 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scalable and Adaptive Graph Neural Networks with Self-Label-Enhanced training
Apr 19, 2021
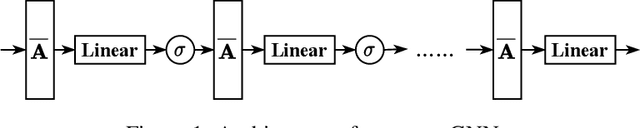
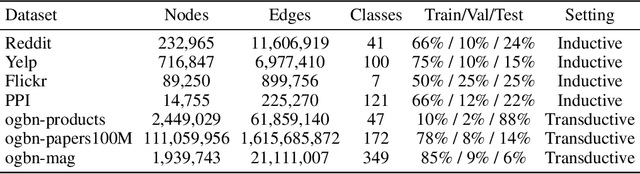
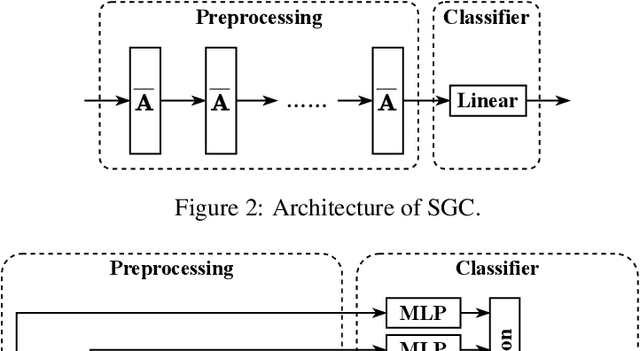
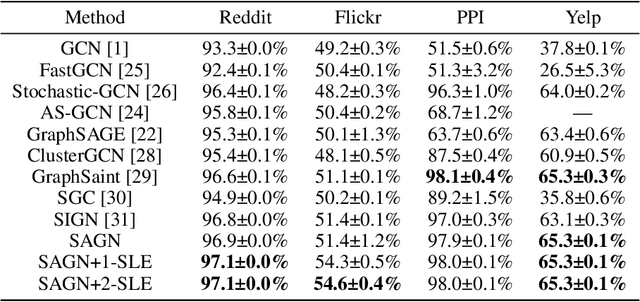
It is hard to directly implement Graph Neural Networks (GNNs) on large scaled graphs. Besides of existed neighbor sampling techniques, scalable methods decoupling graph convolutions and other learnable transformations into preprocessing and post classifier allow normal minibatch training. By replacing redundant concatenation operation with attention mechanism in SIGN, we propose Scalable and Adaptive Graph Neural Networks (SAGN). SAGN can adaptively gather neighborhood information among different hops. To further improve scalable models on semi-supervised learning tasks, we propose Self-Label-Enhance (SLE) framework combining self-training approach and label propagation in depth. We add base model with a scalable node label module. Then we iteratively train models and enhance train set in several stages. To generate input of node label module, we directly apply label propagation based on one-hot encoded label vectors without inner random masking. We find out that empirically the label leakage has been effectively alleviated after graph convolutions. The hard pseudo labels in enhanced train set participate in label propagation with true labels. Experiments on both inductive and transductive datasets demonstrate that, compared with other sampling-based and sampling-free methods, SAGN achieves better or comparable results and SLE can further improve performance.
LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference
Apr 02, 2021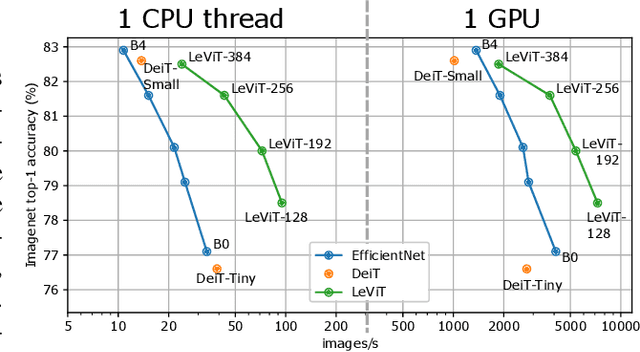
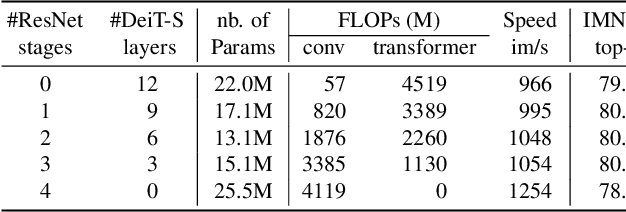

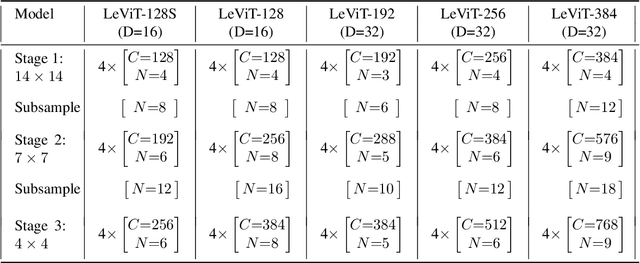
We design a family of image classification architectures that optimize the trade-off between accuracy and efficiency in a high-speed regime. Our work exploits recent findings in attention-based architectures, which are competitive on highly parallel processing hardware. We re-evaluated principles from the extensive literature on convolutional neural networks to apply them to transformers, in particular activation maps with decreasing resolutions. We also introduce the attention bias, a new way to integrate positional information in vision transformers. As a result, we propose LeVIT: a hybrid neural network for fast inference image classification. We consider different measures of efficiency on different hardware platforms, so as to best reflect a wide range of application scenarios. Our extensive experiments empirically validate our technical choices and show they are suitable to most architectures. Overall, LeViT significantly outperforms existing convnets and vision transformers with respect to the speed/accuracy tradeoff. For example, at 80\% ImageNet top-1 accuracy, LeViT is 3.3 times faster than EfficientNet on the CPU.
