 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Feature Disentanglement in Imaging Data via Joint Invariant Variational Autoencoders: from Cards to Atoms
Apr 20, 2021

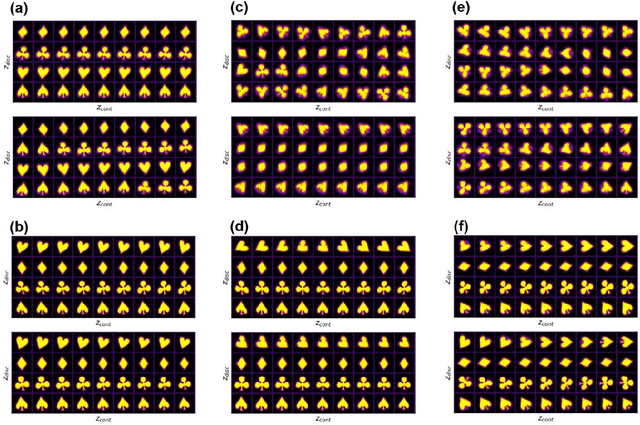
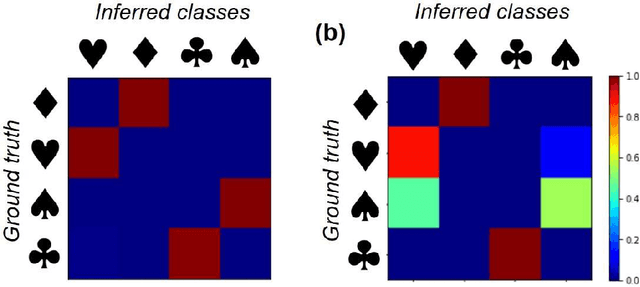
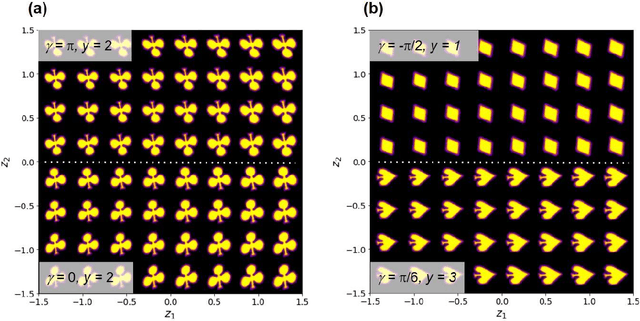
Recent advances in imaging from celestial objects in astronomy visualized via optical and radio telescopes to atoms and molecules resolved via electron and probe microscopes are generating immense volumes of imaging data, containing information about the structure of the universe from atomic to astronomic levels. The classical deep convolutional neural network architectures traditionally perform poorly on the data sets having a significant orientational disorder, that is, having multiple copies of the same or similar object in arbitrary orientation in the image plane. Similarly, while clustering methods are well suited for classification into discrete classes and manifold learning and variational autoencoders methods can disentangle representations of the data, the combined problem is ill-suited to a classical non-supervised learning paradigm. Here we introduce a joint rotationally (and translationally) invariant variational autoencoder (j-trVAE) that is ideally suited to the solution of such a problem. The performance of this method is validated on several synthetic data sets and extended to high-resolution imaging data of electron and scanning probe microscopy. We show that latent space behaviors directly comport to the known physics of ferroelectric materials and quantum systems. We further note that the engineering of the latent space structure via imposed topological structure or directed graph relationship allows for applications in topological discovery and causal physical learning.
