 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DF^2AM: Dual-level Feature Fusion and Affinity Modeling for RGB-Infrared Cross-modality Person Re-identification
Apr 01, 2021
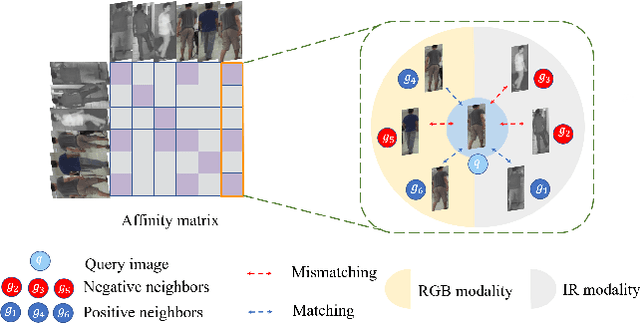
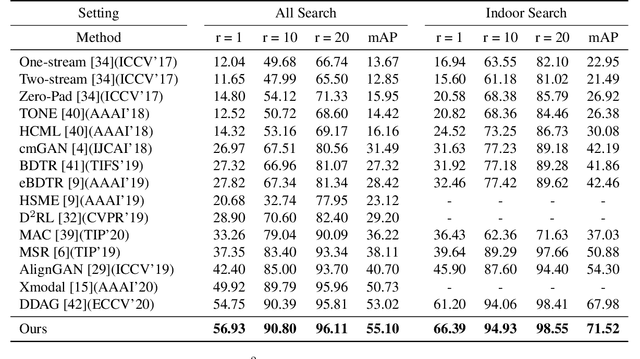
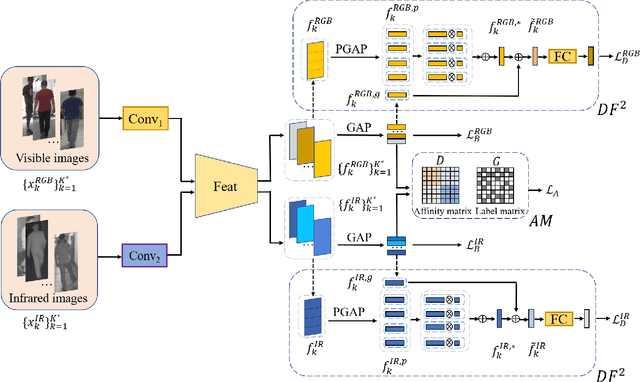
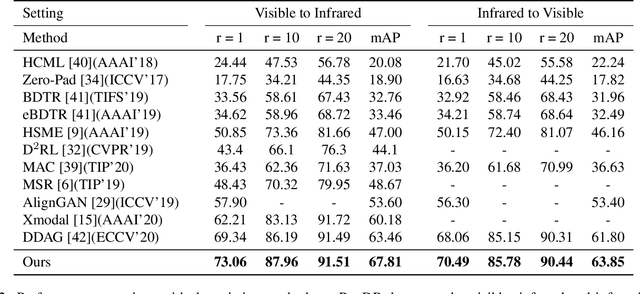
RGB-infrared person re-identification is a challenging task due to the intra-class variations and cross-modality discrepancy. Existing works mainly focus on learning modality-shared global representations by aligning image styles or feature distributions across modalities, while local feature from body part and relationships between person images are largely neglected. In this paper, we propose a Dual-level (i.e., local and global) Feature Fusion (DF^2) module by learning attention for discriminative feature from local to global manner. In particular, the attention for a local feature is determined locally, i.e., applying a learned transformation function on itself. Meanwhile, to further mining the relationships between global features from person images, we propose an Affinities Modeling (AM) module to obtain the optimal intra- and inter-modality image matching. Specifically, AM employes intra-class compactness and inter-class separability in the sample similarities as supervised information to model the affinities between intra- and inter-modality samples. Experimental results show that our proposed method outperforms state-of-the-arts by large margins on two widely used cross-modality re-ID datasets SYSU-MM01 and RegDB, respectively.
