 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Know What and Know Where: An Object-and-Room Informed Sequential BERT for Indoor Vision-Language Navigation
Apr 09, 2021
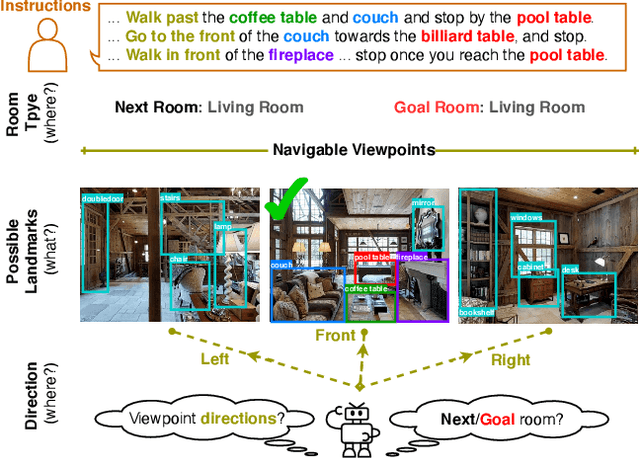

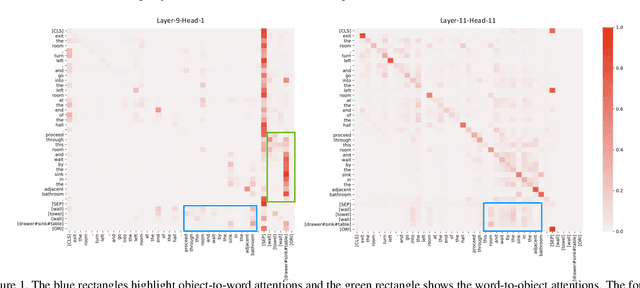
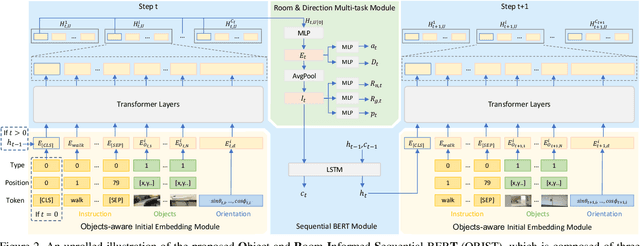
Vision-and-Language Navigation (VLN) requires an agent to navigate to a remote location on the basis of natural-language instructions and a set of photo-realistic panoramas. Most existing methods take words in instructions and discrete views of each panorama as the minimal unit of encoding. However, this requires a model to match different textual landmarks in instructions (e.g., TV, table) against the same view feature. In this work, we propose an object-informed sequential BERT to encode visual perceptions and linguistic instructions at the same fine-grained level, namely objects and words, to facilitate the matching between visual and textual entities and hence "know what". Our sequential BERT enables the visual-textual clues to be interpreted in light of the temporal context, which is crucial to multi-round VLN tasks. Additionally, we enable the model to identify the relative direction (e.g., left/right/front/back) of each navigable location and the room type (e.g., bedroom, kitchen) of its current and final navigation goal, namely "know where", as such information is widely mentioned in instructions implying the desired next and final locations. Extensive experiments demonstrate the effectiveness compared against several state-of-the-art methods on three indoor VLN tasks: REVERIE, NDH, and R2R.
