 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SportsCap: Monocular 3D Human Motion Capture and Fine-grained Understanding in Challenging Sports Videos
Apr 26, 2021
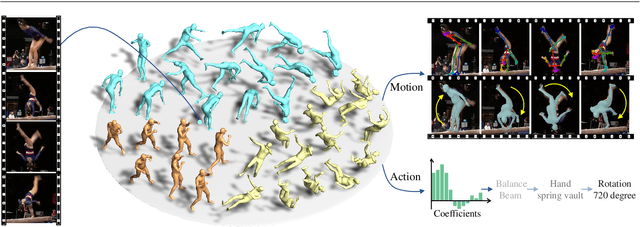
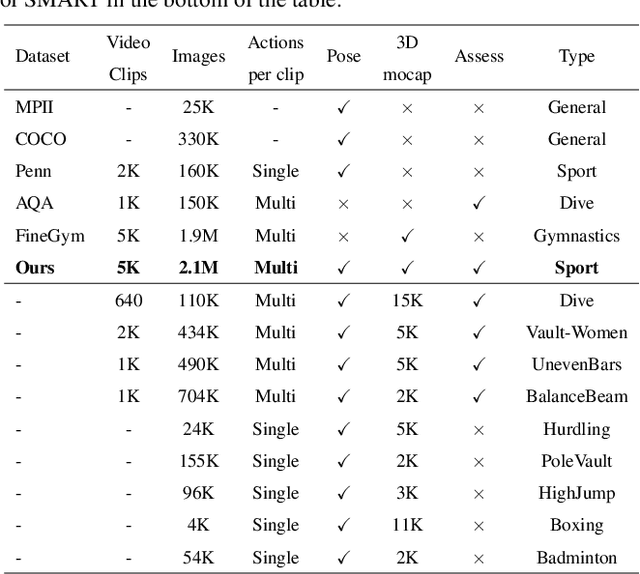
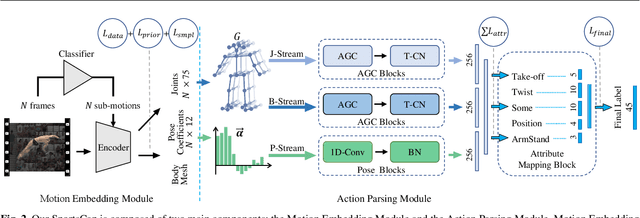
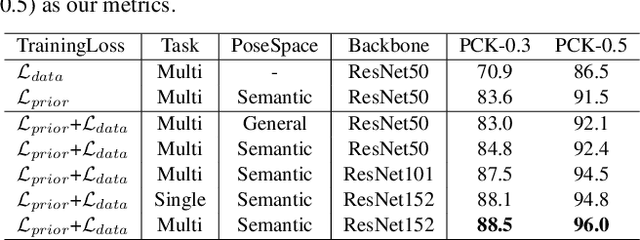
Markerless motion capture and understanding of professional non-daily human movements is an important yet unsolved task, which suffers from complex motion patterns and severe self-occlusion, especially for the monocular setting. In this paper, we propose SportsCap -- the first approach for simultaneously capturing 3D human motions and understanding fine-grained actions from monocular challenging sports video input. Our approach utilizes the semantic and temporally structured sub-motion prior in the embedding space for motion capture and understanding in a data-driven multi-task manner. To enable robust capture under complex motion patterns, we propose an effective motion embedding module to recover both the implicit motion embedding and explicit 3D motion details via a corresponding mapping function as well as a sub-motion classifier. Based on such hybrid motion information, we introduce a multi-stream spatial-temporal Graph Convolutional Network(ST-GCN) to predict the fine-grained semantic action attributes, and adopt a semantic attribute mapping block to assemble various correlated action attributes into a high-level action label for the overall detailed understanding of the whole sequence, so as to enable various applications like action assessment or motion scoring. Comprehensive experiments on both public and our proposed datasets show that with a challenging monocular sports video input, our novel approach not only significantly improves the accuracy of 3D human motion capture, but also recovers accurate fine-grained semantic action attributes.