Continual learning in cross-modal retrieval
Apr 19, 2021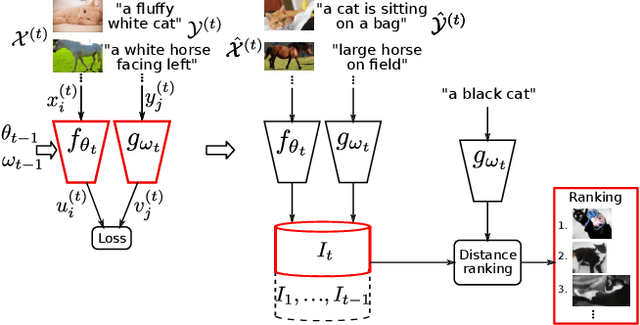
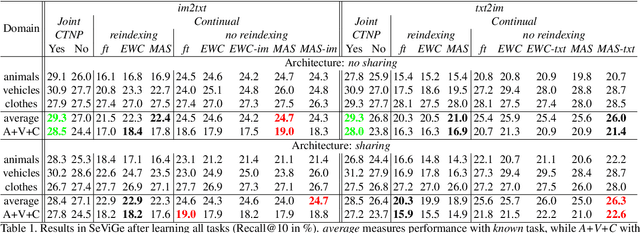
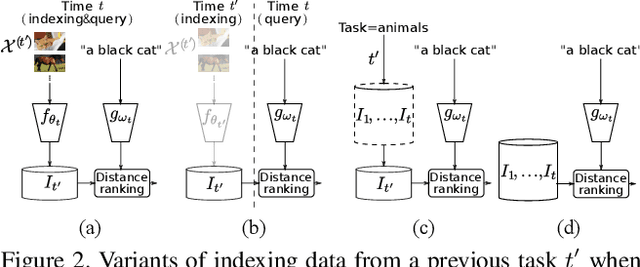
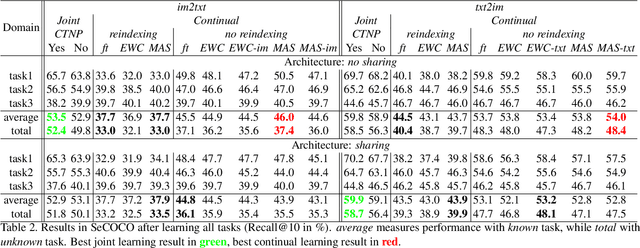
Multimodal representations and continual learning are two areas closely related to human intelligence. The former considers the learning of shared representation spaces where information from different modalities can be compared and integrated (we focus on cross-modal retrieval between language and visual representations). The latter studies how to prevent forgetting a previously learned task when learning a new one. While humans excel in these two aspects, deep neural networks are still quite limited. In this paper, we propose a combination of both problems into a continual cross-modal retrieval setting, where we study how the catastrophic interference caused by new tasks impacts the embedding spaces and their cross-modal alignment required for effective retrieval. We propose a general framework that decouples the training, indexing and querying stages. We also identify and study different factors that may lead to forgetting, and propose tools to alleviate it. We found that the indexing stage pays an important role and that simply avoiding reindexing the database with updated embedding networks can lead to significant gains. We evaluated our methods in two image-text retrieval datasets, obtaining significant gains with respect to the fine tuning baseline.
