 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Coordinated Aerial-Ground Robot Exploration via Monte-Carlo View Quality Rendering
Nov 10, 2020
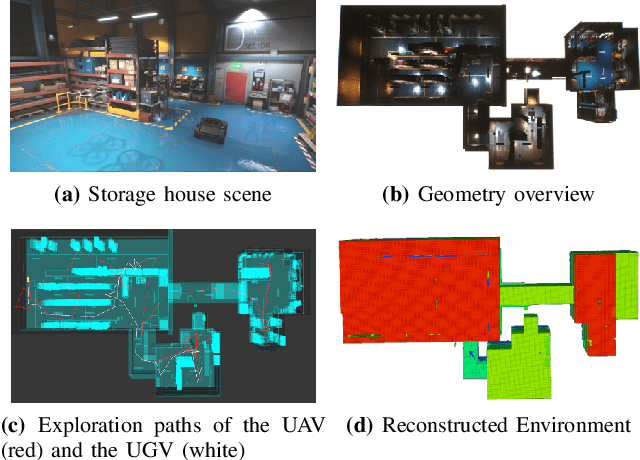
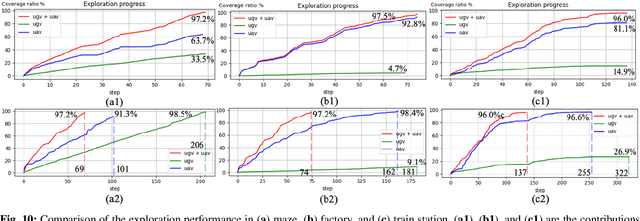
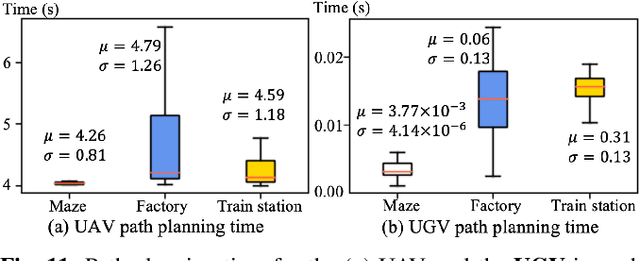

We present a framework for a ground-aerial robotic team to explore large, unstructured, and unknown environments. In such exploration problems, the effectiveness of existing exploration-boosting heuristics often scales poorly with the environments' size and complexity. This work proposes a novel framework combining incremental frontier distribution, goal selection with Monte-Carlo view quality rendering, and an automatic-differentiable information gain measure to improve exploration efficiency. Simulated with multiple complex environments, we demonstrate that the proposed method effectively utilizes collaborative aerial and ground robots, consistently guides agents to informative viewpoints, improves exploration paths' information gain, and reduces planning time.
Gaussian Process Based Message Filtering for Robust Multi-Agent Cooperation in the Presence of Adversarial Communication
Dec 01, 2020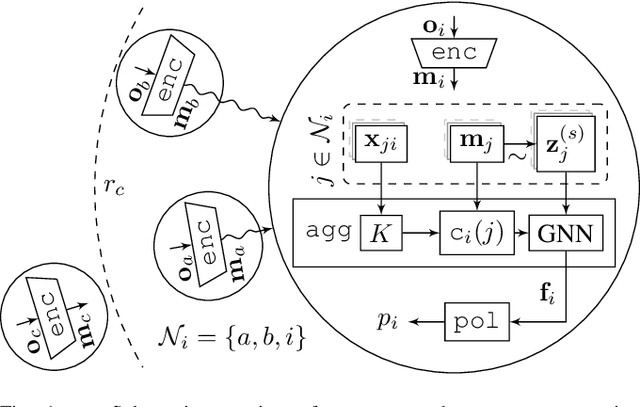
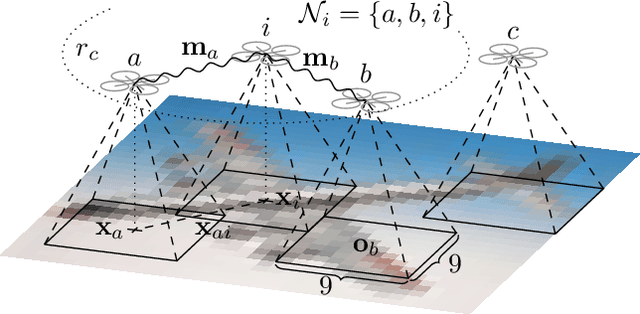
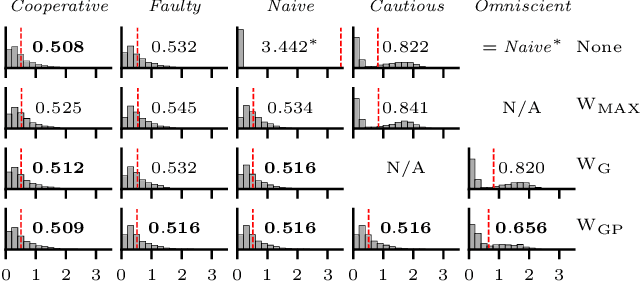

In this paper, we consider the problem of providing robustness to adversarial communication in multi-agent systems. Specifically, we propose a solution towards robust cooperation, which enables the multi-agent system to maintain high performance in the presence of anonymous non-cooperative agents that communicate faulty, misleading or manipulative information. In pursuit of this goal, we propose a communication architecture based on Graph Neural Networks (GNNs), which is amenable to a novel Gaussian Process (GP)-based probabilistic model characterizing the mutual information between the simultaneous communications of different agents due to their physical proximity and relative position. This model allows agents to locally compute approximate