Pedestrian Path Modification Mobile Tool for COVID-19 Social Distancing for Use in Multi-Modal Trip Navigation
May 08, 2021
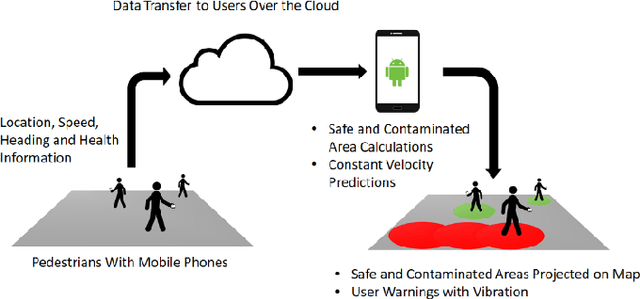
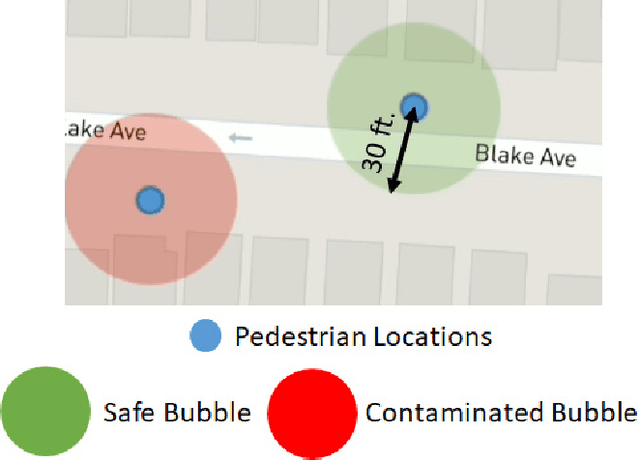
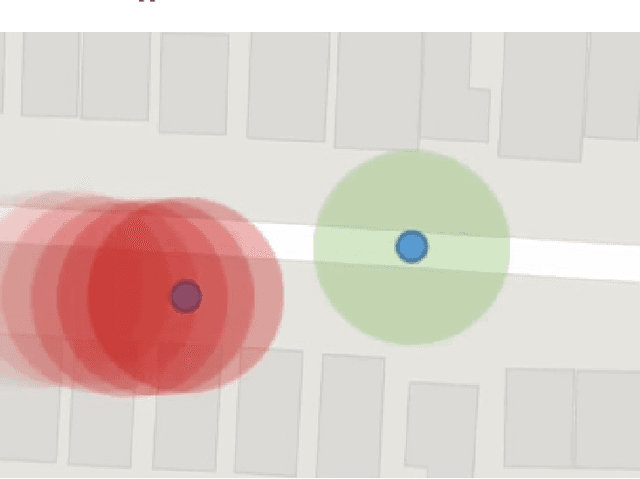
The novel Corona virus pandemic is one of the biggest worldwide problems right now. While hygiene and wearing masks make up a large portion of the currently suggested precautions by the Centers for Disease Control and Prevention (CDC) and World Health Organization (WHO), social distancing is another and arguably the most important precaution that would protect people since the airborne virus is easily transmitted through the air. Social distancing while walking outside, can be more effective, if pedestrians know locations of each other and even better if they know locations of people who are possible carriers. With this information, they can change their routes depending on the people walking nearby or they can stay away from areas that contain or have recently contained crowds. This paper presents a mobile device application that would be a very beneficial tool for social distancing during Coronavirus Disease 2019 (COVID-19). The application works, synced close to real-time, in a networking fashion with all users obtaining their locations and drawing a virtual safety bubble around them. These safety bubbles are used with the constant velocity pedestrian model to predict possible future social distancing violations and warn the user with sound and vibration. Moreover, it takes into account the virus staying airborne for a certain time, hence, creating time-decaying non-safe areas in