Advanced Long-context End-to-end Speech Recognition Using Context-expanded Transformers
Apr 19, 2021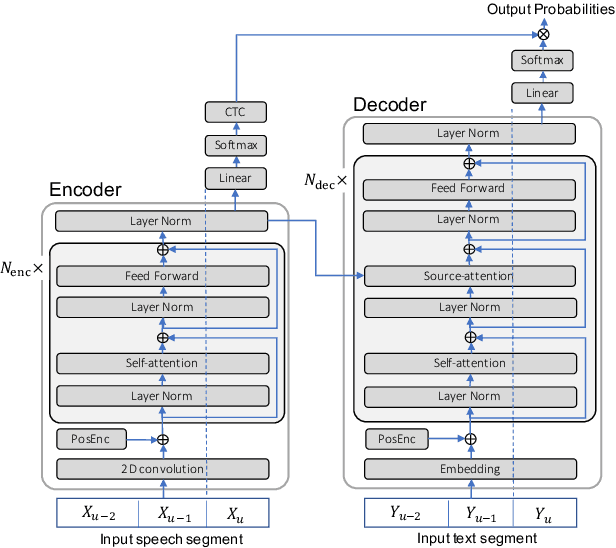
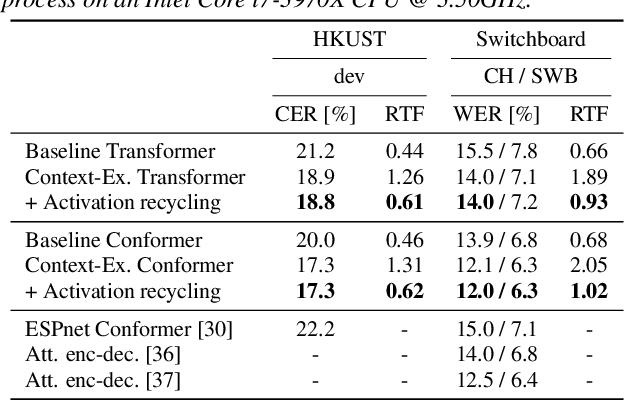
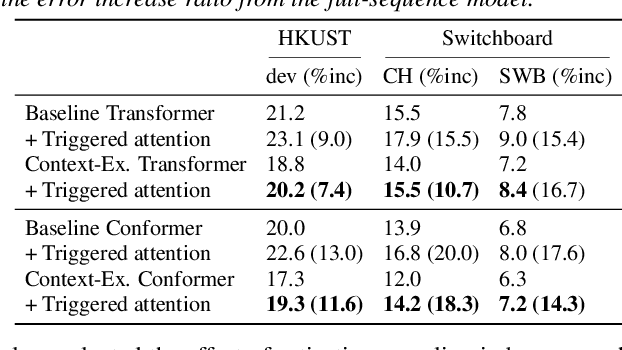
This paper addresses end-to-end automatic speech recognition (ASR) for long audio recordings such as lecture and conversational speeches. Most end-to-end ASR models are designed to recognize independent utterances, but contextual information (e.g., speaker or topic) over multiple utterances is known to be useful for ASR. In our prior work, we proposed a context-expanded Transformer that accepts multiple consecutive utterances at the same time and predicts an output sequence for the last utterance, achieving 5-15% relative error reduction from utterance-based baselines in lecture and conversational ASR benchmarks. Although the results have shown remarkable performance gain, there is still potential to further improve the model architecture and the decoding process. In this paper, we extend our prior work by (1) introducing the Conformer architecture to further improve the accuracy, (2) accelerating the decoding process with a novel activation recycling technique, and (3) enabling streaming decoding with triggered attention. We demonstrate that the extended Transformer provides state-of-the-art end-to-end ASR performance, obtaining a 17.3% character error rate for the HKUST dataset and 12.0%/6.3% word error rates for the Switchboard-300 Eval2000 CallHome/Switchboard test sets. The new decoding method reduces decoding time by more than 50% and further enables streaming ASR with limited accuracy degradation.
