 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ELO System for Skat and Other Games of Chance
Apr 07, 2021
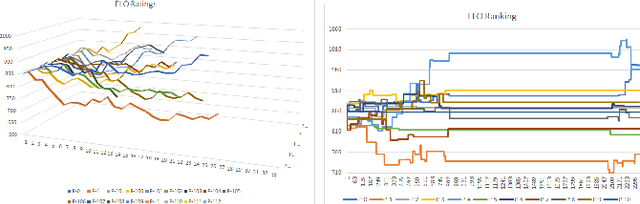
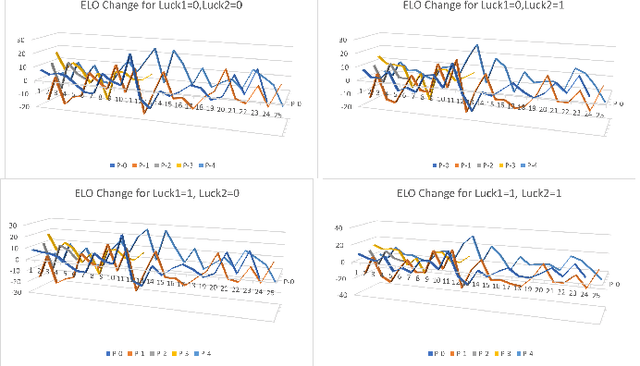
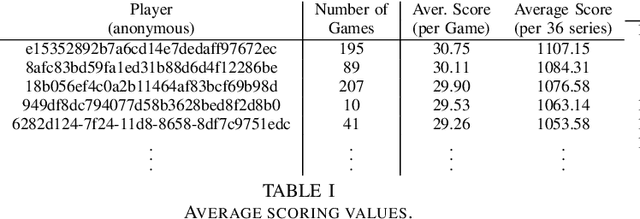
Assessing the skill level of players to predict the outcome and to rank the players in a longer series of games is of critical importance for tournament play. Besides weaknesses, like an observed continuous inflation, through a steadily increasing playing body, the ELO ranking system, named after its creator Arpad Elo, has proven to be a reliable method for calculating the relative skill levels of players in zero-sum games. The evaluation of player strength in trick-taking card games like Skat or Bridge, however, is not obvious. Firstly, these are incomplete information partially observable games with more than one player, where opponent strength should influence the scoring as it does in existing ELO systems. Secondly, they are game of both skill and chance, so that besides the playing strength the outcome of a game also depends on the deal. Last but not least, there are internationally established scoring systems, in which the players are used to be evaluated, and to which ELO should align. Based on a tournament scoring system, we propose a new ELO system for Skat to overcome these weaknesses.
Facilitating Machine Learning Model Comparison and Explanation Through A Radial Visualisation
Apr 15, 2021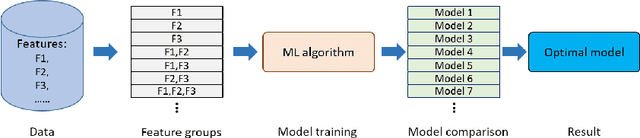
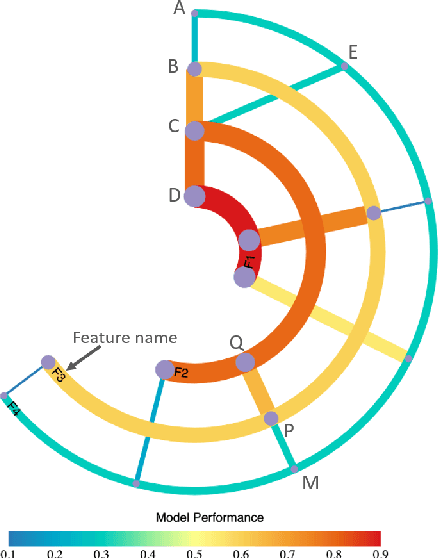
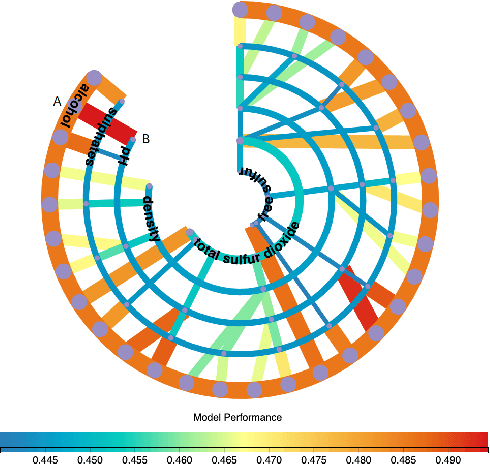
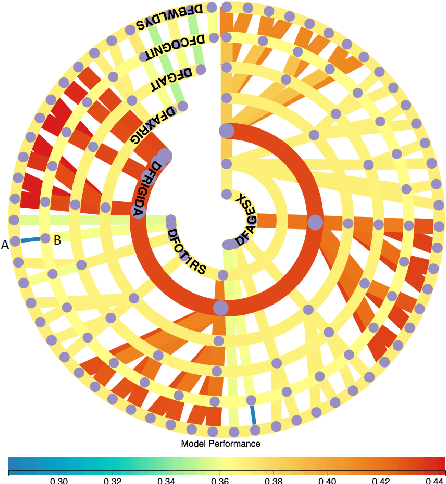
