 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Proceedings of NeurIPS 2020 Workshop on Artificial Intelligence for Humanitarian Assistance and Disaster Response
Dec 08, 2020
These are the "proceedings" of the 2nd AI + HADR workshop which was held virtually on December 12, 2020 as part of the Neural Information Processing Systems conference. These are non-archival and merely serve as a way to collate all the papers accepted to the workshop.
Federated $f$-Differential Privacy
Feb 22, 2021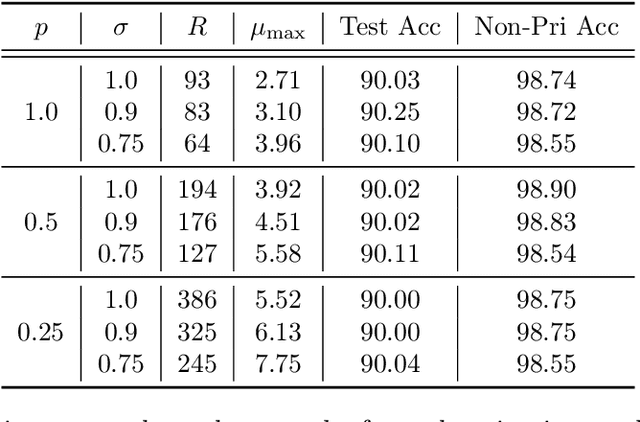
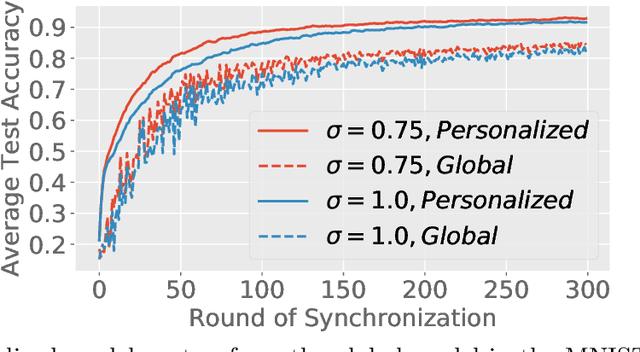
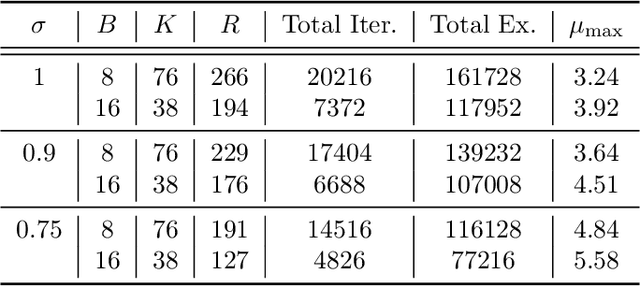
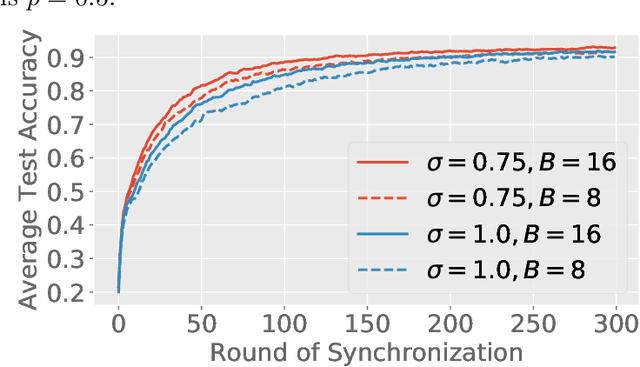
Federated learning (FL) is a training paradigm where the clients collaboratively learn models by repeatedly sharing information without compromising much on the privacy of their local sensitive data. In this paper, we introduce federated $f$-differential privacy, a new notion specifically tailored to the federated setting, based on the framework of Gaussian differential privacy. Federated $f$-differential privacy operates on record level: it provides the privacy guarantee on each individual record of one client's data against adversaries. We then propose a generic private federated learning framework {PriFedSync} that accommodates a large family of state-of-the-art FL algorithms, which provably achieves federated $f$-differential privacy. Finally, we empirically demonstrate the trade-off between privacy guarantee and prediction performance for models trained by {PriFedSync} in computer vision tasks.
