 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users
May 11, 2021
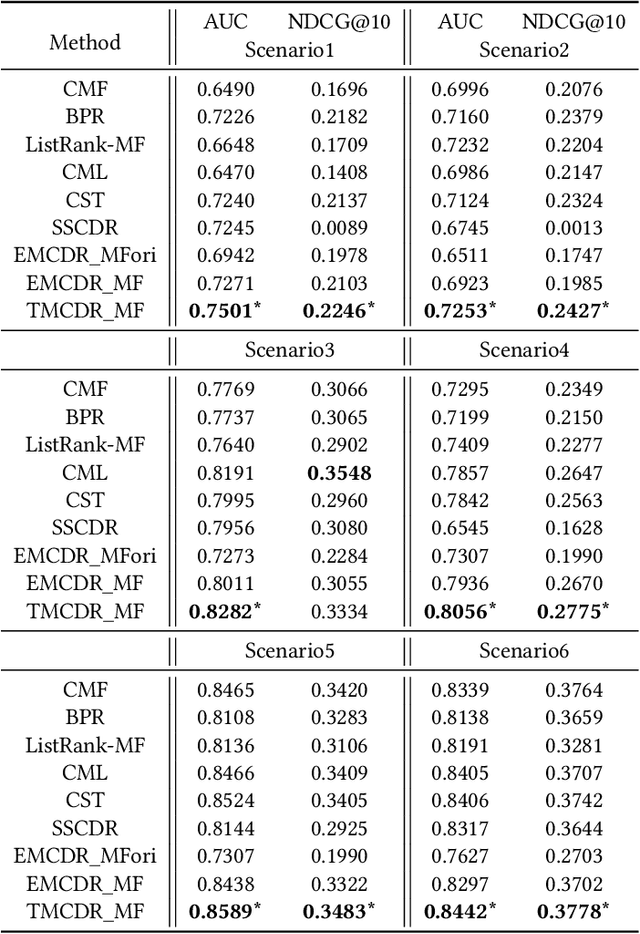
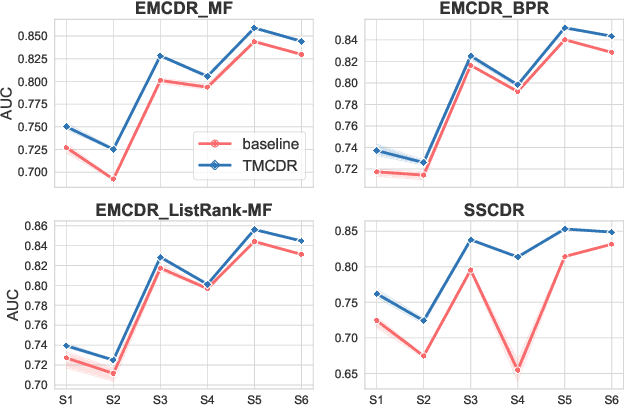
Cold-start problems are enormous challenges in practical recommender systems. One promising solution for this problem is cross-domain recommendation (CDR) which leverages rich information from an auxiliary (source) domain to improve the performance of recommender system in the target domain. In these CDR approaches, the family of Embedding and Mapping methods for CDR (EMCDR) is very effective, which explicitly learn a mapping function from source embeddings to target embeddings with overlapping users. However, these approaches suffer from one serious problem: the mapping function is only learned on limited overlapping users, and the function would be biased to the limited overlapping users, which leads to unsatisfying generalization ability and degrades the performance on cold-start users in the target domain. With the advantage of meta learning which has good generalization ability to novel tasks, we propose a transfer-meta framework for CDR (TMCDR) which has a transfer stage and a meta stage. In the transfer (pre-training) stage, a source model and a target model are trained on source and target domains, respectively. In the meta stage, a task-oriented meta network is learned to implicitly transform the user embedding in the source domain to the target feature space. In addition, the TMCDR is a general framework that can be applied upon various base models, e.g., MF, BPR, CML. By utilizing data from Amazon and Douban, we conduct extensive experiments on 6 cross-domain tasks to demonstrate the superior performance and compatibility of TMCDR.
