 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LIFE: Lighting Invariant Flow Estimation
Apr 07, 2021


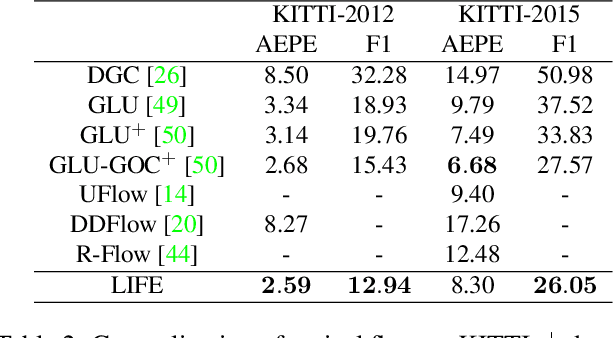
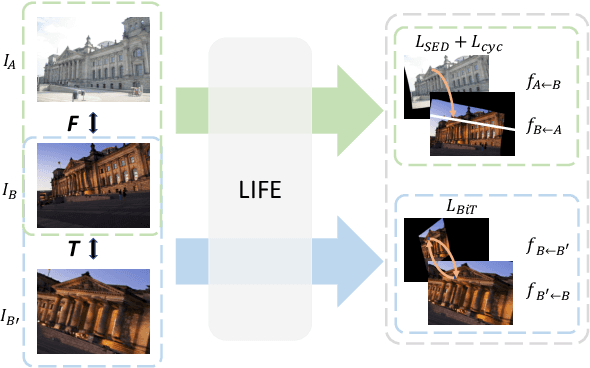
We tackle the problem of estimating flow between two images with large lighting variations. Recent learning-based flow estimation frameworks have shown remarkable performance on image pairs with small displacement and constant illuminations, but cannot work well on cases with large viewpoint change and lighting variations because of the lack of pixel-wise flow annotations for such cases. We observe that via the Structure-from-Motion (SfM) techniques, one can easily estimate relative camera poses between image pairs with large viewpoint change and lighting variations. We propose a novel weakly supervised framework LIFE to train a neural network for estimating accurate lighting-invariant flows between image pairs. Sparse correspondences are conventionally established via feature matching with descriptors encoding local image contents. However, local image contents are inevitably ambiguous and error-prone during the cross-image feature matching process, which hinders downstream tasks. We propose to guide feature matching with the flows predicted by LIFE, which addresses the ambiguous matching by utilizing abundant context information in the image pairs. We show that LIFE outperforms previous flow learning frameworks by large margins in challenging scenarios, consistently improves feature matching, and benefits downstream tasks.
Synthetic aperture interference light (SAIL) microscopy for high-throughput label-free imaging
Apr 15, 2021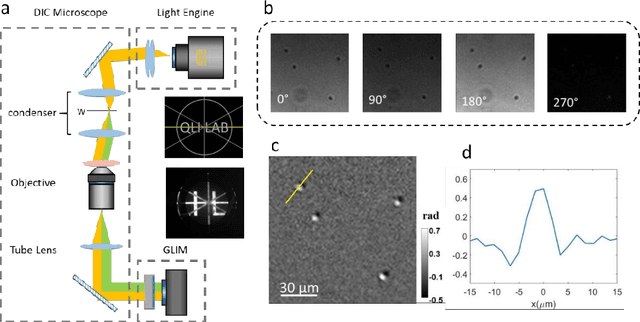
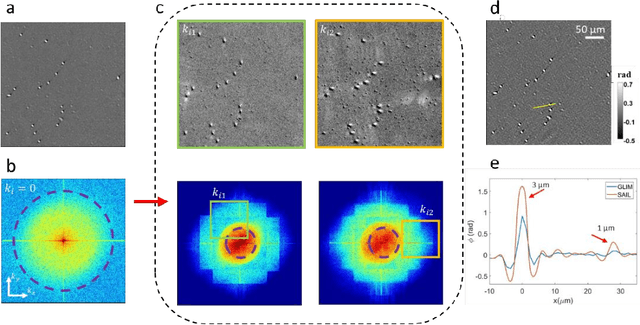


Quantitative phase imaging (QPI) is a valuable label-free modality that has gained significant interest due to its wide potentials, from basic biology to clinical applications. Most existing QPI systems measure microscopic objects via interferometry or nonlinear iterative phase reconstructions from intensity measurements. However, all imaging systems compromise spatial resolution for field of view and vice versa, i.e., suffer from a limited space bandwidth product. Current solutions to this problem involve computational phase retrieval algorithms, which are time-consuming and often suffer from convergence problems. In this article, we presented synthetic aperture interference light (SAIL) microscopy as a novel modality for high-resolution, wide field of view QPI. The proposed approach employs low-coherence interferometry to directly measure the optical phase delay under different illumination angles and produces large space-bandwidth product (SBP) label-free imaging. We validate the performance of SAIL on standard samples and illustrate the biomedical applications on various specimens: pathology slides, entire insects, and dynamic live cells in large cultures. The reconstructed images have a synthetic numeric aperture of 0.45, and a field of view of 2.6 x 2.6 mm2. Due to its direct measurement of the phase information, SAIL microscopy does not require long computational time, eliminates data redundancy, and always converges.