Empirical Study of Transformers for Source Code
Oct 15, 2020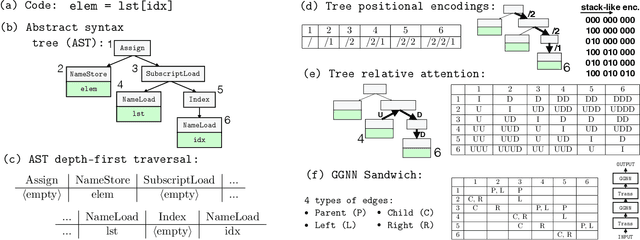


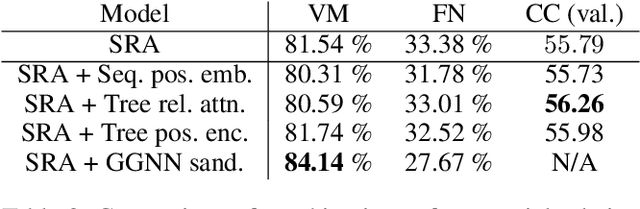
Initially developed for natural language processing (NLP), Transformers are now widely used for source code processing, due to the format similarity between source code and text. In contrast to natural language, source code is strictly structured, i. e. follows the syntax of the programming language. Several recent works develop Transformer modifications for capturing syntactic information in source code. The drawback of these works is that they do not compare to each other and all consider different tasks. In this work, we conduct a thorough empirical study of the capabilities of Transformers to utilize syntactic information in different tasks. We consider three tasks (code completion, function naming and bug fixing) and re-implement different syntax-capturing modifications in a unified framework. We show that Transformers are able to make meaningful predictions based purely on syntactic information and underline the best practices of taking the syntactic information into account for improving the performance of the model.
An HVS-Oriented Saliency Map Prediction Modeling
Nov 16, 2020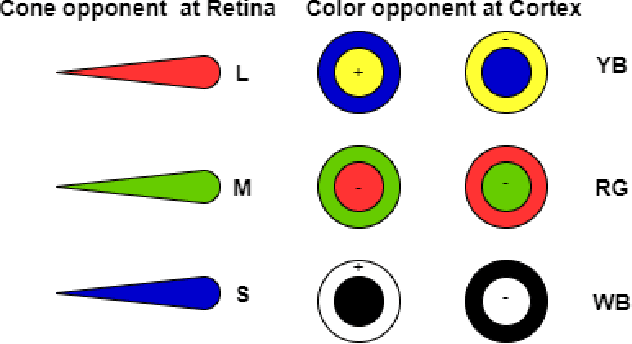
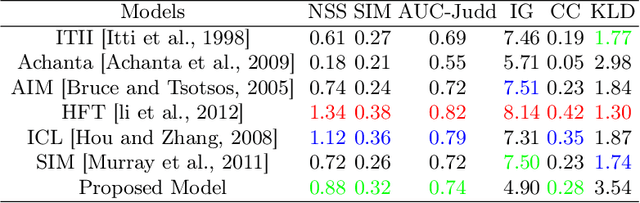

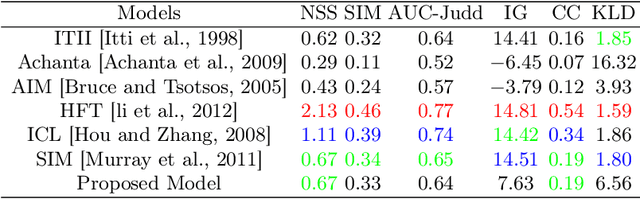
Visual attention is one of the most significant characteristics for selecting and understanding the outside world. The nature complex scenes, including larger redundancy and human vision, can't be processing all information simultaneously because of the information bottleneck. The visual system mainly focuses on dominant parts of the scenes to reduce the input visual redundancy information. It's commonly known as visual attention prediction or visual saliency map. This paper proposes a new saliency prediction architecture inspired by human low-level visual cortex function. The model considered the opponent color channel, wavelet energy map, and contrast sensitivity function for extract image features and maximum approach to real visual neural network function in the brain. The proposed model is evaluated several datasets, including MIT1003, MIT300, TORONTO, and SID4VAM to explain its efficiency. The proposed model results are quantitatively and qualitatively compared to other state-of-the-art salience prediction models and their achieved out-performing of visual saliency prediction.
