 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Constituency Parsing with Span Attention
Oct 15, 2020
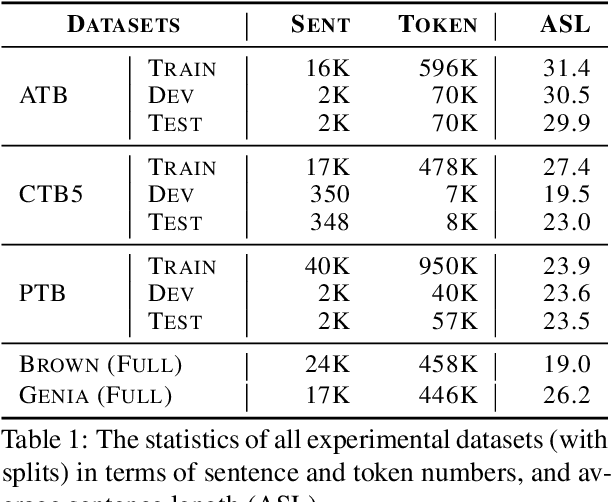
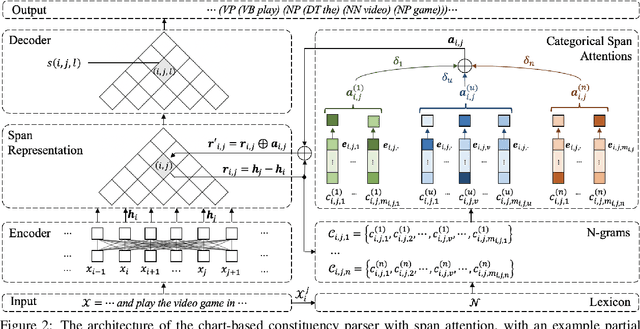
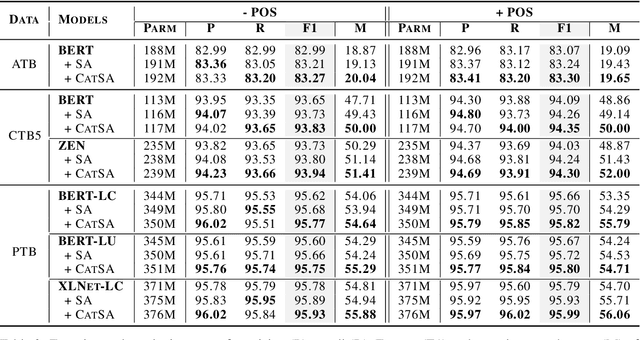
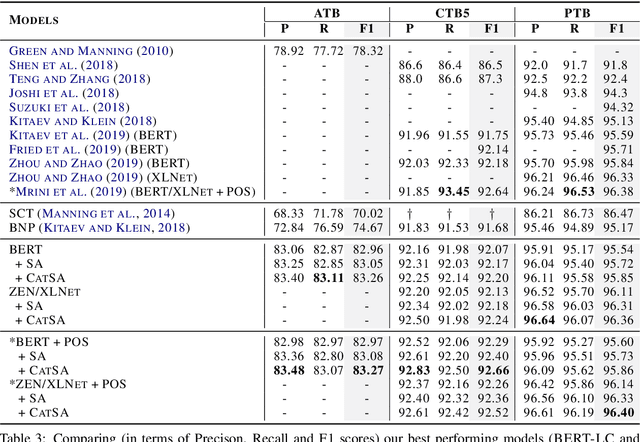
Constituency parsing is a fundamental and important task for natural language understanding, where a good representation of contextual information can help this task. N-grams, which is a conventional type of feature for contextual information, have been demonstrated to be useful in many tasks, and thus could also be beneficial for constituency parsing if they are appropriately modeled. In this paper, we propose span attention for neural chart-based constituency parsing to leverage n-gram information. Considering that current chart-based parsers with Transformer-based encoder represent spans by subtraction of the hidden states at the span boundaries, which may cause information loss especially for long spans, we incorporate n-grams into span representations by weighting them according to their contributions to the parsing process. Moreover, we propose categorical span attention to further enhance the model by weighting n-grams within different length categories, and thus benefit long-sentence parsing. Experimental results on three widely used benchmark datasets demonstrate the effectiveness of our approach in parsing Arabic, Chinese, and English, where state-of-the-art performance is obtained by our approach on all of them.
