 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Persuade on the Fly: Robustness Against Ignorance
Feb 19, 2021
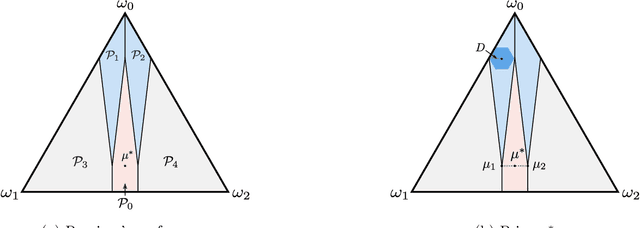

We study a repeated persuasion setting between a sender and a receiver, where at each time $t$, the sender observes a payoff-relevant state drawn independently and identically from an unknown prior distribution, and shares state information with the receiver, who then myopically chooses an action. As in the standard setting, the sender seeks to persuade the receiver into choosing actions that are aligned with the sender's preference by selectively sharing information about the state. However, in contrast to the standard models, the sender does not know the prior, and has to persuade while gradually learning the prior on the fly. We study the sender's learning problem of making persuasive action recommendations to achieve low regret against the optimal persuasion mechanism with the knowledge of the prior distribution. Our main positive result is an algorithm that, with high probability, is persuasive across all rounds and achieves $O(\sqrt{T\log T})$ regret, where $T$ is the horizon length. The core philosophy behind the design of our algorithm is to leverage robustness against the sender's ignorance of the prior. Intuitively, at each time our algorithm maintains a set of candidate priors, and chooses a persuasion scheme that is simultaneously persuasive for all of them. To demonstrate the effectiveness of our algorithm, we further prove that no algorithm can achieve regret better than $\Omega(\sqrt{T})$, even if the persuasiveness requirements were significantly relaxed. Therefore, our algorithm achieves optimal regret for the sender's learning problem up to terms logarithmic in $T$.
Predicting the Number of Reported Bugs in a Software Repository
Apr 24, 2021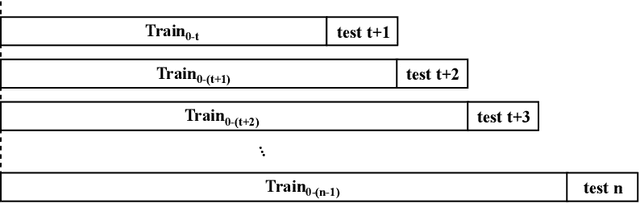
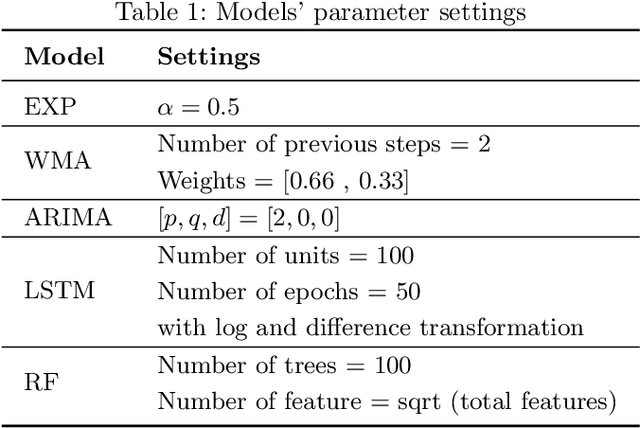
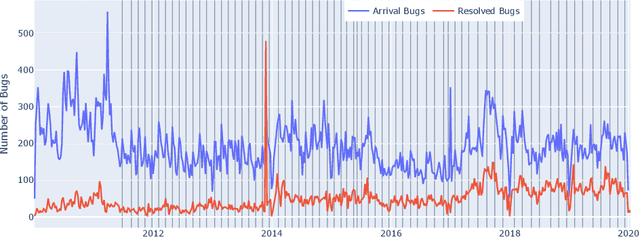
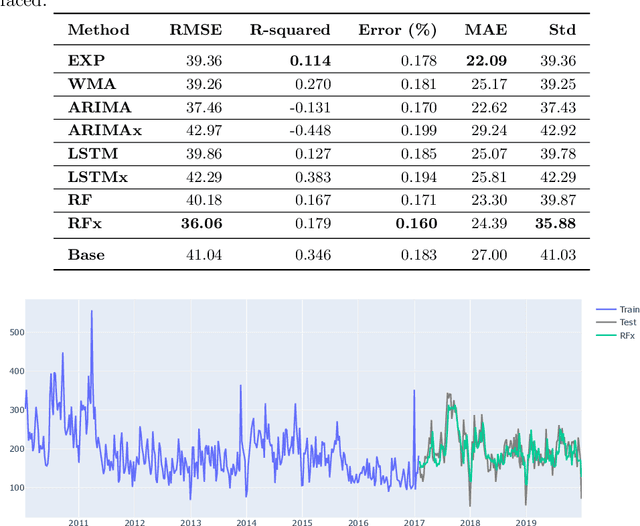
The bug growth pattern prediction is a complicated, unrelieved task, which needs considerable attention. Advance knowledge of the likely number of bugs discovered in the software system helps software developers in designating sufficient resources at a convenient time. The developers may also use such information to take necessary actions to increase the quality of the system and in turn customer satisfaction. In this study, we examine eight different time series forecasting models, including Long Short Term Memory Neural Networks (LSTM), auto-regressive integrated moving average (ARIMA), and Random Forest Regressor. Further, we assess the impact of exogenous variables such as software release dates by incorporating those into the prediction models. We analyze the quality of long-term prediction for each model based on different performance metrics. The assessment is conducted on Mozilla, which is a large open-source software application. The dataset is originally mined from Bugzilla and contains the number of bugs for the project between Jan 2010 and Dec 2019. Our numerical analysis provides insights on evaluating the trends in a bug repository. We observe that LSTM is effective when considering long-run predictions whereas Random Forest Regressor enriched by exogenous variables performs better for predicting the number of bugs in the short term.
