 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine Learning Prediction of Time-Varying Rayleigh Channels
Mar 10, 2021
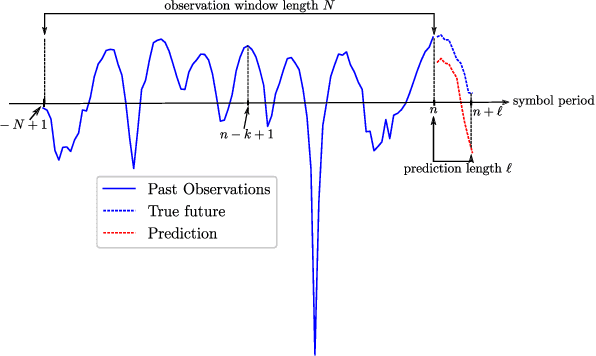
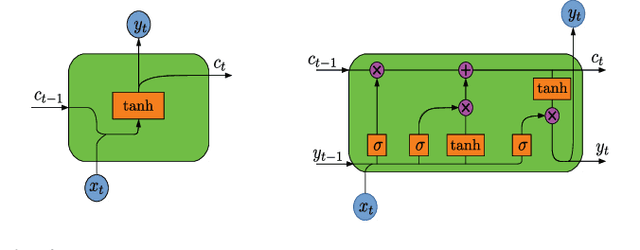
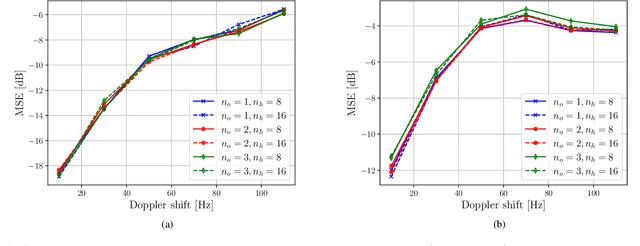
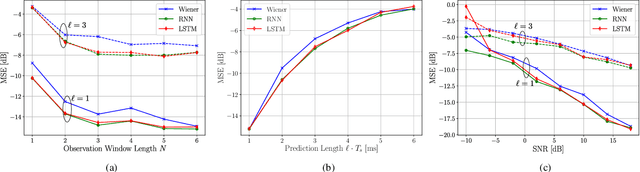
Channel state information (CSI) rapidly becomes outdated in high mobility scenarios, degrading the performance of wireless communication systems. In these cases, time series prediction techniques can be applied to combat the effects of outdated CSI. Recently, it has been shown that recurrent neural networks (RNNs) exhibit outstanding performance in time series prediction tasks. In this paper, we investigate the performance of RNN and long short term memory (LSTM) predictors in a simple Rayleigh flat-fading channel. We conduct numerical experiments to evaluate whether these machine-learning (ML)-based predictors can outperform the optimal linear minimum mean square error Wiener predictor. Our simulation results indicate that the considered neural network predictors outperform the Wiener predictor for small observation window lengths and are more robust under weak channel correlation as well as in the presence of noise. Furthermore, we show that simple shallow RNNs are sufficient to model Rayleigh channels over a wide range of Doppler shifts.