Medical Transformer: Universal Brain Encoder for 3D MRI Analysis
Apr 28, 2021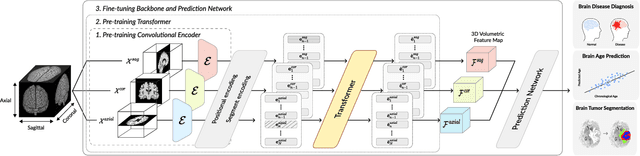
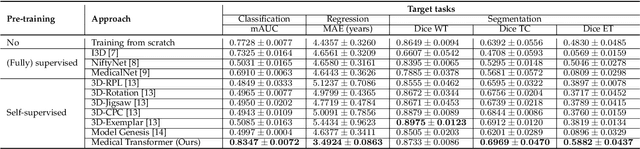
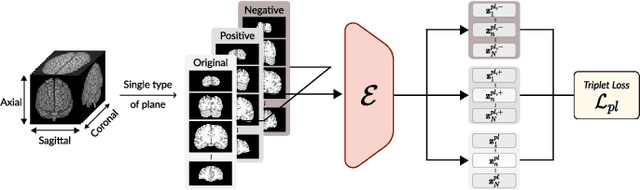
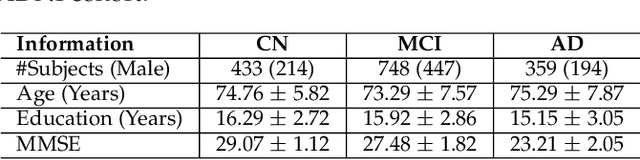
Transfer learning has gained attention in medical image analysis due to limited annotated 3D medical datasets for training data-driven deep learning models in the real world. Existing 3D-based methods have transferred the pre-trained models to downstream tasks, which achieved promising results with only a small number of training samples. However, they demand a massive amount of parameters to train the model for 3D medical imaging. In this work, we propose a novel transfer learning framework, called Medical Transformer, that effectively models 3D volumetric images in the form of a sequence of 2D image slices. To make a high-level representation in 3D-form empowering spatial relations better, we take a multi-view approach that leverages plenty of information from the three planes of 3D volume, while providing parameter-efficient training. For building a source model generally applicable to various tasks, we pre-train the model in a self-supervised learning manner for masked encoding vector prediction as a proxy task, using a large-scale normal, healthy brain magnetic resonance imaging (MRI) dataset. Our pre-trained model is evaluated on three downstream tasks: (i) brain disease diagnosis, (ii) brain age prediction, and (iii) brain tumor segmentation, which are actively studied in brain MRI research. The experimental results show that our Medical Transformer outperforms the state-of-the-art transfer learning methods, efficiently reducing the number of parameters up to about 92% for classification and
SChuBERT: Scholarly Document Chunks with BERT-encoding boost Citation Count Prediction
Dec 21, 2020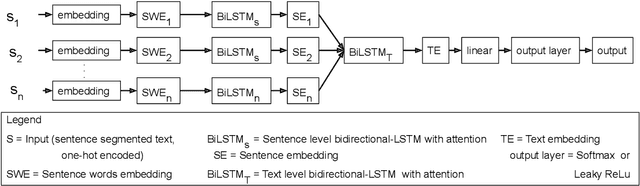
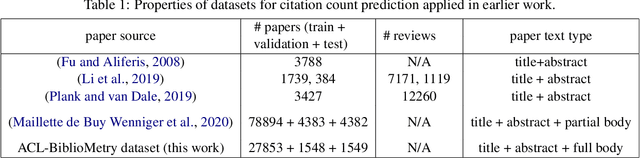
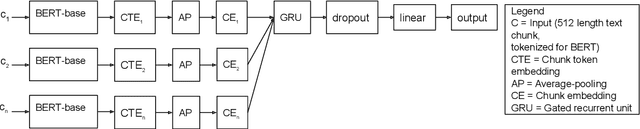
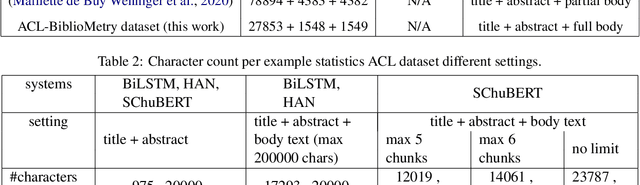