A Review of Biomedical Datasets Relating to Drug Discovery: A Knowledge Graph Perspective
Feb 19, 2021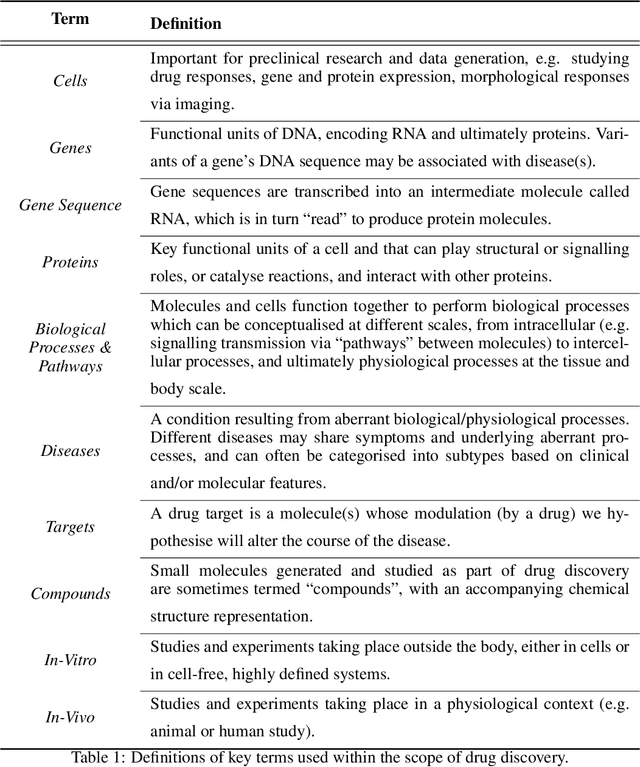
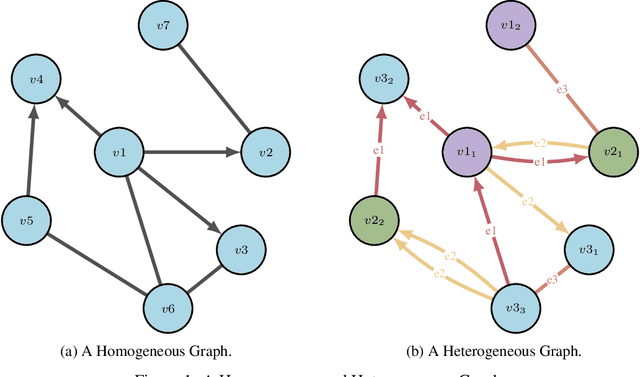
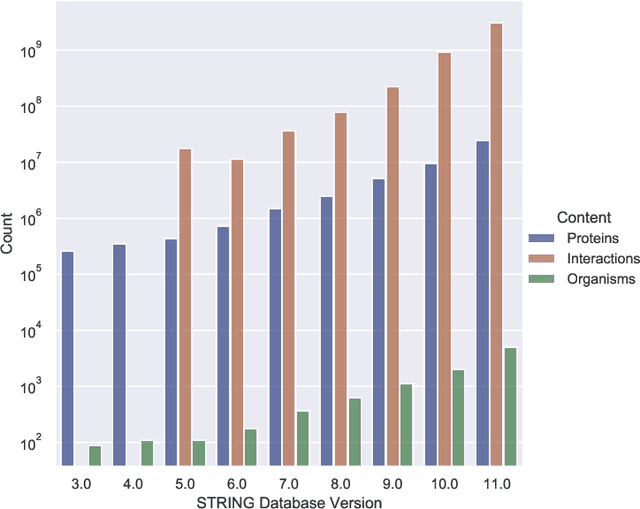
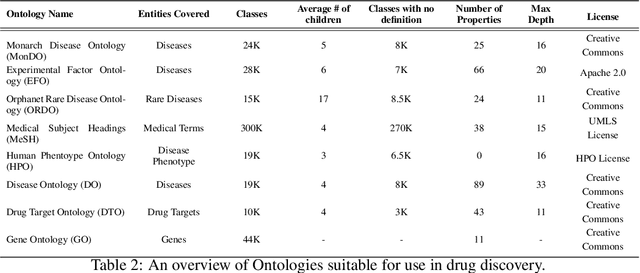
Drug discovery and development is an extremely complex process, with high attrition contributing to the costs of delivering new medicines to patients. Recently, various machine learning approaches have been proposed and investigated to help improve the effectiveness and speed of multiple stages of the drug discovery pipeline. Among these techniques, it is especially those using Knowledge Graphs that are proving to have considerable promise across a range of tasks, including drug repurposing, drug toxicity prediction and target gene-disease prioritisation. In such a knowledge graph-based representation of drug discovery domains, crucial elements including genes, diseases and drugs are represented as entities or vertices, whilst relationships or edges between them indicate some level of interaction. For example, an edge between a disease and drug entity might represent a successful clinical trial, or an edge between two drug entities could indicate a potentially harmful interaction. In order to construct high-quality and ultimately informative knowledge graphs however, suitable data and information is of course required. In this review, we detail publicly available primary data sources containing information suitable for use in constructing various drug discovery focused knowledge graphs. We aim to help guide machine learning and knowledge graph practitioners who are interested in applying new techniques to the drug discovery field, but who may be unfamiliar with the relevant data sources. Overall we hope this review will help motivate more machine learning researchers to explore combining knowledge graphs and machine learning to help solve key and emerging questions in the drug discovery domain.
