 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image Captioning with Context-Aware Auxiliary Guidance
Dec 10, 2020
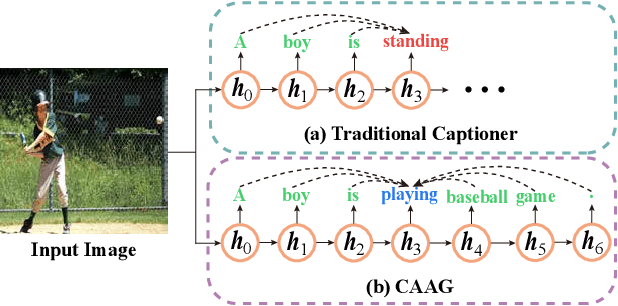
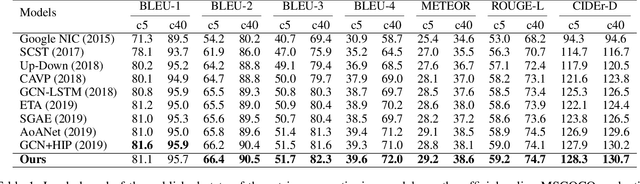
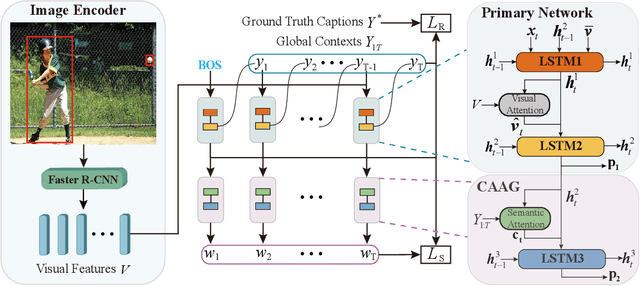
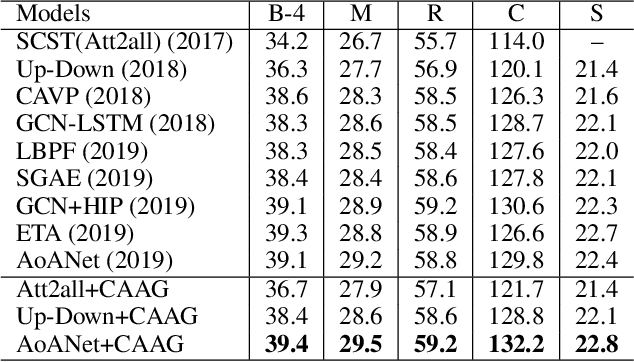
Image captioning is a challenging computer vision task, which aims to generate a natural language description of an image. Most recent researches follow the encoder-decoder framework which depends heavily on the previous generated words for the current prediction. Such methods can not effectively take advantage of the future predicted information to learn complete semantics. In this paper, we propose Context-Aware Auxiliary Guidance (CAAG) mechanism that can guide the captioning model to perceive global contexts. Upon the captioning model, CAAG performs semantic attention that selectively concentrates on useful information of the global predictions to reproduce the current generation. To validate the adaptability of the method, we apply CAAG to three popular captioners and our proposal achieves competitive performance on the challenging Microsoft COCO image captioning benchmark, e.g. 132.2 CIDEr-D score on Karpathy split and 130.7 CIDEr-D (c40) score on official online evaluation server.
