 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SuSketch: Surrogate Models of Gameplay as a Design Assistant
Mar 22, 2021
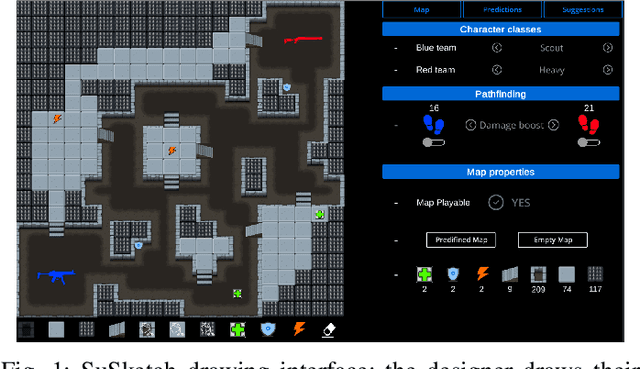

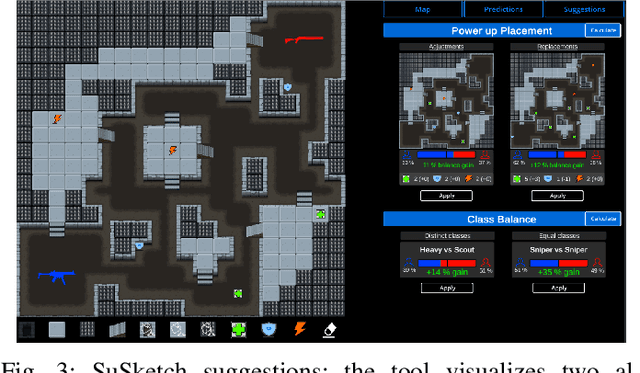
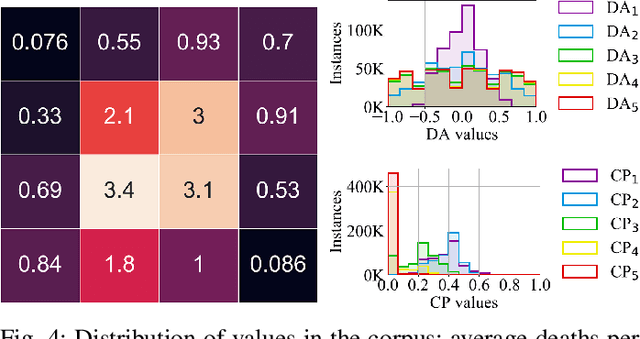
This paper introduces SuSketch, a design tool for first person shooter levels. SuSketch provides the designer with gameplay predictions for two competing players of specific character classes. The interface allows the designer to work side-by-side with an artificially intelligent creator and to receive varied types of feedback such as path information, predicted balance between players in a complete playthrough, or a predicted heatmap of the locations of player deaths. The system also proactively designs alternatives to the level and class pairing, and presents them to the designer as suggestions that improve the predicted balance of the game. SuSketch offers a new way of integrating machine learning into mixed-initiative co-creation tools, as a surrogate of human play trained on a large corpus of artificial playtraces. A user study with 16 game developers indicated that the tool was easy to use, but also highlighted a need to make SuSketch more accessible and more explainable.