A Framework for Deep Constrained Clustering
Jan 07, 2021

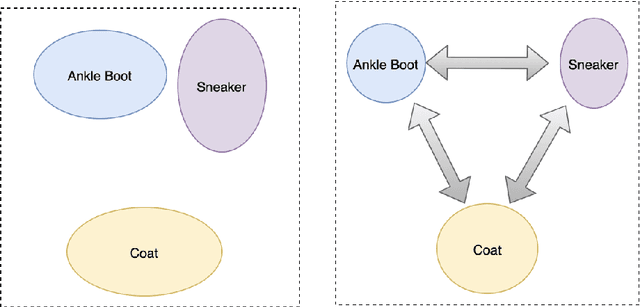
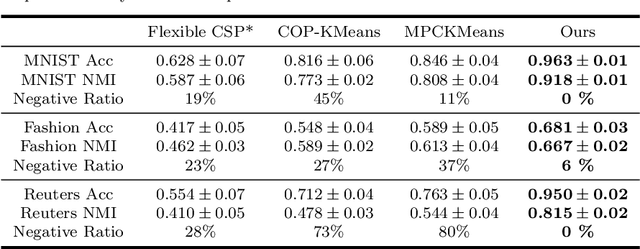
The area of constrained clustering has been extensively explored by researchers and used by practitioners. Constrained clustering formulations exist for popular algorithms such as k-means, mixture models, and spectral clustering but have several limitations. A fundamental strength of deep learning is its flexibility, and here we explore a deep learning framework for constrained clustering and in particular explore how it can extend the field of constrained clustering. We show that our framework can not only handle standard together/apart constraints (without the well documented negative effects reported earlier) generated from labeled side information but more complex constraints generated from new types of side information such as continuous values and high-level domain knowledge. Furthermore, we propose an efficient training paradigm that is generally applicable to these four types of constraints. We validate the effectiveness of our approach by empirical results on both image and text datasets. We also study the robustness of our framework when learning with noisy constraints and show how different components of our framework contribute to the final performance. Our source code is available at $\href{https://github.com/blueocean92/deep_constrained_clustering}{\text{URL}}$.
A Zero Attentive Relevance Matching Networkfor Review Modeling in Recommendation System
Jan 16, 2021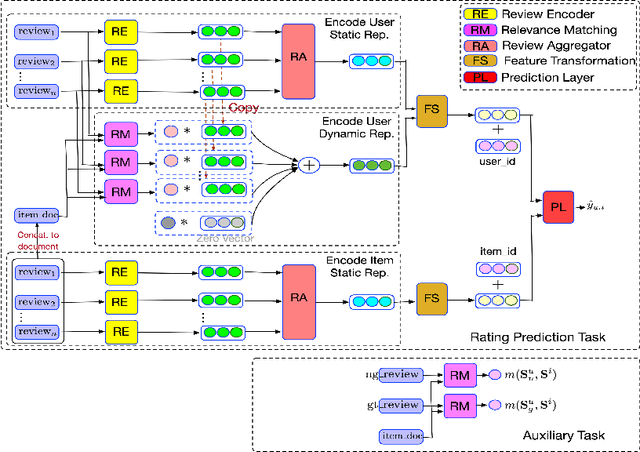
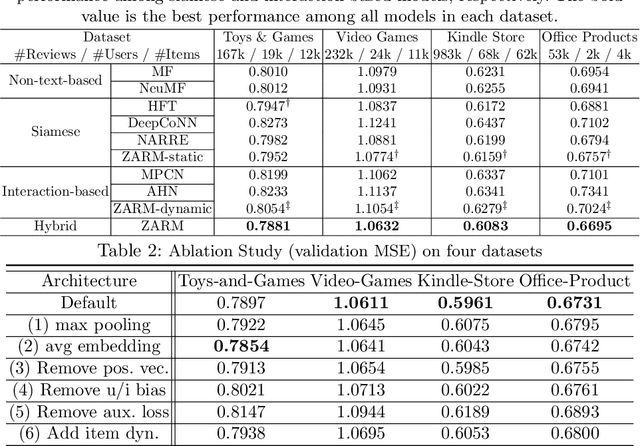
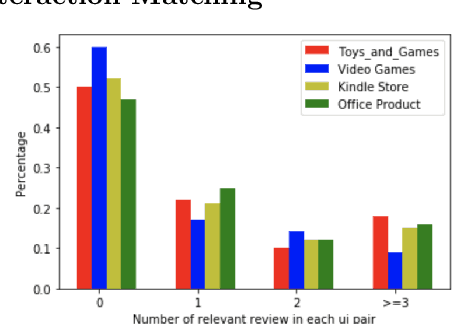
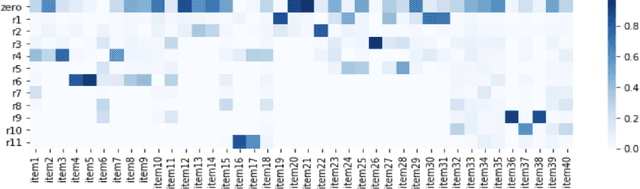
User and item reviews are valuable for the construction of recommender systems. In general, existing review-based methods for recommendation can be broadly categorized into two groups: the siamese models that build static user and item representations from their reviews respectively, and the interaction-based models that encode user and item dynamically according to the similarity or relationships of their reviews. Although the interaction-based models have more model capacity and fit human purchasing behavior better, several problematic model designs and assumptions of the existing interaction-based models lead to its suboptimal performance compared to existing siamese models. In this paper, we identify three problems of the existing interaction-based recommendation models and propose a couple of solutions as well as a