RGB-D Local Implicit Function for Depth Completion of Transparent Objects
Apr 01, 2021
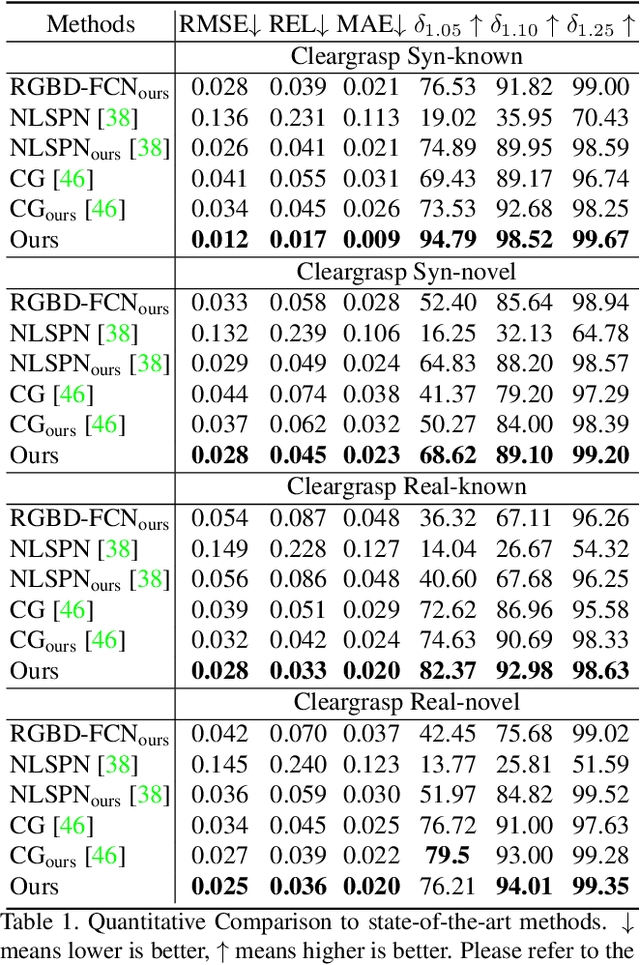


Majority of the perception methods in robotics require depth information provided by RGB-D cameras. However, standard 3D sensors fail to capture depth of transparent objects due to refraction and absorption of light. In this paper, we introduce a new approach for depth completion of transparent objects from a single RGB-D image. Key to our approach is a local implicit neural representation built on ray-voxel pairs that allows our method to generalize to unseen objects and achieve fast inference speed. Based on this representation, we present a novel framework that can complete missing depth given noisy RGB-D input. We further improve the depth estimation iteratively using a self-correcting refinement model. To train the whole pipeline, we build a large scale synthetic dataset with transparent objects. Experiments demonstrate that our method performs significantly better than the current state-of-the-art methods on both synthetic and real world data. In addition, our approach improves the inference speed by a factor of 20 compared to the previous best method, ClearGrasp. Code and dataset will be released at https://research.nvidia.com/publication/2021-03_RGB-D-Local-Implicit.
Imagination-enabled Robot Perception
Nov 27, 2020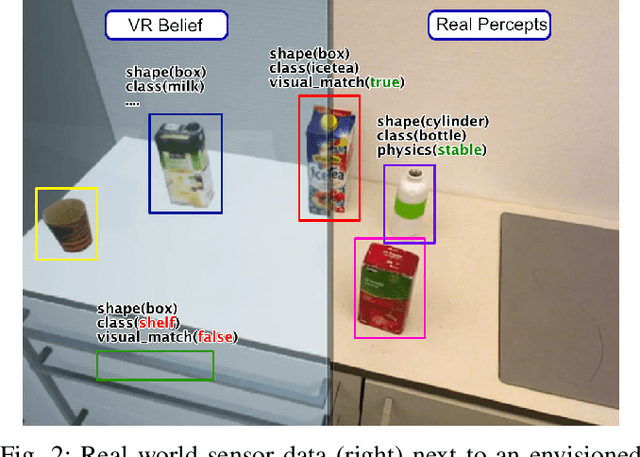
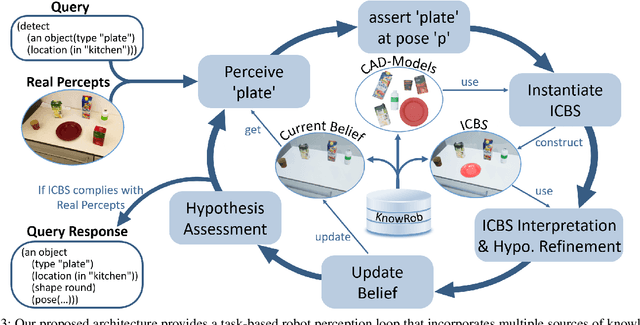
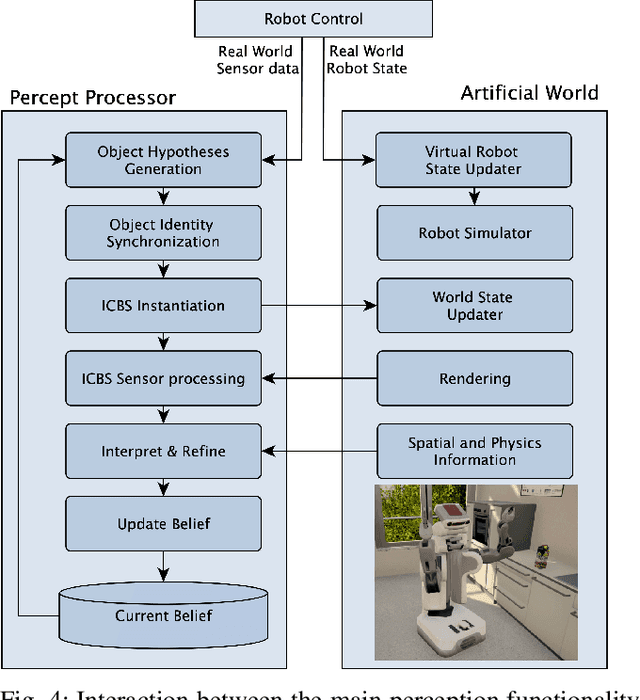
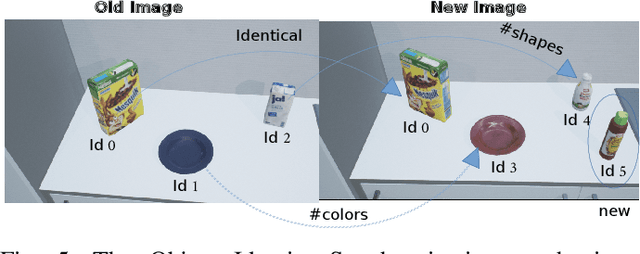
Many of today's robot perception systems aim at accomplishing perception tasks that are too simplistic and too hard. They are too simplistic because they do not require the perception systems to provide all the information needed to accomplish manipulation tasks. Typically the perception results do not include information about the part structure of objects, articulation mechanisms and other attributes needed for adapting manipulation behavior. On the other hand, the perception problems stated are also too hard because -- unlike humans -- the perception systems cannot leverage