 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ShipSRDet: An End-to-End Remote Sensing Ship Detector Using Super-Resolved Feature Representation
Mar 17, 2021

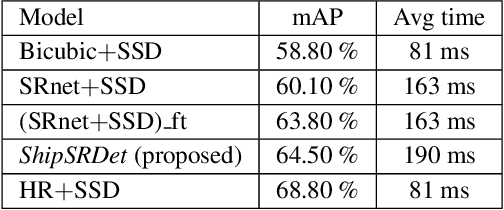
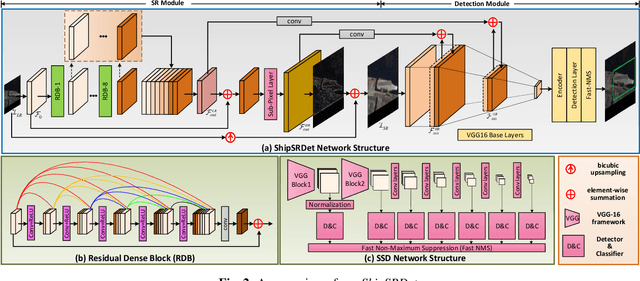

High-resolution remote sensing images can provide abundant appearance information for ship detection. Although several existing methods use image super-resolution (SR) approaches to improve the detection performance, they consider image SR and ship detection as two separate processes and overlook the internal coherence between these two correlated tasks. In this paper, we explore the potential benefits introduced by image SR to ship detection, and propose an end-to-end network named ShipSRDet. In our method, we not only feed the super-resolved images to the detector but also integrate the intermediate features of the SR network with those of the detection network. In this way, the informative feature representation extracted by the SR network can be fully used for ship detection. Experimental results on the HRSC dataset validate the effectiveness of our method. Our ShipSRDet can recover the missing details from the input image and achieves promising ship detection performance.
Sparsely Factored Neural Machine Translation
Feb 17, 2021

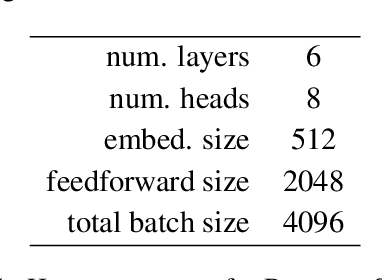
The standard approach to incorporate linguistic information to neural machine translation systems consists in maintaining separate vocabularies for each of the annotated features to be incorporated (e.g. POS tags, dependency relation label), embed them, and then aggregate them with each subword in the word they belong to. This approach, however, cannot easily accommodate annotation schemes that are not dense for every word. We propose a method suited for such a case, showing large improvements in out-of-domain data, and comparable quality for the in-domain data. Experiments are performed in morphologically-rich languages like Basque and German, for the case of low-resource scenarios.