the past trajectories of the users. The mobile app generates collision free paths for navigating around the undesired locations for the pedestrian mode of transportation when used as part of a multi-modal trip planning app. Results are applicable to other modes of transportation also. Features and the methods used for implementation are discussed in the paper. The application is tested using previously collected real pedestrian walking data in a realistic environment.
Parsing Indonesian Sentence into Abstract Meaning Representation using Machine Learning Approach
Mar 05, 2021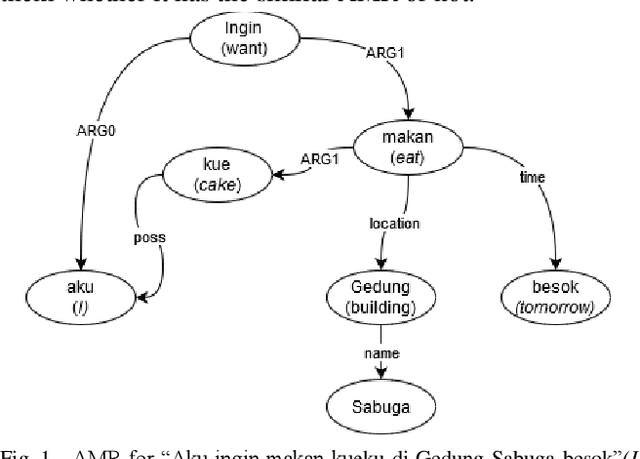
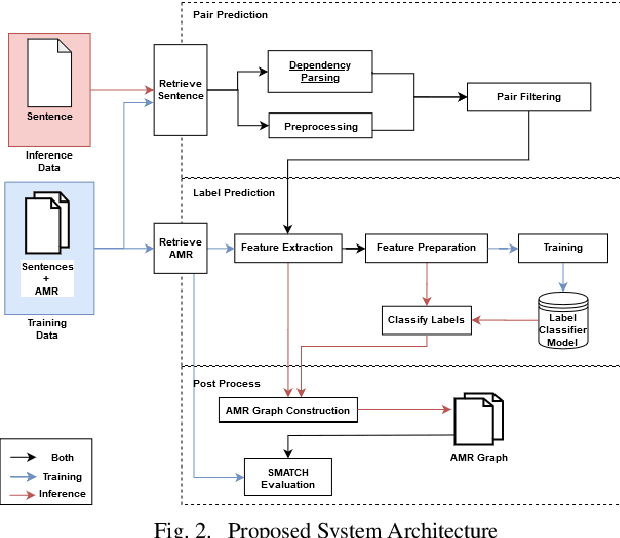
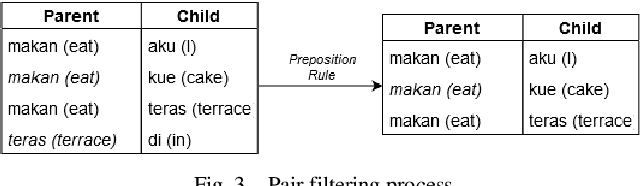
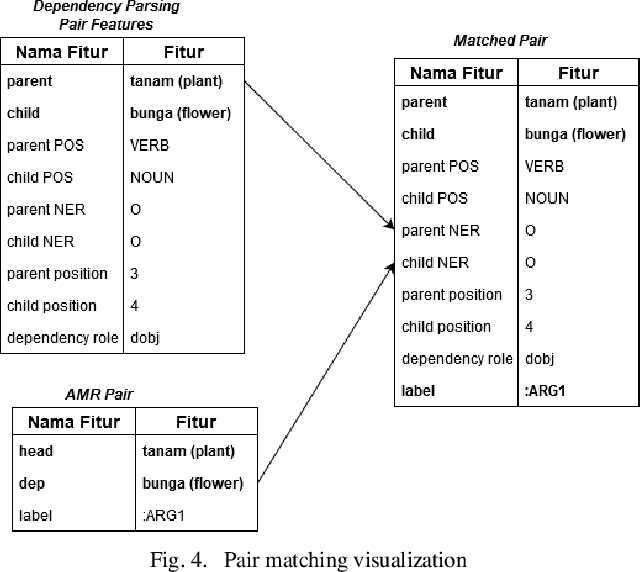
Abstract Meaning Representation (AMR) provides many information of a sentence such as semantic relations, coreferences, and named entity relation in one representation. However, research on AMR parsing for Indonesian sentence is fairly limited. In this paper, we develop a system that aims to parse an Indonesian sentence using a machine learning approach. Based on Zhang et al. work, our system consists of three steps: pair prediction, label prediction, and graph construction. Pair prediction uses dependency parsing component to get the edges between the words for the AMR. The result of pair prediction is passed to the label prediction process which used a supervised learning algorithm to predict the label between the edges of the AMR. We used simple sentence dataset that is gathered from articles and news article sentences. Our model achieved the SMATCH score of 0.820 for simple sentence test data.
