 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Where am I? SLAM for Mobile Machines on A Smart Working Site
Nov 05, 2020

The current optimization approaches of construction machinery are mainly based on internal sensors. However, the decision of a reasonable strategy is not only determined by its intrinsic signals, but also very strongly by environmental information, especially the terrain. Due to the dynamically changing of the construction site and the consequent absence of a high definition map, the Simultaneous Localization and Mapping (SLAM) offering the terrain information for construction machines is still challenging. Current SLAM technologies proposed for mobile machines are strongly dependent on costly or computationally expensive sensors, such as RTK GPS and cameras, so that commercial use is rare. In this study, we proposed an affordable SLAM method to create a multi-layer gird map for the construction site so that the machine can have the environmental information and be optimized accordingly. Concretely, after the machine passes by, we can get the local information and record it. Combining with positioning technology, we then create a map of the interesting places of the construction site. As a result of our research gathered from Gazebo, we showed that a suitable layout is the combination of 1 IMU and 2 differential GPS antennas using the unscented Kalman filter, which keeps the average distance error lower than 2m and the mapping error lower than 1.3% in the harsh environment. As an outlook, our SLAM technology provides the cornerstone to activate many efficiency improvement approaches.
A Sheaf and Topology Approach to Generating Local Branch Numbers in Digital Images
Dec 03, 2020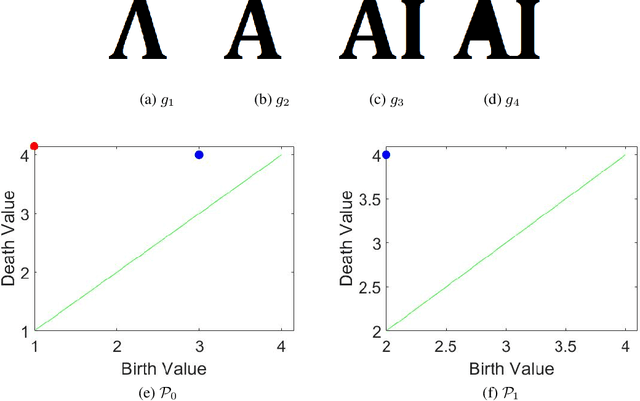
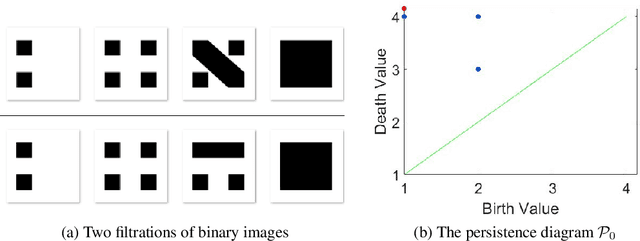
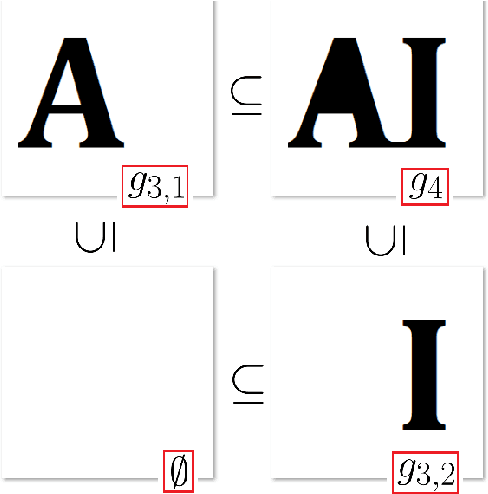

This paper concerns a theoretical approach that combines topological data analysis (TDA) and sheaf theory. Topological data analysis, a rising field in mathematics and computer science, concerns the shape of the data and has been proven effective in many scientific disciplines. Sheaf theory, a mathematics subject in algebraic geometry, provides a framework for describing the local consistency in geometric objects. Persistent homology (PH) is one of the main driving forces in TDA, and the idea is to track changes of geometric objects at different scales. The persistence diagram (PD) summarizes the information of PH in the form of a multi-set. While PD provides useful information about the underlying objects, it lacks fine relations about the local consistency of specific pairs of generators in PD, such as the merging relation between two connected components in the PH. The sheaf structure provides a novel point of view for describing the merging relation of local objects in PH. It is the goal of this paper to establish a theoretic framework that utilizes the sheaf theory to uncover finer information from the PH. We also show that the proposed theory can be applied to identify the branch numbers of local objects in digital images.
