 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cognitive Indoor Positioning and Tracking using Multipath Channel Information
Oct 19, 2016
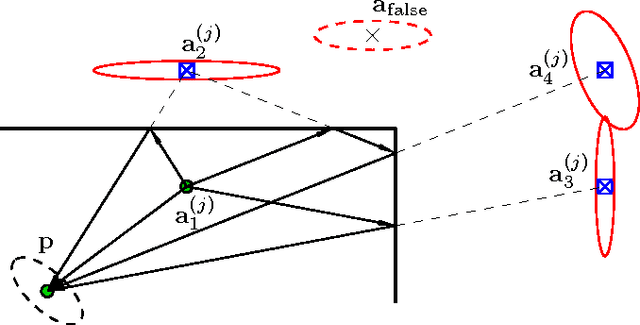
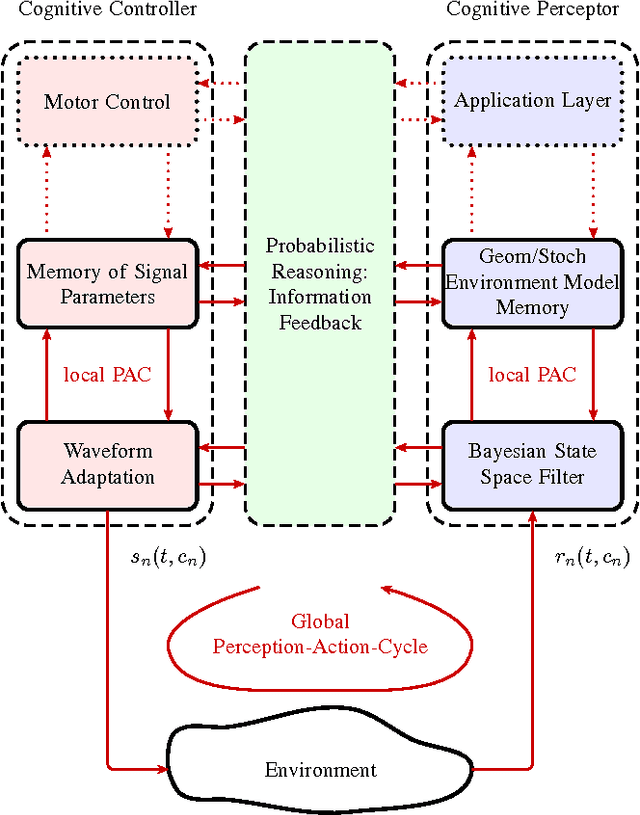
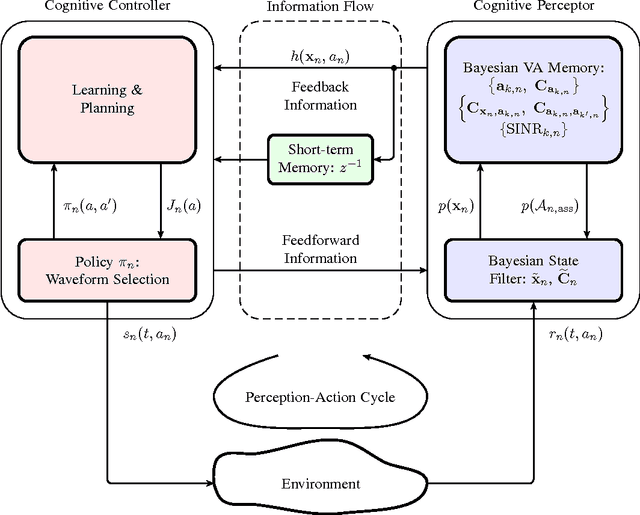
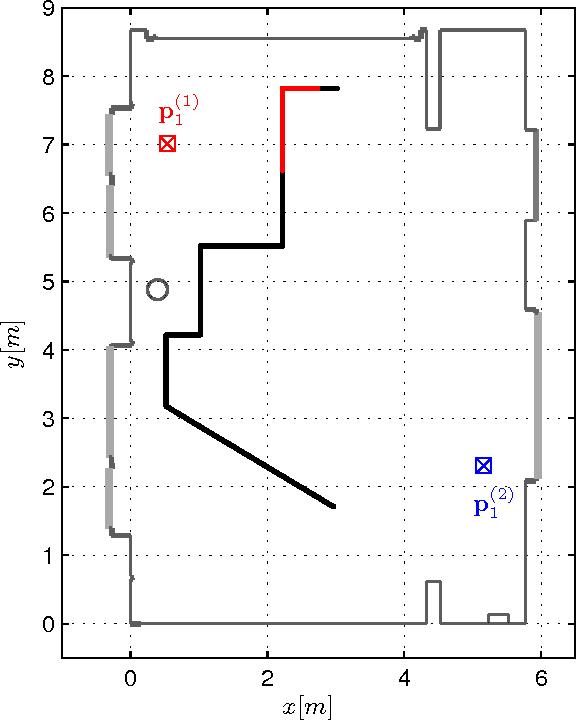
This paper presents a robust and accurate positioning system that adapts its behavior to the surrounding environment like the visual brain, mimicking its capability of filtering out clutter and focusing attention on activity and relevant information. Especially in indoor environments, which are characterized by harsh multipath propagation, it is still elusive to achieve the needed level of accuracy robustly under the constraint of reasonable infrastructural needs. In such environments it is essential to separate relevant from irrelevant information and attain an appropriate uncertainty model for measurements that are used for positioning.
