 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond 4D Tracking: Using Cluster Shapes for Track Seeding
Dec 08, 2020




Tracking is one of the most time consuming aspects of event reconstruction at the Large Hadron Collider (LHC) and its high-luminosity upgrade (HL-LHC). Innovative detector technologies extend tracking to four-dimensions by including timing in the pattern recognition and parameter estimation. However, present and future hardware already have additional information that is largely unused by existing track seeding algorithms. The shape of clusters provides an additional dimension for track seeding that can significantly reduce the combinatorial challenge of track finding. We use neural networks to show that cluster shapes can reduce significantly the rate of fake combinatorical backgrounds while preserving a high efficiency. We demonstrate this using the information in cluster singlets, doublets and triplets. Numerical results are presented with simulations from the TrackML challenge.
Coarse-to-Fine Entity Representations for Document-level Relation Extraction
Dec 04, 2020
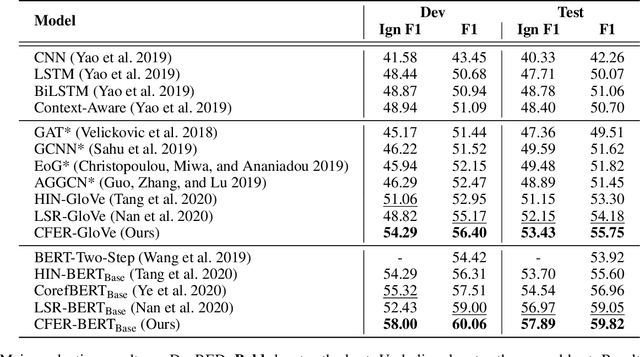
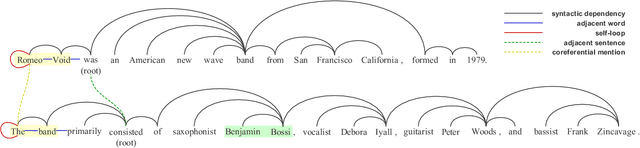
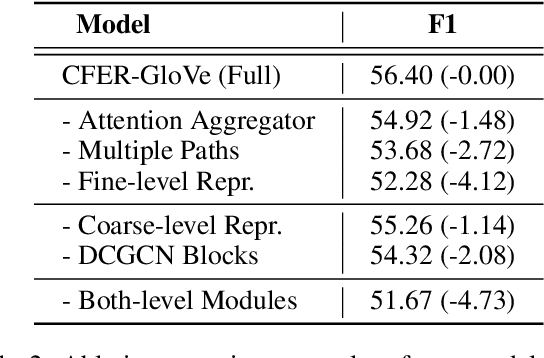
Document-level Relation Extraction (RE) requires extracting relations expressed within and across sentences. Recent works show that graph-based methods, usually constructing a document-level graph that captures document-aware interactions, can obtain useful entity representations thus helping tackle document-level RE. These methods either focus more on the entire graph, or pay more attention to a part of the graph, e.g., paths between the target entity pair. However, we find that document-level RE may benefit from focusing on both of them simultaneously. Therefore, to obtain more comprehensive entity representations, we propose the \textbf{C}oarse-to-\textbf{F}ine \textbf{E}ntity \textbf{R}epresentation model (\textbf{CFER}) that adopts a coarse-to-fine strategy involving two phases. First, CFER uses graph neural networks to integrate global information in the entire graph at a coarse level. Next, CFER utilizes the global information as a guidance to selectively aggregate path information between the target entity pair at a fine level. In classification, we combine the entity representations from both two levels into more comprehensive representations for relation extraction. Experimental results on a large-scale document-level RE dataset show that CFER achieves better performance than previous baseline models. Further, we verify the effectiveness of our strategy through elaborate model analysis.
