 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhanced Spatio-Temporal Interaction Learning for Video Deraining: A Faster and Better Framework
Mar 23, 2021
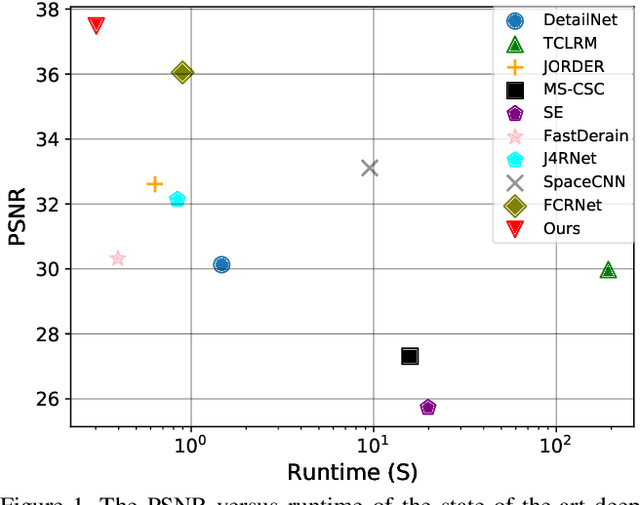
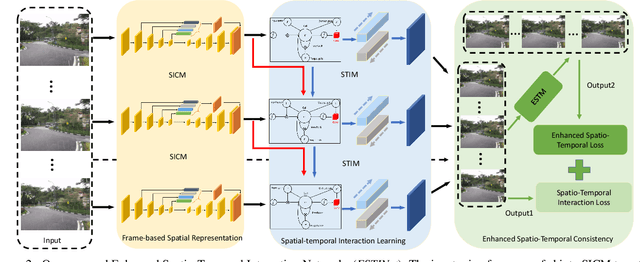
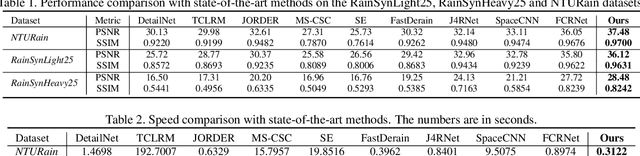
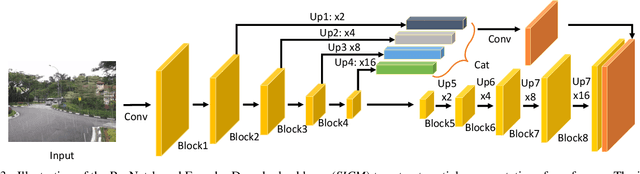
Video deraining is an important task in computer vision as the unwanted rain hampers the visibility of videos and deteriorates the robustness of most outdoor vision systems. Despite the significant success which has been achieved for video deraining recently, two major challenges remain: 1) how to exploit the vast information among continuous frames to extract powerful spatio-temporal features across both the spatial and temporal domains, and 2) how to restore high-quality derained videos with a high-speed approach. In this paper, we present a new end-to-end video deraining framework, named Enhanced Spatio-Temporal Interaction Network (ESTINet), which considerably boosts current state-of-the-art video deraining quality and speed. The ESTINet takes the advantage of deep residual networks and convolutional long short-term memory, which can capture the spatial features and temporal correlations among continuing frames at the cost of very little computational source. Extensive experiments on three public datasets show that the proposed ESTINet can achieve faster speed than the competitors, while maintaining better performance than the state-of-the-art methods.
