 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Discriminative and Semantic Feature Selection for Place Recognition towards Dynamic Environments
Mar 18, 2021

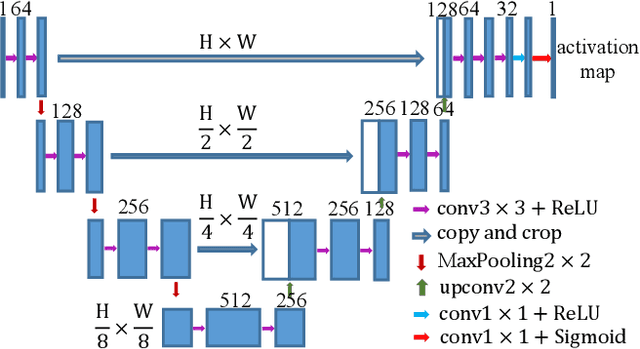
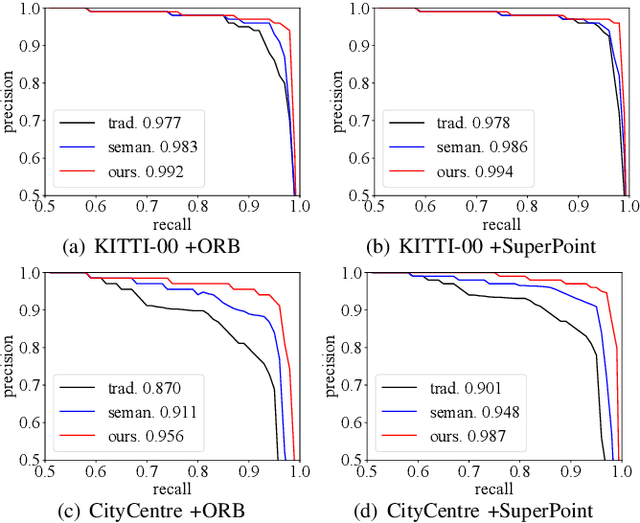
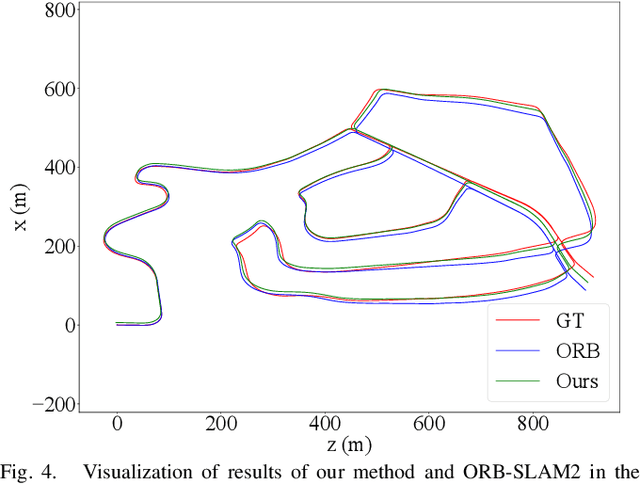
Features play an important role in various visual tasks, especially in visual place recognition applied in perceptual changing environments. In this paper, we address the challenges of place recognition due to dynamics and confusable patterns by proposing a discriminative and semantic feature selection network, dubbed as DSFeat. Supervised by both semantic information and attention mechanism, we can estimate pixel-wise stability of features, indicating the probability of a static and stable region from which features are extracted, and then select features that are insensitive to dynamic interference and distinguishable to be correctly matched. The designed feature selection model is evaluated in place recognition and SLAM system in several public datasets with varying appearances and viewpoints. Experimental results conclude that the effectiveness of the proposed method. It should be noticed that our proposal can be readily pluggable into any feature-based SLAM system.