A New Parallel Adaptive Clustering and its Application to Streaming Data
Apr 06, 2021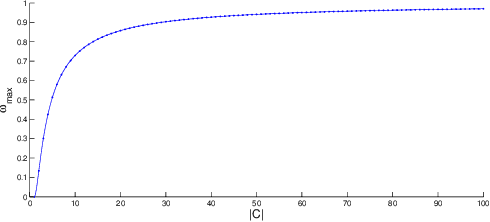

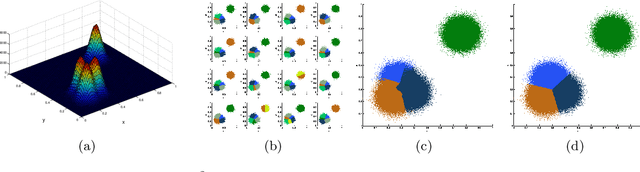
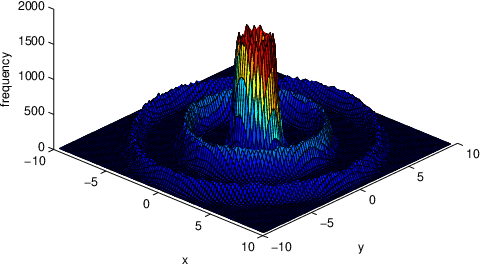
This paper presents a parallel adaptive clustering (PAC) algorithm to automatically classify data while simultaneously choosing a suitable number of classes. Clustering is an important tool for data analysis and understanding in a broad set of areas including data reduction, pattern analysis, and classification. However, the requirement to specify the number of clusters in advance and the computational burden associated with clustering large sets of data persist as challenges in clustering. We propose a new parallel adaptive clustering (PAC) algorithm that addresses these challenges by adaptively computing the number of clusters and leveraging the power of parallel computing. The algorithm clusters disjoint subsets of the data on parallel computation threads. We develop regularized set \mi{k}-means to efficiently cluster the results from the parallel threads. A refinement step further improves the clusters. The PAC algorithm offers the capability to adaptively cluster data sets which change over time by reusing the information from previous time steps to decrease computation. We provide theoretical analysis and numerical experiments to characterize the performance of the method, validate its properties, and demonstrate the computational efficiency of the method.
Dual Pointer Network for Fast Extraction of Multiple Relations in a Sentence
Mar 05, 2021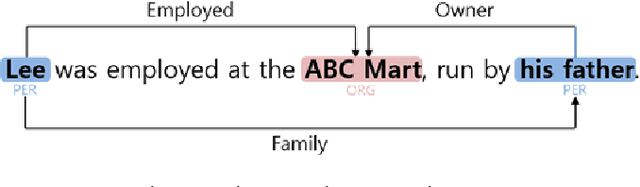

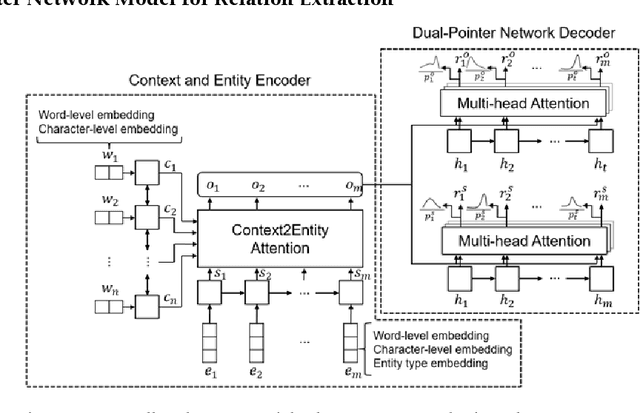
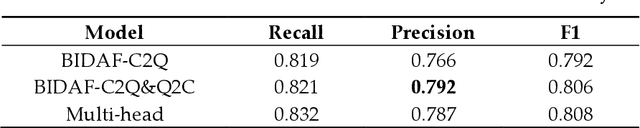
Relation extraction is a type of information extraction task that recognizes semantic relationships between entities in a sentence. Many previous studies have focused on extracting only one semantic relation between two entities in a single sentence. However, multiple entities in a sentence are associated through various relations. To address this issue, we propose a relation extraction model based on a dual pointer network with a multi-head attention mechanism. The proposed model finds n-to-1 subject-object relations using a forward object decoder. Then, it finds 1-to-n subject-object relations using a backward subject decoder. Our experiments confirmed that the proposed model outperformed previous models, with an F1-score of 80.8% for the ACE-2005 corpus and an F1-score of 78.3% for the NYT corpus.