Building an effective Machine Learning (ML) model for a data set is a difficult task involving various steps. One of the most important steps is to compare generated substantial amounts of ML models to find the optimal one for the deployment. It is challenging to compare such models with dynamic number of features. Comparison is more than just finding differences of ML model performance, users are also interested in the relations between features and model performance such as feature importance for ML explanations. This paper proposes RadialNet Chart, a novel visualisation approach to compare ML models trained with a different number of features of a given data set while revealing implicit dependent relations. In RadialNet Chart, ML models and features are represented by lines and arcs respectively. These lines are generated effectively using a recursive function. The dependence of ML models with dynamic number of features is encoded into the structure of visualisation, where ML models and their dependent features are directly revealed from related line connections. ML model performance information is encoded with colour and line width in RadialNet Chart. Together with the structure of visualisation, feature importance can be directly discerned in RadialNet Chart for ML explanations.
Self-supervised Learning of Depth Inference for Multi-view Stereo
Apr 07, 2021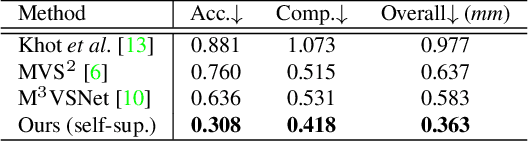
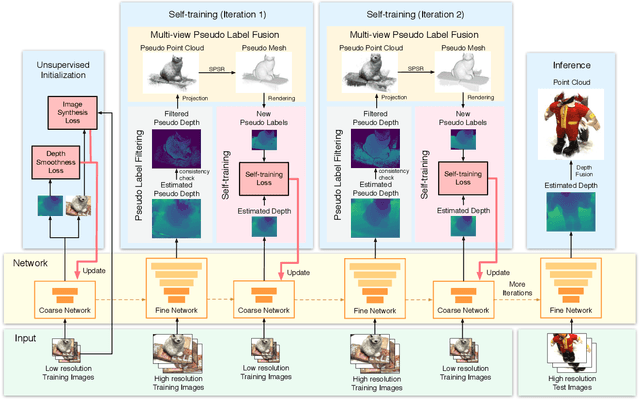
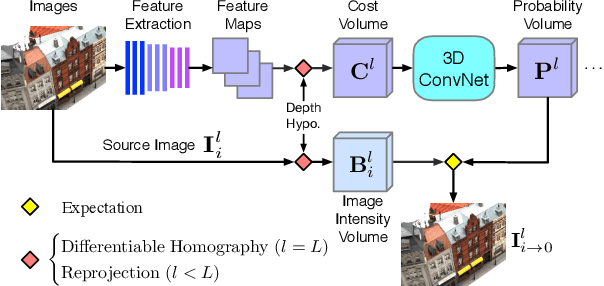
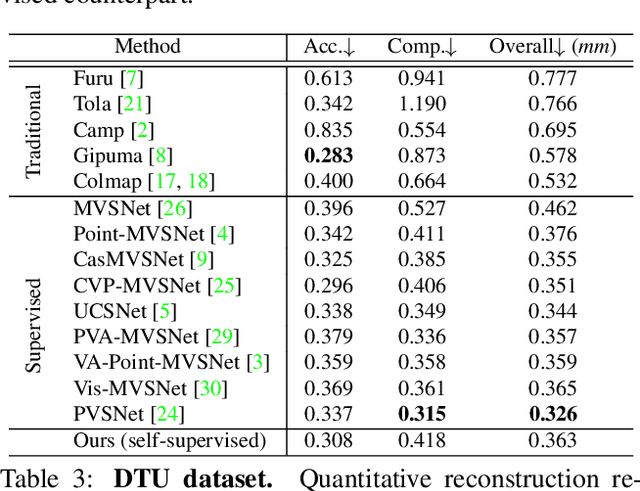
Recent supervised multi-view depth estimation networks have achieved promising results. Similar to all supervised approaches, these networks require ground-truth data during training. However, collecting a large amount of multi-view depth data is very challenging. Here, we propose a self-supervised learning framework for multi-view stereo that exploit pseudo labels from the input data. We start by learning to estimate depth maps as initial pseudo labels under an unsupervised learning framework relying on image reconstruction loss as supervision. We then refine the initial pseudo labels using a carefully designed pipeline