Privileged Knowledge Distillation for Online Action Detection
Nov 18, 2020

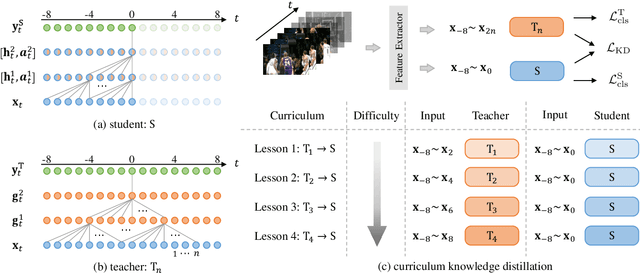
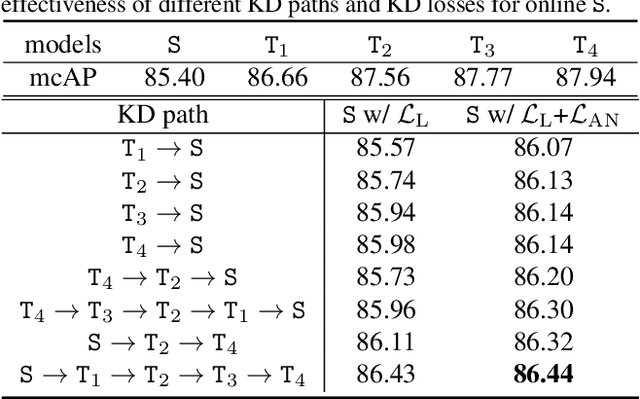
Online Action Detection (OAD) in videos is proposed as a per-frame labeling task to address the real-time prediction tasks that can only obtain the previous and current video frames. This paper presents a novel learning-with-privileged based framework for online action detection where the future frames only observable at the training stages are considered as a form of privileged information. Knowledge distillation is employed to transfer the privileged information from the offline teacher to the online student. We note that this setting is different from conventional KD because the difference between the teacher and student models mostly lies in input data rather than the network architecture. We propose Privileged Knowledge Distillation (PKD) which (i) schedules a curriculum learning procedure and (ii) inserts auxiliary nodes to the student model, both for shrinking the information gap and improving learning performance. Compared to other OAD methods that explicitly predict future frames, our approach avoids learning unpredictable unnecessary yet inconsistent visual contents and achieves state-of-the-art accuracy on two popular OAD benchmarks, TVSeries and THUMOS14.
Beyond 4D Tracking: Using Cluster Shapes for Track Seeding
Dec 08, 2020



Tracking is one of the most time consuming aspects of event reconstruction at the Large Hadron Collider (LHC) and its high-luminosity upgrade (HL-LHC). Innovative detector technologies extend tracking to four-dimensions by including timing in the pattern recognition and parameter estimation. However, present and future hardware already have additional information that is largely unused by existing track seeding algorithms. The shape of clusters provides an additional dimension for track seeding that can significantly reduce the combinatorial challenge of track finding. We use neural networks to show that cluster shapes can reduce significantly the rate of fake combinatorical backgrounds while preserving a high efficiency. We demonstrate this using the information in cluster singlets, doublets and triplets. Numerical results are presented with simulations from the TrackML challenge.