ZePHyR: Zero-shot Pose Hypothesis Rating
Apr 28, 2021
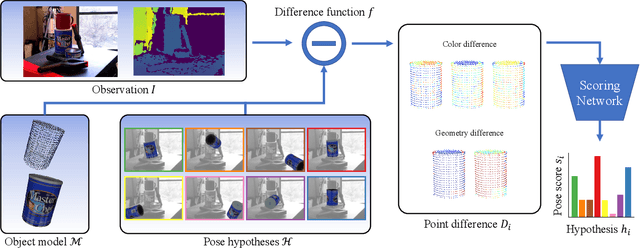

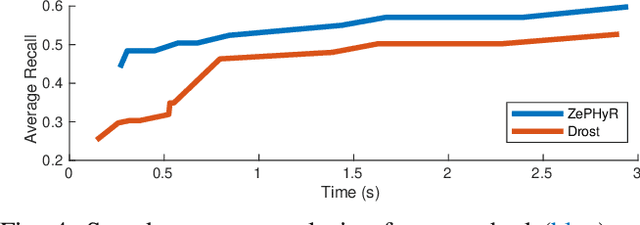
Pose estimation is a basic module in many robot manipulation pipelines. Estimating the pose of objects in the environment can be useful for grasping, motion planning, or manipulation. However, current state-of-the-art methods for pose estimation either rely on large annotated training sets or simulated data. Further, the long training times for these methods prohibit quick interaction with novel objects. To address these issues, we introduce a novel method for zero-shot object pose estimation in clutter. Our approach uses a hypothesis generation and scoring framework, with a focus on learning a scoring function that generalizes to objects not used for training. We achieve zero-shot generalization by rating hypotheses as a function of unordered point differences. We evaluate our method on challenging datasets with both textured and untextured objects in cluttered scenes and demonstrate that our method significantly outperforms previous methods on this task. We also demonstrate how our system can be used by quickly scanning and building a model of a novel object, which can immediately be used by our method for pose estimation. Our work allows users to estimate the pose of novel objects without requiring any retraining. Additional information can be found on our website https://bokorn.github.io/zephyr/
UIT-HSE at WNUT-2020 Task 2: Exploiting CT-BERT for Identifying COVID-19 Information on the Twitter Social Network
Sep 07, 2020


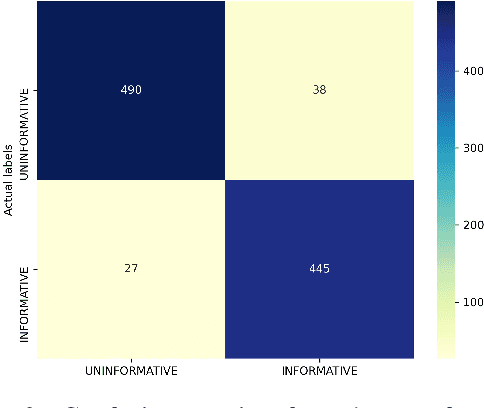
Recently, COVID-19 has affected a variety of real-life aspects of the world and led to dreadful consequences. More and more tweets about COVID-19 has been shared publicly on Twitter. However, the plurality of those Tweets are uninformative, which is challenging to build automatic systems to detect the informative ones for useful AI applications. In this paper, we present our results at the W-NUT 2020 Shared Task 2: Identification of Informative COVID-19 English Tweets. In particular, we propose our simple but effective approach using the transformer-based models based on COVID-Twitter-BERT (CT-BERT) with different fine-tuning techniques. As a result, we achieve the F1-Score of 90.94\% with the third place on the leaderboard of this task which attracted 56 submitted teams in total.
