 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A bandit-learning approach to multifidelity approximation
Mar 29, 2021
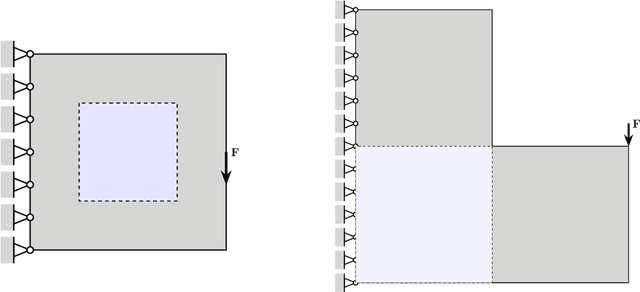
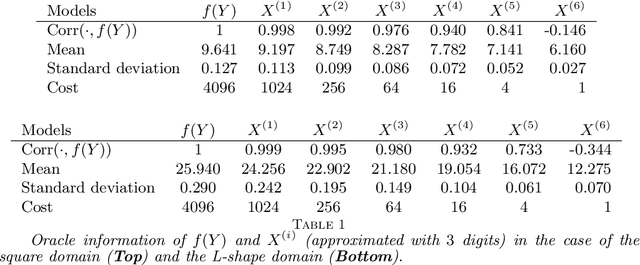
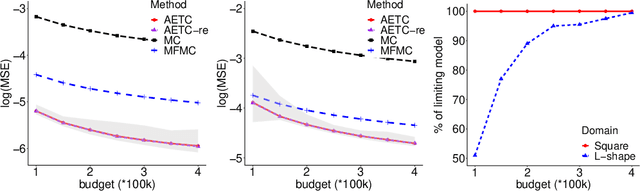
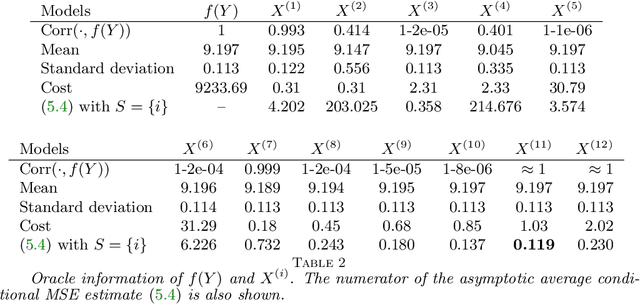
Multifidelity approximation is an important technique in scientific computation and simulation. In this paper, we introduce a bandit-learning approach for leveraging data of varying fidelities to achieve precise estimates of the parameters of interest. Under a linear model assumption, we formulate a multifidelity approximation as a modified stochastic bandit, and analyze the loss for a class of policies that uniformly explore each model before exploiting. Utilizing the estimated conditional mean-squared error, we propose a consistent algorithm, adaptive Explore-Then-Commit (AETC), and establish a corresponding trajectory-wise optimality result. These results are then extended to the case of vector-valued responses, where we demonstrate that the algorithm is efficient without the need to worry about estimating high-dimensional parameters. The main advantage of our approach is that we require neither hierarchical model structure nor \textit{a priori} knowledge of statistical information (e.g., correlations) about or between models. Instead, the AETC algorithm requires only knowledge of which model is a trusted high-fidelity model, along with (relative) computational cost estimates of querying each model. Numerical experiments are provided at the end to support our theoretical findings.