Automatic Micro-Expression Apex Frame Spotting using Local Binary Pattern from Six Intersection Planes
Apr 05, 2021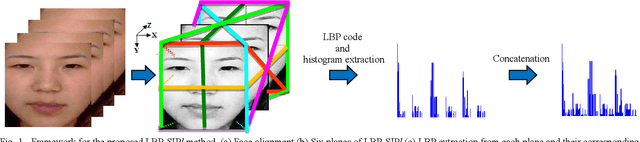
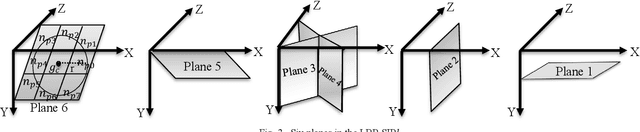

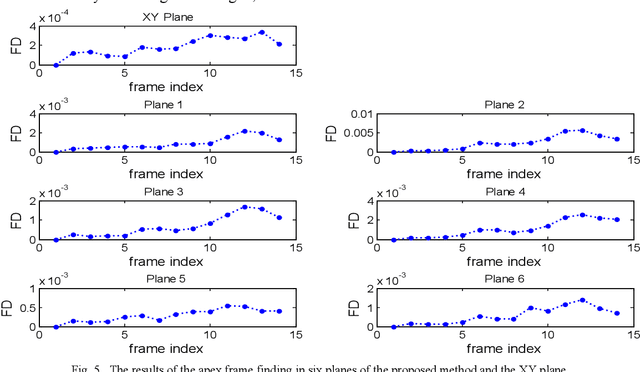
Facial expressions are one of the most effective ways for non-verbal communications, which can be expressed as the Micro-Expression (ME) in the high-stake situations. The MEs are involuntary, rapid, and, subtle, and they can reveal real human intentions. However, their feature extraction is very challenging due to their low intensity and very short duration. Although Local Binary Pattern from Three Orthogonal Plane (LBP-TOP) feature extractor is useful for the ME analysis, it does not consider essential information. To address this problem, we propose a new feature extractor called Local Binary Pattern from Six Intersection Planes (LBP-SIPl). This method extracts LBP code on six intersection planes, and then it combines them. Results show that the proposed method has superior performance in apex frame spotting automatically in comparison with the relevant methods on the CASME database. Simulation results show that, using the proposed method, the apex frame has been spotted in 43% of subjects in the CASME database, automatically. Also, the mean absolute error of 1.76 is achieved, using our novel proposed method.
Coarse-to-Fine Entity Representations for Document-level Relation Extraction
Dec 04, 2020
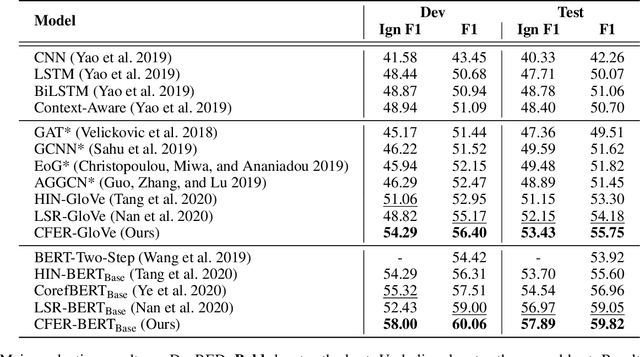
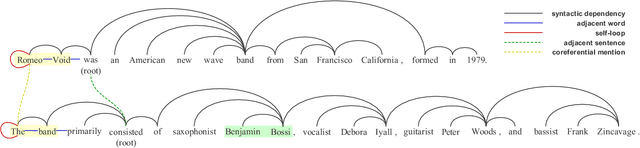
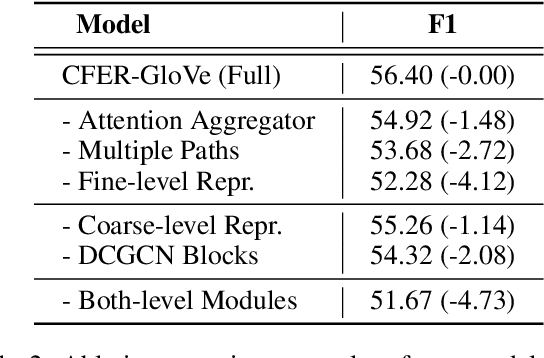
Document-level Relation Extraction (RE) requires extracting relations expressed within and across sentences. Recent works show that graph-based methods, usually constructing a document-level graph that captures document-aware interactions, can obtain useful entity representations thus helping tackle document-level RE. These methods either focus more on the entire graph, or pay more attention to a part of the graph, e.g., paths between the target entity pair. However, we find that document-level RE may benefit from focusing on both of them simultaneously. Therefore, to obtain more comprehensive entity representations, we propose the \textbf{C}oarse-to-\textbf{F}ine \textbf{E}ntity \textbf{R}epresentation model (\textbf{CFER}) that adopts a coarse-to-fine strategy involving two phases. First, CFER uses graph neural networks to integrate global information in the entire graph at a coarse level. Next, CFER utilizes the global information as a guidance to selectively aggregate path information between the target entity pair at a fine level. In classification, we combine the entity representations from both two levels into more comprehensive representations for relation extraction. Experimental results on a large-scale document-level RE dataset show that CFER achieves better performance than previous baseline models. Further, we verify the effectiveness of our strategy through elaborate model analysis.