Team Phoenix at WASSA 2021: Emotion Analysis on News Stories with Pre-Trained Language Models
Mar 10, 2021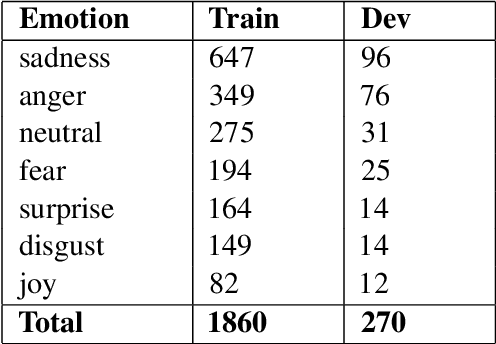
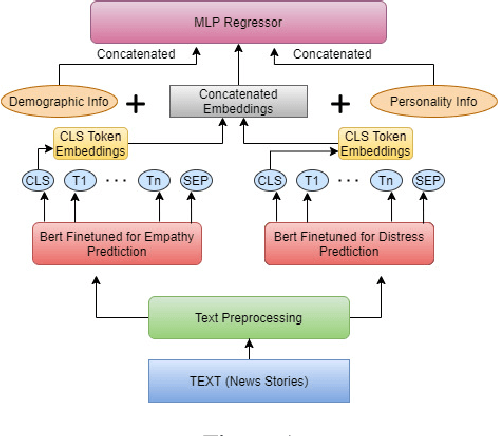
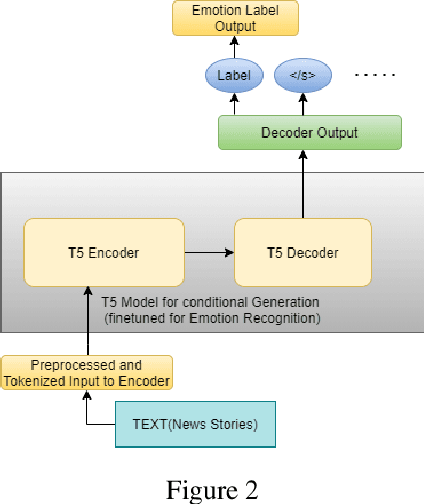
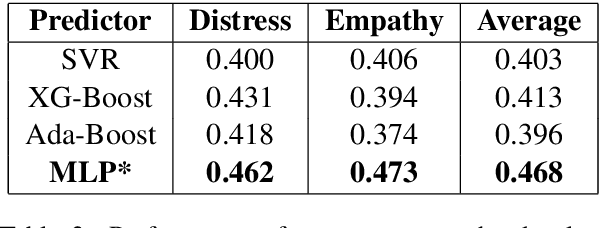
Emotion is fundamental to humanity. The ability to perceive, understand and respond to social interactions in a human-like manner is one of the most desired capabilities in artificial agents, particularly in social-media bots. Over the past few years, computational understanding and detection of emotional aspects in language have been vital in advancing human-computer interaction. The WASSA Shared Task 2021 released a dataset of news-stories across two tracks, Track-1 for Empathy and Distress Prediction and Track-2 for Multi-Dimension Emotion prediction at the essay-level. We describe our system entry for the WASSA 2021 Shared Task (for both Track-1 and Track-2), where we leveraged the information from Pre-trained language models for Track-specific Tasks. Our proposed models achieved an Average Pearson Score of 0.417 and a Macro-F1 Score of 0.502 in Track 1 and Track 2, respectively. In the Shared Task leaderboard, we secured 4th rank in Track 1 and 2nd rank in Track 2.
Bilinear Classes: A Structural Framework for Provable Generalization in RL
Mar 19, 2021
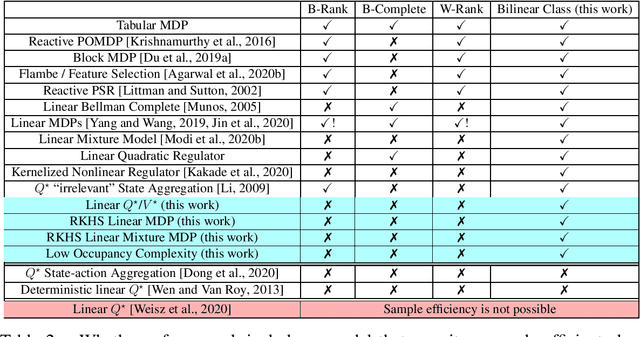
This work introduces Bilinear Classes, a new structural framework, which permit generalization in reinforcement learning in a wide variety of settings through the use of function approximation. The framework incorporates nearly all existing models in which a polynomial sample complexity is achievable, and, notably, also includes new models, such as the Linear $Q^*/V^*$ model in which both the optimal $Q$-function and the optimal $V$-function are linear in some known feature space. Our main result provides an RL algorithm which has polynomial sample complexity for Bilinear Classes; notably, this sample complexity is stated in terms of a reduction to the generalization error of an underlying supervised learning sub-problem. These bounds nearly match the best known sample complexity bounds for existing models. Furthermore, this framework also extends to the infinite dimensional (RKHS) setting: for the the Linear $Q^*/V^*$ model, linear MDPs, and linear mixture MDPs, we provide sample complexities that have no explicit dependence on the explicit feature dimension (which could be infinite), but instead depends only on information theoretic quantities.