Linnaeus: A highly reusable and adaptable ML based log classification pipeline
Mar 11, 2021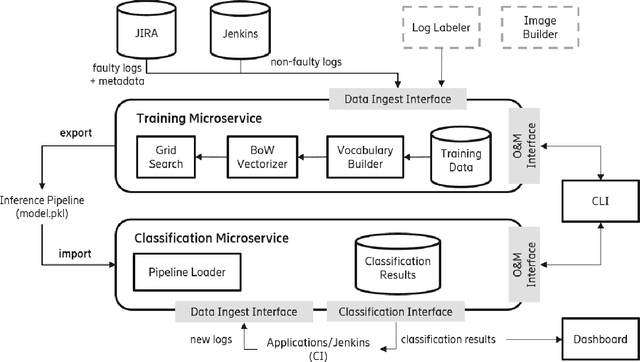
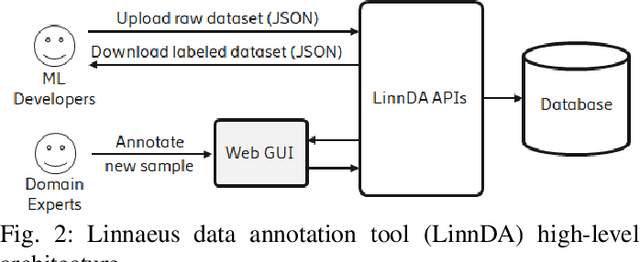
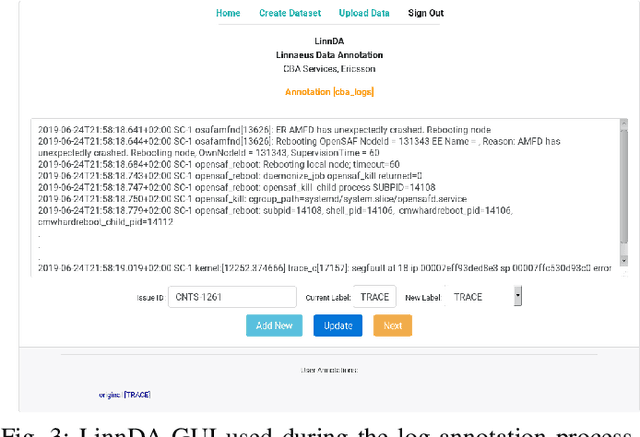
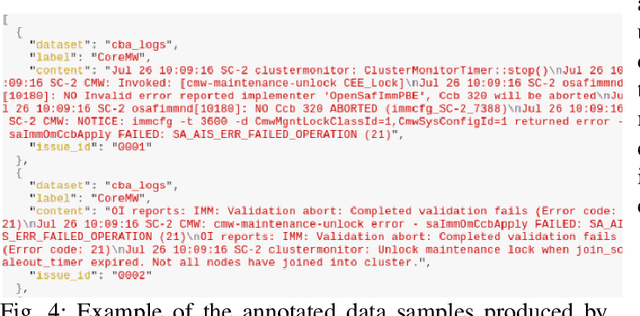
Logs are a common way to record detailed run-time information in software. As modern software systems evolve in scale and complexity, logs have become indispensable to understanding the internal states of the system. At the same time however, manually inspecting logs has become impractical. In recent times, there has been more emphasis on statistical and machine learning (ML) based methods for analyzing logs. While the results have shown promise, most of the literature focuses on algorithms and state-of-the-art (SOTA), while largely ignoring the practical aspects. In this paper we demonstrate our end-to-end log classification pipeline, Linnaeus. Besides showing the more traditional ML flow, we also demonstrate our solutions for adaptability and re-use, integration towards large scale software development processes, and how we cope with lack of labelled data. We hope Linnaeus can serve as a blueprint for, and inspire the integration of, various ML based solutions in other large scale industrial settings.
LocalViT: Bringing Locality to Vision Transformers
Apr 12, 2021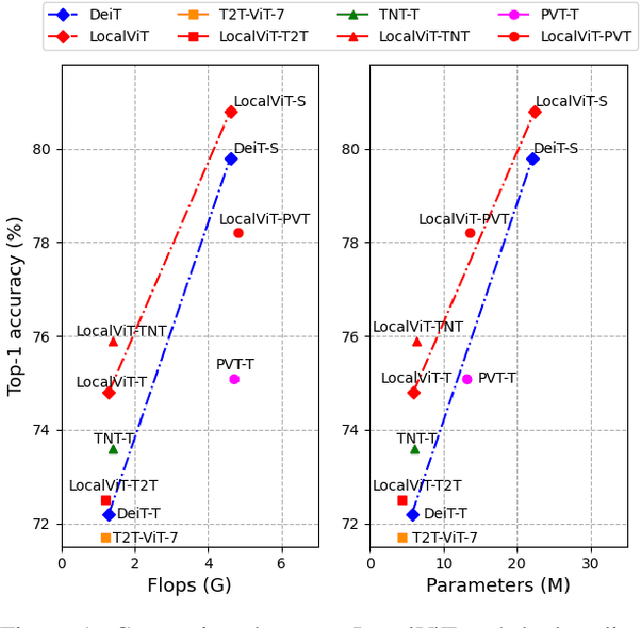
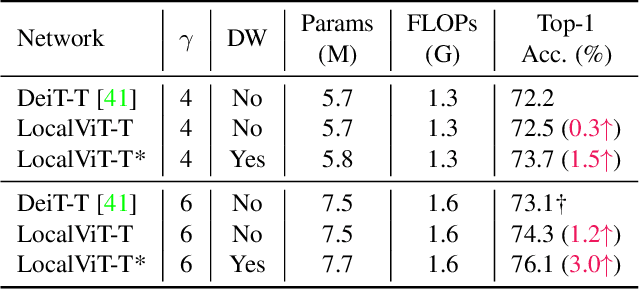
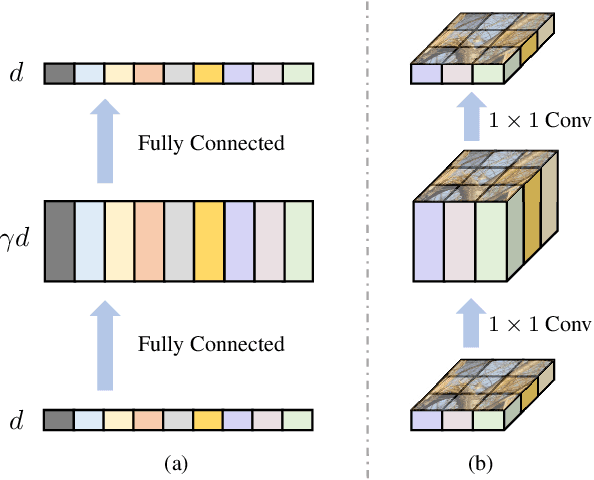
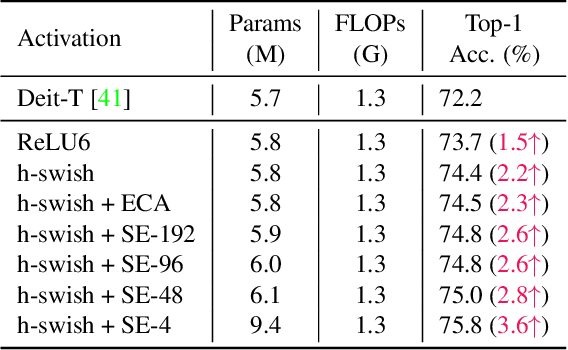
We study how to introduce locality mechanisms into vision transformers. The transformer network originates from machine translation and is particularly good at modelling long-range dependencies within a long sequence. Although the global interaction between the token embeddings could be well modelled by the self-attention mechanism of transformers, what is lacking a locality mechanism for information exchange within a local region. Yet, locality is essential for images since it pertains to structures like lines, edges, shapes, and even objects. We add locality to vision transformers by introducing depth-wise convolution into the feed-forward network. This seemingly simple solution is inspired by the comparison between feed-forward networks and inverted residual blocks. The importance of locality mechanisms is validated in two ways: 1) A wide range of design choices (activation function, layer placement, expansion ratio) are available for incorporating locality mechanisms and all proper choices can lead to a performance gain over the baseline, and 2) The same locality mechanism is successfully applied to 4 vision transformers, which shows the generalization of the locality concept. In particular, for ImageNet2012 classification, the locality-enhanced transformers outperform the baselines DeiT-T and PVT-T by 2.6\% and 3.1\% with a negligible increase in the number of parameters and computational effort. Code is available at \url{https://github.com/ofsoundof/LocalViT}.