leveraging depth information inferred from higher resolution images and neighboring views. We use these high-quality pseudo labels as the supervision signal to train the network and improve, iteratively, its performance by self-training. Extensive experiments on the DTU dataset show that our proposed self-supervised learning framework outperforms existing unsupervised multi-view stereo networks by a large margin and performs on par compared to the supervised counterpart. Code is available at https://github.com/JiayuYANG/Self-supervised-CVP-MVSNet.
FocusedDropout for Convolutional Neural Network
Mar 29, 2021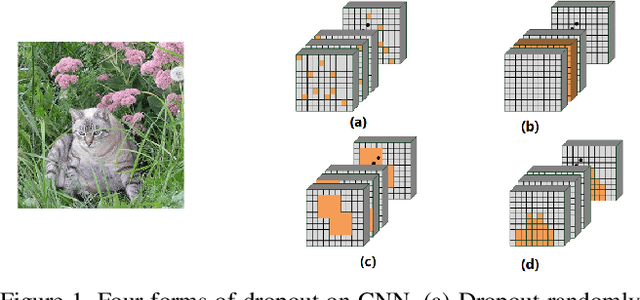
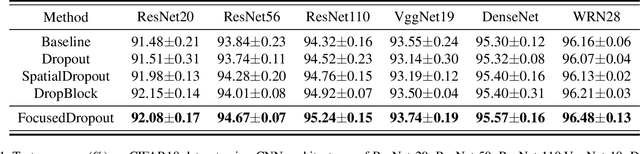
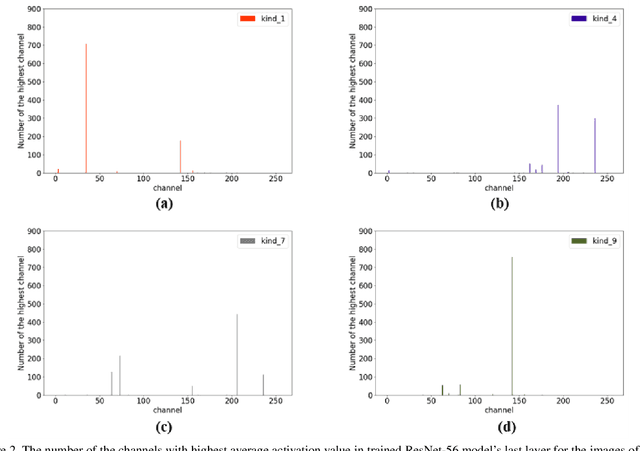
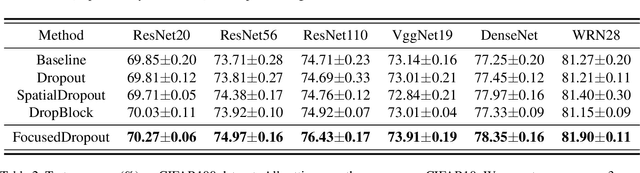
In convolutional neural network (CNN), dropout cannot work well because dropped information is not entirely obscured in convolutional layers where features are correlated spatially. Except randomly discarding regions or channels, many approaches try to overcome this defect by dropping influential units. In this paper, we propose a non-random dropout method named FocusedDropout, aiming to make the network focus more on the target. In FocusedDropout, we use a simple but effective way to search for the target-related features, retain these features and discard others, which is contrary to the existing methods. We found that this novel method can improve network performance by making the network more target-focused. Besides, increasing the weight decay while using FocusedDropout can avoid the overfitting and increase accuracy. Experimental results show that even a slight cost, 10\% of batches employing FocusedDropout, can produce a nice performance boost over the baselines on multiple datasets of classification, including CIFAR10, CIFAR100, Tiny Imagenet, and has a good versatility for different CNN models.