iRotate: Active Visual SLAM for Omnidirectional Robots
Mar 22, 2021

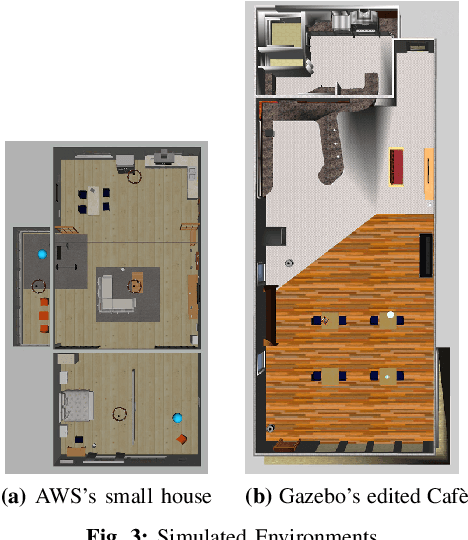
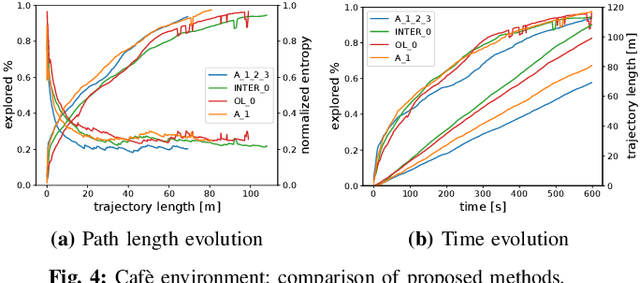
In this letter, we present an active visual SLAM approach for omnidirectional robots. The goal is to generate control commands that allow such a robot to simultaneously localize itself and map an unknown environment while maximizing the amount of information gained and consume as little energy as possible. Leveraging the robot's independent translation and rotation control, we introduce a multi-layered approach for active V-SLAM. The top layer decides on informative goal locations and generates highly informative paths to them. The second and third layers actively re-plan and execute the path, exploiting the continuously updated map. Moreover, they allow the robot to maximize its visibility of 3D visual features in the environment. Through rigorous simulations, real robot experiments and comparisons with the state-of-the-art methods, we demonstrate that our approach achieves similar coverage and lesser overall map entropy while keeping the traversed distance up to 36% less than the other methods. Code and implementation details are provided as open-source.
HumAID: Human-Annotated Disaster Incidents Data from Twitter with Deep Learning Benchmarks
Apr 08, 2021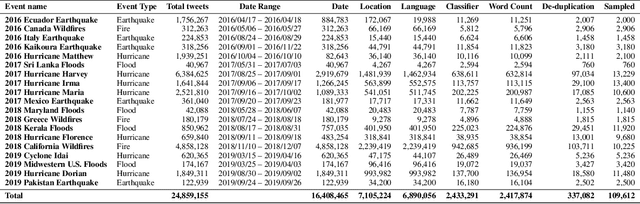
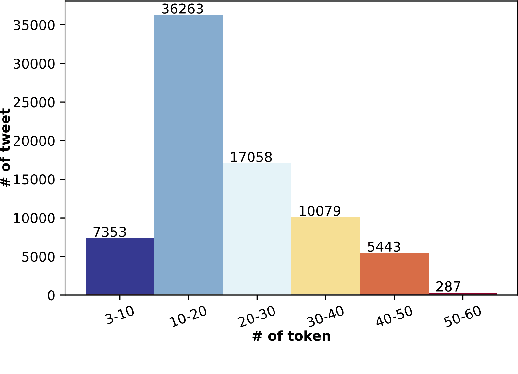
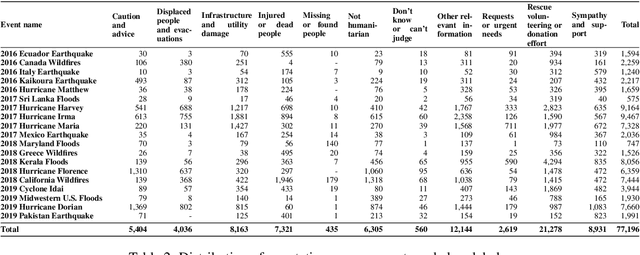
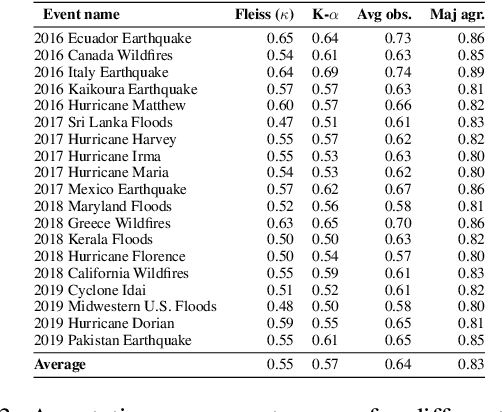
Social networks are widely used for information consumption and dissemination, especially during time-critical events such as natural disasters. Despite its significantly large volume, social media content is often too noisy for direct use in any application. Therefore, it is important to filter, categorize, and concisely summarize the available content to facilitate effective consumption and decision-making. To address such issues automatic classification systems have been developed using supervised modeling approaches, thanks to the earlier efforts on creating labeled datasets. However, existing datasets are limited in different aspects (e.g., size, contains duplicates) and less suitable to