 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Helmholtzian Eigenmap: Topological feature discovery & edge flow learning from point cloud data
Mar 13, 2021
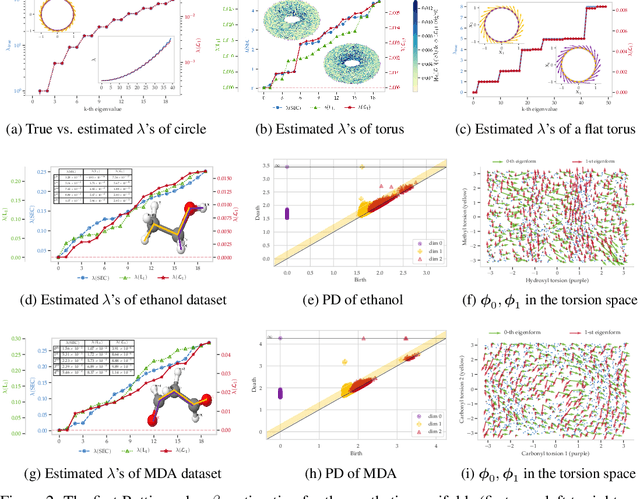
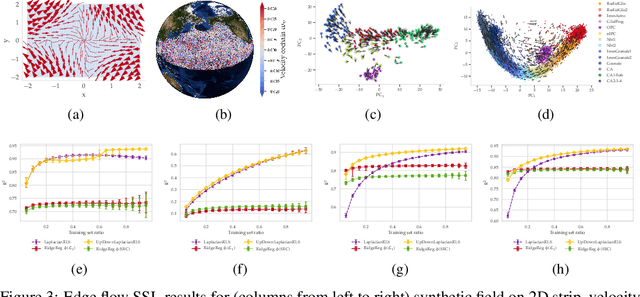
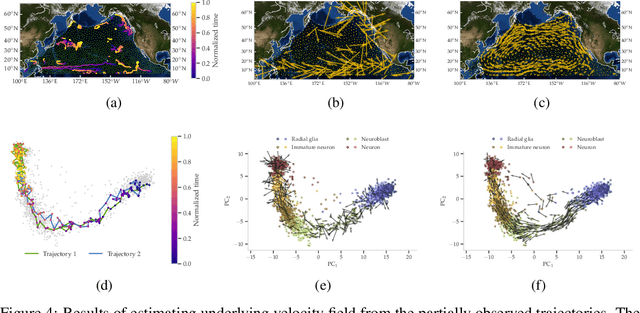
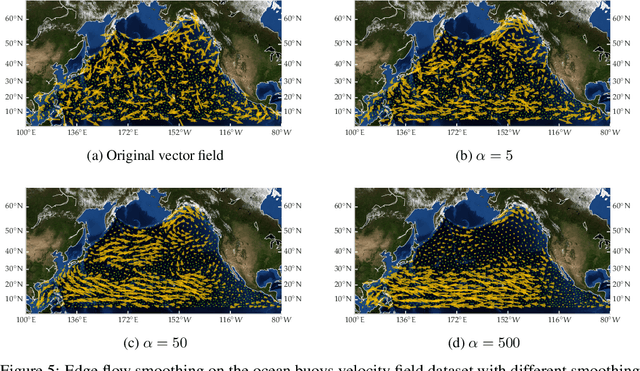
The manifold Helmholtzian (1-Laplacian) operator $\Delta_1$ elegantly generalizes the Laplace-Beltrami operator to vector fields on a manifold $\mathcal M$. In this work, we propose the estimation of the manifold Helmholtzian from point cloud data by a weighted 1-Laplacian $\mathbf{\mathcal L}_1$. While higher order Laplacians ave been introduced and studied, this work is the first to present a graph Helmholtzian constructed from a simplicial complex as an estimator for the continuous operator in a non-parametric setting. Equipped with the geometric and topological information about $\mathcal M$, the Helmholtzian is a useful tool for the analysis of flows and vector fields on $\mathcal M$ via the Helmholtz-Hodge theorem. In addition, the $\mathbf{\mathcal L}_1$ allows the smoothing, prediction, and feature extraction of the flows. We demonstrate these possibilities on substantial sets of synthetic and real point cloud datasets with non-trivial topological structures; and provide theoretical results on the limit of $\mathbf{\mathcal L}_1$ to $\Delta_1$.