3D-to-2D Distillation for Indoor Scene Parsing
Apr 07, 2021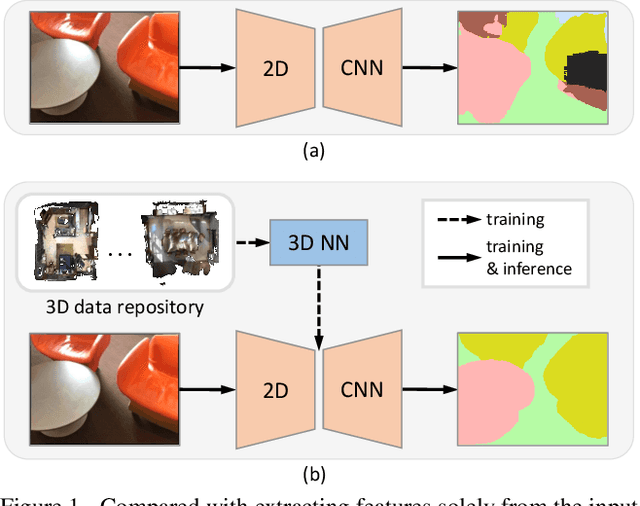

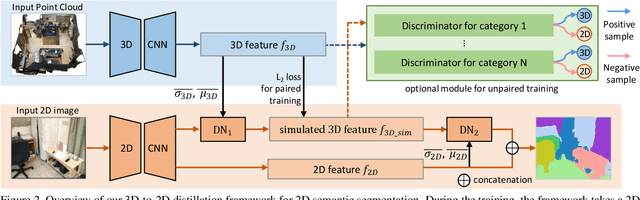
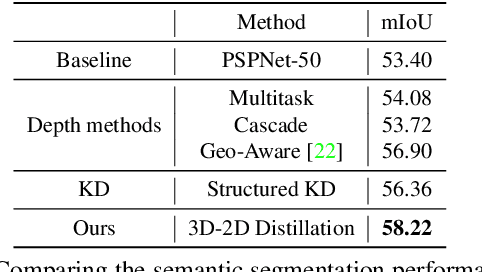
Indoor scene semantic parsing from RGB images is very challenging due to occlusions, object distortion, and viewpoint variations. Going beyond prior works that leverage geometry information, typically paired depth maps, we present a new approach, a 3D-to-2D distillation framework, that enables us to leverage 3D features extracted from large-scale 3D data repository (e.g., ScanNet-v2) to enhance 2D features extracted from RGB images. Our work has three novel contributions. First, we distill 3D knowledge from a pretrained 3D network to supervise a 2D network to learn simulated 3D features from 2D features during the training, so the 2D network can infer without requiring 3D data. Second, we design a two-stage dimension normalization scheme to calibrate the 2D and 3D features for better integration. Third, we design a semantic-aware adversarial training model to extend our framework for training with unpaired 3D data. Extensive experiments on various datasets, ScanNet-V2, S3DIS, and NYU-v2, demonstrate the superiority of our approach. Also, experimental results show that our 3D-to-2D distillation improves the model generalization.