Multiple Sclerosis Lesion Analysis in Brain Magnetic Resonance Images: Techniques and Clinical Applications
Apr 20, 2021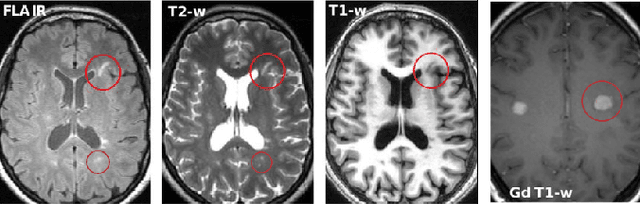
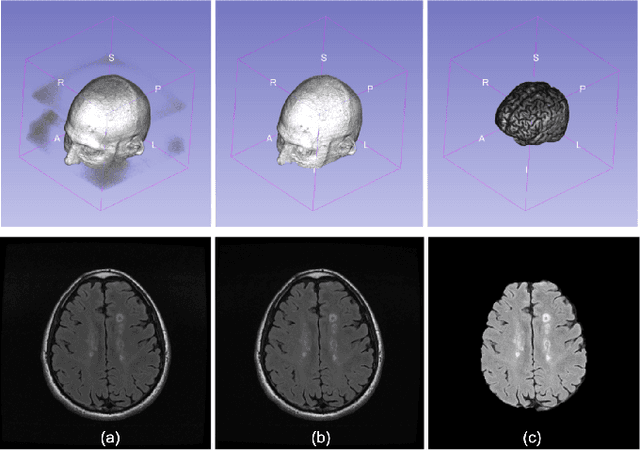
Multiple sclerosis (MS) is a chronic inflammatory and degenerative disease of the central nervous system, characterized by the appearance of focal lesions in the white and gray matter that topographically correlate with an individual patient's neurological symptoms and signs. Magnetic resonance imaging (MRI) provides detailed in-vivo structural information, permitting the quantification and categorization of MS lesions that critically inform disease management. Traditionally, MS lesions have been manually annotated on 2D MRI slices, a process that is inefficient and prone to inter-/intra-observer errors. Recently, automated statistical imaging analysis techniques have been proposed to extract and segment MS lesions based on MRI voxel intensity. However, their effectiveness is limited by the heterogeneity of both MRI data acquisition techniques and the appearance of MS lesions. By learning complex lesion representations directly from images, deep learning techniques have achieved remarkable breakthroughs in the MS lesion segmentation task. Here, we provide a comprehensive review of state-of-the-art automatic statistical and deep-learning MS segmentation methods and discuss current and future clinical applications. Further, we review technical strategies, such as domain adaptation, to enhance MS lesion segmentation in real-world clinical settings.
Latent Correlation Representation Learning for Brain Tumor Segmentation with Missing MRI Modalities
Apr 20, 2021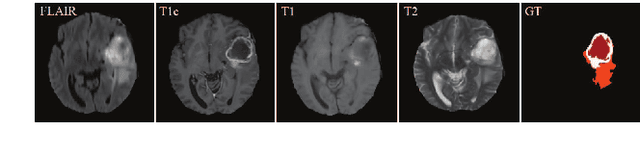
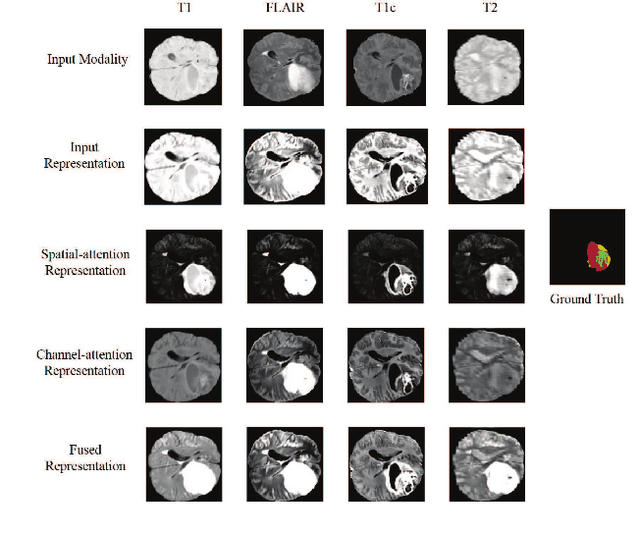
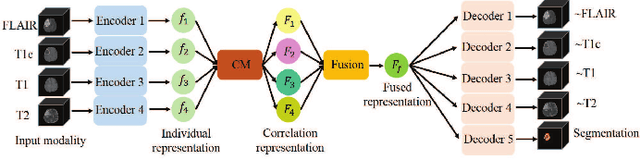
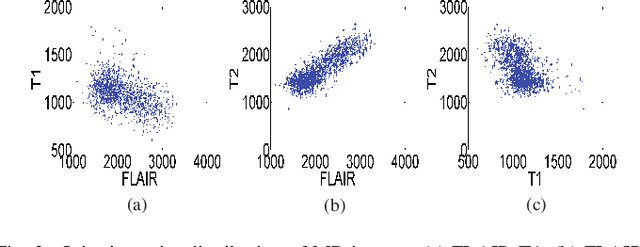
Magnetic Resonance Imaging (MRI) is a widely used imaging technique to assess brain tumor. Accurately segmenting brain tumor from MR images is the key to clinical diagnostics and treatment planning. In addition, multi-modal MR images can provide complementary information for accurate brain tumor segmentation. However, it's common to miss some imaging modalities in clinical practice. In this paper, we present a novel brain tumor segmentation algorithm with missing modalities. Since it exists a strong correlation between multi-modalities, a correlation model is proposed to specially represent the latent multi-source correlation. Thanks to the obtained correlation representation, the segmentation becomes more robust in the case of missing modality. First, the individual representation produced by each encoder is used to estimate the modality independent parameter. Then, the correlation model transforms all the individual representations to the latent multi-source correlation representations. Finally, the correlation representations across modalities are fused via attention mechanism into a shared representation to emphasize the most important features for segmentation. We evaluate our model on BraTS 2018 and BraTS 2019 dataset, it outperforms the current state-of-the-art methods and produces robust results when one or more modalities are missing.