SIT3: Code Summarization with Structure-Induced Transformer
Dec 29, 2020

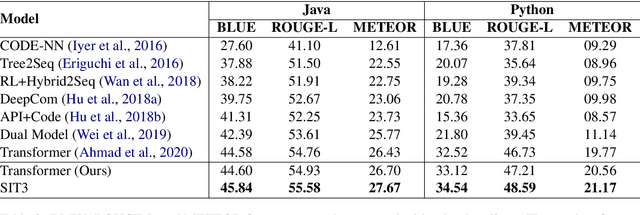
Code summarization (CS) is becoming a promising area in recent natural language understanding, which aims to generate sensible annotations automatically for source code and is known as programmer oriented. Previous works attempt to apply structure-based traversal (SBT) or non-sequential models like Tree-LSTM and GNN to learn structural program semantics. They both meet the following drawbacks: 1) it is shown ineffective to incorporate SBT into Transformer; 2) it is limited to capture global information through GNN; 3) it is underestimated to capture structural semantics only using Transformer. In this paper, we propose a novel model based on structure-induced self-attention, which encodes sequential inputs with highly-effective structure modeling. Extensive experiments show that our newly-proposed model achieves new state-of-the-art results on popular benchmarks. To our best knowledge, it is the first work on code summarization that uses Transformer to model structural information with high efficiency and no extra parameters. We also provide a tutorial on how we pre-process.
Domain Generalization with MixStyle
Apr 05, 2021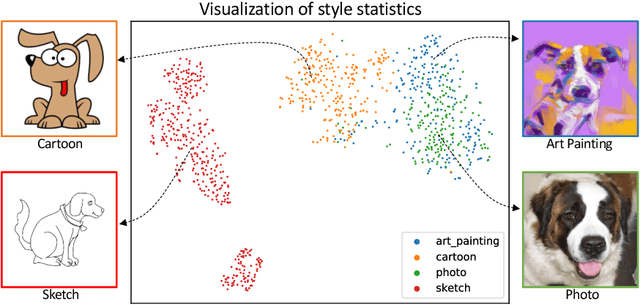
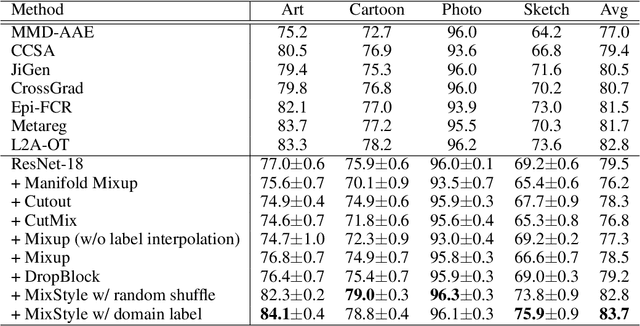
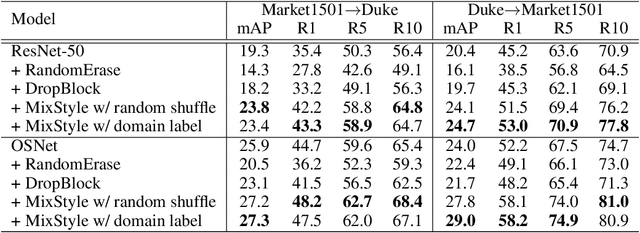
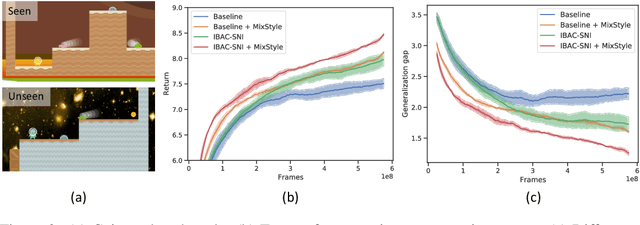
Though convolutional neural networks (CNNs) have demonstrated remarkable ability in learning discriminative features, they often generalize poorly to unseen domains. Domain generalization aims to address this problem by learning from a set of source domains a model that is generalizable to any unseen domain. In this paper, a novel approach is proposed based on probabilistically mixing instance-level feature statistics of training samples across source domains. Our method, termed MixStyle, is motivated by the observation that visual domain is closely related to image style (e.g., photo vs.~sketch images). Such style information is captured by the bottom layers of a CNN where our proposed style-mixing takes place. Mixing styles of training instances results in novel domains being synthesized implicitly, which increase the domain diversity of the source domains, and hence the generalizability of the trained model. MixStyle fits into mini-batch training perfectly and is extremely easy to implement. The effectiveness of MixStyle is demonstrated on a wide range of tasks including category classification, instance retrieval and reinforcement learning.