A Sketching Framework for Reduced Data Transfer in Photon Counting Lidar
Feb 17, 2021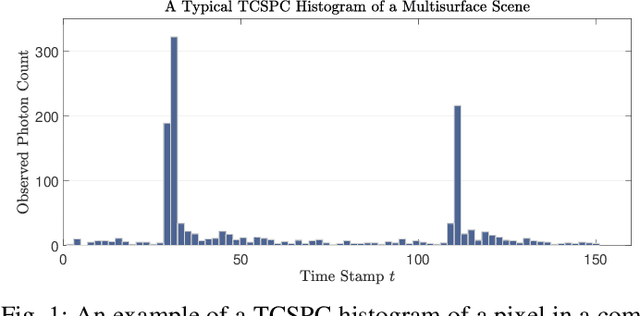
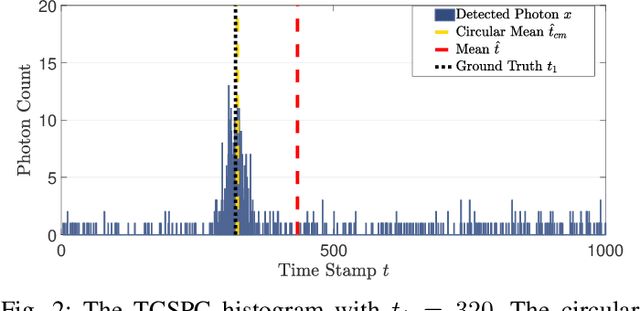
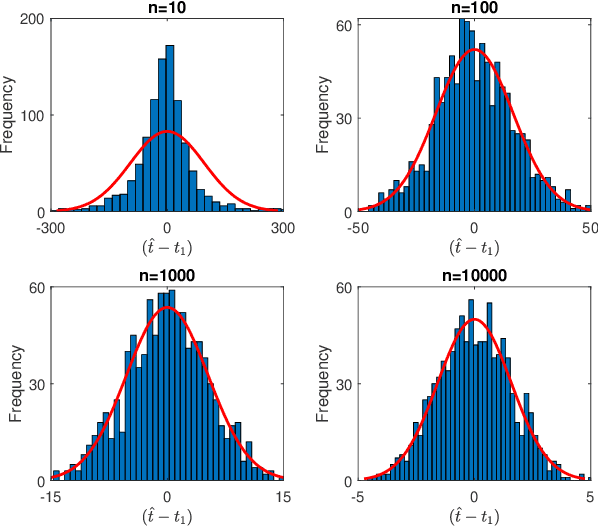
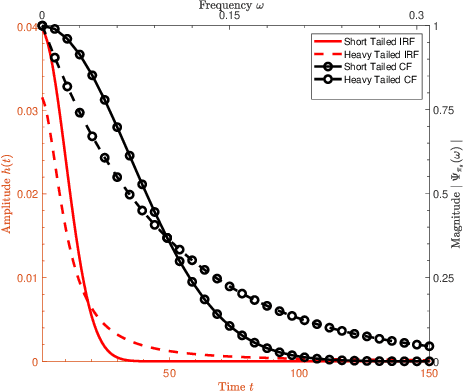
Single-photon lidar has become a prominent tool for depth imaging in recent years. At the core of the technique, the depth of a target is measured by constructing a histogram of time delays between emitted light pulses and detected photon arrivals. A major data processing bottleneck arises on the device when either the number of photons per pixel is large or the resolution of the time stamp is fine, as both the space requirement and the complexity of the image reconstruction algorithms scale with these parameters. We solve this limiting bottleneck of existing lidar techniques by sampling the characteristic function of the time of flight (ToF) model to build a compressive statistic, a so-called sketch of the time delay distribution, which is sufficient to infer the spatial distance and intensity of the object. The size of the sketch scales with the degrees of freedom of the ToF model (number of objects) and not, fundamentally, with the number of photons or the time stamp resolution. Moreover, the sketch is highly amenable for on-chip online processing. We show theoretically that the loss of information for compression is controlled and the mean squared error of the inference quickly converges towards the optimal Cram\'er-Rao bound (i.e. no loss of information) for modest sketch sizes. The proposed compressed single-photon lidar framework is tested and evaluated on real life datasets of complex scenes where it is shown that a compression rate of up-to 1/150 is achievable in practice without sacrificing the overall resolution of the reconstructed image.