support more advanced and data-hungry deep learning models. In this paper, we present a new large-scale dataset with ~77K human-labeled tweets, sampled from a pool of ~24 million tweets across 19 disaster events that happened between 2016 and 2019. Moreover, we propose a data collection and sampling pipeline, which is important for social media data sampling for human annotation. We report multiclass classification results using classic and deep learning (fastText and transformer) based models to set the ground for future studies. The dataset and associated resources are publicly available. https://crisisnlp.qcri.org/humaid_dataset.html
MRI-based Alzheimer's disease prediction via distilling the knowledge in multi-modal data
Apr 08, 2021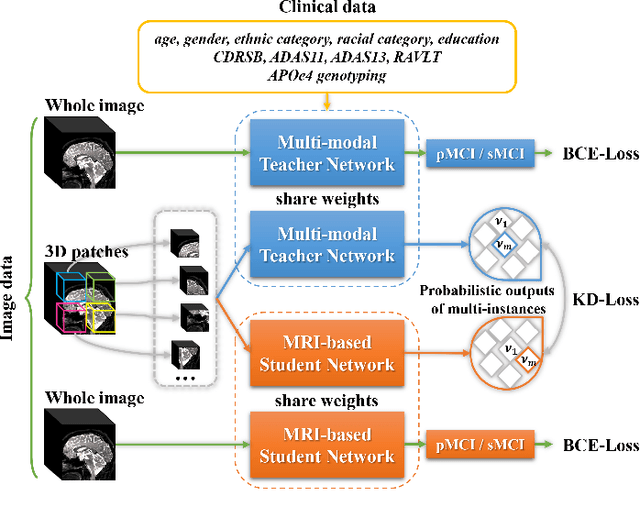
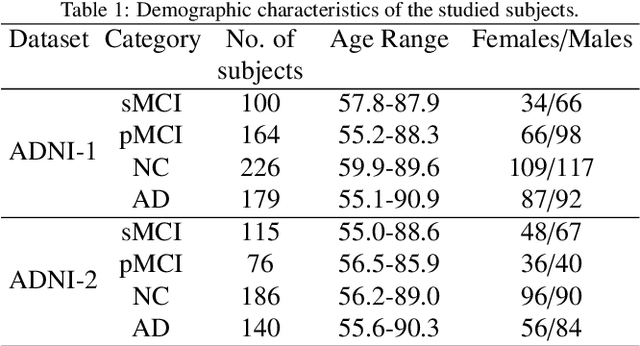
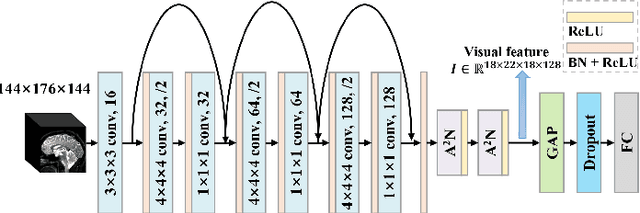
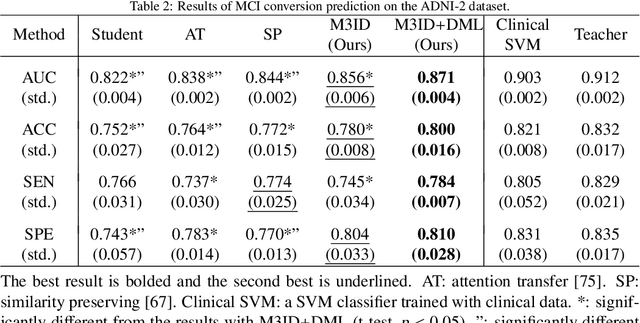
Mild cognitive impairment (MCI) conversion prediction, i.e., identifying MCI patients of high risks converting to Alzheimer's disease (AD), is essential for preventing or slowing the progression of AD. Although previous studies have shown that the fusion of multi-modal data can effectively improve the prediction accuracy, their applications are largely restricted by the limited availability or high cost of multi-modal data. Building an effective prediction model using only magnetic resonance imaging (MRI) remains a challenging research topic. In this work, we propose a multi-modal multi-instance distillation scheme, which aims to distill the knowledge learned from multi-modal data to an MRI-based network for MCI conversion prediction. In contrast to existing distillation algorithms, the proposed multi-instance probabilities demonstrate a superior capability of representing the complicated atrophy distributions, and can guide the MRI-based network to better explore the input MRI. To our best knowledge, this is the first study that attempts to improve an MRI-based prediction model by leveraging extra supervision distilled from multi-modal information. Experiments demonstrate the advantage of our framework, suggesting its potentials in the data-limited clinical settings.