On the relationship between a Gamma distributed precision parameter and the associated standard deviation in the context of Bayesian parameter inference
Jan 15, 2021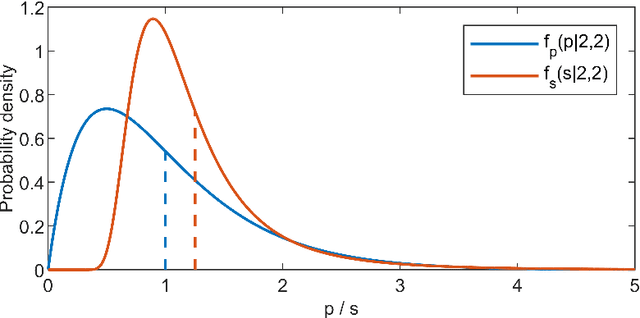
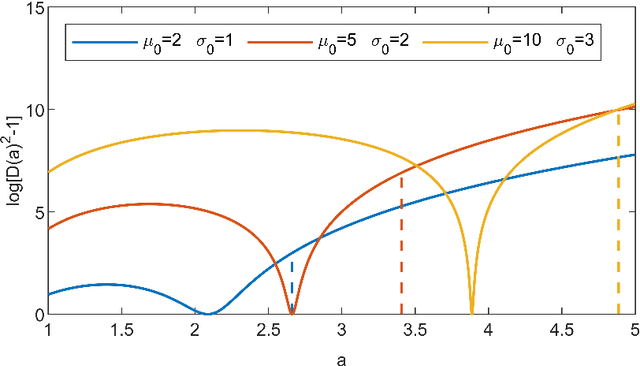
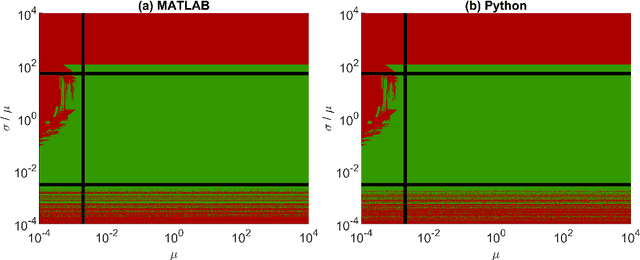
In Bayesian inference, an unknown measurement uncertainty is often quantified in terms of a Gamma distributed precision parameter, which is impractical when prior information on the standard deviation of the measurement uncertainty shall be utilised during inference. This paper thus introduces a method for transforming between a gamma distributed precision parameter and the distribution of the associated standard deviation. The proposed method is based on numerical optimisation and shows adequate results for a wide range of scenarios.
Representation Learning of Reconstructed Graphs Using Random Walk Graph Convolutional Network
Jan 02, 2021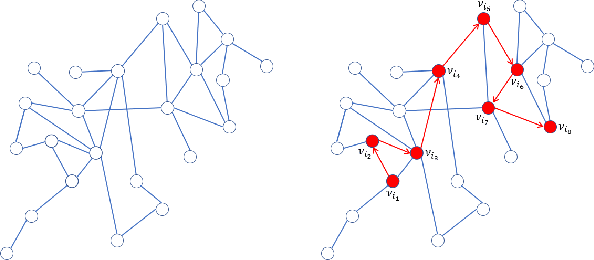
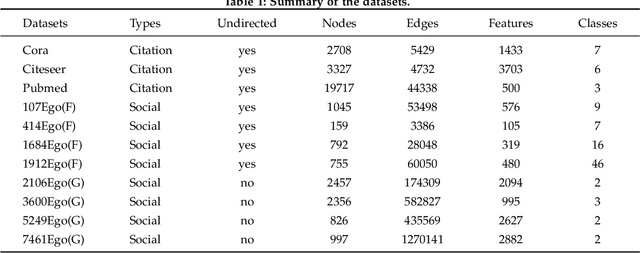
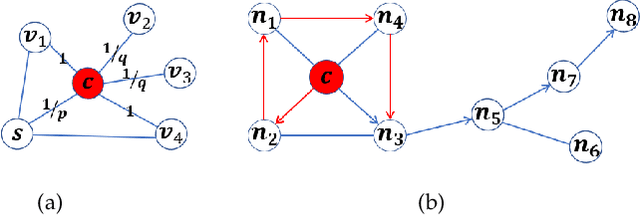
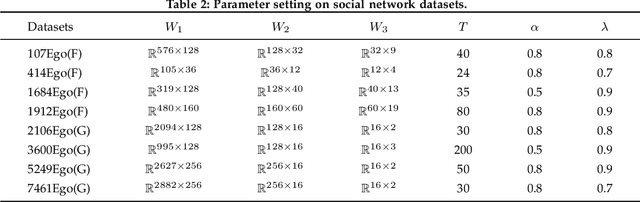
Graphs are often used to organize data because of their simple topological structure, and therefore play a key role in machine learning. And it turns out that the low-dimensional embedded representation obtained by graph representation learning are extremely useful in various typical tasks, such as node classification, content recommendation and link prediction. However, the existing methods mostly start from the microstructure (i.e., the edges) in the graph, ignoring the mesoscopic structure (high-order local structure). Here, we propose wGCN -- a novel framework that utilizes random walk to obtain the node-specific mesoscopic structures of the graph, and utilizes these mesoscopic structures to reconstruct the graph And organize the characteristic information of the nodes. Our method can effectively generate node embeddings for previously unseen data, which has been proven in a series of experiments conducted on citation networks and social networks (our method has advantages over baseline methods). We believe that combining high-order local structural information can more efficiently explore the potential of the network, which will greatly improve the learning efficiency of graph neural network and promote the establishment of new learning models.