Trans-SVNet: Accurate Phase Recognition from Surgical Videos via Hybrid Embedding Aggregation Transformer
Mar 17, 2021
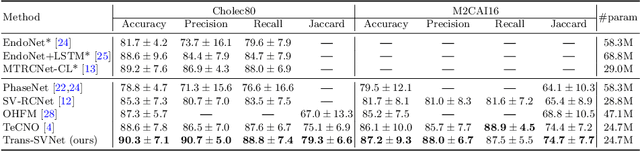
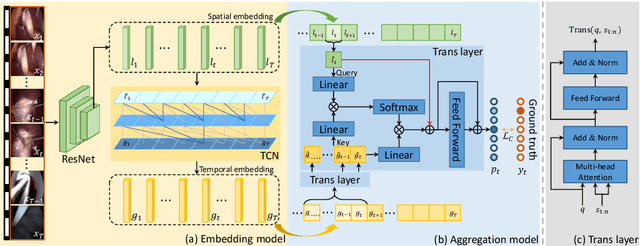

Real-time surgical phase recognition is a fundamental task in modern operating rooms. Previous works tackle this task relying on architectures arranged in spatio-temporal order, however, the supportive benefits of intermediate spatial features are not considered. In this paper, we introduce, for the first time in surgical workflow analysis, Transformer to reconsider the ignored complementary effects of spatial and temporal features for accurate surgical phase recognition. Our hybrid embedding aggregation Transformer fuses cleverly designed spatial and temporal embeddings by allowing for active queries based on spatial information from temporal embedding sequences. More importantly, our framework is lightweight and processes the hybrid embeddings in parallel to achieve a high inference speed. Our method is thoroughly validated on two large surgical video datasets, i.e., Cholec80 and M2CAI16 Challenge datasets, and significantly outperforms the state-of-the-art approaches at a processing speed of 91 fps.
ShipSRDet: An End-to-End Remote Sensing Ship Detector Using Super-Resolved Feature Representation
Mar 17, 2021
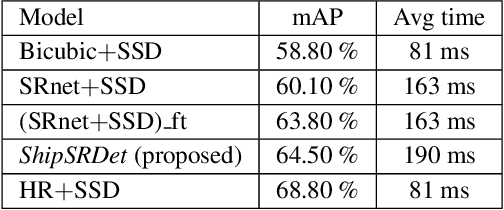
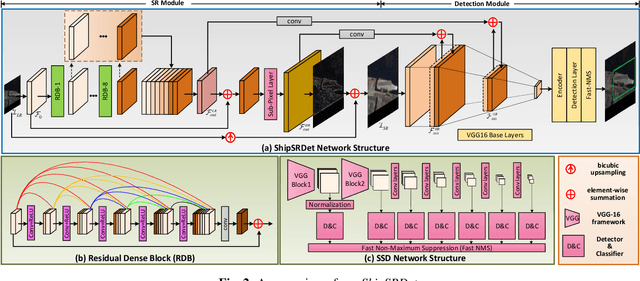

High-resolution remote sensing images can provide abundant appearance information for ship detection. Although several existing methods use image super-resolution (SR) approaches to improve the detection performance, they consider image SR and ship detection as two separate processes and overlook the internal coherence between these two correlated tasks. In this paper, we explore the potential benefits introduced by image SR to ship detection, and propose an end-to-end network named ShipSRDet. In our method, we not only feed the super-resolved images to the detector but also integrate the intermediate features of the SR network with those of the detection network. In this way, the informative feature representation extracted by the SR network can be fully used for ship detection. Experimental results on the HRSC dataset validate the effectiveness of our method. Our ShipSRDet can recover the missing details from the input image and achieves promising ship detection performance.