Real-time Ionospheric Imaging of S4 Scintillation from Limited Data with Parallel Kalman Filters and Smoothness
May 11, 2021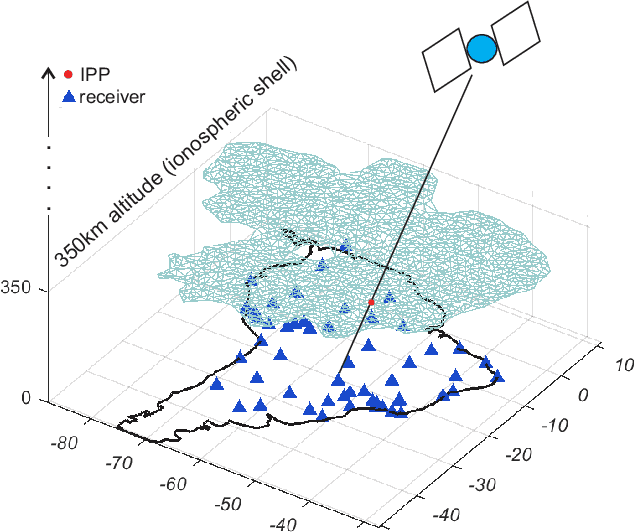
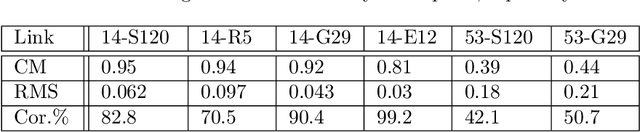
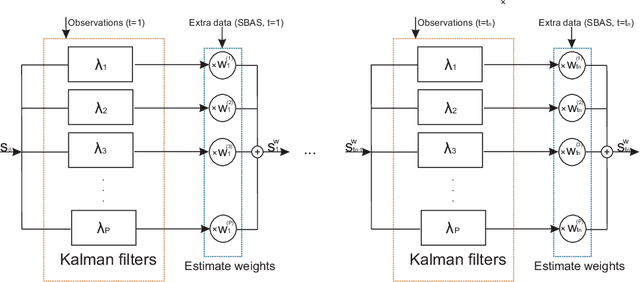
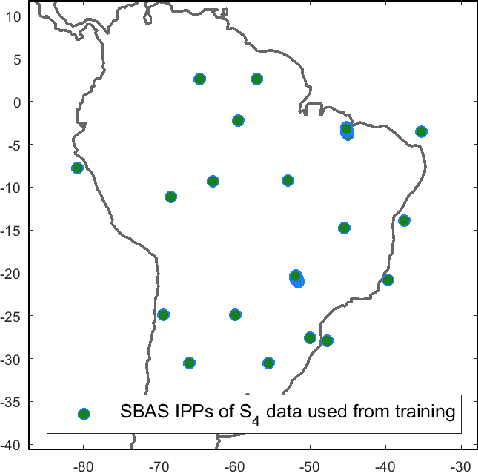
In this paper, we propose a Bayesian framework to create two dimensional ionospheric images of high spatio-temporal resolution to monitor ionospheric irregularities as measured by the S4 index. Here, we recast the standard Bayesian recursive filtering for a linear Gaussian state-space model, also referred to as the Kalman filter, first by augmenting the (pierce point) observation model with connectivity information stemming from the insight and assumptions/standard modeling about the spatial distribution of the scintillation activity on the ionospheric shell at 350 km altitude. Thus, we achieve to handle the limited spatio-temporal observations. Then, by introducing a set of Kalman filters running in parallel, we mitigate the uncertainty related to a tuning parameter of the proposed augmented model. The output images are a weighted average of the state estimates of the individual filters. We demonstrate our approach by rendering two dimensional real-time ionospheric images of S4 amplitude scintillation at 350 km over South America with temporal resolution of one minute. Furthermore, we employ extra S4 data that was not used in producing these ionospheric images, to check and verify the ability of our images to predict this extra data in particular ionospheric pierce points. Our results show that in areas with a network of ground receivers with a relatively good coverage (e.g. within a couple of kilometers distance) the produced images can provide reliable real-time results. Our proposed algorithmic framework can be readily used to visualize real-time ionospheric images taking as inputs the available scintillation data provided from freely available web-servers.
