 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Visualisation System for Construction Building Information Models Using Saliency
Mar 07, 2016
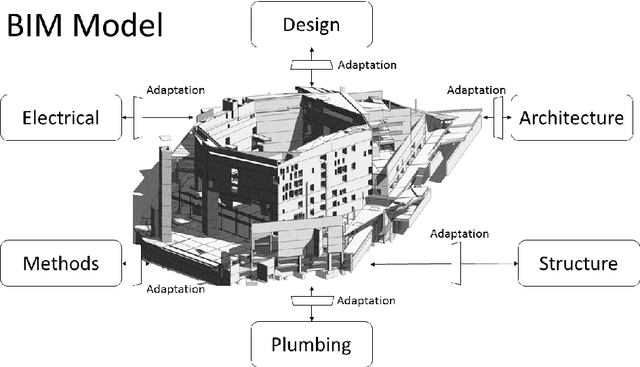


Building Information Modeling (BIM) is a recent construction process based on a 3D model, containing every component related to the building achievement. Architects, structure engineers, method engineers, and others participant to the building process work on this model through the design-to-construction cycle. The high complexity and the large amount of information included in these models raise several issues, delaying its wide adoption in the industrial world. One of the most important is the visualization: professionals have difficulties to find out the relevant information for their job. Actual solutions suffer from two limitations: the BIM models information are processed manually and insignificant information are simply hidden, leading to inconsistencies in the building model. This paper describes a system relying on an ontological representation of the building information to label automatically the building elements. Depending on the user's department, the visualization is modified according to these labels by automatically adjusting the colors and image properties based on a saliency model. The proposed saliency model incorporates several adaptations to fit the specificities of architectural images.
Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone
Apr 12, 2021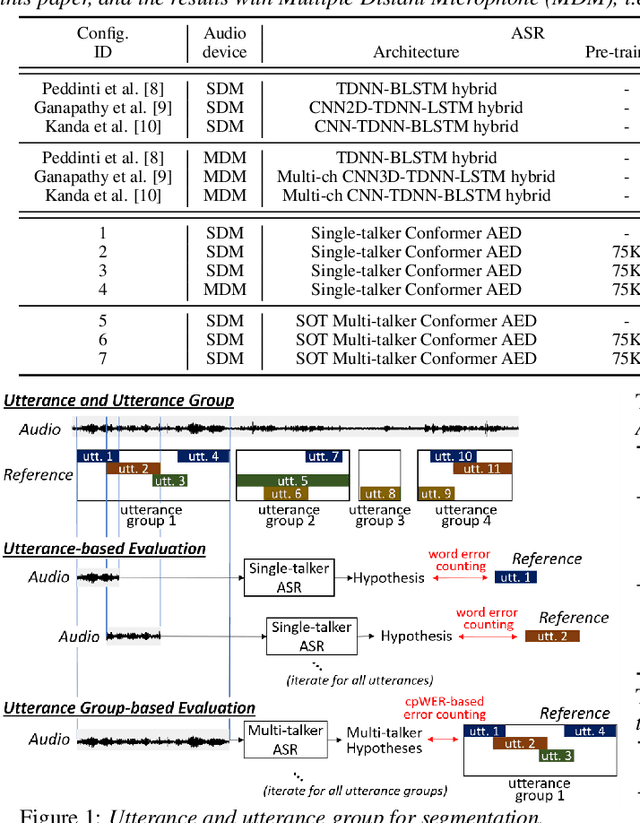


Transcribing meetings containing overlapped speech with only a single distant microphone (SDM) has been one of the most challenging problems for automatic speech recognition (ASR). While various approaches have been proposed, all previous studies on the monaural overlapped speech recognition problem were based on either simulation data or small-scale real data. In this paper, we extensively investigate a two-step approach where we first pre-train a serialized output training (SOT)-based multi-talker ASR by using large-scale simulation data and then fine-tune the model with a small amount of real meeting data. Experiments are conducted by utilizing 75 thousand (K) hours of our internal single-talker recording to simulate a total of 900K hours of multi-talker audio segments for supervised pre-training. With fine-tuning on the 70 hours of the AMI-SDM training data, our SOT ASR model achieves a word error rate (WER) of 21.2% for the AMI-SDM evaluation set while automatically counting speakers in each test segment. This result is not only significantly better than the previous state-of-the-art WER of 36.4% with oracle utterance boundary information but also better than a result by a similarly fine-tuned single-talker ASR model applied to beamformed audio.