Spectrum Congruency of Multiscale Local Patches for Edge Detection
Mar 10, 2021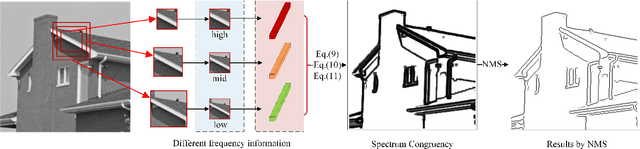

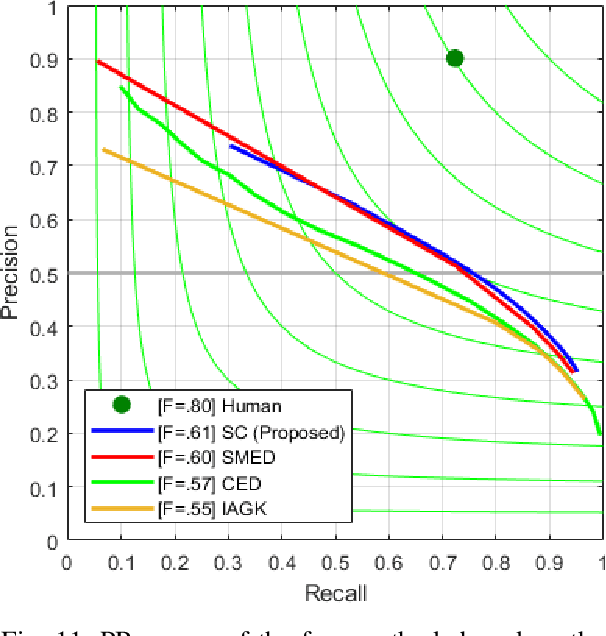
This paper proposes a novel feature called spectrum congruency for describing edges in images. The spectrum congruency is a generalization of the phase congruency, which depicts how much each Fourier components of the image are congruent in phase. Instead of using fixed bases in phase congruency, the spectrum congruency measures the congruency of the energy distribution of multiscale patches in a data-driven transform domain, which is more adaptable to the input images. Multiscale image patches are used to acquire different frequency components for modeling the local energy and amplitude. The spectrum congruency coincides nicely with human visions of perceiving features and provides a more reliable way of detecting edges. Unlike most existing differential-based multiscale edge detectors which simply combine the multiscale information, our method focuses on exploiting the correlation of the multiscale patches based on their local energy. We test our proposed method on synthetic and real images, and the results demonstrate that our approach is practical and highly robust to noise.
LexNLP: Natural language processing and information extraction for legal and regulatory texts
Jun 10, 2018LexNLP is an open source Python package focused on natural language processing and machine learning for legal and regulatory text. The package includes functionality to (i) segment documents, (ii) identify key text such as titles and section headings, (iii) extract over eighteen types of structured information like distances and dates, (iv) extract named entities such as companies and geopolitical entities, (v) transform text into features for model training, and (vi) build unsupervised and supervised models such as word embedding or tagging models. LexNLP includes pre-trained models based on thousands of unit tests drawn from real documents available from the SEC EDGAR database as well as various judicial and regulatory proceedings. LexNLP is designed for use in both academic research and industrial applications, and is distributed at https://github.com/LexPredict/lexpredict-lexnlp.