Active Reinforcement Learning: Observing Rewards at a Cost
Nov 13, 2020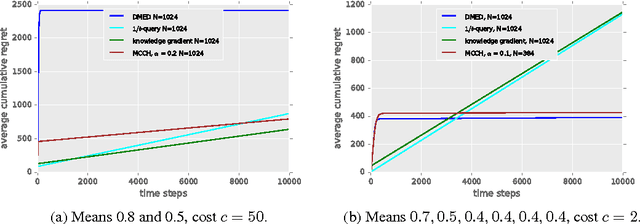
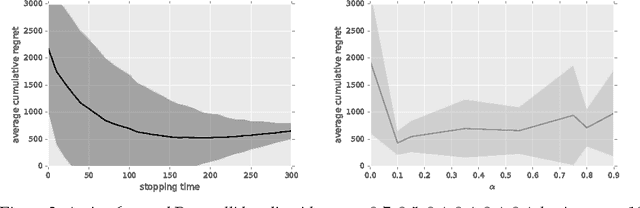
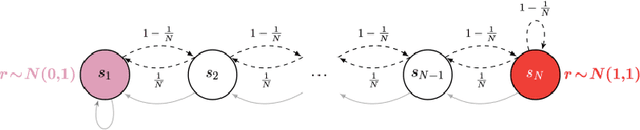
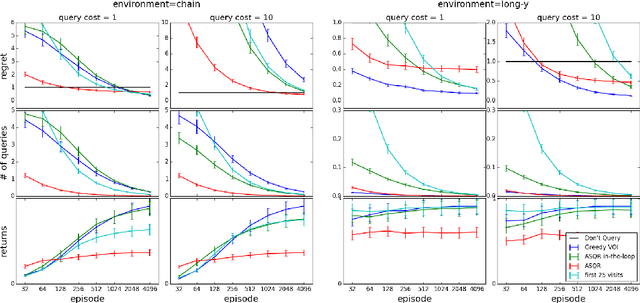
Active reinforcement learning (ARL) is a variant on reinforcement learning where the agent does not observe the reward unless it chooses to pay a query cost c > 0. The central question of ARL is how to quantify the long-term value of reward information. Even in multi-armed bandits, computing the value of this information is intractable and we have to rely on heuristics. We propose and evaluate several heuristic approaches for ARL in multi-armed bandits and (tabular) Markov decision processes, and discuss and illustrate some challenging aspects of the ARL problem.
Deep Learning with Heterogeneous Graph Embeddings for Mortality Prediction from Electronic Health Records
Dec 28, 2020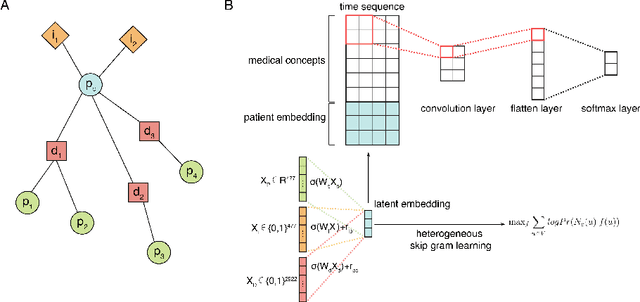
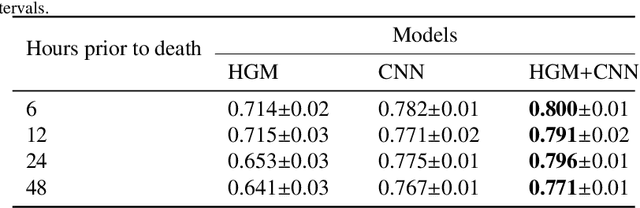
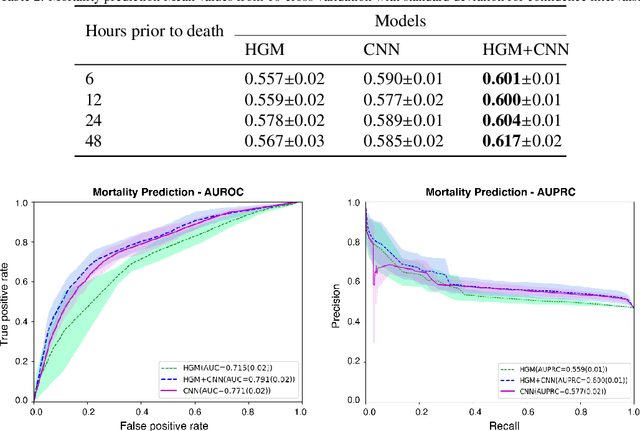
Computational prediction of in-hospital mortality in the setting of an intensive care unit can help clinical practitioners to guide care and make early decisions for interventions. As clinical data are complex and varied in their structure and components, continued innovation of modeling strategies is required to identify architectures that can best model outcomes. In this work, we train a Heterogeneous Graph Model (HGM) on Electronic Health Record data and use the resulting embedding vector as additional information added to a Convolutional Neural Network (CNN) model for predicting in-hospital mortality. We show that the additional information provided by including time as a vector in the embedding captures the relationships between medical concepts, lab tests, and diagnoses, which enhances predictive performance. We find that adding HGM to a CNN model increases the mortality prediction accuracy up to 4\%. This framework serves as a foundation for future experiments involving different EHR data types on important healthcare prediction tasks.