Adaptive Degradation Process with Deep Learning-Driven Trajectory
Mar 22, 2021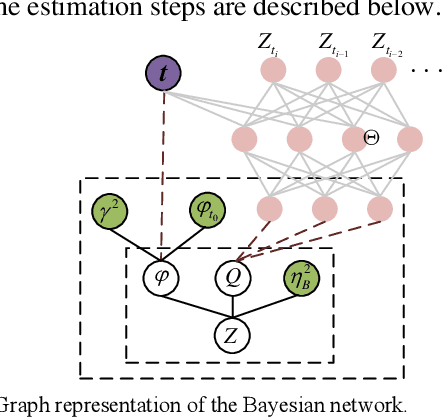
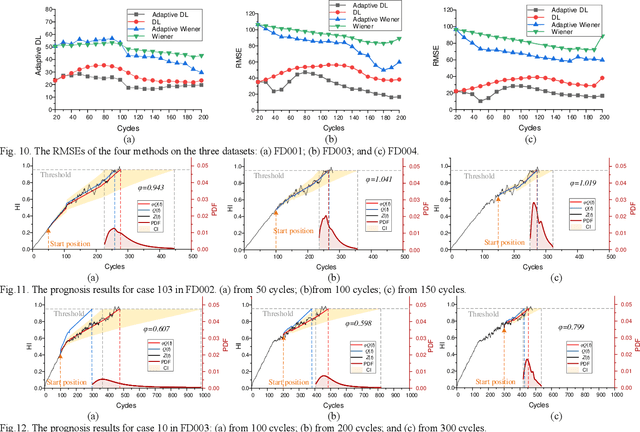
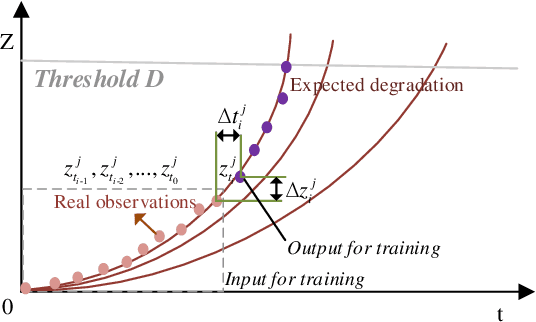
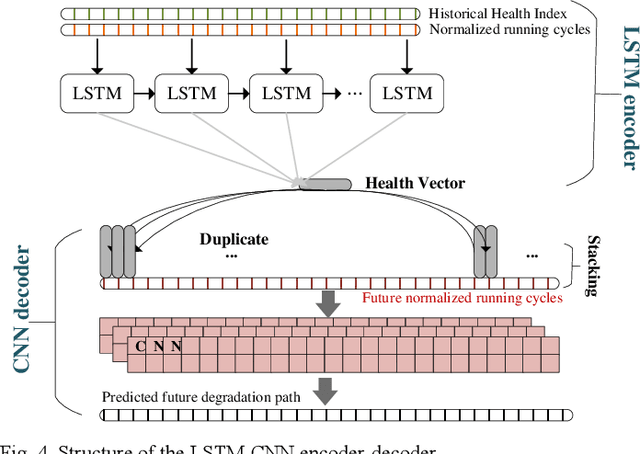
Remaining useful life (RUL) estimation is a crucial component in the implementation of intelligent predictive maintenance and health management. Deep neural network (DNN) approaches have been proven effective in RUL estimation due to their capacity in handling high-dimensional non-linear degradation features. However, the applications of DNN in practice face two challenges: (a) online update of lifetime information is often unavailable, and (b) uncertainties in predicted values may not be analytically quantified. This paper addresses these issues by developing a hybrid DNN-based prognostic approach, where a Wiener-based-degradation model is enhanced with adaptive drift to characterize the system degradation. An LSTM-CNN encoder-decoder is developed to predict future degradation trajectories by jointly learning noise coefficients as well as drift coefficients, and adaptive drift is updated via Bayesian inference. A computationally efficient algorithm is proposed for the calculation of RUL distributions. Numerical experiments are presented using turbofan engines degradation data to demonstrate the superior accuracy of RUL prediction of our proposed approach.