MoG-QSM: Model-based Generative Adversarial Deep Learning Network for Quantitative Susceptibility Mapping
Jan 21, 2021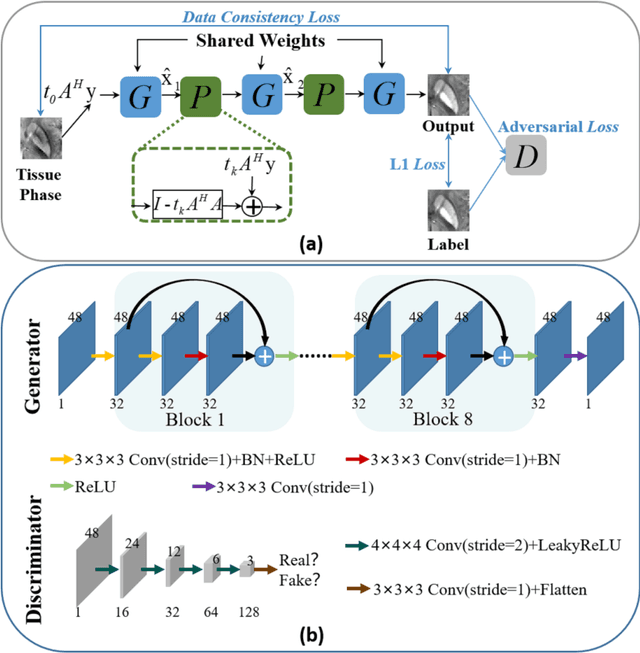
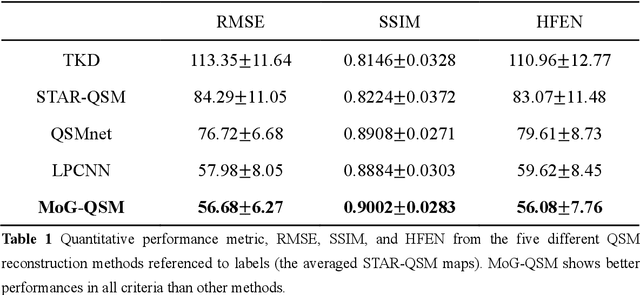
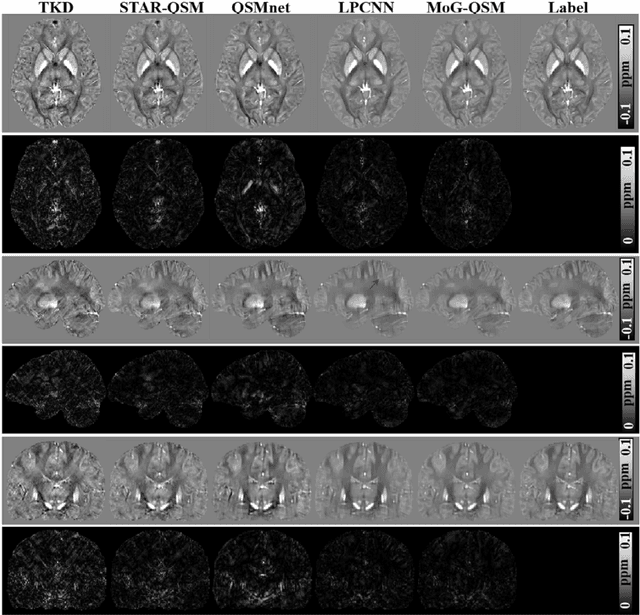
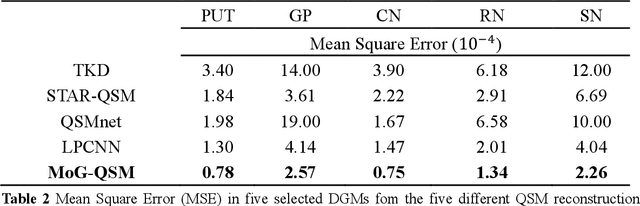
Quantitative susceptibility mapping (QSM) estimates the underlying tissue magnetic susceptibility from the MRI gradient-echo phase signal and has demonstrated great potential in quantifying tissue susceptibility in various brain diseases. However, the intrinsic ill-posed inverse problem relating the tissue phase to the underlying susceptibility distribution affects the accuracy for quantifying tissue susceptibility. The resulting susceptibility map is known to suffer from noise amplification and streaking artifacts. To address these challenges, we propose a model-based framework that permeates benefits from generative adversarial networks to train a regularization term that contains prior information to constrain the solution of the inverse problem, referred to as MoG-QSM. A residual network leveraging a mixture of least-squares (LS) GAN and the L1 cost was trained as the generator to learn the prior information in susceptibility maps. A multilayer convolutional neural network was jointly trained to discriminate the quality of output images. MoG-QSM generates highly accurate susceptibility maps from single orientation phase maps. Quantitative evaluation parameters were compared with recently developed deep learning QSM methods and the results showed MoG-QSM achieves the best performance. Furthermore, a higher intraclass correlation coefficient (ICC) was obtained from MoG-QSM maps of the traveling subjects, demonstrating its potential for future applications, such as large cohorts of multi-center studies. MoG-QSM is also helpful for reliable longitudinal measurement of susceptibility time courses, enabling more precise monitoring for metal ion accumulation in neurodegenerative disorders.