UAV-Assisted Underwater Sensor Networks using RF and Optical Wireless Links
Apr 27, 2021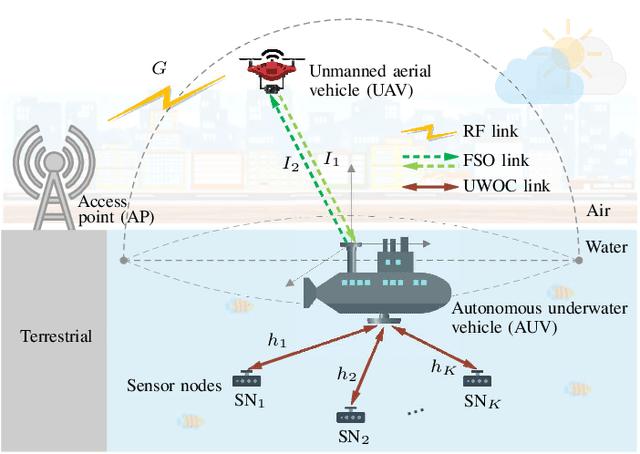
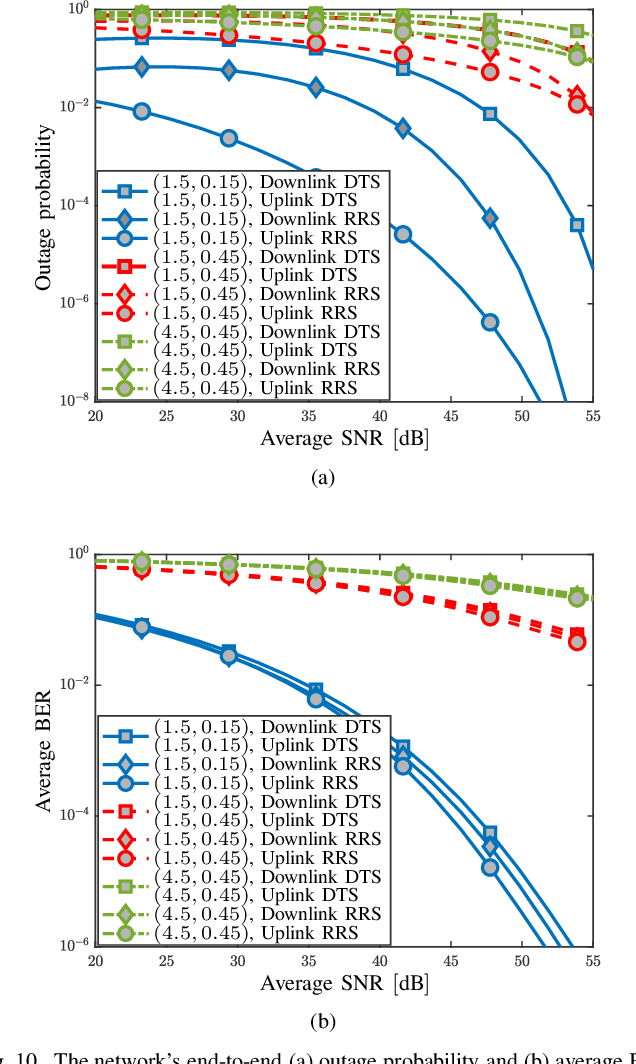
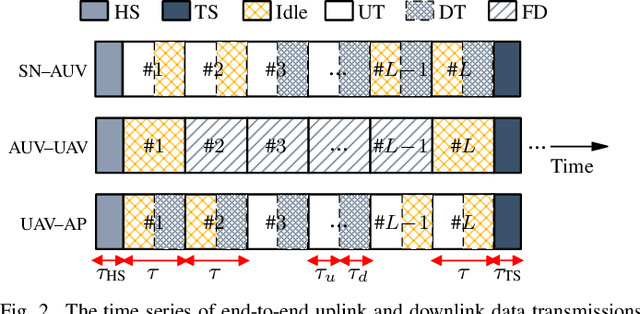
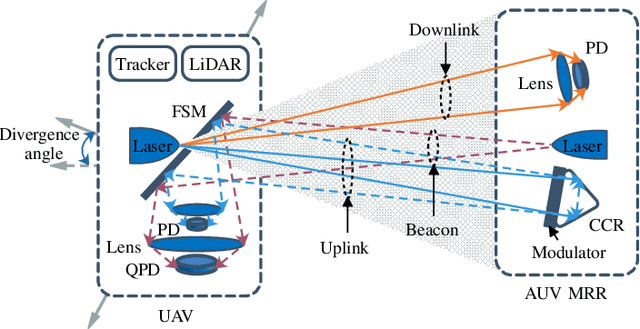
Underwater sensor networks (UWSNs) are of interest to gather data from underwater sensor nodes (SNs) and deliver information to a terrestrial access point (AP) in the uplink transmission, and transfer data from the AP to the SNs in the downlink transmission. In this paper, we investigate a triple-hop UWSN in which autonomous underwater vehicle (AUV) and unmanned aerial vehicle (UAV) relays enable end-to-end communications between the SNs and the AP. It is assumed that the SN--AUV, AUV--UAV, and UAV--AP links are deployed by underwater optical communication (UWOC), free-space optic (FSO), and radio frequency (RF) technologies, respectively. Two scenarios are proposed for the FSO uplink and downlink transmissions between the AUV and the UAV, subject to water-to-air and air-to-water interface impacts; direct transmission scenario (DTS) and retro-reflection scenario (RRS). After providing the channel models and their statistics, the UWSN's outage probability and average bit error rate (BER) are computed. Besides, a tracking procedure is proposed to set up reliable and stable AUV--UAV FSO communications. Through numerical results, it is concluded that the RSS scheme outperforms the DTS one with about 200% (32%) and 80% (17%) better outage probability (average BER) in the uplink and downlink, respectively. It is also shown that the tracking procedure provides on average 480% and 170% improvements in the network's outage probability and average BER, respectively, compared to poorly aligned FSO conditions. The results are verified by applying Monte-Carlo simulations.
Resilient Machine Learning for Networked Cyber Physical Systems: A Survey for Machine Learning Security to Securing Machine Learning for CPS