Predicting the number of citations of scholarly documents is an upcoming task in scholarly document processing. Besides the intrinsic merit of this information, it also has a wider use as an imperfect proxy for quality which has the advantage of being cheaply available for large volumes of scholarly documents. Previous work has dealt with number of citations prediction with relatively small training data sets, or larger datasets but with short, incomplete input text. In this work we leverage the open access ACL Anthology collection in combination with the Semantic Scholar bibliometric database to create a large corpus of scholarly documents with associated citation information and we propose a new citation prediction model called SChuBERT. In our experiments we compare SChuBERT with several state-of-the-art citation prediction models and show that it outperforms previous methods by a large margin. We also show the merit of using more training data and longer input for number of citations prediction.
* Published at the First Workshop on Scholarly Document Processing, at EMNLP 2020. Minor corrections were made to the workshop version, including addition of color to Figures 1,2
ActivationNet: Representation learning to predict contact quality of interacting 3-D surfaces in engineering designs
Mar 21, 2021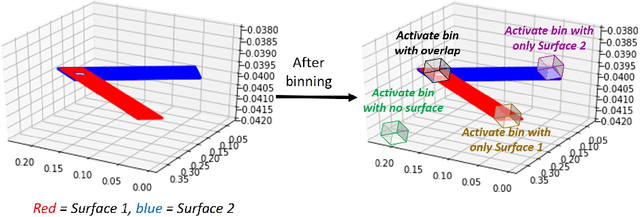
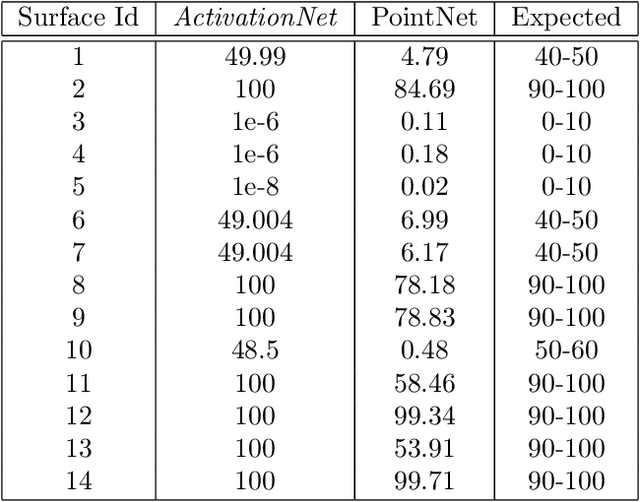
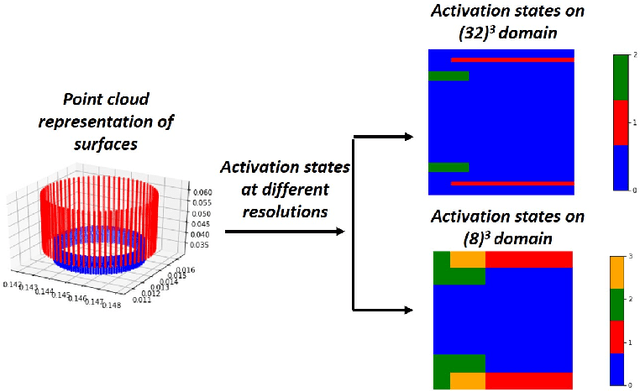
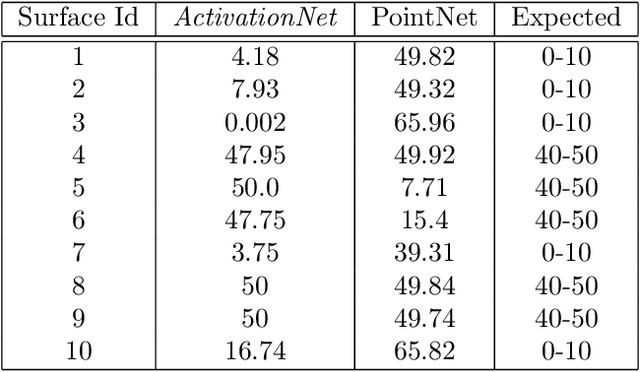
Engineering simulations for analysis of structural and fluid systems require information of contacts between various 3-D surfaces of the geometry to accurately model the physics between them. In machine learning applications, 3-D surfaces are most suitably represented with point clouds or meshes and learning representations of interacting geometries form point-based representations is challenging. The objective of this work is to introduce a machine learning algorithm, ActivationNet, that can learn from point clouds or meshes of interacting 3-D surfaces and predict the quality of contact between these surfaces. The ActivationNet generates activation states from point-based representation of surfaces using a multi-dimensional binning approach. The activation states are further used to contact quality between surfaces using deep neural networks. The performance of our model is demonstrated using several experiments, including tests on interacting surfaces extracted from engineering geometries. In all the experiments presented in this paper, the contact quality predictions of ActivationNet agree well with the expectations.