Policy Search with Rare Significant Events: Choosing the Right Partner to Cooperate with
Mar 11, 2021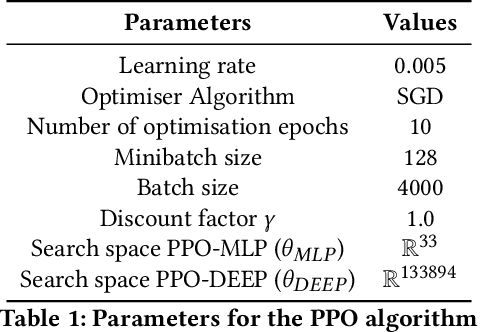
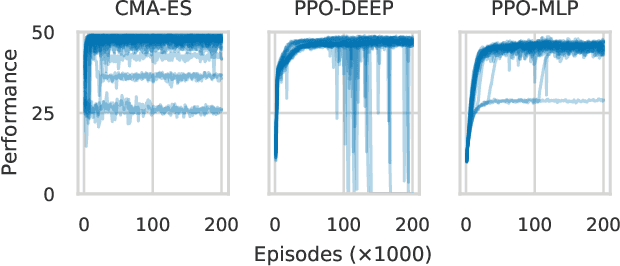
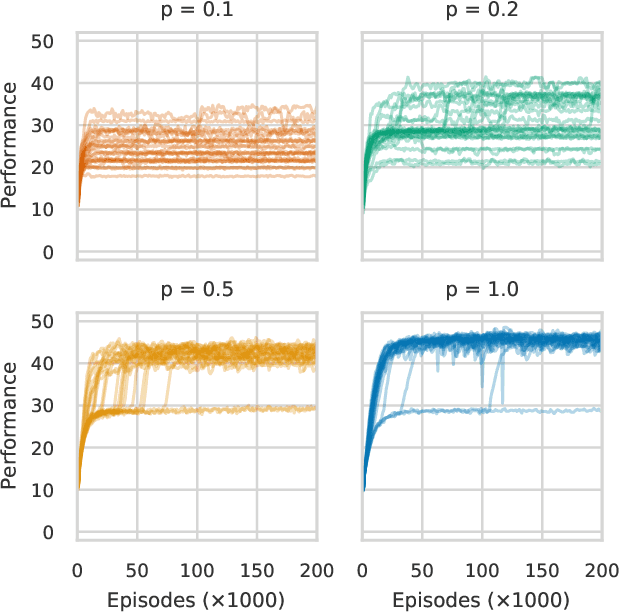
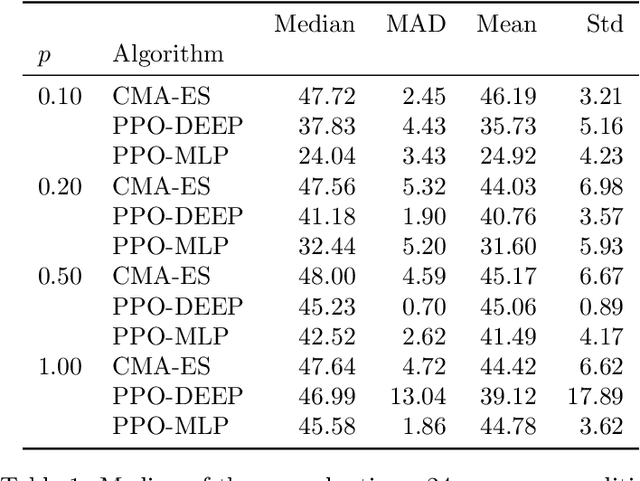
This paper focuses on a class of reinforcement learning problems where significant events are rare and limited to a single positive reward per episode. A typical example is that of an agent who has to choose a partner to cooperate with, while a large number of partners are simply not interested in cooperating, regardless of what the agent has to offer. We address this problem in a continuous state and action space with two different kinds of search methods: a gradient policy search method and a direct policy search method using an evolution strategy. We show that when significant events are rare, gradient information is also scarce, making it difficult for policy gradient search methods to find an optimal policy, with or without a deep neural architecture. On the other hand, we show that direct policy search methods are invariant to the rarity of significant events, which is yet another confirmation of the unique role evolutionary algorithms has to play as a reinforcement learning method.