F2Net: Learning to Focus on the Foreground for Unsupervised Video Object Segmentation
Dec 04, 2020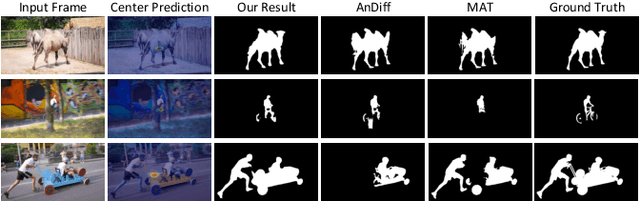
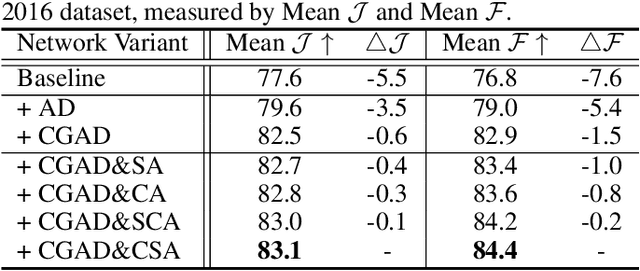
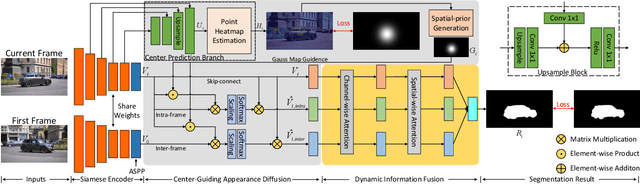
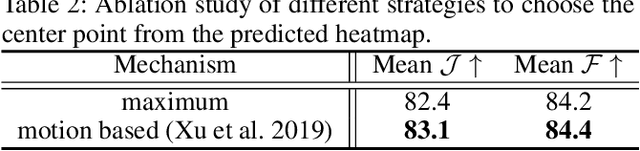
Although deep learning based methods have achieved great progress in unsupervised video object segmentation, difficult scenarios (e.g., visual similarity, occlusions, and appearance changing) are still not well-handled. To alleviate these issues, we propose a novel Focus on Foreground Network (F2Net), which delves into the intra-inter frame details for the foreground objects and thus effectively improve the segmentation performance. Specifically, our proposed network consists of three main parts: Siamese Encoder Module, Center Guiding Appearance Diffusion Module, and Dynamic Information Fusion Module. Firstly, we take a siamese encoder to extract the feature representations of paired frames (reference frame and current frame). Then, a Center Guiding Appearance Diffusion Module is designed to capture the inter-frame feature (dense correspondences between reference frame and current frame), intra-frame feature (dense correspondences in current frame), and original semantic feature of current frame. Specifically, we establish a Center Prediction Branch to predict the center location of the foreground object in current frame and leverage the center point information as spatial guidance prior to enhance the inter-frame and intra-frame feature extraction, and thus the feature representation considerably focus on the foreground objects. Finally, we propose a Dynamic Information Fusion Module to automatically select relatively important features through three aforementioned different level features. Extensive experiments on DAVIS2016, Youtube-object, and FBMS datasets show that our proposed F2Net achieves the state-of-the-art performance with significant improvement.