A reconfigurable neural network ASIC for detector front-end data compression at the HL-LHC
May 04, 2021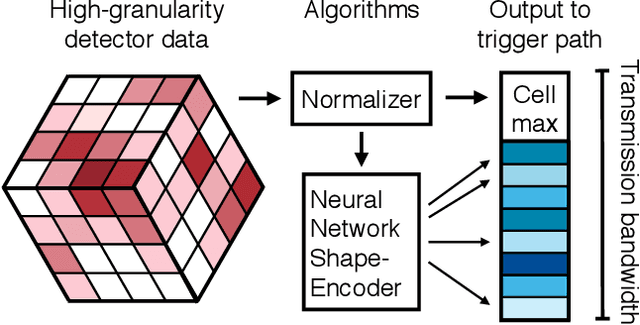
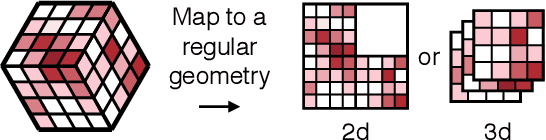
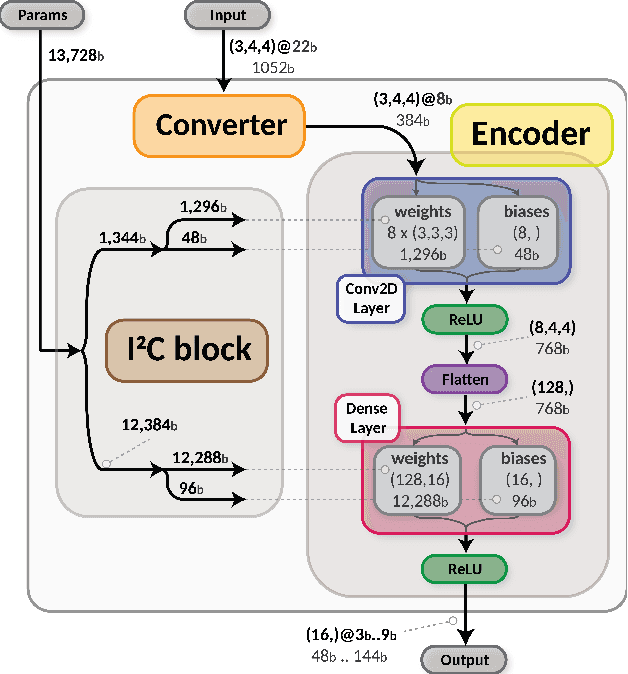
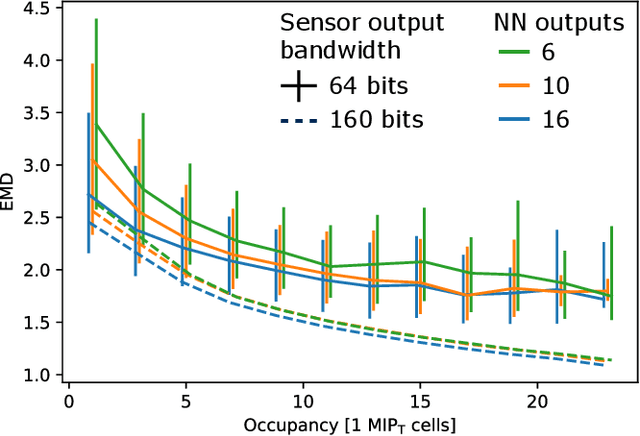
Despite advances in the programmable logic capabilities of modern trigger systems, a significant bottleneck remains in the amount of data to be transported from the detector to off-detector logic where trigger decisions are made. We demonstrate that a neural network autoencoder model can be implemented in a radiation tolerant ASIC to perform lossy data compression alleviating the data transmission problem while preserving critical information of the detector energy profile. For our application, we consider the high-granularity calorimeter from the CMS experiment at the CERN Large Hadron Collider. The advantage of the machine learning approach is in the flexibility and configurability of the algorithm. By changing the neural network weights, a unique data compression algorithm can be deployed for each sensor in different detector regions, and changing detector or collider conditions. To meet area, performance, and power constraints, we perform a quantization-aware training to create an optimized neural network hardware implementation. The design is achieved through the use of high-level synthesis tools and the hls4ml framework, and was processed through synthesis and physical layout flows based on a LP CMOS 65 nm technology node. The flow anticipates 200 Mrad of ionizing radiation to select gates, and reports a total area of 3.6 mm^2 and consumes 95 mW of power. The simulated energy consumption per inference is 2.4 nJ. This is the first radiation tolerant on-detector ASIC implementation of a neural network that has been designed for particle physics applications.