new interaction-based model to incorporate review data for rating prediction. Our model implements a relevance matching model with regularized training losses to discover user relevant information from long item reviews, and it also adapts a zero attention strategy to dynamically balance the item-dependent and item-independent information extracted from user reviews. Empirical experiments and case studies on Amazon Product Benchmark datasets show that our model can extract effective and interpretable user/item representations from their reviews and outperforms multiple types of state-of-the-art review-based recommendation models.
Rule-Based Approach for Party-Based SentimentAnalysis in Legal Opinion Texts
Nov 11, 2020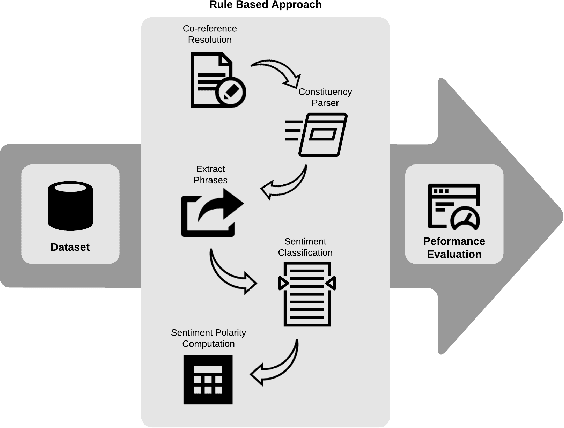
A document which elaborates opinions and arguments related to the previous court cases is known as a legal opinion text. Lawyers and legal officials have to spend considerable effort and time to obtain the required information manually from those documents when dealing with new legal cases. Hence, it provides much convenience to those individuals if there is a way to automate the process of extracting information from legal opinion texts. Party-based sentiment analysis will play a key role in the automation system by identifying opinion values with respect to each legal parties in legal texts.
AxonNet: A self-supervised Deep Neural Network for Intravoxel Structure Estimation from DW-MRI
Mar 19, 2021
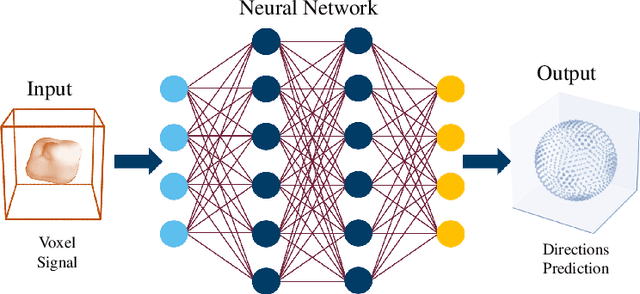
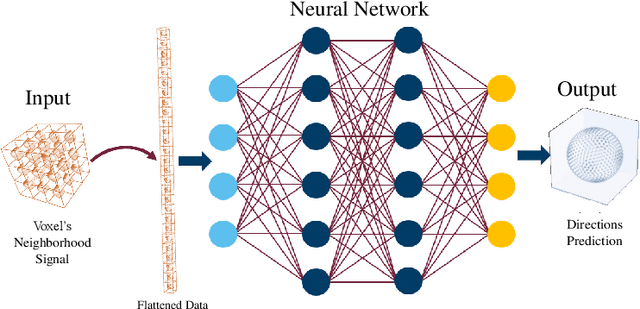
We present a method for estimating intravoxel parameters from a DW-MRI based on deep learning techniques. We show that neural networks (DNNs) have the potential to extract information from diffusion-weighted signals to reconstruct cerebral tracts. We present two DNN models: one that estimates the axonal structure in the form of a voxel and the other to calculate the structure of the central voxel using the voxel neighborhood. Our methods are based on a proposed parameter representation suitable for the problem. Since it is practically impossible to have real tagged data for any acquisition protocol, we used a self-supervised strategy. Experiments with synthetic data and real data show that our approach is competitive, and the computational times show that our approach is faster than the SOTA methods, even if training times are considered. This computational advantage increases if we consider the prediction of multiple images with the same acquisition protocol.
