 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatial Context based Angular Information Preserving Projection for Hyperspectral Image Classification
Jul 15, 2016
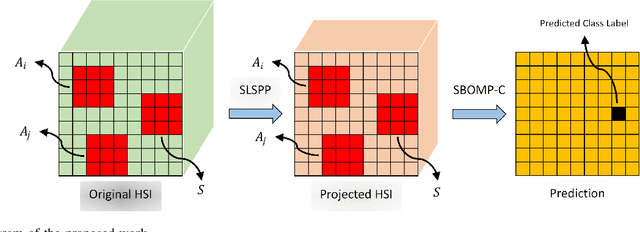
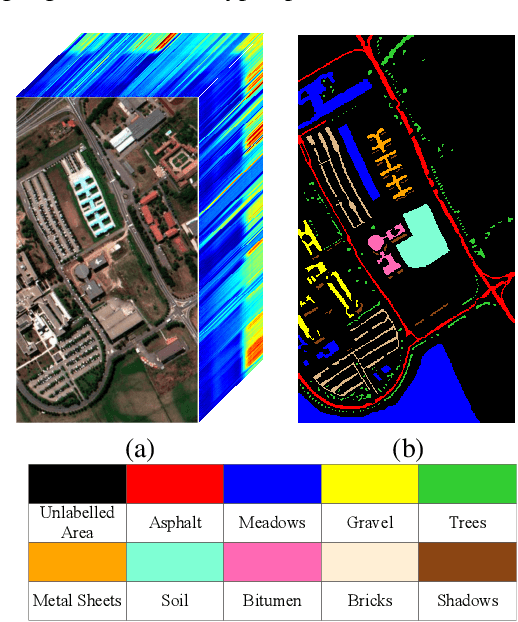

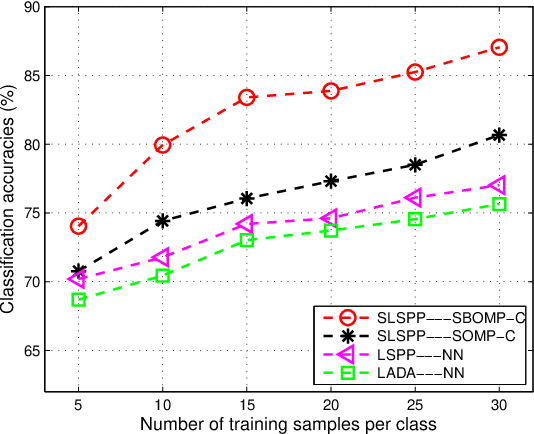
Dimensionality reduction is a crucial preprocessing for hyperspectral data analysis - finding an appropriate subspace is often required for subsequent image classification. In recent work, we proposed supervised angular information based dimensionality reduction methods to find effective subspaces. Since unlabeled data are often more readily available compared to labeled data, we propose an unsupervised projection that finds a lower dimensional subspace where local angular information is preserved. To exploit spatial information from the hyperspectral images, we further extend our unsupervised projection to incorporate spatial contextual information around each pixel in the image. Additionally, we also propose a sparse representation based classifier which is optimized to exploit spatial information during classification - we hence assert that our proposed projection is particularly suitable for classifiers where local similarity and spatial context are both important. Experimental results with two real-world hyperspectral datasets demonstrate that our proposed methods provide a robust classification performance.