A Signal-Centric Perspective on the Evolution of Symbolic Communication
Mar 31, 2021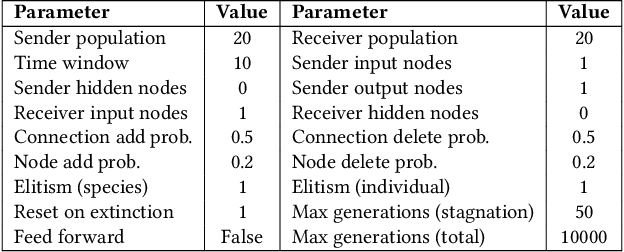
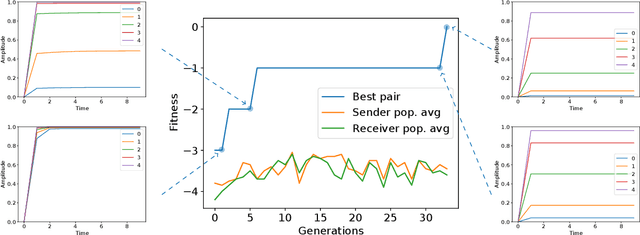
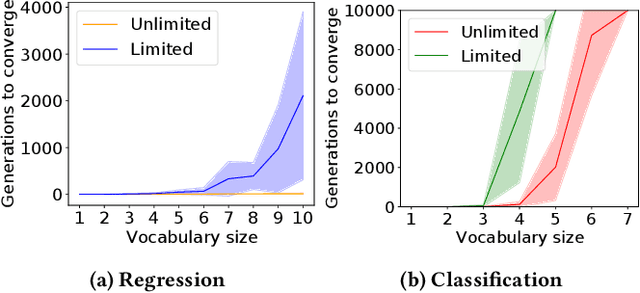
The evolution of symbolic communication is a longstanding open research question in biology. While some theories suggest that it originated from sub-symbolic communication (i.e., iconic or indexical), little experimental evidence exists on how organisms can actually evolve to define a shared set of symbols with unique interpretable meaning, thus being capable of encoding and decoding discrete information. Here, we use a simple synthetic model composed of sender and receiver agents controlled by Continuous-Time Recurrent Neural Networks, which are optimized by means of neuro-evolution. We characterize signal decoding as either regression or classification, with limited and unlimited signal amplitude. First, we show how this choice affects the complexity of the evolutionary search, and leads to different levels of generalization. We then assess the effect of noise, and test the evolved signaling system in a referential game. In various settings, we observe agents evolving to share a dictionary of symbols, with each symbol spontaneously associated to a 1-D unique signal. Finally, we analyze the constellation of signals associated to the evolved signaling systems and note that in most cases these resemble a Pulse Amplitude Modulation system.
