 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders
Mar 11, 2021

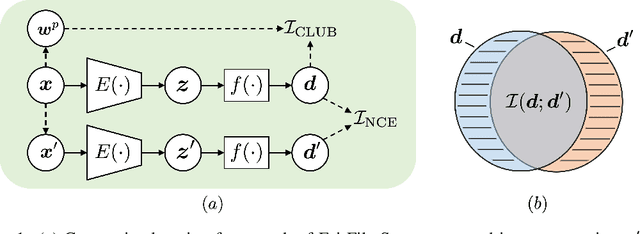
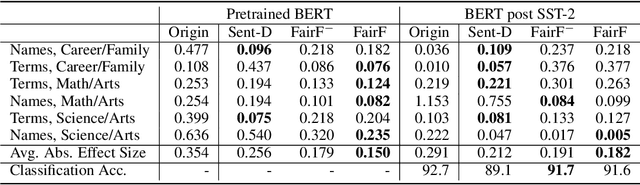
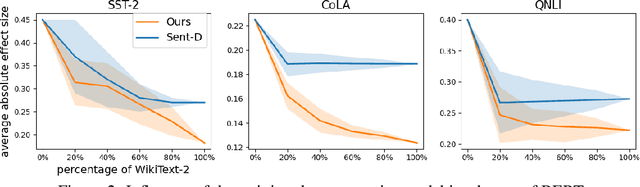
Pretrained text encoders, such as BERT, have been applied increasingly in various natural language processing (NLP) tasks, and have recently demonstrated significant performance gains. However, recent studies have demonstrated the existence of social bias in these pretrained NLP models. Although prior works have made progress on word-level debiasing, improved sentence-level fairness of pretrained encoders still lacks exploration. In this paper, we proposed the first neural debiasing method for a pretrained sentence encoder, which transforms the pretrained encoder outputs into debiased representations via a fair filter (FairFil) network. To learn the FairFil, we introduce a contrastive learning framework that not only minimizes the correlation between filtered embeddings and bias words but also preserves rich semantic information of the original sentences. On real-world datasets, our FairFil effectively reduces the bias degree of pretrained text encoders, while continuously showing desirable performance on downstream tasks. Moreover, our post-hoc method does not require any retraining of the text encoders, further enlarging FairFil's application space.
Generating Intelligible Plumitifs Descriptions: Use Case Application with Ethical Considerations
Nov 24, 2020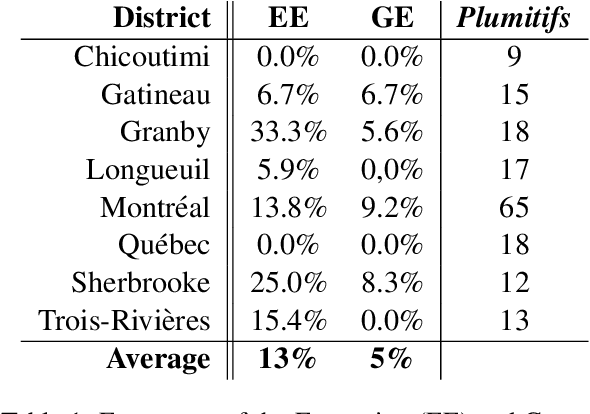
Plumitifs (dockets) were initially a tool for law clerks. Nowadays, they are used as summaries presenting all the steps of a judicial case. Information concerning parties' identity, jurisdiction in charge of administering the case, and some information relating to the nature and the course of the preceding are available through plumitifs. They are publicly accessible but barely understandable; they are written using abbreviations and referring to provisions from the Criminal Code of Canada, which makes them hard to reason about. In this paper, we propose a simple yet efficient multi-source language generation architecture that leverages both the plumitif and the Criminal Code's content to generate intelligible plumitifs descriptions. It goes without saying that ethical considerations rise with these sensitive documents made readable and available at scale, legitimate concerns that we address in this paper.