Deep Neural Networks to Recover Unknown Physical Parameters from Oscillating Time Series
Jan 11, 2021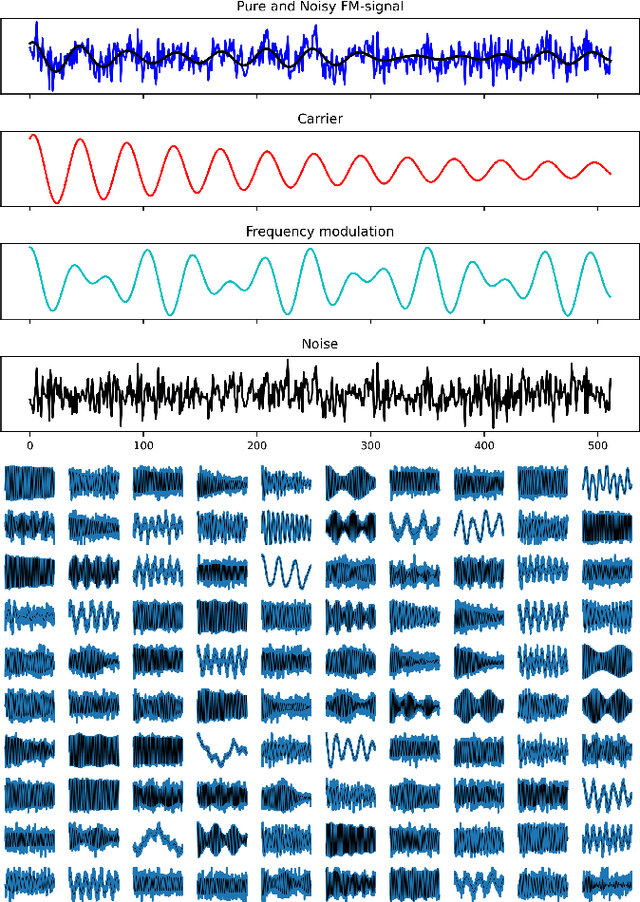
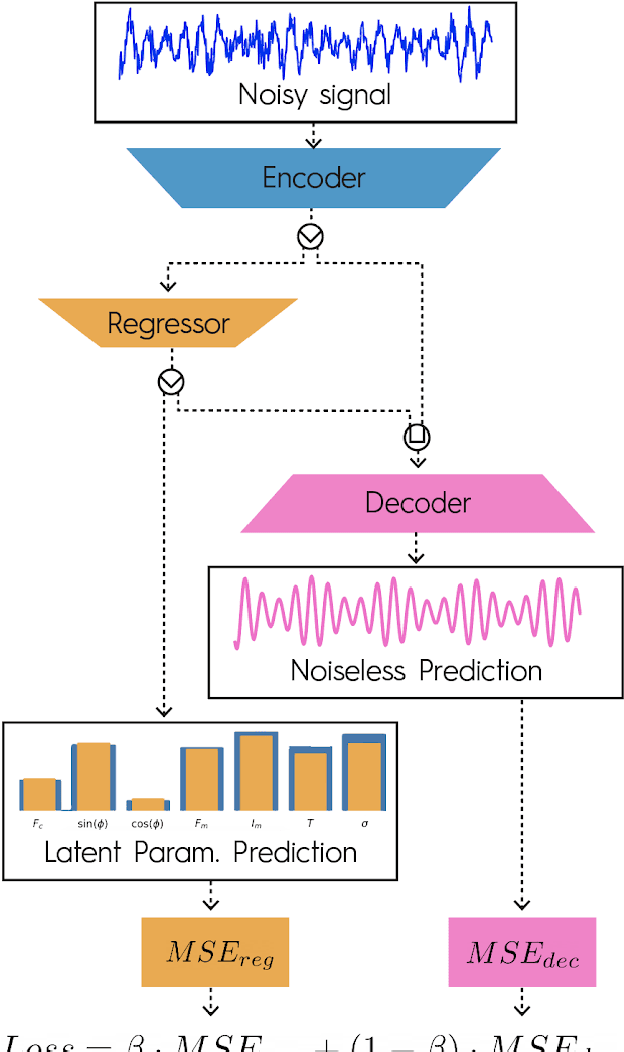
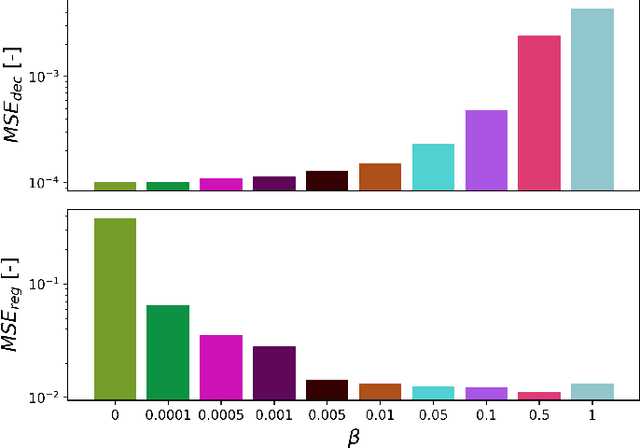
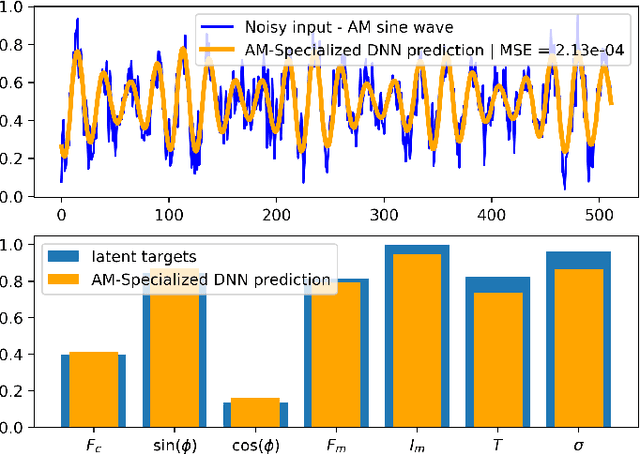
Deep neural networks (DNNs) are widely used in pattern-recognition tasks for which a human comprehensible, quantitative description of the data-generating process, e.g., in the form of equations, cannot be achieved. While doing so, DNNs often produce an abstract (entangled and non-interpretable) representation of the data-generating process. This is one of the reasons why DNNs are not extensively used in physics-signal processing: physicists generally require their analyses to yield quantitative information about the studied systems. In this article we use DNNs to disentangle components of oscillating time series, and recover meaningful information. We show that, because DNNs can find useful abstract feature representations, they can be used when prior knowledge about the signal-generating process exists, but is not complete, as it is particularly the case in "new-physics" searches. To this aim, we train our DNN on synthetic oscillating time series to perform two tasks: a regression of the signal latent parameters and signal denoising by an Autoencoder-like architecture. We show that the regression and denoising performance is similar to those of least-square curve fittings (LS-fit) with true latent parameters' initial guesses, in spite of the DNN needing no initial guesses at all. We then explore applications in which we believe our architecture could prove useful for time-series processing in physics, when prior knowledge is incomplete. As an example, we employ DNNs as a tool to inform LS-fits when initial guesses are unknown. We show that the regression can be performed on some latent parameters, while ignoring the existence of others. Because the Autoencoder needs no prior information about the physical model, the remaining unknown latent parameters can still be captured, thus making use of partial prior knowledge, while leaving space for data exploration and discoveries.