posterior probabilities, or confidences, that any given one of their communication partners is being truthful. These confidences can be used as weights in a message filtering scheme, thereby suppressing the influence of suspicious communication on the receiving agent's decisions. In order to assess the efficacy of our method, we introduce a taxonomy of non-cooperative agents, which distinguishes them by the amount of information available to them. We demonstrate in two distinct experiments that our method performs well across this taxonomy, outperforming alternative methods. For all but the best informed adversaries, our filtering method is able to reduce the impact that non-cooperative agents cause, reducing it to the point of negligibility, and with negligible cost to performance in the absence of adversaries.
Self-Feature Regularization: Self-Feature Distillation Without Teacher Models
Mar 17, 2021
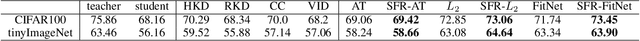
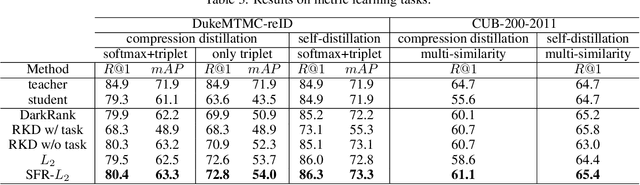
Knowledge distillation is the process of transferring the knowledge from a large model to a small model. In this process, the small model learns the generalization ability of the large model and retains the performance close to that of the large model. Knowledge distillation provides a training means to migrate the knowledge of models, facilitating model deployment and speeding up inference. However, previous distillation methods require pre-trained teacher models, which still bring computational and storage overheads. In this paper, a novel general training framework called Self-Feature Regularization~(SFR) is proposed, which uses features in the deep layers to supervise feature learning in the shallow layers, retains more semantic information. Specifically, we firstly use EMD-l2 loss to match local features and a many-to-one approach to distill features more intensively in the channel dimension. Then dynamic label smoothing is used in the output layer to achieve better performance. Experiments further show the effectiveness of our proposed framework.
