 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Persian Ezafe Recognition Using Transformers and Its Role in Part-Of-Speech Tagging
Oct 04, 2020
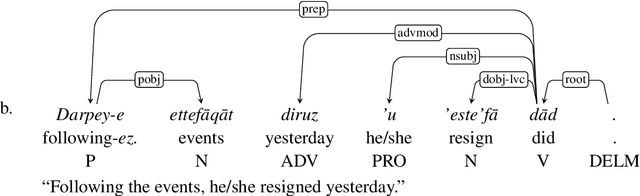
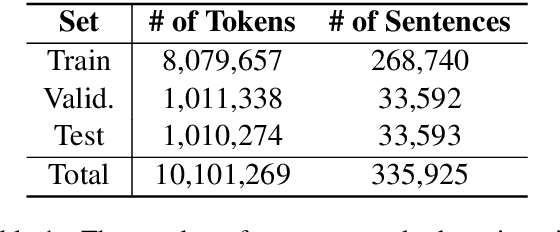
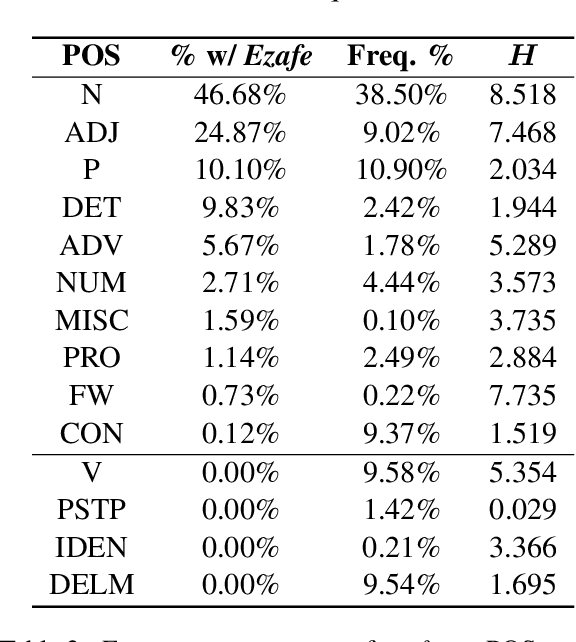
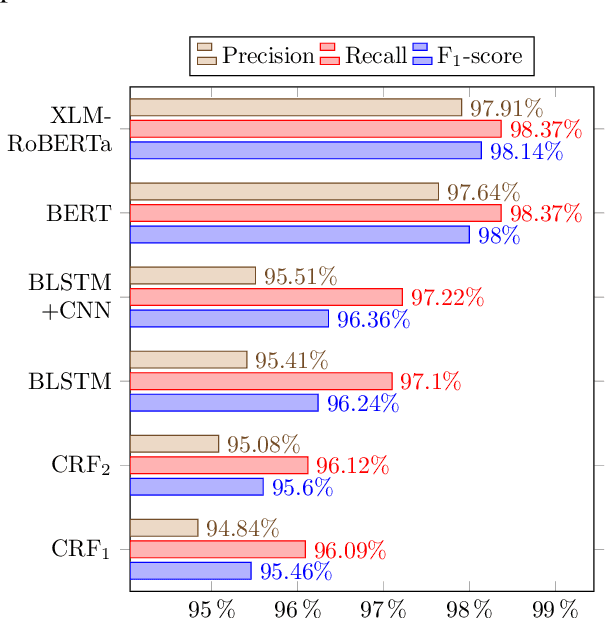
Ezafe is a grammatical particle in some Iranian languages that links two words together. Regardless of the important information it conveys, it is almost always not indicated in Persian script, resulting in mistakes in reading complex sentences and errors in natural language processing tasks. In this paper, we experiment with different machine learning methods to achieve state-of-the-art results in the task of ezafe recognition. Transformer-based methods, BERT and XLMRoBERTa, achieve the best results, the latter achieving 2.68% F1-score more than the previous state-of-the-art. We, moreover, use ezafe information to improve Persian part-of-speech tagging results and show that such information will not be useful to transformer-based methods and explain why that might be the case.