CFPNet-M: A Light-Weight Encoder-Decoder Based Network for Multimodal Biomedical Image Real-Time Segmentation
May 10, 2021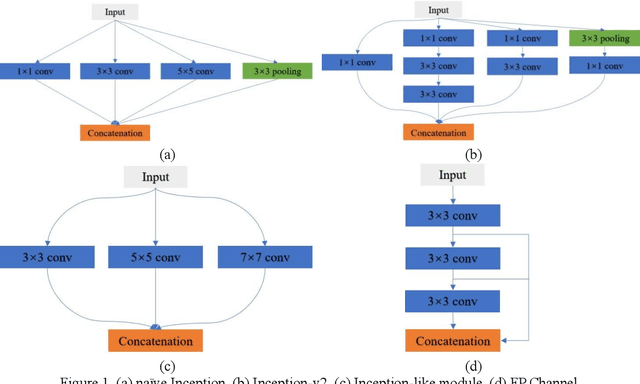
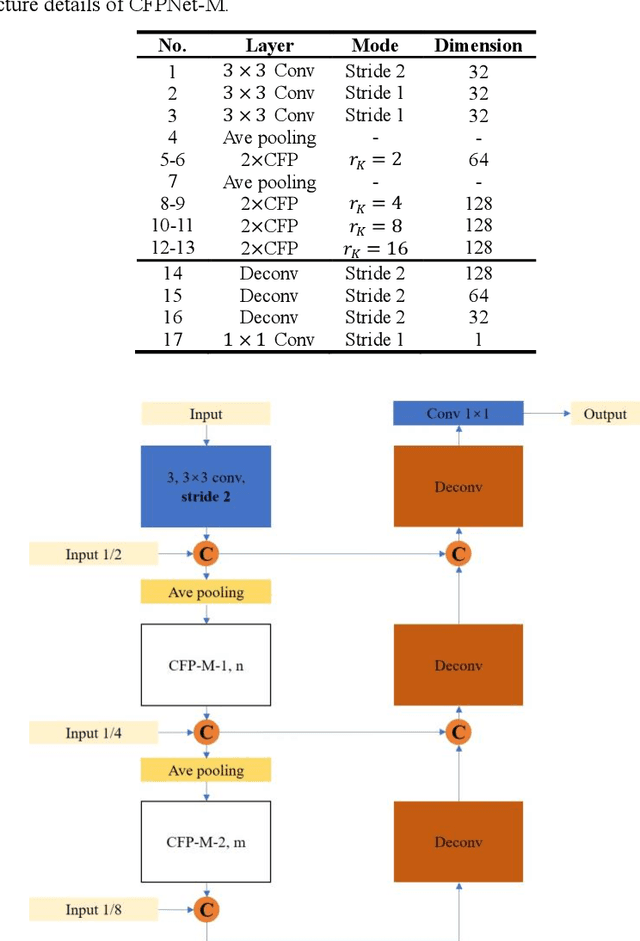
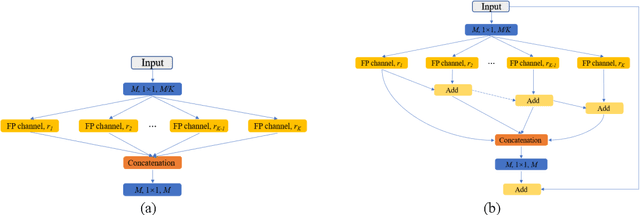

Currently, developments of deep learning techniques are providing instrumental to identify, classify, and quantify patterns in medical images. Segmentation is one of the important applications in medical image analysis. In this regard, U-Net is the predominant approach to medical image segmentation tasks. However, we found that those U-Net based models have limitations in several aspects, for example, millions of parameters in the U-Net consuming considerable computation resource and memory, lack of global information, and missing some tough objects. Therefore, we applied two modifications to improve the U-Net model: 1) designed and added the dilated channel-wise CNN module, 2) simplified the U shape network. Based on these two modifications, we proposed a novel light-weight architecture -- Channel-wise Feature Pyramid Network for Medicine (CFPNet-M). To evaluate our method, we selected five datasets with different modalities: thermography, electron microscopy, endoscopy, dermoscopy, and digital retinal images. And we compared its performance with several models having different parameter scales. This paper also involves our previous studies of DC-UNet and some commonly used light-weight neural networks. We applied the Tanimoto similarity instead of the Jaccard index for gray-level image measurements. By comparison, CFPNet-M achieves comparable segmentation results on all five medical datasets with only 0.65 million parameters, which is about 2% of U-Net, and 8.8 MB memory. Meanwhile, the inference speed can reach 80 FPS on a single RTX 2070Ti GPU with the 256 by 192 pixels input size.
