 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local word statistics affect reading times independently of surprisal
Mar 07, 2021
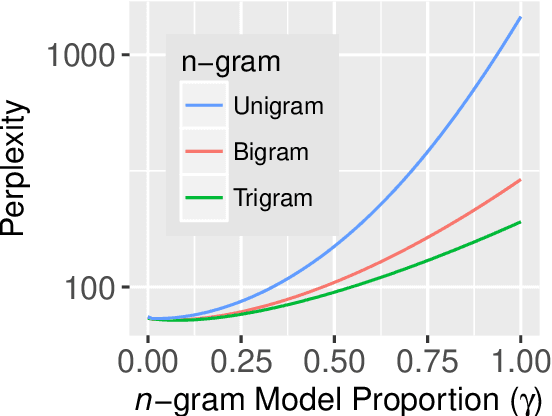
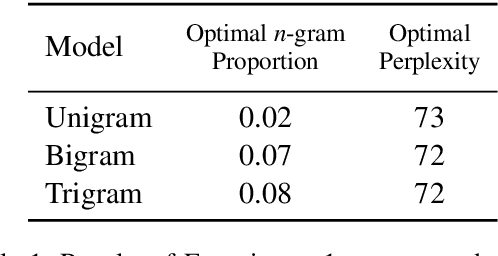

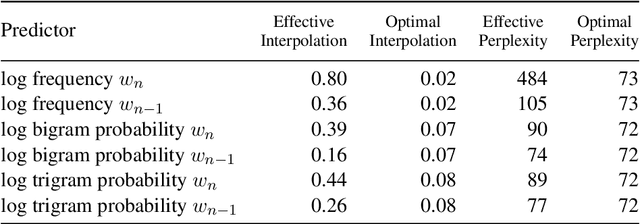
Surprisal theory has provided a unifying framework for understanding many phenomena in sentence processing (Hale, 2001; Levy, 2008a), positing that a word's conditional probability given all prior context fully determines processing difficulty. Problematically for this claim, one local statistic, word frequency, has also been shown to affect processing, even when conditional probability given context is held constant. Here, we ask whether other local statistics have a role in processing, or whether word frequency is a special case. We present the first clear evidence that more complex local statistics, word bigram and trigram probability, also affect processing independently of surprisal. These findings suggest a significant and independent role of local statistics in processing. Further, it motivates research into new generalizations of surprisal that can also explain why local statistical information should have an outsized effect.
Disambiguation of weak supervision with exponential convergence rates
Feb 04, 2021
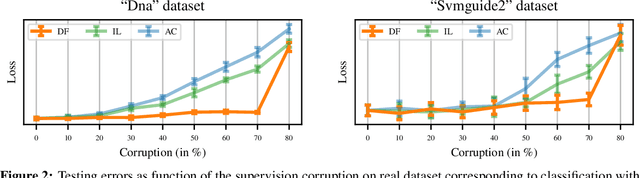
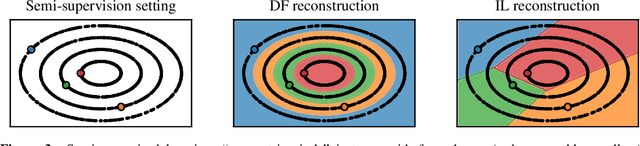
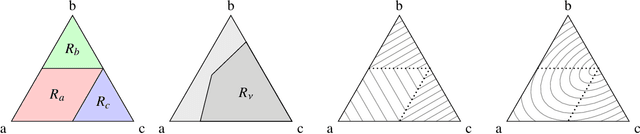
Machine learning approached through supervised learning requires expensive annotation of data. This motivates weakly supervised learning, where data are annotated with incomplete yet discriminative information. In this paper, we focus on partial labelling, an instance of weak supervision where, from a given input, we are given a set of potential targets. We review a disambiguation principle to recover full supervision from weak supervision, and propose an empirical disambiguation algorithm. We prove exponential convergence rates of our algorithm under classical learnability assumptions, and we illustrate the usefulness of our method on practical examples.