Feb 14, 2021
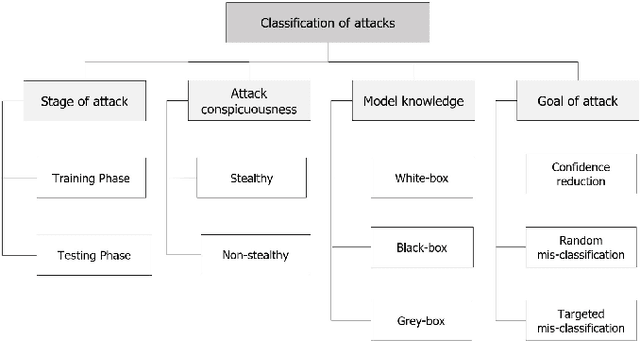
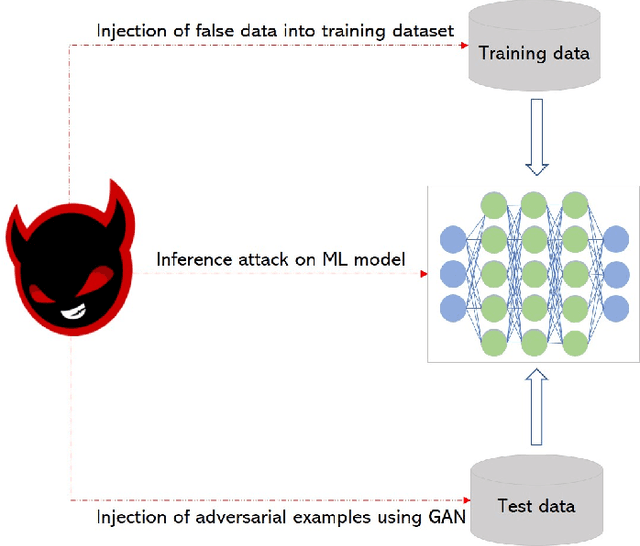
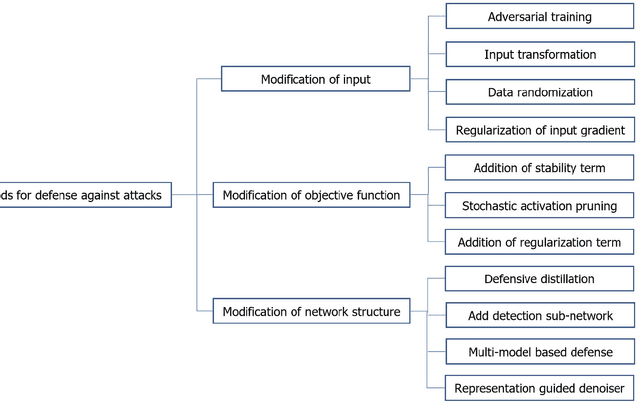
Cyber Physical Systems (CPS) are characterized by their ability to integrate the physical and information or cyber worlds. Their deployment in critical infrastructure have demonstrated a potential to transform the world. However, harnessing this potential is limited by their critical nature and the far reaching effects of cyber attacks on human, infrastructure and the environment. An attraction for cyber concerns in CPS rises from the process of sending information from sensors to actuators over the wireless communication medium, thereby widening the attack surface. Traditionally, CPS security has been investigated from the perspective of preventing intruders from gaining access to the system using cryptography and other access control techniques. Most research work have therefore focused on the detection of attacks in CPS. However, in a world of increasing adversaries, it is becoming more difficult to totally prevent CPS from adversarial attacks, hence the need to focus on making CPS resilient. Resilient CPS are designed to withstand disruptions and remain functional despite the operation of adversaries. One of the dominant methodologies explored for building resilient CPS is dependent on machine learning (ML) algorithms. However, rising from recent research in adversarial ML, we posit that ML algorithms for securing CPS must themselves be resilient. This paper is therefore aimed at comprehensively surveying the interactions between resilient CPS using ML and resilient ML when applied in CPS. The paper concludes with a number of research trends and promising future research directions. Furthermore, with this paper, readers can have a thorough understanding of recent advances on ML-based security and securing ML for CPS and countermeasures, as well as research trends in this active research area.