Gaussian Process for Tomography
Mar 29, 2021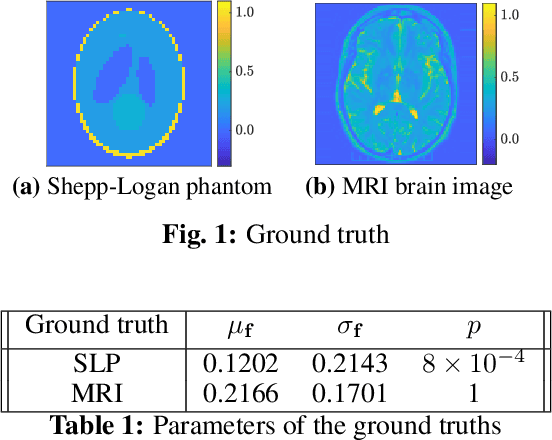
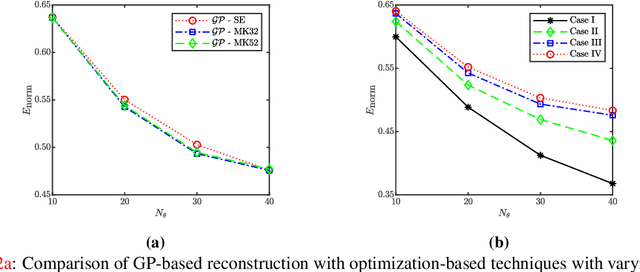
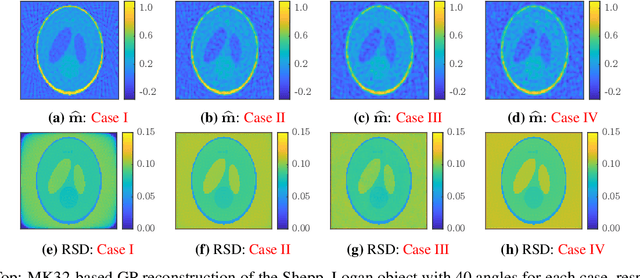
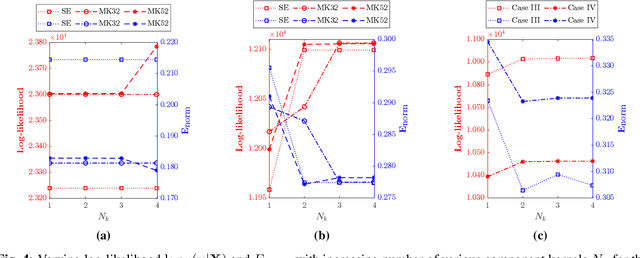
Tomographic reconstruction, despite its revolutionary impact on a wide range of applications, suffers from its ill-posed nature in that there is no unique solution because of limited and noisy measurements. Traditional optimization-based reconstruction relies on regularization to address this issue; however, it faces its own challenge because the type of regularizer and choice of regularization parameter are a critical but difficult decision. Moreover, traditional reconstruction yields point estimates for the reconstruction with no further indication of the quality of the solution. In this work we address these challenges by exploring Gaussian processes (GPs). Our proposed GP approach yields not only the reconstructed object through the posterior mean but also a quantification of the solution uncertainties through the posterior covariance. Furthermore, we explore the flexibility of the GP framework to provide a robust model of the information across various length scales in the object, as well as the complex noise in the measurements. We illustrate the proposed approach on both synthetic and real tomography images and show its unique capability of uncertainty quantification in the presence of various types of noise, as well as reconstruction comparison with existing methods.