Explainable Patterns: Going from Findings to Insights to Support Data Analytics Democratization
Jan 19, 2021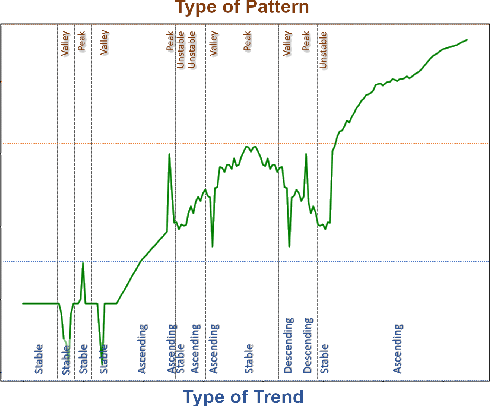
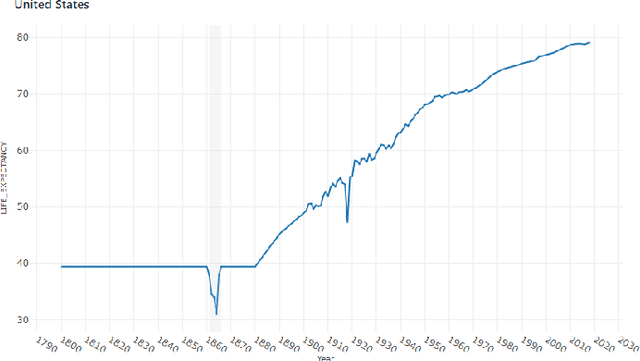
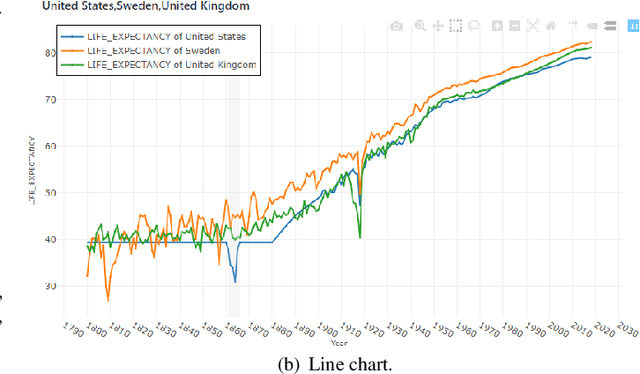
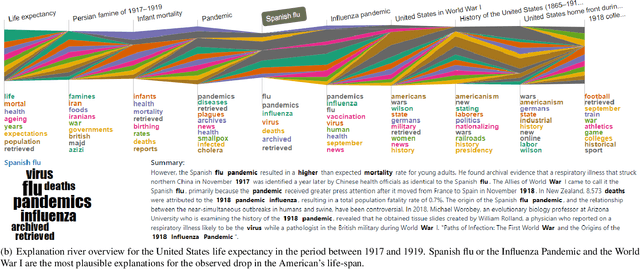
In the past decades, massive efforts involving companies, non-profit organizations, governments, and others have been put into supporting the concept of data democratization, promoting initiatives to educate people to confront information with data. Although this represents one of the most critical advances in our free world, access to data without concrete facts to check or the lack of an expert to help on understanding the existing patterns hampers its intrinsic value and lessens its democratization. So the benefits of giving full access to data will only be impactful if we go a step further and support the Data Analytics Democratization, assisting users in transforming findings into insights without the need of domain experts to promote unconstrained access to data interpretation and verification. In this paper, we present Explainable Patterns (ExPatt), a new framework to support lay users in exploring and creating data storytellings, automatically generating plausible explanations for observed or selected findings using an external (textual) source of information, avoiding or reducing the need for domain experts. ExPatt applicability is confirmed via different use-cases involving world demographics indicators and Wikipedia as an external source of explanations, showing how it can be used in practice towards the data analytics democratization.