Towards Explaining Expressive Qualities in Piano Recordings: Transfer of Explanatory Features via Acoustic Domain Adaptation
Feb 26, 2021



Emotion and expressivity in music have been topics of considerable interest in the field of music information retrieval. In recent years, mid-level perceptual features have been suggested as means to explain computational predictions of musical emotion. We find that the diversity of musical styles and genres in the available dataset for learning these features is not sufficient for models to generalise well to specialised acoustic domains such as solo piano music. In this work, we show that by utilising unsupervised domain adaptation together with receptive-field regularised deep neural networks, it is possible to significantly improve generalisation to this domain. Additionally, we demonstrate that our domain-adapted models can better predict and explain expressive qualities in classical piano performances, as perceived and described by human listeners.
CellTrack R-CNN: A Novel End-To-End Deep Neural Network for Cell Segmentation and Tracking in Microscopy Images
Feb 20, 2021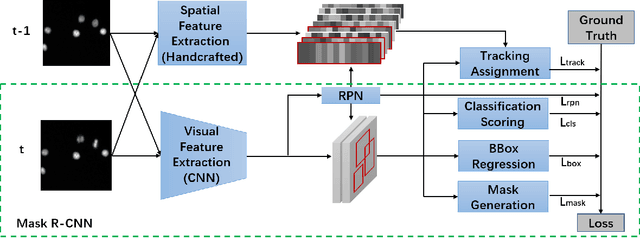
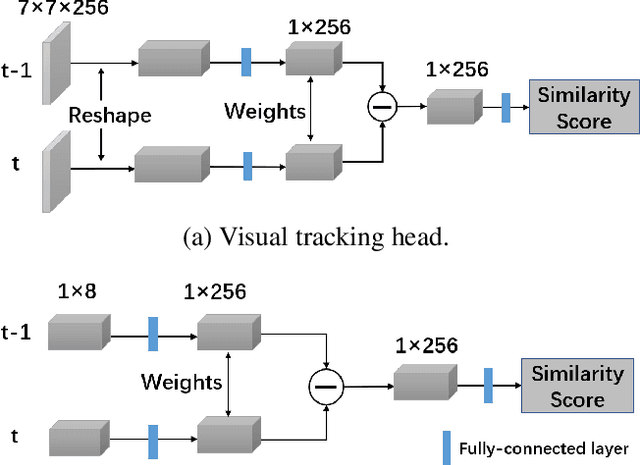
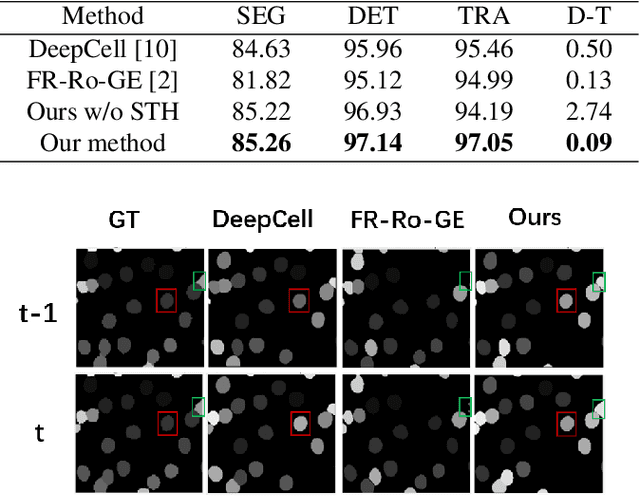
Cell segmentation and tracking in microscopy images are of great significance to new discoveries in biology and medicine. In this study, we propose a novel approach to combine cell segmentation and cell tracking into a unified end-to-end deep learning based framework, where cell detection and segmentation are performed with a current instance segmentation pipeline and cell tracking is implemented by integrating Siamese Network with the pipeline. Besides, tracking performance is improved by incorporating spatial information into the network and fusing spatial and visual prediction. Our approach was evaluated on the DeepCell benchmark dataset. Despite being simple and efficient, our method outperforms state-of-the-art algorithms in terms of both cell segmentation and cell tracking accuracies.