Societal Biases in Retrieved Contents: Measurement Framework and Adversarial Mitigation for BERT Rankers
Apr 28, 2021

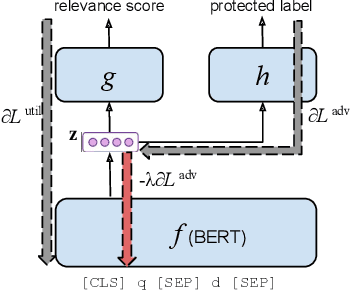
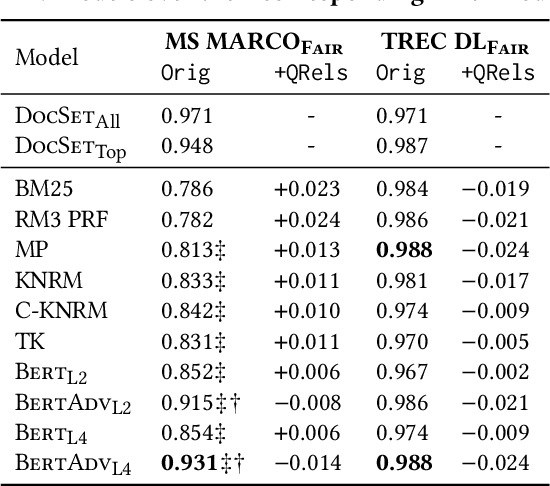
Societal biases resonate in the retrieved contents of information retrieval (IR) systems, resulting in reinforcing existing stereotypes. Approaching this issue requires established measures of fairness regarding the representation of various social groups in retrieved contents, as well as methods to mitigate such biases, particularly in the light of the advances in deep ranking models. In this work, we first provide a novel framework to measure the fairness in the retrieved text contents of ranking models. Introducing a ranker-agnostic measurement, the framework also enables the disentanglement of the effect on fairness of collection from that of rankers. Second, we propose an adversarial bias mitigation approach applied to the state-of-the-art Bert rankers, which jointly learns to predict relevance and remove protected attributes. We conduct experiments on two passage retrieval collections (MS MARCO Passage Re-ranking and TREC Deep Learning 2019 Passage Re-ranking), which we extend by fairness annotations of a selected subset of queries regarding gender attributes. Our results on the MS MARCO benchmark show that, while the fairness of all ranking models is lower than the ones of ranker-agnostic baselines, the fairness in retrieved contents significantly improves when applying the proposed adversarial training. Lastly, we investigate the trade-off between fairness and utility, showing that through applying a combinatorial model selection method, we can maintain the significant improvements in fairness without any significant loss in utility.