Focal points and their implications for Möbius Transforms and Dempster-Shafer Theory
Nov 12, 2020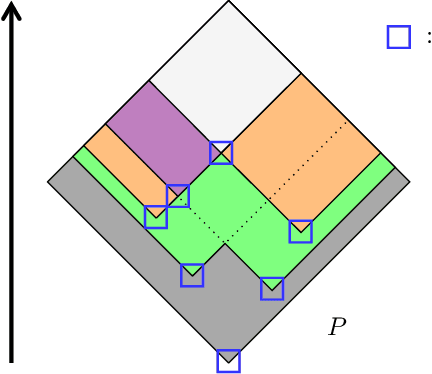
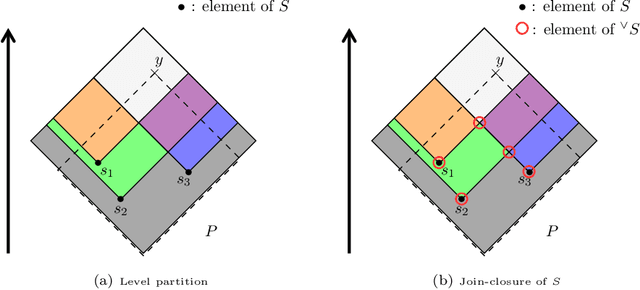
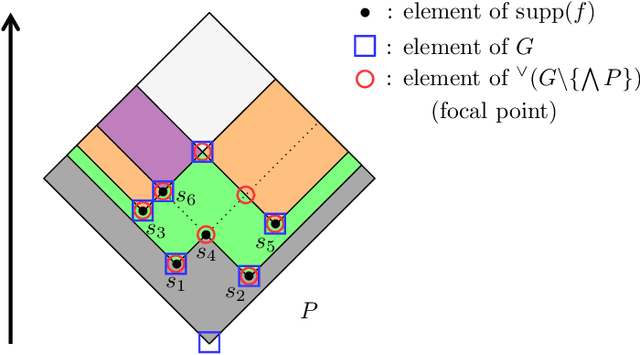
Dempster-Shafer Theory (DST) generalizes Bayesian probability theory, offering useful additional information, but suffers from a much higher computational burden. A lot of work has been done to reduce the time complexity of information fusion with Dempster's rule, which is a pointwise multiplication of two zeta transforms, and optimal general algorithms have been found to get the complete definition of these transforms. Yet, it is shown in this paper that the zeta transform and its inverse, the M\"obius transform, can be exactly simplified, fitting the quantity of information contained in belief functions. Beyond that, this simplification actually works for any function on any partially ordered set. It relies on a new notion that we call focal point and that constitutes the smallest domain on which both the zeta and M\"obius transforms can be defined. We demonstrate the interest of these general results for DST, not only for the reduction in complexity of most transformations between belief representations and their fusion, but also for theoretical purposes. Indeed, we provide a new generalization of the conjunctive decomposition of evidence and formulas uncovering how each decomposition weight is tied to the corresponding mass function.