Fundamental Limits and Tradeoffs in Invariant Representation Learning
Dec 19, 2020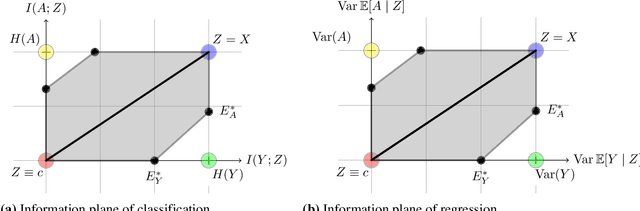
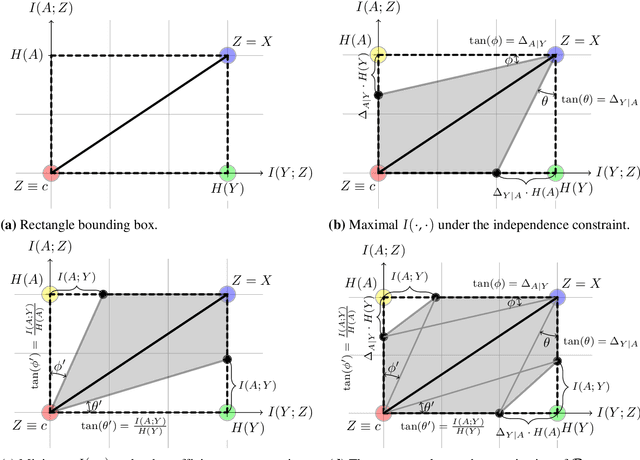
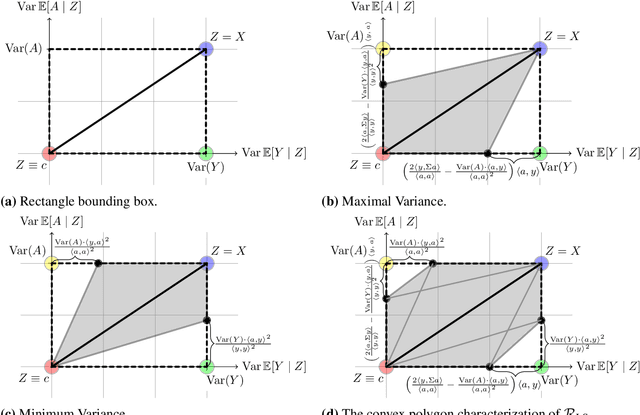
Many machine learning applications involve learning representations that achieve two competing goals: To maximize information or accuracy with respect to a subset of features (e.g.\ for prediction) while simultaneously maximizing invariance or independence with respect to another, potentially overlapping, subset of features (e.g.\ for fairness, privacy, etc). Typical examples include privacy-preserving learning, domain adaptation, and algorithmic fairness, just to name a few. In fact, all of the above problems admit a common minimax game-theoretic formulation, whose equilibrium represents a fundamental tradeoff between accuracy and invariance. Despite its abundant applications in the aforementioned domains, theoretical understanding on the limits and tradeoffs of invariant representations is severely lacking. In this paper, we provide an information-theoretic analysis of this general and important problem under both classification and regression settings. In both cases, we analyze the inherent tradeoffs between accuracy and invariance by providing a geometric characterization of the feasible region in the information plane, where we connect the geometric properties of this feasible region to the fundamental limitations of the tradeoff problem. In the regression setting, we also derive a tight lower bound on the Lagrangian objective that quantifies the tradeoff between accuracy and invariance. This lower bound leads to a better understanding of the tradeoff via the spectral properties of the joint distribution. In both cases, our results shed new light on this fundamental problem by providing insights on the interplay between accuracy and invariance. These results deepen our understanding of this fundamental problem and may be useful in guiding the design of adversarial representation learning algorithms.