Predicting Intensive Care Unit Length of Stay and Mortality Using Patient Vital Signs: Machine Learning Model Development and Validation
May 05, 2021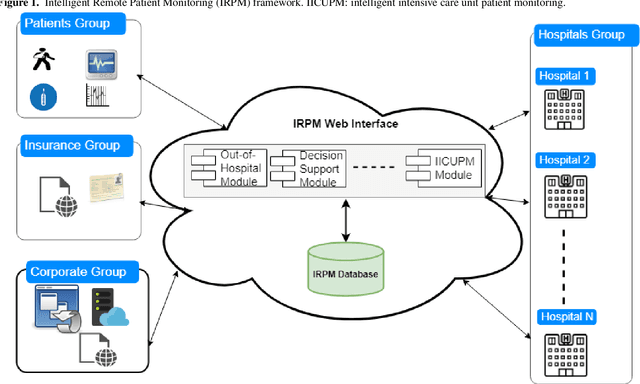

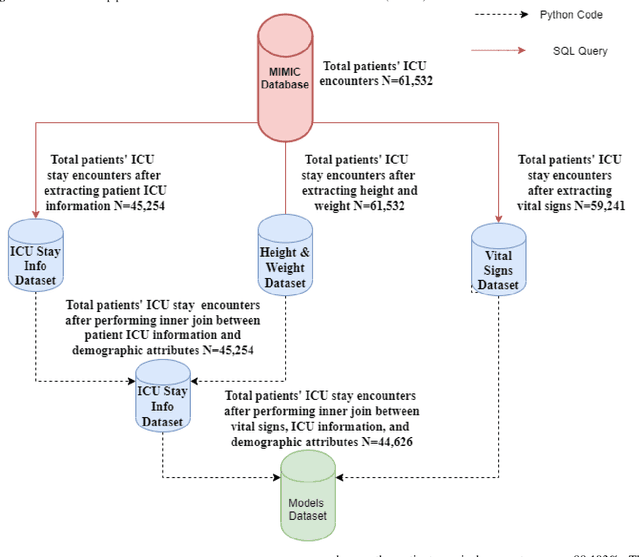

Patient monitoring is vital in all stages of care. We here report the development and validation of ICU length of stay and mortality prediction models. The models will be used in an intelligent ICU patient monitoring module of an Intelligent Remote Patient Monitoring (IRPM) framework that monitors the health status of patients, and generates timely alerts, maneuver guidance, or reports when adverse medical conditions are predicted. We utilized the publicly available Medical Information Mart for Intensive Care (MIMIC) database to extract ICU stay data for adult patients to build two prediction models: one for mortality prediction and another for ICU length of stay. For the mortality model, we applied six commonly used machine learning (ML) binary classification algorithms for predicting the discharge status (survived or not). For the length of stay model, we applied the same six ML algorithms for binary classification using the median patient population ICU stay of 2.64 days. For the regression-based classification, we used two ML algorithms for predicting the number of days. We built two variations of each prediction model: one using 12 baseline demographic and vital sign features, and the other based on our proposed quantiles approach, in which we use 21 extra features engineered from the baseline vital sign features, including their modified means, standard deviations, and quantile percentages. We could perform predictive modeling with minimal features while maintaining reasonable performance using the quantiles approach. The best accuracy achieved in the mortality model was approximately 89% using the random forest algorithm. The highest accuracy achieved in the length of stay model, based on the population median ICU stay (2.64 days), was approximately 65% using the random forest algorithm.
* 23 Pages, 11 Figures, 13 Tables
Influencing Reinforcement Learning through Natural Language Guidance
Apr 11, 2021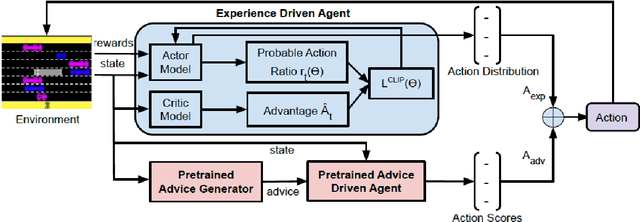
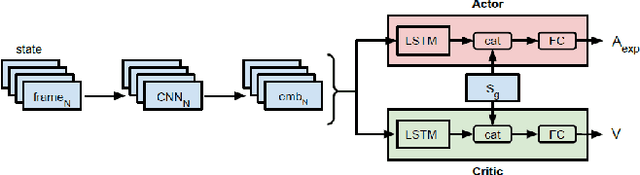
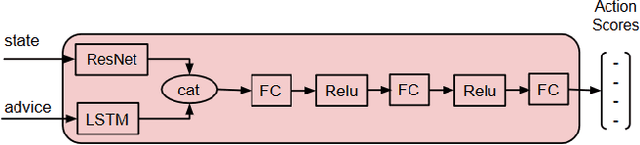

Interactive reinforcement learning agents use human feedback or instruction to help them learn in complex environments. Often, this feedback comes in the form of a discrete signal that is either positive or negative. While informative, this information can be difficult to generalize on its own. In this work, we explore how natural language advice can be used to provide a richer feedback signal to a reinforcement learning agent by extending policy shaping, a well-known Interactive reinforcement learning technique. Usually policy shaping employs a human feedback policy to help an agent to learn more about how to achieve its goal. In our case, we replace this human feedback policy with policy generated based on natural language advice. We aim to inspect if the generated natural language reasoning provides support to a deep reinforcement learning agent to decide its actions successfully in any given environment. So, we design our model with three networks: first one is the experience driven, next is the advice generator and third one is the advice driven. While the experience driven reinforcement learning agent chooses its actions being influenced by the environmental reward, the advice driven neural network with generated feedback by the advice generator for any new state selects its actions to assist the reinforcement learning agent to better policy shaping.