Exploiting Playbacks in Unsupervised Domain Adaptation for 3D Object Detection
Mar 26, 2021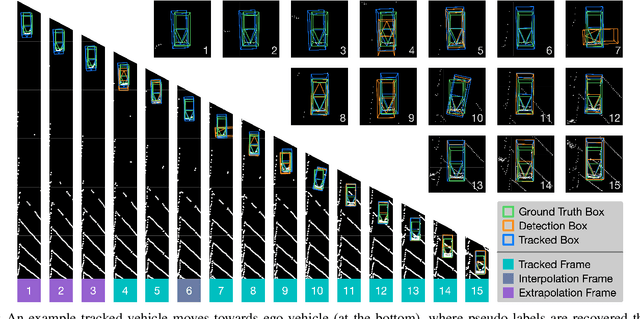


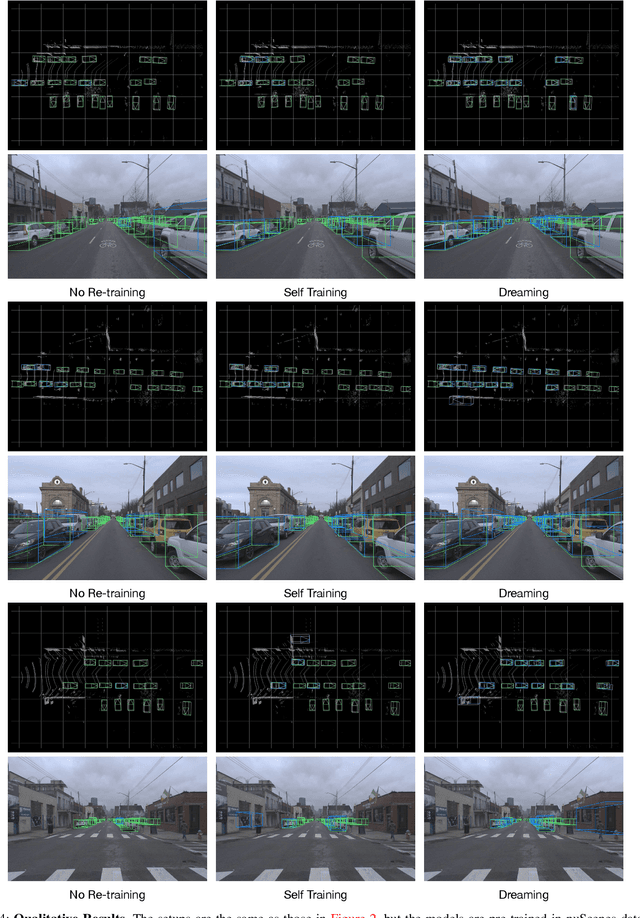
Self-driving cars must detect other vehicles and pedestrians in 3D to plan safe routes and avoid collisions. State-of-the-art 3D object detectors, based on deep learning, have shown promising accuracy but are prone to over-fit to domain idiosyncrasies, making them fail in new environments -- a serious problem if autonomous vehicles are meant to operate freely. In this paper, we propose a novel learning approach that drastically reduces this gap by fine-tuning the detector on pseudo-labels in the target domain, which our method generates while the vehicle is parked, based on replays of previously recorded driving sequences. In these replays, objects are tracked over time, and detections are interpolated and extrapolated -- crucially, leveraging future information to catch hard cases. We show, on five autonomous driving datasets, that fine-tuning the object detector on these pseudo-labels substantially reduces the domain gap to new driving environments, yielding drastic improvements in accuracy and detection reliability.
Unified Spatio-Temporal Modeling for Traffic Forecasting using Graph Neural Network
Apr 26, 2021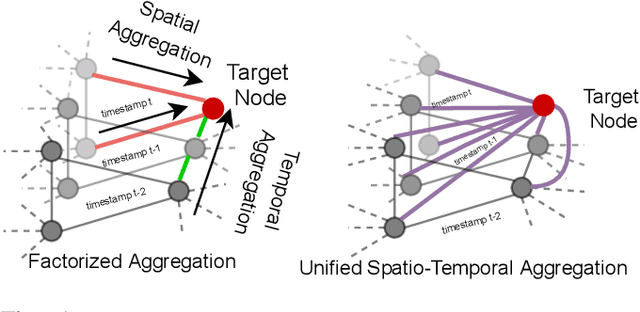
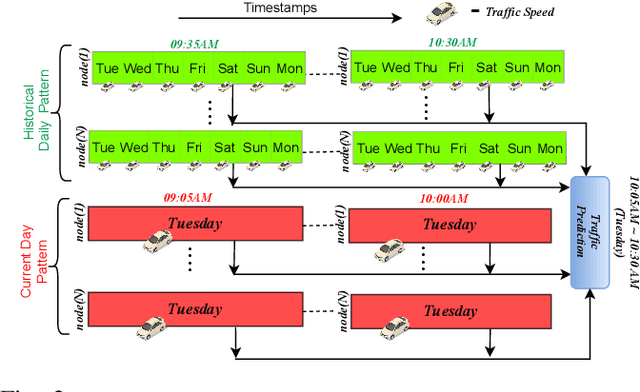
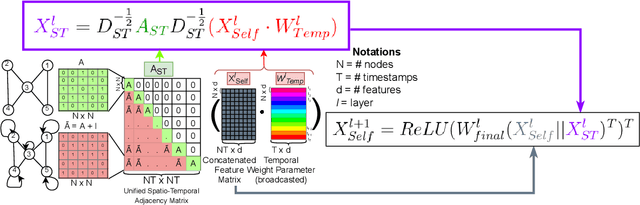

Research in deep learning models to forecast traffic intensities has gained great attention in recent years due to their capability to capture the complex spatio-temporal relationships within the traffic data. However, most state-of-the-art approaches have designed spatial-only (e.g. Graph Neural Networks) and temporal-only (e.g. Recurrent Neural Networks) modules to separately extract spatial and temporal features. However, we argue that it is less effective to extract the complex spatio-temporal relationship with such factorized modules. Besides, most existing works predict the traffic intensity of a particular time interval only based on the traffic data of the previous one hour of that day. And thereby ignores the repetitive daily/weekly pattern that may exist in the last hour of data. Therefore, we propose a Unified Spatio-Temporal Graph Convolution Network (USTGCN) for traffic forecasting that performs both spatial and temporal aggregation through direct information propagation across different timestamp nodes with the help of spectral graph convolution on a spatio-temporal graph. Furthermore, it captures historical daily patterns in previous days and current-day patterns in current-day traffic data. Finally, we validate our work's effectiveness through experimental analysis, which shows that our model USTGCN can outperform state-of-the-art performances in three popular benchmark datasets from the Performance Measurement System (PeMS). Moreover, the training time is reduced significantly with our proposed USTGCN model.