Named Entity Recognition for Social Media Texts with Semantic Augmentation
Oct 29, 2020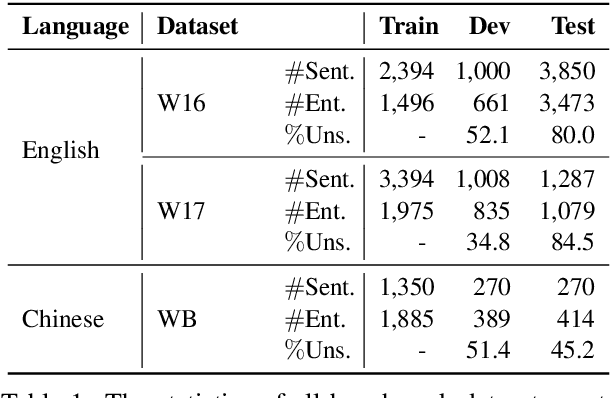
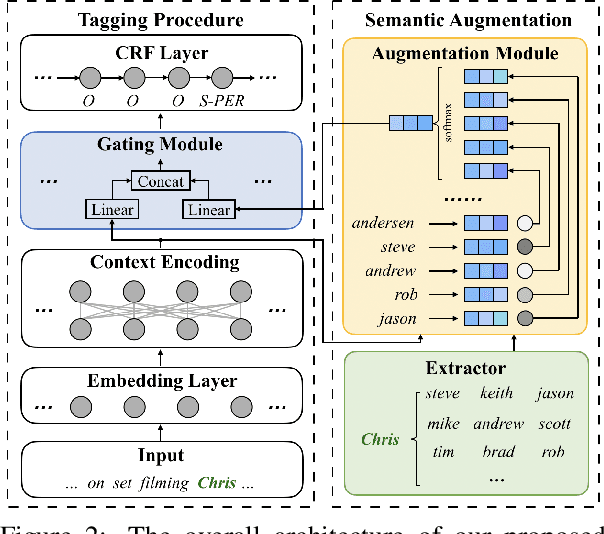
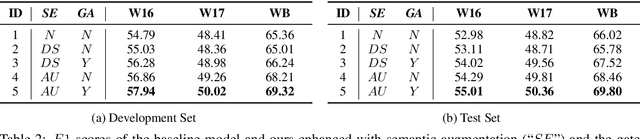
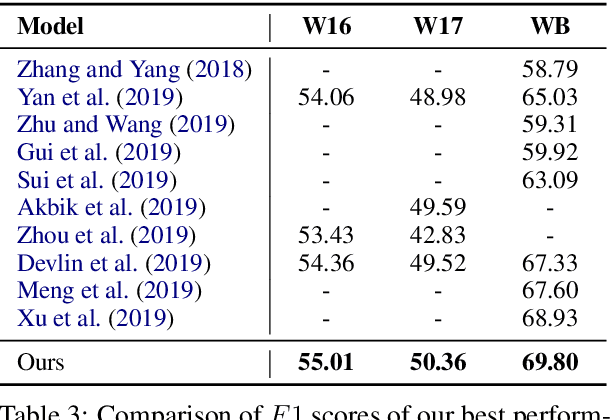
Existing approaches for named entity recognition suffer from data sparsity problems when conducted on short and informal texts, especially user-generated social media content. Semantic augmentation is a potential way to alleviate this problem. Given that rich semantic information is implicitly preserved in pre-trained word embeddings, they are potential ideal resources for semantic augmentation. In this paper, we propose a neural-based approach to NER for social media texts where both local (from running text) and augmented semantics are taken into account. In particular, we obtain the augmented semantic information from a large-scale corpus, and propose an attentive semantic augmentation module and a gate module to encode and aggregate such information, respectively. Extensive experiments are performed on three benchmark datasets collected from English and Chinese social media platforms, where the results demonstrate the superiority of our approach to previous studies across all three datasets.