Addressing Annotation Imprecision for Tree Crown Delineation Using the RandCrowns Index
May 05, 2021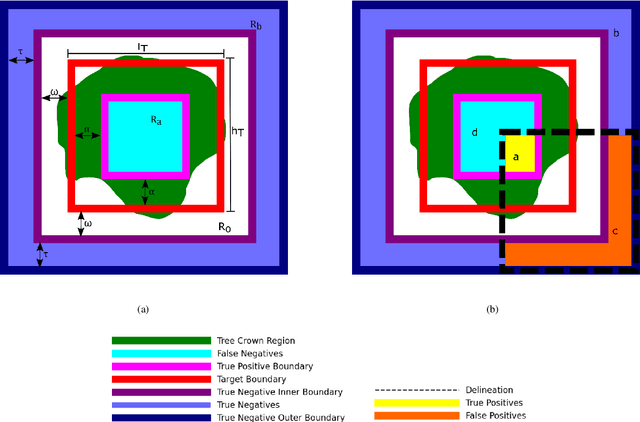
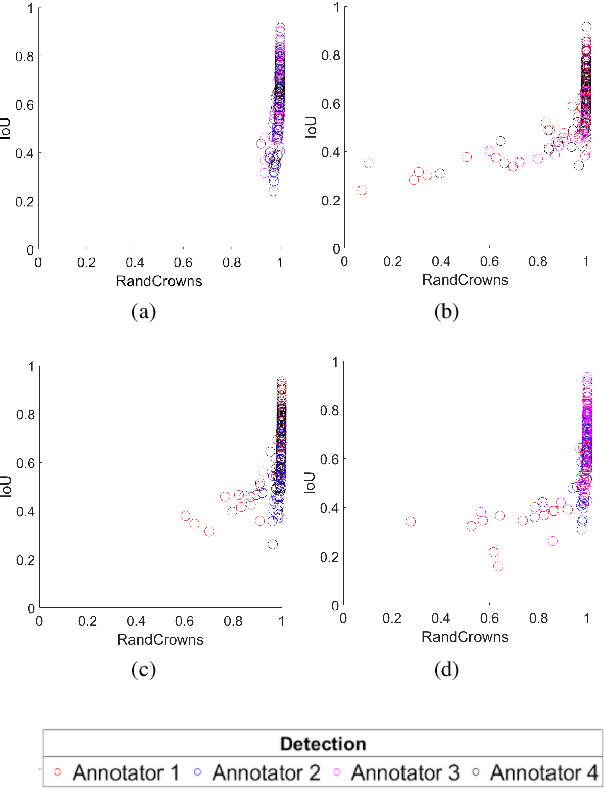


Supervised methods for object delineation in remote sensing require labeled ground-truth data. Gathering sufficient high quality ground-truth data is difficult, especially when the targets are of irregular shape or difficult to distinguish from the background or neighboring objects. Tree crown delineation provides key information from remote sensing images for forestry, ecology, and management. However, tree crowns in remote sensing imagery are often difficult to label and annotate due to irregular shape, overlapping canopies, shadowing, and indistinct edges. There are also multiple approaches to annotation in this field (e.g., rectangular boxes vs. convex polygons) that further contribute to annotation imprecision. However, current evaluation methods do not account for this uncertainty in annotations, and quantitative metrics for evaluation can vary across multiple annotators. We address these limitations using an adaptation of the Rand index for weakly-labeled crown delineation that we call RandCrowns. The RandCrowns metric reformulates the Rand index by adjusting the areas over which each term of the index is computed to account for uncertain and imprecise object delineation labels. Quantitative comparisons to the commonly used intersection over union (Jaccard similarity) method shows a decrease in the variance generated by differences among multiple annotators. Combined with qualitative examples, our results suggest that this RandCrowns metric is more robust for scoring target delineations in the presence of uncertainty and imprecision in annotations that are inherent to tree crown delineation. Although the focus of this paper is on evaluation of tree crown delineations, annotation imprecision is a challenge that is common across remote sensing of the environment (and many computer vision problems in general).