Scalable Visual Transformers with Hierarchical Pooling
Mar 19, 2021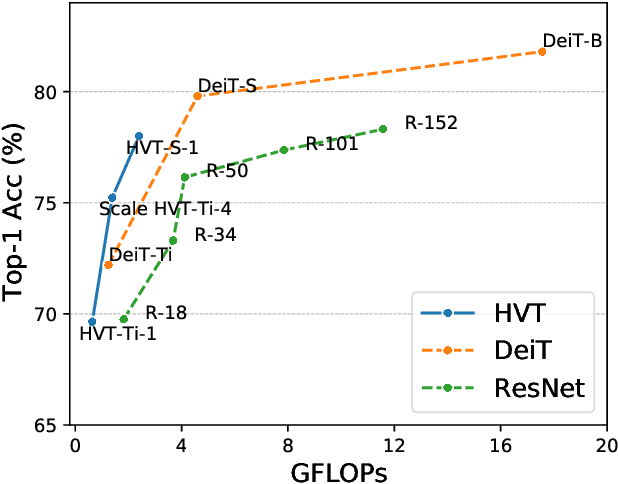

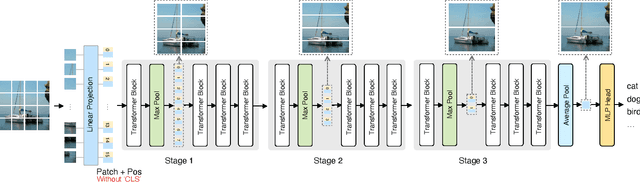

The recently proposed Visual image Transformers (ViT) with pure attention have achieved promising performance on image recognition tasks, such as image classification. However, the routine of the current ViT model is to maintain a full-length patch sequence during inference, which is redundant and lacks hierarchical representation. To this end, we propose a Hierarchical Visual Transformer (HVT) which progressively pools visual tokens to shrink the sequence length and hence reduces the computational cost, analogous to the feature maps downsampling in Convolutional Neural Networks (CNNs). It brings a great benefit that we can increase the model capacity by scaling dimensions of depth/width/resolution/patch size without introducing extra computational complexity due to the reduced sequence length. Moreover, we empirically find that the average pooled visual tokens contain more discriminative information than the single class token. To demonstrate the improved scalability of our HVT, we conduct extensive experiments on the image classification task. With comparable FLOPs, our HVT outperforms the competitive baselines on ImageNet and CIFAR-100 datasets.