Isconna: Streaming Anomaly Detection with Frequency and Patterns
Apr 04, 2021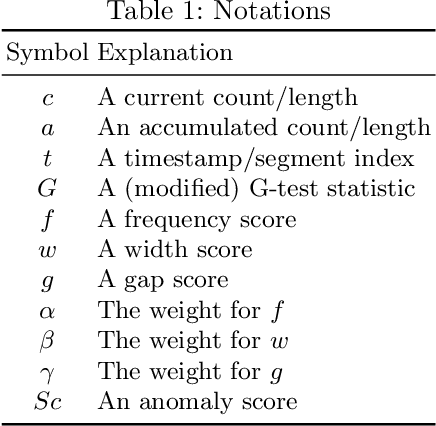
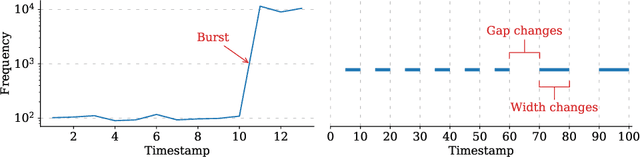
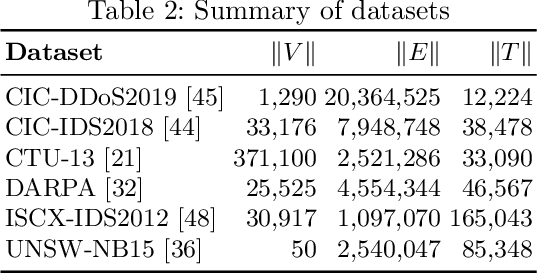
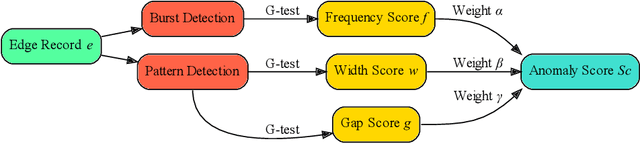
An edge stream is a common form of presentation of dynamic networks. It can evolve with time, with new types of nodes or edges being continuously added. Existing methods for anomaly detection rely on edge occurrence counts or compare pattern snippets found in historical records. In this work, we propose Isconna, which focuses on both the frequency and the pattern of edge records. The burst detection component targets anomalies between individual timestamps, while the pattern detection component highlights anomalies across segments of timestamps. These two components together produce three intermediate scores, which are aggregated into the final anomaly score. Isconna does not actively explore or maintain pattern snippets; it instead measures the consecutive presence and absence of edge records. Isconna is an online algorithm, it does not keep the original information of edge records; only statistical values are maintained in a few count-min sketches (CMS). Isconna's space complexity $O(rc)$ is determined by two user-specific parameters, the size of CMSs. In worst case, Isconna's time complexity can be up to $O(rc)$, but it can be amortized in practice. Experiments show that Isconna outperforms five state-of-the-art frequency- and/or pattern-based baselines on six real-world datasets with up to 20 million edge records.
Joint Registration and Segmentation via Multi-Task Learning for Adaptive Radiotherapy of Prostate Cancer
May 05, 2021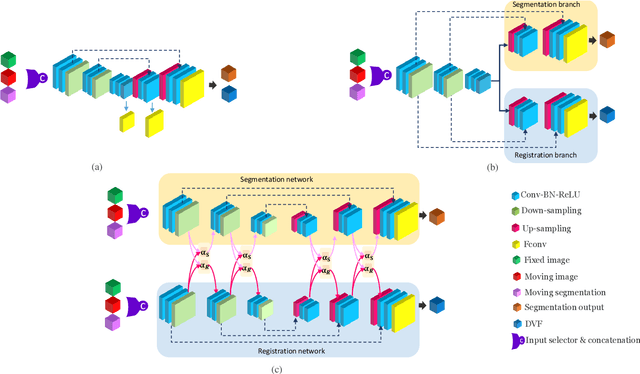
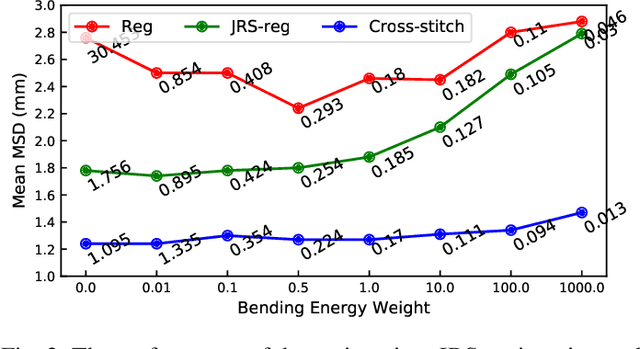
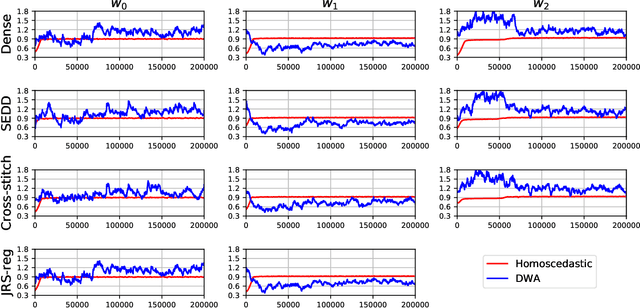
Medical image registration and segmentation are two of the most frequent tasks in medical image analysis. As these tasks are complementary and correlated, it would be beneficial to apply them simultaneously in a joint manner. In this paper, we formulate registration and segmentation as a joint problem via a Multi-Task Learning (MTL) setting, allowing these tasks to leverage their strengths and mitigate their weaknesses through the sharing of beneficial information. We propose to merge these tasks not only on the loss level, but on the architectural level as well. We studied this approach in the context of adaptive image-guided radiotherapy for prostate cancer, where planning