Enquire One's Parent and Child Before Decision: Fully Exploit Hierarchical Structure for Self-Supervised Taxonomy Expansion
Jan 27, 2021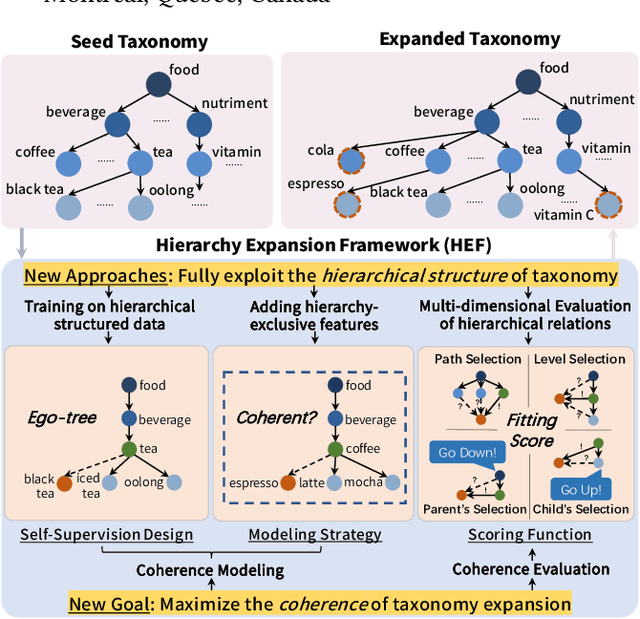
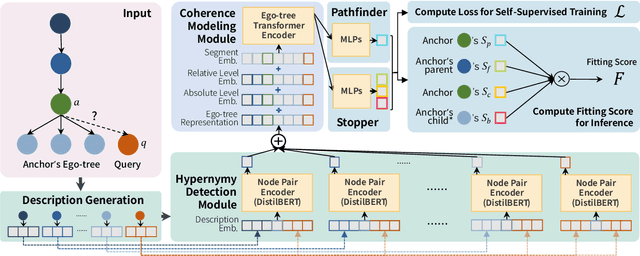
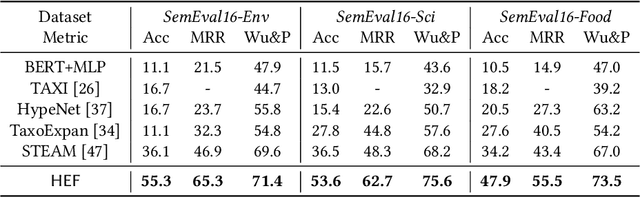
Taxonomy is a hierarchically structured knowledge graph that plays a crucial role in machine intelligence. The taxonomy expansion task aims to find a position for a new term in an existing taxonomy to capture the emerging knowledge in the world and keep the taxonomy dynamically updated. Previous taxonomy expansion solutions neglect valuable information brought by the hierarchical structure and evaluate the correctness of merely an added edge, which downgrade the problem to node-pair scoring or mini-path classification. In this paper, we propose the Hierarchy Expansion Framework (HEF), which fully exploits the hierarchical structure's properties to maximize the coherence of expanded taxonomy. HEF makes use of taxonomy's hierarchical structure in multiple aspects: i) HEF utilizes subtrees containing most relevant nodes as self-supervision data for a complete comparison of parental and sibling relations; ii) HEF adopts a coherence modeling module to evaluate the coherence of a taxonomy's subtree by integrating hypernymy relation detection and several tree-exclusive features; iii) HEF introduces the Fitting Score for position selection, which explicitly evaluates both path and level selections and takes full advantage of parental relations to interchange information for disambiguation and self-correction. Extensive experiments show that by better exploiting the hierarchical structure and optimizing taxonomy's coherence, HEF vastly surpasses the prior state-of-the-art on three benchmark datasets by an average improvement of 46.7% in accuracy and 32.3% in mean reciprocal rank.
Show or Tell? Demonstration is More Robust to Changes in Shared Perception than Explanation
Dec 16, 2020


Successful teaching entails a complex interaction between a teacher and a learner. The teacher must select and convey information based on what they think the learner perceives and believes. Teaching always involves misaligned beliefs, but studies of pedagogy often focus on situations where teachers and learners share perceptions. Nonetheless, a teacher and learner may not always experience or attend to the same aspects of the environment. Here, we study how misaligned perceptions influence communication. We hypothesize that the efficacy of different forms of communication depends on the shared perceptual state between teacher and learner. We develop a cooperative teaching game to test whether concrete mediums (demonstrations, or "showing") are more robust than abstract ones (language, or "telling") when the teacher and learner are not perceptually aligned. We find evidence that (1) language-based teaching is more affected by perceptual misalignment, but (2) demonstration-based teaching is less likely to convey nuanced information. We discuss implications for human pedagogy and machine learning.