Malware Classification with Word Embedding Features
Mar 03, 2021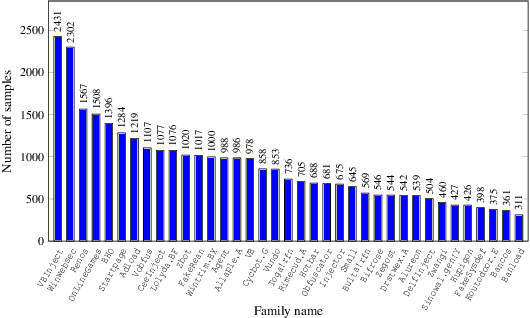
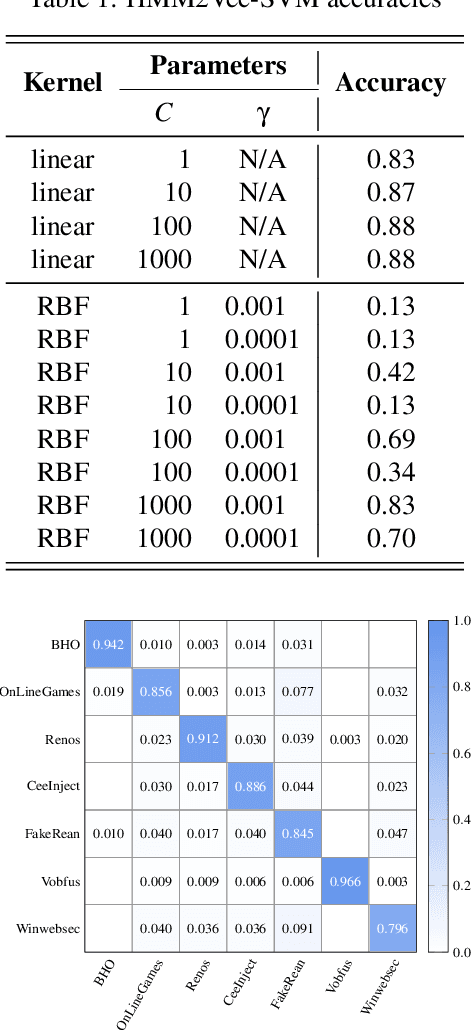
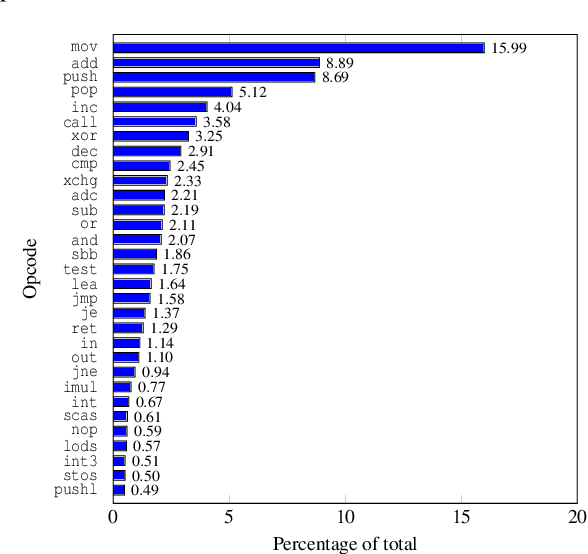

Malware classification is an important and challenging problem in information security. Modern malware classification techniques rely on machine learning models that can be trained on features such as opcode sequences, API calls, and byte $n$-grams, among many others. In this research, we consider opcode features. We implement hybrid machine learning techniques, where we engineer feature vectors by training hidden Markov models -- a technique that we refer to as HMM2Vec -- and Word2Vec embeddings on these opcode sequences. The resulting HMM2Vec and Word2Vec embedding vectors are then used as features for classification algorithms. Specifically, we consider support vector machine (SVM), $k$-nearest neighbor ($k$-NN), random forest (RF), and convolutional neural network (CNN) classifiers. We conduct substantial experiments over a variety of malware families. Our experiments extend well beyond any previous work in this field.