Autonomous Robotic Mapping of Fragile Geologic Features
May 04, 2021
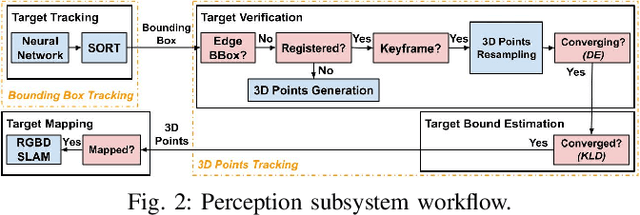
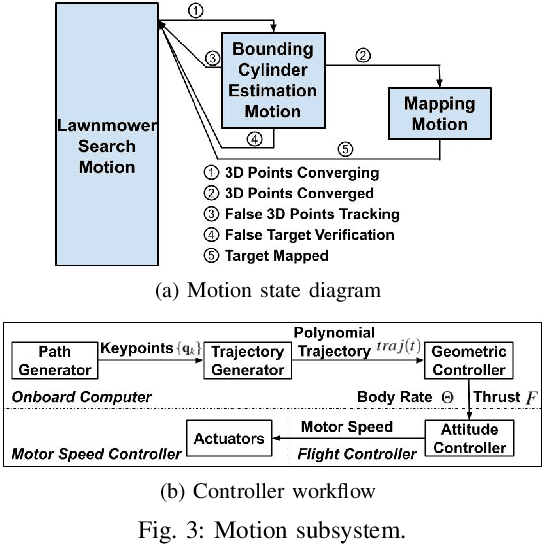
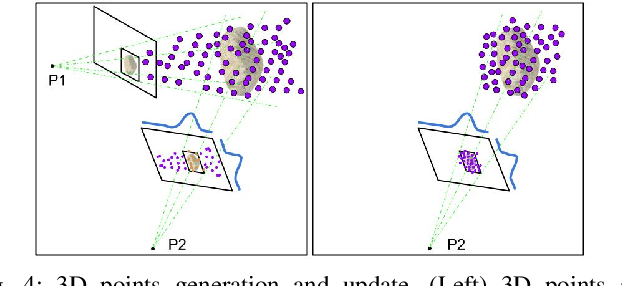
Robotic mapping is useful in scientific applications that involve surveying unstructured environments. This paper presents a target-oriented mapping system for sparsely distributed geologic surface features, such as precariously balanced rocks (PBRs), whose geometric fragility parameters can provide valuable information on earthquake shaking history and landscape development for a region. With this geomorphology problem as the test domain, we demonstrate a pipeline for detecting, localizing, and precisely mapping fragile geologic features distributed on a landscape. To do so, we first carry out a lawn-mower search pattern in the survey region from a high elevation using an Unpiloted Aerial Vehicle (UAV). Once a potential PBR target is detected by a deep neural network, we track the bounding box in the image frames using a real-time tracking algorithm. The location and occupancy of the target in world coordinates are estimated using a sampling-based filtering algorithm, where a set of 3D points are re-sampled after weighting by the tracked bounding boxes from different camera perspectives. The converged 3D points provide a prior on 3D bounding shape of a target, which is used for UAV path planning to closely and completely map the target with Simultaneous Localization and Mapping (SLAM). After target mapping, the UAV resumes the lawn-mower search pattern to find the next target. We introduce techniques to make the target mapping robust to false positive and missing detection from the neural network. Our target-oriented mapping system has the advantages of reducing map storage and emphasizing complete visible surface features on specified targets.