Accent Estimation of Japanese Words from Their Surfaces and Romanizations for Building Large Vocabulary Accent Dictionaries
Sep 21, 2020

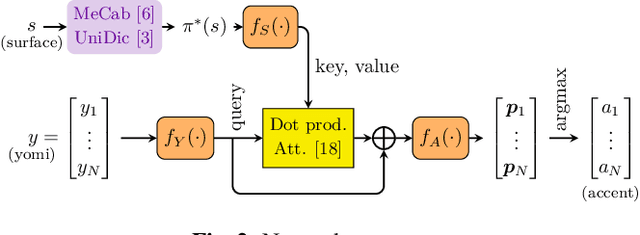
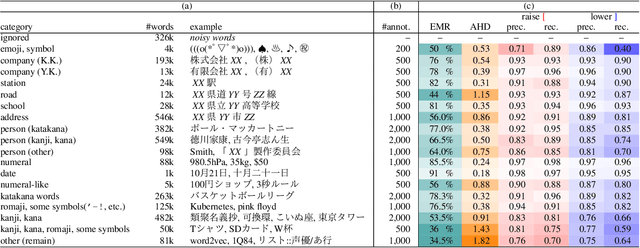
In Japanese text-to-speech (TTS), it is necessary to add accent information to the input sentence. However, there are a limited number of publicly available accent dictionaries, and those dictionaries e.g. UniDic, do not contain many compound words, proper nouns, etc., which are required in a practical TTS system. In order to build a large scale accent dictionary that contains those words, the authors developed an accent estimation technique that predicts the accent of a word from its limited information, namely the surface (e.g. kanji) and the yomi (simplified phonetic information). It is experimentally shown that the technique can estimate accents with high accuracies, especially for some categories of words. The authors applied this technique to an existing large vocabulary Japanese dictionary NEologd, and obtained a large vocabulary Japanese accent dictionary. Many cases have been observed in which the use of this dictionary yields more appropriate phonetic information than UniDic.
* 7 pages, 2 figures. IEEE ICASSP 2020
Sim-to-Real Transfer for Robotic Manipulation with Tactile Sensory
Feb 28, 2021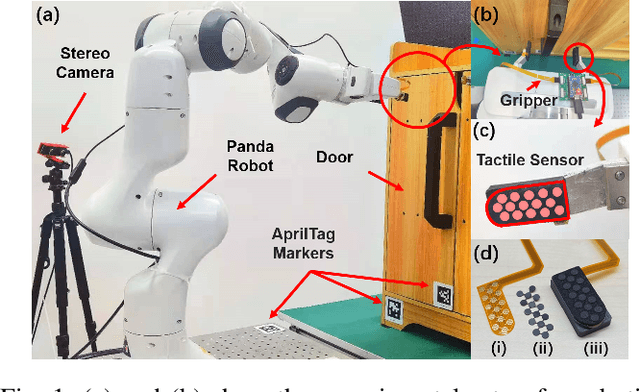
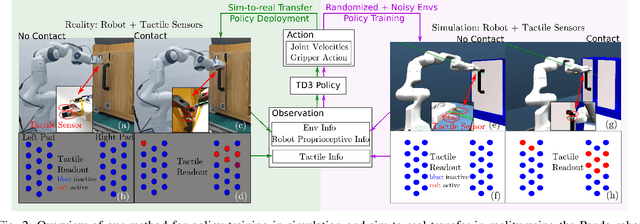
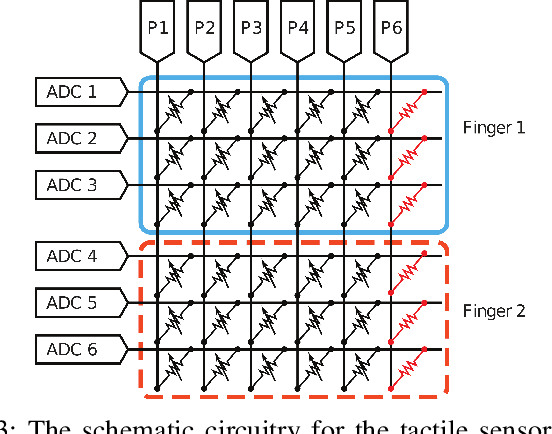
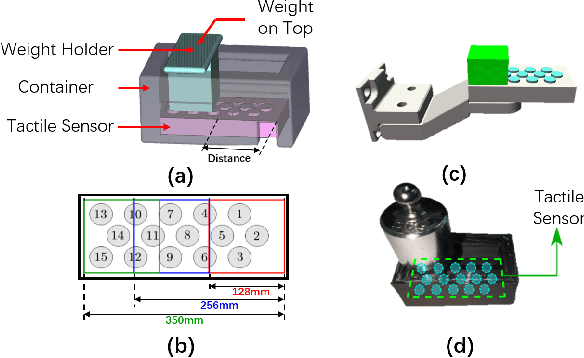
Reinforcement Learning (RL) methods have been widely applied for robotic manipulations via sim-to-real transfer, typically with proprioceptive and visual information. However, the incorporation of tactile sensing into RL for contact-rich tasks lacks investigation. In this paper, we model a tactile sensor in simulation and study the effects of its feedback in RL-based robotic control via a zero-shot sim-to-real approach with domain randomization. We demonstrate that learning and controlling with feedback from tactile sensor arrays at the gripper, both in simulation and reality, can enhance grasping stability, which leads to a significant improvement in robotic manipulation performance for a door opening task. In real-world experiments, the door open angle was increased by 45% on average for transferred policies with tactile sensing over those without it.