Dense Multiscale Feature Fusion Pyramid Networks for Object Detection in UAV-Captured Images
Dec 19, 2020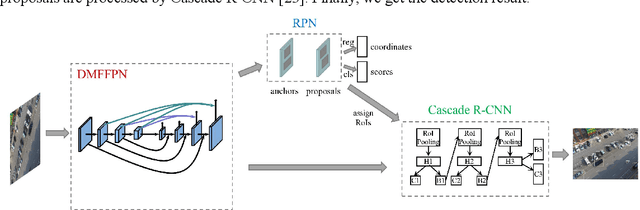

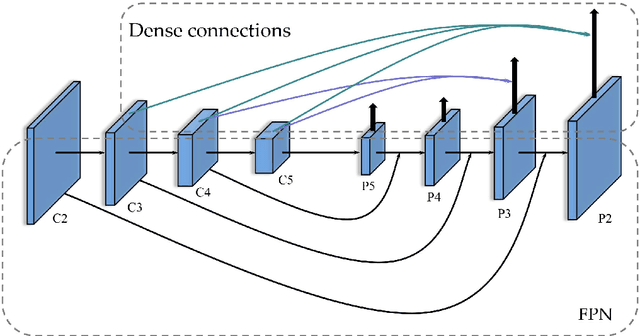

Although much significant progress has been made in the research field of object detection with deep learning, there still exists a challenging task for the objects with small size, which is notably pronounced in UAV-captured images. Addressing these issues, it is a critical need to explore the feature extraction methods that can extract more sufficient feature information of small objects. In this paper, we propose a novel method called Dense Multiscale Feature Fusion Pyramid Networks(DMFFPN), which is aimed at obtaining rich features as much as possible, improving the information propagation and reuse. Specifically, the dense connection is designed to fully utilize the representation from the different convolutional layers. Furthermore, cascade architecture is applied in the second stage to enhance the localization capability. Experiments on the drone-based datasets named VisDrone-DET suggest a competitive performance of our method.
A Probabilistic Approach to Personalize Type-based Facet Ranking for POI Suggestion
May 10, 2021
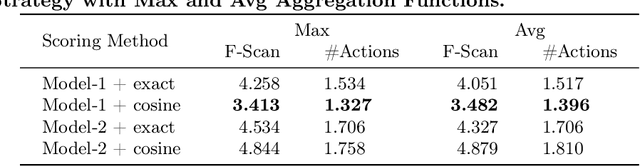
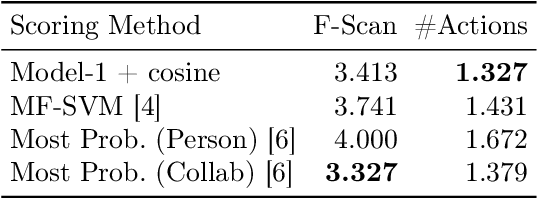
Faceted Search Systems (FSS) have become one of the main search interfaces used in vertical search systems, offering users meaningful facets to refine their search query and narrow down the results quickly to find the intended search target. This work focuses on the problem of ranking type-based facets. In a structured information space, type-based facets (t-facets) indicate the category to which each object belongs. When they belong to a large multi-level taxonomy, it is desirable to rank them separately before ranking other facet groups. This helps the searcher in filtering the results according to their type first. This also makes it easier to rank the rest of the facets once the type of the intended search target is selected. Existing research employs the same ranking methods for different facet groups. In this research, we propose a two-step approach to personalize t-facet ranking. The first step assigns a relevance score to each individual leaf-node t-facet. The score is generated using probabilistic models and it reflects t-facet relevance to the query and the user profile. In the second step, this score is used to re-order and select the sub-tree to present to the user. We investigate the usefulness of the proposed method to a Point Of Interest (POI) suggestion task. Our evaluation aims at capturing the user effort required to fulfil her search needs by using the ranked facets. The proposed approach achieved better results than other existing personalized baselines.