VersaGNN: a Versatile accelerator for Graph neural networks
May 04, 2021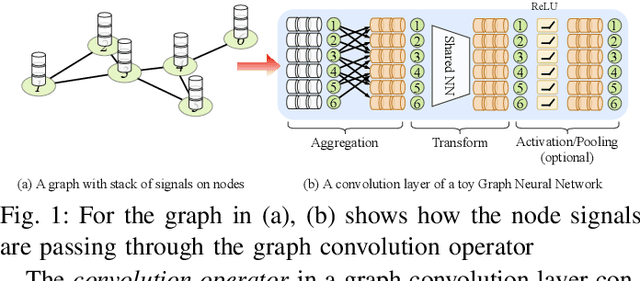
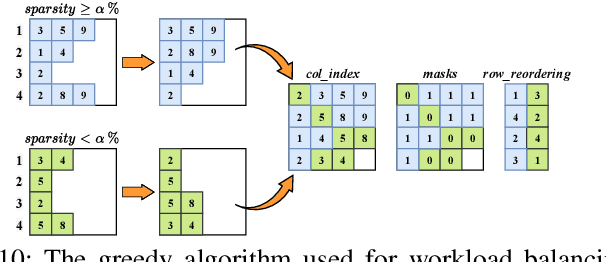
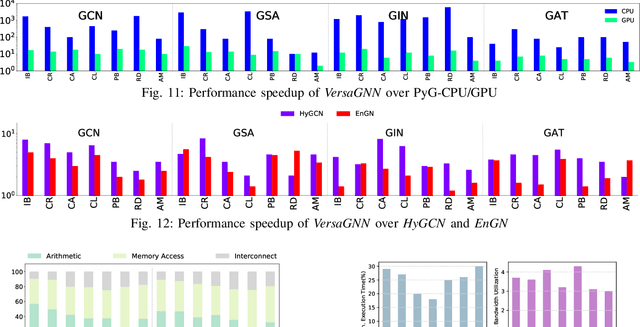
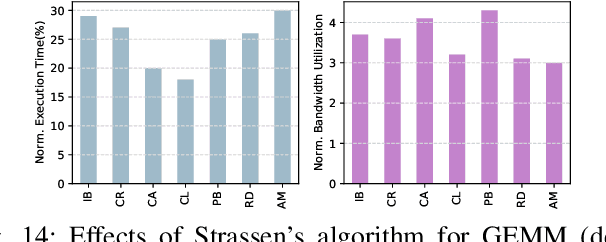
\textit{Graph Neural Network} (GNN) is a promising approach for analyzing graph-structured data that tactfully captures their dependency information via node-level message passing. It has achieved state-of-the-art performances in many tasks, such as node classification, graph matching, clustering, and graph generation. As GNNs operate on non-Euclidean data, their irregular data access patterns cause considerable computational costs and overhead on conventional architectures, such as GPU and CPU. Our analysis shows that GNN adopts a hybrid computing model. The \textit{Aggregation} (or \textit{Message Passing}) phase performs vector additions where vectors are fetched with irregular strides. The \textit{Transformation} (or \textit{Node Embedding}) phase can be either dense or sparse-dense matrix multiplication. In this work, We propose \textit{VersaGNN}, an ultra-efficient, systolic-array-based versatile hardware accelerator that unifies dense and sparse matrix multiplication. By applying this single optimized systolic array to both aggregation and transformation phases, we have significantly reduced chip sizes and energy consumption. We then divide the computing engine into blocked systolic arrays to support the \textit{Strassen}'s algorithm for dense matrix multiplication, dramatically scaling down the number of multiplications and enabling high-throughput computation of GNNs. To balance the workload of sparse-dense matrix multiplication, we also introduced a greedy algorithm to combine sparse sub-matrices of compressed format into condensed ones to reduce computational cycles. Compared with current state-of-the-art GNN software frameworks, \textit{VersaGNN} achieves on average 3712$\times$ speedup with 1301.25$\times$ energy reduction on CPU, and 35.4$\times$ speedup with 17.66$\times$ energy reduction on GPU.