MIDeepSeg: Minimally Interactive Segmentation of Unseen Objects from Medical Images Using Deep Learning
Apr 25, 2021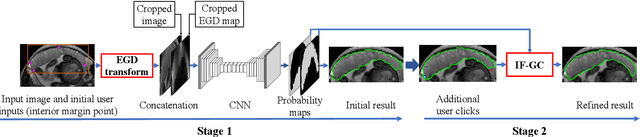
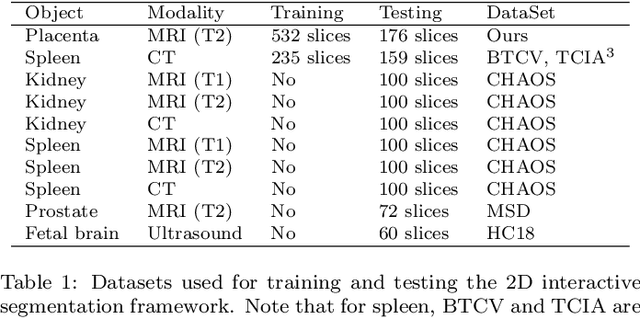
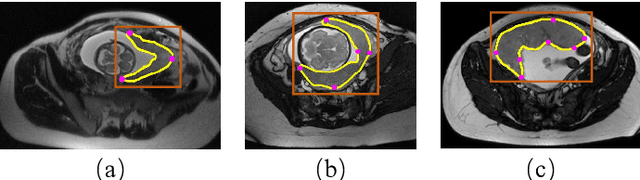
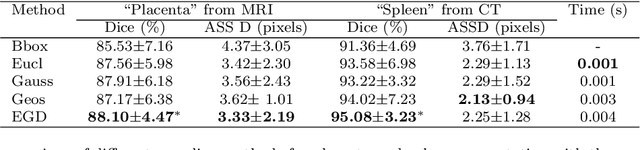
Segmentation of organs or lesions from medical images plays an essential role in many clinical applications such as diagnosis and treatment planning. Though Convolutional Neural Networks (CNN) have achieved the state-of-the-art performance for automatic segmentation, they are often limited by the lack of clinically acceptable accuracy and robustness in complex cases. Therefore, interactive segmentation is a practical alternative to these methods. However, traditional interactive segmentation methods require a large amount of user interactions, and recently proposed CNN-based interactive segmentation methods are limited by poor performance on previously unseen objects. To solve these problems, we propose a novel deep learning-based interactive segmentation method that not only has high efficiency due to only requiring clicks as user inputs but also generalizes well to a range of previously unseen objects. Specifically, we first encode user-provided interior margin points via our proposed exponentialized geodesic distance that enables a CNN to achieve a good initial segmentation result of both previously seen and unseen objects, then we use a novel information fusion method that combines the initial segmentation with only few additional user clicks to efficiently obtain a refined segmentation. We validated our proposed framework through extensive experiments on 2D and 3D medical image segmentation tasks with a wide range of previous unseen objects that were not present in the training set. Experimental results showed that our proposed framework 1) achieves accurate results with fewer user interactions and less time compared with state-of-the-art interactive frameworks and 2) generalizes well to previously unseen objects.
Sim-to-real for high-resolution optical tactile sensing: From images to 3D contact force distributions
Dec 31, 2020
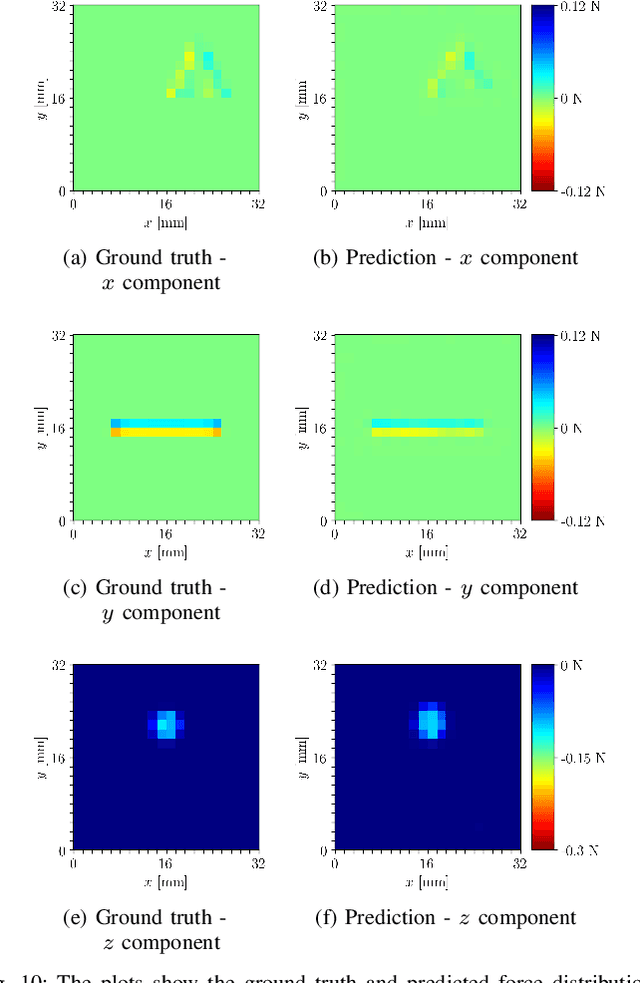