* 12 pages, 10 figures, accepted by IEEE Transactions on Image Processing (8 April 2021). arXiv admin note: text overlap with arXiv:2003.08870, arXiv:2102.03111
Predicting Emotions Perceived from Sounds
Dec 04, 2020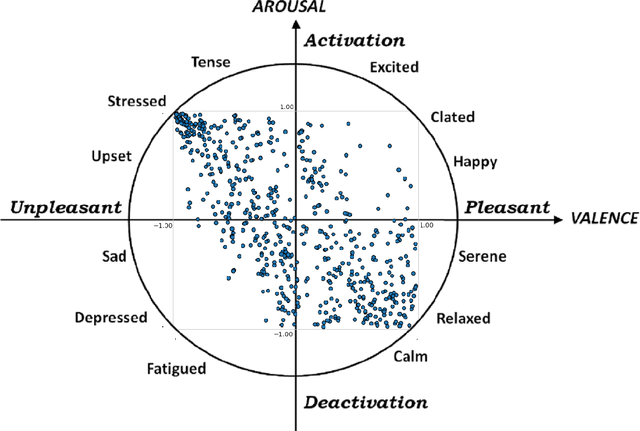
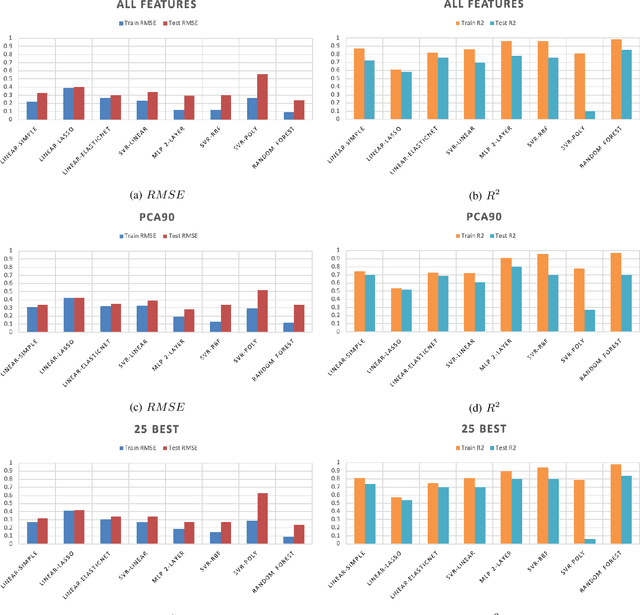
Sonification is the science of communication of data and events to users through sounds. Auditory icons, earcons, and speech are the common auditory display schemes utilized in sonification, or more specifically in the use of audio to convey information. Once the captured data are perceived, their meanings, and more importantly, intentions can be interpreted more easily and thus can be employed as a complement to visualization techniques. Through auditory perception it is possible to convey information related to temporal, spatial, or some other context-oriented information. An important research question is whether the emotions perceived from these auditory icons or earcons are predictable in order to build an automated sonification platform. This paper conducts an experiment through which several mainstream and conventional machine learning algorithms are developed to study the prediction of emotions perceived from sounds. To do so, the key features of sounds are captured and then are modeled using machine learning algorithms using feature reduction techniques. We observe that it is possible to predict perceived emotions with high accuracy. In particular, the regression based on Random Forest demonstrated its superiority compared to other machine learning algorithms.