and follow-up CT images as well as their corresponding contours are available for training. The study involves two datasets from different manufacturers and institutes. The first dataset was divided into training (12 patients) and validation (6 patients), and was used to optimize and validate the methodology, while the second dataset (14 patients) was used as an independent test set. We carried out an extensive quantitative comparison between the quality of the automatically generated contours from different network architectures as well as loss weighting methods. Moreover, we evaluated the quality of the generated deformation vector field (DVF). We show that MTL algorithms outperform their Single-Task Learning (STL) counterparts and achieve better generalization on the independent test set. The best algorithm achieved a mean surface distance of $1.06 \pm 0.3$ mm, $1.27 \pm 0.4$ mm, $0.91 \pm 0.4$ mm, and $1.76 \pm 0.8$ mm on the validation set for the prostate, seminal vesicles, bladder, and rectum, respectively. The high accuracy of the proposed method combined with the fast inference speed, makes it a promising method for automatic re-contouring of follow-up scans for adaptive radiotherapy.
The hidden label-marginal biases of segmentation losses
Apr 18, 2021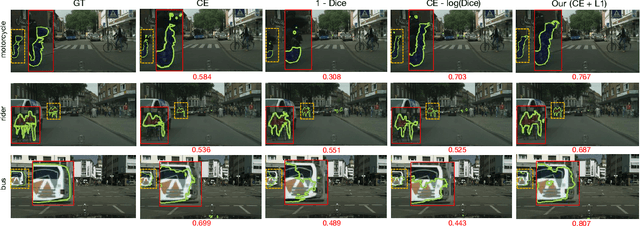
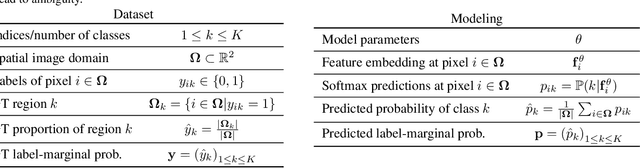
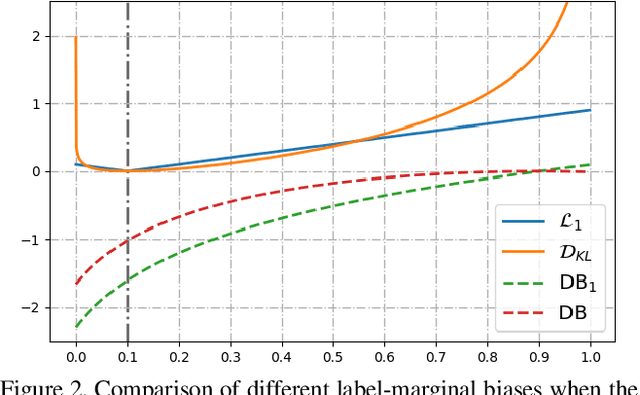
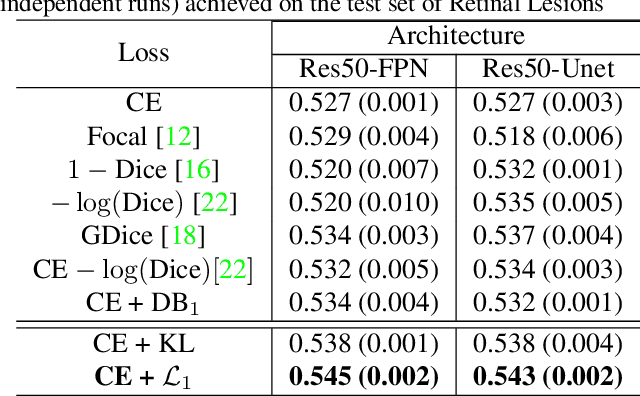
Most segmentation losses are arguably variants of the Cross-Entropy (CE) or Dice loss. In the literature, there is no clear consensus as to which of these losses is a better choice, with varying performances for each across different benchmarks and applications. We develop a theoretical analysis that links these two types of losses, exposing their advantages and weaknesses. First, we explicitly demonstrate that CE and Dice share a much deeper connection than previously thought: CE is an upper bound on both logarithmic and linear Dice losses. Furthermore, we provide an information-theoretic analysis, which highlights hidden label-marginal biases : Dice has an intrinsic bias towards imbalanced solutions, whereas CE implicitly encourages the ground-truth region proportions. Our theoretical results explain the wide experimental evidence in the medical-imaging literature, whereby Dice losses bring improvements for imbalanced segmentation. It also explains why CE dominates natural-image problems with diverse class proportions, in which case Dice