The images captured by vision-based tactile sensors carry information about high-resolution tactile fields, such as the distribution of the contact forces applied to their soft sensing surface. However, extracting the information encoded in the images is challenging and often addressed with learning-based approaches, which generally require a large amount of training data. This article proposes a strategy to generate tactile images in simulation for a vision-based tactile sensor based on an internal camera that tracks the motion of spherical particles within a soft material. The deformation of the material is simulated in a finite element environment under a diverse set of contact conditions, and spherical particles are projected to a simulated image. Features extracted from the images are mapped to the 3D contact force distribution, with the ground truth also obtained via finite-element simulations, with an artificial neural network that is therefore entirely trained on synthetic data avoiding the need for real-world data collection. The resulting model exhibits high accuracy when evaluated on real-world tactile images, is transferable across multiple tactile sensors without further training, and is suitable for efficient real-time inference.
Human Pose Transfer by Adaptive Hierarchical Deformation
Dec 13, 2020Human pose transfer, as a misaligned image generation task, is very challenging. Existing methods cannot effectively utilize the input information, which often fail to preserve the style and shape of hair and clothes. In this paper, we propose an adaptive human pose transfer network with two hierarchical deformation levels. The first level generates human semantic parsing aligned with the target pose, and the second level generates the final textured person image in the target pose with the semantic guidance. To avoid the drawback of vanilla convolution that treats all the pixels as valid information, we use gated convolution in both two levels to dynamically select the important features and adaptively deform the image layer by layer. Our model has very few parameters and is fast to converge. Experimental results demonstrate that our model achieves better performance with more consistent hair, face and clothes with fewer parameters than state-of-the-art methods. Furthermore, our method can be applied to clothing texture transfer.