Progressively Complementary Network for Fisheye Image Rectification Using Appearance Flow
Mar 31, 2021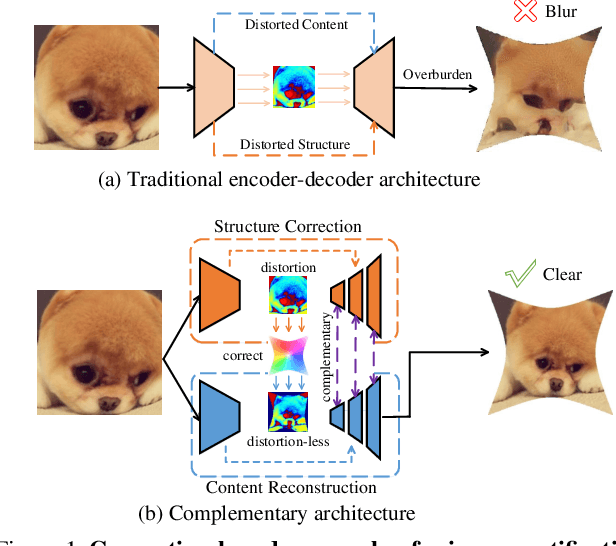
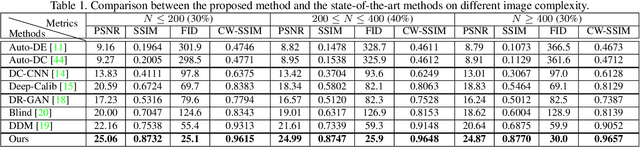
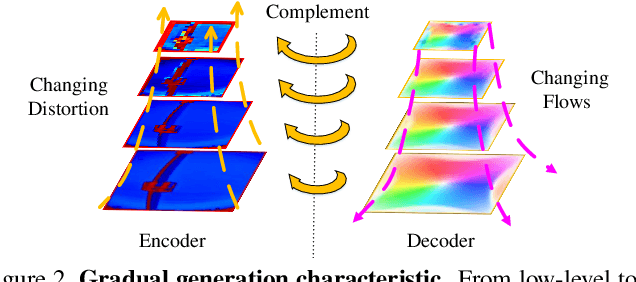
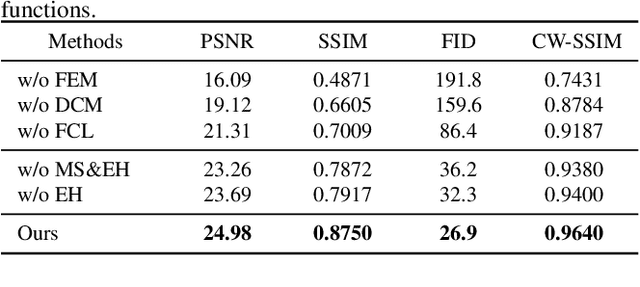
Distortion rectification is often required for fisheye images. The generation-based method is one mainstream solution due to its label-free property, but its naive skip-connection and overburdened decoder will cause blur and incomplete correction. First, the skip-connection directly transfers the image features, which may introduce distortion and cause incomplete correction. Second, the decoder is overburdened during simultaneously reconstructing the content and structure of the image, resulting in vague performance. To solve these two problems, in this paper, we focus on the interpretable correction mechanism of the distortion rectification network and propose a feature-level correction scheme. We embed a correction layer in skip-connection and leverage the appearance flows in different layers to pre-correct the image features. Consequently, the decoder can easily reconstruct a plausible result with the remaining distortion-less information. In addition, we propose a parallel complementary structure. It effectively reduces the burden of the decoder by separating content reconstruction and structure correction. Subjective and objective experiment results on different datasets demonstrate the superiority of our method.