Semi-Automatic Video Annotation For Object Detection
Jan 24, 2021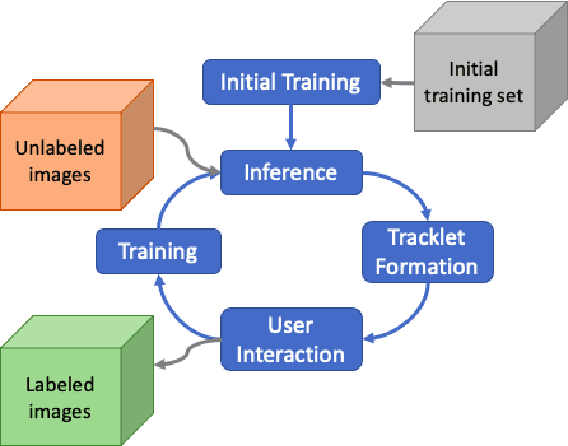
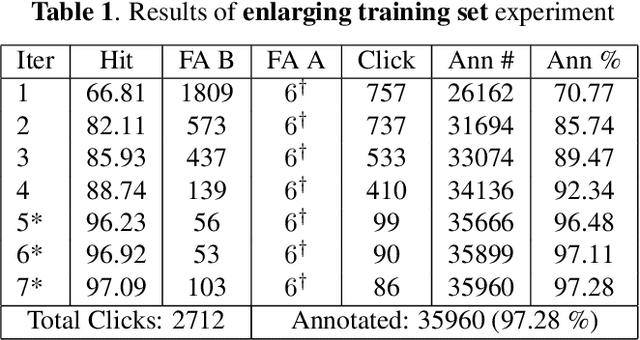

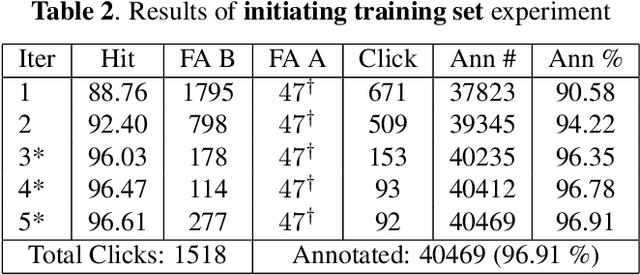
In this study, a semi-automatic video annotation method is proposed which utilizes temporal information to eliminate false-positives with a tracking-by-detection approach by employing multiple hypothesis tracking (MHT). MHT method automatically forms tracklets which are confirmed by human operators to enlarge the training set. A novel incremental learning approach helps to annotate videos in an iterative way. The experiments performed on AUTH Multidrone Dataset reveals that the annotation workload can be reduced up to 96% by the proposed approach.
A Video Is Worth Three Views: Trigeminal Transformers for Video-based Person Re-identification
Apr 05, 2021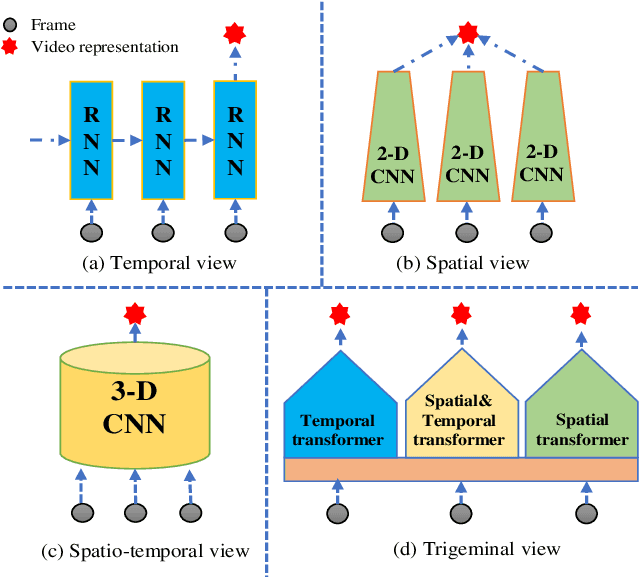
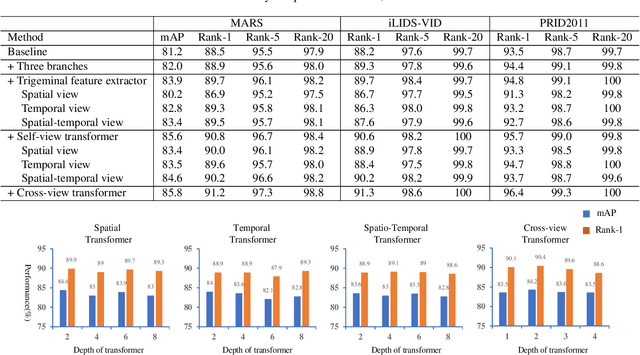
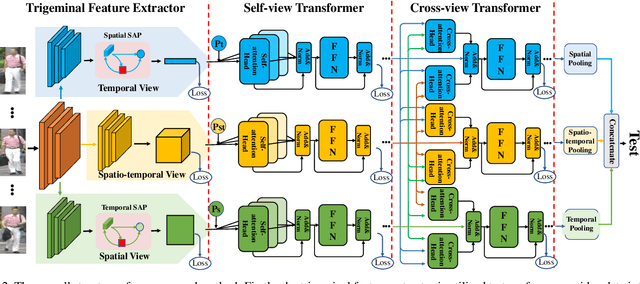
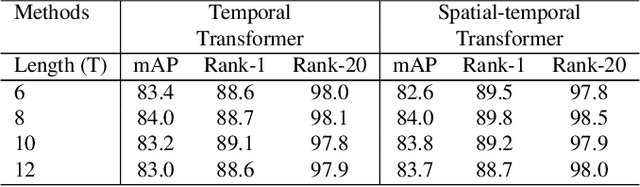
Video-based person re-identification (Re-ID) aims to retrieve video sequences of the same person under non-overlapping cameras. Previous methods usually focus on limited views, such as spatial, temporal or spatial-temporal view, which lack of the observations in different feature domains. To capture richer perceptions and extract more comprehensive video representations, in this paper we propose a novel framework named Trigeminal Transformers (TMT) for video-based person Re-ID. More specifically, we design a trigeminal feature extractor to jointly transform raw video data into spatial, temporal and spatial-temporal domain. Besides, inspired by the great success of vision transformer, we introduce the transformer structure for video-based person Re-ID. In our work, three self-view transformers are proposed to exploit the relationships between local features for information enhancement in spatial, temporal and spatial-temporal domains. Moreover, a cross-view transformer is proposed to aggregate the multi-view features for comprehensive video representations. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches on public Re-ID benchmarks. We will release the code for model reproduction.