Dual-Level Collaborative Transformer for Image Captioning
Jan 16, 2021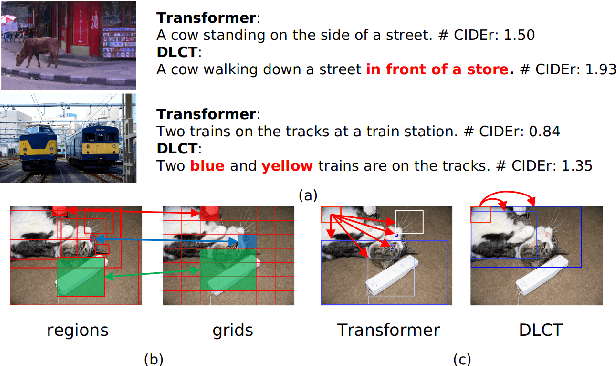
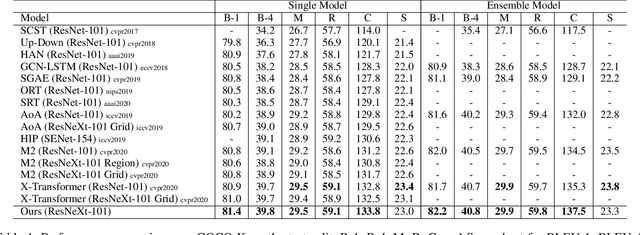
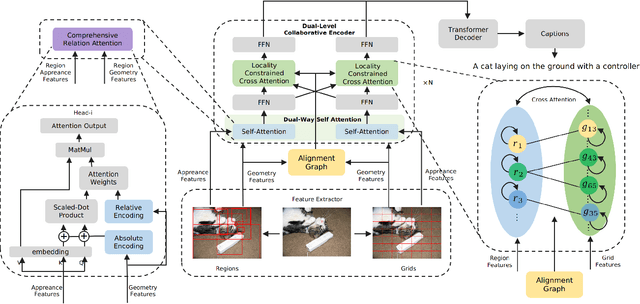
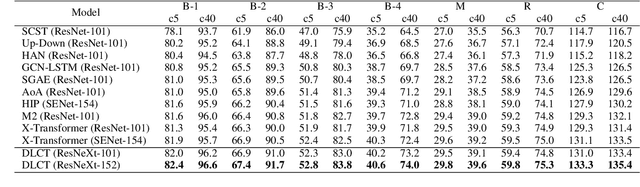
Descriptive region features extracted by object detection networks have played an important role in the recent advancements of image captioning. However, they are still criticized for the lack of contextual information and fine-grained details, which in contrast are the merits of traditional grid features. In this paper, we introduce a novel Dual-Level Collaborative Transformer (DLCT) network to realize the complementary advantages of the two features. Concretely, in DLCT, these two features are first processed by a novelDual-way Self Attenion (DWSA) to mine their intrinsic properties, where a Comprehensive Relation Attention component is also introduced to embed the geometric information. In addition, we propose a Locality-Constrained Cross Attention module to address the semantic noises caused by the direct fusion of these two features, where a geometric alignment graph is constructed to accurately align and reinforce region and grid features. To validate our model, we conduct extensive experiments on the highly competitive MS-COCO dataset, and achieve new state-of-the-art performance on both local and online test sets, i.e., 133.8% CIDEr-D on Karpathy split and 135.4% CIDEr on the official split. Code is available at https://github.com/luo3300612/image-captioning-DLCT.