Divide-and-Conquer for Lane-Aware Diverse Trajectory Prediction
Apr 16, 2021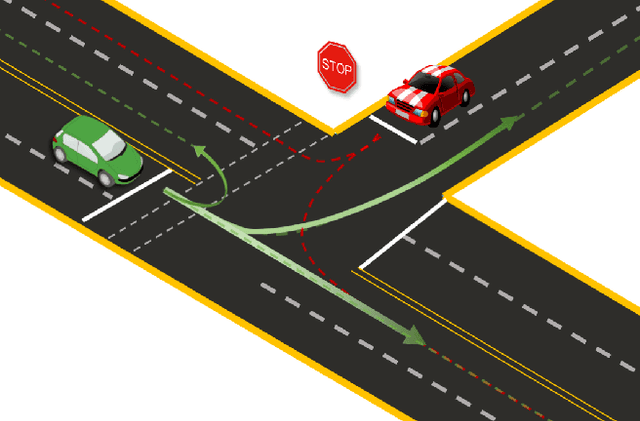
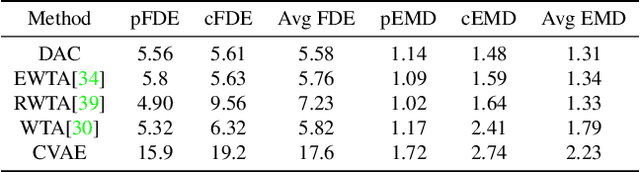

Trajectory prediction is a safety-critical tool for autonomous vehicles to plan and execute actions. Our work addresses two key challenges in trajectory prediction, learning multimodal outputs, and better predictions by imposing constraints using driving knowledge. Recent methods have achieved strong performances using Multi-Choice Learning objectives like winner-takes-all (WTA) or best-of-many. But the impact of those methods in learning diverse hypotheses is under-studied as such objectives highly depend on their initialization for diversity. As our first contribution, we propose a novel Divide-And-Conquer (DAC) approach that acts as a better initialization technique to WTA objective, resulting in diverse outputs without any spurious modes. Our second contribution is a novel trajectory prediction framework called ALAN that uses existing lane centerlines as anchors to provide trajectories constrained to the input lanes. Our framework provides multi-agent trajectory outputs in a forward pass by capturing interactions through hypercolumn descriptors and incorporating scene information in the form of rasterized images and per-agent lane anchors. Experiments on synthetic and real data show that the proposed DAC captures the data distribution better compare to other WTA family of objectives. Further, we show that our ALAN approach provides on par or better performance with SOTA methods evaluated on Nuscenes urban driving benchmark.
Fast digital refocusing and depth of field extended Fourier ptychography microscopy
May 06, 2021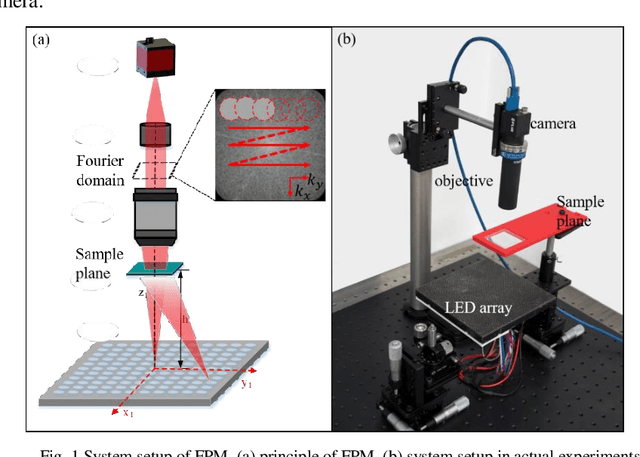
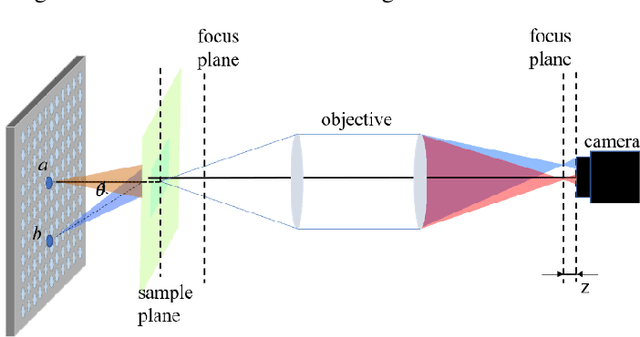
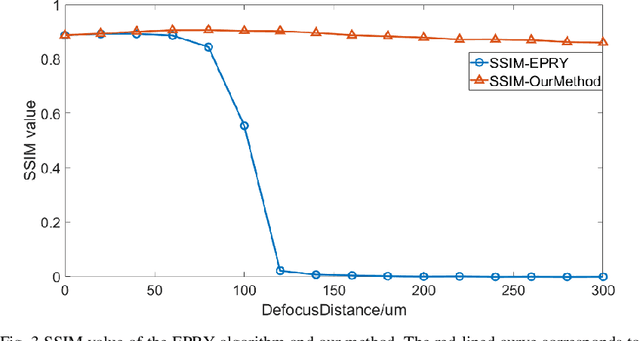

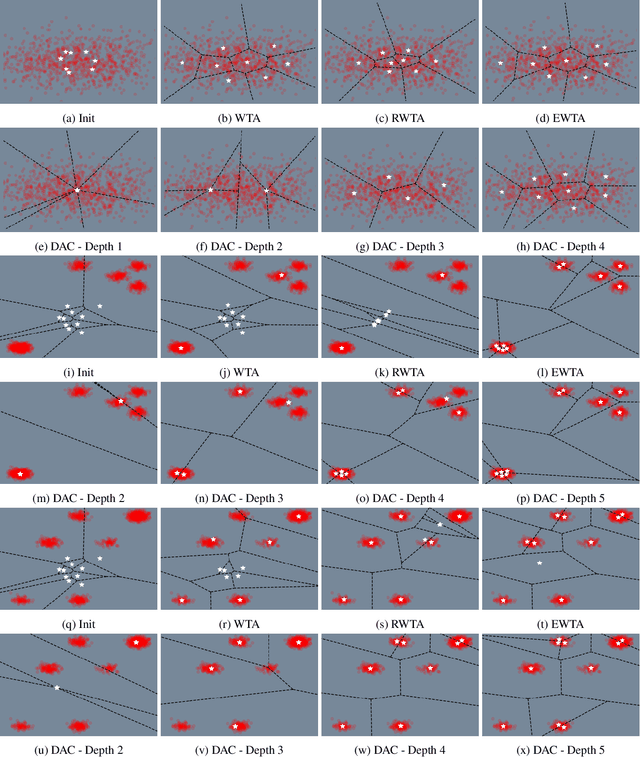
Fourier ptychography microscopy (FPM), sharing its roots with synthetic aperture technique and phase retrieval method, is a recently developed computational microscopic super-resolution technique. By turning on the light-emitting diode (LED) elements sequentially and acquiring the corresponding images that contain different spatial frequencies, FPM can achieve a wide field-of-view (FOV), high-spatial-resolution imaging, and phase recovery simultaneously. Conventional FPM assumes that the sample is sufficiently thin and strictly in focus. Nevertheless, even for a relatively thin sample, the non-planar distribution characteristics and the non-ideal position/posture of the sample will cause all or part of FOV to be defocused. In this paper, we proposed a fast