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
Mar 27, 2021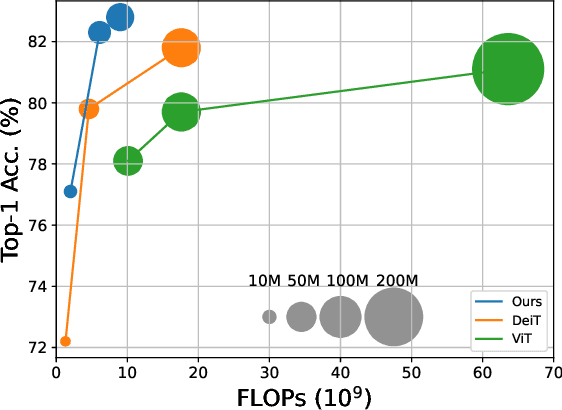
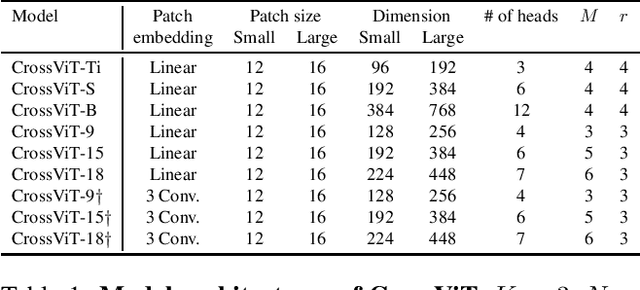
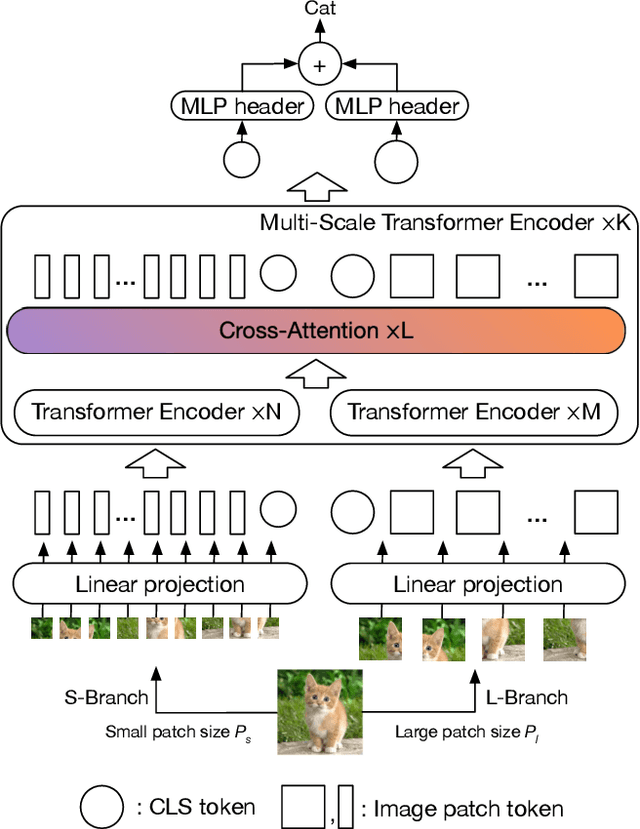
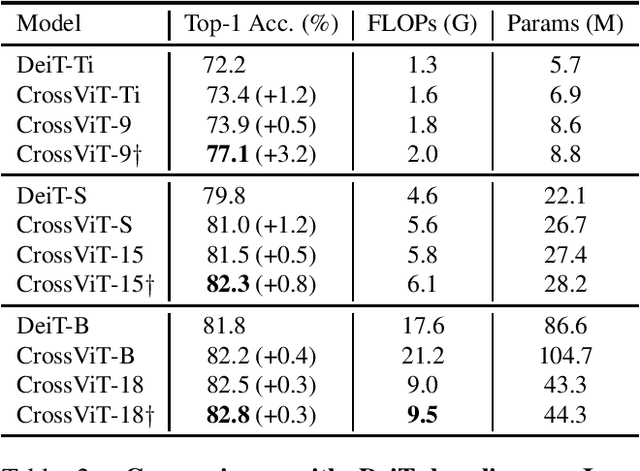
The recently developed vision transformer (ViT) has achieved promising results on image classification compared to convolutional neural networks. Inspired by this, in this paper, we study how to learn multi-scale feature representations in transformer models for image classification. To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features. Our approach processes small-patch and large-patch tokens with two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. Furthermore, to reduce computation, we develop a simple yet effective token fusion module based on cross attention, which uses a single token for each branch as a query to exchange information with other branches. Our proposed cross-attention only requires linear time for both computational and memory complexity instead of quadratic time otherwise. Extensive experiments demonstrate that the proposed approach performs better than or on