might have difficulty adapting to different label-marginal distributions. Based on our theoretical analysis, we propose a principled and simple solution, which enables to control explicitly the label-marginal bias. Our loss integrates CE with explicit ${\cal L}_1$ regularization, which encourages label marginals to match target class proportions, thereby mitigating class imbalance but without losing generality. Comprehensive experiments and ablation studies over different losses and applications validate our theoretical analysis, as well as the effectiveness of our explicit label-marginal regularizers.
Automatic Myocardial Infarction Evaluation from Delayed-Enhancement Cardiac MRI using Deep Convolutional Networks
Oct 30, 2020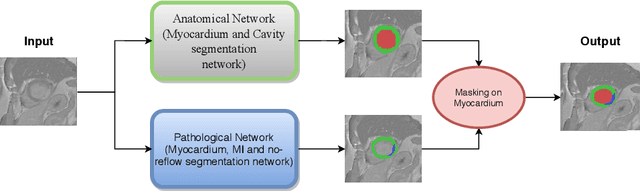

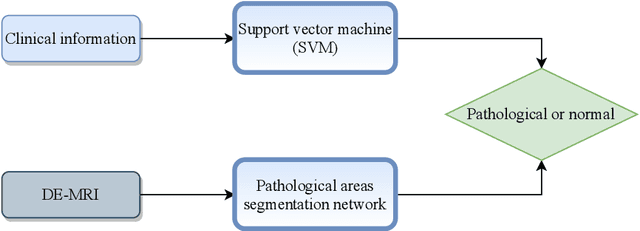
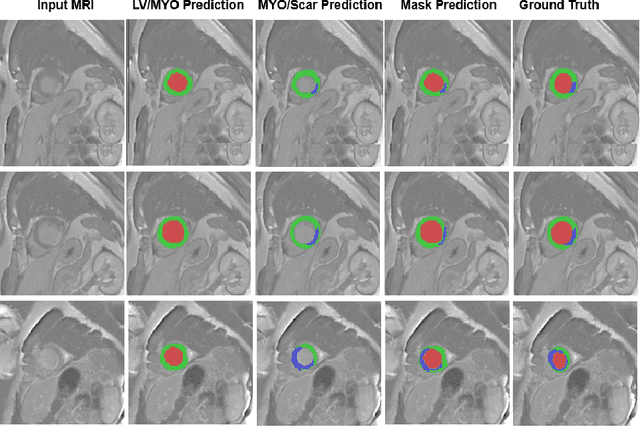
In this paper, we propose a new deep learning framework for an automatic myocardial infarction evaluation from clinical information and delayed enhancement-MRI (DE-MRI). The proposed framework addresses two tasks. The first task is automatic detection of myocardial contours, the infarcted area, the no-reflow area, and the left ventricular cavity from a short-axis DE-MRI series. It employs two segmentation neural networks. The first network is used to segment the anatomical structures such as the myocardium and left ventricular cavity. The second network is used to segment the pathological areas such as myocardial infarction, myocardial no-reflow, and normal myocardial region. The segmented myocardium region from the first network is further used to refine the second network's pathological segmentation results. The second task is to automatically classify a given case into normal or pathological from clinical information with or without DE-MRI. A cascaded support vector machine (SVM) is employed to classify a given case from its associated clinical information. The segmented pathological areas from DE-MRI are also used for the classification task. We evaluated our method on the 2020 EMIDEC MICCAI challenge dataset. It yielded an average Dice index of 0.93 and 0.84, respectively, for the left ventricular cavity and the myocardium. The classification from using only clinical information yielded 80% accuracy over five-fold cross-validation. Using the DE-MRI, our method can classify the cases with 93.3% accuracy. These experimental results reveal that the proposed method can automatically evaluate the myocardial infarction.
