 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural Lumigraph Rendering
Mar 22, 2021
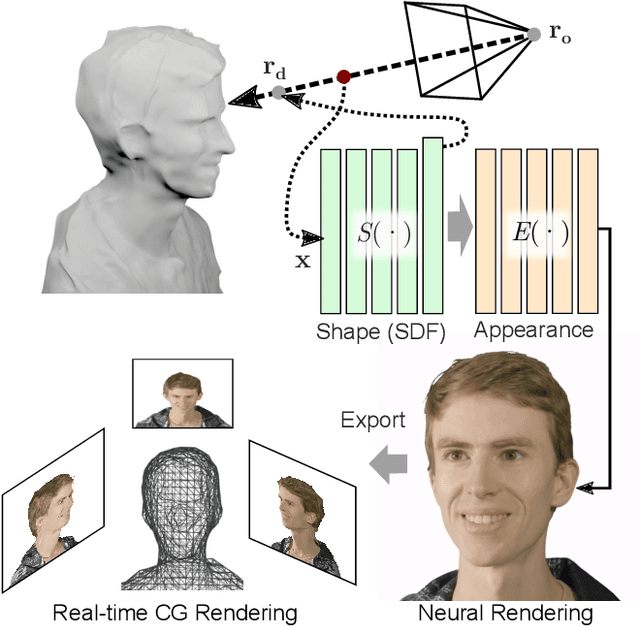


Novel view synthesis is a challenging and ill-posed inverse rendering problem. Neural rendering techniques have recently achieved photorealistic image quality for this task. State-of-the-art (SOTA) neural volume rendering approaches, however, are slow to train and require minutes of inference (i.e., rendering) time for high image resolutions. We adopt high-capacity neural scene representations with periodic activations for jointly optimizing an implicit surface and a radiance field of a scene supervised exclusively with posed 2D images. Our neural rendering pipeline accelerates SOTA neural volume rendering by about two orders of magnitude and our implicit surface representation is unique in allowing us to export a mesh with view-dependent texture information. Thus, like other implicit surface representations, ours is compatible with traditional graphics pipelines, enabling real-time rendering rates, while achieving unprecedented image quality compared to other surface methods. We assess the quality of our approach using existing datasets as well as high-quality 3D face data captured with a custom multi-camera rig.
Scalable Optical Learning Operator
Dec 22, 2020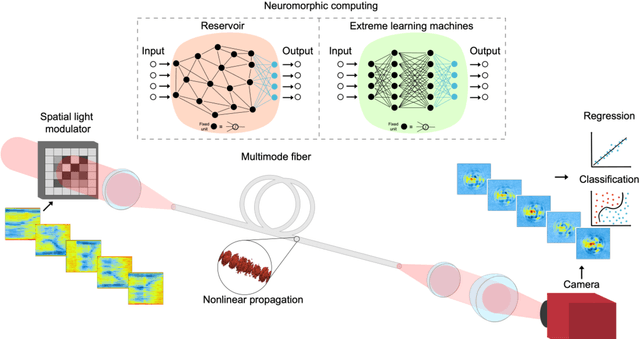
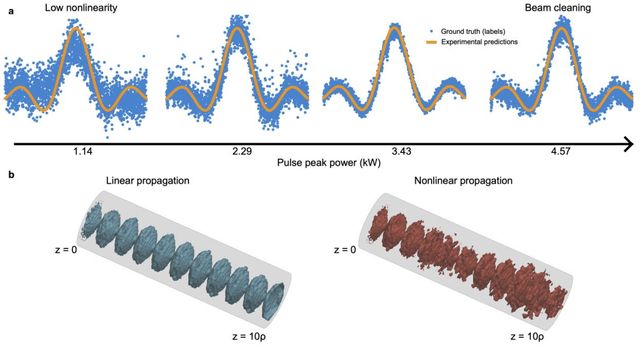
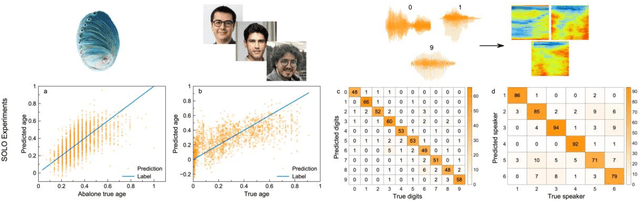
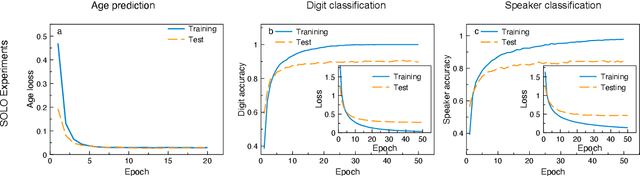
Today's heavy machine learning tasks are fueled by large datasets. Computing is performed with power hungry processors whose performance is ultimately limited by the data transfer to and from memory. Optics is one of the powerful means of communicating and processing information and there is intense current interest in optical information processing for realizing high-speed computations. Here we present and experimentally demonstrate an optical computing framework based on spatiotemporal effects in multimode fibers for a range of learning tasks from classifying COVID-19 X-ray lung images