Property Inference From Poisoning
Jan 26, 2021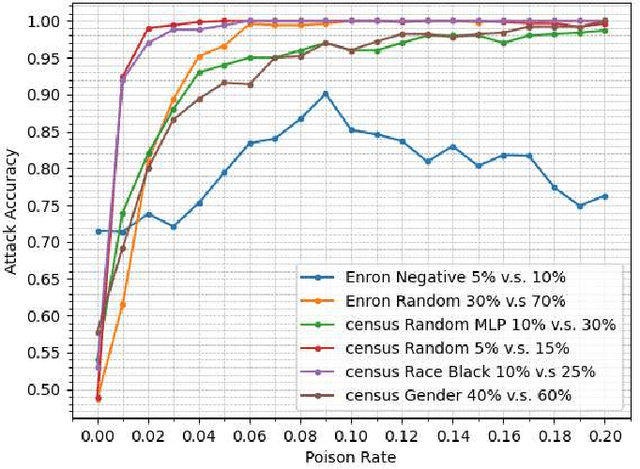
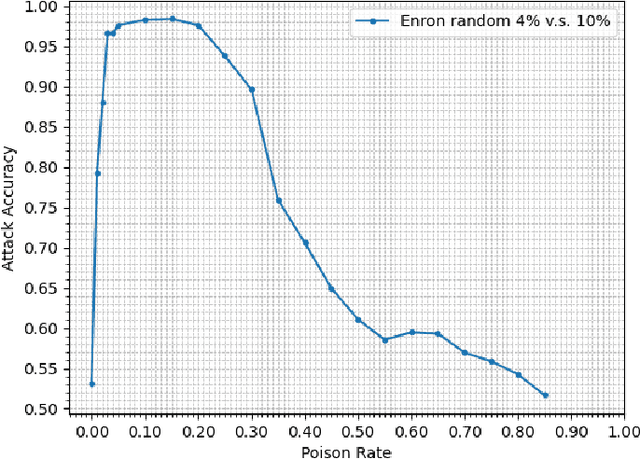
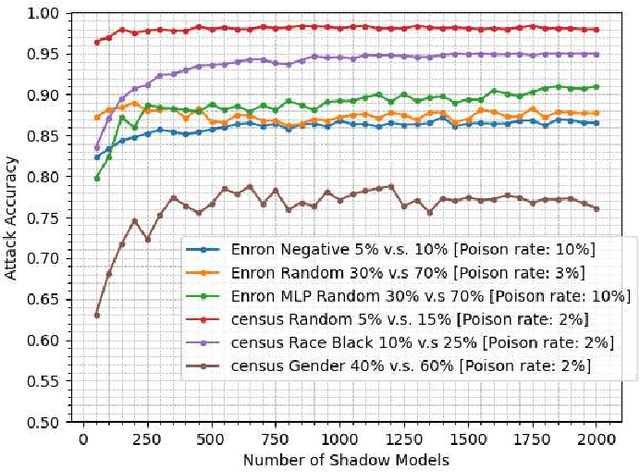
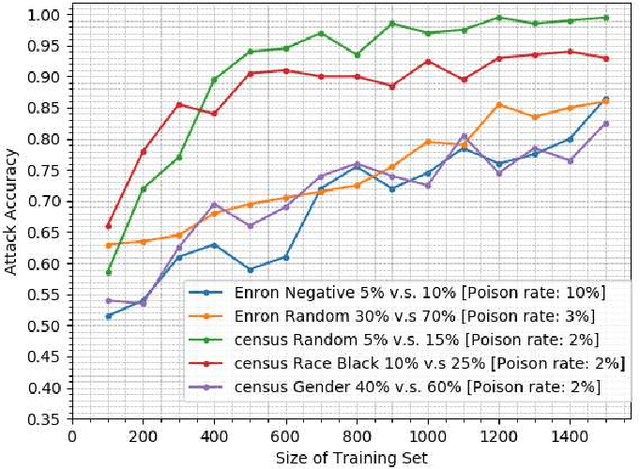
Property inference attacks consider an adversary who has access to the trained model and tries to extract some global statistics of the training data. In this work, we study property inference in scenarios where the adversary can maliciously control part of the training data (poisoning data) with the goal of increasing the leakage. Previous work on poisoning attacks focused on trying to decrease the accuracy of models either on the whole population or on specific sub-populations or instances. Here, for the first time, we study poisoning attacks where the goal of the adversary is to increase the information leakage of the model. Our findings suggest that poisoning attacks can boost the information leakage significantly and should be considered as a stronger threat model in sensitive applications where some of the data sources may be malicious. We describe our \emph{property inference poisoning attack} that allows the adversary to learn the prevalence in the training data of any property it chooses. We theoretically prove that our attack can always succeed as long as the learning algorithm used has good generalization properties. We then verify the effectiveness of our attack by experimentally evaluating it on two datasets: a Census dataset and the Enron email dataset. We were able to achieve above $90\%$ attack accuracy with $9-10\%$ poisoning in all of our experiments.