Rule-Based Approach for Party-Based SentimentAnalysis in Legal Opinion Texts
Nov 11, 2020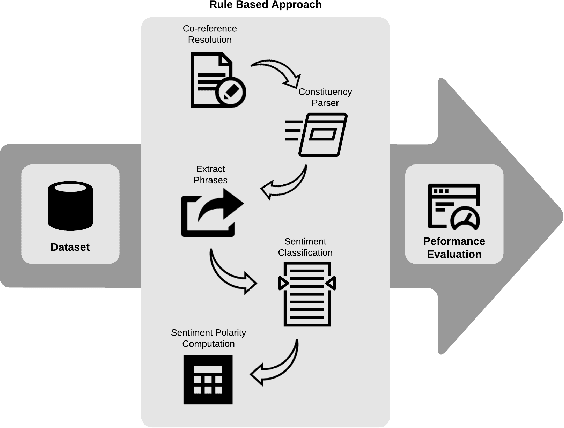
A document which elaborates opinions and arguments related to the previous court cases is known as a legal opinion text. Lawyers and legal officials have to spend considerable effort and time to obtain the required information manually from those documents when dealing with new legal cases. Hence, it provides much convenience to those individuals if there is a way to automate the process of extracting information from legal opinion texts. Party-based sentiment analysis will play a key role in the automation system by identifying opinion values with respect to each legal parties in legal texts.
Cloth Interactive Transformer for Virtual Try-On
Apr 12, 20212D image-based virtual try-on has attracted increased attention from the multimedia and computer vision communities. However, most of the existing image-based virtual try-on methods directly put both person and the in-shop clothing representations together, without considering the mutual correlation between them. What is more, the long-range information, which is crucial for generating globally consistent results, is also hard to be established via the regular convolution operation. To alleviate these two problems, in this paper we propose a novel two-stage Cloth Interactive Transformer (CIT) for virtual try-on. In the first stage, we design a CIT matching block, aiming to perform a learnable thin-plate spline transformation that can capture more reasonable long-range relation. As a result, the warped in-shop clothing looks more natural. In the second stage, we propose a novel CIT reasoning block for establishing the global mutual interactive dependence. Based on this mutual dependence, the significant region within the input data can be highlighted, and consequently, the try-on results can become more realistic. Extensive experiments on a public fashion dataset demonstrate that our CIT can achieve the new state-of-the-art virtual try-on performance both qualitatively and quantitatively. The source code and trained models are available at https://github.com/Amazingren/CIT.