Despeckling Sentinel-1 GRD images by deep learning and application to narrow river segmentation
Feb 01, 2021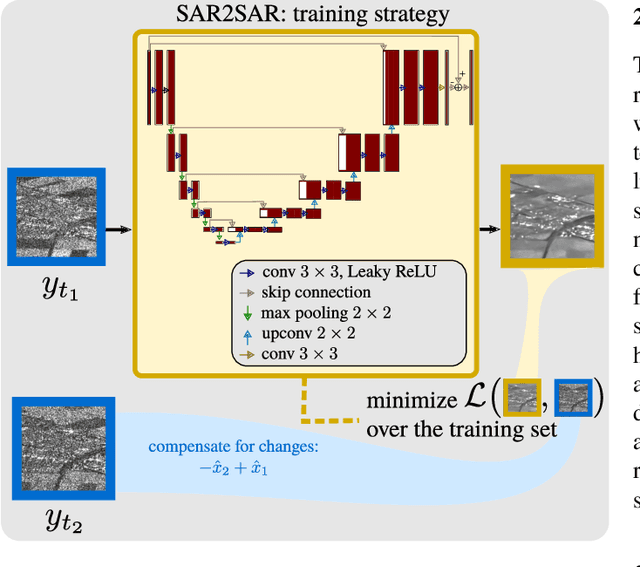


This paper presents a despeckling method for Sentinel-1 GRD images based on the recently proposed framework "SAR2SAR": a self-supervised training strategy. Training the deep neural network on collections of Sentinel 1 GRD images leads to a despeckling algorithm that is robust to space-variant spatial correlations of speckle. Despeckled images improve the detection of structures like narrow rivers. We apply a detector based on exogenous information and a linear features detector and show that rivers are better segmented when the processing chain is applied to images pre-processed by our despeckling neural network.
Recent Advances in Deep Learning-based Dialogue Systems
May 13, 2021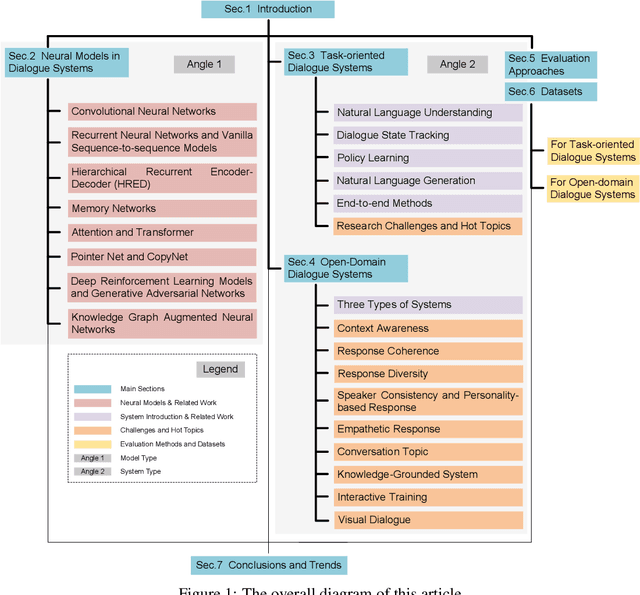
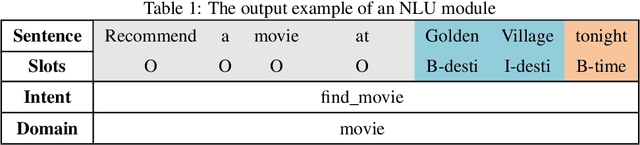
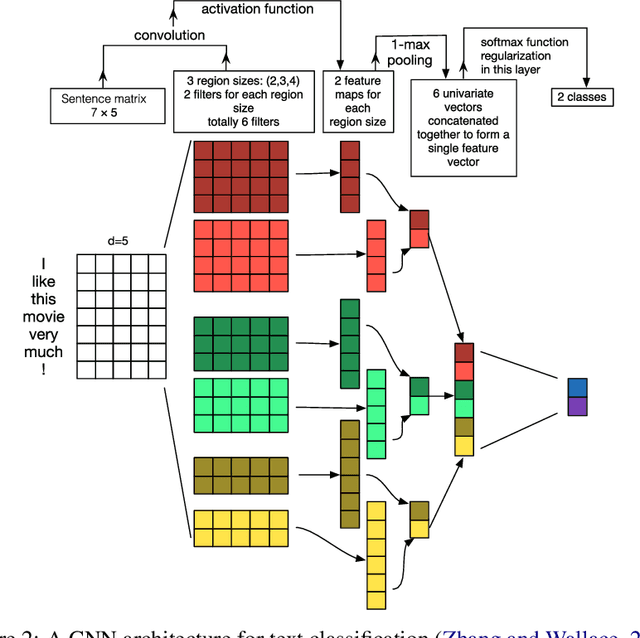
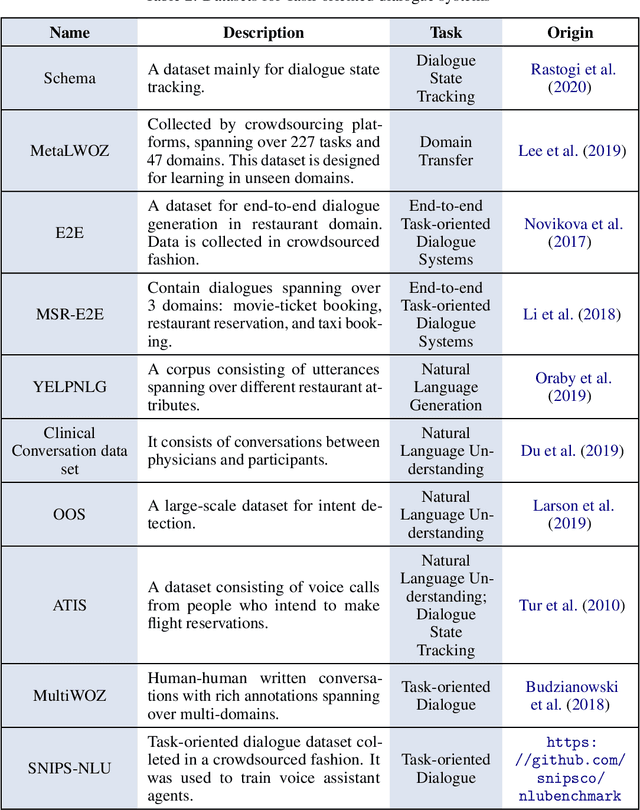
Dialogue systems are a popular Natural Language Processing (NLP) task as it is promising in real-life applications. It is also a complicated task since many NLP tasks deserving study are involved. As a result, a multitude of novel works on this task are carried out, and most of them are deep learning-based due to the outstanding performance. In this survey, we mainly focus on the deep learning-based dialogue systems. We comprehensively review state-of-the-art research outcomes in dialogue systems and analyze them from two angles: model type and system type. Specifically, from the angle of model type, we discuss the principles, characteristics, and applications of different models that are widely used in dialogue systems. This will help researchers acquaint these models and see how they are applied in state-of-the-art frameworks, which is rather helpful when designing a new dialogue system. From the angle of system type, we discuss task-oriented