Improving prostate whole gland segmentation in t2-weighted MRI with synthetically generated data
Mar 27, 2021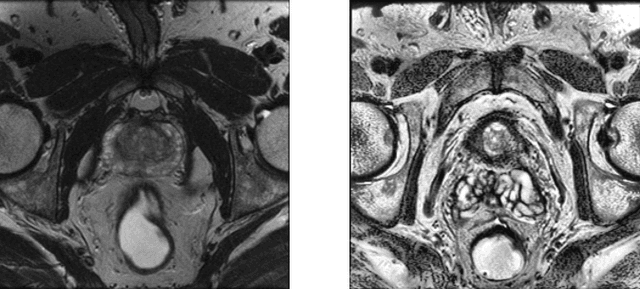
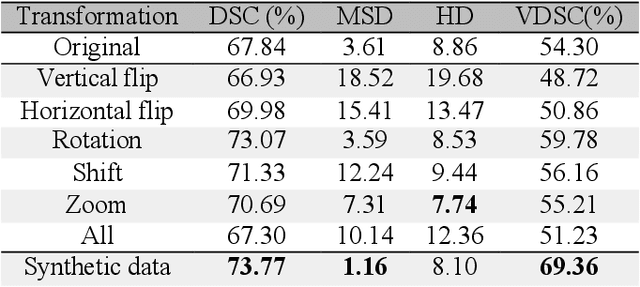
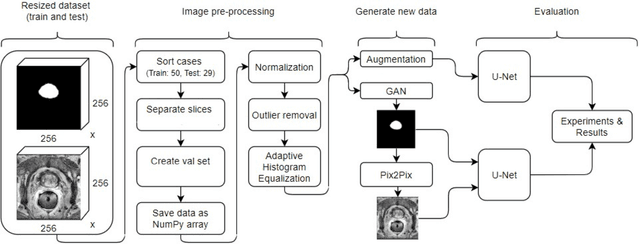
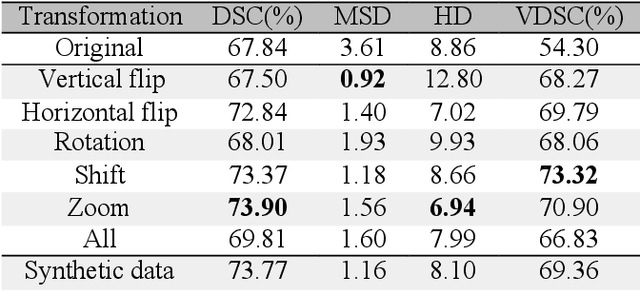
Whole gland (WG) segmentation of the prostate plays a crucial role in detection, staging and treatment planning of prostate cancer (PCa). Despite promise shown by deep learning (DL) methods, they rely on the availability of a considerable amount of annotated data. Augmentation techniques such as translation and rotation of images present an alternative to increase data availability. Nevertheless, the amount of information provided by the transformed data is limited due to the correlation between the generated data and the original. Based on the recent success of generative adversarial networks (GAN) in producing synthetic images for other domains as well as in the medical domain, we present a pipeline to generate WG segmentation masks and synthesize T2-weighted MRI of the prostate based on a publicly available multi-center dataset. Following, we use the generated data as a form of data augmentation. Results show an improvement in the quality of the WG segmentation when compared to standard augmentation techniques.
Lite-HRNet: A Lightweight High-Resolution Network
Apr 13, 2021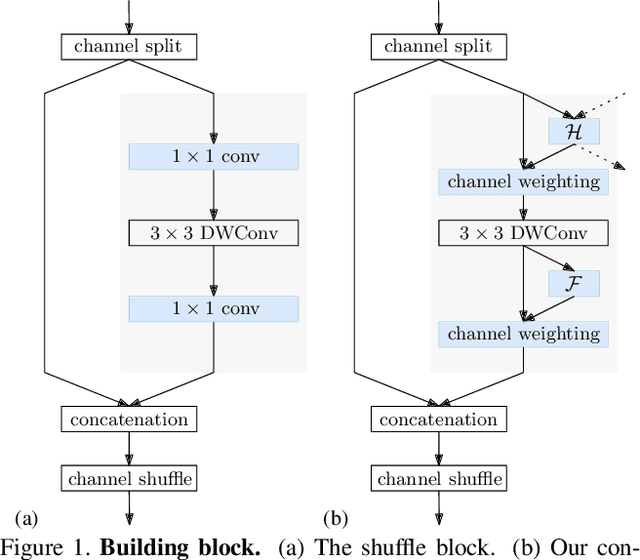
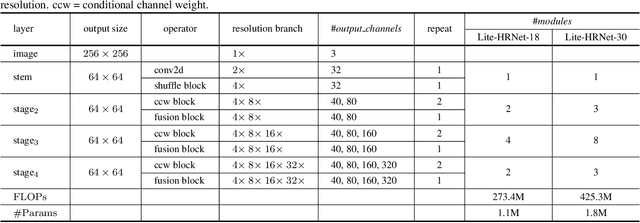
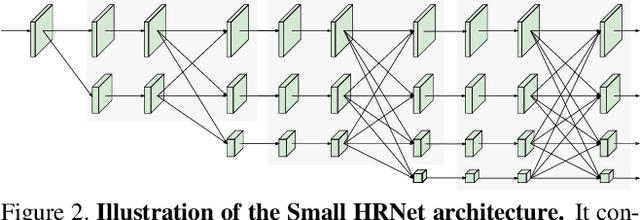

We present an efficient high-resolution network, Lite-HRNet, for human pose estimation. We start by simply applying the efficient shuffle block in ShuffleNet to HRNet (high-resolution network), yielding stronger performance over popular lightweight networks, such as MobileNet, ShuffleNet, and Small HRNet. We find that the heavily-used pointwise (1x1) convolutions in shuffle blocks become the computational bottleneck. We introduce a lightweight unit, conditional channel weighting, to replace costly pointwise (1x1) convolutions in shuffle blocks. The complexity of channel