Answerer in Questioner's Mind: Information Theoretic Approach to Goal-Oriented Visual Dialog
Sep 21, 2018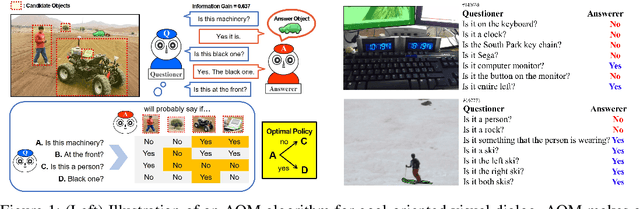
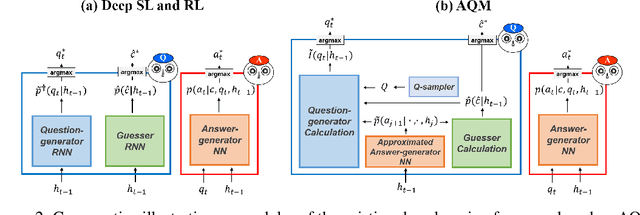
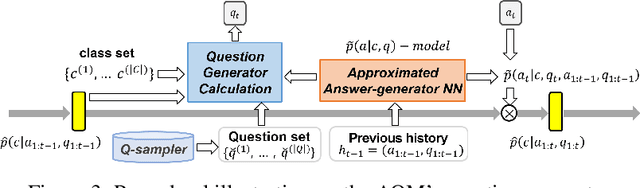
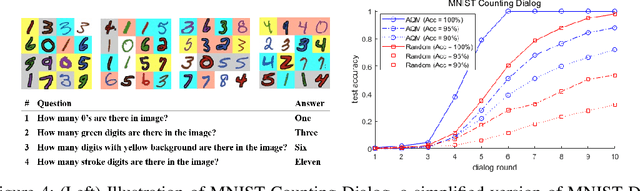
Goal-oriented dialog has been given attention due to its numerous applications in artificial intelligence. Goal-oriented dialogue tasks occur when a questioner asks an action-oriented question and an answerer responds with the intent of letting the questioner know a correct action to take. To ask the adequate question, deep learning and reinforcement learning have been recently applied. However, these approaches struggle to find a competent recurrent neural questioner, owing to the complexity of learning a series of sentences. Motivated by theory of mind, we propose "Answerer in Questioner's Mind" (AQM), a novel algorithm for goal-oriented dialog. With AQM, a questioner asks and infers based on an approximated probabilistic model of the answerer. The questioner figures out the answerer's intention via selecting a plausible question by explicitly calculating the information gain of the candidate intentions and possible answers to each question. We test our framework on two goal-oriented visual dialog tasks: "MNIST Counting Dialog" and "GuessWhat?!." In our experiments, AQM outperforms comparative algorithms by a large margin.