digital refocusing and depth-of-field (DOF) extended FPM strategy by taking the advantages of image lateral shift caused by sample defocusing and varied-angle illuminations. The lateral shift amount is proportional to the defocus distance and the tangent of the illumination angle. Instead of searching the optimal defocus distance in optimization strategy, which is time-consuming, the defocus distance of each subregion of the sample can be precisely and quickly obtained by calculating the relative lateral shift amounts corresponding to different oblique illuminations. And then, the digital refocusing strategy rooting in the Fresnel propagator is integrated into the FPM framework to achieve the high-resolution and phase information reconstruction for each part of the sample, which means the DOF the FPM is effectively extended. The feasibility of the proposed method in fast digital refocusing and FOV extending is verified in the actual experiments with the USAF chart and biological samples.
proScript: Partially Ordered Scripts Generation via Pre-trained Language Models
Apr 16, 2021
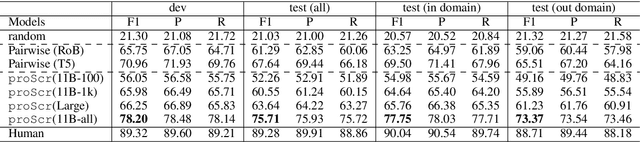
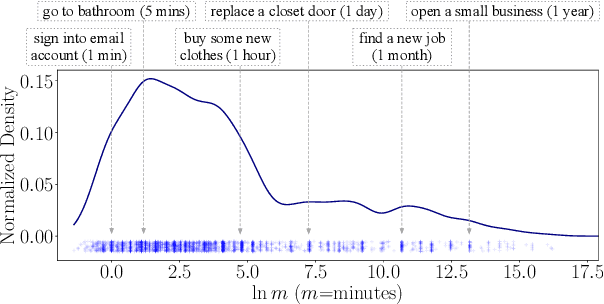
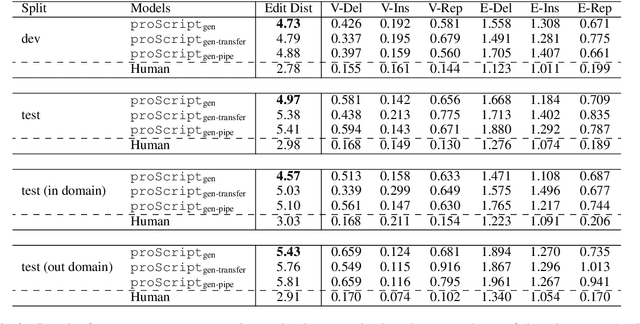
Scripts - standardized event sequences describing typical everyday activities - have been shown to help understand narratives by providing expectations, resolving ambiguity, and filling in unstated information. However, to date they have proved hard to author or extract from text. In this work, we demonstrate for the first time that pre-trained neural language models (LMs) can be be finetuned to generate high-quality scripts, at varying levels of granularity, for a wide range of everyday scenarios (e.g., bake a cake). To do this, we collected a large (6.4k), crowdsourced partially ordered scripts (named proScript), which is substantially larger than prior datasets, and developed models that generate scripts with combining language generation and structure prediction. We define two complementary tasks: (i) edge prediction: given a scenario and unordered events, organize the events into a valid (possibly partial-order) script, and (ii) script generation: given only a scenario, generate events and organize them into a (possibly partial-order) script. Our experiments show that our models perform well (e.g., F1=75.7 in task (i)), illustrating a new approach to overcoming previous barriers to script collection. We also show that there is still significant room for improvement toward human level performance. Together, our tasks, dataset, and models offer a new research direction for learning script knowledge.