Unsupervised Degradation Representation Learning for Blind Super-Resolution
Apr 01, 2021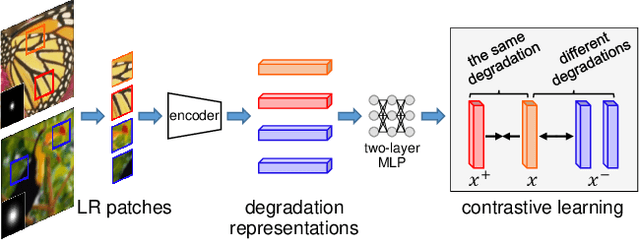

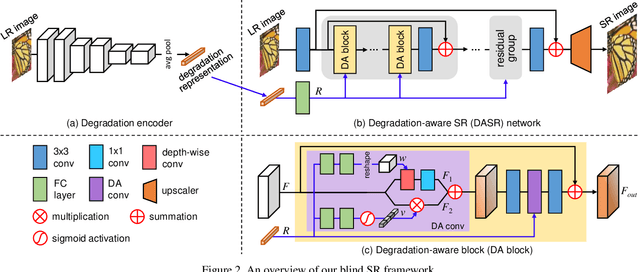
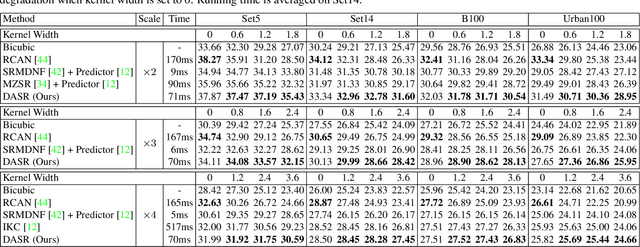
Most existing CNN-based super-resolution (SR) methods are developed based on an assumption that the degradation is fixed and known (e.g., bicubic downsampling). However, these methods suffer a severe performance drop when the real degradation is different from their assumption. To handle various unknown degradations in real-world applications, previous methods rely on degradation estimation to reconstruct the SR image. Nevertheless, degradation estimation methods are usually time-consuming and may lead to SR failure due to large estimation errors. In this paper, we propose an unsupervised degradation representation learning scheme for blind SR without explicit degradation estimation. Specifically, we learn abstract representations to distinguish various degradations in the representation space rather than explicit estimation in the pixel space. Moreover, we introduce a Degradation-Aware SR (DASR) network with flexible adaption to various degradations based on the learned representations. It is demonstrated that our degradation representation learning scheme can extract discriminative representations to obtain accurate degradation information. Experiments on both synthetic and real images show that our network achieves state-of-the-art performance for the blind SR task. Code is available at: https://github.com/LongguangWang/DASR.
Accurate Prediction of Free Solvation Energy of Organic Molecules via Graph Attention Network and Message Passing Neural Network from Pairwise Atomistic Interactions