the expectations about what they will see to their full potential. Therefore, we investigate a variation of robot perception tasks suitable for robots accomplishing everyday manipulation tasks, such as household robots or a robot in a retail store. In such settings it is reasonable to assume that robots know most objects and have detailed models of them. We propose a perception system that maintains its beliefs about its environment as a scene graph with physics simulation and visual rendering. When detecting objects, the perception system retrieves the model of the object and places it at the corresponding place in a VR-based environment model. The physics simulation ensures that object detections that are physically not possible are rejected and scenes can be rendered to generate expectations at the image level. The result is a perception system that can provide useful information for manipulation tasks.
Visual Perception Generalization for Vision-and-Language Navigation via Meta-Learning
Jan 19, 2021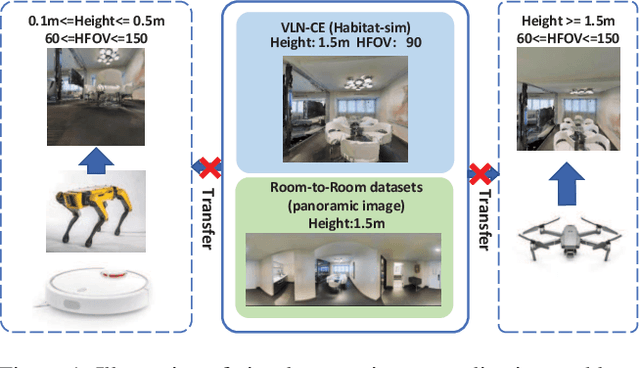
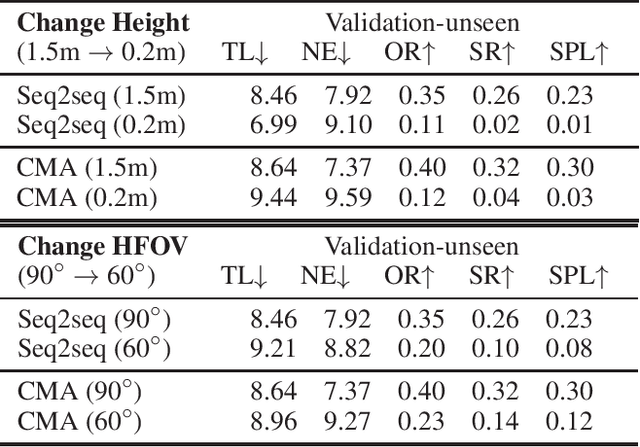
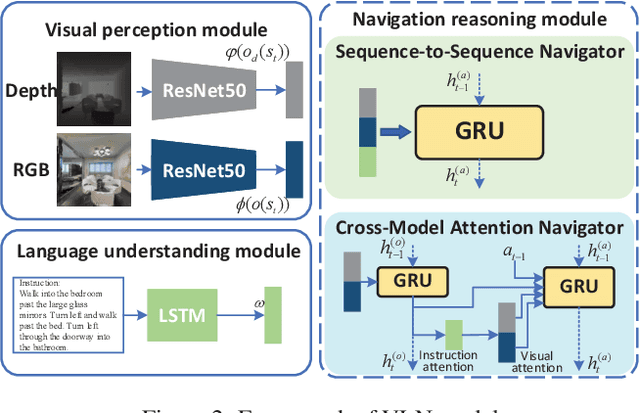
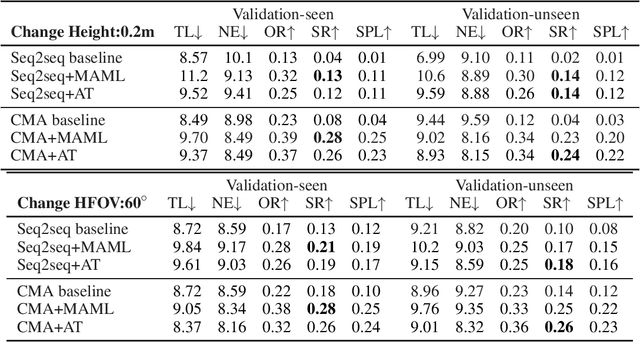
Vision-and-language navigation (VLN) is a challenging task that requires an agent to navigate in real-world environments by understanding natural language instructions and visual information received in real-time. Prior works have implemented VLN tasks on continuous environments or physical robots, all of which use a fixed camera configuration due to the limitations of datasets, such as 1.5 meters height, 90 degrees horizontal field of view (HFOV), etc. However, real-life robots with different purposes have multiple camera configurations, and the huge gap in visual information makes it difficult to directly transfer the learned navigation model between various robots. In this paper, we propose a visual perception generalization strategy based on meta-learning, which enables the agent to fast adapt to a new camera configuration with a few shots. In the training phase, we first locate the generalization problem to the visual