Dense Multiscale Feature Fusion Pyramid Networks for Object Detection in UAV-Captured Images
Dec 19, 2020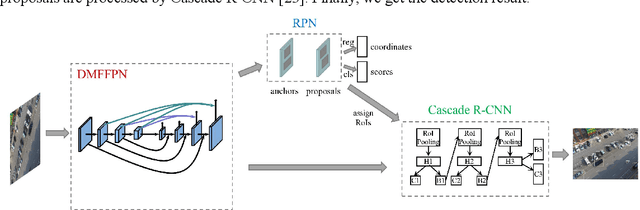

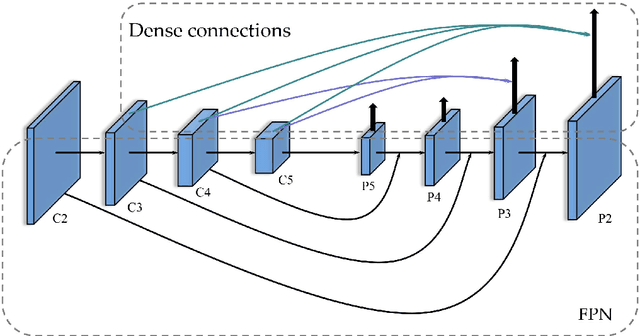

Although much significant progress has been made in the research field of object detection with deep learning, there still exists a challenging task for the objects with small size, which is notably pronounced in UAV-captured images. Addressing these issues, it is a critical need to explore the feature extraction methods that can extract more sufficient feature information of small objects. In this paper, we propose a novel method called Dense Multiscale Feature Fusion Pyramid Networks(DMFFPN), which is aimed at obtaining rich features as much as possible, improving the information propagation and reuse. Specifically, the dense connection is designed to fully utilize the representation from the different convolutional layers. Furthermore, cascade architecture is applied in the second stage to enhance the localization capability. Experiments on the drone-based datasets named VisDrone-DET suggest a competitive performance of our method.
SIT3: Code Summarization with Structure-Induced Transformer
Dec 29, 2020

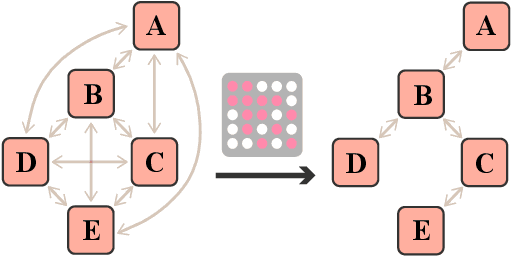
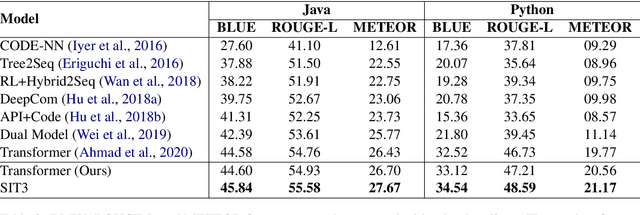
Code summarization (CS) is becoming a promising area in recent natural language understanding, which aims to generate sensible annotations automatically for source code and is known as programmer oriented. Previous works attempt to apply structure-based traversal (SBT) or non-sequential models like Tree-LSTM and GNN to learn structural program semantics. They both meet the following drawbacks: 1) it is shown ineffective to incorporate SBT into Transformer; 2) it is limited to capture global information through GNN; 3) it is underestimated to capture structural semantics only using Transformer. In this paper, we propose a novel model based on structure-induced self-attention, which encodes sequential inputs with highly-effective structure modeling. Extensive experiments show that our newly-proposed model achieves new state-of-the-art results on popular benchmarks. To our best knowledge, it is the first work on code summarization that uses Transformer to model structural information with high efficiency and no extra parameters. We also provide a tutorial on how we pre-process.