Localization of Autonomous Vehicles: Proof of Concept for A Computer Vision Approach
Apr 06, 2021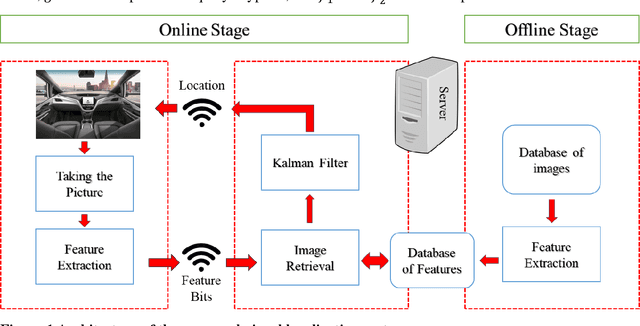


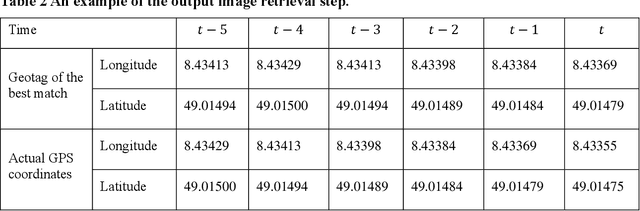
This paper introduces a visual-based localization method for autonomous vehicles (AVs) that operate in the absence of any complicated hardware system but a single camera. Visual localization refers to techniques that aim to find the location of an object based on visual information of its surrounding area. The problem of localization has been of interest for many years. However, visual localization is a relatively new subject in the literature of transportation. Moreover, the inevitable application of this type of localization in the context of autonomous vehicles demands special attention from the transportation community to this problem. This study proposes a two-step localization method that requires a database of geotagged images and a camera mounted on a vehicle that can take pictures while the car is moving. The first step which is image retrieval uses SIFT local feature descriptor to find an initial location for the vehicle using image matching. The next step is to utilize the Kalman filter to estimate a more accurate location for the vehicle as it is moving. All stages of the introduced method are implemented as a complete system using different Python libraries. The proposed system is tested on the KITTI dataset and has shown an average accuracy of 2 meters in finding the final location of the vehicle.
Weakly Supervised Temporal Action Localization Through Learning Explicit Subspaces for Action and Context
Mar 30, 2021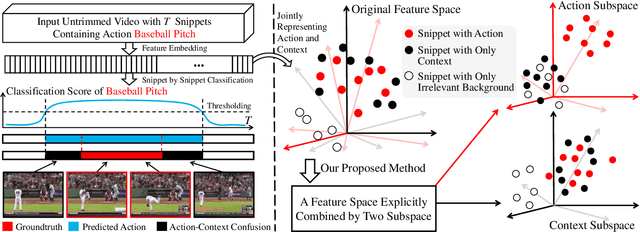

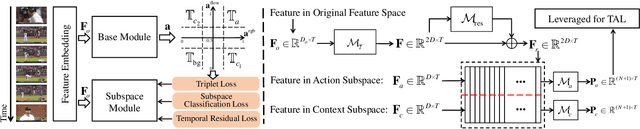
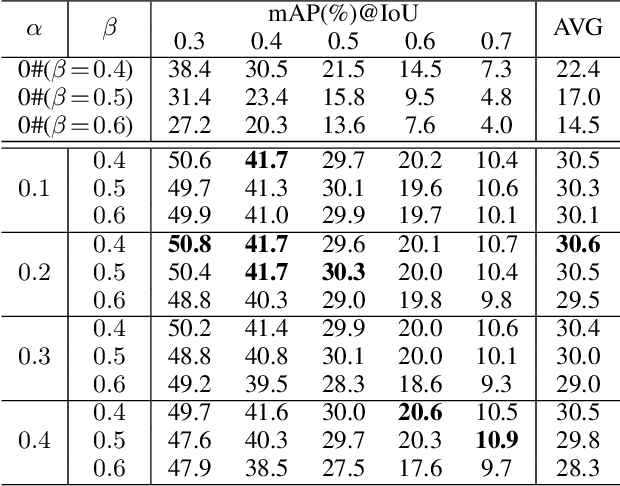
Weakly-supervised Temporal Action Localization (WS-TAL) methods learn to localize temporal starts and ends of action instances in a video under only video-level supervision. Existing WS-TAL methods rely on deep features learned for action recognition. However, due to the mismatch between classification and localization, these features cannot distinguish the frequently co-occurring contextual background, i.e., the context, and the actual action instances. We term this challenge action-context confusion, and it will adversely affect the action localization accuracy. To address this challenge, we introduce a framework that learns two feature subspaces respectively for actions and their context. By explicitly accounting for action visual elements, the action instances can be localized more precisely without the distraction from the context. To facilitate the learning of these two feature subspaces with only video-level categorical labels, we leverage the predictions from both spatial and temporal streams for snippets grouping. In addition, an unsupervised learning task is introduced to make the proposed module focus on mining temporal information. The proposed approach outperforms state-of-the-art WS-TAL methods on three benchmarks, i.e., THUMOS14, ActivityNet v1.2 and v1.3 datasets.