and speech recognition to predicting age from face images. The presented framework overcomes the energy scaling problem of existing systems without compromising speed. We leveraged simultaneous, linear, and nonlinear interaction of spatial modes as a computation engine. We numerically and experimentally showed the ability of the method to execute several different tasks with accuracy comparable to a digital implementation. Our results indicate that a powerful supercomputer would be required to duplicate the performance of the multimode fiber-based computer.
Progressively Complementary Network for Fisheye Image Rectification Using Appearance Flow
Mar 31, 2021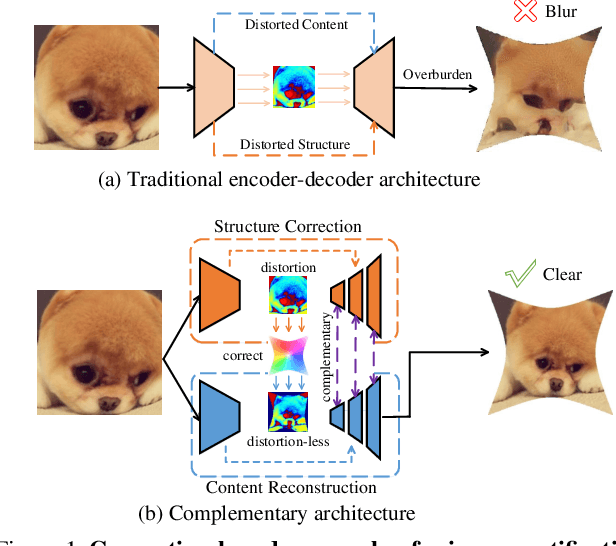
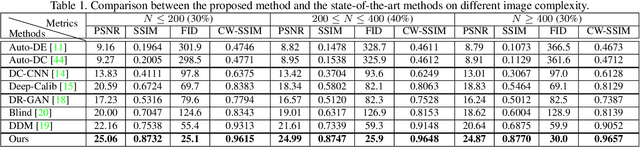
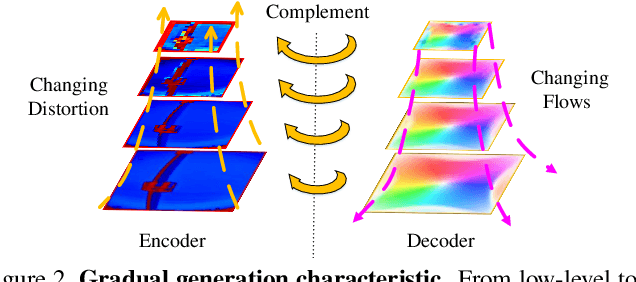
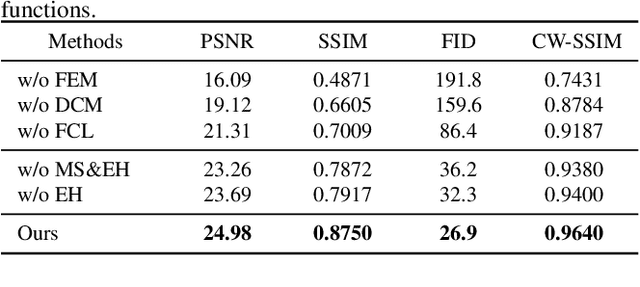
Distortion rectification is often required for fisheye images. The generation-based method is one mainstream solution due to its label-free property, but its naive skip-connection and overburdened decoder will cause blur and incomplete correction. First, the skip-connection directly transfers the image features, which may introduce distortion and cause incomplete correction. Second, the decoder is overburdened during simultaneously reconstructing the content and structure of the image, resulting in vague performance. To solve these two problems, in this paper, we focus on the interpretable correction mechanism of the distortion rectification network and propose a feature-level correction scheme. We embed a correction layer in skip-connection and leverage the appearance flows in different layers to pre-correct the image features. Consequently, the decoder can easily reconstruct a plausible result with the remaining distortion-less information. In addition, we propose a parallel complementary structure. It effectively reduces the burden of the decoder by separating content reconstruction and structure correction. Subjective and objective experiment results on different datasets demonstrate the superiority of our method.