par with several concurrent works on vision transformer, in addition to efficient CNN models. For example, on the ImageNet1K dataset, with some architectural changes, our approach outperforms the recent DeiT by a large margin of 2\%
Deep Variational Autoencoder with Shallow Parallel Path for Top-N Recommendation (VASP)
Feb 10, 2021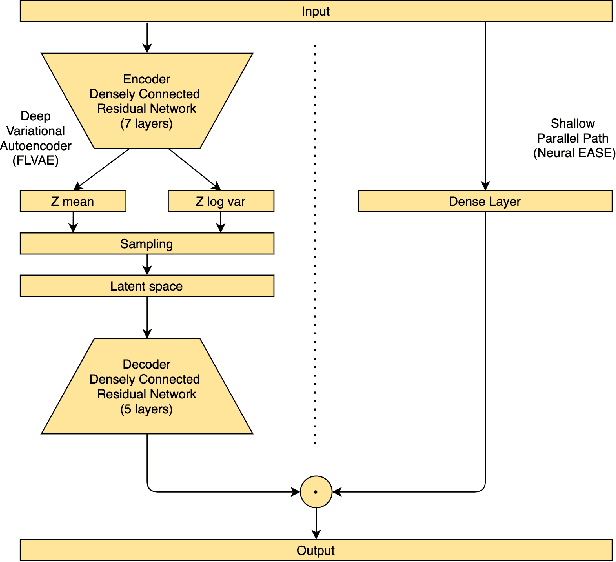
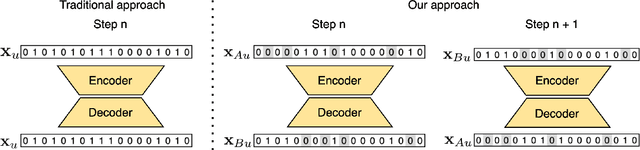

Recently introduced EASE algorithm presents a simple and elegant way, how to solve the top-N recommendation task. In this paper, we introduce Neural EASE to further improve the performance of this algorithm by incorporating techniques for training modern neural networks. Also, there is a growing interest in the recsys community to utilize variational autoencoders (VAE) for this task. We introduce deep autoencoder FLVAE benefiting from multiple non-linear layers without an information bottleneck while not overfitting towards the identity. We show how to learn FLVAE in parallel with Neural EASE and achieve the state of the art performance on the MovieLens 20M dataset and competitive results on the Netflix Prize dataset.