From Weakly Supervised Learning to Biquality Learning, a brief introduction
Dec 16, 2020


The field of Weakly Supervised Learning (WSL) has recently seen a surge of popularity, with numerous papers addressing different types of "supervision deficiencies". In WSL use cases, a variety of situations exists where the collected "information" is imperfect. The paradigm of WSL attempts to list and cover these problems with associated solutions. In this paper, we review the research progress on WSL with the aim to make it as a brief introduction to this field. We present the three axis of WSL cube and an overview of most of all the elements of their facets. We propose three measurable quantities that acts as coordinates in the previously defined cube namely: Quality, Adaptability and Quantity of information. Thus we suggest that Biquality Learning framework can be defined as a plan of the WSL cube and propose to re-discover previously unrelated patches in WSL literature as a unified Biquality Learning literature.
MRI brain tumor segmentation and uncertainty estimation using 3D-UNet architectures
Dec 30, 2020
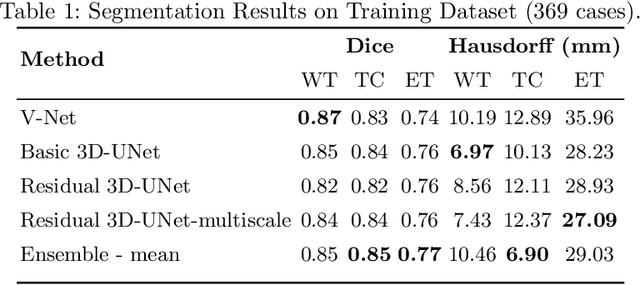
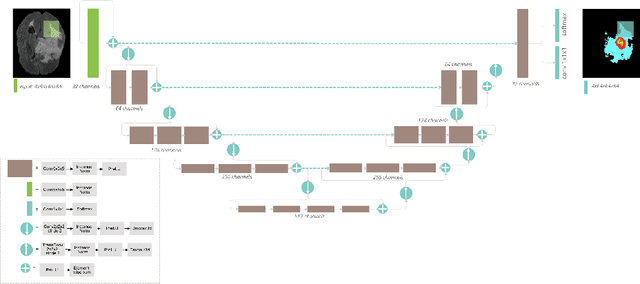
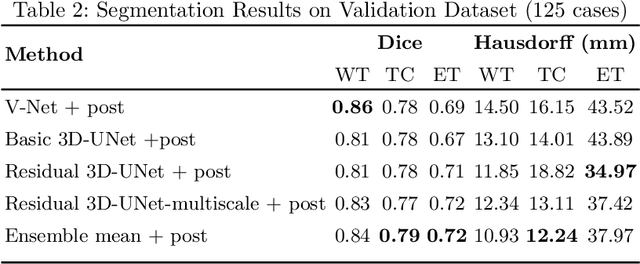
Automation of brain tumor segmentation in 3D magnetic resonance images (MRIs) is key to assess the diagnostic and treatment of the disease. In recent years, convolutional neural networks (CNNs) have shown improved results in the task. However, high memory consumption is still a problem in 3D-CNNs. Moreover, most methods do not include uncertainty information, which is especially critical in medical diagnosis. This work studies 3D encoder-decoder architectures trained with patch-based techniques to reduce memory consumption and decrease the effect of unbalanced data. The different trained models are then used to create an ensemble that leverages the properties of each model, thus increasing the performance. We also