and open-domain dialogue systems as two streams of research, providing insight into the hot topics related. Furthermore, we comprehensively review the evaluation methods and datasets for dialogue systems to pave the way for future research. Finally, some possible research trends are identified based on the recent research outcomes. To the best of our knowledge, this survey is the most comprehensive and up-to-date one at present in the area of dialogue systems and dialogue-related tasks, extensively covering the popular frameworks, topics, and datasets. Keywords: Dialogue Systems, Chatbots, Conversational AI, Task-oriented, Open Domain, Chit-chat, Question Answering, Artificial Intelligence, Natural Language Processing, Information Retrieval, Deep Learning, Neural Networks, CNN, RNN, Hierarchical Recurrent Encoder-Decoder, Memory Networks, Attention, Transformer, Pointer Net, CopyNet, Reinforcement Learning, GANs, Knowledge Graph, Survey, Review
Design of a vision based range bearing and heading system for robot swarms
Mar 14, 2021An essential problem of swarm robotics is how members of the swarm knows the positions of other robots. The main aim of this research is to develop a cost-effective and simple vision-based system to detect the range, bearing, and heading of the robots inside a swarm using a multi-purpose passive landmark. A small Zumo robot equipped with Raspberry Pi, PiCamera is utilized for the implementation of the algorithm, and different kinds of multipurpose passive landmarks with nonsymmetrical patterns, which give reliable information about the range, bearing and heading in a single unit, are designed. By comparing the recorded features obtained from image analysis of the landmark through systematical experimentation and the actual measurements, correlations are obtained, and algorithms converting those features into range, bearing and heading are designed. The reliability and accuracy of algorithms are tested and errors are found within an acceptable range.