Rule-Based Approach for Party-Based Sentiment Analysis in Legal Opinion Texts
Nov 13, 2020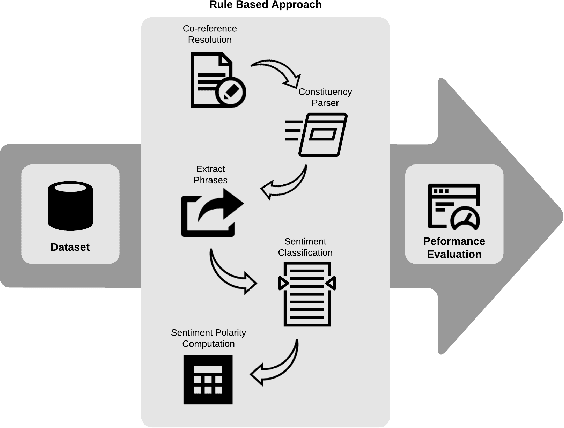
A document which elaborates opinions and arguments related to the previous court cases is known as a legal opinion text. Lawyers and legal officials have to spend considerable effort and time to obtain the required information manually from those documents when dealing with new legal cases. Hence, it provides much convenience to those individuals if there is a way to automate the process of extracting information from legal opinion texts. Party-based sentiment analysis will play a key role in the automation system by identifying opinion values with respect to each legal parties in legal texts.
FedGNN: Federated Graph Neural Network for Privacy-Preserving Recommendation
Feb 09, 2021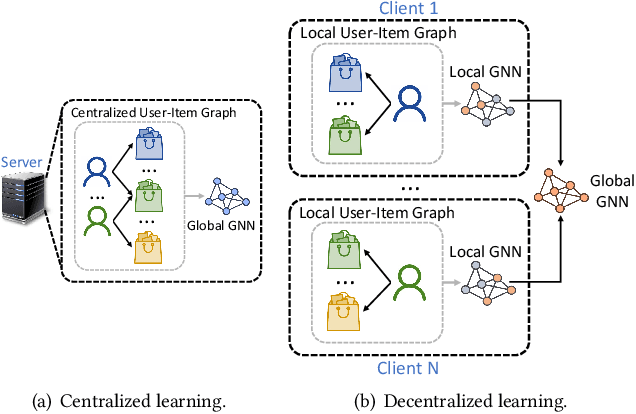

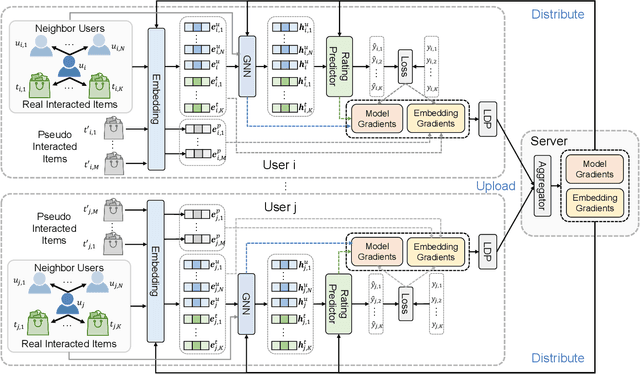

Graph neural network (GNN) is widely used for recommendation to model high-order interactions between users and items. Existing GNN-based recommendation methods rely on centralized storage of user-item graphs and centralized model learning. However, user data is privacy-sensitive, and the centralized storage of user-item graphs may arouse privacy concerns and risk. In this paper, we propose a federated framework for privacy-preserving GNN-based recommendation, which can collectively train GNN models from decentralized user data and meanwhile exploit high-order user-item interaction information with privacy well protected. In our method, we locally train GNN model in each user client based on the user-item graph inferred from the local user-item interaction data. Each client uploads the local gradients of GNN to a server for aggregation, which are further sent to user clients for updating local GNN models. Since local gradients may contain private information, we apply local differential privacy techniques to the local gradients to protect user privacy. In addition, in order to protect the items that users have interactions with, we propose to incorporate randomly sampled items as pseudo interacted items for anonymity. To incorporate high-order user-item interactions, we propose a user-item graph expansion method that can find neighboring users with co-interacted items and exchange their embeddings for expanding the local user-item graphs in a privacy-preserving way. Extensive experiments on six benchmark datasets validate that our approach can achieve competitive results with existing centralized GNN-based recommendation methods and meanwhile effectively protect user privacy.