Single-view robot pose and joint angle estimation via render & compare
Apr 19, 2021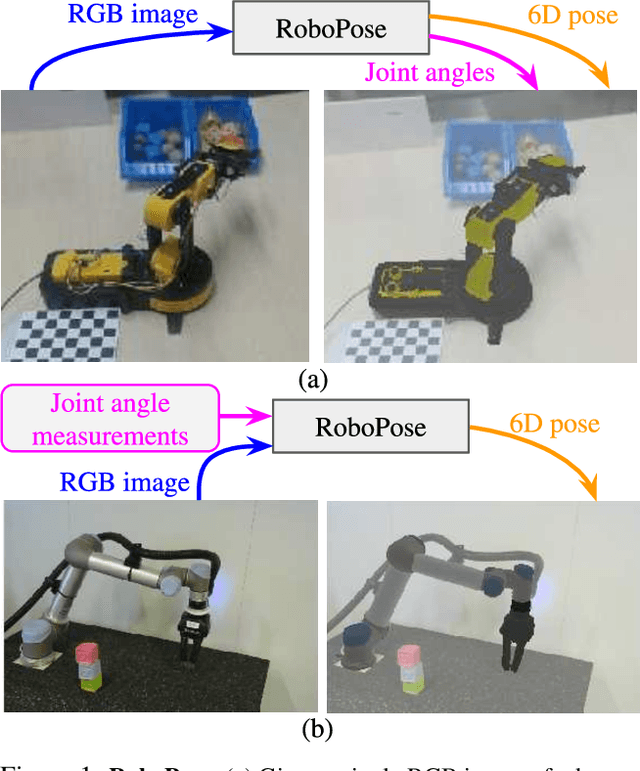
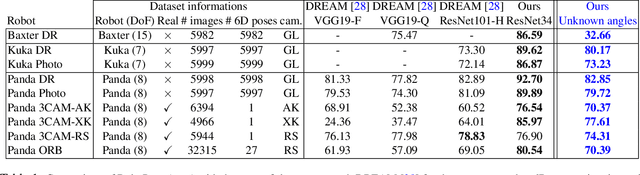
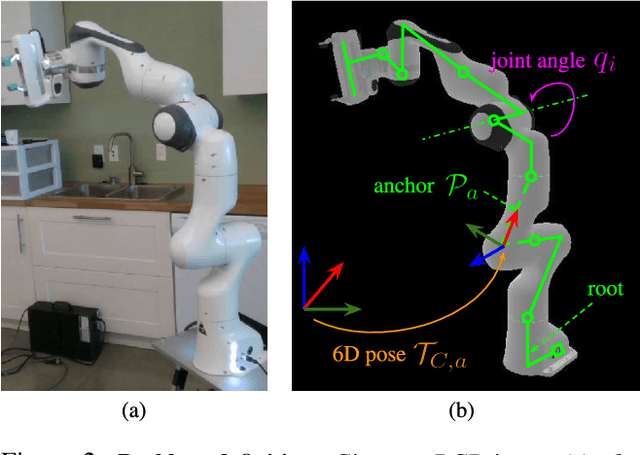
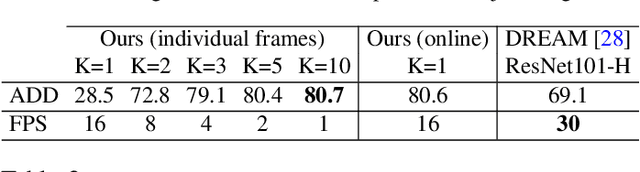
We introduce RoboPose, a method to estimate the joint angles and the 6D camera-to-robot pose of a known articulated robot from a single RGB image. This is an important problem to grant mobile and itinerant autonomous systems the ability to interact with other robots using only visual information in non-instrumented environments, especially in the context of collaborative robotics. It is also challenging because robots have many degrees of freedom and an infinite space of possible configurations that often result in self-occlusions and depth ambiguities when imaged by a single camera. The contributions of this work are three-fold. First, we introduce a new render & compare approach for estimating the 6D pose and joint angles of an articulated robot that can be trained from synthetic data, generalizes to new unseen robot configurations at test time, and can be applied to a variety of robots. Second, we experimentally demonstrate the importance of the robot parametrization for the iterative pose updates and design a parametrization strategy that is independent of the robot structure. Finally, we show experimental results on existing benchmark datasets for four different robots and demonstrate that our method significantly outperforms the state of the art. Code and pre-trained models are available on the project webpage https://www.di.ens.fr/willow/research/robopose/.