Rate-Splitting Multiple Access for Multigroup Multicast Cellular and Satellite Communications: PHY Layer Design and Link-Level Simulations
Apr 01, 2021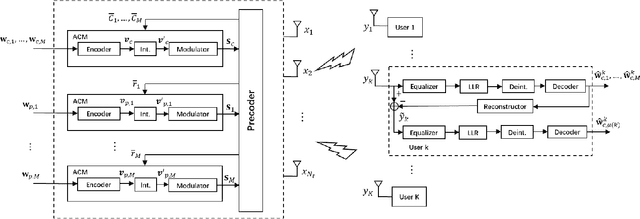
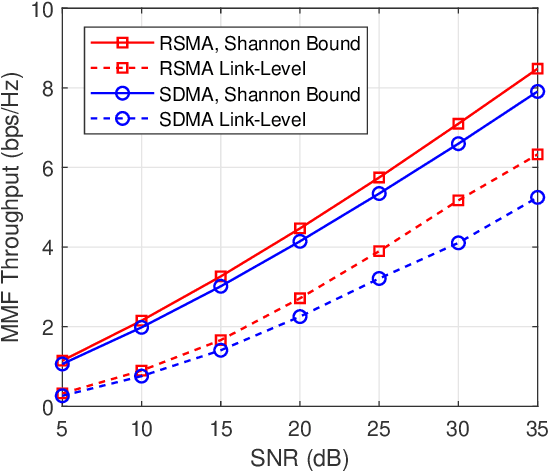
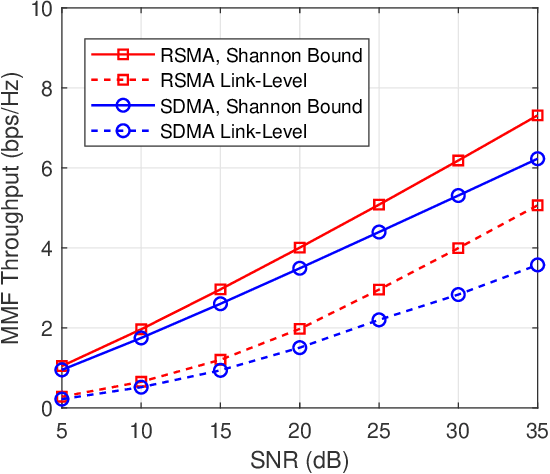
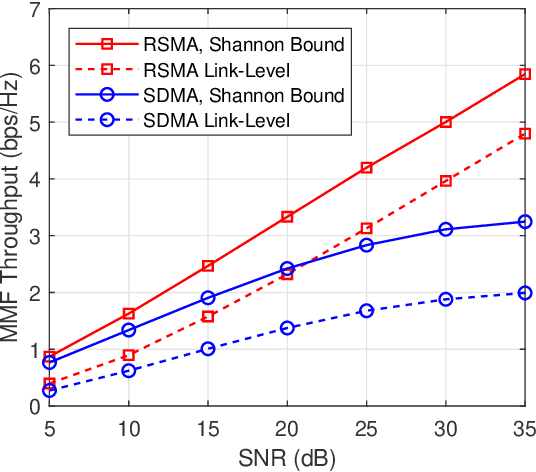
Rate-splitting multiple access (RSMA), relying on linearly precoded rate-splitting (RS) at the transmitter and successive interference cancellation (SIC) at the receivers has emerged as a powerful and flexible multiple access strategy for downlink multi-user multi-antenna systems. Through message splitting and the transmission of both common and private messages, RSMA has been demonstrated to be a robust interference management strategy which enables partially decoding interference and partially treating interference as noise. In this work, we consider the application of RSMA in a multigroup multicast scenario, where each message is intended to a group of users. By leveraging the recent results on the max-min fair (MMF) optimization problem of RSMA-based multigroup multicast beamforming with imperfect channel state information at the transmitter (CSIT), we investigate the design of the physical (PHY) layer including finite length polar coding, finite alphabet modulation, adaptive modulation and coding (AMC) algorithm, and SIC receivers, etc. Link-level simulation (LLS) results verify the superiority of RSMA-based multigroup multicast transmission compared with space-division multiple access (SDMA)-based strategy in both cellular systems and multibeam satellite systems.