Event-based Synthetic Aperture Imaging with a Hybrid Network
Mar 30, 2021
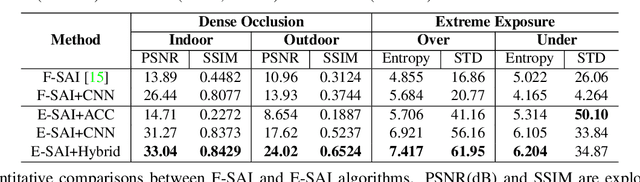


Synthetic aperture imaging (SAI) is able to achieve the see through effect by blurring out the off-focus foreground occlusions and reconstructing the in-focus occluded targets from multi-view images. However, very dense occlusions and extreme lighting conditions may bring significant disturbances to the SAI based on conventional frame-based cameras, leading to performance degeneration. To address these problems, we propose a novel SAI system based on the event camera which can produce asynchronous events with extremely low latency and high dynamic range. Thus, it can eliminate the interference of dense occlusions by measuring with almost continuous views, and simultaneously tackle the over/under exposure problems. To reconstruct the occluded targets, we propose a hybrid encoder-decoder network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs). In the hybrid network, the spatio-temporal information of the collected events is first encoded by SNN layers, and then transformed to the visual image of the occluded targets by a style-transfer CNN decoder. Through experiments, the proposed method shows remarkable performance in dealing with very dense occlusions and extreme lighting conditions, and high quality visual images can be reconstructed using pure event data.
Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments
Mar 30, 2021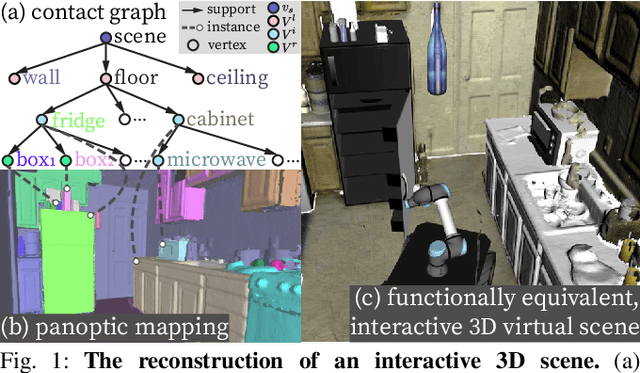
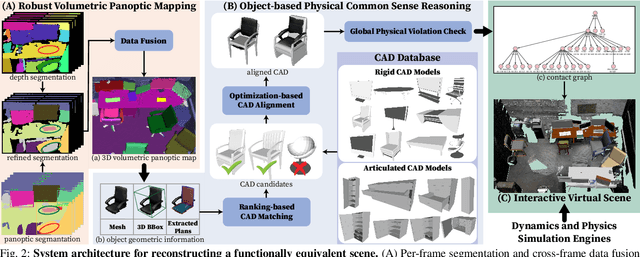
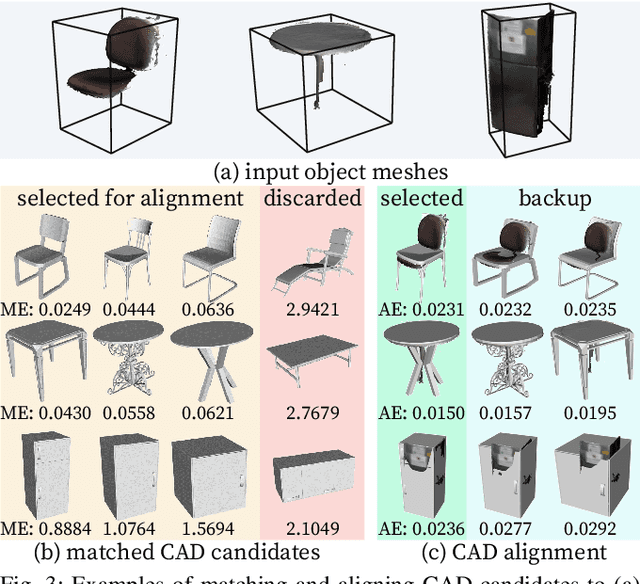
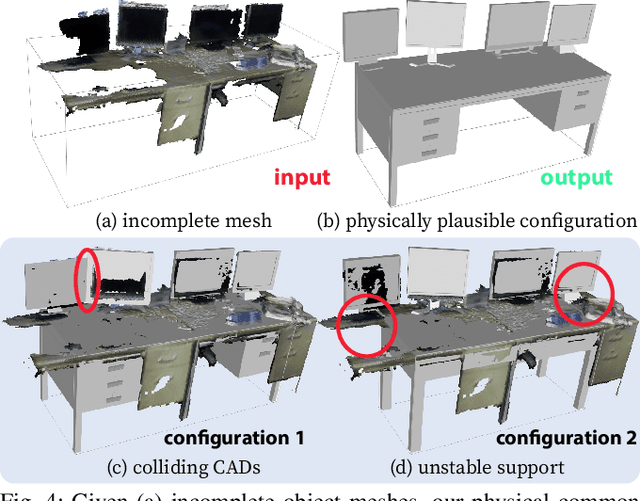
In this paper, we rethink the problem of scene reconstruction from an embodied agent's perspective: While the classic view focuses on the reconstruction accuracy, our new perspective emphasizes the underlying functions and constraints such that the reconstructed scenes provide \em{actionable} information for simulating \em{interactions} with agents. Here, we address this challenging problem by reconstructing an interactive scene using RGB-D data stream, which captures (i) the semantics and geometry of objects and layouts by a 3D volumetric panoptic mapping module, and (ii) object affordance and contextual relations by reasoning over physical common sense among objects, organized by a graph-based scene representation. Crucially, this reconstructed scene replaces the object meshes in the dense panoptic map with part-based articulated