PCAL: A Privacy-preserving Intelligent Credit Risk Modeling Framework Based on Adversarial Learning
Oct 06, 2020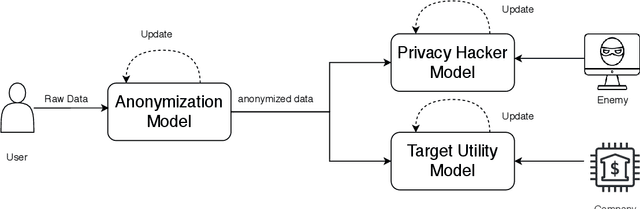
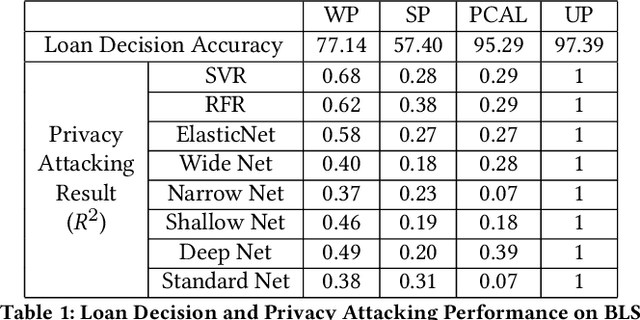
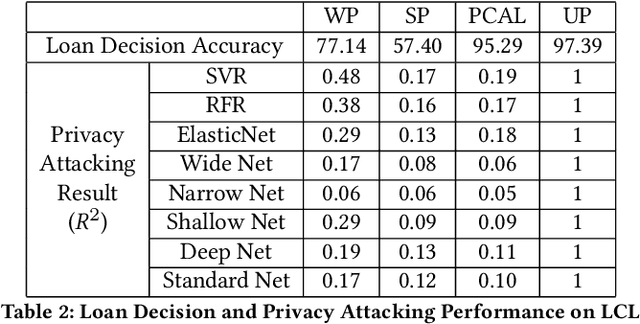
Credit risk modeling has permeated our everyday life. Most banks and financial companies use this technique to model their clients' trustworthiness. While machine learning is increasingly used in this field, the resulting large-scale collection of user private information has reinvigorated the privacy debate, considering dozens of data breach incidents every year caused by unauthorized hackers, and (potentially even more) information misuse/abuse by authorized parties. To address those critical concerns, this paper proposes a framework of Privacy-preserving Credit risk modeling based on Adversarial Learning (PCAL). PCAL aims to mask the private information inside the original dataset, while maintaining the important utility information for the target prediction task performance, by (iteratively) weighing between a privacy-risk loss and a utility-oriented loss. PCAL is compared against off-the-shelf options in terms of both utility and privacy protection. Results indicate that PCAL can learn an effective, privacy-free representation from user data, providing a solid foundation towards privacy-preserving machine learning for credit risk analysis.