4D Attention-based Neural Network for EEG Emotion Recognition
Jan 14, 2021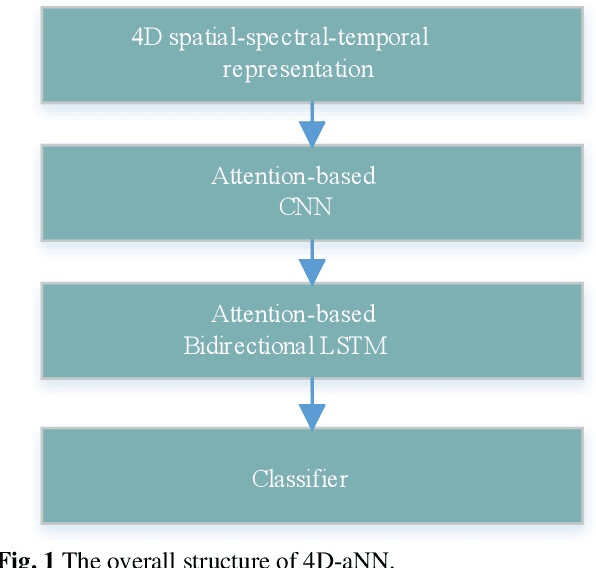
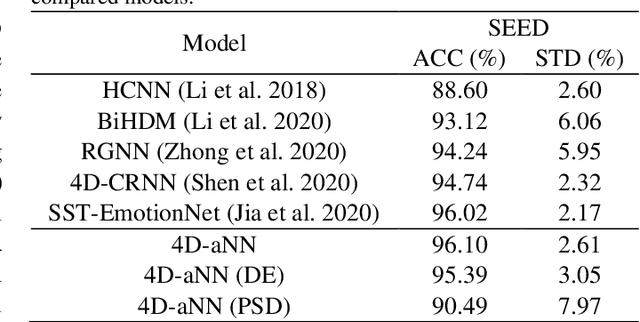
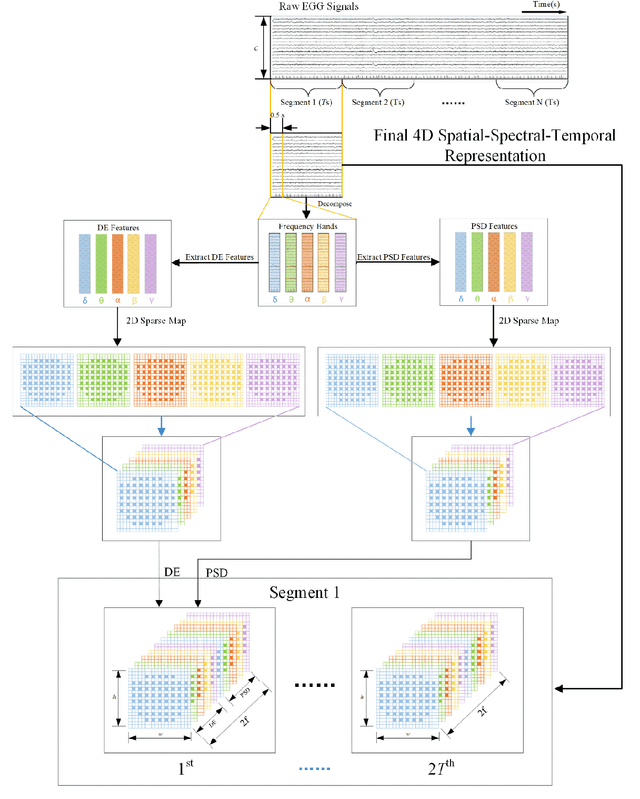
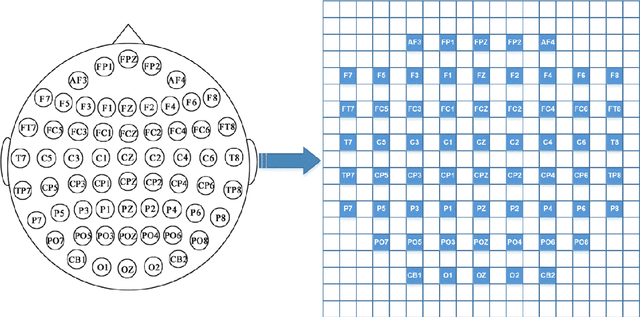
Electroencephalograph (EEG) emotion recognition is a significant task in the brain-computer interface field. Although many deep learning methods are proposed recently, it is still challenging to make full use of the information contained in different domains of EEG signals. In this paper, we present a novel method, called four-dimensional attention-based neural network (4D-aNN) for EEG emotion recognition. First, raw EEG signals are transformed into 4D spatial-spectral-temporal representations. Then, the proposed 4D-aNN adopts spectral and spatial attention mechanisms to adaptively assign the weights of different brain regions and frequency bands, and a convolutional neural network (CNN) is utilized to deal with the spectral and spatial information of the 4D representations. Moreover, a temporal attention mechanism is integrated into a bidirectional Long Short-Term Memory (LSTM) to explore temporal dependencies of the 4D representations. Our model achieves state-of-the-art performance on the SEED dataset under intra-subject splitting. The experimental results have shown the effectiveness of the attention mechanisms in different domains for EEG emotion recognition.