Mining Latent Structures for Multimedia Recommendation
Apr 19, 2021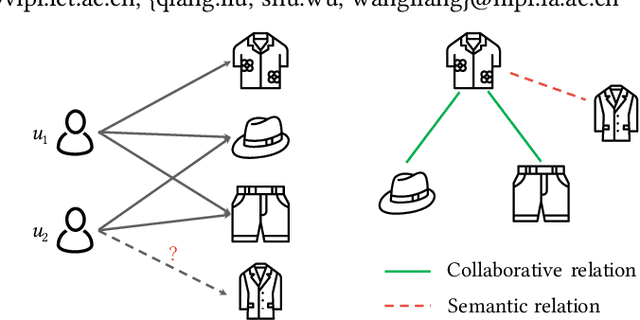
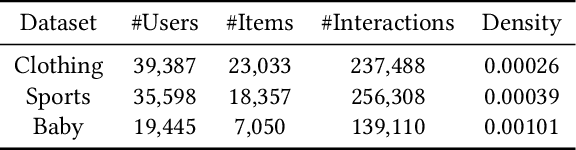
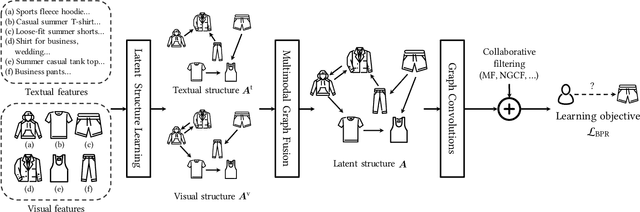
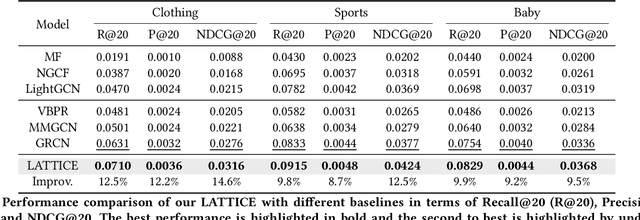
Multimedia content is of predominance in the modern Web era. Investigating how users interact with multimodal items is a continuing concern within the rapid development of recommender systems. The majority of previous work focuses on modeling user-item interactions with multimodal features included as side information. However, this scheme is not well-designed for multimedia recommendation. Specifically, only collaborative item-item relationships are implicitly modeled through high-order item-user-item relations. Considering that items are associated with rich contents in multiple modalities, we argue that the latent item-item structures underlying these multimodal contents could be beneficial for learning better item representations and further boosting recommendation. To this end, we propose a LATent sTructure mining method for multImodal reCommEndation, which we term LATTICE for brevity. To be specific, in the proposed LATTICE model, we devise a novel modality-aware structure learning layer, which learns item-item structures for each modality and aggregates multiple modalities to obtain latent item graphs. Based on the learned latent graphs, we perform graph convolutions to explicitly inject high-order item affinities into item representations. These enriched item representations can then be plugged into existing collaborative filtering methods to make more accurate recommendations. Extensive experiments on three real-world datasets demonstrate the superiority of our method over state-of-the-art multimedia recommendation methods and validate the efficacy of mining latent item-item relationships from multimodal features.
Using Machine Learning and Natural Language Processing Techniques to Analyze and Support Moderation of Student Book Discussions
Nov 23, 2020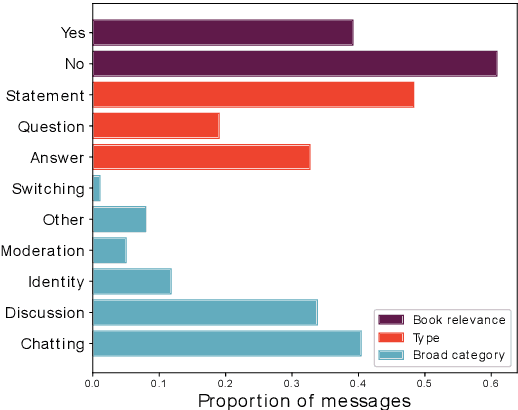
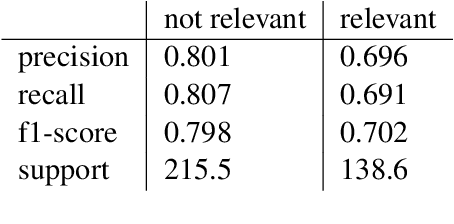
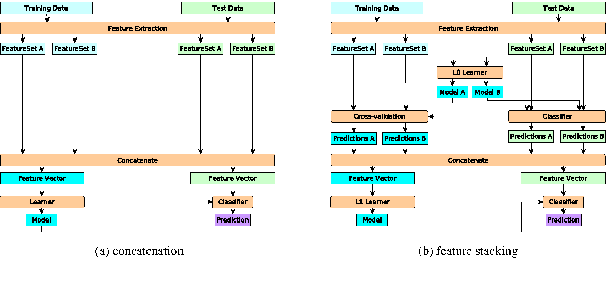
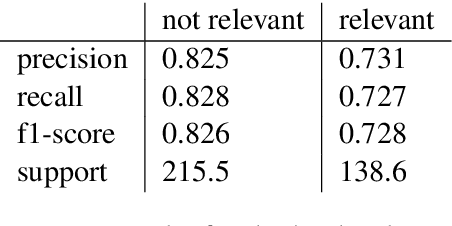
The increasing adoption of technology to augment or even replace traditional face-to-face learning has led to the development of a myriad of tools and platforms aimed at engaging the students and facilitating the teacher's ability to present new information. The IMapBook project aims at improving the literacy and reading comprehension skills of elementary school-aged children by presenting them with interactive e-books and letting them take part in moderated book discussions. This study aims to develop and illustrate a machine learning-based approach to message classification that could be used to automatically notify the discussion moderator of a possible need for an intervention and also to collect other useful information about the ongoing discussion. We aim to predict whether a message posted in the discussion is relevant to the discussed book, whether the message is a statement, a question, or an answer, and in which broad category it can be classified. We incrementally enrich our used feature subsets and compare them using standard classification algorithms as well as the novel Feature stacking method. We use standard classification performance metrics as well as the Bayesian correlated t-test to show that the use of described methods in discussion moderation is feasible. Moving forward, we seek to attain better performance by focusing on extracting more of the significant information found in the strong temporal interdependence of the messages.