Modality-specific Distillation
Jan 06, 2021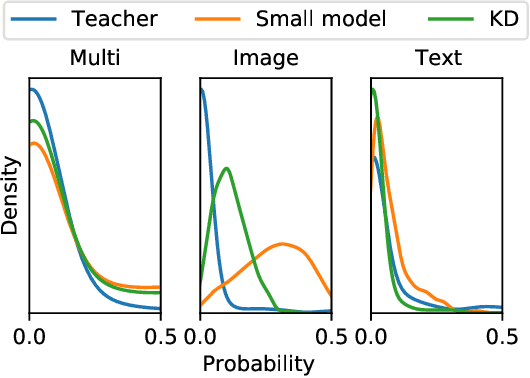
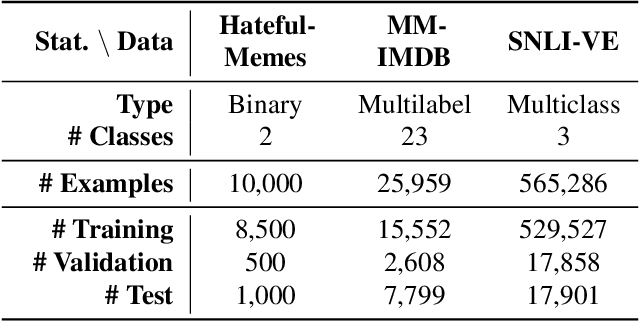
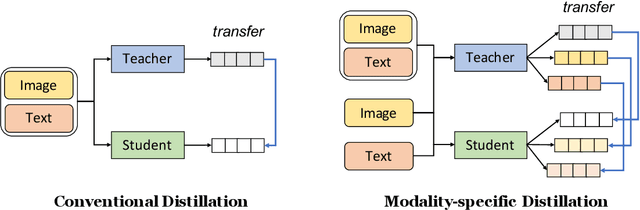
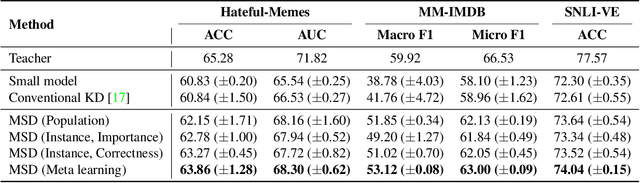
Large neural networks are impractical to deploy on mobile devices due to their heavy computational cost and slow inference. Knowledge distillation (KD) is a technique to reduce the model size while retaining performance by transferring knowledge from a large "teacher" model to a smaller "student" model. However, KD on multimodal datasets such as vision-language datasets is relatively unexplored and digesting such multimodal information is challenging since different modalities present different types of information. In this paper, we propose modality-specific distillation (MSD) to effectively transfer knowledge from a teacher on multimodal datasets. Existing KD approaches can be applied to multimodal setup, but a student doesn't have access to modality-specific predictions. Our idea aims at mimicking a teacher's modality-specific predictions by introducing an auxiliary loss term for each modality. Because each modality has different importance for predictions, we also propose weighting approaches for the auxiliary losses; a meta-learning approach to learn the optimal weights on these loss terms. In our experiments, we demonstrate the effectiveness of our MSD and the weighting scheme and show that it achieves better performance than KD.