Asymptotic Risk of Overparameterized Likelihood Models: Double Descent Theory for Deep Neural Networks
Feb 28, 2021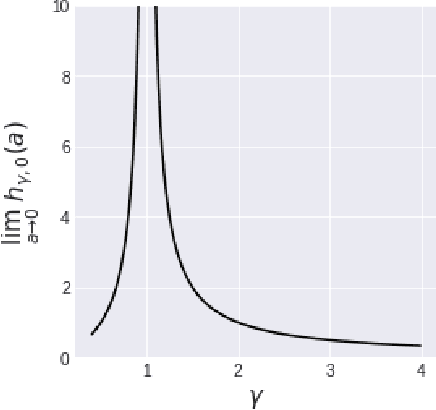
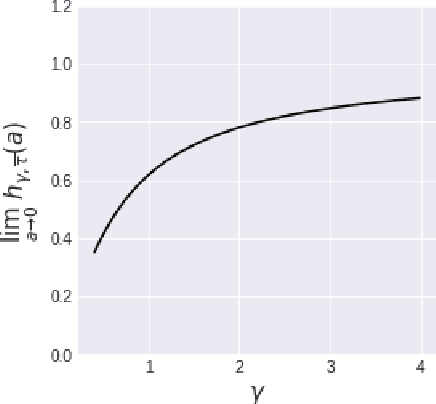
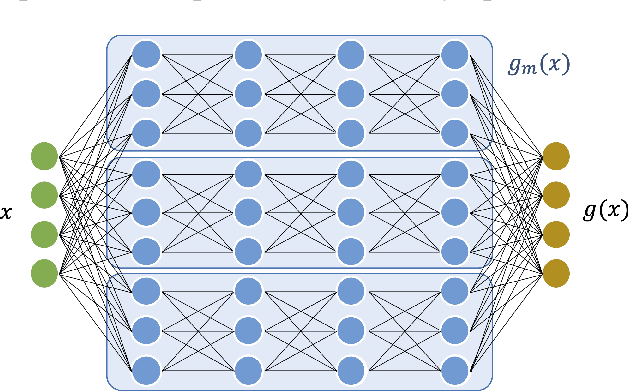
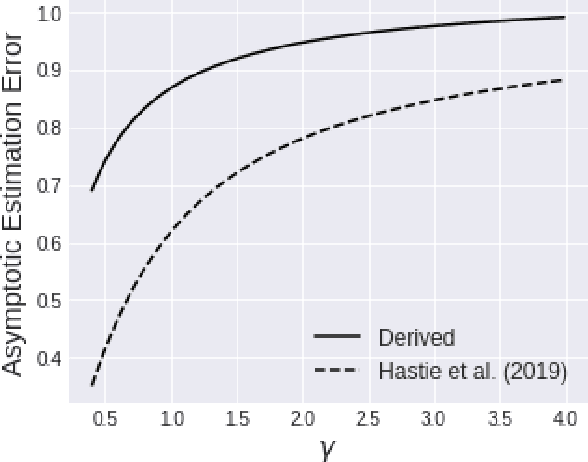
We investigate the asymptotic risk of a general class of overparameterized likelihood models, including deep models. The recent empirical success of large-scale models has motivated several theoretical studies to investigate a scenario wherein both the number of samples, $n$, and parameters, $p$, diverge to infinity and derive an asymptotic risk at the limit. However, these theorems are only valid for linear-in-feature models, such as generalized linear regression, kernel regression, and shallow neural networks. Hence, it is difficult to investigate a wider class of nonlinear models, including deep neural networks with three or more layers. In this study, we consider a likelihood maximization problem without the model constraints and analyze the upper bound of an asymptotic risk of an estimator with penalization. Technically, we combine a property of the Fisher information matrix with an extended Marchenko-Pastur law and associate the combination with empirical process techniques. The derived bound is general, as it describes both the double descent and the regularized risk curves, depending on the penalization. Our results are valid without the linear-in-feature constraints on models and allow us to derive the general spectral distributions of a Fisher information matrix from the likelihood. We demonstrate that several explicit models, such as parallel deep neural networks and ensemble learning, are in agreement with our theory. This result indicates that even large and deep models have a small asymptotic risk if they exhibit a specific structure, such as divisibility. To verify this finding, we conduct a real-data experiment with parallel deep neural networks. Our results expand the applicability of the asymptotic risk analysis, and may also contribute to the understanding and application of deep learning.