perception module, and then compare two meta-learning algorithms for better generalization in seen and unseen environments. One of them uses the Model-Agnostic Meta-Learning (MAML) algorithm that requires a few shot adaptation, and the other refers to a metric-based meta-learning method with a feature-wise affine transformation layer. The experiment results show that our strategy successfully adapts the learned navigation model to a new camera configuration, and the two algorithms show their advantages in seen and unseen environments respectively.
Know What and Know Where: An Object-and-Room Informed Sequential BERT for Indoor Vision-Language Navigation
Apr 09, 2021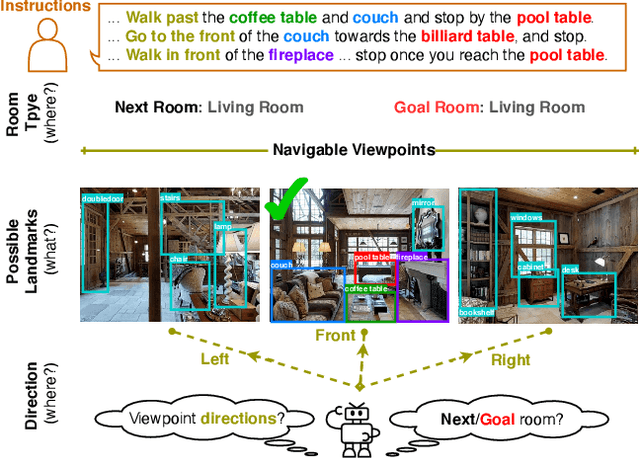

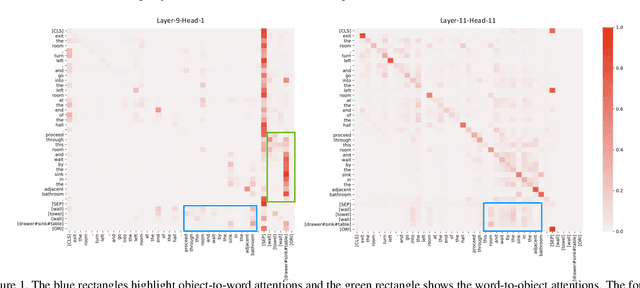
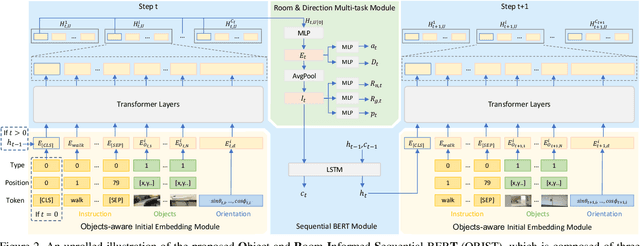
Vision-and-Language Navigation (VLN) requires an agent to navigate to a remote location on the basis of natural-language instructions and a set of photo-realistic panoramas. Most existing methods take words in instructions and discrete views of each panorama as the minimal unit of encoding. However, this requires a model to match different textual landmarks in instructions (e.g., TV, table) against the same view feature. In this work, we propose an object-informed sequential BERT to encode visual perceptions and linguistic instructions at the same fine-grained level, namely objects and words, to facilitate the matching between visual and textual entities and hence "know what". Our sequential BERT enables the visual-textual clues to be interpreted in light of the temporal context, which is crucial to multi-round VLN tasks. Additionally, we enable the model to identify the relative direction (e.g., left/right/front/back) of each navigable location and the room type (e.g., bedroom, kitchen) of its current and final navigation goal, namely "know where", as such information is widely mentioned in instructions implying the desired next and final locations. Extensive experiments demonstrate the effectiveness compared against several state-of-the-art methods on three indoor VLN tasks: REVERIE, NDH, and R2R.