No Intruder, no Validity: Evaluation Criteria for Privacy-Preserving Text Anonymization
Mar 16, 2021
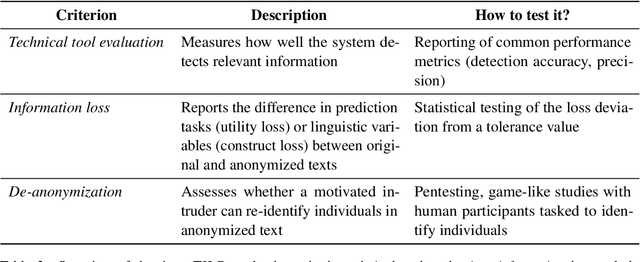
For sensitive text data to be shared among NLP researchers and practitioners, shared documents need to comply with data protection and privacy laws. There is hence a growing interest in automated approaches for text anonymization. However, measuring such methods' performance is challenging: missing a single identifying attribute can reveal an individual's identity. In this paper, we draw attention to this problem and argue that researchers and practitioners developing automated text anonymization systems should carefully assess whether their evaluation methods truly reflect the system's ability to protect individuals from being re-identified. We then propose TILD, a set of evaluation criteria that comprises an anonymization method's technical performance, the information loss resulting from its anonymization, and the human ability to de-anonymize redacted documents. These criteria may facilitate progress towards a standardized way for measuring anonymization performance.
Set-Theoretic Learning for Detection in Cell-Less C-RAN Systems
Mar 21, 2021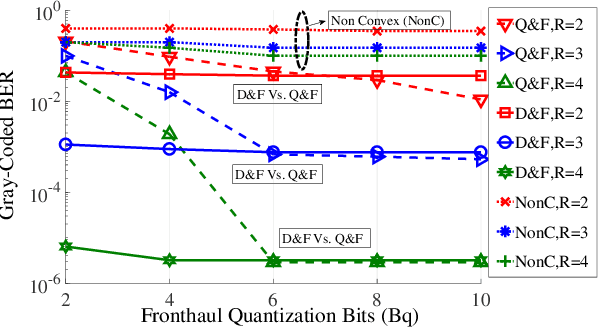
Cloud-radio access network (C-RAN) can enable cell-less operation by connecting distributed remote radio heads (RRHs) via fronthaul links to a powerful central unit. In conventional C-RAN, baseband signals are forwarded after quantization/ compression to the central unit for centralized processing to keep the complexity of the RRHs low. However, the limited capacity of the fronthaul is thought to be a significant bottleneck in the ability of C-RAN to support large systems (e.g. massive machine-type communications (mMTC)). Therefore, in contrast to the conventional C-RAN, we propose a learning-based system in which the detection is performed locally at each RRH and only the likelihood information is conveyed to the CU. To this end, we develop a general set-theoretic learningmethod to estimate likelihood functions. The method can be used to extend existing detection methods to the C-RAN setting.