Finding the Gap: Neuromorphic Motion Vision in Cluttered Environments
Feb 16, 2021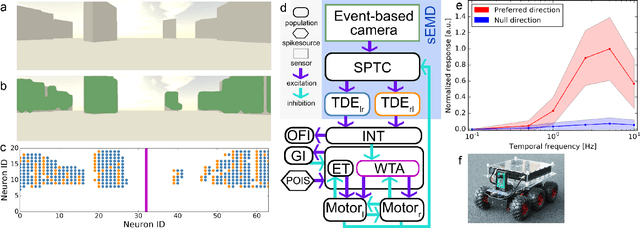
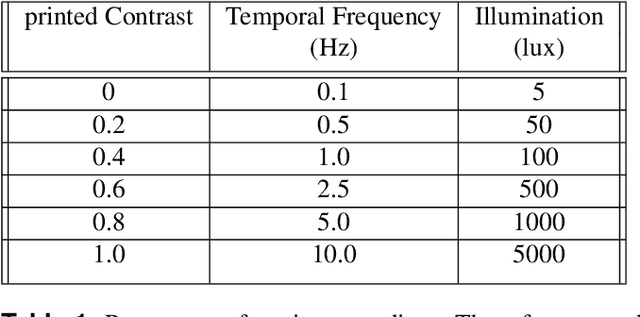
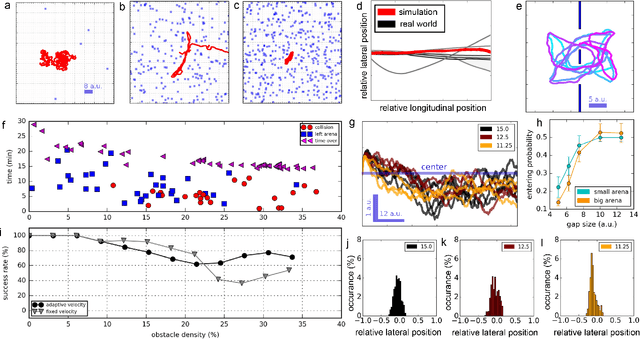
Many animals meander in environments and avoid collisions. How the underlying neuronal machinery can yield robust behaviour in a variety of environments remains unclear. In the fly brain, motion-sensitive neurons indicate the presence of nearby objects and directional cues are integrated within an area known as the central complex. Such neuronal machinery, in contrast with the traditional stream-based approach to signal processing, uses an event-based approach, with events occurring when changes are sensed by the animal. Contrary to von Neumann computing architectures, event-based neuromorphic hardware is designed to process information in an asynchronous and distributed manner. Inspired by the fly brain, we model, for the first time, a neuromorphic closed-loop system mimicking essential behaviours observed in flying insects, such as meandering in clutter and gap crossing, which are highly relevant for autonomous vehicles. We implemented our system both in software and on neuromorphic hardware. While moving through an environment, our agent perceives changes in its surroundings and uses this information for collision avoidance. The agent's manoeuvres result from a closed action-perception loop implementing probabilistic decision-making processes. This loop-closure is thought to have driven the development of neural circuitry in biological agents since the Cambrian explosion. In the fundamental quest to understand neural computation in artificial agents, we come closer to understanding and modelling biological intelligence by closing the loop also in neuromorphic systems. As a closed-loop system, our system deepens our understanding of processing in neural networks and computations in biological and artificial systems. With these investigations, we aim to set the foundations for neuromorphic intelligence in the future, moving towards leveraging the full potential of neuromorphic systems.