3D Registration of Curves and Surfaces using Local Differential Information
Apr 02, 2018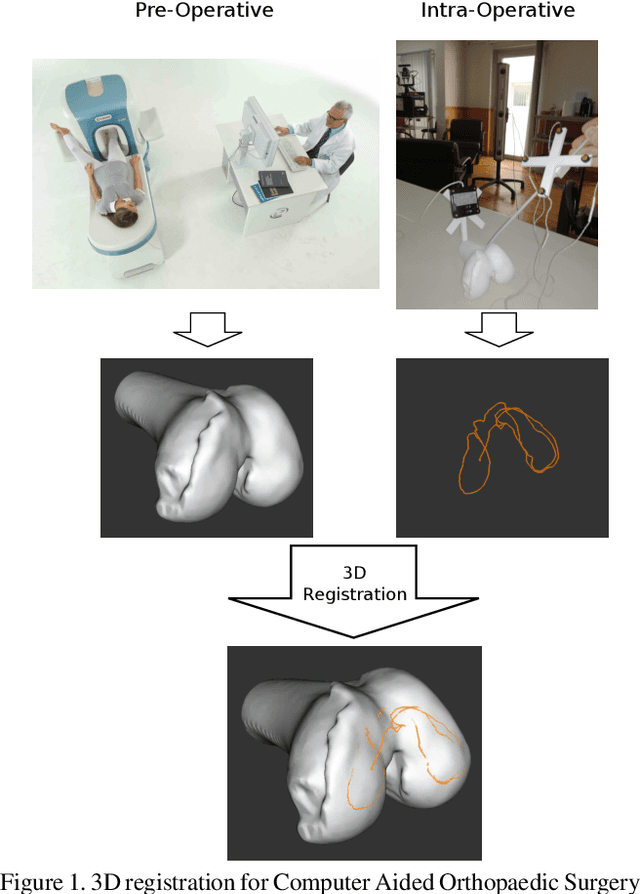
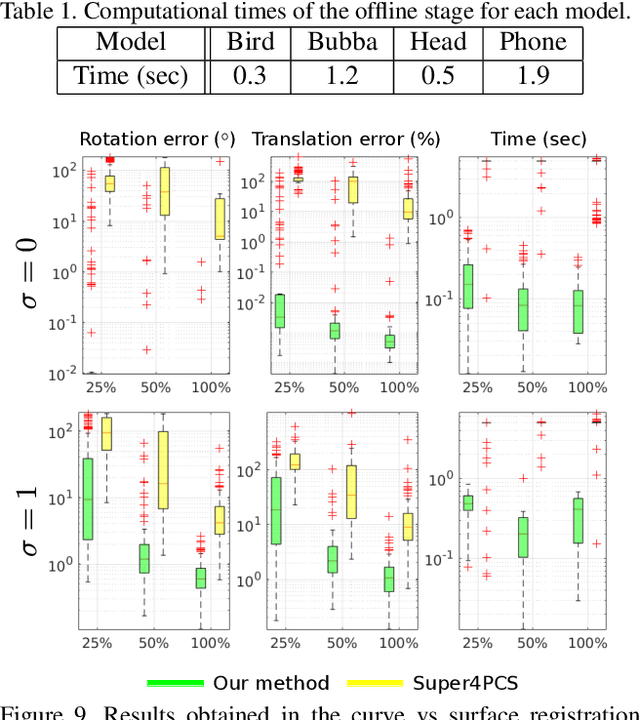

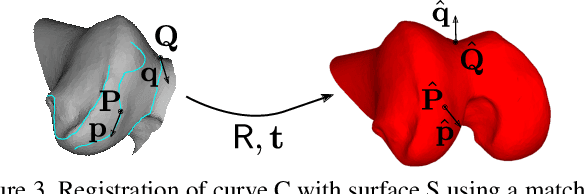
This article presents for the first time a global method for registering 3D curves with 3D surfaces without requiring an initialization. The algorithm works with 2-tuples point+vector that consist in pairs of points augmented with the information of their tangents or normals. A closed-form solution for determining the alignment transformation from a pair of matching 2-tuples is proposed. In addition, the set of necessary conditions for two 2-tuples to match is derived. This allows fast search of correspondences that are used in an hypothesise-and-test framework for accomplishing global registration. Comparative experiments demonstrate that the proposed algorithm is the first effective solution for curve vs surface registration, with the method achieving accurate alignment in situations of small overlap and large percentage of outliers in a fraction of a second. The proposed framework is extended to the cases of curve vs curve and surface vs surface registration, with the former being particularly relevant since it is also a largely unsolved problem.