Unsupervised Degradation Representation Learning for Blind Super-Resolution
Apr 01, 2021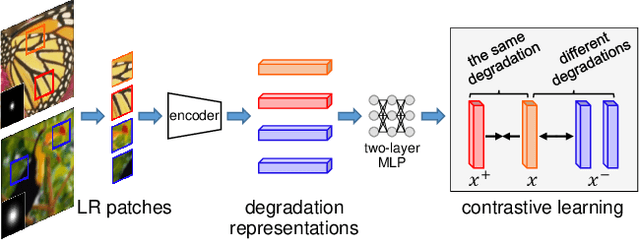

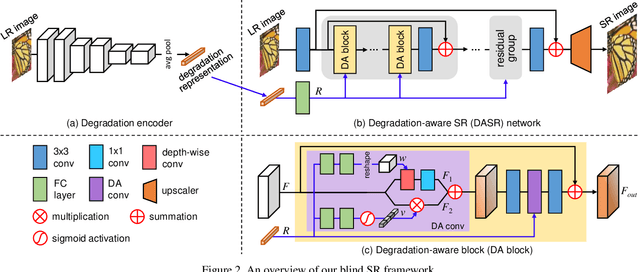
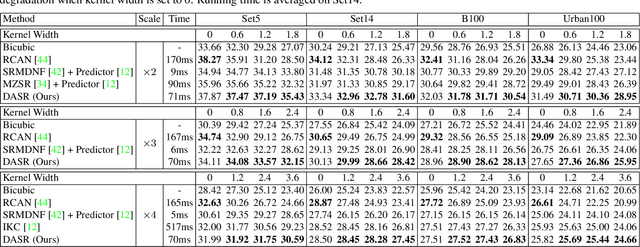
Most existing CNN-based super-resolution (SR) methods are developed based on an assumption that the degradation is fixed and known (e.g., bicubic downsampling). However, these methods suffer a severe performance drop when the real degradation is different from their assumption. To handle various unknown degradations in real-world applications, previous methods rely on degradation estimation to reconstruct the SR image. Nevertheless, degradation estimation methods are usually time-consuming and may lead to SR failure due to large estimation errors. In this paper, we propose an unsupervised degradation representation learning scheme for blind SR without explicit degradation estimation. Specifically, we learn abstract representations to distinguish various degradations in the representation space rather than explicit estimation in the pixel space. Moreover, we introduce a Degradation-Aware SR (DASR) network with flexible adaption to various degradations based on the learned representations. It is demonstrated that our degradation representation learning scheme can extract discriminative representations to obtain accurate degradation information. Experiments on both synthetic and real images show that our network achieves state-of-the-art performance for the blind SR task. Code is available at: https://github.com/LongguangWang/DASR.