Semantic Analysis for Automated Evaluation of the Potential Impact of Research Articles
Apr 26, 2021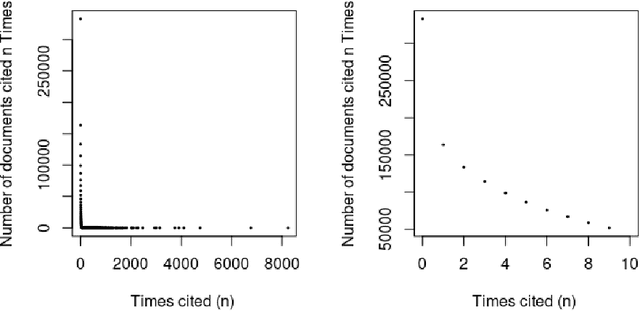
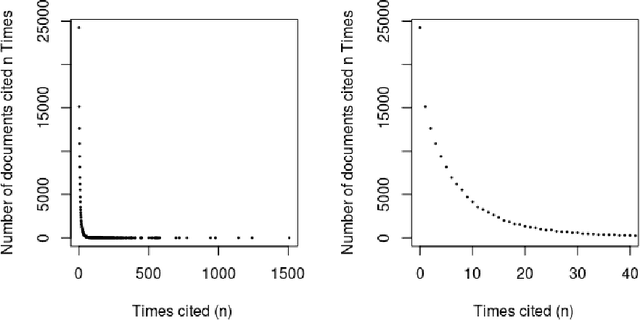
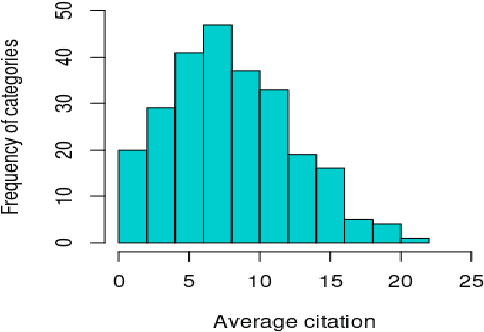
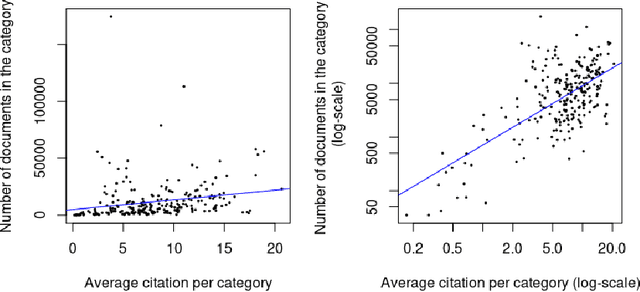
Can the analysis of the semantics of words used in the text of a scientific paper predict its future impact measured by citations? This study details examples of automated text classification that achieved 80% success rate in distinguishing between highly-cited and little-cited articles. Automated intelligent systems allow the identification of promising works that could become influential in the scientific community. The problems of quantifying the meaning of texts and representation of human language have been clear since the inception of Natural Language Processing. This paper presents a novel method for vector representation of text meaning based on information theory and show how this informational semantics is used for text classification on the basis of the Leicester Scientific Corpus. We describe the experimental framework used to evaluate the impact of scientific articles through their informational semantics. Our interest is in citation classification to discover how important semantics of texts are in predicting the citation count. We propose the semantics of texts as an important factor for citation prediction. For each article, our system extracts the abstract of paper, represents the words of the abstract as vectors in Meaning Space, automatically analyses the distribution of scientific categories (Web of Science categories) within the text of abstract, and then classifies papers according to citation counts (highly-cited, little-cited). We show that an informational approach to representing the meaning of a text has offered a way to effectively predict the scientific impact of research papers.