Learning Dynamic Network Using a Reuse Gate Function in Semi-supervised Video Object Segmentation
Dec 21, 2020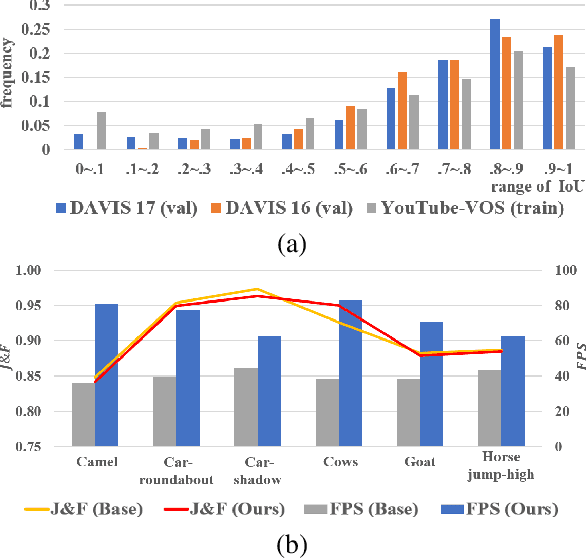
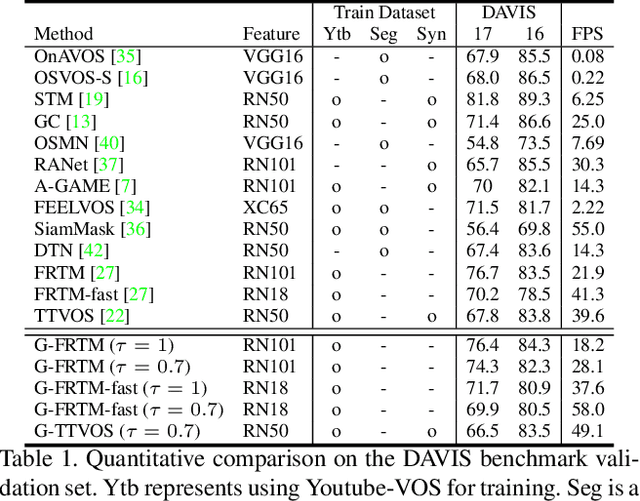
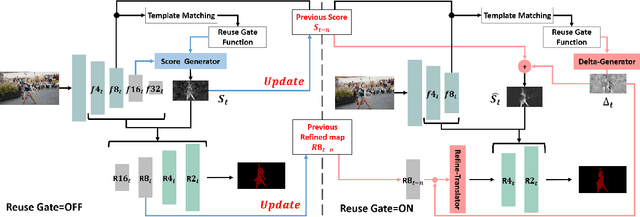
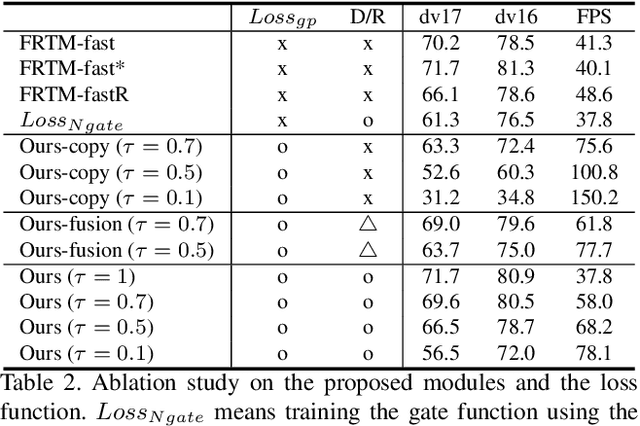
Current state-of-the-art approaches for Semi-supervised Video Object Segmentation (Semi-VOS) propagates information from previous frames to generate segmentation mask for the current frame. This results in high-quality segmentation across challenging scenarios such as changes in appearance and occlusion. But it also leads to unnecessary computations for stationary or slow-moving objects where the change across frames is minimal. In this work, we exploit this observation by using temporal information to quickly identify frames with minimal change and skip the heavyweight mask generation step. To realize this efficiency, we propose a novel dynamic network that estimates change across frames and decides which path -- computing a full network or reusing previous frame's feature -- to choose depending on the expected similarity. Experimental results show that our approach significantly improves inference speed without much accuracy degradation on challenging Semi-VOS datasets -- DAVIS 16, DAVIS 17, and YouTube-VOS. Furthermore, our approach can be applied to multiple Semi-VOS methods demonstrating its generality.