Incorporating Connections Beyond Knowledge Embeddings: A Plug-and-Play Module to Enhance Commonsense Reasoning in Machine Reading Comprehension
Mar 26, 2021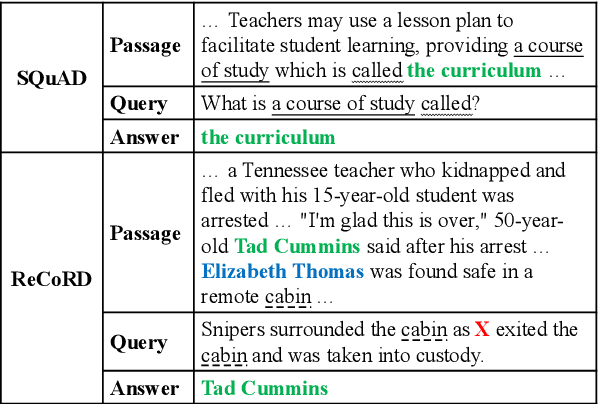
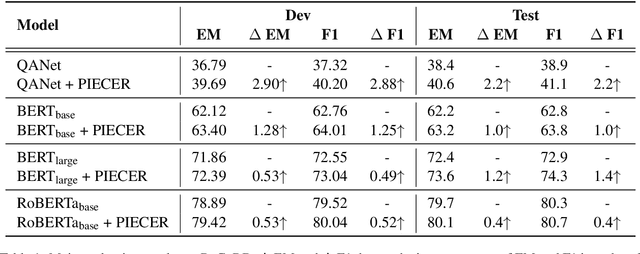
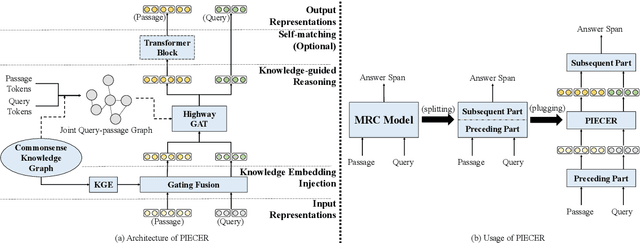

Conventional Machine Reading Comprehension (MRC) has been well-addressed by pattern matching, but the ability of commonsense reasoning remains a gap between humans and machines. Previous methods tackle this problem by enriching word representations via pre-trained Knowledge Graph Embeddings (KGE). However, they make limited use of a large number of connections between nodes in Knowledge Graphs (KG), which could be pivotal cues to build the commonsense reasoning chains. In this paper, we propose a Plug-and-play module to IncorporatE Connection information for commonsEnse Reasoning (PIECER). Beyond enriching word representations with knowledge embeddings, PIECER constructs a joint query-passage graph to explicitly guide commonsense reasoning by the knowledge-oriented connections between words. Further, PIECER has high generalizability since it can be plugged into suitable positions in any MRC model. Experimental results on ReCoRD, a large-scale public MRC dataset requiring commonsense reasoning, show that PIECER introduces stable performance improvements for four representative base MRC models, especially in low-resource settings.
L3DAS21 Challenge: Machine Learning for 3D Audio Signal Processing
Apr 12, 2021
The L3DAS21 Challenge is aimed at encouraging and fostering collaborative research on machine learning for 3D audio signal processing, with particular focus on 3D speech enhancement (SE) and 3D sound localization and detection (SELD). Alongside with the challenge, we release the L3DAS21 dataset, a 65 hours 3D audio corpus, accompanied with a Python API that facilitates the data usage and results submission stage. Usually, machine learning approaches to 3D audio tasks are based on single-perspective Ambisonics recordings or on arrays of single-capsule microphones. We propose, instead, a novel multichannel audio configuration based multiple-source and multiple-perspective Ambisonics recordings, performed with an array of two first-order Ambisonics microphones. To the best of our knowledge, it is the first time that a dual-mic Ambisonics configuration is used for these tasks. We provide baseline models and results for both tasks, obtained with state-of-the-art architectures: FaSNet for SE and SELDNet for SELD. This report is aimed at providing all needed information to participate in the L3DAS21 Challenge, illustrating the details of the L3DAS21 dataset, the challenge tasks and the baseline models.