"How to rate a video game?" - A prediction system for video games based on multimodal information
May 29, 2018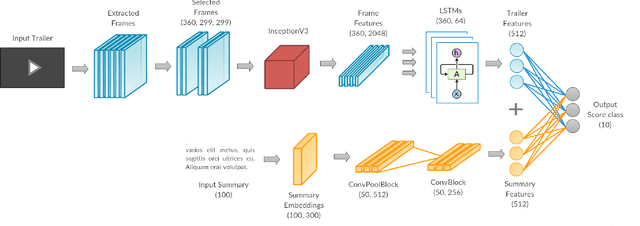
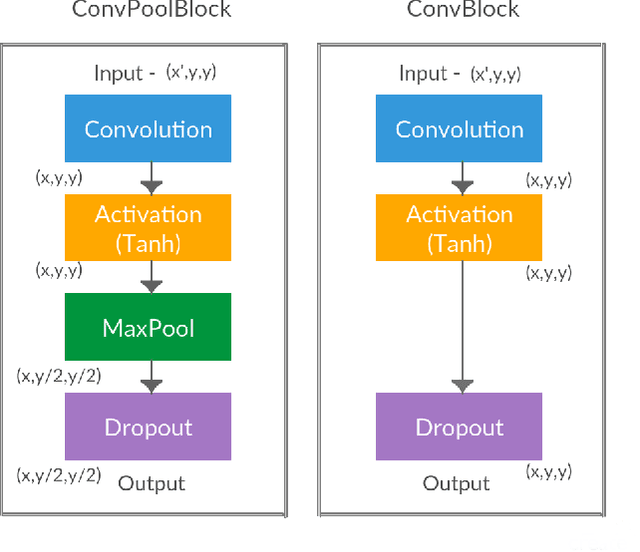

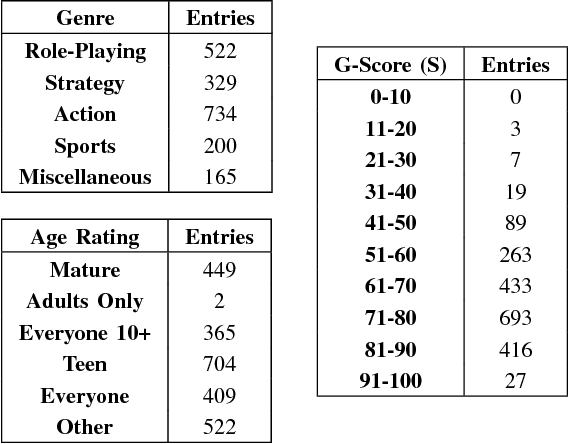
Video games have become an integral part of most people's lives in recent times. This led to an abundance of data related to video games being shared online. However, this comes with issues such as incorrect ratings, reviews or anything that is being shared. Recommendation systems are powerful tools that help users by providing them with meaningful recommendations. A straightforward approach would be to predict the scores of video games based on other information related to the game. It could be used as a means to validate user-submitted ratings as well as provide recommendations. This work provides a method to predict the G-Score, that defines how good a video game is, from its trailer (video) and summary (text). We first propose models to predict the G-Score based on the trailer alone (unimodal). Later on, we show that considering information from multiple modalities helps the models perform better compared to using information from videos alone. Since we couldn't find any suitable multimodal video game dataset, we created our own dataset named VGD (Video Game Dataset) and provide it along with this work. The approach mentioned here can be generalized to other multimodal datasets such as movie trailers and summaries etc. Towards the end, we talk about the shortcomings of the work and some methods to overcome them.
Gaussian Process Based Message Filtering for Robust Multi-Agent Cooperation in the Presence of Adversarial Communication
Dec 01, 2020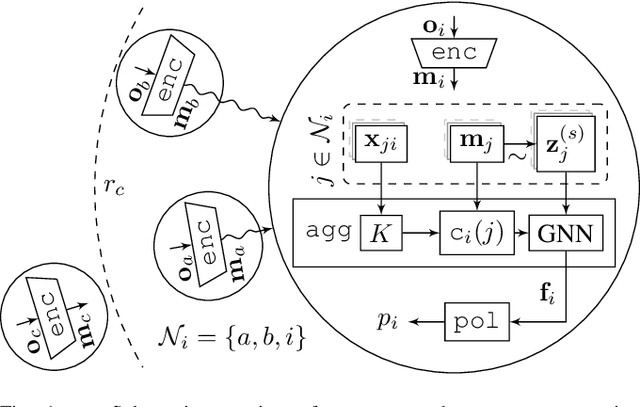
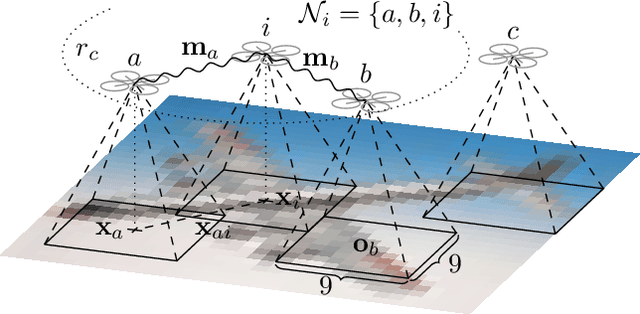
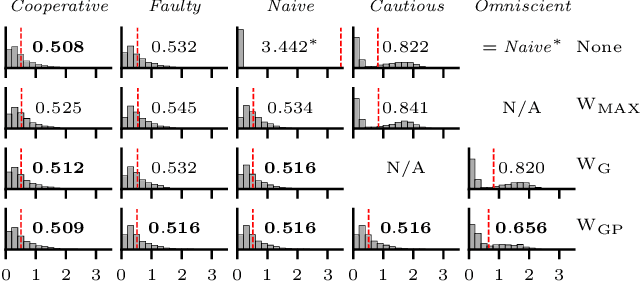

In this paper, we consider the problem of providing robustness to adversarial communication in multi-agent systems. Specifically, we propose a solution towards robust cooperation, which enables the multi-agent system to maintain high performance in the presence of anonymous non-cooperative agents that communicate faulty, misleading or manipulative information. In pursuit of this goal, we propose a communication architecture based on Graph Neural Networks (GNNs), which is amenable to a novel Gaussian Process (GP)-based probabilistic model characterizing the