Distributed Multi-Target Tracking in Camera Networks
Oct 26, 2020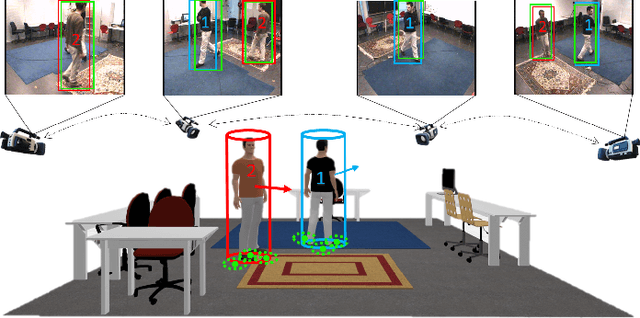
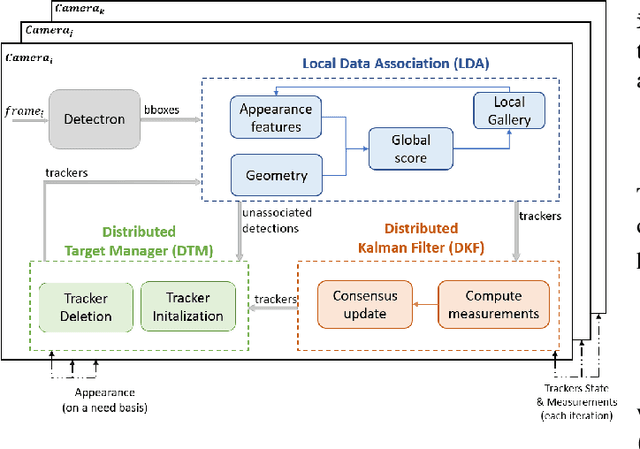

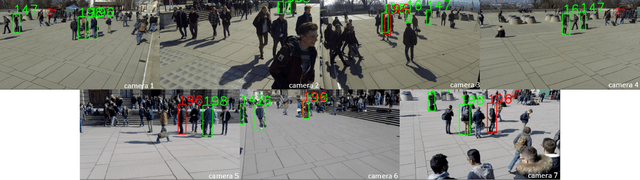
Most recent works on multi-target tracking with multiple cameras focus on centralized systems. In contrast, this paper presents a multi-target tracking approach implemented in a distributed camera network. The advantages of distributed systems lie in lighter communication management, greater robustness to failures and local decision making. On the other hand, data association and information fusion are more challenging than in a centralized setup, mostly due to the lack of global and complete information. The proposed algorithm boosts the benefits of the Distributed-Consensus Kalman Filter with the support of a re-identification network and a distributed tracker manager module to facilitate consistent information. These techniques complement each other and facilitate the cross-camera data association in a simple and effective manner. We evaluate the whole system with known public data sets under different conditions demonstrating the advantages of combining all the modules. In addition, we compare our algorithm to some existing centralized tracking methods, outperforming their behavior in terms of accuracy and bandwidth usage.
Robowflex: Robot Motion Planning with MoveIt Made Easy
Mar 23, 2021



Robowflex is a software library for robot motion planning in industrial and research applications, leveraging the popular MoveIt library and Robot Operating System (ROS) middleware. Robowflex takes advantage of the ease of motion planning with MoveIt while providing an augmented API to craft and manipulate motion planning queries within a single program. Robowflex's high-level API simplifies many common use-cases while still providing access to the underlying MoveIt library. Robowflex is particularly useful for 1) developing new motion planners, 2) evaluation of motion planners, and 3) complex problems that use motion planning (e.g., task and motion planning). Robowflex also provides visualization capabilities, integrations to other robotics libraries (e.g., DART and Tesseract), and is complimentary to many other robotics packages. With our library, the user does not need to be an expert at ROS or MoveIt in order to set up motion planning queries, extract information from results, and directly interface with a variety of software components. We provide a few example use-cases that demonstrate its efficacy.
Less is More: Accelerating Faster Neural Networks Straight from JPEG
Apr 01, 2021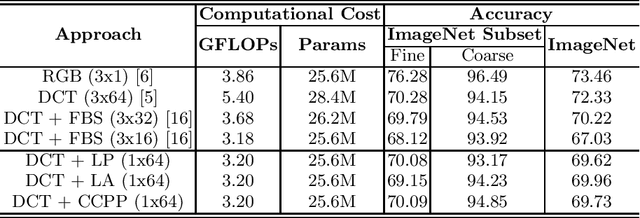

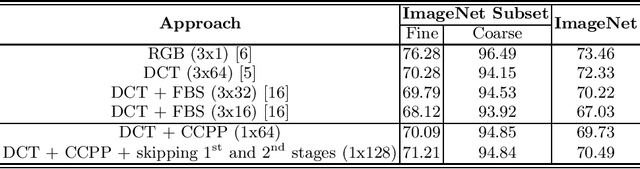
Most image data available are often stored in a compressed format, from which JPEG is the most widespread. To feed this data on a convolutional neural network (CNN), a preliminary decoding process is required to obtain RGB pixels, demanding a high computational load and memory usage. For this reason, the design of CNNs for processing JPEG compressed data has gained attention in recent years. In most existing works, typical CNN architectures are adapted to facilitate the learning with the DCT coefficients rather than RGB pixels. Although they are effective, their architectural changes either raise the computational costs or neglect relevant information from DCT inputs. In this paper, we examine different ways of speeding up CNNs designed for DCT inputs, exploiting learning strategies to reduce the computational complexity by taking full advantage of DCT inputs. Our experiments were conducted on the ImageNet dataset. Results show that learning how to combine all DCT inputs in a data-driven fashion is better than discarding them by hand, and its combination with a reduction of layers has proven to be effective for reducing the computational costs while retaining accuracy.