Speak or Chat with Me: End-to-End Spoken Language Understanding System with Flexible Inputs
Apr 07, 2021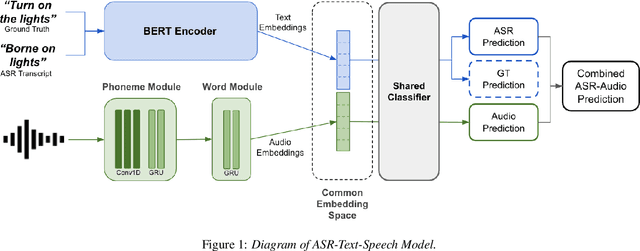
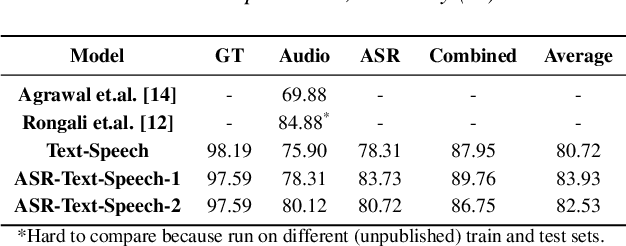
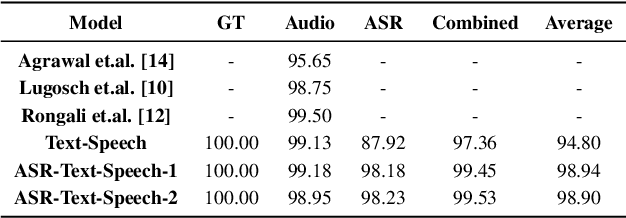
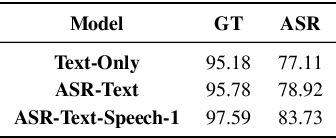
A major focus of recent research in spoken language understanding (SLU) has been on the end-to-end approach where a single model can predict intents directly from speech inputs without intermediate transcripts. However, this approach presents some challenges. First, since speech can be considered as personally identifiable information, in some cases only automatic speech recognition (ASR) transcripts are accessible. Second, intent-labeled speech data is scarce. To address the first challenge, we propose a novel system that can predict intents from flexible types of inputs: speech, ASR transcripts, or both. We demonstrate strong performance for either modality separately, and when both speech and ASR transcripts are available, through system combination, we achieve better results than using a single input modality. To address the second challenge, we leverage a semantically robust pre-trained BERT model and adopt a cross-modal system that co-trains text embeddings and acoustic embeddings in a shared latent space. We further enhance this system by utilizing an acoustic module pre-trained on LibriSpeech and domain-adapting the text module on our target datasets. Our experiments show significant advantages for these pre-training and fine-tuning strategies, resulting in a system that achieves competitive intent-classification performance on Snips SLU and Fluent Speech Commands datasets.
The Bayesian Linear Information Filtering Problem
Oct 22, 2016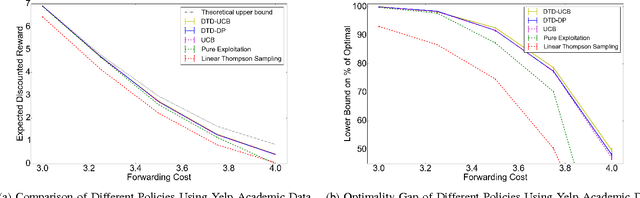
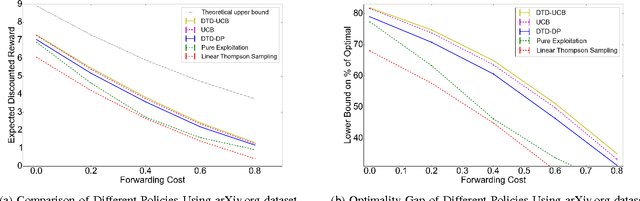
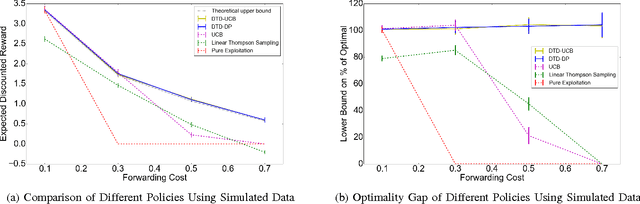
We present a Bayesian sequential decision-making formulation of the information filtering problem, in which an algorithm presents items (news articles, scientific papers, tweets) arriving in a stream, and learns relevance from user feedback on presented items. We model user preferences using a Bayesian linear model, similar in spirit to a Bayesian linear bandit. We compute a computational upper bound on the value of the optimal policy, which allows computing an optimality gap for implementable policies. We then use this analysis as motivation in introducing a pair of new Decompose-Then-Decide (DTD) heuristic policies, DTD-Dynamic-Programming (DTD-DP) and DTD-Upper-Confidence-Bound (DTD-UCB). We compare DTD-DP and DTD-UCB against several benchmarks on real and simulated data, demonstrating significant improvement, and show that the achieved performance is close to the upper bound.