CAD models for finer-grained robot interactions. In the experiments, we demonstrate that (i) our panoptic mapping module outperforms previous state-of-the-art methods, (ii) a high-performant physical reasoning procedure that matches, aligns, and replaces objects' meshes with best-fitted CAD models, and (iii) reconstructed scenes are physically plausible and naturally afford actionable interactions; without any manual labeling, they are seamlessly imported to ROS-based simulators and virtual environments for complex robot task executions.
Collaborative Filtering with Information-Rich and Information-Sparse Entities
Mar 06, 2014
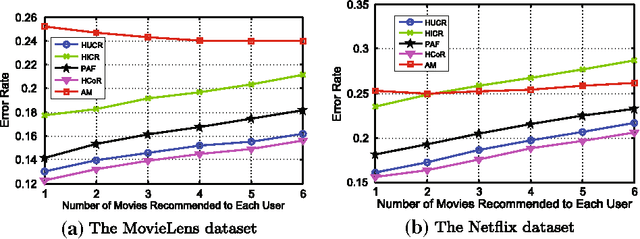

In this paper, we consider a popular model for collaborative filtering in recommender systems where some users of a website rate some items, such as movies, and the goal is to recover the ratings of some or all of the unrated items of each user. In particular, we consider both the clustering model, where only users (or items) are clustered, and the co-clustering model, where both users and items are clustered, and further, we assume that some users rate many items (information-rich users) and some users rate only a few items (information-sparse users). When users (or items) are clustered, our algorithm can recover the rating matrix with $\omega(MK \log M)$ noisy entries while $MK$ entries are necessary, where $K$ is the number of clusters and $M$ is the number of items. In the case of co-clustering, we prove that $K^2$ entries are necessary for recovering the rating matrix, and our algorithm achieves this lower bound within a logarithmic factor when $K$ is sufficiently large. We compare our algorithms with a well-known algorithms called alternating minimization (AM), and a similarity score-based algorithm known as the popularity-among-friends (PAF) algorithm by applying all three to the MovieLens and Netflix data sets. Our co-clustering algorithm and AM have similar overall error rates when recovering the rating matrix, both of which are lower than the error rate under PAF. But more importantly, the error rate of our co-clustering algorithm is significantly lower than AM and PAF in the scenarios of interest in recommender systems: when recommending a few items to each user or when recommending items to users who only rated a few items (these users are the majority of the total user population). The performance difference increases even more when noise is added to the datasets.