Spatial Context-Aware Self-Attention Model For Multi-Organ Segmentation
Dec 16, 2020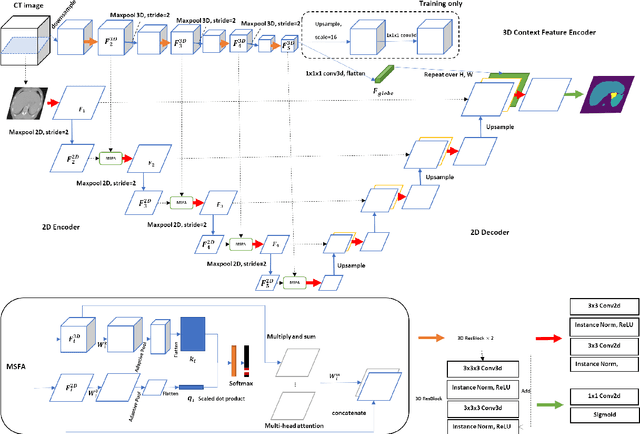

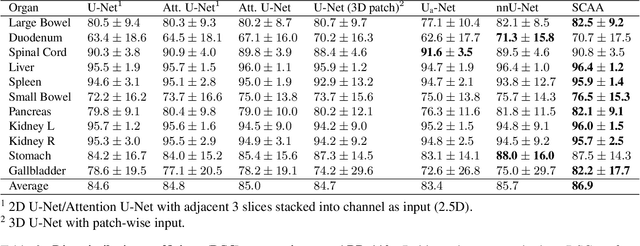
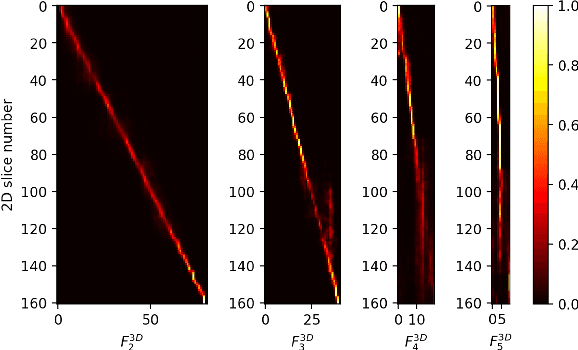
Multi-organ segmentation is one of most successful applications of deep learning in medical image analysis. Deep convolutional neural nets (CNNs) have shown great promise in achieving clinically applicable image segmentation performance on CT or MRI images. State-of-the-art CNN segmentation models apply either 2D or 3D convolutions on input images, with pros and cons associated with each method: 2D convolution is fast, less memory-intensive but inadequate for extracting 3D contextual information from volumetric images, while the opposite is true for 3D convolution. To fit a 3D CNN model on CT or MRI images on commodity GPUs, one usually has to either downsample input images or use cropped local regions as inputs, which limits the utility of 3D models for multi-organ segmentation. In this work, we propose a new framework for combining 3D and 2D models, in which the segmentation is realized through high-resolution 2D convolutions, but guided by spatial contextual information extracted from a low-resolution 3D model. We implement a self-attention mechanism to control which 3D features should be used to guide 2D segmentation. Our model is light on memory usage but fully equipped to take 3D contextual information into account. Experiments on multiple organ segmentation datasets demonstrate that by taking advantage of both 2D and 3D models, our method is consistently outperforms existing 2D and 3D models in organ segmentation accuracy, while being able to directly take raw whole-volume image data as inputs.
PWCLO-Net: Deep LiDAR Odometry in 3D Point Clouds Using Hierarchical Embedding Mask Optimization
Dec 02, 2020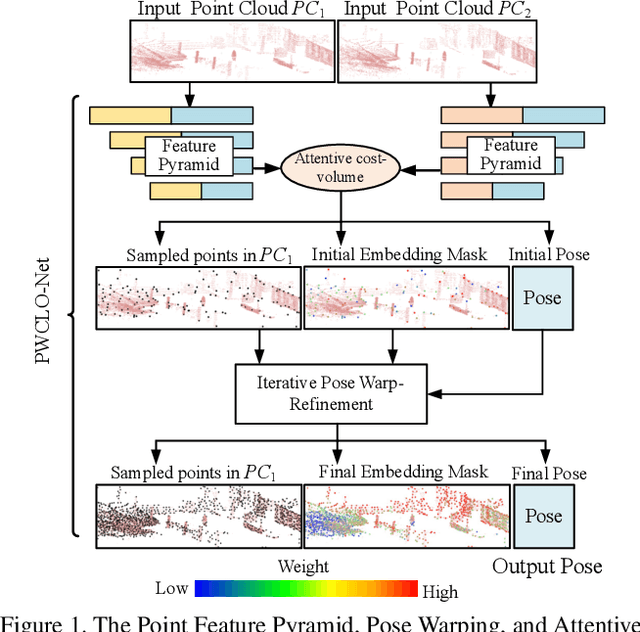
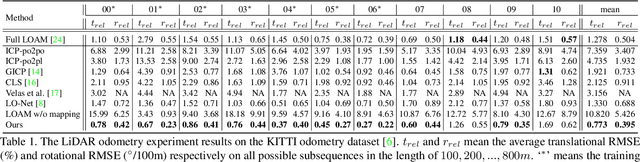
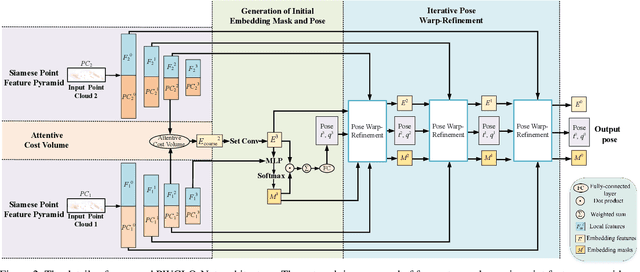

A novel 3D point cloud learning model for deep LiDAR odometry, named PWCLO-Net, using hierarchical embedding mask optimization is proposed in this paper. In this model, the Pyramid, Warping, and Cost volume (PWC) structure for the LiDAR Odometry task is built to hierarchically refine the estimated pose in a coarse-to-fine approach. An attentive cost volume is built to associate two point clouds and obtain the embedding motion information. Then, a novel trainable embedding mask is proposed to weight the cost volume of all points to the overall pose information and filter outlier points. The estimated current pose is used to warp the first point cloud to bridge the distance to the second point cloud, and then the cost volume of the residual motion is built. At the same time, the embedding mask is optimized hierarchically from coarse to fine to obtain more accurate filtering information for pose refinement. The pose warp-refinement process is repeatedly used to make the pose estimation more robust for outliers. The superior performance and effectiveness of our LiDAR odometry model are demonstrated on the KITTI odometry dataset. Our method outperforms all recent learning-based methods and outperforms the geometry-based approach, LOAM with mapping optimization, on most sequences of the KITTI odometry dataset.