introduce voxel-wise uncertainty information, both epistemic and aleatoric using test-time dropout (TTD) and data-augmentation (TTA) respectively. In addition, a hybrid approach is proposed that helps increase the accuracy of the segmentation. The model and uncertainty estimation measurements proposed in this work have been used in the BraTS'20 Challenge for task 1 and 3 regarding tumor segmentation and uncertainty estimation.
Learning non-Gaussian graphical models via Hessian scores and triangular transport
Jan 08, 2021
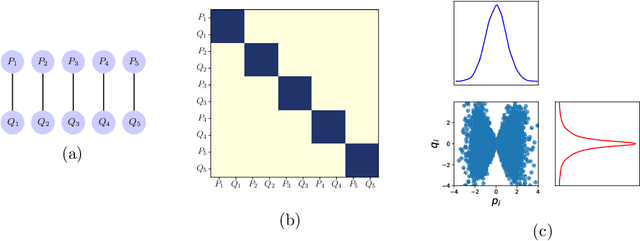
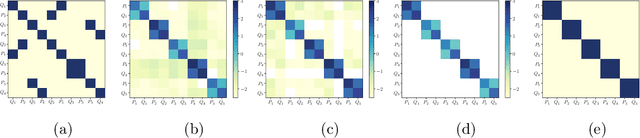
Undirected probabilistic graphical models represent the conditional dependencies, or Markov properties, of a collection of random variables. Knowing the sparsity of such a graphical model is valuable for modeling multivariate distributions and for efficiently performing inference. While the problem of learning graph structure from data has been studied extensively for certain parametric families of distributions, most existing methods fail to consistently recover the graph structure for non-Gaussian data. Here we propose an algorithm for learning the Markov structure of continuous and non-Gaussian distributions. To characterize conditional independence, we introduce a score based on integrated Hessian information from the joint log-density, and we prove that this score upper bounds the conditional mutual information for a general class of distributions. To compute the score, our algorithm SING estimates the density using a deterministic coupling, induced by a triangular transport map, and iteratively exploits sparse structure in the map to reveal sparsity in the graph. For certain non-Gaussian datasets, we show that our algorithm recovers the graph structure even with a biased approximation to the density. Among other examples, we apply sing to learn the dependencies between the states of a chaotic dynamical system with local interactions.