3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Apr 01, 2021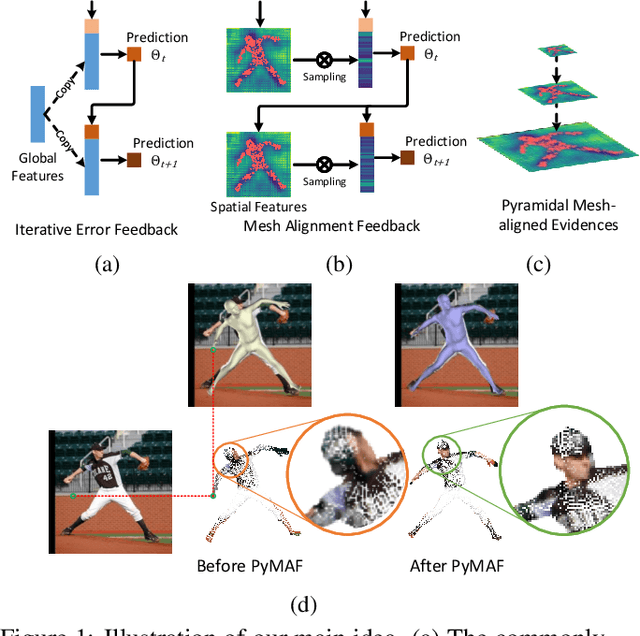
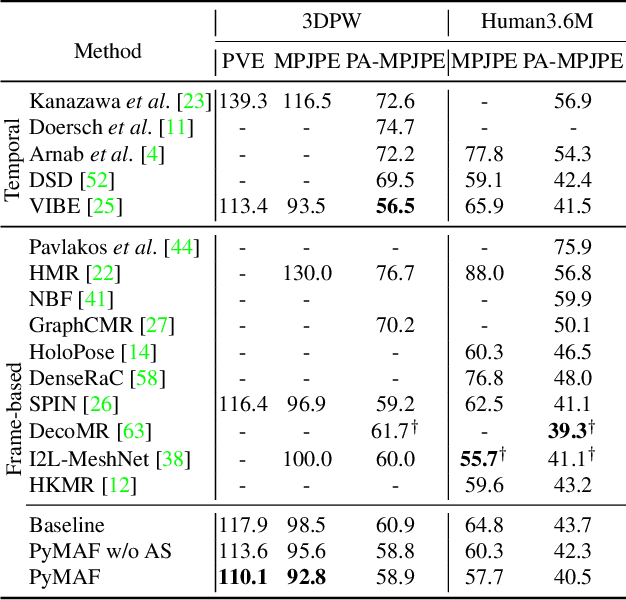
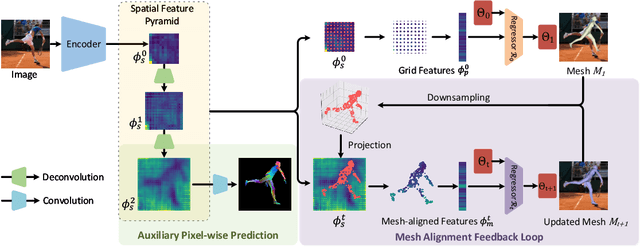
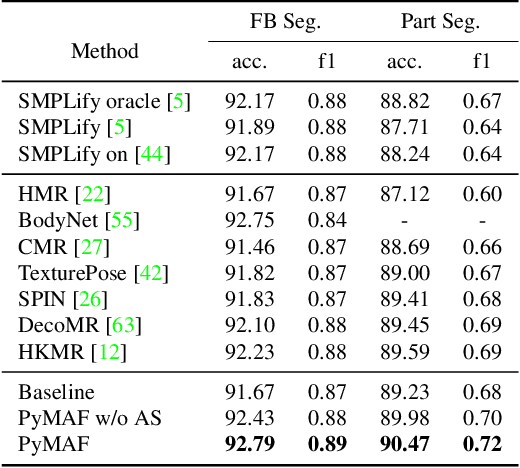
Regression-based methods have recently shown promising results in reconstructing human meshes from monocular images. By directly mapping from raw pixels to model parameters, these methods can produce parametric models in a feed-forward manner via neural networks. However, minor deviation in parameters may lead to noticeable misalignment between the estimated meshes and image evidences. To address this issue, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status in our deep regressor. In PyMAF, given the currently predicted parameters, mesh-aligned evidences will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To reduce noise and enhance the reliability of these evidences, an auxiliary pixel-wise supervision is imposed on the feature encoder, which provides mesh-image correspondence guidance for our network to preserve the most related information in spatial features. The efficacy of our approach is validated on several benchmarks, including Human3.6M, 3DPW, LSP, and COCO, where experimental results show that our approach consistently improves the mesh-image alignment of the reconstruction. Our code is publicly available at https://hongwenzhang.github.io/pymaf .