* 13 pages, 10 figures. Code is available at https://github.com/Zhangjinso/PINet_PG
Meta Graph Attention on Heterogeneous Graph with Node-Edge Co-evolution
Oct 09, 2020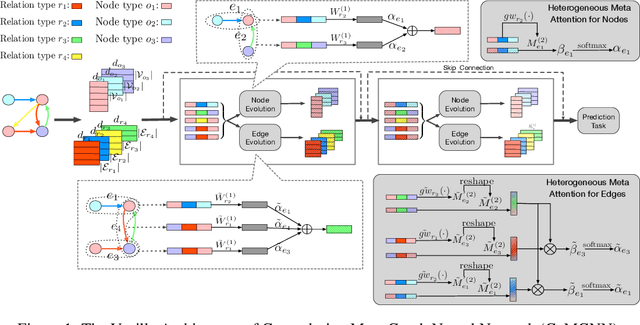
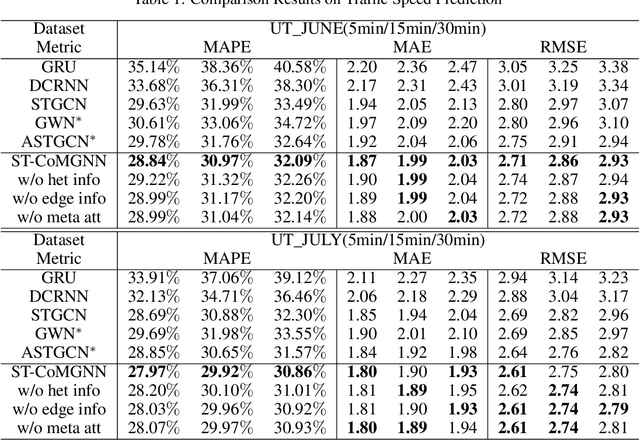
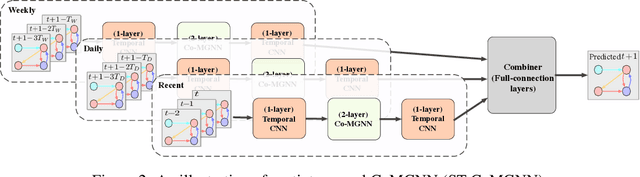
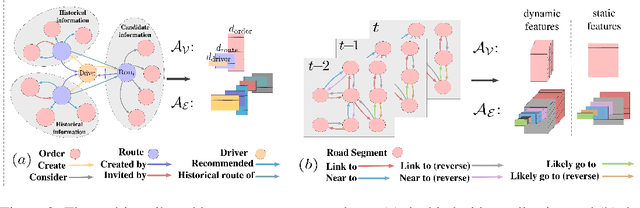
Graph neural networks have become an important tool for modeling structured data. In many real-world systems, intricate hidden information may exist, e.g., heterogeneity in nodes/edges, static node/edge attributes, and spatiotemporal node/edge features. However, most existing methods only take part of the information into consideration. In this paper, we present the Co-evolved Meta Graph Neural Network (CoMGNN), which applies meta graph attention to heterogeneous graphs with co-evolution of node and edge states. We further propose a spatiotemporal adaption of CoMGNN (ST-CoMGNN) for modeling spatiotemporal patterns on nodes and edges. We conduct experiments on two large-scale real-world datasets. Experimental results show that our models significantly outperform the state-of-the-art methods, demonstrating the effectiveness of encoding diverse information from different aspects.
Multi-agent Bayesian Learning with Adaptive Strategies: Convergence and Stability
Oct 18, 2020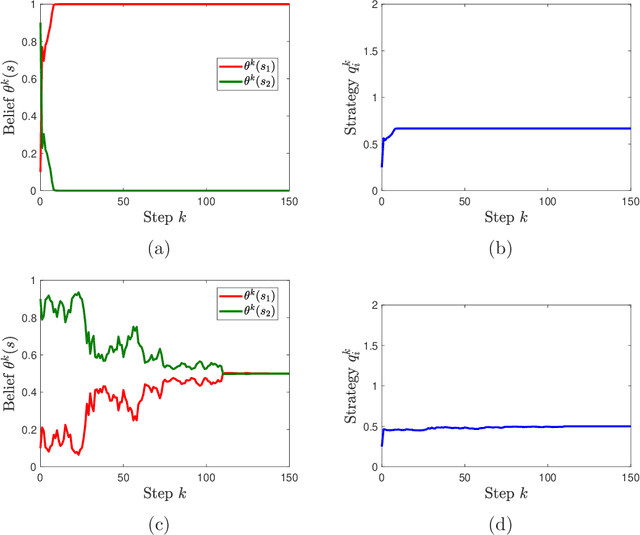
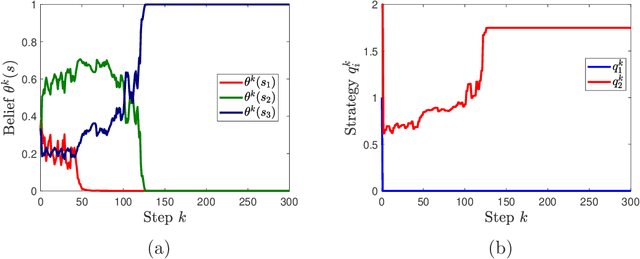
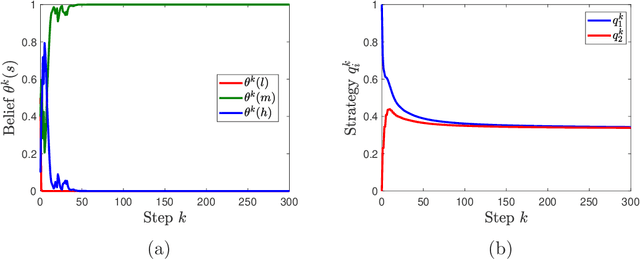
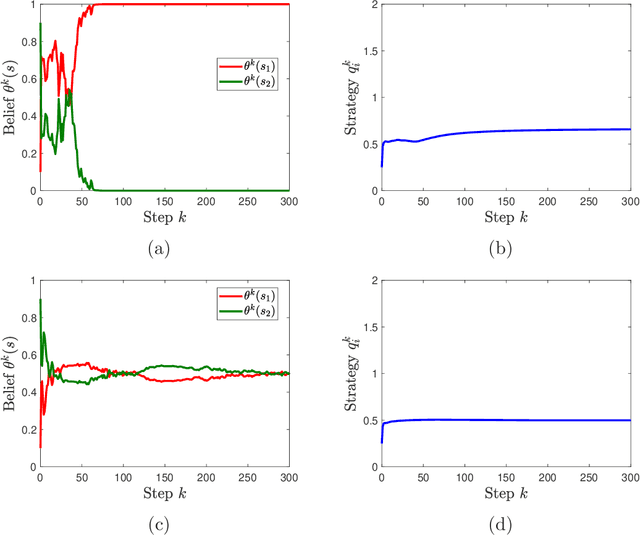
We study learning dynamics induced by strategic agents who repeatedly play a game with an unknown payoff-relevant parameter. In each step, an information system estimates a belief distribution of the parameter based on the players' strategies and realized payoffs using Bayes' rule. Players adjust their strategies by accounting for an equilibrium strategy or a best response strategy based on the updated belief. We prove that beliefs and strategies converge to a fixed point with probability 1. We also provide conditions that guarantee local and global stability of fixed points. Any