Modelling Temporal Information Using Discrete Fourier Transform for Video Classification
Aug 17, 2016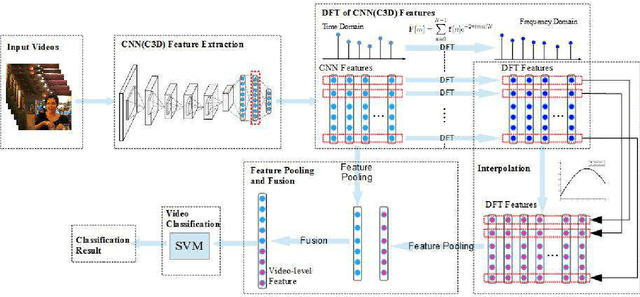
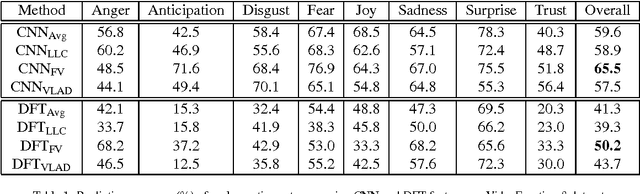
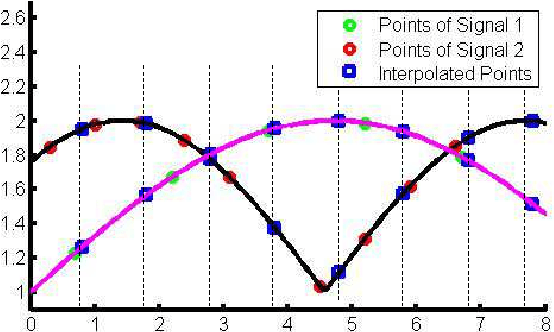
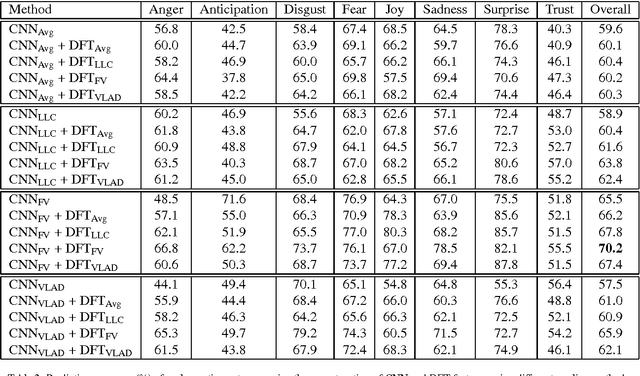
Recently, video classification attracts intensive research efforts. However, most existing works are based on framelevel visual features, which might fail to model the temporal information, e.g. characteristics accumulated along time. In order to capture video temporal information, we propose to analyse features in frequency domain transformed by discrete Fourier transform (DFT features). Frame-level features are firstly extract by a pre-trained deep convolutional neural network (CNN). Then, time domain features are transformed and interpolated into DFT features. CNN and DFT features are further encoded by using different pooling methods and fused for video classification. In this way, static image features extracted from a pre-trained deep CNN and temporal information represented by DFT features are jointly considered for video classification. We test our method for video emotion classification and action recognition. Experimental results demonstrate that combining DFT features can effectively capture temporal information and therefore improve the performance of both video emotion classification and action recognition. Our approach has achieved a state-of-the-art performance on the largest video emotion dataset (VideoEmotion-8 dataset) and competitive results on UCF-101.