mutual information between the simultaneous communications of different agents due to their physical proximity and relative position. This model allows agents to locally compute approximate posterior probabilities, or confidences, that any given one of their communication partners is being truthful. These confidences can be used as weights in a message filtering scheme, thereby suppressing the influence of suspicious communication on the receiving agent's decisions. In order to assess the efficacy of our method, we introduce a taxonomy of non-cooperative agents, which distinguishes them by the amount of information available to them. We demonstrate in two distinct experiments that our method performs well across this taxonomy, outperforming alternative methods. For all but the best informed adversaries, our filtering method is able to reduce the impact that non-cooperative agents cause, reducing it to the point of negligibility, and with negligible cost to performance in the absence of adversaries.
Tensor Networks for Multi-Modal Non-Euclidean Data
Mar 27, 2021
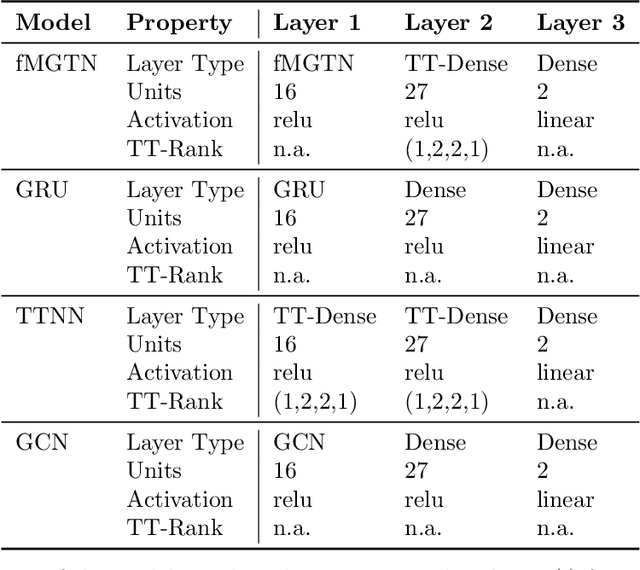
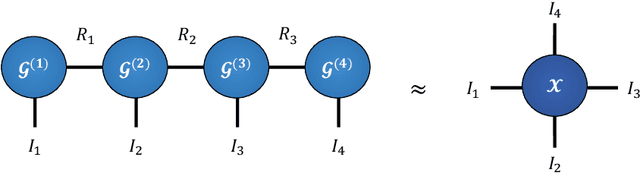
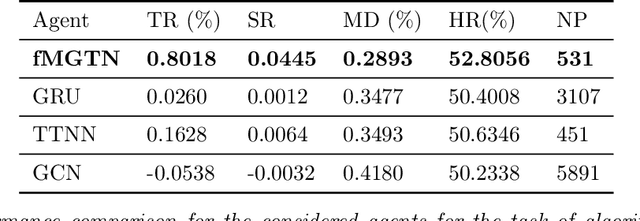
Modern data sources are typically of large scale and multi-modal natures, and acquired on irregular domains, which poses serious challenges to traditional deep learning models. These issues are partially mitigated by either extending existing deep learning algorithms to irregular domains through graphs, or by employing tensor methods to alleviate the computational bottlenecks imposed by the Curse of Dimensionality. To simultaneously resolve both these issues, we introduce a novel Multi-Graph Tensor Network (MGTN) framework, which leverages on the desirable properties of graphs, tensors and neural networks in a physically meaningful and compact manner. This equips MGTNs with the ability to exploit local information in irregular data sources at a drastically reduced parameter complexity, and over a range of learning paradigms such as regression, classification and reinforcement learning. The benefits of the MGTN framework, especially its ability to avoid overfitting through the inherent low-rank regularization properties of tensor networks, are demonstrated through its superior performance against competing models in the individual tensor, graph, and neural network domains.