Guided Incremental Local Densification for Accelerated Sampling-based Motion Planning
Apr 11, 2021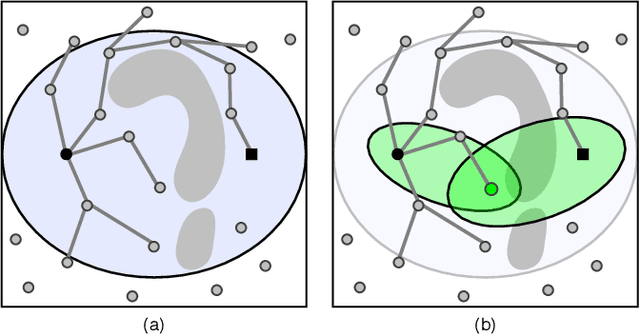
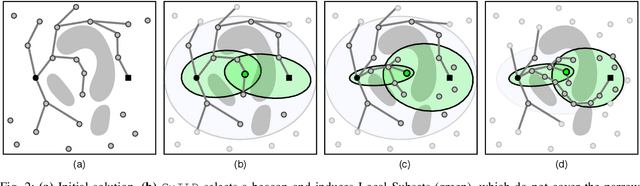
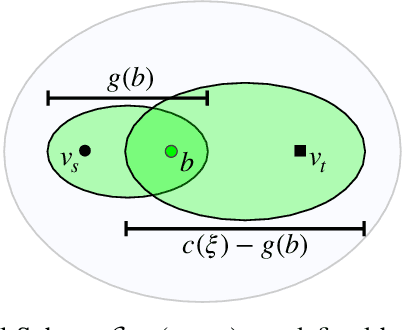
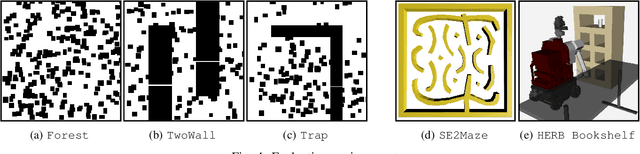
Sampling-based motion planners rely on incremental densification to discover progressively shorter paths. After computing feasible path $\xi$ between start $x_s$ and goal $x_t$, the Informed Set (IS) prunes the configuration space $\mathcal{C}$ by conservatively eliminating points that cannot yield shorter paths. Densification via sampling from this Informed Set retains asymptotic optimality of sampling from the entire configuration space. For path length $c(\xi)$ and Euclidean heuristic $h$, $IS = \{ x | x \in \mathcal{C}, h(x_s, x) + h(x, x_t) \leq c(\xi) \}$. Relying on the heuristic can render the IS especially conservative in high dimensions or complex environments. Furthermore, the IS only shrinks when shorter paths are discovered. Thus, the computational effort from each iteration of densification and planning is wasted if it fails to yield a shorter path, despite improving the cost-to-come for vertices in the search tree. Our key insight is that even in such a failure, shorter paths to vertices in the search tree (rather than just the goal) can immediately improve the planner's sampling strategy. Guided Incremental Local Densification (GuILD) leverages this information to sample from Local Subsets of the IS. We show that GuILD significantly outperforms uniform sampling of the Informed Set in simulated $\mathbb{R}^2$, $SE(2)$ environments and manipulation tasks in $\mathbb{R}^7$.