On the Post-hoc Explainability of Deep Echo State Networks for Time Series Forecasting, Image and Video Classification
Feb 17, 2021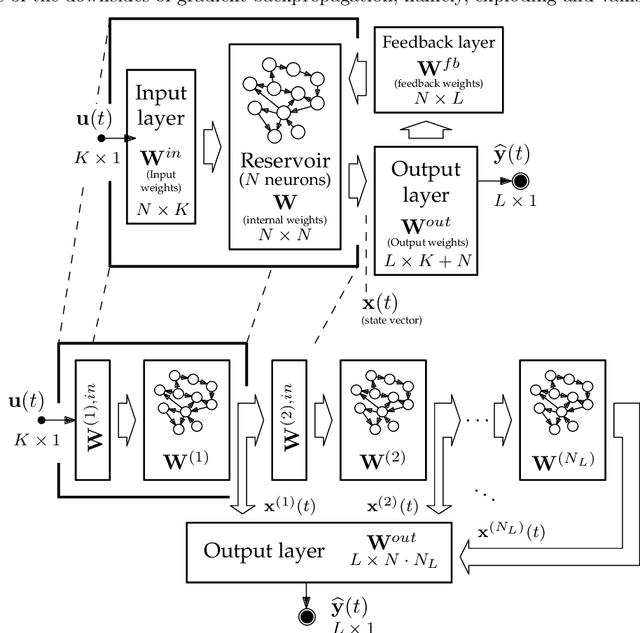
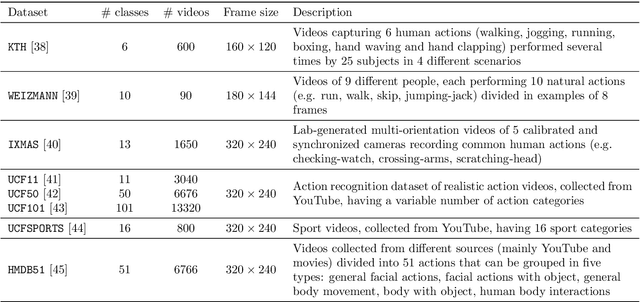
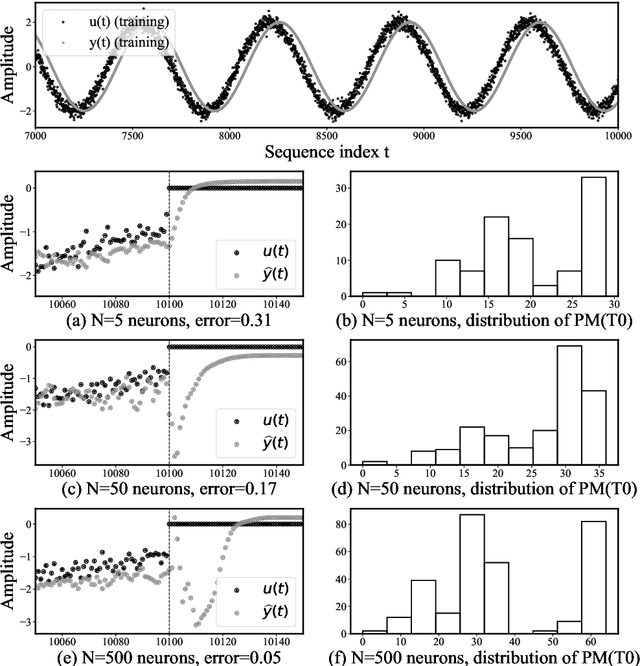
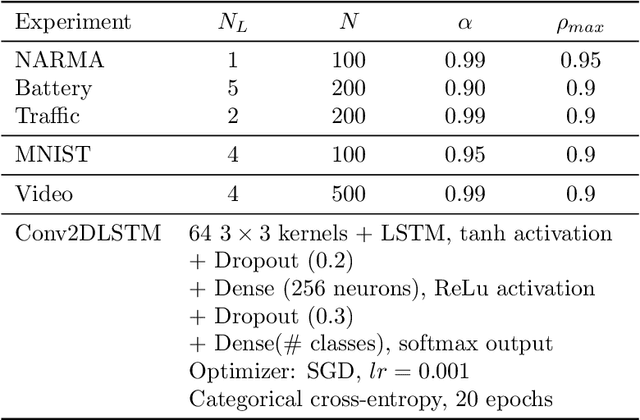
Since their inception, learning techniques under the Reservoir Computing paradigm have shown a great modeling capability for recurrent systems without the computing overheads required for other approaches. Among them, different flavors of echo state networks have attracted many stares through time, mainly due to the simplicity and computational efficiency of their learning algorithm. However, these advantages do not compensate for the fact that echo state networks remain as black-box models whose decisions cannot be easily explained to the general audience. This work addresses this issue by conducting an explainability study of Echo State Networks when applied to learning tasks with time series, image and video data. Specifically, the study proposes three different techniques capable of eliciting understandable information about the knowledge grasped by these recurrent models, namely, potential memory, temporal patterns and pixel absence effect. Potential memory addresses questions related to the effect of the reservoir size in the capability of the model to store temporal information, whereas temporal patterns unveils the recurrent relationships captured by the model over time. Finally, pixel absence effect attempts at evaluating the effect of the absence of a given pixel when the echo state network model is used for image and video classification. We showcase the benefits of our proposed suite of techniques over three different domains of applicability: time