Saliency-Guided Deep Learning Network for Automatic Tumor Bed Volume Delineation in Post-operative Breast Irradiation
May 06, 2021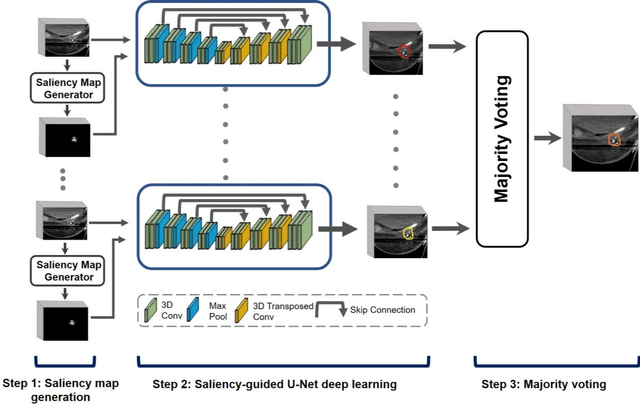
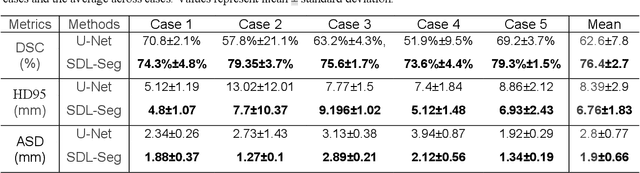
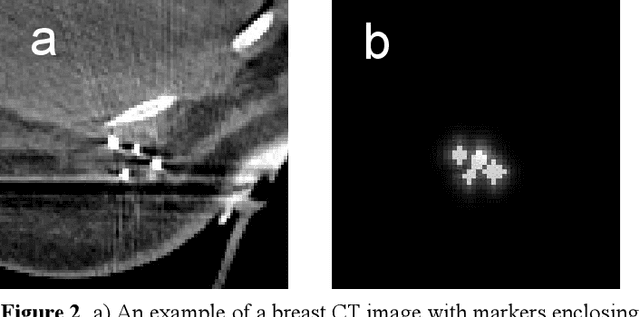

Efficient, reliable and reproducible target volume delineation is a key step in the effective planning of breast radiotherapy. However, post-operative breast target delineation is challenging as the contrast between the tumor bed volume (TBV) and normal breast tissue is relatively low in CT images. In this study, we propose to mimic the marker-guidance procedure in manual target delineation. We developed a saliency-based deep learning segmentation (SDL-Seg) algorithm for accurate TBV segmentation in post-operative breast irradiation. The SDL-Seg algorithm incorporates saliency information in the form of markers' location cues into a U-Net model. The design forces the model to encode the location-related features, which underscores regions with high saliency levels and suppresses low saliency regions. The saliency maps were generated by identifying markers on CT images. Markers' locations were then converted to probability maps using a distance-transformation coupled with a Gaussian filter. Subsequently, the CT images and the corresponding saliency maps formed a multi-channel input for the SDL-Seg network. Our in-house dataset was comprised of 145 prone CT images from 29 post-operative breast cancer patients, who received 5-fraction partial breast irradiation (PBI) regimen on GammaPod. The performance of the proposed method was compared against basic U-Net. Our model achieved mean (standard deviation) of 76.4 %, 6.76 mm, and 1.9 mm for DSC, HD95, and ASD respectively on the test set with computation time of below 11 seconds per one CT volume. SDL-Seg showed superior performance relative to basic U-Net for all the evaluation metrics while preserving low computation cost. The findings demonstrate that SDL-Seg is a promising approach for improving the efficiency and accuracy of the on-line treatment planning procedure of PBI, such as GammaPod based PBI.