Three Steps to Multimodal Trajectory Prediction: Modality Clustering, Classification and Synthesis
Mar 14, 2021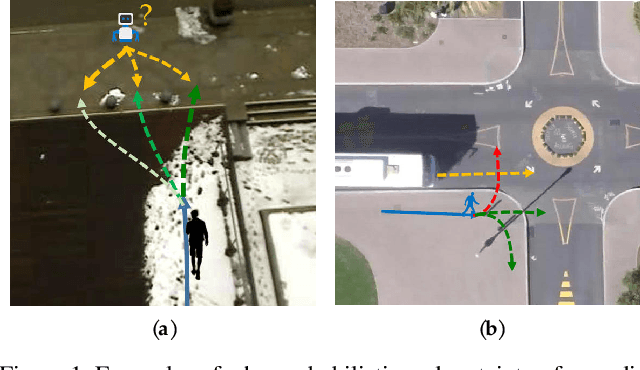
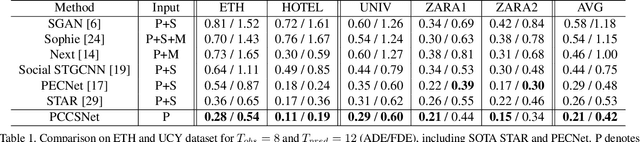
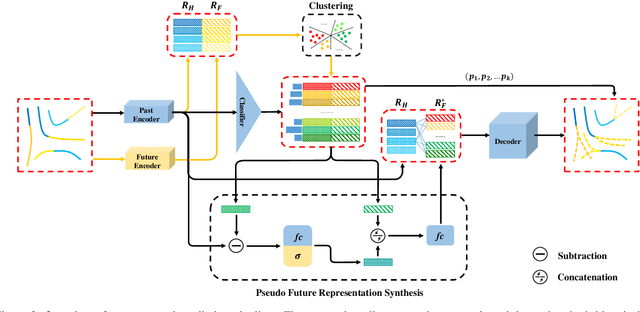
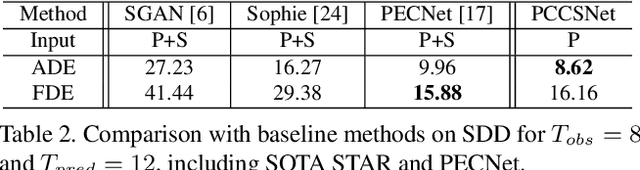
Multimodal prediction results are essential for trajectory forecasting task as there is no single correct answer for the future. Previous frameworks can be divided into three categories: regression, generation and classification frameworks. However, these frameworks have weaknesses in different aspects so that they cannot model the multimodal prediction task comprehensively. In this paper, we present a novel insight along with a brand-new prediction framework by formulating multimodal prediction into three steps: modality clustering, classification and synthesis, and address the shortcomings of earlier frameworks. Exhaustive experiments on popular benchmarks have demonstrated that our proposed method surpasses state-of-the-art works even without introducing social and map information. Specifically, we achieve 19.2% and 20.8% improvement on ADE and FDE respectively on ETH/UCY dataset. Our code will be made publicly available.
LiRaNet: End-to-End Trajectory Prediction using Spatio-Temporal Radar Fusion
Oct 02, 2020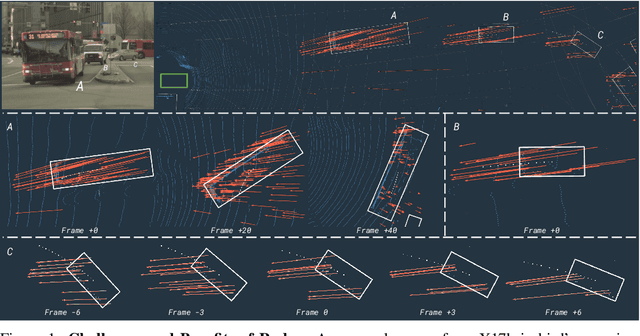
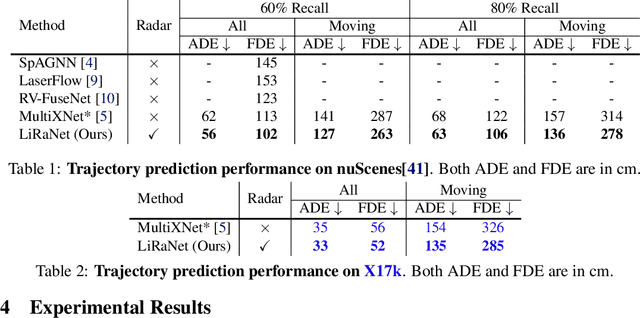
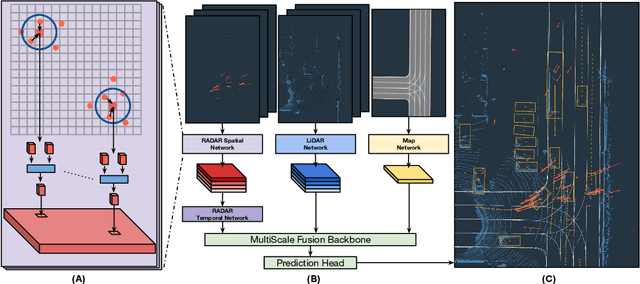

In this paper, we present LiRaNet, a novel end-to-end trajectory prediction method which utilizes radar sensor information along with widely used lidar and high definition (HD) maps. Automotive radar provides rich, complementary information, allowing for longer range vehicle detection as well as instantaneous radial velocity measurements. However, there are factors that make the fusion of lidar