series modeling, image and, for the first time in the related literature, video classification. Our results reveal that the proposed techniques not only allow for a informed understanding of the way these models work, but also serve as diagnostic tools capable of detecting issues inherited from data (e.g. presence of hidden bias).
Combined Depth Space based Architecture Search For Person Re-identification
Apr 09, 2021
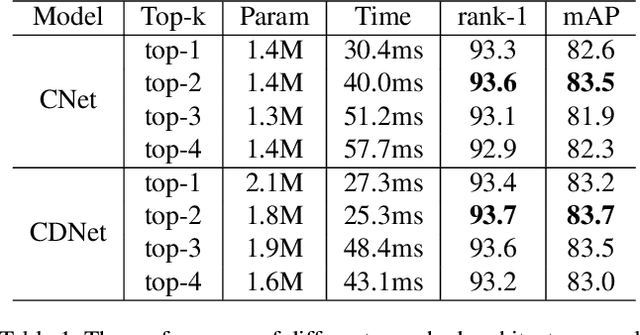
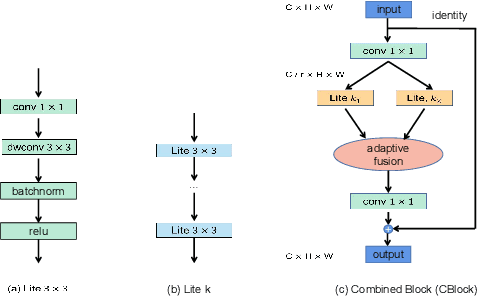
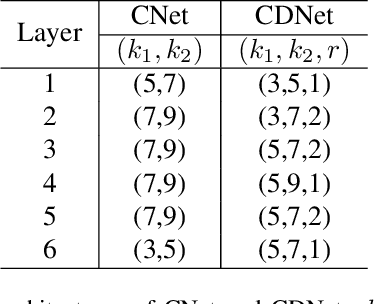
Most works on person re-identification (ReID) take advantage of large backbone networks such as ResNet, which are designed for image classification instead of ReID, for feature extraction. However, these backbones may not be computationally efficient or the most suitable architectures for ReID. In this work, we aim to design a lightweight and suitable network for ReID. We propose a novel search space called Combined Depth Space (CDS), based on which we search for an efficient network architecture, which we call CDNet, via a differentiable architecture search algorithm. Through the use of the combined basic building blocks in CDS, CDNet tends to focus on combined pattern information that is typically found in images of pedestrians. We then propose a low-cost search strategy named the Top-k Sample Search strategy to make full use of the search space and avoid trapping in local optimal result. Furthermore, an effective Fine-grained Balance Neck (FBLNeck), which is removable at the inference time, is presented to balance the effects of triplet loss and softmax loss during the training process. Extensive experiments show that our CDNet (~1.8M parameters) has comparable performance with state-of-the-art lightweight networks.