Explainable AI For COVID-19 CT Classifiers: An Initial Comparison Study
Apr 25, 2021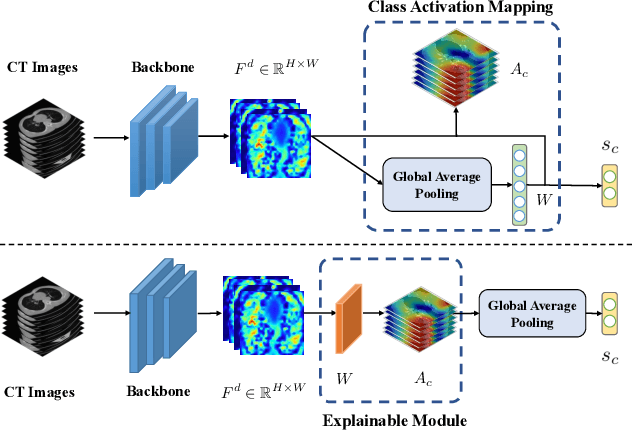
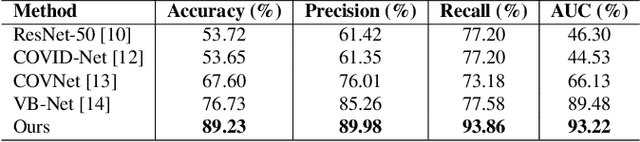
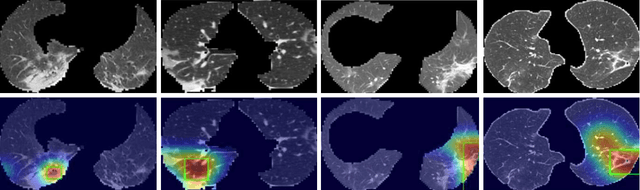
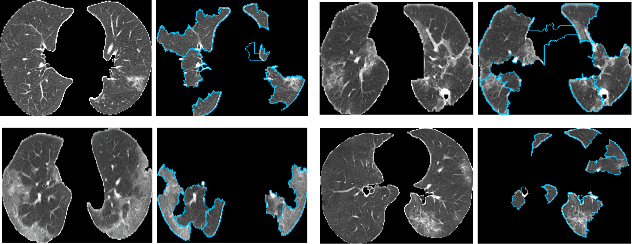
Artificial Intelligence (AI) has made leapfrogs in development across all the industrial sectors especially when deep learning has been introduced. Deep learning helps to learn the behaviour of an entity through methods of recognising and interpreting patterns. Despite its limitless potential, the mystery is how deep learning algorithms make a decision in the first place. Explainable AI (XAI) is the key to unlocking AI and the black-box for deep learning. XAI is an AI model that is programmed to explain its goals, logic, and decision making so that the end users can understand. The end users can be domain experts, regulatory agencies, managers and executive board members, data scientists, users that use AI, with or without awareness, or someone who is affected by the decisions of an AI model. Chest CT has emerged as a valuable tool for the clinical diagnostic and treatment management of the lung diseases associated with COVID-19. AI can support rapid evaluation of CT scans to differentiate COVID-19 findings from other lung diseases. However, how these AI tools or deep learning algorithms reach such a decision and which are the most influential features derived from these neural networks with typically deep layers are not clear. The aim of this study is to propose and develop XAI strategies for COVID-19 classification models with an investigation of comparison. The results demonstrate promising quantification and qualitative visualisations that can further enhance the clinician's understanding and decision making with more granular information from the results given by the learned XAI models.