Knowledge-guided Open Attribute Value Extraction with Reinforcement Learning
Oct 19, 2020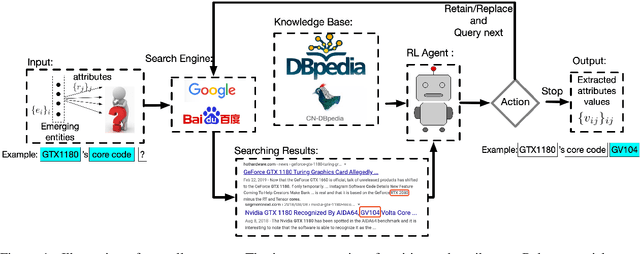
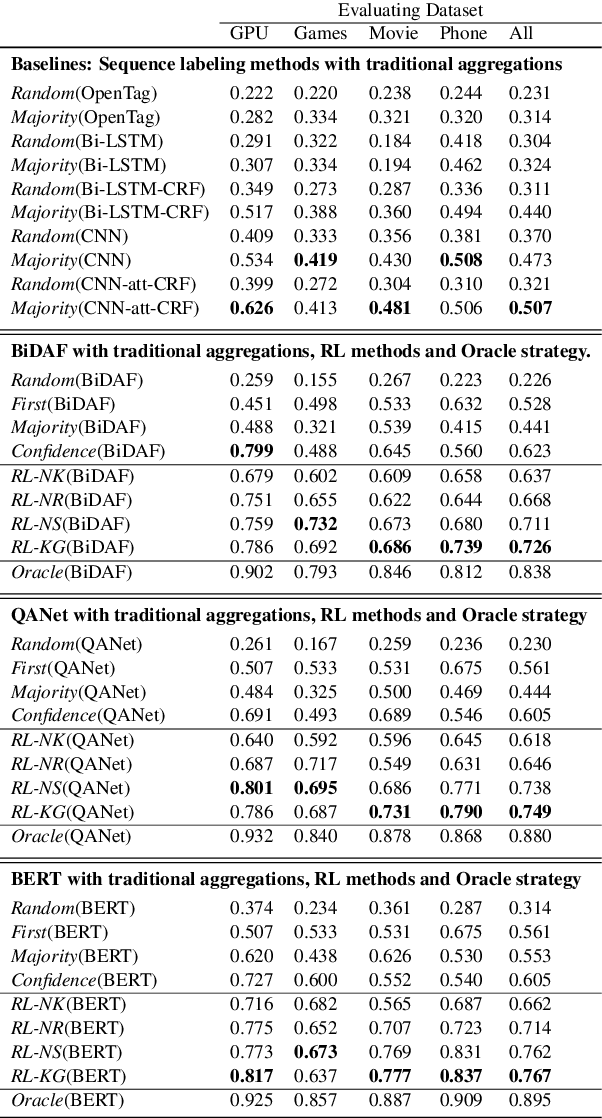
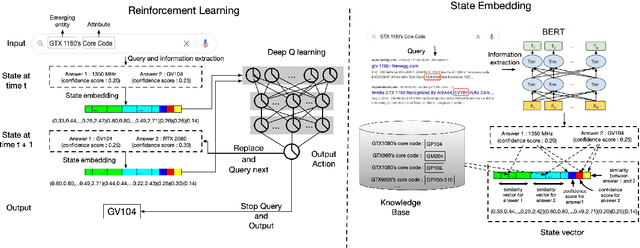

Open attribute value extraction for emerging entities is an important but challenging task. A lot of previous works formulate the problem as a \textit{question-answering} (QA) task. While the collections of articles from web corpus provide updated information about the emerging entities, the retrieved texts can be noisy, irrelevant, thus leading to inaccurate answers. Effectively filtering out noisy articles as well as bad answers is the key to improving extraction accuracy. Knowledge graph (KG), which contains rich, well organized information about entities, provides a good resource to address the challenge. In this work, we propose a knowledge-guided reinforcement learning (RL) framework for open attribute value extraction. Informed by relevant knowledge in KG, we trained a deep Q-network to sequentially compare extracted answers to improve extraction accuracy. The proposed framework is applicable to different information extraction system. Our experimental results show that our method outperforms the baselines by 16.5 - 27.8\%.