fixed point belief consistently estimates the payoff distribution given the fixed point strategy profile. However, convergence to a complete information Nash equilibrium is not always guaranteed. We provide a sufficient and necessary condition under which fixed point belief recovers the unknown parameter. We also provide a sufficient condition for convergence to complete information equilibrium even when parameter learning is incomplete.
Using Information Invariants to Compare Swarm Algorithms and General Multi-Robot Algorithms: A Technical Report
Feb 25, 2018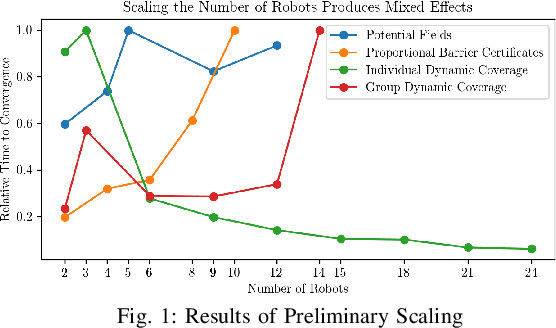
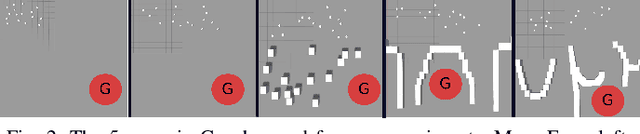
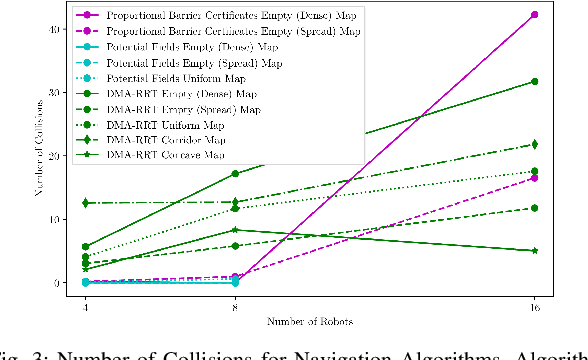
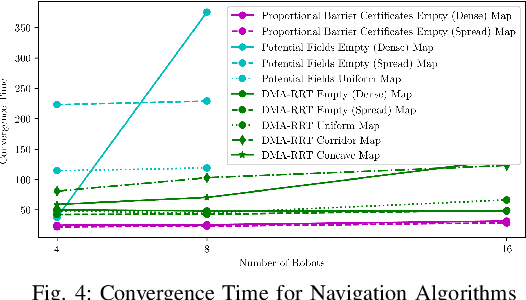
Robotic swarms are decentralized multi-robot systems whose members use local information from proximal neighbors to execute simple reactive control laws that result in emergent collective behaviors. In contrast, members of a general multi-robot system may have access to global information, all- to-all communication or sophisticated deliberative collabora- tion. Some algorithms in the literature are applicable to robotic swarms. Others require the extra complexity of general multi- robot systems. Given an application domain, a system designer or supervisory operator must choose an appropriate system or algorithm respectively that will enable them to achieve their goals while satisfying mission constraints (e.g. bandwidth, energy, time limits). In this paper, we compare representative swarm and general multi-robot algorithms in two application domains - navigation and dynamic area coverage - with respect to several metrics (e.g. completion time, distance trav- elled). Our objective is to characterize each class of algorithms to inform offline system design decisions by engineers or online algorithm selection decisions by supervisory operators. Our contributions are (a) an empirical performance comparison of representative swarm and general multi-robot algorithms in two application domains, (b) a comparative analysis of the algorithms based on the theory of information invariants, which provides a theoretical characterization supported by our empirical results.