Relational Subsets Knowledge Distillation for Long-tailed Retinal Diseases Recognition
Apr 22, 2021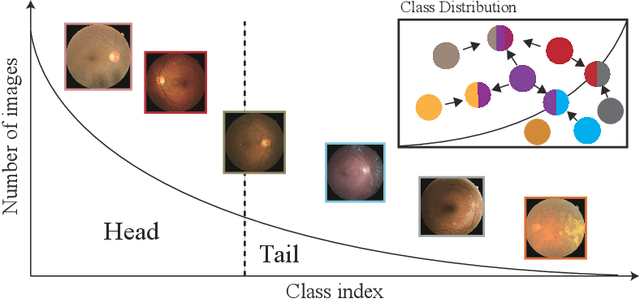

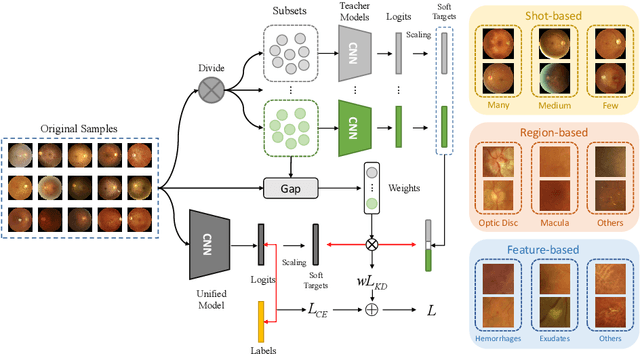
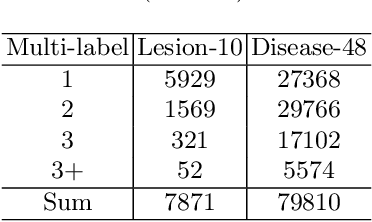
In the real world, medical datasets often exhibit a long-tailed data distribution (i.e., a few classes occupy most of the data, while most classes have rarely few samples), which results in a challenging imbalance learning scenario. For example, there are estimated more than 40 different kinds of retinal diseases with variable morbidity, however with more than 30+ conditions are very rare from the global patient cohorts, which results in a typical long-tailed learning problem for deep learning-based screening models. In this study, we propose class subset learning by dividing the long-tailed data into multiple class subsets according to prior knowledge, such as regions and phenotype information. It enforces the model to focus on learning the subset-specific knowledge. More specifically, there are some relational classes that reside in the fixed retinal regions, or some common pathological features are observed in both the majority and minority conditions. With those subsets learnt teacher models, then we are able to distill the multiple teacher models into a unified model with weighted knowledge distillation loss. The proposed framework proved to be effective for the long-tailed retinal diseases recognition task. The experimental results on two different datasets demonstrate that our method is flexible and can be easily plugged into many other state-of-the-art techniques with significant improvements.