Collaborative SLAM based on Wifi Fingerprint Similarity and Motion Information
Nov 30, 2019
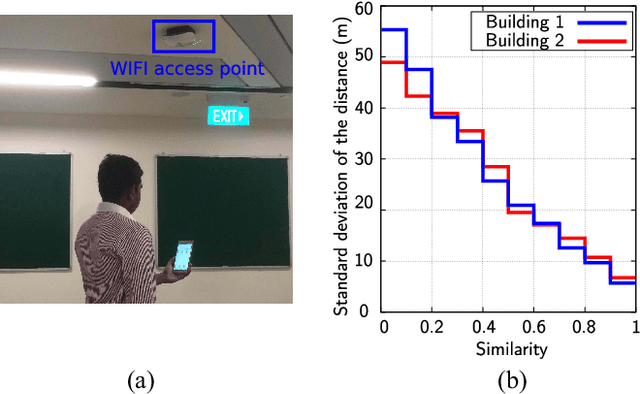
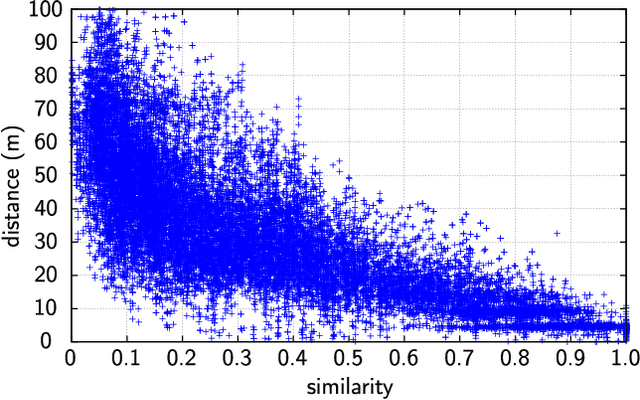
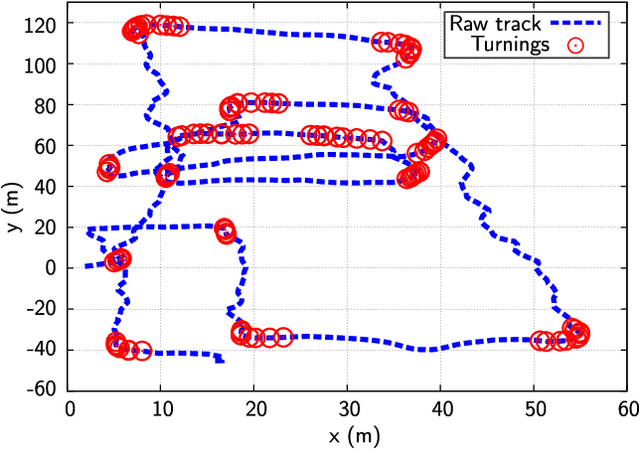
Simultaneous localization and mapping (SLAM) has been extensively researched in past years particularly with regard to range-based or visual-based sensors. Instead of deploying dedicated devices that use visual features, it is more pragmatic to exploit the radio features to achieve this task, due to their ubiquitous nature and the widespread deployment of Wi-Fi wireless network. This paper presents a novel approach for collaborative simultaneous localization and radio fingerprint mapping (C-SLAM-RF) in large unknown indoor environments. The proposed system uses received signal strengths (RSS) from Wi-Fi access points (AP) in the existing infrastructure and pedestrian dead reckoning (PDR) from a smart phone, without a prior knowledge about map or distribution of AP in the environment. We claim a loop closure based on the similarity of the two radio fingerprints. To further improve the performance, we incorporate the turning motion and assign a small uncertainty value to a loop closure if a matched turning is identified. The experiment was done in an area of 130 meters by 70 meters and the results show that our proposed system is capable of estimating the tracks of four users with an accuracy of 0.6 meters with Tango-based PDR and 4.76 meters with a step counter-based PDR.