Fine-tuning Handwriting Recognition systems with Temporal Dropout
Jan 31, 2021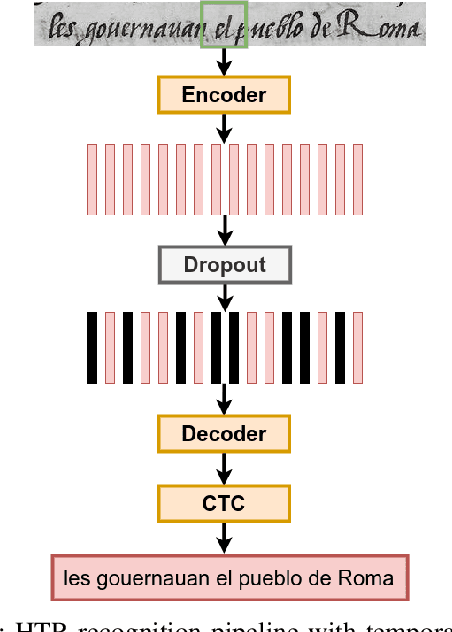
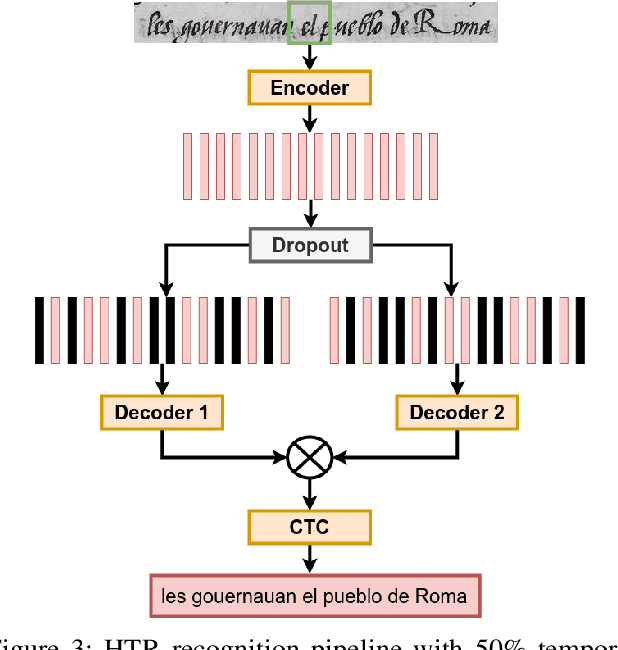
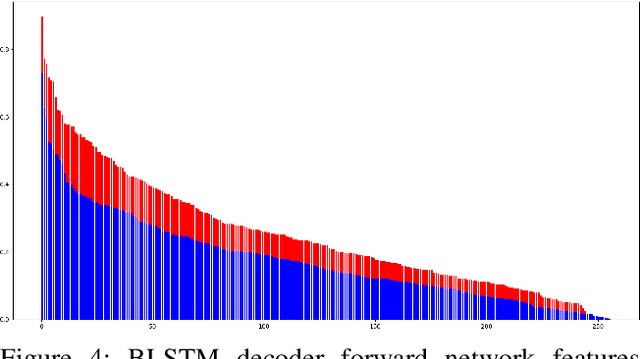
This paper introduces a novel method to fine-tune handwriting recognition systems based on Recurrent Neural Networks (RNN). Long Short-Term Memory (LSTM) networks are good at modeling long sequences but they tend to overfit over time. To improve the system's ability to model sequences, we propose to drop information at random positions in the sequence. We call our approach Temporal Dropout (TD). We apply TD at the image level as well to internal network representation. We show that TD improves the results on two different datasets. Our method outperforms previous state-of-the-art on Rodrigo dataset.