Understanding Negations in Information Processing: Learning from Replicating Human Behavior
Apr 18, 2017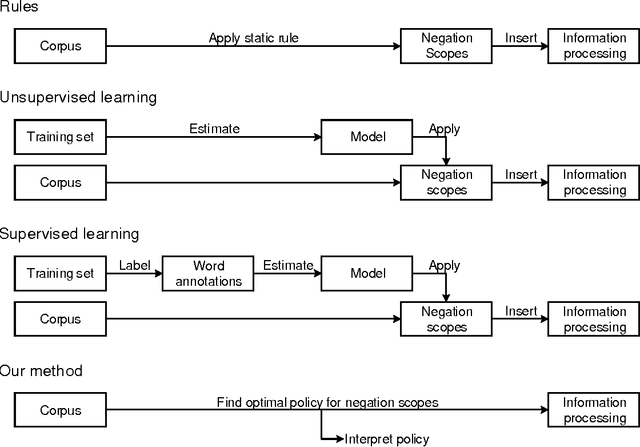

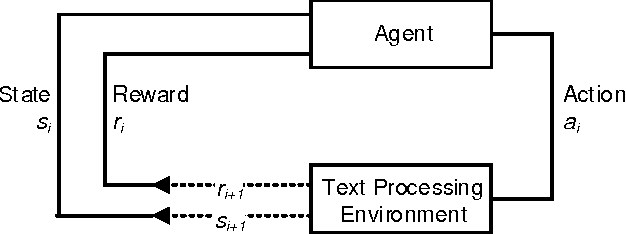

Information systems experience an ever-growing volume of unstructured data, particularly in the form of textual materials. This represents a rich source of information from which one can create value for people, organizations and businesses. For instance, recommender systems can benefit from automatically understanding preferences based on user reviews or social media. However, it is difficult for computer programs to correctly infer meaning from narrative content. One major challenge is negations that invert the interpretation of words and sentences. As a remedy, this paper proposes a novel learning strategy to detect negations: we apply reinforcement learning to find a policy that replicates the human perception of negations based on an exogenous response, such as a user rating for reviews. Our method yields several benefits, as it eliminates the former need for expensive and subjective manual labeling in an intermediate stage. Moreover, the inferred policy can be used to derive statistical inferences and implications regarding how humans process and act on negations.
Editable Free-viewpoint Video Using a Layered Neural Representation
Apr 30, 2021
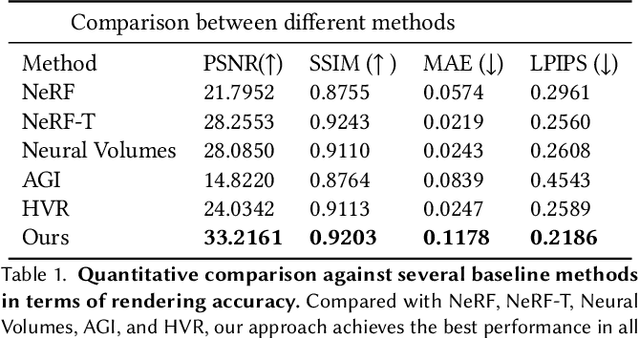
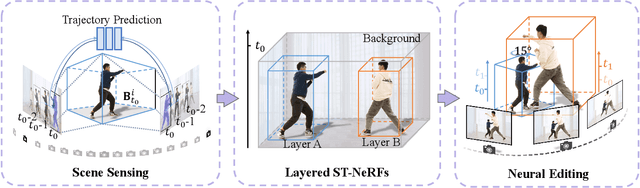
Generating free-viewpoint videos is critical for immersive VR/AR experience but recent neural advances still lack the editing ability to manipulate the visual perception for large dynamic scenes. To fill this gap, in this paper we propose the first approach for editable photo-realistic free-viewpoint video generation for large-scale dynamic scenes using only sparse 16 cameras. The core of our approach is a new layered neural representation, where each dynamic entity including the environment itself is formulated into a space-time coherent neural layered radiance representation called ST-NeRF. Such layered representation supports fully perception and realistic manipulation of the dynamic scene whilst still supporting a free viewing experience in a wide range. In our ST-NeRF, the dynamic entity/layer is represented as continuous functions, which achieves the disentanglement of location, deformation as well as the appearance of the dynamic entity in a continuous and self-supervised manner. We propose a scene parsing 4D label map tracking to disentangle the spatial information explicitly, and a continuous deform module to disentangle the temporal motion implicitly. An object-aware volume rendering scheme is further introduced for the re-assembling of all the neural layers. We adopt a novel layered loss and motion-aware ray sampling strategy to enable efficient training for a large dynamic scene with multiple performers, Our framework further enables a variety of editing functions, i.e., manipulating the scale and location, duplicating or retiming individual neural layers to create numerous visual effects while preserving high realism. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality, photo-realistic, and editable free-viewpoint video generation for dynamic scenes.