Connecting Context-specific Adaptation in Humans to Meta-learning
Dec 01, 2020
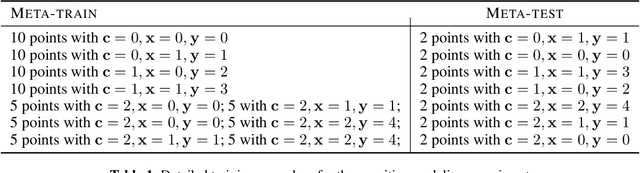


Cognitive control, the ability of a system to adapt to the demands of a task, is an integral part of cognition. A widely accepted fact about cognitive control is that it is context-sensitive: Adults and children alike infer information about a task's demands from contextual cues and use these inferences to learn from ambiguous cues. However, the precise way in which people use contextual cues to guide adaptation to a new task remains poorly understood. This work connects the context-sensitive nature of cognitive control to a method for meta-learning with context-conditioned adaptation. We begin by identifying an essential difference between human learning and current approaches to meta-learning: In contrast to humans, existing meta-learning algorithms do not make use of task-specific contextual cues but instead rely exclusively on online feedback in the form of task-specific labels or rewards. To remedy this, we introduce a framework for using contextual information about a task to guide the initialization of task-specific models before adaptation to online feedback. We show how context-conditioned meta-learning can capture human behavior in a cognitive task and how it can be scaled to improve the speed of learning in various settings, including few-shot classification and low-sample reinforcement learning. Our work demonstrates that guiding meta-learning with task information can capture complex, human-like behavior, thereby deepening our understanding of cognitive control.
Decorrelating Adversarial Nets for Clustering Mobile Network Data
Mar 11, 2021
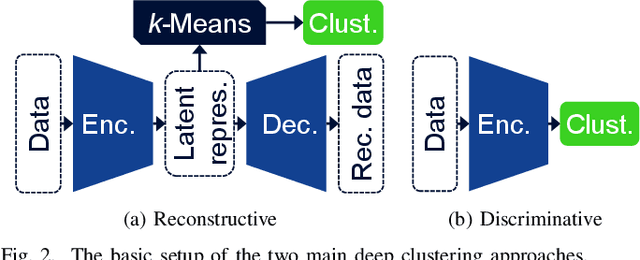
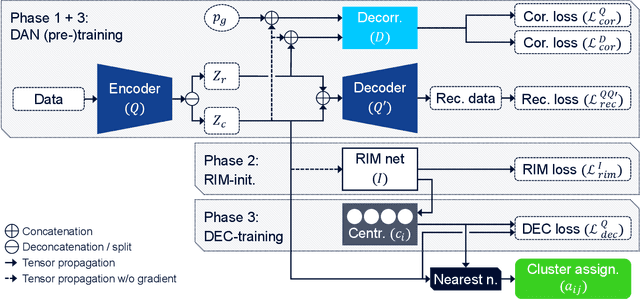
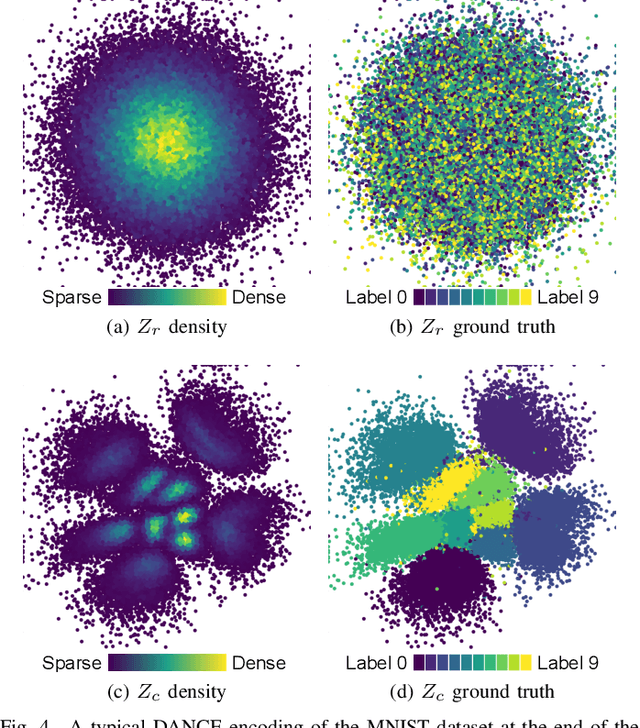