Pre-trained Language Model based Ranking in Baidu Search
May 24, 2021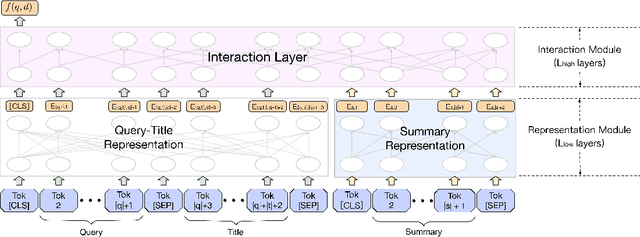
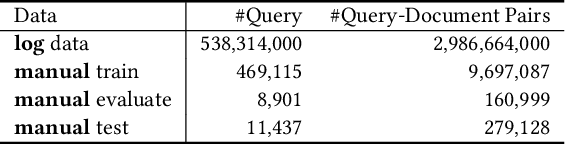
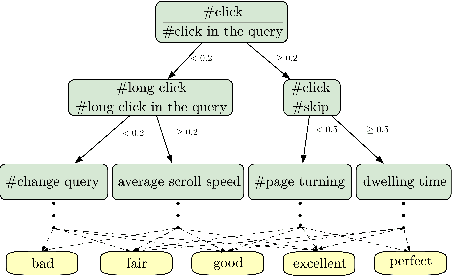
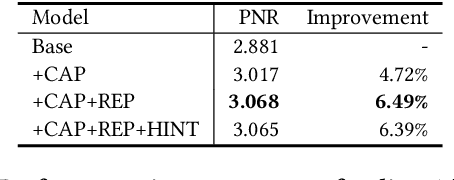
As the heart of a search engine, the ranking system plays a crucial role in satisfying users' information demands. More recently, neural rankers fine-tuned from pre-trained language models (PLMs) establish state-of-the-art ranking effectiveness. However, it is nontrivial to directly apply these PLM-based rankers to the large-scale web search system due to the following challenging issues:(1) the prohibitively expensive computations of massive neural PLMs, especially for long texts in the web-document, prohibit their deployments in an online ranking system that demands extremely low latency;(2) the discrepancy between existing ranking-agnostic pre-training objectives and the ad-hoc retrieval scenarios that demand comprehensive relevance modeling is another main barrier for improving the online ranking system;(3) a real-world search engine typically involves a committee of ranking components, and thus the compatibility of the individually fine-tuned ranking model is critical for a cooperative ranking system. In this work, we contribute a series of successfully applied techniques in tackling these exposed issues when deploying the state-of-the-art Chinese pre-trained language model, i.e., ERNIE, in the online search engine system. We first articulate a novel practice to cost-efficiently summarize the web document and contextualize the resultant summary content with the query using a cheap yet powerful Pyramid-ERNIE architecture. Then we endow an innovative paradigm to finely exploit the large-scale noisy and biased post-click behavioral data for relevance-oriented pre-training. We also propose a human-anchored fine-tuning strategy tailored for the online ranking system, aiming to stabilize the ranking signals across various online components. Extensive offline and online experimental results show that the proposed techniques significantly boost the search engine's performance.