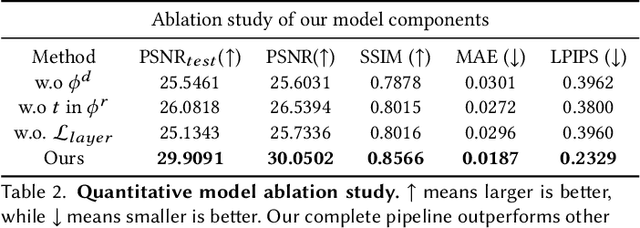
Identifying ARDS using the Hierarchical Attention Network with Sentence Objectives Framework
Mar 10, 2021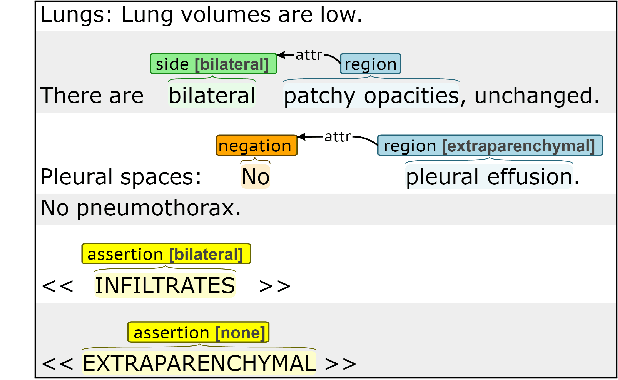
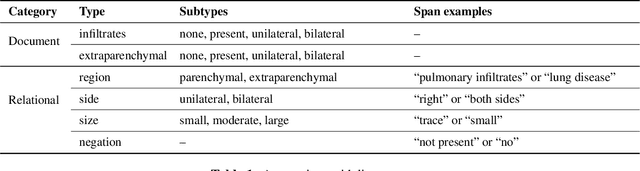

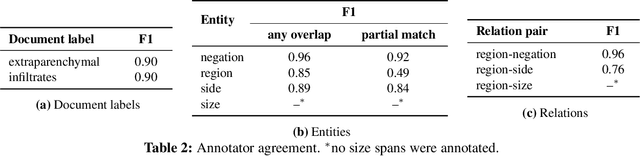
Acute respiratory distress syndrome (ARDS) is a life-threatening condition that is often undiagnosed or diagnosed late. ARDS is especially prominent in those infected with COVID-19. We explore the automatic identification of ARDS indicators and confounding factors in free-text chest radiograph reports. We present a new annotated corpus of chest radiograph reports and introduce the Hierarchical Attention Network with Sentence Objectives (HANSO) text classification framework. HANSO utilizes fine-grained annotations to improve document classification performance. HANSO can extract ARDS-related information with high performance by leveraging relation annotations, even if the annotated spans are noisy. Using annotated chest radiograph images as a gold standard, HANSO identifies bilateral infiltrates, an indicator of ARDS, in chest radiograph reports with performance (0.87 F1) comparable to human annotations (0.84 F1). This algorithm could facilitate more efficient and expeditious identification of ARDS by clinicians and researchers and contribute to the development of new therapies to improve patient care.