Learned Block-based Hybrid Image Compression
Jan 18, 2021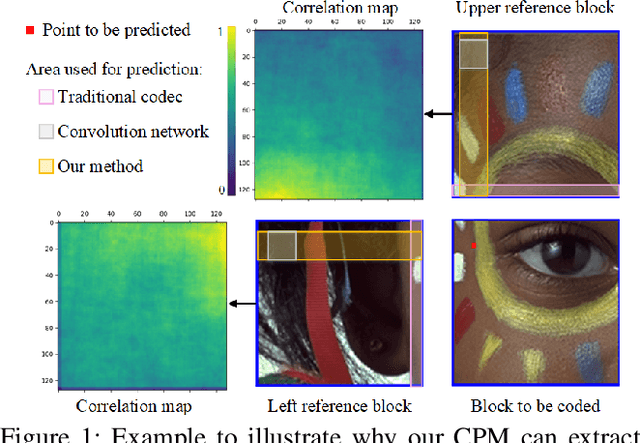
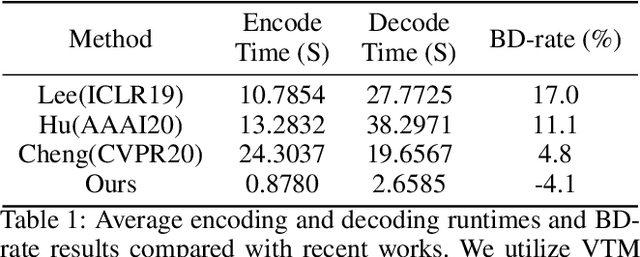
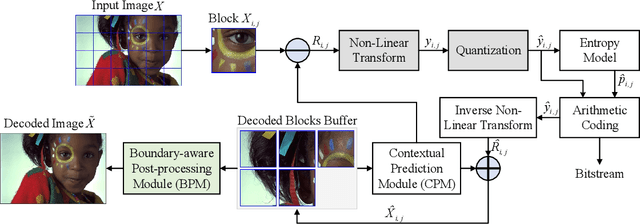
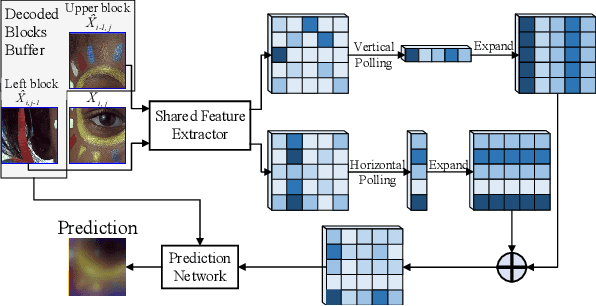
Recent works on learned image compression perform encoding and decoding processes in a full-resolution manner, resulting in two problems when deployed for practical applications. First, parallel acceleration of the autoregressive entropy model cannot be achieved due to serial decoding. Second, full-resolution inference often causes the out-of-memory(OOM) problem with limited GPU resources, especially for high-resolution images. Block partition is a good design choice to handle the above issues, but it brings about new challenges in reducing the redundancy between blocks and eliminating block effects. To tackle the above challenges, this paper provides a learned block-based hybrid image compression (LBHIC) framework. Specifically, we introduce explicit intra prediction into a learned image compression framework to utilize the relation among adjacent blocks. Superior to context modeling by linear weighting of neighbor pixels in traditional codecs, we propose a contextual prediction module (CPM) to better capture long-range correlations by utilizing the strip pooling to extract the most relevant information in neighboring latent space, thus achieving effective information prediction. Moreover, to alleviate blocking artifacts, we further propose a boundary-aware postprocessing module (BPM) with the edge importance taken into account. Extensive experiments demonstrate that the proposed LBHIC codec outperforms the VVC, with a bit-rate conservation of 4.1%, and reduces the decoding time by approximately 86.7% compared with that of state-of-the-art learned image compression methods.