MultiModalQA: Complex Question Answering over Text, Tables and Images
Apr 13, 2021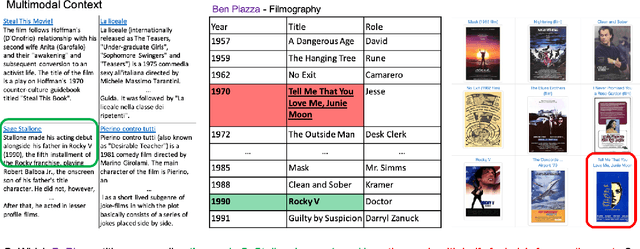
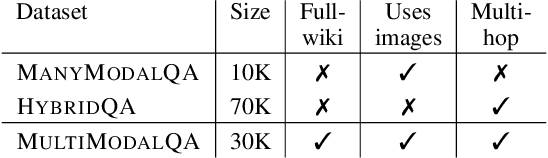

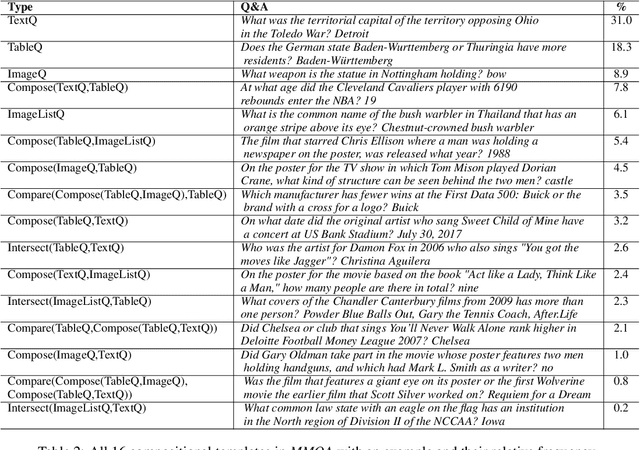
When answering complex questions, people can seamlessly combine information from visual, textual and tabular sources. While interest in models that reason over multiple pieces of evidence has surged in recent years, there has been relatively little work on question answering models that reason across multiple modalities. In this paper, we present MultiModalQA(MMQA): a challenging question answering dataset that requires joint reasoning over text, tables and images. We create MMQA using a new framework for generating complex multi-modal questions at scale, harvesting tables from Wikipedia, and attaching images and text paragraphs using entities that appear in each table. We then define a formal language that allows us to take questions that can be answered from a single modality, and combine them to generate cross-modal questions. Last, crowdsourcing workers take these automatically-generated questions and rephrase them into more fluent language. We create 29,918 questions through this procedure, and empirically demonstrate the necessity of a multi-modal multi-hop approach to solve our task: our multi-hop model, ImplicitDecomp, achieves an average F1of 51.7 over cross-modal questions, substantially outperforming a strong baseline that achieves 38.2 F1, but still lags significantly behind human performance, which is at 90.1 F1