A Video Is Worth Three Views: Trigeminal Transformers for Video-based Person Re-identification
Apr 05, 2021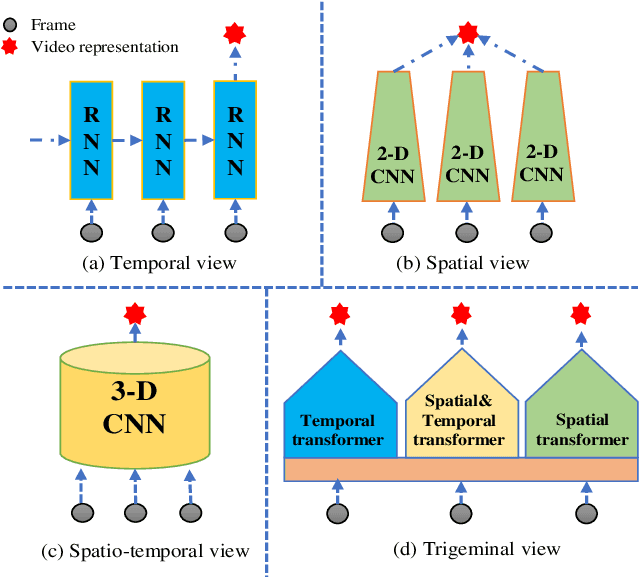
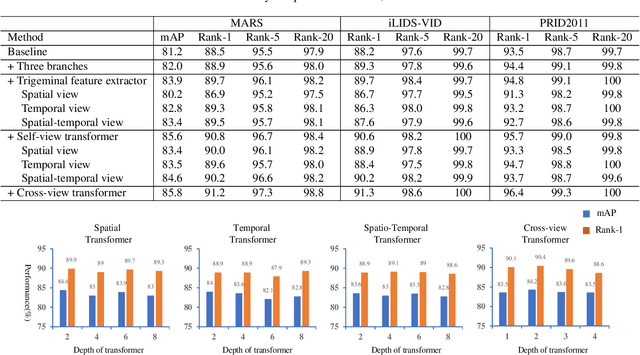
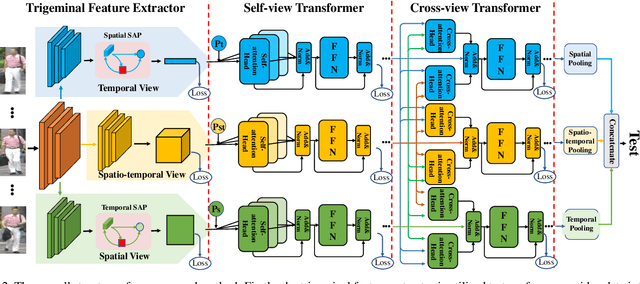
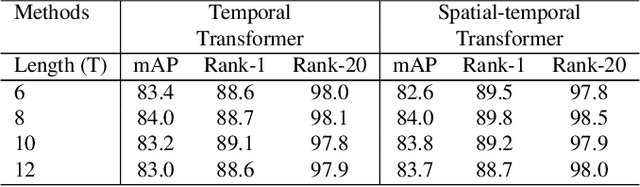
Video-based person re-identification (Re-ID) aims to retrieve video sequences of the same person under non-overlapping cameras. Previous methods usually focus on limited views, such as spatial, temporal or spatial-temporal view, which lack of the observations in different feature domains. To capture richer perceptions and extract more comprehensive video representations, in this paper we propose a novel framework named Trigeminal Transformers (TMT) for video-based person Re-ID. More specifically, we design a trigeminal feature extractor to jointly transform raw video data into spatial, temporal and spatial-temporal domain. Besides, inspired by the great success of vision transformer, we introduce the transformer structure for video-based person Re-ID. In our work, three self-view transformers are proposed to exploit the relationships between local features for information enhancement in spatial, temporal and spatial-temporal domains. Moreover, a cross-view transformer is proposed to aggregate the multi-view features for comprehensive video representations. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches on public Re-ID benchmarks. We will release the code for model reproduction.