ReadOnce Transformers: Reusable Representations of Text for Transformers
Oct 24, 2020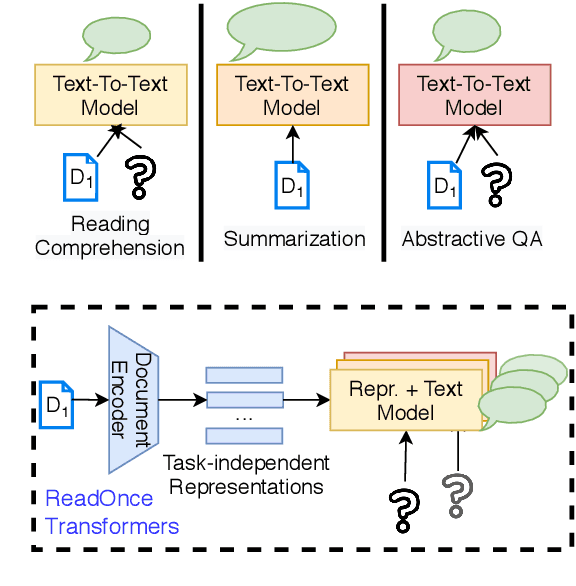
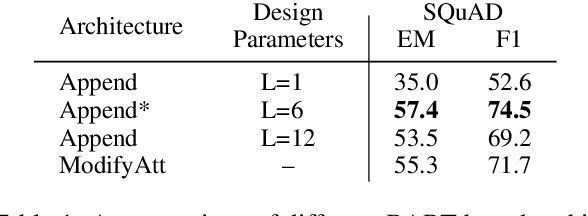
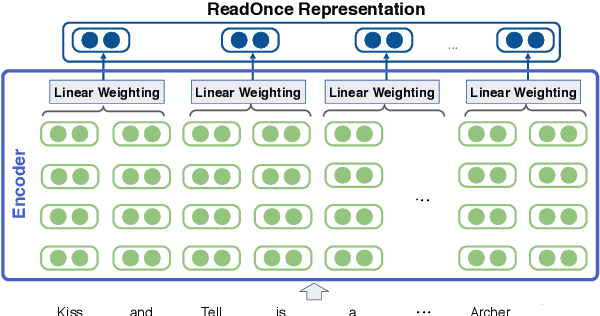
While large-scale language models are extremely effective when directly fine-tuned on many end-tasks, such models learn to extract information and solve the task simultaneously from end-task supervision. This is wasteful, as the general problem of gathering information from a document is mostly task-independent and need not be re-learned from scratch each time. Moreover, once the information has been captured in a computable representation, it can now be re-used across examples, leading to faster training and evaluation of models. We present a transformer-based approach, ReadOnce Transformers, that is trained to build such information-capturing representations of text. Our model compresses the document into a variable-length task-independent representation that can now be re-used in different examples and tasks, thereby requiring a document to only be read once. Additionally, we extend standard text-to-text models to consume our ReadOnce Representations along with text to solve multiple downstream tasks. We show our task-independent representations can be used for multi-hop QA, abstractive QA, and summarization. We observe 2x-5x speedups compared to standard text-to-text models, while also being able to handle long documents that would normally exceed the length limit of current models.