Dilated Fully Convolutional Neural Network for Depth Estimation from a Single Image
Mar 12, 2021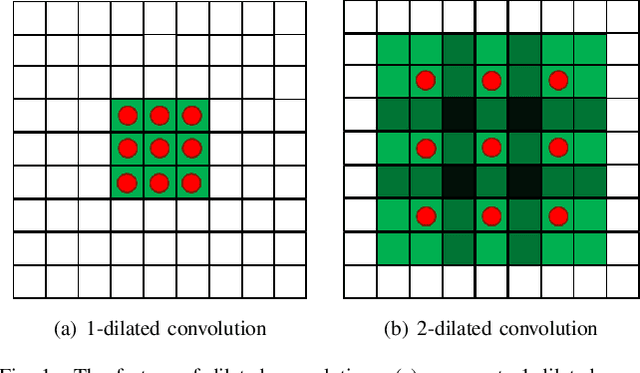
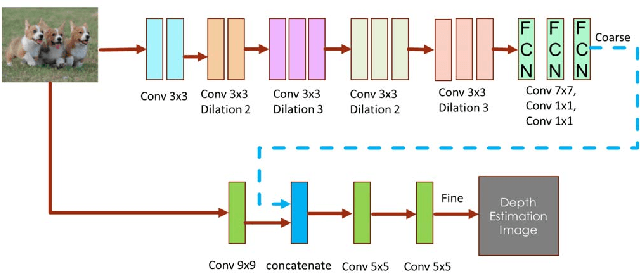


Depth prediction plays a key role in understanding a 3D scene. Several techniques have been developed throughout the years, among which Convolutional Neural Network has recently achieved state-of-the-art performance on estimating depth from a single image. However, traditional CNNs suffer from the lower resolution and information loss caused by the pooling layers. And oversized parameters generated from fully connected layers often lead to a exploded memory usage problem. In this paper, we present an advanced Dilated Fully Convolutional Neural Network to address the deficiencies. Taking advantages of the exponential expansion of the receptive field in dilated convolutions, our model can minimize the loss of resolution. It also reduces the amount of parameters significantly by replacing the fully connected layers with the fully convolutional layers. We show experimentally on NYU Depth V2 datasets that the depth prediction obtained from our model is considerably closer to ground truth than that from traditional CNNs techniques.
Towards Fully Automated Manga Translation
Jan 09, 2021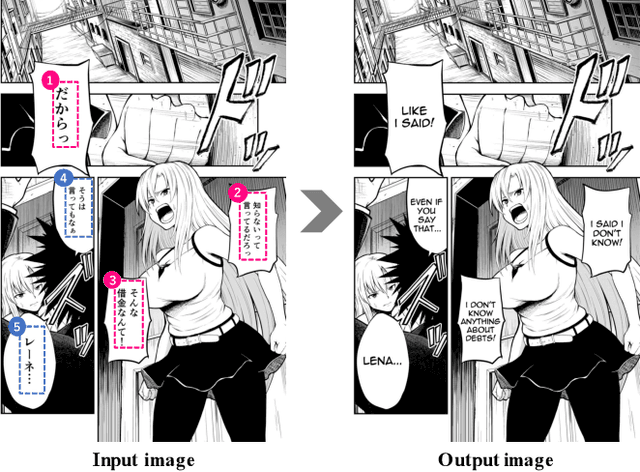
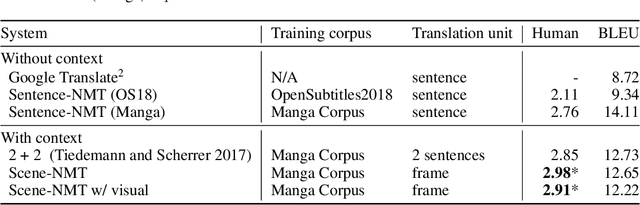
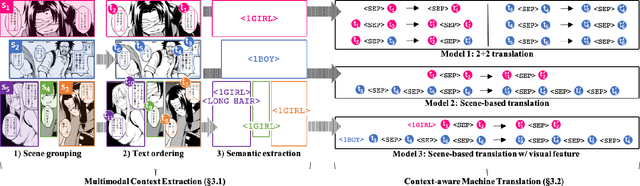
We tackle the problem of machine translation of manga, Japanese comics. Manga translation involves two important problems in machine translation: context-aware and multimodal translation. Since text and images are mixed up in an unstructured fashion in Manga, obtaining context from the image is essential for manga translation. However, it is still an open problem how to extract context from image and integrate into MT models. In addition, corpus and benchmarks to train and evaluate such model is currently unavailable. In this paper, we make the following four contributions that establishes the foundation of manga translation research. First, we propose multimodal context-aware translation framework. We are the first to incorporate context information obtained from manga image. It enables us to translate texts in speech bubbles that cannot be translated without using context information (e.g., texts in other speech bubbles, gender of speakers, etc.). Second, for training the model, we propose the approach to automatic corpus construction from pairs of original manga and their translations, by which large parallel corpus can be constructed without any manual labeling. Third, we created a new benchmark to evaluate manga translation. Finally, on top of our proposed methods, we devised a first comprehensive system for fully automated manga translation.