Deep learning will play a crucial role in enabling cognitive automation for the mobile networks of the future. Deep clustering, a subset of deep learning, could be a valuable tool for many network automation use-cases. Unfortunately, most state-of-the-art clustering algorithms target image datasets, which makes them hard to apply to mobile network data due to their highly tuned nature and related assumptions about the data. In this paper, we propose a new algorithm, DANCE (Decorrelating Adversarial Nets for Clustering-friendly Encoding), intended to be a reliable deep clustering method which also performs well when applied to network automation use-cases. DANCE uses a reconstructive clustering approach, separating clustering-relevant from clustering-irrelevant features in a latent representation. This separation removes unnecessary information from the clustering, increasing consistency and peak performance. We comprehensively evaluate DANCE and other select state-of-the-art deep clustering algorithms, and show that DANCE outperforms these algorithms by a significant margin on a mobile network dataset.
Hyperspectral Image Classification -- Traditional to Deep Models: A Survey for Future Prospects
Jan 15, 2021
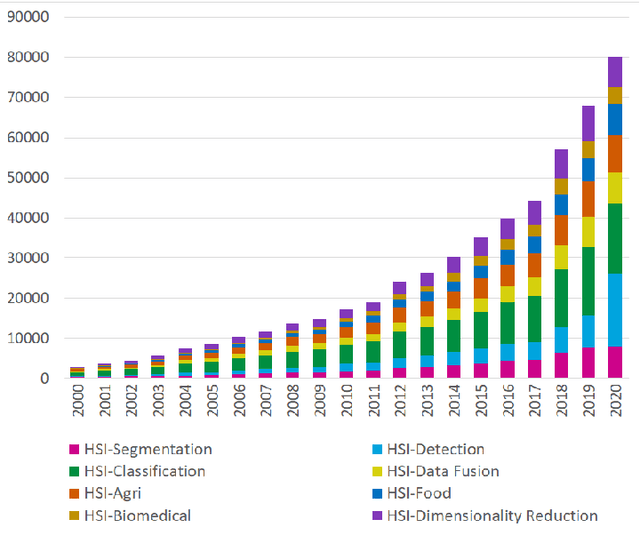
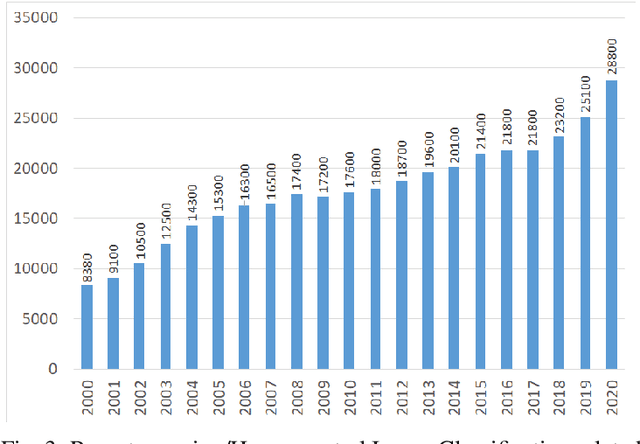
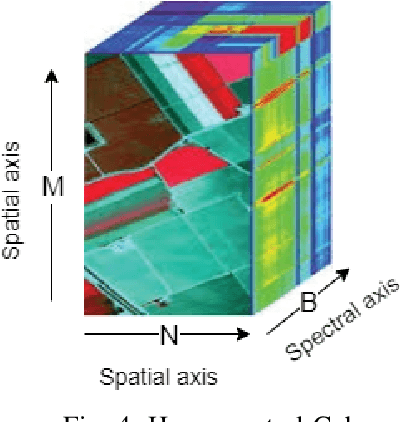
Hyperspectral Imaging (HSI) has been extensively utilized in many real-life applications because it benefits from the detailed spectral information contained in each pixel. Notably, the complex characteristics i.e., the nonlinear relation among the captured spectral information and the corresponding object of HSI data make accurate classification challenging for traditional methods. In the last few years, deep learning (DL) has been substantiated as a powerful feature extractor that effectively addresses the nonlinear problems that