Generalizable Limited-Angle CT Reconstruction via Sinogram Extrapolation
Mar 15, 2021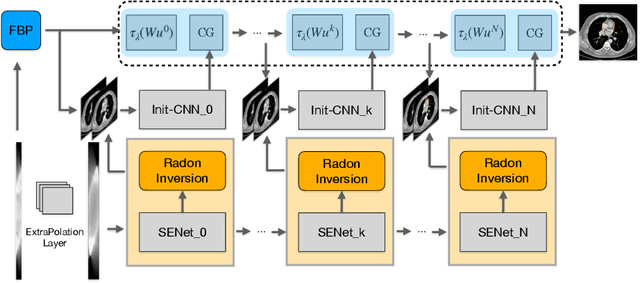

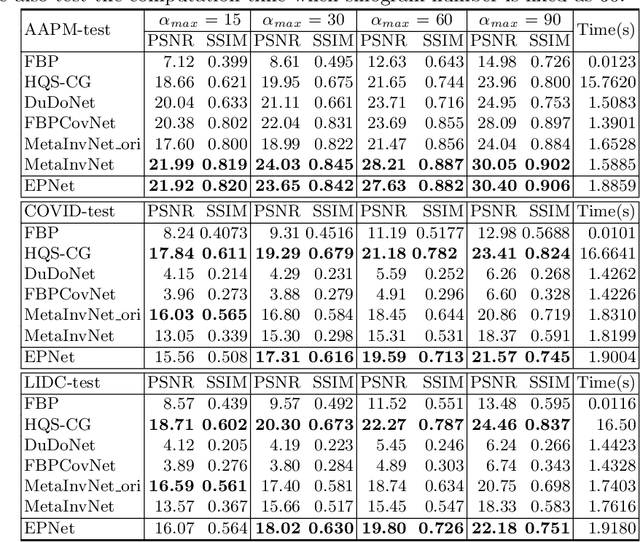
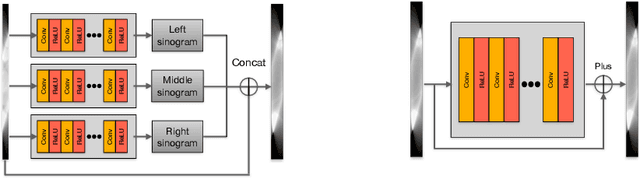
Computed tomography (CT) reconstruction from X-ray projections acquired within a limited angle range is challenging, especially when the angle range is extremely small. Both analytical and iterative models need more projections for effective modeling. Deep learning methods have gained prevalence due to their excellent reconstruction performances, but such success is mainly limited within the same dataset and does not generalize across datasets with different distributions. Hereby we propose ExtraPolationNetwork for limited-angle CT reconstruction via the introduction of a sinogram extrapolation module, which is theoretically justified. The module complements extra sinogram information and boots model generalizability. Extensive experimental results show that our reconstruction model achieves state-of-the-art performance on NIH-AAPM dataset, similar to existing approaches. More importantly, we show that using such a sinogram extrapolation module significantly improves the generalization capability of the model on unseen datasets (e.g., COVID-19 and LIDC datasets) when compared to existing approaches.
F2Net: Learning to Focus on the Foreground for Unsupervised Video Object Segmentation
Dec 04, 2020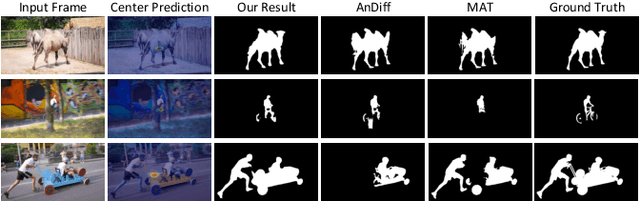
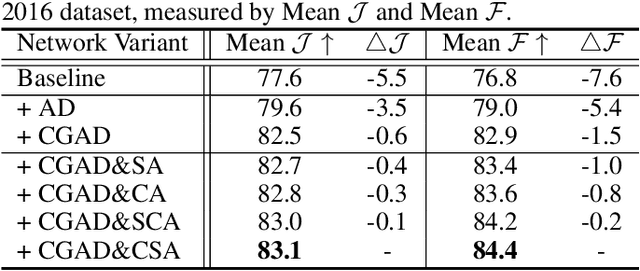
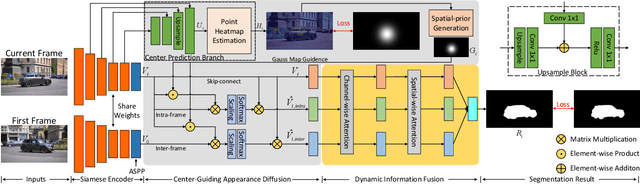
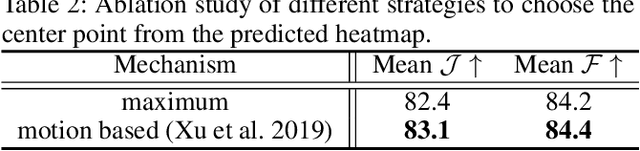
Although deep learning based methods have achieved great progress in unsupervised video object segmentation, difficult scenarios (e.g., visual similarity, occlusions, and appearance changing) are still not well-handled. To alleviate these issues, we propose a novel Focus on Foreground Network (F2Net), which delves into the intra-inter frame details for the foreground objects and thus effectively improve the segmentation performance. Specifically, our proposed network consists of three main parts: Siamese Encoder Module, Center Guiding Appearance Diffusion Module, and Dynamic Information Fusion Module. Firstly, we take a siamese encoder to extract the feature representations of paired frames (reference frame and current frame). Then, a Center Guiding Appearance Diffusion Module is designed to capture the inter-frame feature (dense correspondences between reference frame and current frame), intra-frame feature (dense correspondences in current frame), and original semantic feature of current frame. Specifically, we establish a Center Prediction Branch to predict the center location of the foreground object in current frame and leverage the center point information as spatial guidance prior to enhance the inter-frame and intra-frame feature extraction, and thus the feature representation considerably focus on the foreground objects. Finally, we propose a Dynamic Information Fusion Module to automatically select relatively important features through three aforementioned different level features. Extensive experiments on DAVIS2016, Youtube-object, and FBMS datasets show that our proposed F2Net achieves the state-of-the-art performance with significant improvement.