Opportunistic Screening of Osteoporosis Using Plain Film Chest X-ray
Apr 05, 2021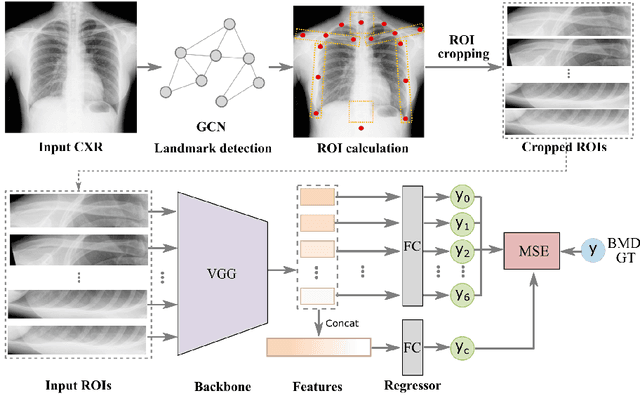
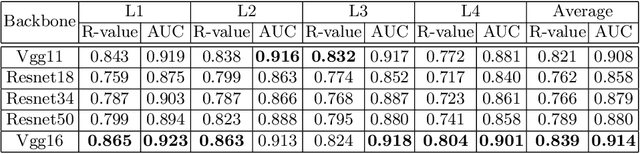
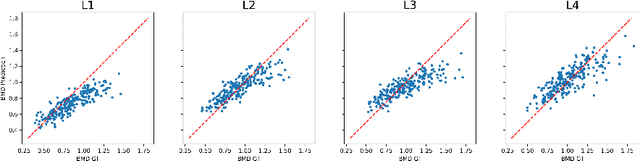
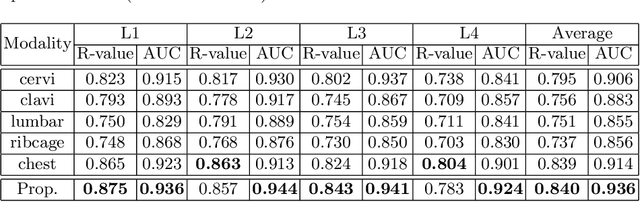
Osteoporosis is a common chronic metabolic bone disease that is often under-diagnosed and under-treated due to the limited access to bone mineral density (BMD) examinations, Dual-energy X-ray Absorptiometry (DXA). In this paper, we propose a method to predict BMD from Chest X-ray (CXR), one of the most common, accessible, and low-cost medical image examinations. Our method first automatically detects Regions of Interest (ROIs) of local and global bone structures from the CXR. Then a multi-ROI model is developed to exploit both local and global information in the chest X-ray image for accurate BMD estimation. Our method is evaluated on 329 CXR cases with ground truth BMD measured by DXA. The model predicted BMD has a strong correlation with the gold standard DXA BMD (Pearson correlation coefficient 0.840). When applied for osteoporosis screening, it achieves a high classification performance (AUC 0.936). As the first effort in the field to use CXR scans to predict the spine BMD, the proposed algorithm holds strong potential in enabling early osteoporosis screening through routine chest X-rays and contributing to the enhancement of public health.