Reinforcement Learning and Control of a Lower Extremity Exoskeleton for Squat Assistance
May 07, 2021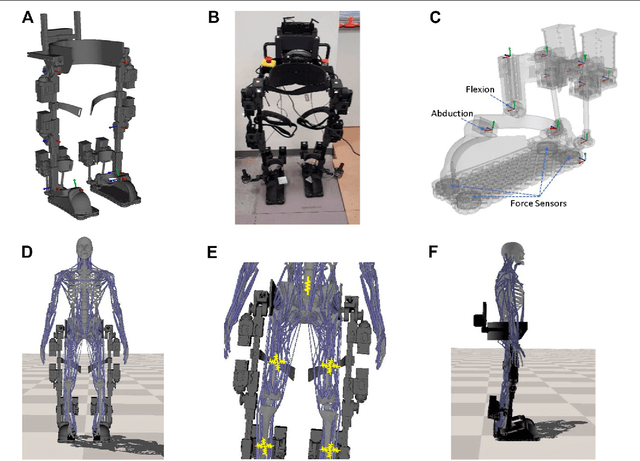
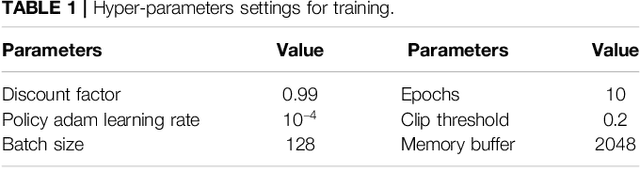
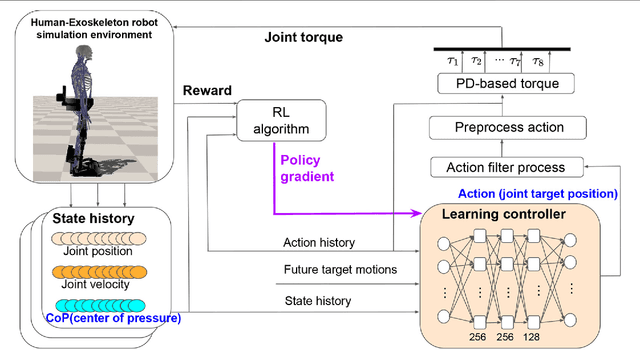

A significant challenge for the control of a robotic lower extremity rehabilitation exoskeleton is to ensure stability and robustness during programmed tasks or motions, which is crucial for the safety of the mobility-impaired user. Due to various levels of the user's disability, the human-exoskeleton interaction forces and external perturbations are unpredictable and could vary substantially and cause conventional motion controllers to behave unreliably or the robot to fall down. In this work, we propose a new, reinforcement learning-based, motion controller for a lower extremity rehabilitation exoskeleton, aiming to perform collaborative squatting exercises with efficiency, stability, and strong robustness. Unlike most existing rehabilitation exoskeletons, our exoskeleton has ankle actuation on both sagittal and front planes and is equipped with multiple foot force sensors to estimate center of pressure (CoP), an important indicator of system balance. This proposed motion controller takes advantage of the CoP information by incorporating it in the state input of the control policy network and adding it to the reward during the learning to maintain a well balanced system state during motions. In addition, we use dynamics randomization and adversary force perturbations including large human interaction forces during the training to further improve control robustness. To evaluate the effectiveness of the learning controller, we conduct numerical experiments with different settings to demonstrate its remarkable ability on controlling the exoskeleton to repetitively perform well balanced and robust squatting motions under strong perturbations and realistic human interaction forces.