Global Context Aware RCNN for Object Detection
Dec 04, 2020
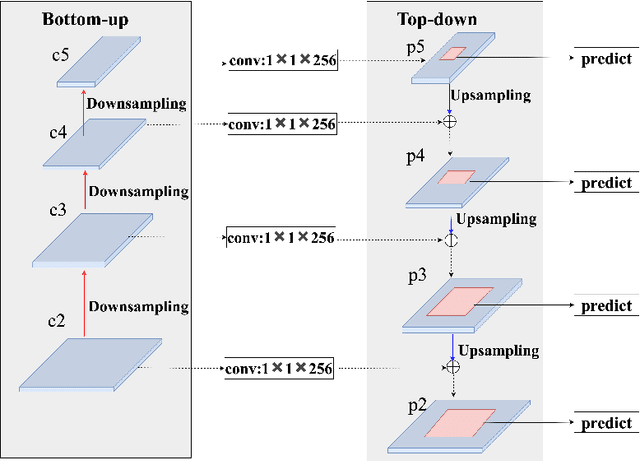
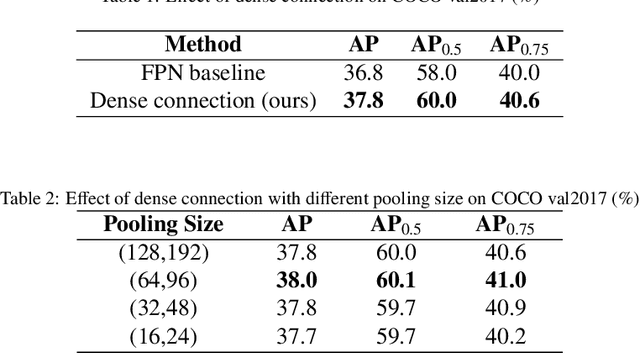
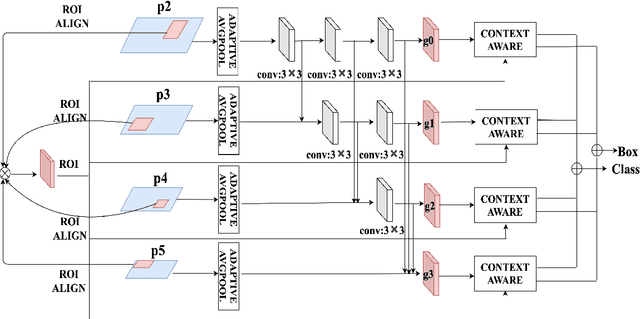
RoIPool/RoIAlign is an indispensable process for the typical two-stage object detection algorithm, it is used to rescale the object proposal cropped from the feature pyramid to generate a fixed size feature map. However, these cropped feature maps of local receptive fields will heavily lose global context information. To tackle this problem, we propose a novel end-to-end trainable framework, called Global Context Aware (GCA) RCNN, aiming at assisting the neural network in strengthening the spatial correlation between the background and the foreground by fusing global context information. The core component of our GCA framework is a context aware mechanism, in which both global feature pyramid and attention strategies are used for feature extraction and feature refinement, respectively. Specifically, we leverage the dense connection to improve the information flow of the global context at different stages in the top-down process of FPN, and further use the attention mechanism to refine the global context at each level in the feature pyramid. In the end, we also present a lightweight version of our method, which only slightly increases model complexity and computational burden. Experimental results on COCO benchmark dataset demonstrate the significant advantages of our approach.