and radar information challenging, such as the relatively low angular resolution of radar measurements, their sparsity and the lack of exact time synchronization with lidar. To overcome these challenges, we propose an efficient spatio-temporal radar feature extraction scheme which achieves state-of-the-art performance on multiple large-scale datasets.Further, by incorporating radar information, we show a 52% reduction in prediction error for objects with high acceleration and a 16% reduction in prediction error for objects at longer range.
Rank Minimization-based Toeplitz Reconstruction for DoA Estimation Using Coprime Array
Mar 29, 2021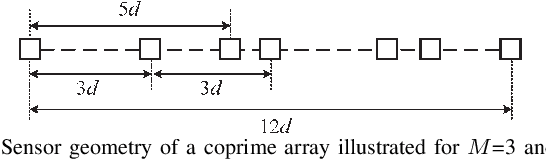
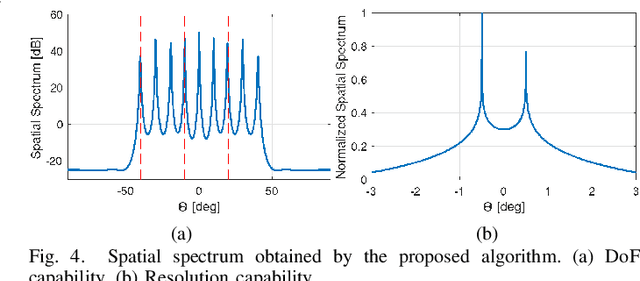
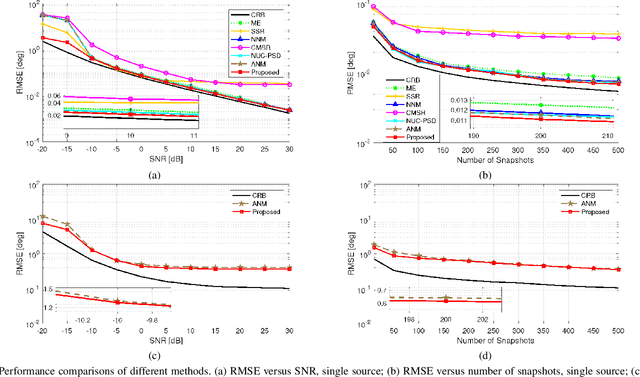
In this paper, we address the problem of direction finding using coprime array, which is one of the most preferred sparse array configurations. Motivated by the fact that non-uniform element spacing hinders full utilization of the underlying information in the receive signals, we propose a direction-of-arrival (DoA) estimation algorithm based on low-rank reconstruction of the Toeplitz covariance matrix. The atomic-norm representation of the measurements from the interpolated virtual array is considered, and the equivalent dual-variable rank minimization problem is formulated and solved using a cyclic optimization approach. The recovered covariance matrix enables the application of conventional subspace-based spectral estimation algorithms, such as MUSIC, to achieve enhanced DoA estimation performance. The estimation performance of the proposed approach, in terms of the degrees-of-freedom and spatial resolution, is examined. We also show the superiority of the proposed method over the competitive approaches in the root-mean-square error sense.