Independent Sign Language Recognition with 3D Body, Hands, and Face Reconstruction
Nov 24, 2020
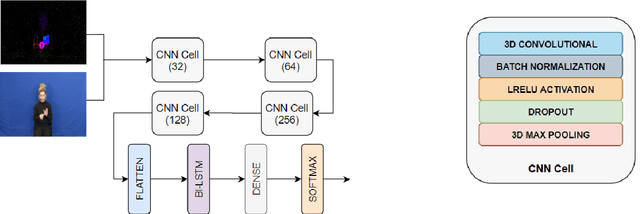

Independent Sign Language Recognition is a complex visual recognition problem that combines several challenging tasks of Computer Vision due to the necessity to exploit and fuse information from hand gestures, body features and facial expressions. While many state-of-the-art works have managed to deeply elaborate on these features independently, to the best of our knowledge, no work has adequately combined all three information channels to efficiently recognize Sign Language. In this work, we employ SMPL-X, a contemporary parametric model that enables joint extraction of 3D body shape, face and hands information from a single image. We use this holistic 3D reconstruction for SLR, demonstrating that it leads to higher accuracy than recognition from raw RGB images and their optical flow fed into the state-of-the-art I3D-type network for 3D action recognition and from 2D Openpose skeletons fed into a Recurrent Neural Network. Finally, a set of experiments on the body, face and hand features showed that neglecting any of these, significantly reduces the classification accuracy, proving the importance of jointly modeling body shape, facial expression and hand pose for Sign Language Recognition.
Model-aided Deep Reinforcement Learning for Sample-efficient UAV Trajectory Design in IoT Networks
May 03, 2021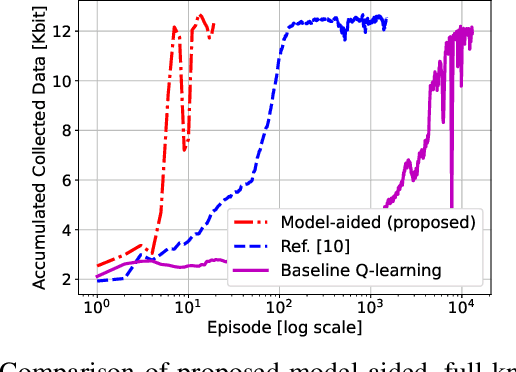
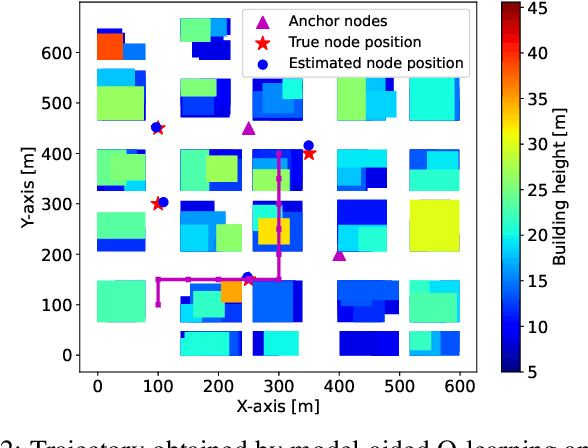
Deep Reinforcement Learning (DRL) is gaining attention as a potential approach to design trajectories for autonomous unmanned aerial vehicles (UAV) used as flying access points in the context of cellular or Internet of Things (IoT) connectivity. DRL solutions offer the advantage of on-the-go learning hence relying on very little prior contextual information. A corresponding drawback however lies in the need for many learning episodes which severely restricts the applicability of such approach in real-world time- and energy-constrained missions. Here, we propose a model-aided deep Q-learning approach that, in contrast to previous work, considerably reduces the need for extensive training data samples, while still achieving the overarching goal of DRL, i.e to guide a battery-limited UAV towards an efficient data harvesting trajectory, without prior knowledge of wireless channel characteristics and limited knowledge of wireless node locations. The key idea consists in using a small subset of nodes as anchors (i.e. with known location) and learning a model of the propagation environment while implicitly estimating the positions of regular nodes. Interaction with the model allows us to train a deep Q-network (DQN) to approximate the optimal UAV control policy. We show that in comparison with standard DRL approaches, the proposed model-aided approach requires at least one order of magnitude less training data samples to reach identical data collection performance, hence offering a first step towards making DRL a viable solution to the problem.