weighting is linear w.r.t the number of channels and lower than the quadratic time complexity for pointwise convolutions. Our solution learns the weights from all the channels and over multiple resolutions that are readily available in the parallel branches in HRNet. It uses the weights as the bridge to exchange information across channels and resolutions, compensating the role played by the pointwise (1x1) convolution. Lite-HRNet demonstrates superior results on human pose estimation over popular lightweight networks. Moreover, Lite-HRNet can be easily applied to semantic segmentation task in the same lightweight manner. The code and models have been publicly available at https://github.com/HRNet/Lite-HRNet.
Automatic identification of outliers in Hubble Space Telescope galaxy images
Jan 07, 2021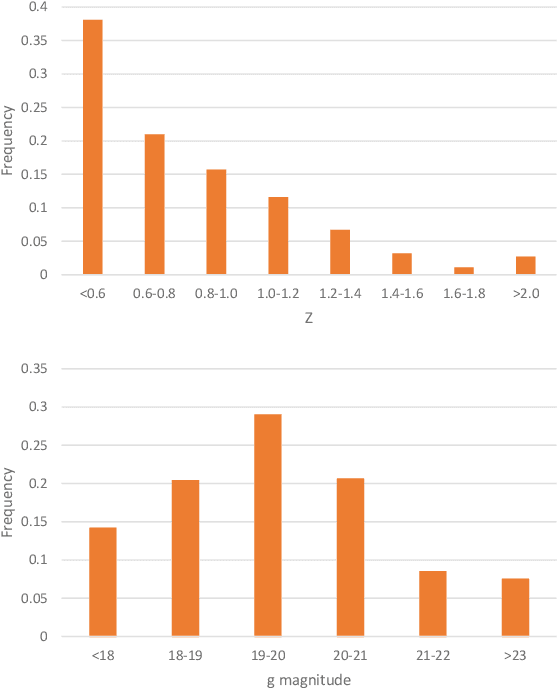
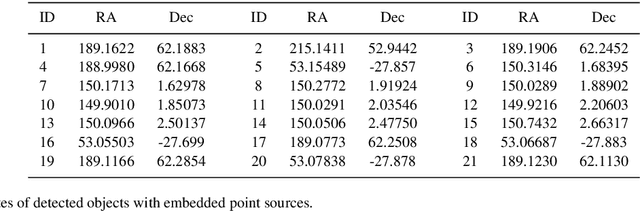


Rare extragalactic objects can carry substantial information about the past, present, and future universe. Given the size of astronomical databases in the information era it can be assumed that very many outlier galaxies are included in existing and future astronomical databases. However, manual search for these objects is impractical due to the required labor, and therefore the ability to detect such objects largely depends on computer algorithms. This paper describes an unsupervised machine learning algorithm for automatic detection of outlier galaxy images, and its application to several Hubble Space Telescope fields. The algorithm does not require training, and therefore is not dependent on the preparation of clean training sets. The application of the algorithm to a large collection of galaxies detected a variety of outlier galaxy images. The algorithm is not perfect in the sense that not all objects detected by the algorithm are indeed considered outliers, but it reduces the dataset by two orders of magnitude to allow practical manual identification. The catalogue contains 147 objects that would be very difficult to identify without using automation.