A Federated Learning Framework for Non-Intrusive Load Monitoring
Apr 04, 2021
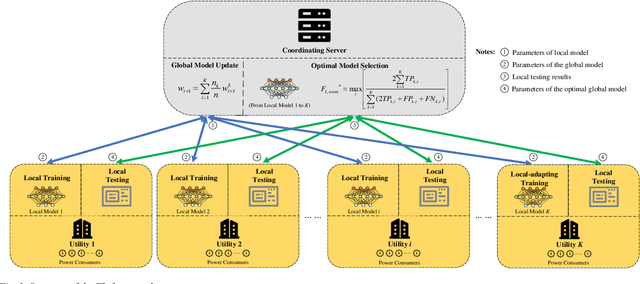
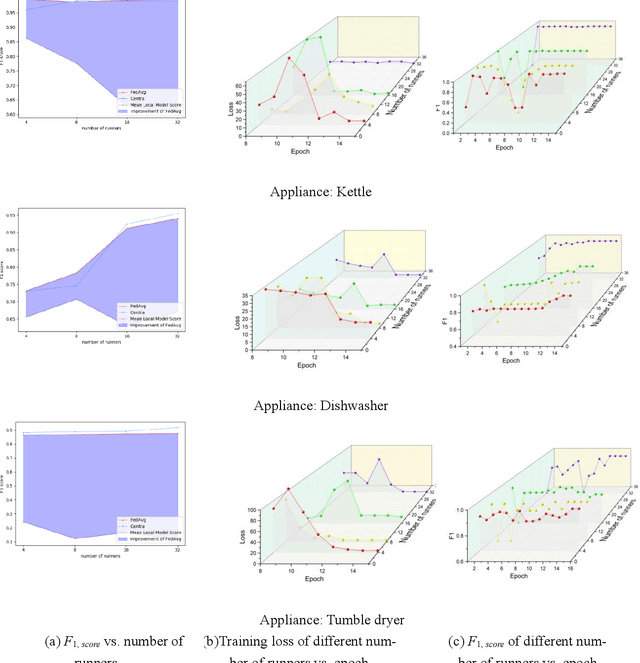
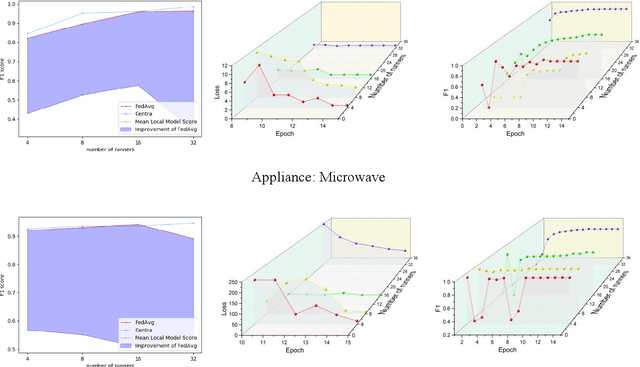
Non-intrusive load monitoring (NILM) aims at decomposing the total reading of the household power consumption into appliance-wise ones, which is beneficial for consumer behavior analysis as well as energy conservation. NILM based on deep learning has been a focus of research. To train a better neural network, it is necessary for the network to be fed with massive data containing various appliances and reflecting consumer behavior habits. Therefore, data cooperation among utilities and DNOs (distributed network operators) who own the NILM data has been increasingly significant. During the cooperation, however, risks of consumer privacy leakage and losses of data control rights arise. To deal with the problems above, a framework to improve the performance of NILM with federated learning (FL) has been set up. In the framework, model weights instead of the local data are shared among utilities. The global model is generated by weighted averaging the locally-trained model weights to gather the locally-trained model information. Optimal model selection help choose the model which adapts to the data from different domains best. Experiments show that this proposal improves the performance of local NILM runners. The performance of this framework is close to that of the centrally-trained model obtained by the convergent data without privacy protection.
LexNLP: Natural language processing and information extraction for legal and regulatory texts
Jun 10, 2018LexNLP is an open source Python package focused on natural language processing and machine learning for legal and regulatory text. The package includes functionality to (i) segment documents, (ii) identify key text such as titles and section headings, (iii) extract over eighteen types of structured information like distances and dates, (iv) extract named entities such as companies and geopolitical entities, (v) transform text into features for model training, and (vi) build unsupervised and supervised models such as word embedding or tagging models. LexNLP includes pre-trained models based on thousands of unit tests drawn from real documents available from the SEC EDGAR database as well as various judicial and regulatory proceedings. LexNLP is designed for use in both academic research and industrial applications, and is distributed at https://github.com/LexPredict/lexpredict-lexnlp.