Learning Robust Beamforming for MISO Downlink Systems
Mar 02, 2021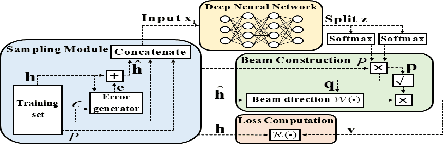
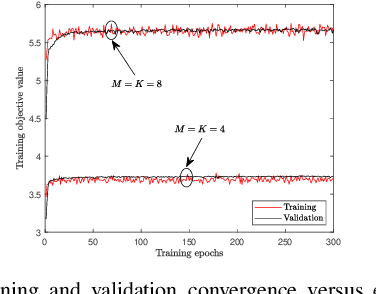
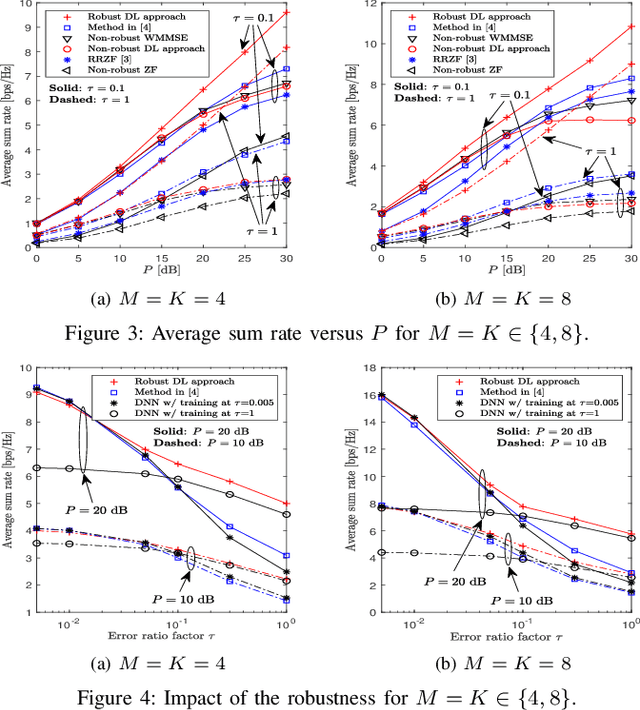
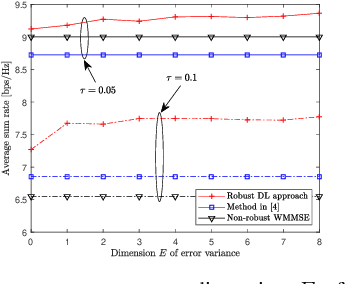
This paper investigates a learning solution for robust beamforming optimization in downlink multi-user systems. A base station (BS) identifies efficient multi-antenna transmission strategies only with imperfect channel state information (CSI) and its stochastic features. To this end, we propose a robust training algorithm where a deep neural network (DNN), which only accepts estimates and statistical knowledge of the perfect CSI, is optimized to fit to real-world propagation environment. Consequently, the trained DNN can provide efficient robust beamforming solutions based only on imperfect observations of the actual CSI. Numerical results validate the advantages of the proposed learning approach compared to conventional schemes.
Transformer based Automatic COVID-19 Fake News Detection System
Jan 01, 2021

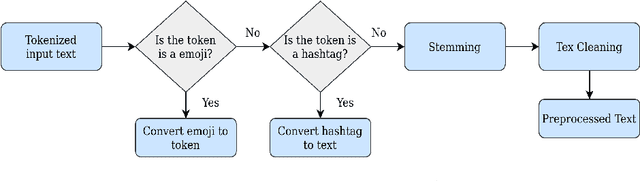

Recent rapid technological advancements in online social networks such as Twitter have led to a great incline in spreading false information and fake news. Misinformation is especially prevalent in the ongoing coronavirus disease (COVID-19) pandemic, leading to individuals accepting bogus and potentially deleterious claims and articles. Quick detection of fake news can reduce the spread of panic and confusion among the public. For our analysis in this paper, we report a methodology to analyze the reliability of information shared on social media pertaining to the COVID-19 pandemic. Our best approach is based on an ensemble of three transformer models (BERT, ALBERT, and XLNET) to detecting fake news. This model was trained and evaluated in the context of the ConstraintAI 2021 shared task COVID19 Fake News Detection in English. Our system obtained 0.9855 f1-score on testset and ranked 5th among 110 teams.