Learning Purified Feature Representations from Task-irrelevant Labels
Feb 22, 2021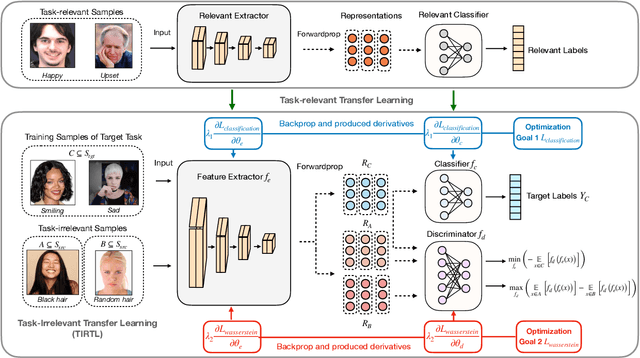
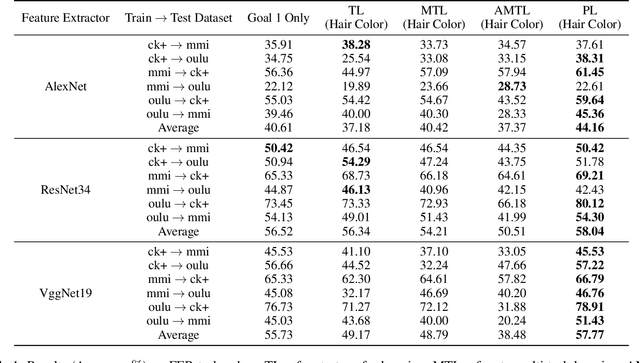
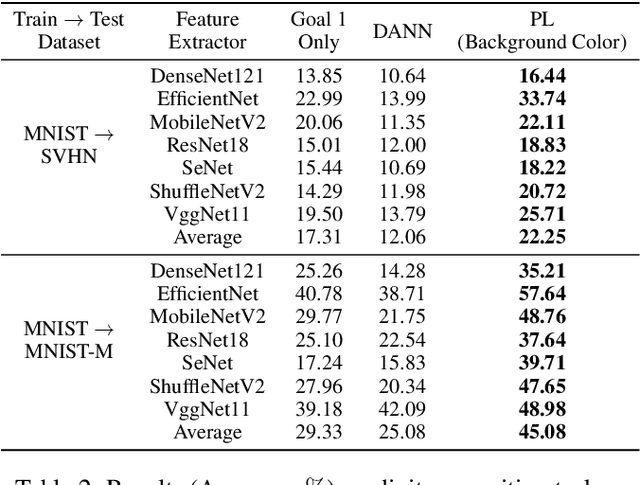
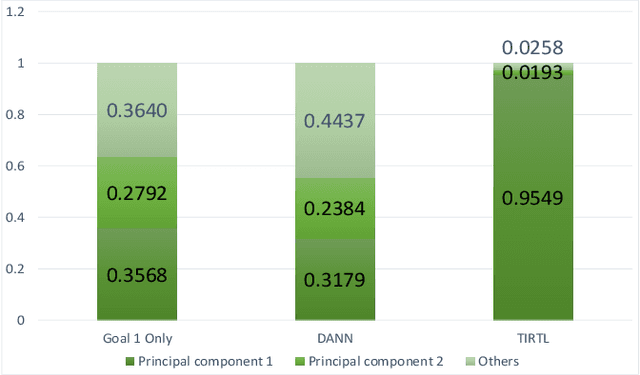
Learning an empirically effective model with generalization using limited data is a challenging task for deep neural networks. In this paper, we propose a novel learning framework called PurifiedLearning to exploit task-irrelevant features extracted from task-irrelevant labels when training models on small-scale datasets. Particularly, we purify feature representations by using the expression of task-irrelevant information, thus facilitating the learning process of classification. Our work is built on solid theoretical analysis and extensive experiments, which demonstrate the effectiveness of PurifiedLearning. According to the theory we proved, PurifiedLearning is model-agnostic and doesn't have any restrictions on the model needed, so it can be combined with any existing deep neural networks with ease to achieve better performance. The source code of this paper will be available in the future for reproducibility.
A Gaussian Process Model of Cross-Category Dynamics in Brand Choice
Apr 23, 2021Understanding individual customers' sensitivities to prices, promotions, brand, and other aspects of the marketing mix is fundamental to a wide swath of marketing problems, including targeting and pricing. Companies that operate across many product categories have a unique opportunity, insofar as they can use purchasing data from one category to augment their insights in another. Such cross-category insights are especially crucial in situations where purchasing data may be rich in one category, and scarce in another. An important aspect of how consumers behave across categories is dynamics: preferences are not stable over time, and changes in individual-level preference parameters in one category may be indicative of changes in other categories, especially if those changes are driven by external factors. Yet, despite the rich history of modeling cross-category preferences, the marketing literature lacks a framework that flexibly accounts for \textit{correlated dynamics}, or the cross-category interlinkages of individual-level sensitivity dynamics. In this work, we propose such a framework, leveraging individual-level, latent, multi-output Gaussian processes to build a nonparametric Bayesian choice model that allows information sharing of preference parameters across customers, time, and categories. We apply our model to grocery purchase data, and show that our model detects interesting dynamics of customers' price sensitivities across multiple categories. Managerially, we show that capturing correlated dynamics yields substantial predictive gains, relative to benchmarks. Moreover, we find that capturing correlated dynamics can have implications for understanding changes in consumers preferences over time, and developing targeted marketing strategies based on those dynamics.