Modified SMOTE Using Mutual Information and Different Sorts of Entropies
Mar 29, 2018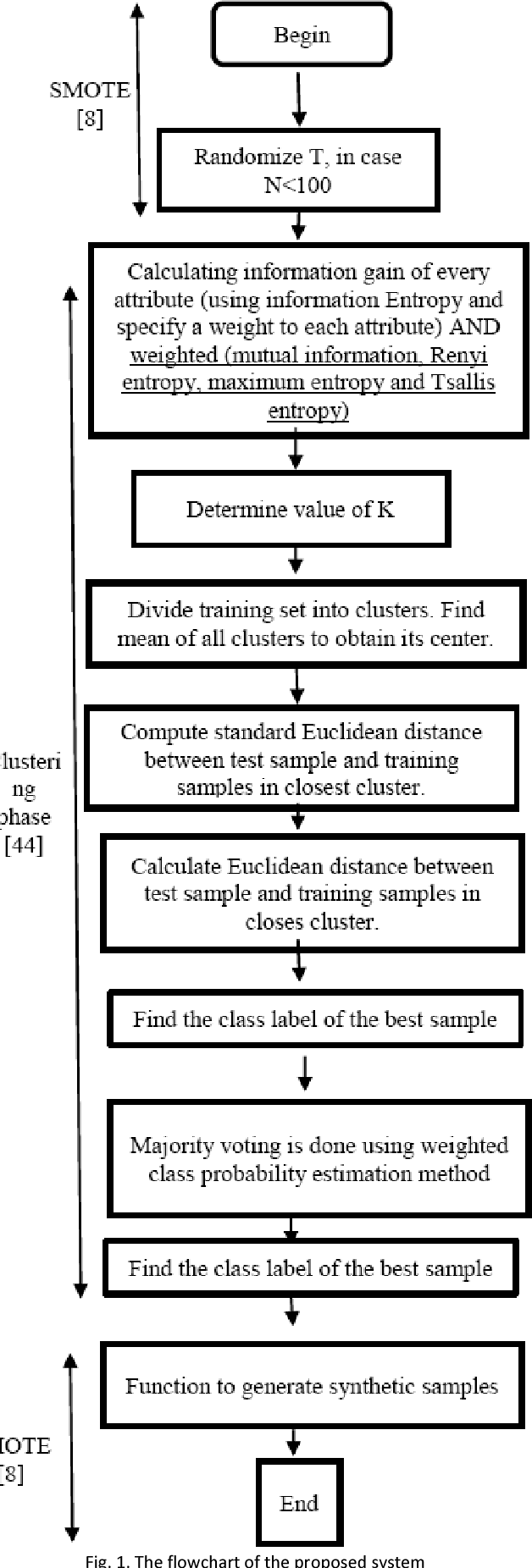
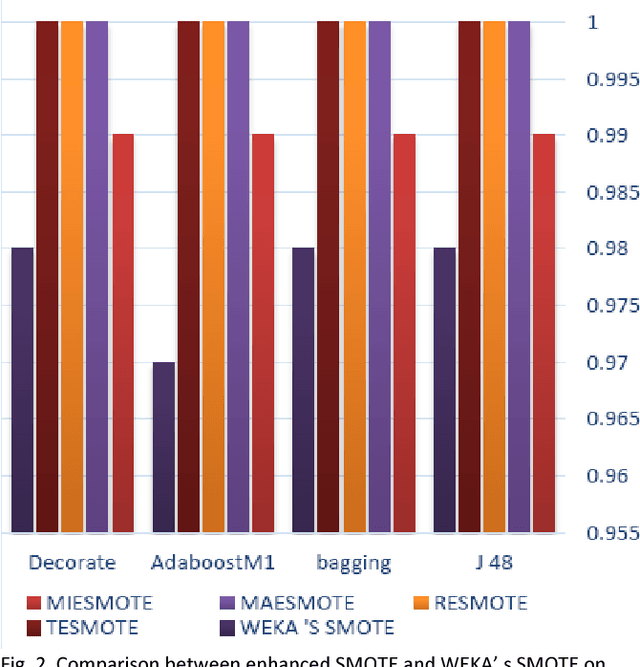
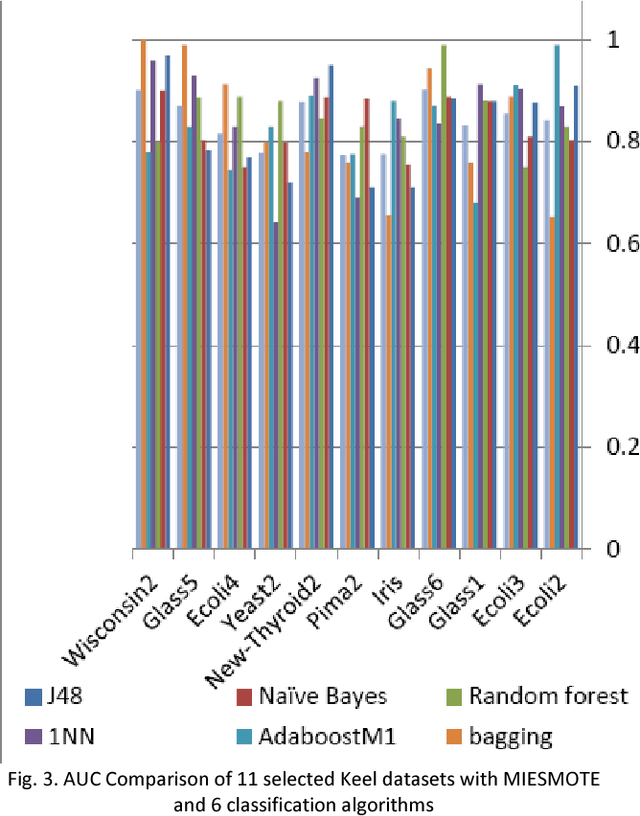
SMOTE is one of the oversampling techniques for balancing the datasets and it is considered as a pre-processing step in learning algorithms. In this paper, four new enhanced SMOTE are proposed that include an improved version of KNN in which the attribute weights are defined by mutual information firstly and then they are replaced by maximum entropy, Renyi entropy and Tsallis entropy. These four pre-processing methods are combined with 1NN and J48 classifiers and their performance are compared with the previous methods on 11 imbalanced datasets from KEEL repository. The results show that these pre-processing methods improves the accuracy compared with the previous stablished works. In addition, as a case study, the first pre-processing method is applied on transportation data of Tehran-Bazargan Highway in Iran with IR equal to 36.