Principled network extraction from images
Dec 23, 2020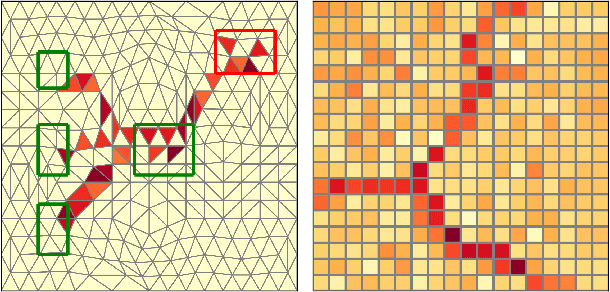
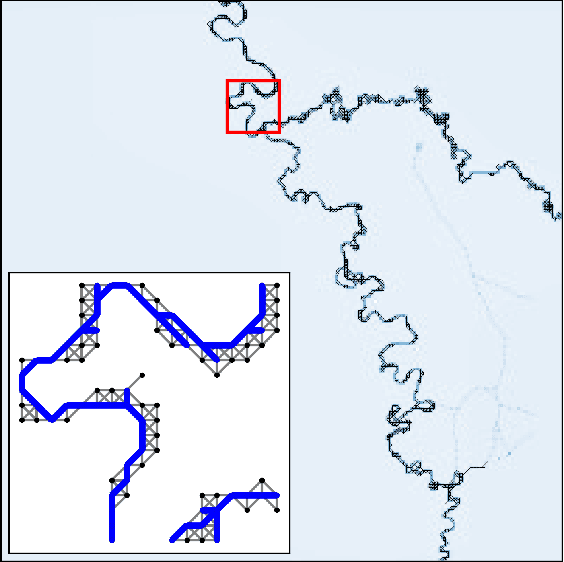
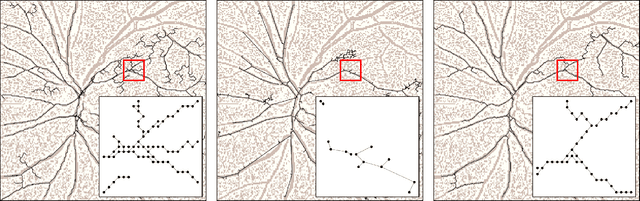
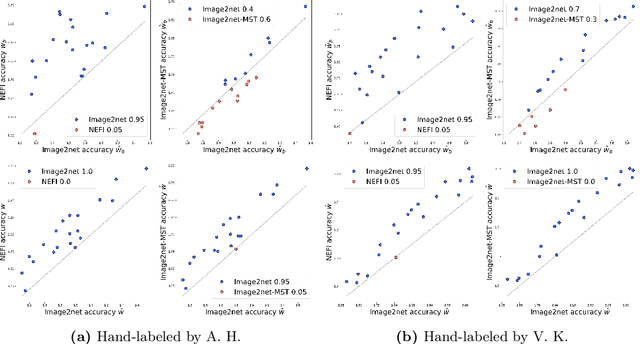
Images of natural systems may represent patterns of network-like structure, which could reveal important information about the topological properties of the underlying subject. However, the image itself does not automatically provide a formal definition of a network in terms of sets of nodes and edges. Instead, this information should be suitably extracted from the raw image data. Motivated by this, we present a principled model to extract network topologies from images that is scalable and efficient. We map this goal into solving a routing optimization problem where the solution is a network that minimizes an energy function which can be interpreted in terms of an operational and infrastructural cost. Our method relies on recent results from optimal transport theory and is a principled alternative to standard image-processing techniques that are based on heuristics. We test our model on real images of the retinal vascular system, slime mold and river networks and compare with routines combining image-processing techniques. Results are tested in terms of a similarity measure related to the amount of information preserved in the extraction. We find that our model finds networks from retina vascular network images that are more similar to hand-labeled ones, while also giving high performance in extracting networks from images of rivers and slime mold for which there is no ground truth available. While there is no unique method that fits all the images the best, our approach performs consistently across datasets, its algorithmic implementation is efficient and can be fully automatized to be run on several datasets with little supervision.