VDB-EDT: An Efficient Euclidean Distance Transform Algorithm Based on VDB Data Structure
May 10, 2021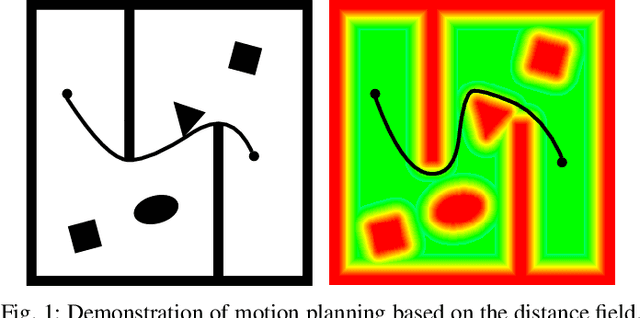
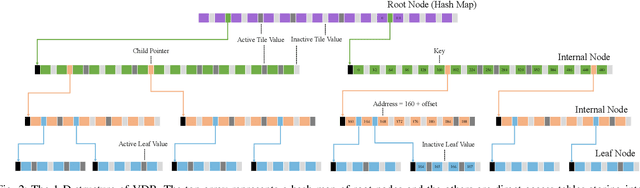
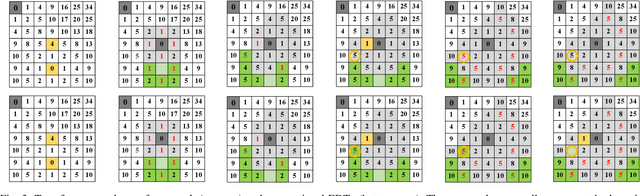
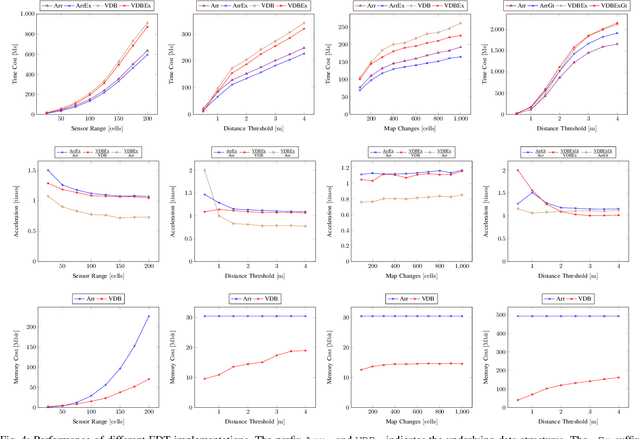
This paper presents a fundamental algorithm, called VDB-EDT, for Euclidean distance transform (EDT) based on the VDB data structure. The algorithm executes on grid maps and generates the corresponding distance field for recording distance information against obstacles, which forms the basis of numerous motion planning algorithms. The contributions of this work mainly lie in three folds. Firstly, we propose a novel algorithm that can facilitate distance transform procedures by optimizing the scheduling priorities of transform functions, which significantly improves the running speed of conventional EDT algorithms. Secondly, we for the first time introduce the memory-efficient VDB data structure, a customed B+ tree, to represent the distance field hierarchically. Benefiting from the special index and caching mechanism, VDB shows a fast (average \textit{O}(1)) random access speed, and thus is very suitable for the frequent neighbor-searching operations in EDT. Moreover, regarding the small scale of existing datasets, we release a large-scale dataset captured from subterranean environments to benchmark EDT algorithms. Extensive experiments on the released dataset and publicly available datasets show that VDB-EDT can reduce memory consumption by about 30%-85%, depending on the sparsity of the environment, while maintaining a competitive running speed with the fastest array-based implementation. The experiments also show that VDB-EDT can significantly outperform the state-of-the-art EDT algorithm in both runtime and memory efficiency, which strongly demonstrates the advantages of our proposed method. The released dataset and source code are available on https://github.com/zhudelong/VDB-EDT.