Stereo Matching by Self-supervision of Multiscopic Vision
Apr 09, 2021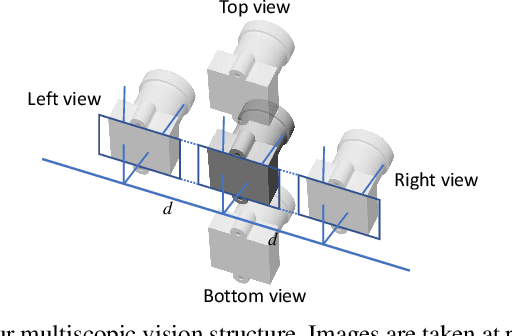

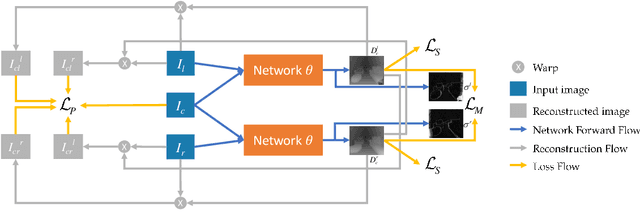

Self-supervised learning for depth estimation possesses several advantages over supervised learning. The benefits of no need for ground-truth depth, online fine-tuning, and better generalization with unlimited data attract researchers to seek self-supervised solutions. In this work, we propose a new self-supervised framework for stereo matching utilizing multiple images captured at aligned camera positions. A cross photometric loss, an uncertainty-aware mutual-supervision loss, and a new smoothness loss are introduced to optimize the network in learning disparity maps end-to-end without ground-truth depth information. To train this framework, we build a new multiscopic dataset consisting of synthetic images rendered by 3D engines and real images captured by real cameras. After being trained with only the synthetic images, our network can perform well in unseen outdoor scenes. Our experiment shows that our model obtains better disparity maps than previous unsupervised methods on the KITTI dataset and is comparable to supervised methods when generalized to unseen data. Our source code and dataset will be made public, and more results are provided in the supplement.
Node metadata can produce predictability transitions in network inference problems
Mar 26, 2021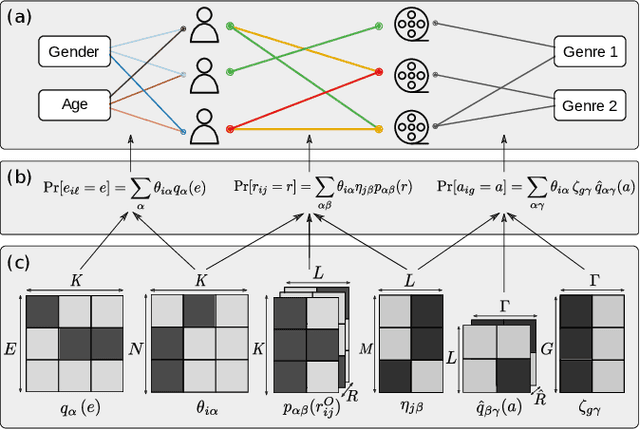
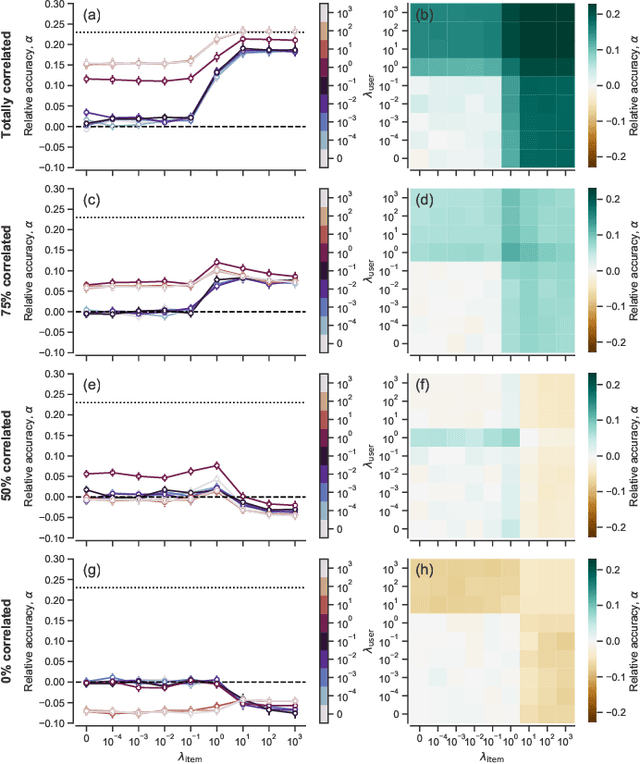
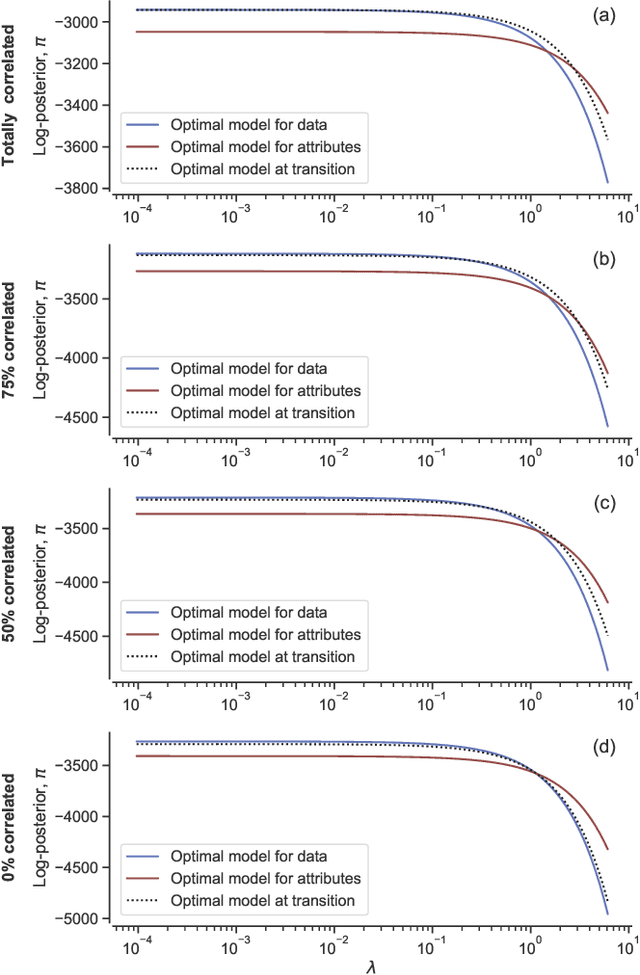
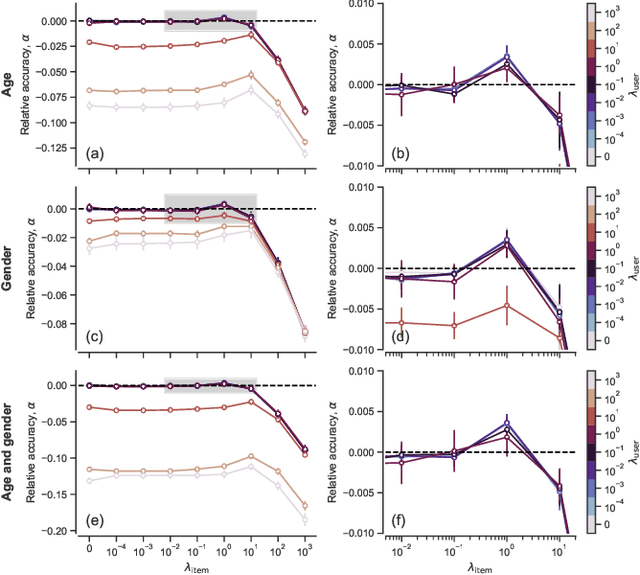