Semantic SLAM with Autonomous Object-Level Data Association
Nov 20, 2020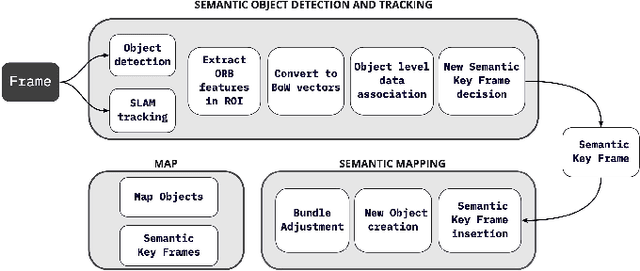



It is often desirable to capture and map semantic information of an environment during simultaneous localization and mapping (SLAM). Such semantic information can enable a robot to better distinguish places with similar low-level geometric and visual features and perform high-level tasks that use semantic information about objects to be manipulated and environments to be navigated. While semantic SLAM has gained increasing attention, there is little research on semanticlevel data association based on semantic objects, i.e., object-level data association. In this paper, we propose a novel object-level data association algorithm based on bag of words algorithm, formulated as a maximum weighted bipartite matching problem. With object-level data association solved, we develop a quadratic-programming-based semantic object initialization scheme using dual quadric and introduce additional constraints to improve the success rate of object initialization. The integrated semantic-level SLAM system can achieve high-accuracy object-level data association and real-time semantic mapping as demonstrated in the experiments. The online semantic map building and semantic-level localization capabilities facilitate semantic-level mapping and task planning in a priori unknown environment.
Neural Lumigraph Rendering
Mar 22, 2021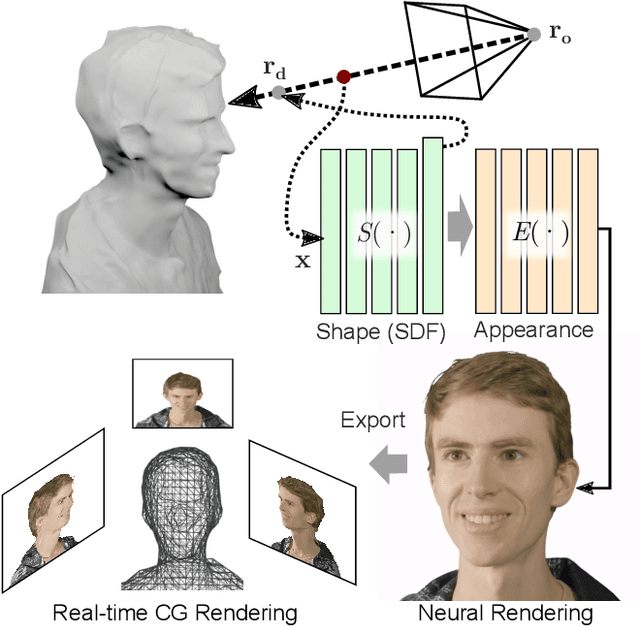


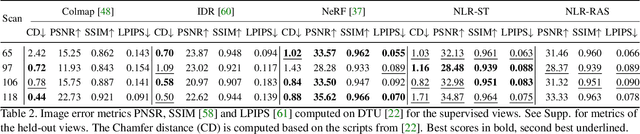
Novel view synthesis is a challenging and ill-posed inverse rendering problem. Neural rendering techniques have recently achieved photorealistic image quality for this task. State-of-the-art (SOTA) neural volume rendering approaches, however, are slow to train and require minutes of inference (i.e., rendering) time for high image resolutions. We adopt high-capacity neural scene representations with periodic activations for jointly optimizing an implicit surface and a radiance field of a scene supervised exclusively with posed 2D images. Our neural rendering pipeline accelerates SOTA neural volume rendering by about two orders of magnitude and our implicit surface representation is unique in allowing us to export a mesh with view-dependent texture information. Thus, like other implicit surface representations, ours is compatible with traditional graphics pipelines, enabling real-time rendering rates, while achieving unprecedented image quality compared to other surface methods. We assess the quality of our approach using existing datasets as well as high-quality 3D face data captured with a custom multi-camera rig.