Progressive Semantic Segmentation
Apr 08, 2021

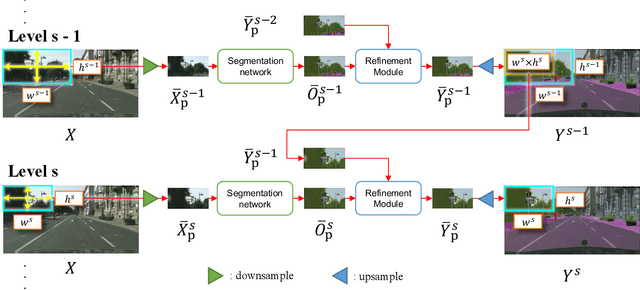
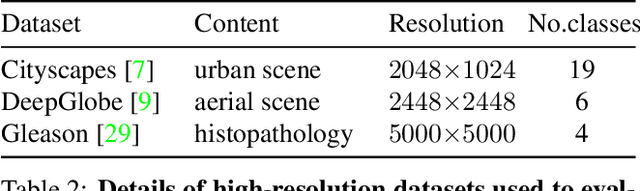
The objective of this work is to segment high-resolution images without overloading GPU memory usage or losing the fine details in the output segmentation map. The memory constraint means that we must either downsample the big image or divide the image into local patches for separate processing. However, the former approach would lose the fine details, while the latter can be ambiguous due to the lack of a global picture. In this work, we present MagNet, a multi-scale framework that resolves local ambiguity by looking at the image at multiple magnification levels. MagNet has multiple processing stages, where each stage corresponds to a magnification level, and the output of one stage is fed into the next stage for coarse-to-fine information propagation. Each stage analyzes the image at a higher resolution than the previous stage, recovering the previously lost details due to the lossy downsampling step, and the segmentation output is progressively refined through the processing stages. Experiments on three high-resolution datasets of urban views, aerial scenes, and medical images show that MagNet consistently outperforms the state-of-the-art methods by a significant margin.
Geometry-based Distance Decomposition for Monocular 3D Object Detection
Apr 08, 2021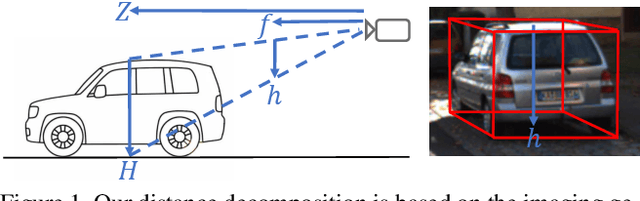
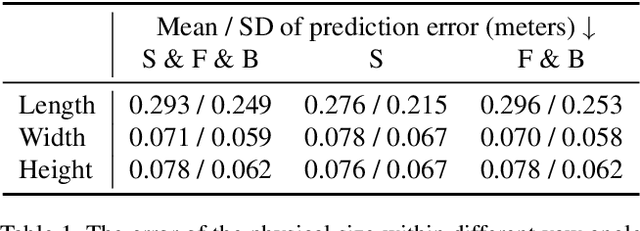

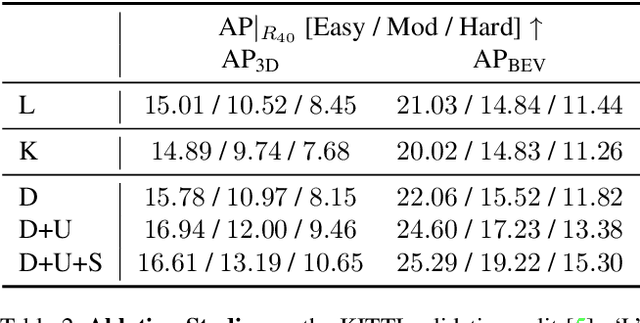
Monocular 3D object detection is of great significance for autonomous driving but remains challenging. The core challenge is to predict the distance of objects in the absence of explicit depth information. Unlike regressing the distance as a single variable in most existing methods, we propose a novel geometry-based distance decomposition to recover the distance by its factors. The decomposition factors the distance of objects into the most representative and stable variables, i.e. the physical height and the projected visual height in the image plane. Moreover, the decomposition maintains the self-consistency between the two heights, leading to the robust distance prediction when both predicted heights are inaccurate. The decomposition also enables us to trace the cause of the distance uncertainty for different scenarios. Such decomposition makes the distance prediction interpretable, accurate, and robust. Our method directly predicts 3D bounding boxes from RGB images with a compact architecture, making the training and inference simple and efficient. The experimental results show that our method achieves the state-of-the-art performance on the monocular 3D Object detection and Birds Eye View tasks on the KITTI dataset, and can generalize to images with different camera intrinsics.