Network inference is the process of learning the properties of complex networks from data. Besides using information about known links in the network, node attributes and other forms of network metadata can help to solve network inference problems. Indeed, several approaches have been proposed to introduce metadata into probabilistic network models and to use them to make better inferences. However, we know little about the effect of such metadata in the inference process. Here, we investigate this issue. We find that, rather than affecting inference gradually, adding metadata causes abrupt transitions in the inference process and in our ability to make accurate predictions, from a situation in which metadata does not play any role to a situation in which metadata completely dominates the inference process. When network data and metadata are partly correlated, metadata optimally contributes to the inference process at the transition between data-dominated and metadata-dominated regimes.
Dyadic aggregated autoregressive (DASAR) model for time-frequency representation of biomedical signals
May 13, 2021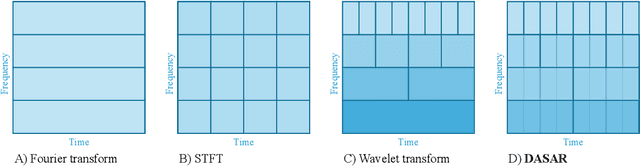
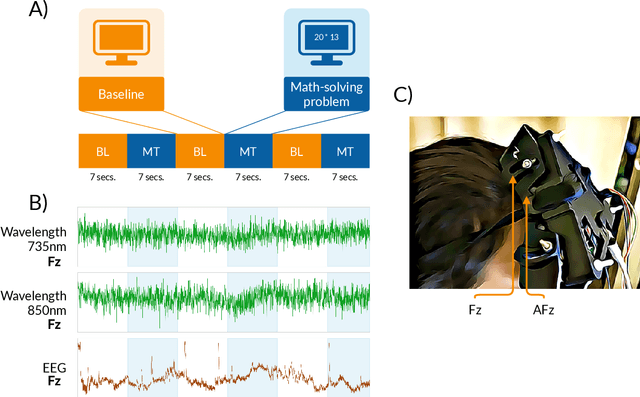
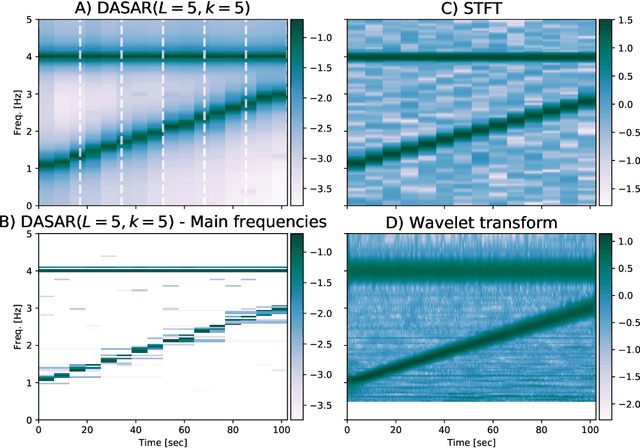
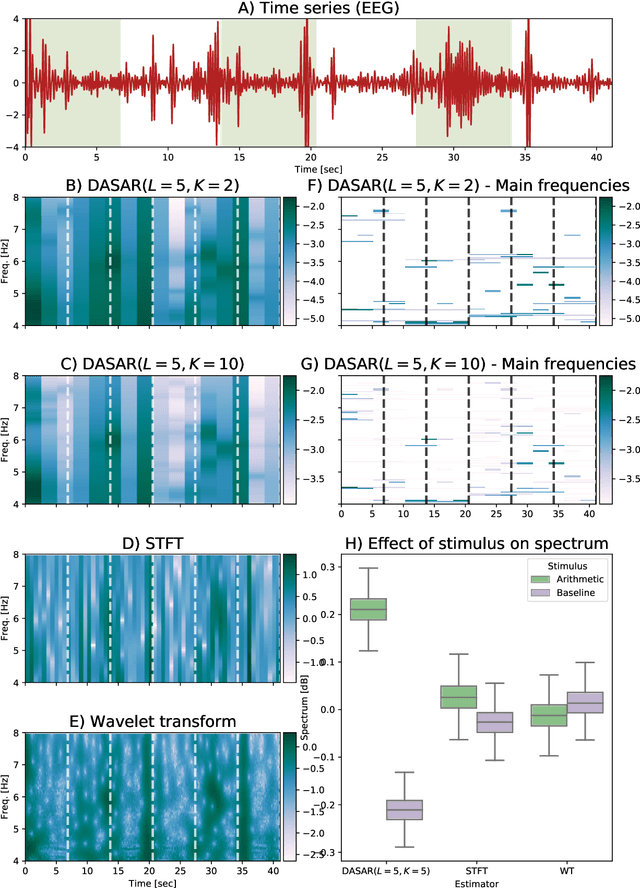
This paper introduces a new time-frequency representation method for biomedical signals: the dyadic aggregated autoregressive (DASAR) model. Signals, such as electroencephalograms (EEGs) and functional near-infrared spectroscopy (fNIRS), exhibit physiological information through time-evolving spectrum components at specific frequency intervals: 0-50 Hz (EEG) or 0-150 mHz (fNIRS). Spectrotemporal features in signals are conventionally estimated using short-time Fourier transform (STFT) and wavelet transform (WT). However, both methods may not offer the most robust or compact representation despite their widespread use in biomedical contexts. The presented method, DASAR, improves precise frequency identification and tracking of interpretable frequency components with a parsimonious set of parameters. DASAR achieves these characteristics by assuming