Global-to-Local Neural Networks for Document-Level Relation Extraction
Sep 22, 2020
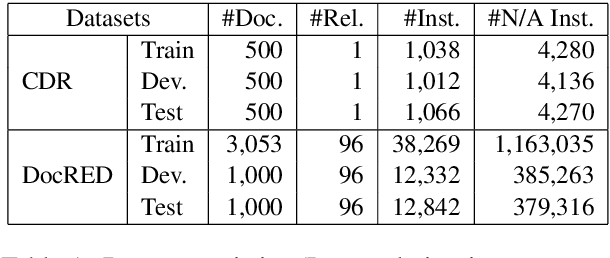
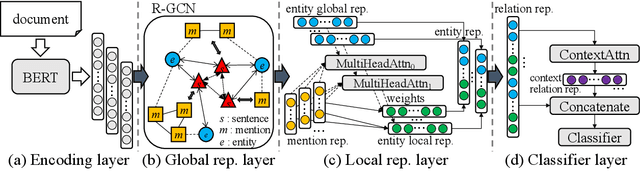
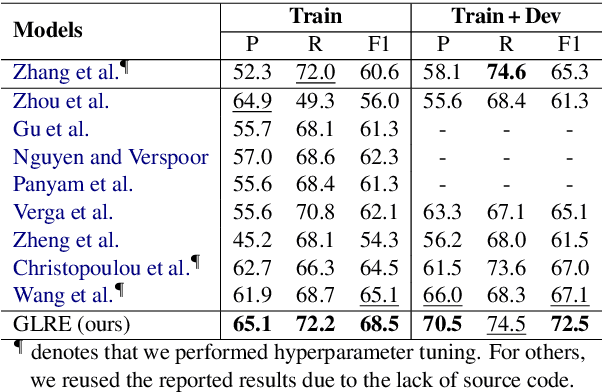
Relation extraction (RE) aims to identify the semantic relations between named entities in text. Recent years have witnessed it raised to the document level, which requires complex reasoning with entities and mentions throughout an entire document. In this paper, we propose a novel model to document-level RE, by encoding the document information in terms of entity global and local representations as well as context relation representations. Entity global representations model the semantic information of all entities in the document, entity local representations aggregate the contextual information of multiple mentions of specific entities, and context relation representations encode the topic information of other relations. Experimental results demonstrate that our model achieves superior performance on two public datasets for document-level RE. It is particularly effective in extracting relations between entities of long distance and having multiple mentions.
FCOS3D: Fully Convolutional One-Stage Monocular 3D Object Detection
Apr 22, 2021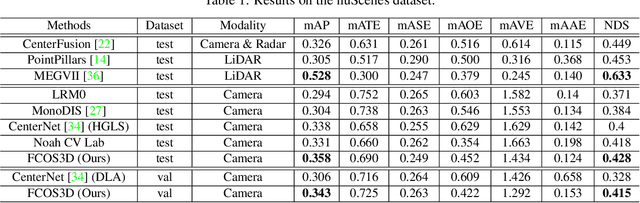
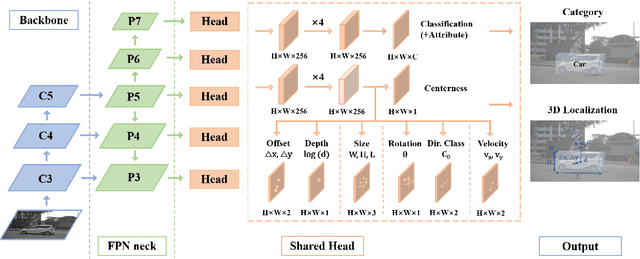

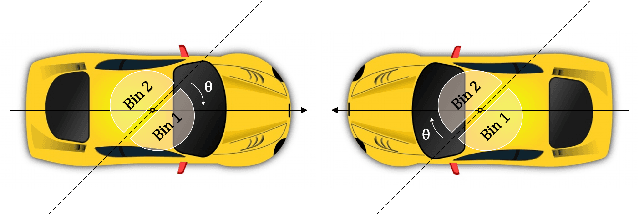
Monocular 3D object detection is an important task for autonomous driving considering its advantage of low cost. It is much more challenging compared to conventional 2D case due to its inherent ill-posed property, which is mainly reflected on the lack of depth information. Recent progress on 2D detection offers opportunities to better solving this problem. However, it is non-trivial to make a general adapted 2D detector work in this 3D task. In this technical report, we study this problem with a practice built on fully convolutional single-stage detector and propose a general framework FCOS3D. Specifically, we first transform the commonly defined 7-DoF 3D targets to image domain and decouple it as 2D and 3D attributes. Then the objects are distributed to different feature levels with the consideration of their 2D scales and assigned only according to the projected 3D-center for training procedure. Furthermore, the center-ness is redefined with a 2D Guassian distribution based on the 3D-center to fit the 3D target formulation. All of these make this framework simple yet effective, getting rid of any 2D detection or 2D-3D correspondence priors. Our solution achieves 1st place out of all the vision-only methods in the nuScenes 3D detection challenge of NeurIPS 2020. Code and models are released at https://github.com/open-mmlab/mmdetection3d.