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 14, 2021
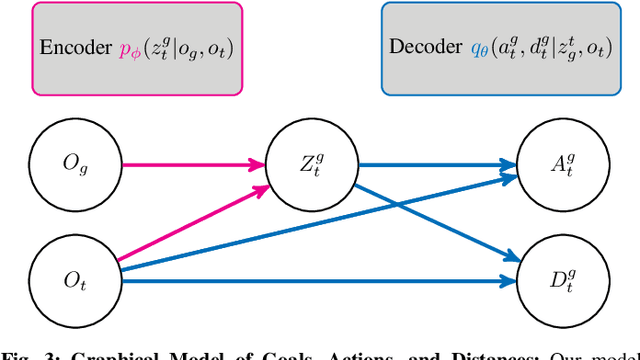
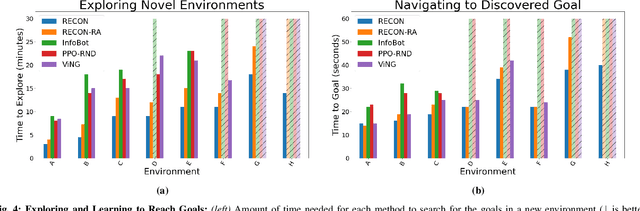
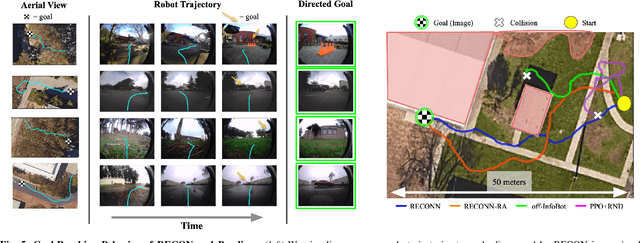
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
Dynamic Network Embedding Survey
Mar 29, 2021
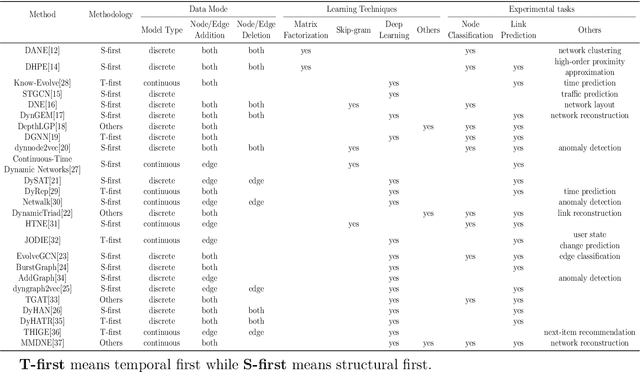
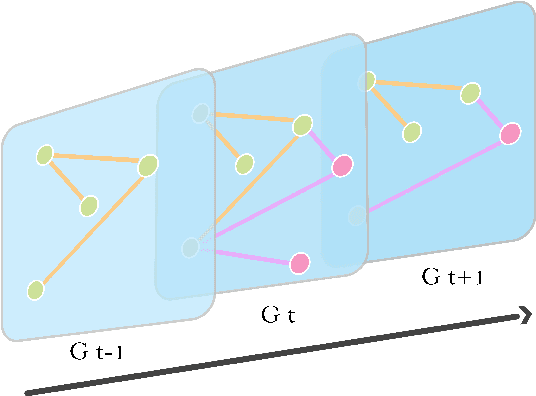
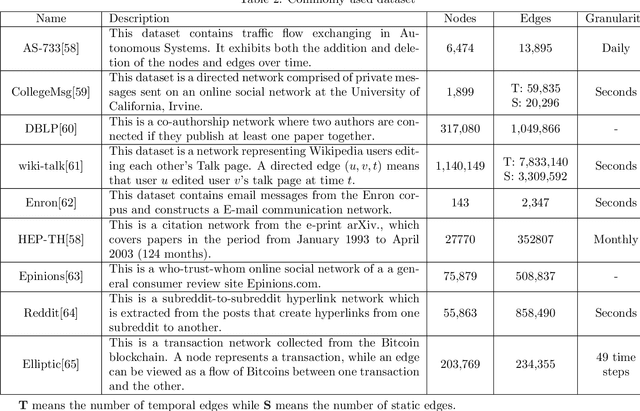
Since many real world networks are evolving over time, such as social networks and user-item networks, there are increasing research efforts on dynamic network embedding in recent years. They learn node representations from a sequence of evolving graphs but not only the latest network, for preserving both structural and temporal information from the dynamic networks. Due to the lack of comprehensive investigation of them, we give a survey of dynamic network embedding in this paper. Our survey inspects the data model, representation learning technique, evaluation and application of current related works and derives common patterns from them. Specifically, we present two basic data models, namely, discrete model and continuous model for dynamic networks. Correspondingly, we summarize two major categories of dynamic network embedding techniques, namely, structural-first and temporal-first that are adopted by most related works. Then we build a taxonomy that refines the category hierarchy by typical learning models. The popular experimental data sets and applications are also summarized. Lastly, we have a discussion of several distinct research topics in dynamic network embedding.