Adversarial Shape Learning for Building Extraction in VHR Remote Sensing Images
Mar 17, 2021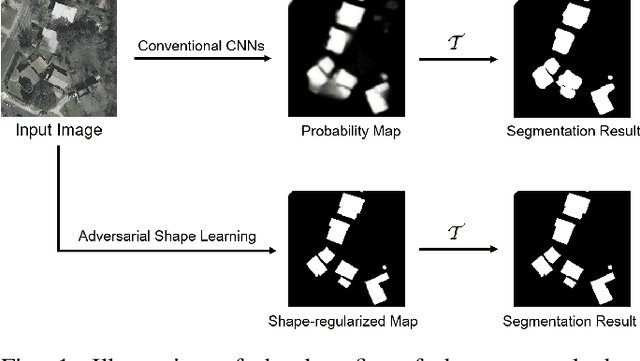
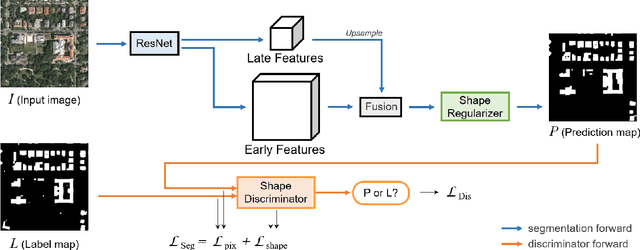
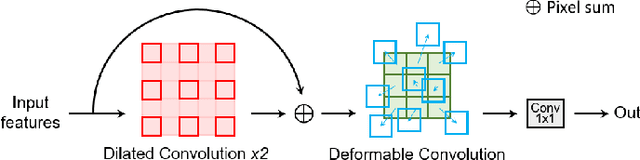
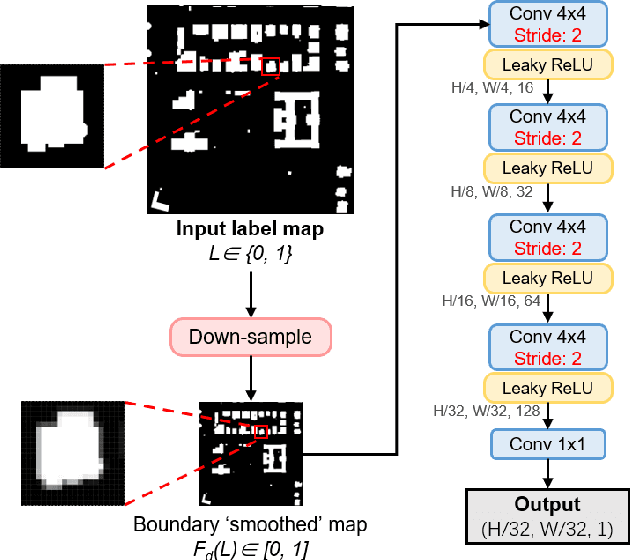
Building extraction in VHR RSIs remains to be a challenging task due to occlusion and boundary ambiguity problems. Although conventional convolutional neural networks (CNNs) based methods are capable of exploiting local texture and context information, they fail to capture the shape patterns of buildings, which is a necessary constraint in the human recognition. In this context, we propose an adversarial shape learning network (ASLNet) to model the building shape patterns, thus improving the accuracy of building segmentation. In the proposed ASLNet, we introduce the adversarial learning strategy to explicitly model the shape constraints, as well as a CNN shape regularizer to strengthen the embedding of shape features. To assess the geometric accuracy of building segmentation results, we further introduced several object-based assessment metrics. Experiments on two open benchmark datasets show that the proposed ASLNet improves both the pixel-based accuracy and the object-based measurements by a large margin. The code is available at: https://github.com/ggsDing/ASLNet
Graph Embedding for Recommendation against Attribute Inference Attacks
Jan 29, 2021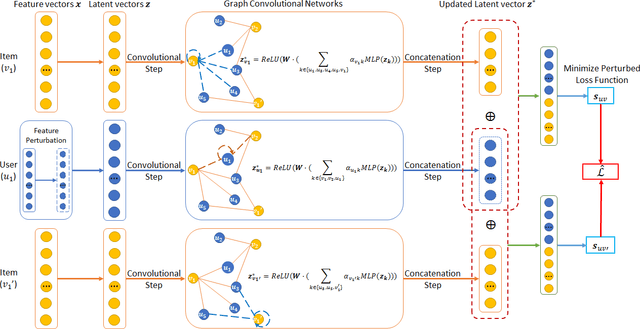
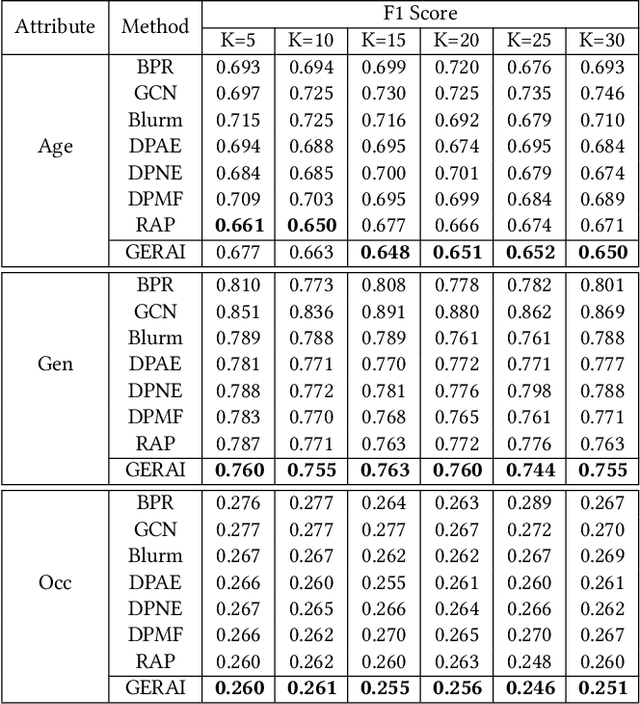
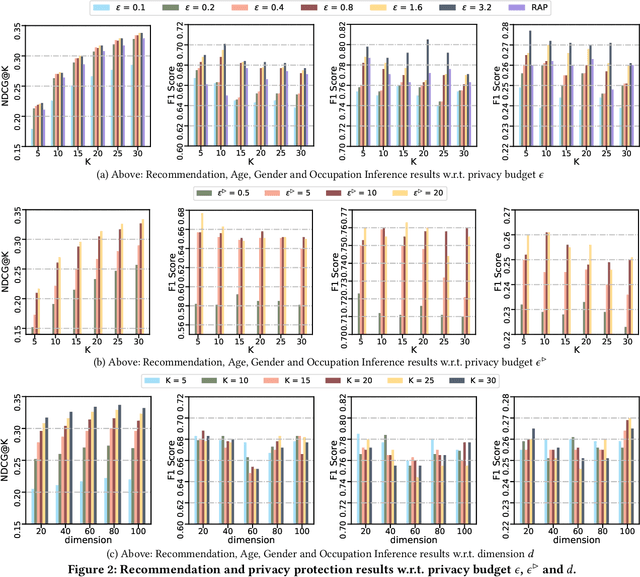
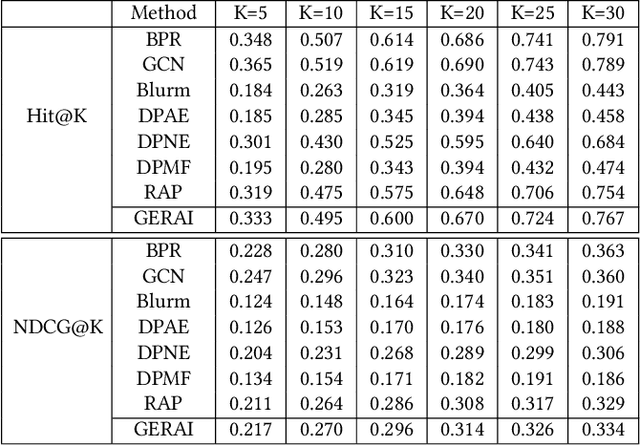
In recent years, recommender systems play a pivotal role in helping users identify the most suitable items that satisfy personal preferences. As user-item interactions can be naturally modelled as graph-structured data, variants of graph convolutional networks (GCNs) have become a well-established building block in the latest recommenders. Due to the wide utilization of sensitive user profile data, existing recommendation paradigms are likely to expose users to the threat of privacy breach, and GCN-based recommenders are no exception. Apart from the leakage of raw user data, the fragility of current recommenders under inference attacks offers malicious attackers a backdoor to estimate users' private attributes via their behavioral footprints and the recommendation results. However, little attention has been paid to developing recommender systems that can defend such attribute inference attacks, and existing works achieve attack resistance by either sacrificing considerable recommendation accuracy or only covering specific attack models or protected information. In our paper, we propose GERAI, a novel differentially private graph convolutional network to address such limitations. Specifically, in GERAI, we bind the information perturbation mechanism in differential privacy with the recommendation capability of graph convolutional networks. Furthermore, based on local differential privacy and functional mechanism, we innovatively devise a dual-stage encryption paradigm to simultaneously enforce privacy guarantee on users' sensitive features and the model optimization process. Extensive experiments show the superiority of GERAI in terms of its resistance to attribute inference attacks and recommendation effectiveness.