Learning Placeholders for Open-Set Recognition
Mar 28, 2021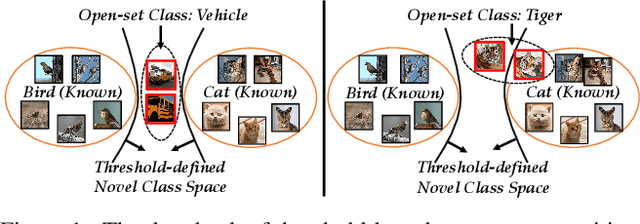
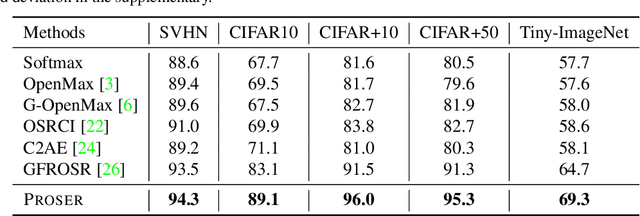
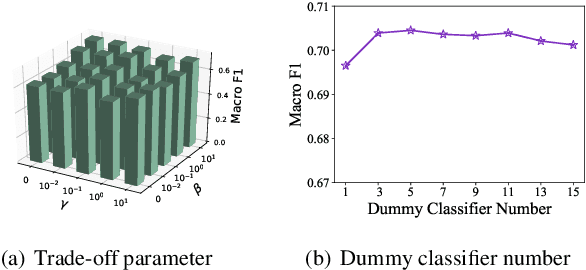
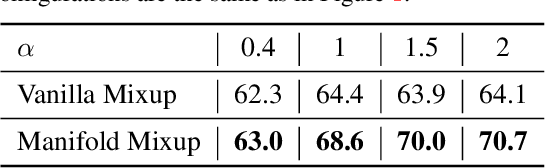
Traditional classifiers are deployed under closed-set setting, with both training and test classes belong to the same set. However, real-world applications probably face the input of unknown categories, and the model will recognize them as known ones. Under such circumstances, open-set recognition is proposed to maintain classification performance on known classes and reject unknowns. The closed-set models make overconfident predictions over familiar known class instances, so that calibration and thresholding across categories become essential issues when extending to an open-set environment. To this end, we proposed to learn PlaceholdeRs for Open-SEt Recognition (Proser), which prepares for the unknown classes by allocating placeholders for both data and classifier. In detail, learning data placeholders tries to anticipate open-set class data, thus transforms closed-set training into open-set training. Besides, to learn the invariant information between target and non-target classes, we reserve classifier placeholders as the class-specific boundary between known and unknown. The proposed Proser efficiently generates novel class by manifold mixup, and adaptively sets the value of reserved open-set classifier during training. Experiments on various datasets validate the effectiveness of our proposed method.
Nearly Optimal Regret for Learning Adversarial MDPs with Linear Function Approximation
Feb 17, 2021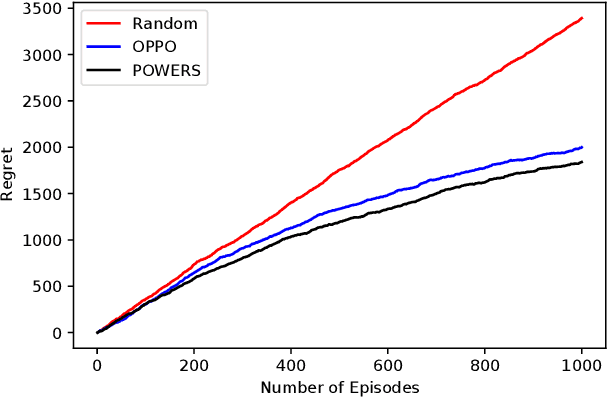
We study the reinforcement learning for finite-horizon episodic Markov decision processes with adversarial reward and full information feedback, where the unknown transition probability function is a linear function of a given feature mapping. We propose an optimistic policy optimization algorithm with Bernstein bonus and show that it can achieve $\tilde{O}(dH\sqrt{T})$ regret, where $H$ is the length of the episode, $T$ is the number of interaction with the MDP and $d$ is the dimension of the feature mapping. Furthermore, we also prove a matching lower bound of $\tilde{\Omega}(dH\sqrt{T})$ up to logarithmic factors. To the best of our knowledge, this is the first computationally efficient, nearly minimax optimal algorithm for adversarial Markov decision processes with linear function approximation.