Partitioned hybrid learning of Bayesian network structures
Mar 22, 2021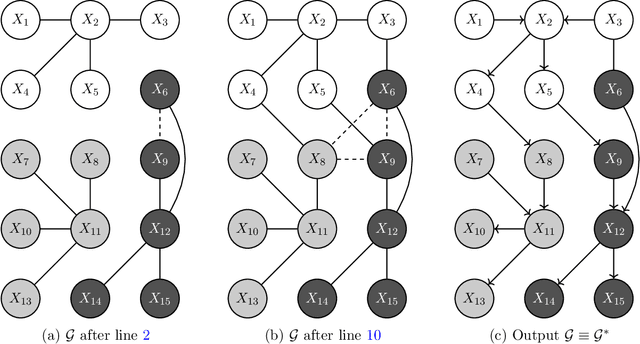
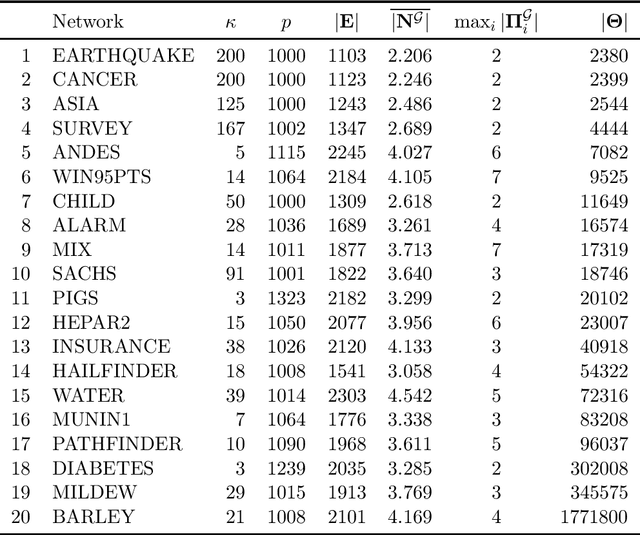
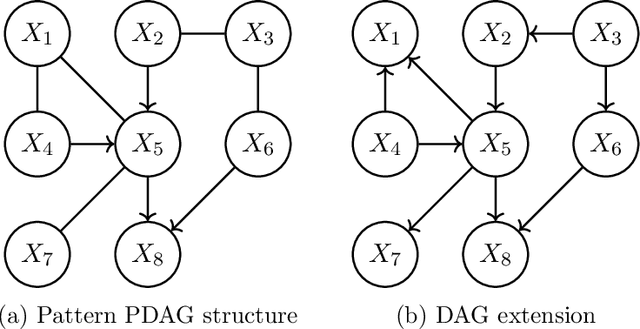
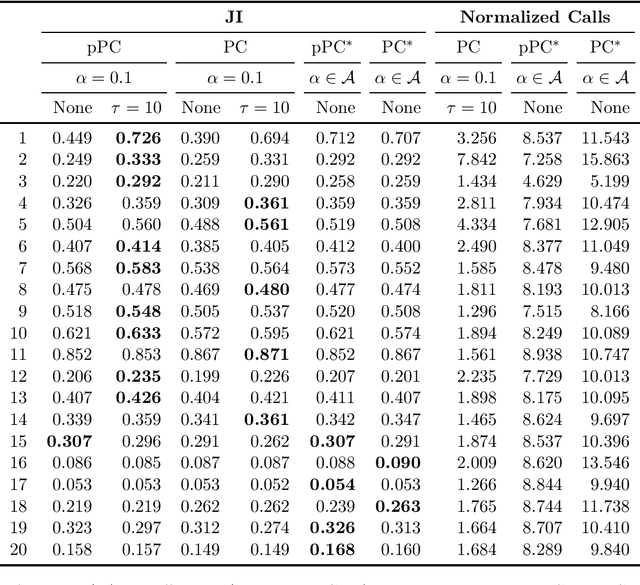
We develop a novel hybrid method for Bayesian network structure learning called partitioned hybrid greedy search (pHGS), composed of three distinct yet compatible new algorithms: Partitioned PC (pPC) accelerates skeleton learning via a divide-and-conquer strategy, $p$-value adjacency thresholding (PATH) effectively accomplishes parameter tuning with a single execution, and hybrid greedy initialization (HGI) maximally utilizes constraint-based information to obtain a high-scoring and well-performing initial graph for greedy search. We establish structure learning consistency of our algorithms in the large-sample limit, and empirically validate our methods individually and collectively through extensive numerical comparisons. The combined merits of pPC and PATH achieve significant computational reductions compared to the PC algorithm without sacrificing the accuracy of estimated structures, and our generally applicable HGI strategy reliably improves the estimation structural accuracy of popular hybrid algorithms with negligible additional computational expense. Our empirical results demonstrate the superior empirical performance of pHGS against many state-of-the-art structure learning algorithms.