that the biomedical time-varying spectrum comprises several independent stochastic oscillators with (piecewise) time-varying frequencies. Local stationarity can be assumed within dyadic subdivisions of the recordings, while the stochastic oscillators can be modeled with an aggregation of second-order autoregressive models (ASAR). DASAR can provide a more accurate representation of the (highly contrasted) EEG and fNIRS frequency ranges by increasing the estimation accuracy in user-defined spectrum region of interest (SROI). A mental arithmetic experiment on a hybrid EEG-fNIRS was conducted to assess the efficiency of the method. Our proposed technique, STFT, and WT were applied on both biomedical signals to discover potential oscillators that improve the discrimination between the task condition and its baseline. The results show that DASAR provided the highest spectrum differentiation and it was the only method that could identify Mayer waves as narrow-band artifacts at 97.4-97.5 mHz.
Successful Nash Equilibrium Agent for a 3-Player Imperfect-Information Game
Apr 13, 2018
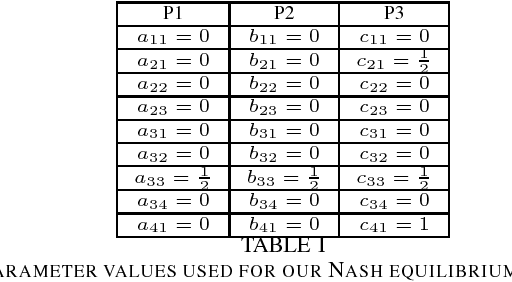
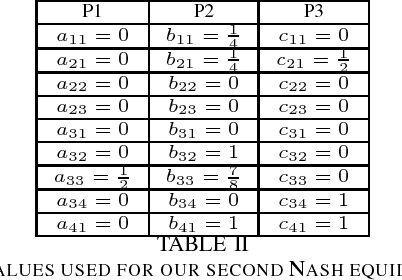
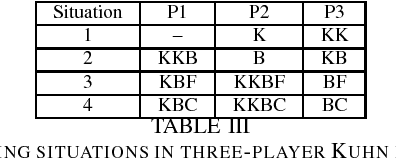
Creating strong agents for games with more than two players is a major open problem in AI. Common approaches are based on approximating game-theoretic solution concepts such as Nash equilibrium, which have strong theoretical guarantees in two-player zero-sum games, but no guarantees in non-zero-sum games or in games with more than two players. We describe an agent that is able to defeat a variety of realistic opponents using an exact Nash equilibrium strategy in a 3-player imperfect-information game. This shows that, despite a lack of theoretical guarantees, agents based on Nash equilibrium strategies can be successful in multiplayer games after all.