So-ViT: Mind Visual Tokens for Vision Transformer
Apr 22, 2021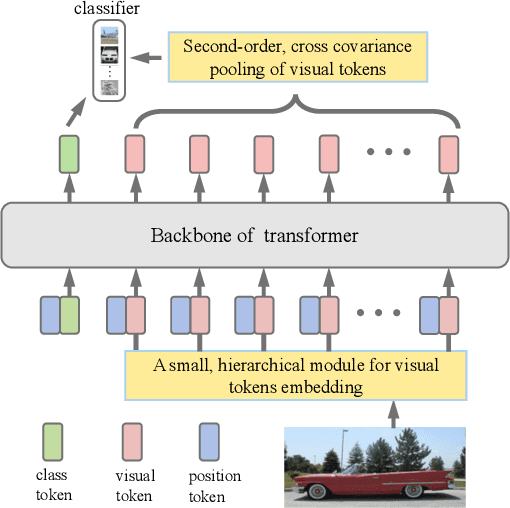
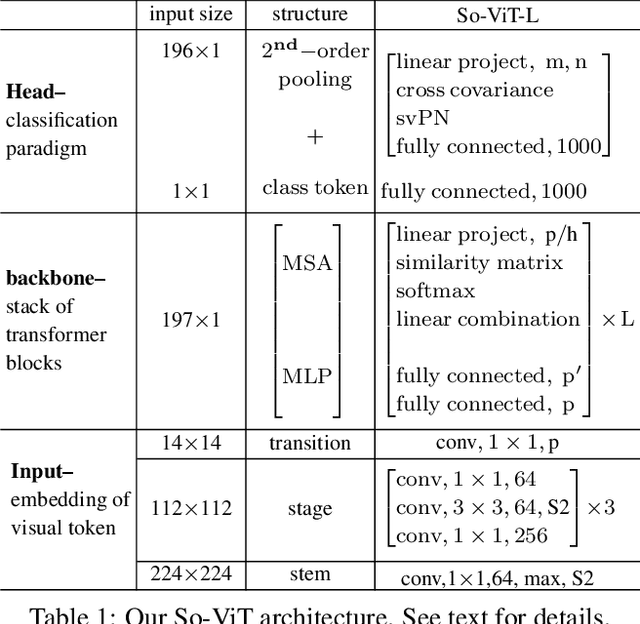
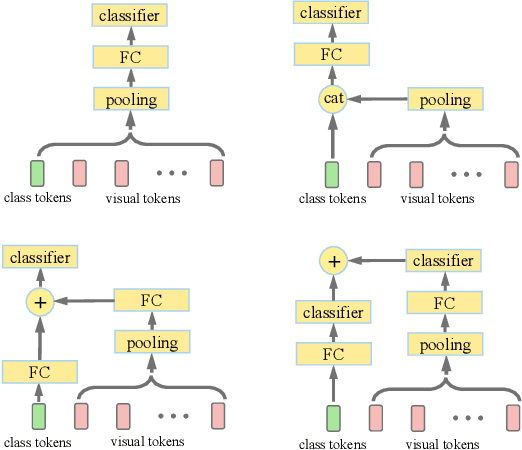
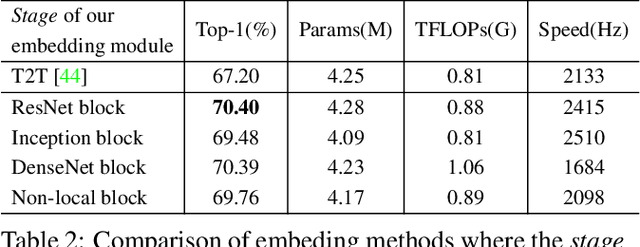
Recently the vision transformer (ViT) architecture, where the backbone purely consists of self-attention mechanism, has achieved very promising performance in visual classification. However, the high performance of the original ViT heavily depends on pretraining using ultra large-scale datasets, and it significantly underperforms on ImageNet-1K if trained from scratch. This paper makes the efforts toward addressing this problem, by carefully considering the role of visual tokens. First, for classification head, existing ViT only exploits class token while entirely neglecting rich semantic information inherent in high-level visual tokens. Therefore, we propose a new classification paradigm, where the second-order, cross-covariance pooling of visual tokens is combined with class token for final classification. Meanwhile, a fast singular value power normalization is proposed for improving the second-order pooling. Second, the original ViT employs the naive embedding of fixed-size image patches, lacking the ability to model translation equivariance and locality. To alleviate this problem, we develop a light-weight, hierarchical module based on off-the-shelf convolutions for visual token embedding. The proposed architecture, which we call So-ViT, is thoroughly evaluated on ImageNet-1K. The results show our models, when trained from scratch, outperform the competing ViT variants, while being on par with or better than state-of-the-art CNN models. Code is available at https://github.com/jiangtaoxie/So-ViT
MeerCRAB: MeerLICHT Classification of Real and Bogus Transients using Deep Learning