Collaborative Filtering with Information-Rich and Information-Sparse Entities
Mar 06, 2014
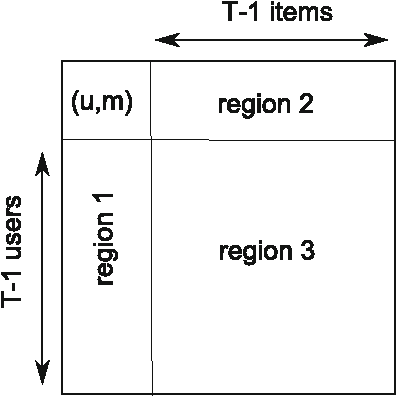
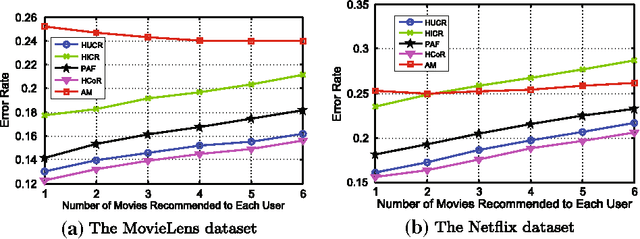

In this paper, we consider a popular model for collaborative filtering in recommender systems where some users of a website rate some items, such as movies, and the goal is to recover the ratings of some or all of the unrated items of each user. In particular, we consider both the clustering model, where only users (or items) are clustered, and the co-clustering model, where both users and items are clustered, and further, we assume that some users rate many items (information-rich users) and some users rate only a few items (information-sparse users). When users (or items) are clustered, our algorithm can recover the rating matrix with $\omega(MK \log M)$ noisy entries while $MK$ entries are necessary, where $K$ is the number of clusters and $M$ is the number of items. In the case of co-clustering, we prove that $K^2$ entries are necessary for recovering the rating matrix, and our algorithm achieves this lower bound within a logarithmic factor when $K$ is sufficiently large. We compare our algorithms with a well-known algorithms called alternating minimization (AM), and a similarity score-based algorithm known as the popularity-among-friends (PAF) algorithm by applying all three to the MovieLens and Netflix data sets. Our co-clustering algorithm and AM have similar overall error rates when recovering the rating matrix, both of which are lower than the error rate under PAF. But more importantly, the error rate of our co-clustering algorithm is significantly lower than AM and PAF in the scenarios of interest in recommender systems: when recommending a few items to each user or when recommending items to users who only rated a few items (these users are the majority of the total user population). The performance difference increases even more when noise is added to the datasets.
A Survey on Stance Detection for Mis- and Disinformation Identification
Feb 27, 2021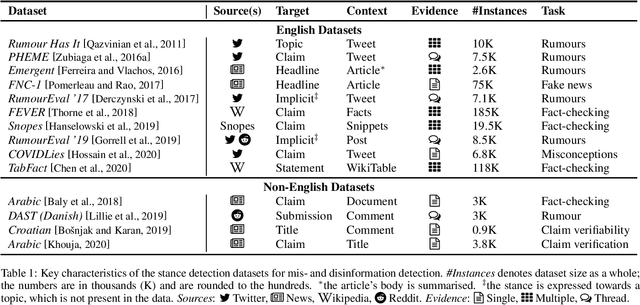
Detecting attitudes expressed in texts, also known as stance detection, has become an important task for the detection of false information online, be it misinformation (unintentionally false) or disinformation (intentionally false, spread deliberately with malicious intent). Stance detection has been framed in different ways, including: (a) as a component of fact-checking, rumour detection, and detecting previously fact-checked claims; or (b) as a task in its own right. While there have been prior efforts to contrast stance detection with other related social media tasks such as argumentation mining and sentiment analysis, there is no survey examining the relationship between stance detection detection and mis- and disinformation detection from a holistic viewpoint, which is the focus of this survey. We review and analyse existing work in this area, before discussing lessons learnt and future challenges.