Effectively Leveraging Attributes for Visual Similarity
May 04, 2021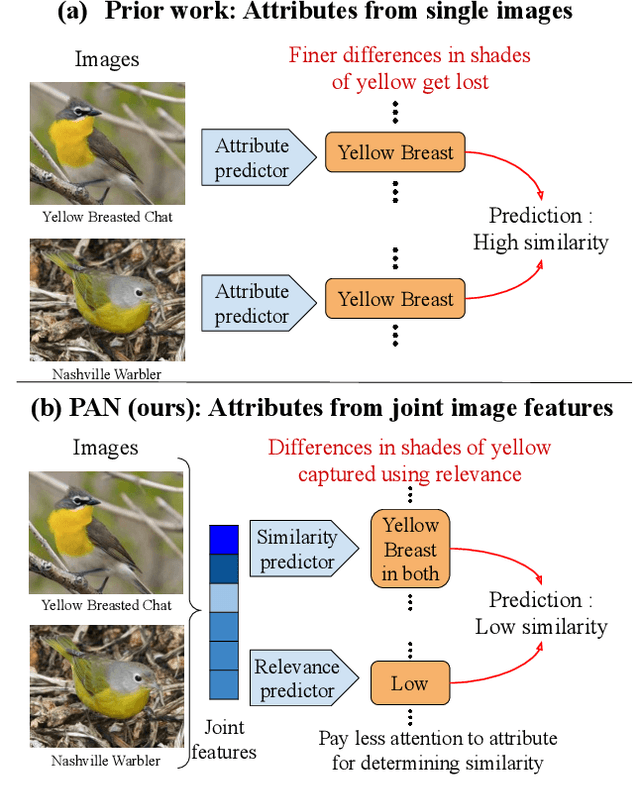
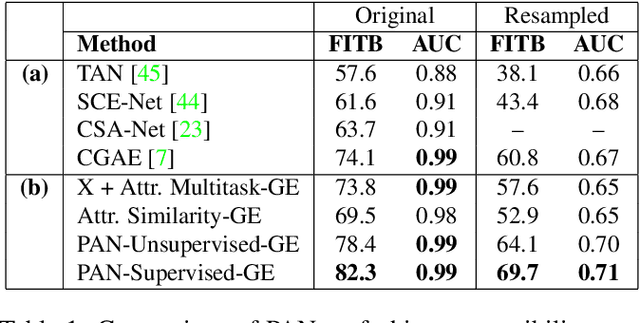
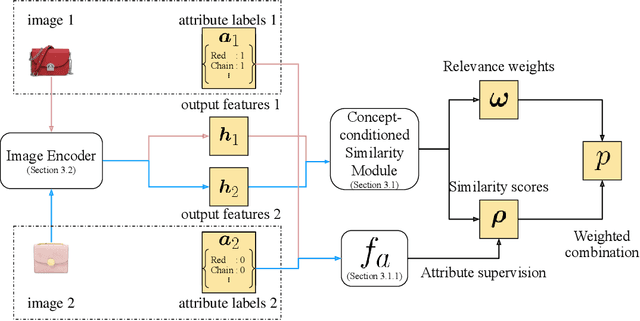
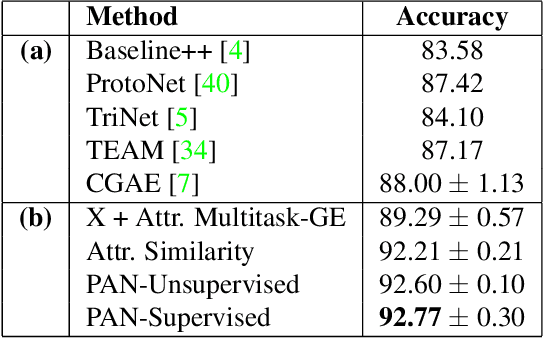
Measuring similarity between two images often requires performing complex reasoning along different axes (e.g., color, texture, or shape). Insights into what might be important for measuring similarity can can be provided by annotated attributes, but prior work tends to view these annotations as complete, resulting in them using a simplistic approach of predicting attributes on single images, which are, in turn, used to measure similarity. However, it is impractical for a dataset to fully annotate every attribute that may be important. Thus, only representing images based on these incomplete annotations may miss out on key information. To address this issue, we propose the Pairwise Attribute-informed similarity Network (PAN), which breaks similarity learning into capturing similarity conditions and relevance scores from a joint representation of two images. This enables our model to identify that two images contain the same attribute, but can have it deemed irrelevant (e.g., due to fine-grained differences between them) and ignored for measuring similarity between the two images. Notably, while prior methods of using attribute annotations are often unable to outperform prior art, PAN obtains a 4-9% improvement on compatibility prediction between clothing items on Polyvore Outfits, a 5\% gain on few shot classification of images using Caltech-UCSD Birds (CUB), and over 1% boost to Recall@1 on In-Shop Clothes Retrieval.