Multifidelity Ensemble Kalman Filtering Using Surrogate Models Defined by Physics-Informed Autoencoders
Mar 10, 2021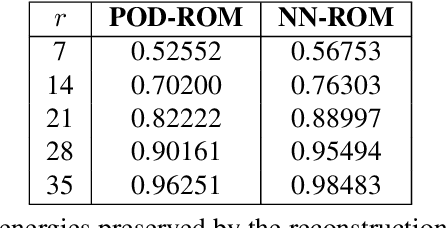
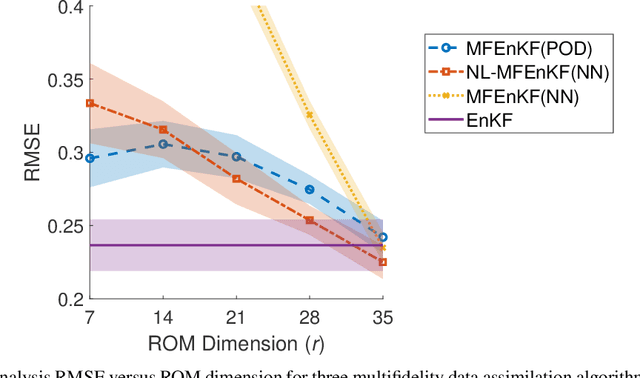
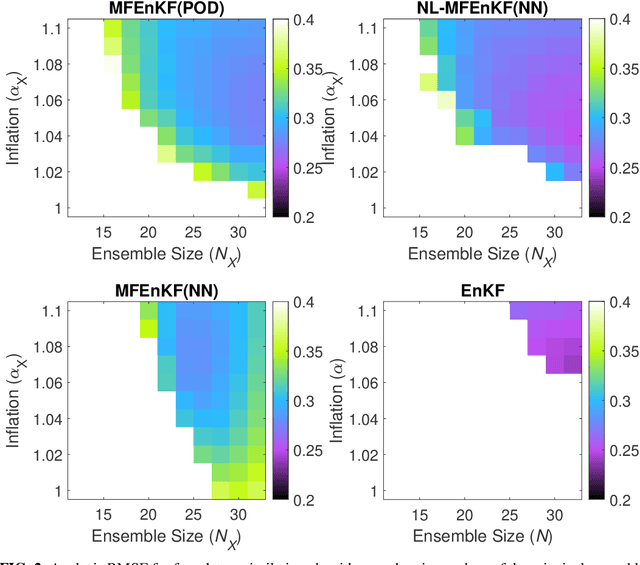
Data assimilation is a Bayesian inference process that obtains an enhanced understanding of a physical system of interest by fusing information from an inexact physics-based model, and from noisy sparse observations of reality. The multifidelity ensemble Kalman filter (MFEnKF) recently developed by the authors combines a full-order physical model and a hierarchy of reduced order surrogate models in order to increase the computational efficiency of data assimilation. The standard MFEnKF uses linear couplings between models, and is statistically optimal in case of Gaussian probability densities. This work extends MFEnKF to work with non-linear couplings between the models. Optimal nonlinear projection and interpolation operators are obtained by appropriately trained physics-informed autoencoders, and this approach allows to construct reduced order surrogate models with less error than conventional linear methods. Numerical experiments with the canonical Lorenz '96 model illustrate that nonlinear surrogates perform better than linear projection-based ones in the context of multifidelity filtering.
Structure-aware Pre-training for Table Understanding with Tree-based Transformers
Nov 06, 2020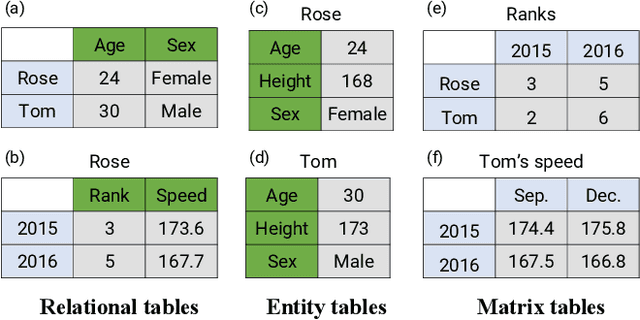
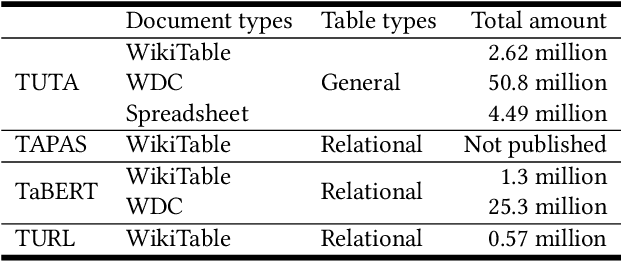
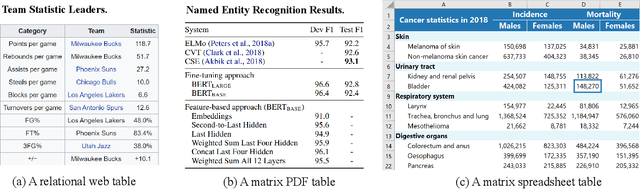

Tables are widely used with various structures to organize and present data. Recent attempts on table understanding mainly focus on relational tables, yet overlook to other common table structures. In this paper, we propose TUTA, a unified pre-training architecture for understanding generally structured tables. Since understanding a table needs to leverage both spatial, hierarchical, and semantic information, we adapt the self-attention strategy with several key structure-aware mechanisms. First, we propose a novel tree-based structure called a bi-dimensional coordinate tree, to describe both the spatial and hierarchical information in tables. Upon this, we extend the pre-training architecture with two core mechanisms, namely the tree-based attention and tree-based position embedding. Moreover, to capture table information in a progressive manner, we devise three pre-training objectives to enable representations at the token, cell, and table levels. TUTA pre-trains on a wide range of unlabeled tables and fine-tunes on a critical task in the field of table structure understanding, i.e. cell type classification. Experiment results show that TUTA is highly effective, achieving state-of-the-art on four well-annotated cell type classification datasets.