Hierarchical Metadata-Aware Document Categorization under Weak Supervision
Oct 26, 2020
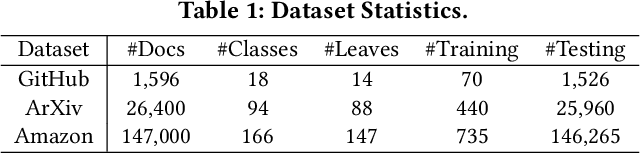
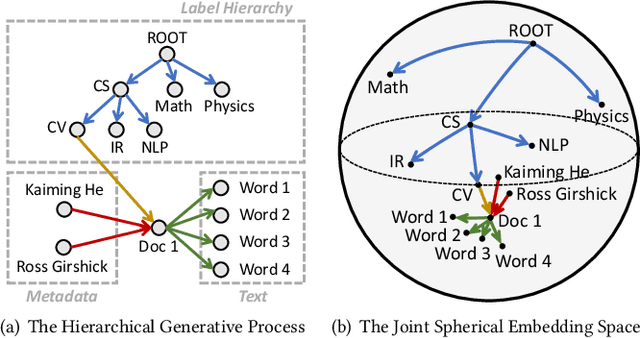
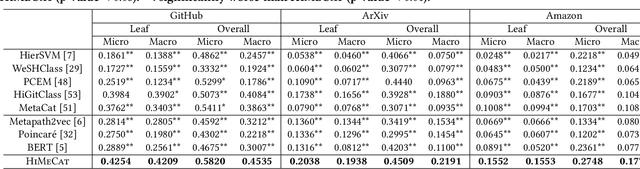
Categorizing documents into a given label hierarchy is intuitively appealing due to the ubiquity of hierarchical topic structures in massive text corpora. Although related studies have achieved satisfying performance in fully supervised hierarchical document classification, they usually require massive human-annotated training data and only utilize text information. However, in many domains, (1) annotations are quite expensive where very few training samples can be acquired; (2) documents are accompanied by metadata information. Hence, this paper studies how to integrate the label hierarchy, metadata, and text signals for document categorization under weak supervision. We develop HiMeCat, an embedding-based generative framework for our task. Specifically, we propose a novel joint representation learning module that allows simultaneous modeling of category dependencies, metadata information and textual semantics, and we introduce a data augmentation module that hierarchically synthesizes training documents to complement the original, small-scale training set. Our experiments demonstrate a consistent improvement of HiMeCat over competitive baselines and validate the contribution of our representation learning and data augmentation modules.
Progressive residual learning for single image dehazing
Mar 14, 2021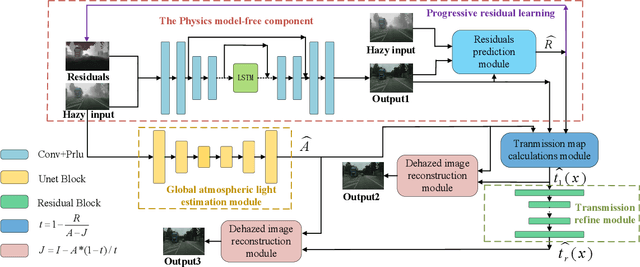



The recent physical model-free dehazing methods have achieved state-of-the-art performances. However, without the guidance of physical models, the performances degrade rapidly when applied to real scenarios due to the unavailable or insufficient data problems. On the other hand, the physical model-based methods have better interpretability but suffer from multi-objective optimizations of parameters, which may lead to sub-optimal dehazing results. In this paper, a progressive residual learning strategy has been proposed to combine the physical model-free dehazing process with reformulated scattering model-based dehazing operations, which enjoys the merits of dehazing methods in both categories. Specifically, the global atmosphere light and transmission maps are interactively optimized with the aid of accurate residual information and preliminary dehazed restorations from the initial physical model-free dehazing process. The proposed method performs favorably against the state-of-the-art methods on public dehazing benchmarks with better model interpretability and adaptivity for complex hazy data.