Ordinal Pooling Networks: For Preserving Information over Shrinking Feature Maps
Apr 15, 2018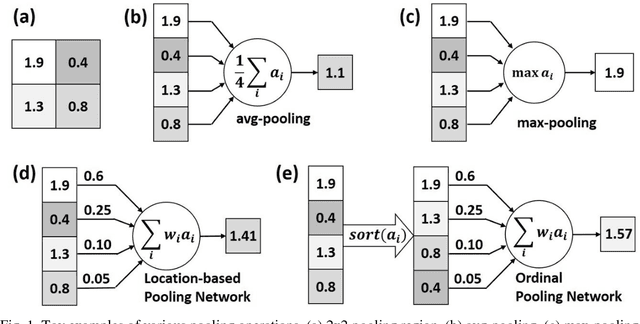
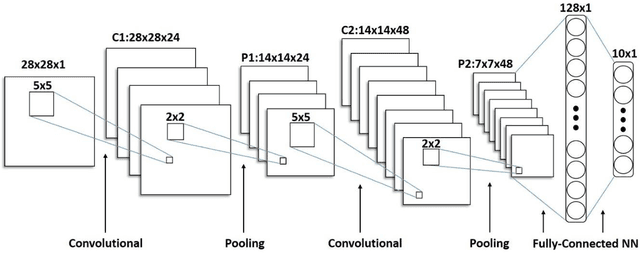
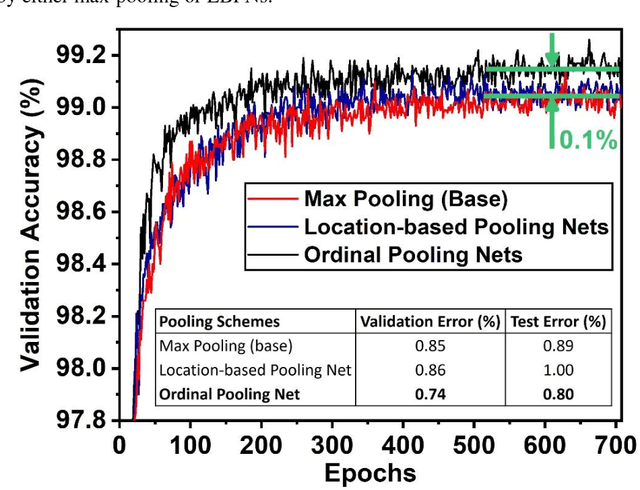
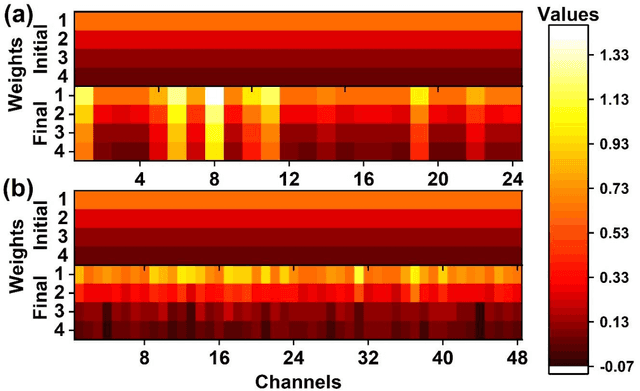
In the framework of convolutional neural networks that lie at the heart of deep learning, downsampling is often performed with a max-pooling operation that only retains the element with maximum activation, while completely discarding the information contained in other elements in a pooling region. To address this issue, a novel pooling scheme, Ordinal Pooling Network (OPN), is introduced in this work. OPN rearranges all the elements of a pooling region in a sequence and assigns different weights to these elements based upon their orders in the sequence, where the weights are learned via the gradient-based optimisation. The results of our small-scale experiments on image classification task demonstrate that this scheme leads to a consistent improvement in the accuracy over max-pooling operation. This improvement is expected to increase in deeper networks, where several layers of pooling become necessary.