Model-inspired Deep Learning for Light-Field Microscopy with Application to Neuron Localization
Mar 10, 2021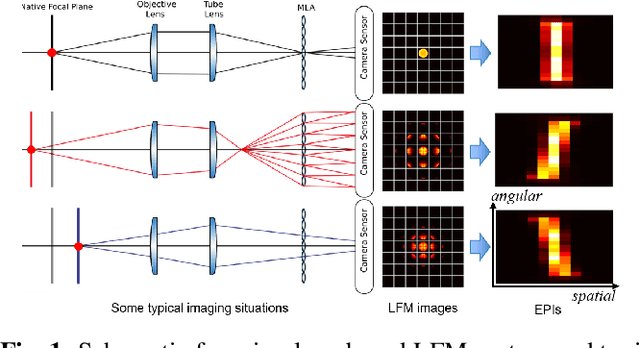
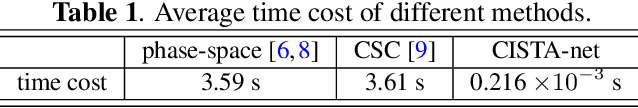
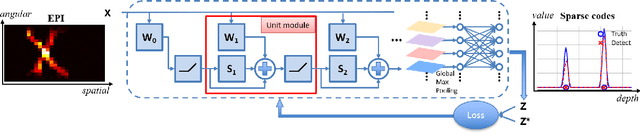
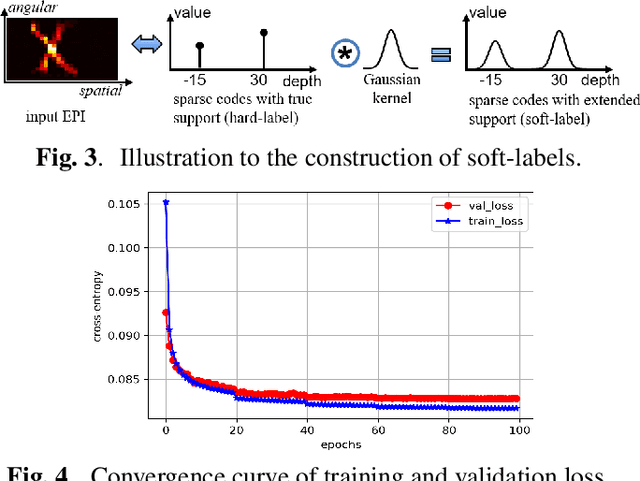
Light-field microscopes are able to capture spatial and angular information of incident light rays. This allows reconstructing 3D locations of neurons from a single snap-shot.In this work, we propose a model-inspired deep learning approach to perform fast and robust 3D localization of sources using light-field microscopy images. This is achieved by developing a deep network that efficiently solves a convolutional sparse coding (CSC) problem to map Epipolar Plane Images (EPI) to corresponding sparse codes. The network architecture is designed systematically by unrolling the convolutional Iterative Shrinkage and Thresholding Algorithm (ISTA) while the network parameters are learned from a training dataset. Such principled design enables the deep network to leverage both domain knowledge implied in the model, as well as new parameters learned from the data, thereby combining advantages of model-based and learning-based methods. Practical experiments on localization of mammalian neurons from light-fields show that the proposed approach simultaneously provides enhanced performance, interpretability and efficiency.