Distributed Client-Server Optimization for SLAM with Limited On-Device Resources
Mar 26, 2021
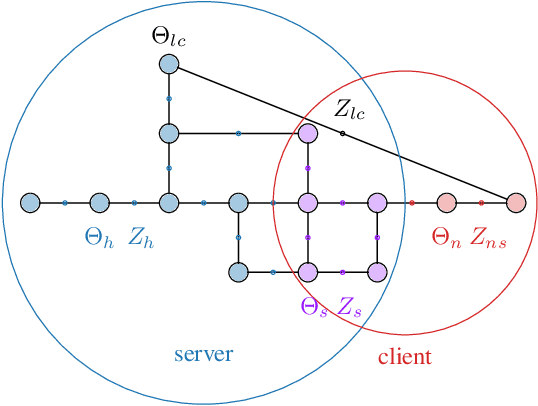
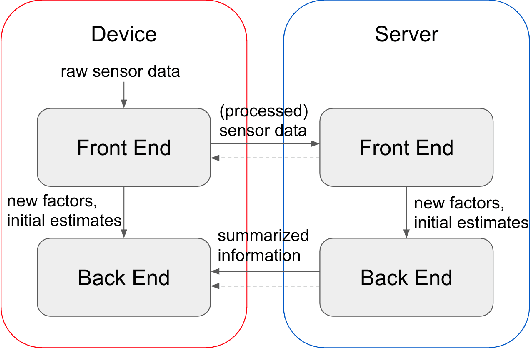
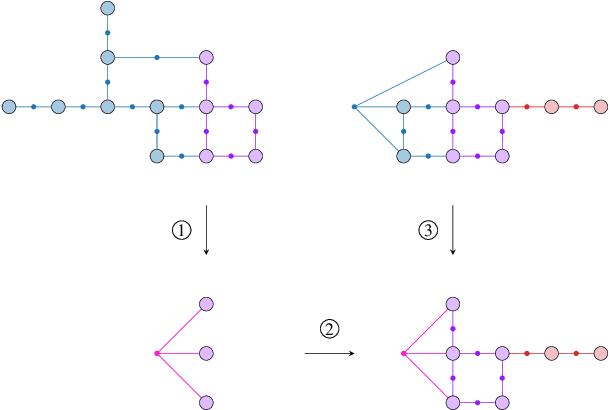
Simultaneous localization and mapping (SLAM) is a crucial functionality for exploration robots and virtual/augmented reality (VR/AR) devices. However, some of such devices with limited resources cannot afford the computational or memory cost to run full SLAM algorithms. We propose a general client-server SLAM optimization framework that achieves accurate real-time state estimation on the device with low requirements of on-board resources. The resource-limited device (the client) only works on a small part of the map, and the rest of the map is processed by the server. By sending the summarized information of the rest of map to the client, the on-device state estimation is more accurate. Further improvement of accuracy is achieved in the presence of on-device early loop closures, which enables reloading useful variables from the server to the client. Experimental results from both synthetic and real-world datasets demonstrate that the proposed optimization framework achieves accurate estimation in real-time with limited computation and memory budget of the device.