Boosting the Speed of Entity Alignment 10*: Dual Attention Matching Network with Normalized Hard Sample Mining
Mar 29, 2021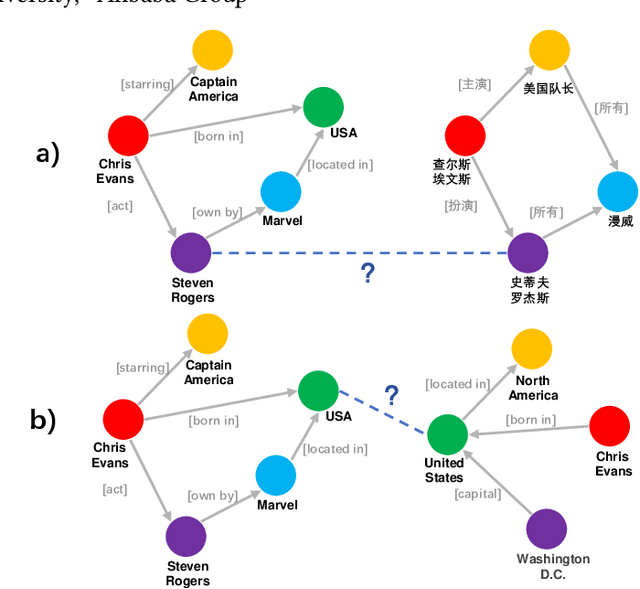
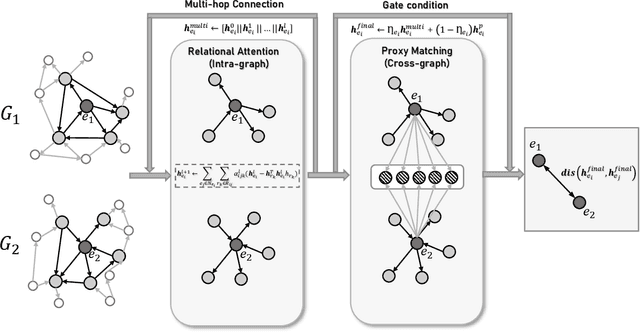
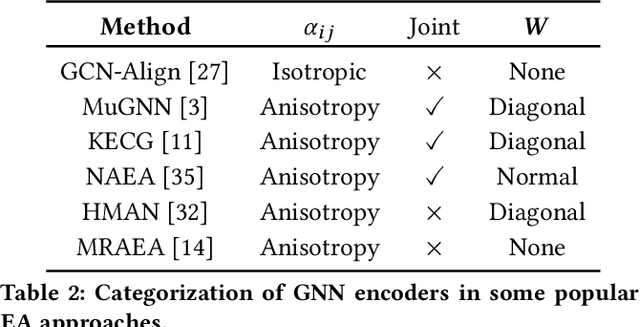
Seeking the equivalent entities among multi-source Knowledge Graphs (KGs) is the pivotal step to KGs integration, also known as \emph{entity alignment} (EA). However, most existing EA methods are inefficient and poor in scalability. A recent summary points out that some of them even require several days to deal with a dataset containing 200,000 nodes (DWY100K). We believe over-complex graph encoder and inefficient negative sampling strategy are the two main reasons. In this paper, we propose a novel KG encoder -- Dual Attention Matching Network (Dual-AMN), which not only models both intra-graph and cross-graph information smartly, but also greatly reduces computational complexity. Furthermore, we propose the Normalized Hard Sample Mining Loss to smoothly select hard negative samples with reduced loss shift. The experimental results on widely used public datasets indicate that our method achieves both high accuracy and high efficiency. On DWY100K, the whole running process of our method could be finished in 1,100 seconds, at least 10* faster than previous work. The performances of our method also outperform previous works across all datasets, where Hits@1 and MRR have been improved from 6% to 13%.