Depth-Adapted CNN for RGB-D cameras
Sep 23, 2020
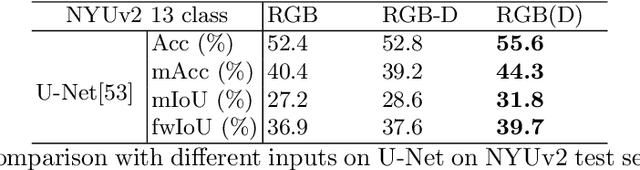
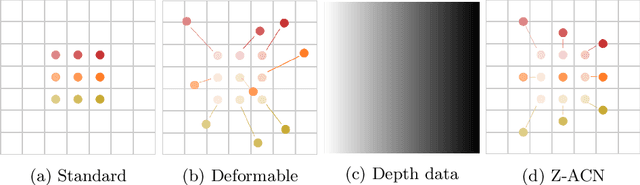
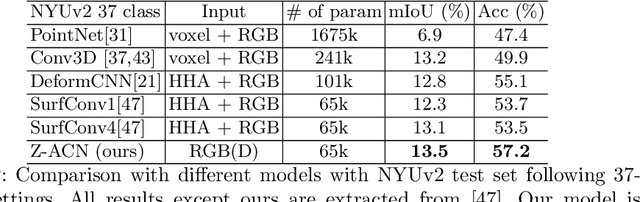
Conventional 2D Convolutional Neural Networks (CNN) extract features from an input image by applying linear filters. These filters compute the spatial coherence by weighting the photometric information on a fixed neighborhood without taking into account the geometric information. We tackle the problem of improving the classical RGB CNN methods by using the depth information provided by the RGB-D cameras. State-of-the-art approaches use depth as an additional channel or image (HHA) or pass from 2D CNN to 3D CNN. This paper proposes a novel and generic procedure to articulate both photometric and geometric information in CNN architecture. The depth data is represented as a 2D offset to adapt spatial sampling locations. The new model presented is invariant to scale and rotation around the X and the Y axis of the camera coordinate system. Moreover, when depth data is constant, our model is equivalent to a regular CNN. Experiments of benchmarks validate the effectiveness of our model.
Neural population geometry: An approach for understanding biological and artificial neural networks
Apr 14, 2021

Advances in experimental neuroscience have transformed our ability to explore the structure and function of neural circuits. At the same time, advances in machine learning have unleashed the remarkable computational power of artificial neural networks (ANNs). While these two fields have different tools and applications, they present a similar challenge: namely, understanding how information is embedded and processed through high-dimensional representations to solve complex tasks. One approach to addressing this challenge is to utilize mathematical and computational tools to analyze the geometry of these high-dimensional representations, i.e., neural population geometry. We review examples of geometrical approaches providing insight into the function of biological and artificial neural networks: representation untangling in perception, a geometric theory of classification capacity, disentanglement and abstraction in cognitive systems, topological representations underlying cognitive maps, dynamic untangling in motor systems, and a dynamical approach to cognition. Together, these findings illustrate an exciting trend at the intersection of machine learning, neuroscience, and geometry, in which neural population geometry provides a useful population-level mechanistic descriptor underlying task implementation. Importantly, geometric descriptions are applicable across sensory modalities, brain regions, network architectures and timescales. Thus, neural population geometry has the potential to unify our understanding of structure and function in biological and artificial neural networks, bridging the gap between single neurons, populations and behavior.