Apr 28, 2021

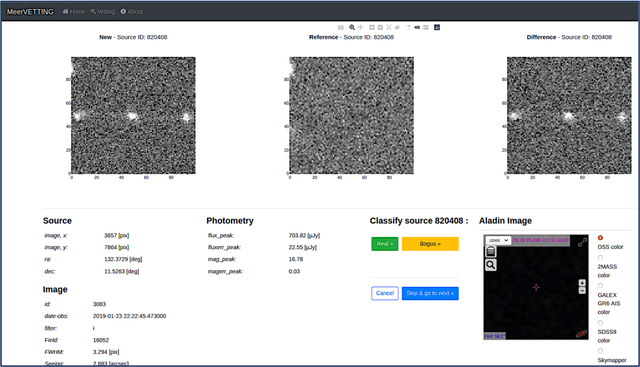
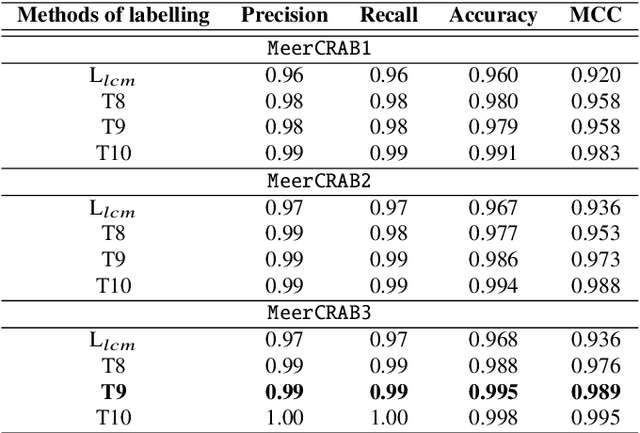
Astronomers require efficient automated detection and classification pipelines when conducting large-scale surveys of the (optical) sky for variable and transient sources. Such pipelines are fundamentally important, as they permit rapid follow-up and analysis of those detections most likely to be of scientific value. We therefore present a deep learning pipeline based on the convolutional neural network architecture called $\texttt{MeerCRAB}$. It is designed to filter out the so called 'bogus' detections from true astrophysical sources in the transient detection pipeline of the MeerLICHT telescope. Optical candidates are described using a variety of 2D images and numerical features extracted from those images. The relationship between the input images and the target classes is unclear, since the ground truth is poorly defined and often the subject of debate. This makes it difficult to determine which source of information should be used to train a classification algorithm. We therefore used two methods for labelling our data (i) thresholding and (ii) latent class model approaches. We deployed variants of $\texttt{MeerCRAB}$ that employed different network architectures trained using different combinations of input images and training set choices, based on classification labels provided by volunteers. The deepest network worked best with an accuracy of 99.5$\%$ and Matthews correlation coefficient (MCC) value of 0.989. The best model was integrated to the MeerLICHT transient vetting pipeline, enabling the accurate and efficient classification of detected transients that allows researchers to select the most promising candidates for their research goals.