Color-related Local Binary Pattern: A Learned Local Descriptor for Color Image Recognition
Dec 11, 2020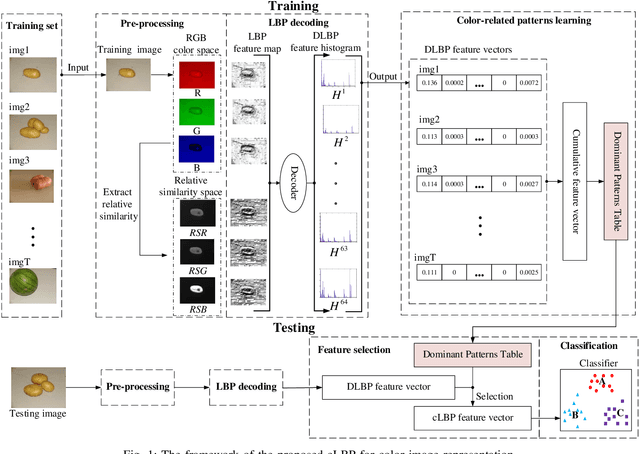
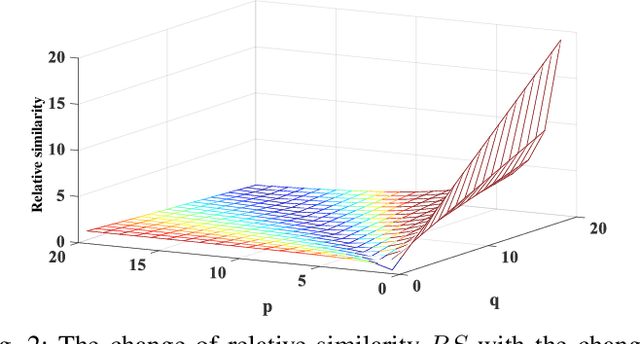
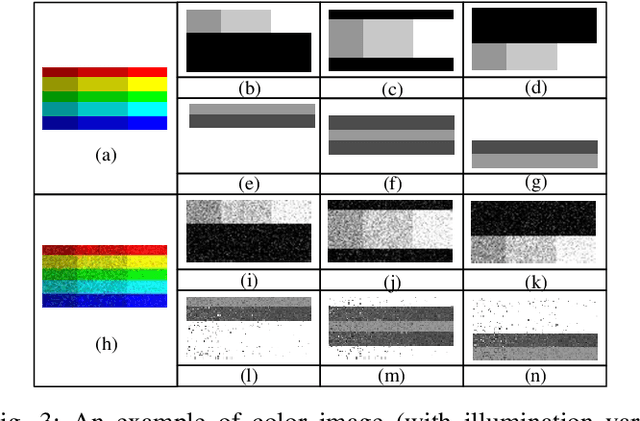
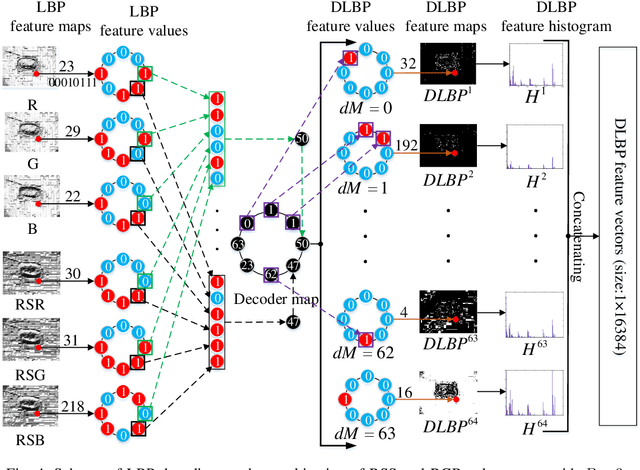
Local binary pattern (LBP) as a kind of local feature has shown its simplicity, easy implementation and strong discriminating power in image recognition. Although some LBP variants are specifically investigated for color image recognition, the color information of images is not adequately considered and the curse of dimensionality in classification is easily caused in these methods. In this paper, a color-related local binary pattern (cLBP) which learns the dominant patterns from the decoded LBP is proposed for color images recognition. This paper first proposes a relative similarity space (RSS) that represents the color similarity between image channels for describing a color image. Then, the decoded LBP which can mine the correlation information between the LBP feature maps correspond to each color channel of RSS traditional RGB spaces, is employed for feature extraction. Finally, a feature learning strategy is employed to learn the dominant color-related patterns for reducing the dimension of feature vector and further improving the discriminatively of features. The theoretic analysis show that the proposed RSS can provide more discriminative information, and has higher noise robustness as well as higher illumination variation robustness than traditional RGB space. Experimental results on four groups, totally twelve public color image datasets show that the proposed method outperforms most of the LBP variants for color image recognition in terms of dimension of features, recognition accuracy under noise-free, noisy and illumination variation conditions.