Apr 15, 2021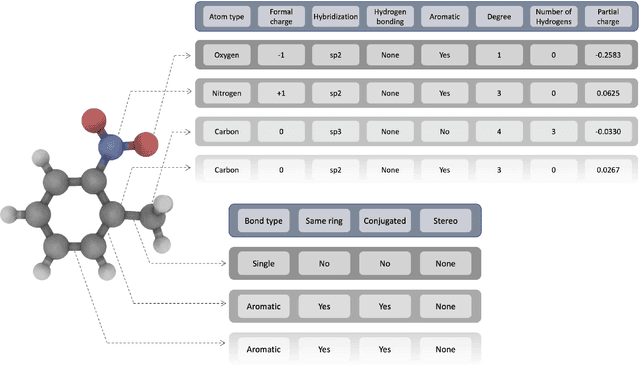
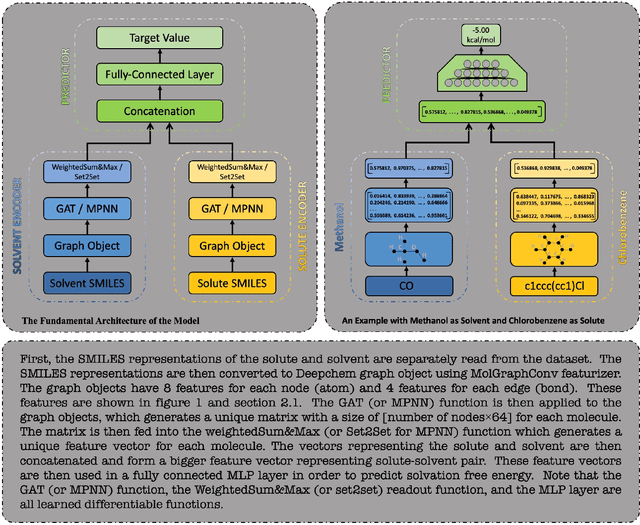
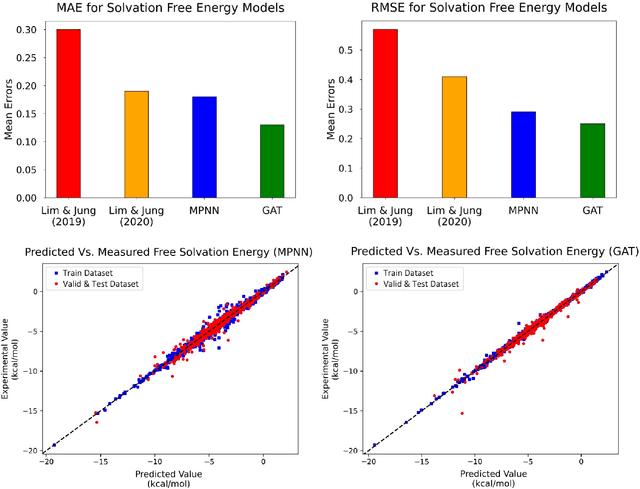
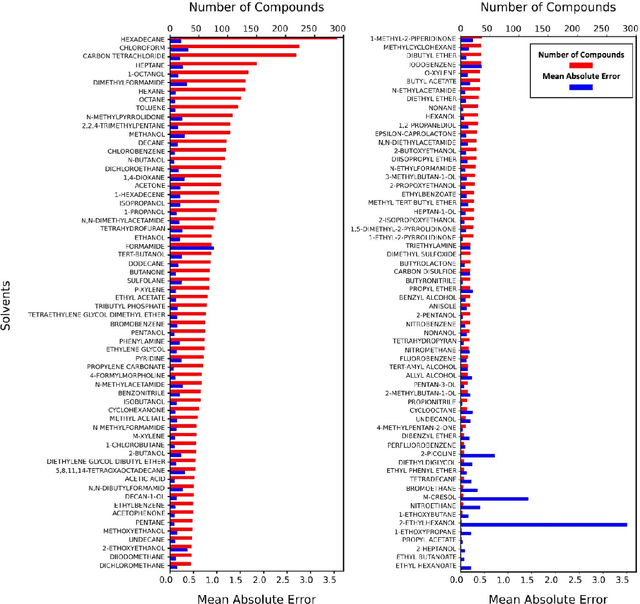
Deep learning based methods have been widely applied to predict various kinds of molecular properties in the pharmaceutical industry with increasingly more success. Solvation free energy is an important index in the field of organic synthesis, medicinal chemistry, drug delivery, and biological processes. However, accurate solvation free energy determination is a time-consuming experimental process. Furthermore, it could be useful to assess solvation free energy in the absence of a physical sample. In this study, we propose two novel models for the problem of free solvation energy predictions, based on the Graph Neural Network (GNN) architectures: Message Passing Neural Network (MPNN) and Graph Attention Network (GAT). GNNs are capable of summarizing the predictive information of a molecule as low-dimensional features directly from its graph structure without relying on an extensive amount of intra-molecular descriptors. As a result, these models are capable of making accurate predictions of the molecular properties without the time consuming process of running an experiment on each molecule. We show that our proposed models outperform all quantum mechanical and molecular dynamics methods in addition to existing alternative machine learning based approaches in the task of solvation free energy prediction. We believe such promising predictive models will be applicable to enhancing the efficiency of the screening of drug molecules and be a useful tool to promote the development of molecular pharmaceutics.