Cloth Interactive Transformer for Virtual Try-On
Apr 12, 20212D image-based virtual try-on has attracted increased attention from the multimedia and computer vision communities. However, most of the existing image-based virtual try-on methods directly put both person and the in-shop clothing representations together, without considering the mutual correlation between them. What is more, the long-range information, which is crucial for generating globally consistent results, is also hard to be established via the regular convolution operation. To alleviate these two problems, in this paper we propose a novel two-stage Cloth Interactive Transformer (CIT) for virtual try-on. In the first stage, we design a CIT matching block, aiming to perform a learnable thin-plate spline transformation that can capture more reasonable long-range relation. As a result, the warped in-shop clothing looks more natural. In the second stage, we propose a novel CIT reasoning block for establishing the global mutual interactive dependence. Based on this mutual dependence, the significant region within the input data can be highlighted, and consequently, the try-on results can become more realistic. Extensive experiments on a public fashion dataset demonstrate that our CIT can achieve the new state-of-the-art virtual try-on performance both qualitatively and quantitatively. The source code and trained models are available at https://github.com/Amazingren/CIT.
Neural Networks for Semantic Gaze Analysis in XR Settings
Mar 18, 2021
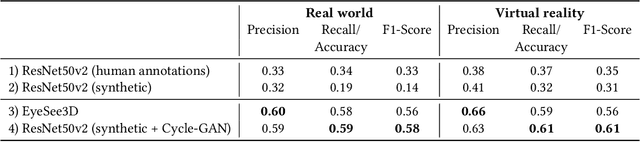
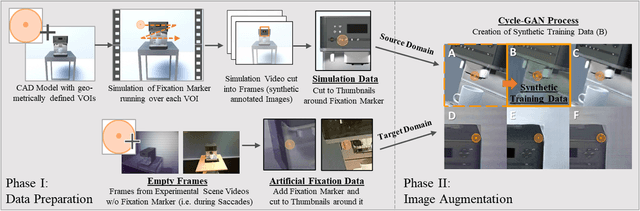
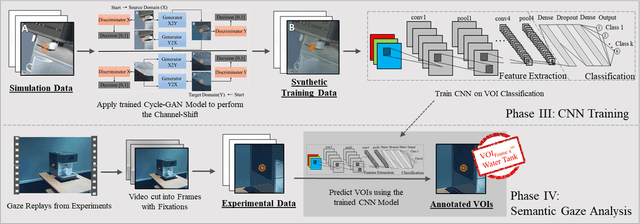
Virtual-reality (VR) and augmented-reality (AR) technology is increasingly combined with eye-tracking. This combination broadens both fields and opens up new areas of application, in which visual perception and related cognitive processes can be studied in interactive but still well controlled settings. However, performing a semantic gaze analysis of eye-tracking data from interactive three-dimensional scenes is a resource-intense task, which so far has been an obstacle to economic use. In this paper we present a novel approach which minimizes time and information necessary to annotate volumes of interest (VOIs) by using techniques from object recognition. To do so, we train convolutional neural networks (CNNs) on synthetic data sets derived from virtual models using image augmentation techniques. We evaluate our method in real and virtual environments, showing that the method can compete with state-of-the-art approaches, while not relying on additional markers or preexisting databases but instead offering cross-platform use.
Neural Multi-Hop Reasoning With Logical Rules on Biomedical Knowledge Graphs
Mar 18, 2021

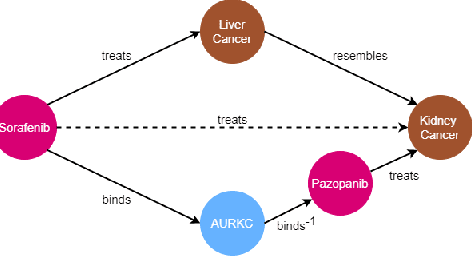

Biomedical knowledge graphs permit an integrative computational approach to reasoning about biological systems. The nature of biological data leads to a graph structure that differs from those typically encountered in benchmarking datasets. To understand the implications this may have on the performance of reasoning algorithms, we conduct an empirical study based on the real-world task of drug repurposing. We formulate this task as a link prediction problem where both compounds and diseases correspond to entities in a knowledge graph. To overcome apparent weaknesses of existing algorithms, we propose a new method, PoLo, that combines policy-guided walks based on reinforcement learning with logical rules. These rules are integrated into the algorithm by using a novel reward function. We apply our method to Hetionet, which integrates biomedical information from 29 prominent bioinformatics databases. Our experiments show that our approach outperforms several state-of-the-art methods for link prediction while providing interpretability.