Relational Subsets Knowledge Distillation for Long-tailed Retinal Diseases Recognition
Apr 22, 2021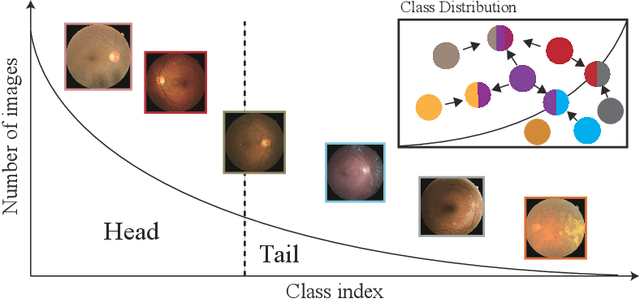

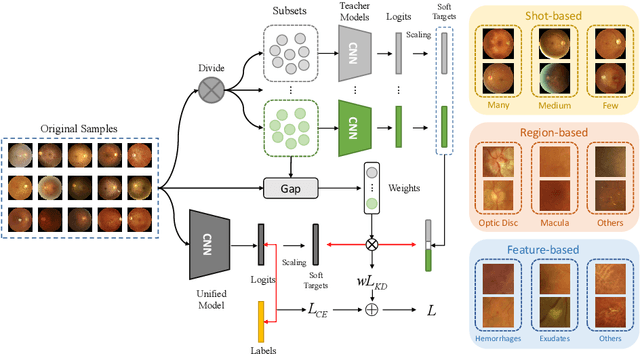
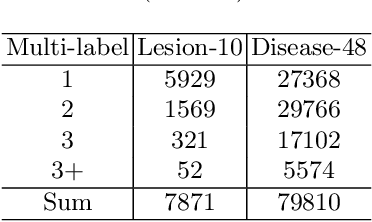
In the real world, medical datasets often exhibit a long-tailed data distribution (i.e., a few classes occupy most of the data, while most classes have rarely few samples), which results in a challenging imbalance learning scenario. For example, there are estimated more than 40 different kinds of retinal diseases with variable morbidity, however with more than 30+ conditions are very rare from the global patient cohorts, which results in a typical long-tailed learning problem for deep learning-based screening models. In this study, we propose class subset learning by dividing the long-tailed data into multiple class subsets according to prior knowledge, such as regions and phenotype information. It enforces the model to focus on learning the subset-specific knowledge. More specifically, there are some relational classes that reside in the fixed retinal regions, or some common pathological features are observed in both the majority and minority conditions. With those subsets learnt teacher models, then we are able to distill the multiple teacher models into a unified model with weighted knowledge distillation loss. The proposed framework proved to be effective for the long-tailed retinal diseases recognition task. The experimental results on two different datasets demonstrate that our method is flexible and can be easily plugged into many other state-of-the-art techniques with significant improvements.