3D Human Pose and Shape Regression with Pyramidal Mesh Alignment Feedback Loop
Apr 01, 2021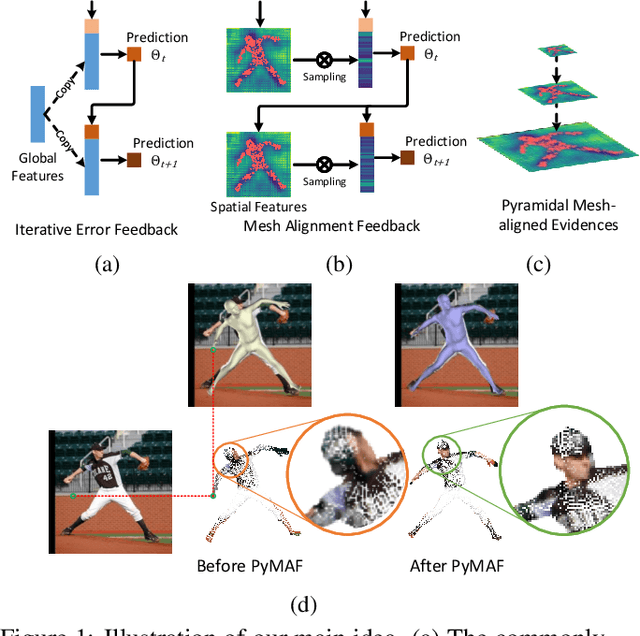
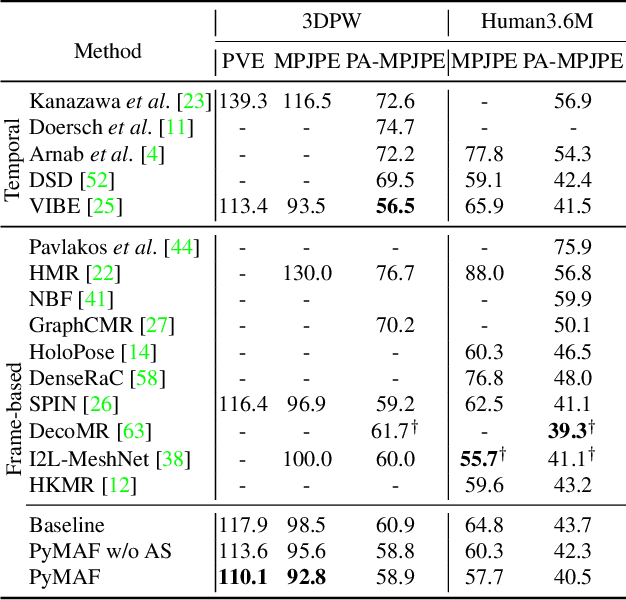
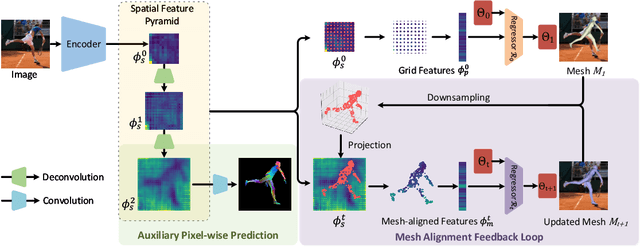
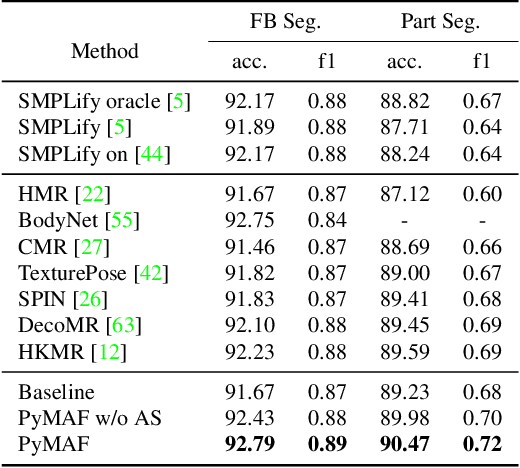
Regression-based methods have recently shown promising results in reconstructing human meshes from monocular images. By directly mapping from raw pixels to model parameters, these methods can produce parametric models in a feed-forward manner via neural networks. However, minor deviation in parameters may lead to noticeable misalignment between the estimated meshes and image evidences. To address this issue, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status in our deep regressor. In PyMAF, given the currently predicted parameters, mesh-aligned evidences will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To reduce noise and enhance the reliability of these evidences, an auxiliary pixel-wise supervision is imposed on the feature encoder, which provides mesh-image correspondence guidance for our network to preserve the most related information in spatial features. The efficacy of our approach is validated on several benchmarks, including Human3.6M, 3DPW, LSP, and COCO, where experimental results show that our approach consistently improves the mesh-image alignment of the reconstruction. Our code is publicly available at https://hongwenzhang.github.io/pymaf .