appeared in a number of computer vision tasks. This prompts the deployment of DL for HSI classification (HSIC) which revealed good performance. This survey enlists a systematic overview of DL for HSIC and compared state-of-the-art strategies of the said topic. Primarily, we will encapsulate the main challenges of traditional machine learning for HSIC and then we will acquaint the superiority of DL to address these problems. This survey breakdown the state-of-the-art DL frameworks into spectral-features, spatial-features, and together spatial-spectral features to systematically analyze the achievements (future directions as well) of these frameworks for HSIC. Moreover, we will consider the fact that DL requires a large number of labeled training examples whereas acquiring such a number for HSIC is challenging in terms of time and cost. Therefore, this survey discusses some strategies to improve the generalization performance of DL strategies which can provide some future guidelines.
Symmetry-Aware Reservoir Computing
Jan 30, 2021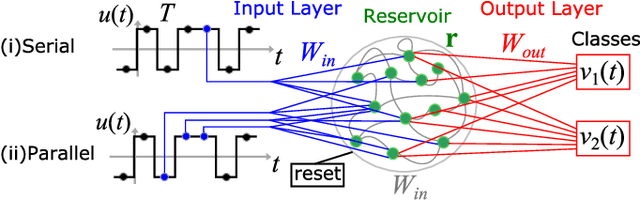
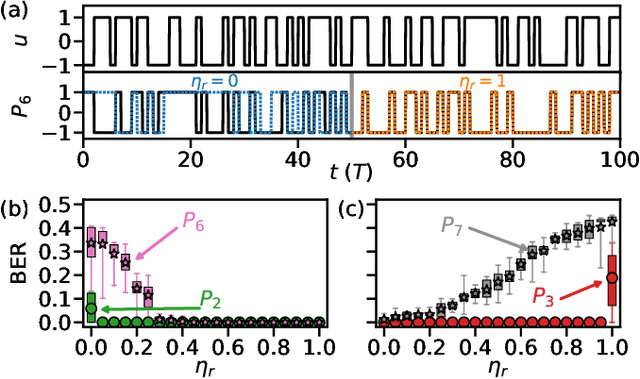
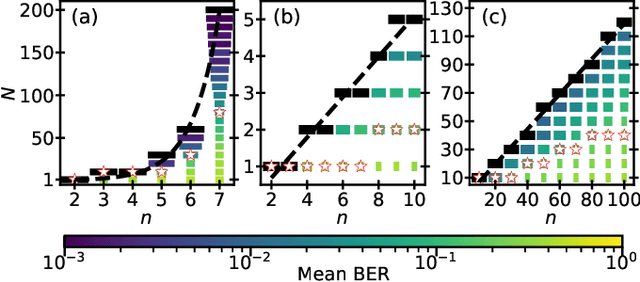
We demonstrate that matching the symmetry properties of a reservoir computer (RC) to the data being processed can dramatically increase its processing power. We apply our method to the parity task, a challenging benchmark problem, which highlights the benefits of symmetry matching. Our method outperforms all other approaches on this task, even artificial neural networks (ANN) hand crafted for this problem. The symmetry-aware RC can obtain zero error using an exponentially reduced number of artificial neurons and training data, greatly speeding up the time-to-result. We anticipate that generalizations of our procedure will have widespread applicability in information processing with ANNs.