Nonlinear Spatial Filtering in Multichannel Speech Enhancement
Apr 22, 2021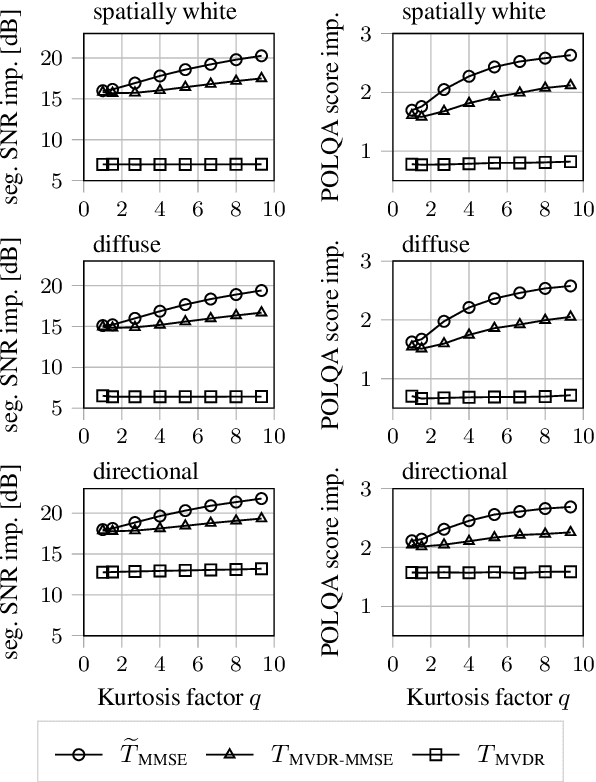
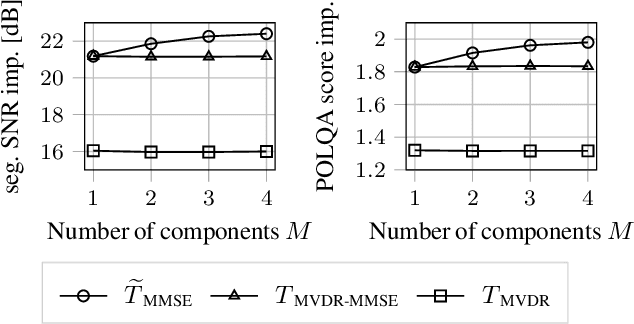
The majority of multichannel speech enhancement algorithms are two-step procedures that first apply a linear spatial filter, a so-called beamformer, and combine it with a single-channel approach for postprocessing. However, the serial concatenation of a linear spatial filter and a postfilter is not generally optimal in the minimum mean square error (MMSE) sense for noise distributions other than a Gaussian distribution. Rather, the MMSE optimal filter is a joint spatial and spectral nonlinear function. While estimating the parameters of such a filter with traditional methods is challenging, modern neural networks may provide an efficient way to learn the nonlinear function directly from data. To see if further research in this direction is worthwhile, in this work we examine the potential performance benefit of replacing the common two-step procedure with a joint spatial and spectral nonlinear filter. We analyze three different forms of non-Gaussianity: First, we evaluate on super-Gaussian noise with a high kurtosis. Second, we evaluate on inhomogeneous noise fields created by five interfering sources using two microphones, and third, we evaluate on real-world recordings from the CHiME3 database. In all scenarios, considerable improvements may be obtained. Most prominently, our analyses show that a nonlinear spatial filter uses the available spatial information more effectively than a linear spatial filter as it is capable of suppressing more than $D-1$ directional interfering sources with a $D$-dimensional microphone array without spatial adaptation.
* Accepted version, 11 pages, 6 figures