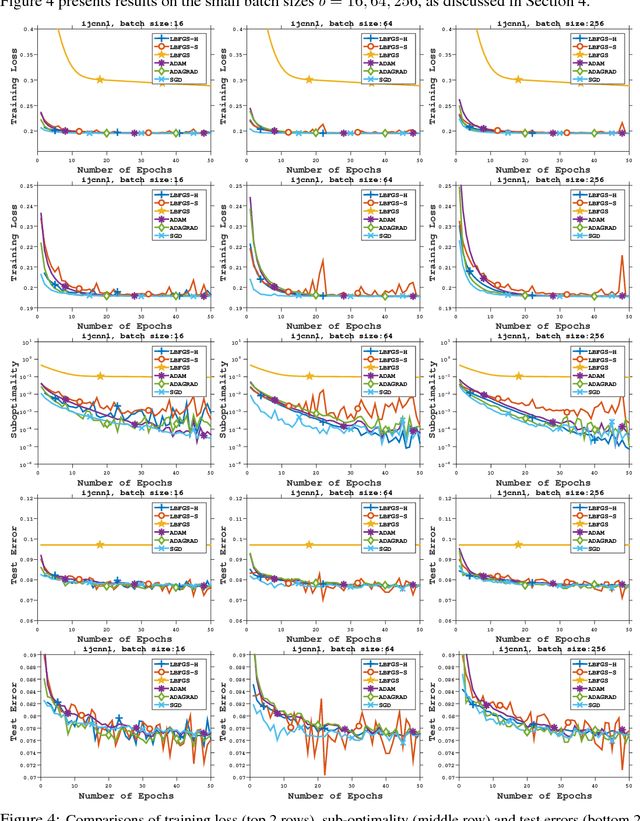
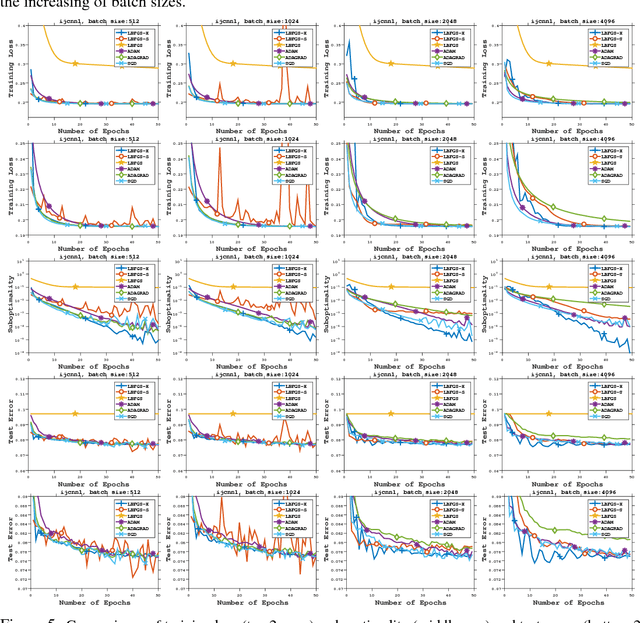
This paper proposes a framework of L-BFGS based on the (approximate) second-order information with stochastic batches, as a novel approach to the finite-sum minimization problems. Different from the classical L-BFGS where stochastic batches lead to instability, we use a smooth estimate for the evaluations of the gradient differences while achieving acceleration by well-scaling the initial Hessians. We provide theoretical analyses for both convex and nonconvex cases. In addition, we demonstrate that within the popular applications of least-square and cross-entropy losses, the algorithm admits a simple implementation in the distributed environment. Numerical experiments support the efficiency of our algorithms.