A New Approach to Overgenerating and Scoring Abstractive Summaries
Apr 05, 2021


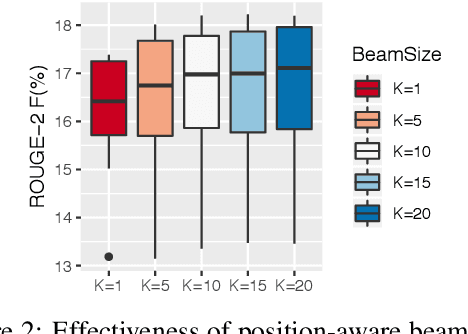
We propose a new approach to generate multiple variants of the target summary with diverse content and varying lengths, then score and select admissible ones according to users' needs. Abstractive summarizers trained on single reference summaries may struggle to produce outputs that achieve multiple desirable properties, i.e., capturing the most important information, being faithful to the original, grammatical and fluent. In this paper, we propose a two-staged strategy to generate a diverse set of candidate summaries from the source text in stage one, then score and select admissible ones in stage two. Importantly, our generator gives a precise control over the length of the summary, which is especially well-suited when space is limited. Our selectors are designed to predict the optimal summary length and put special emphasis on faithfulness to the original text. Both stages can be effectively trained, optimized and evaluated. Our experiments on benchmark summarization datasets suggest that this paradigm can achieve state-of-the-art performance.
Source and Target Bidirectional Knowledge Distillation for End-to-end Speech Translation
Apr 13, 2021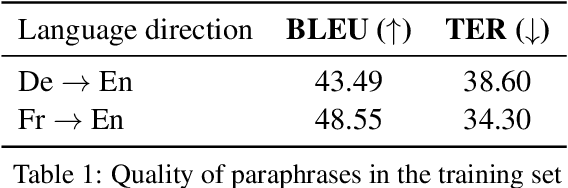
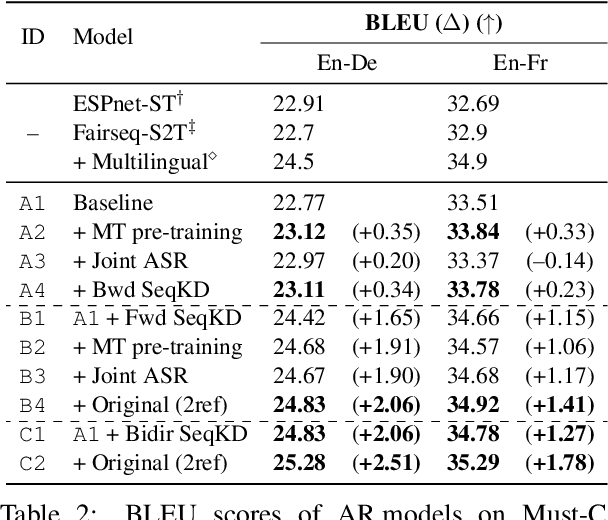
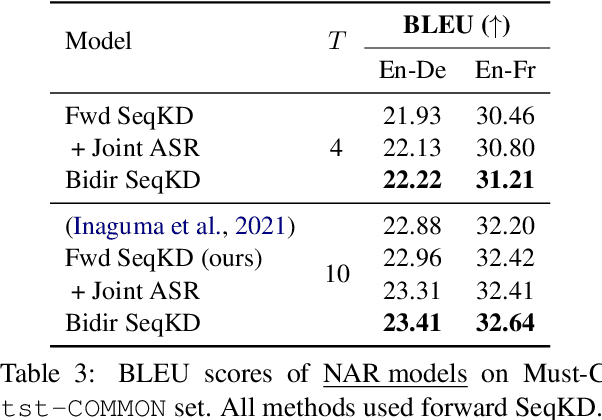
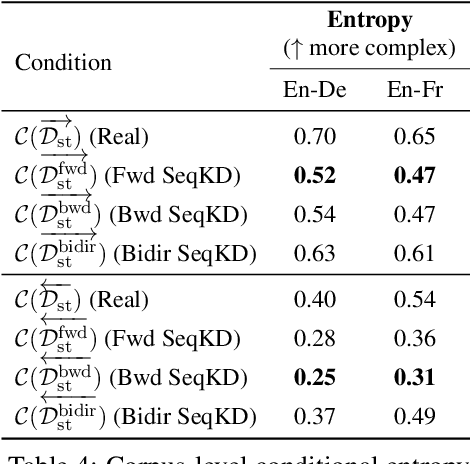
A conventional approach to improving the performance of end-to-end speech translation (E2E-ST) models is to leverage the source transcription via pre-training and joint training with automatic speech recognition (ASR) and neural machine translation (NMT) tasks. However, since the input modalities are different, it is difficult to leverage source language text successfully. In this work, we focus on sequence-level knowledge distillation (SeqKD) from external text-based NMT models. To leverage the full potential of the source language information, we propose backward SeqKD, SeqKD from a target-to-source backward NMT model. To this end, we train a bilingual E2E-ST model to predict paraphrased transcriptions as an auxiliary task with a single decoder. The paraphrases are generated from the translations in bitext via back-translation. We further propose bidirectional SeqKD in which SeqKD from both forward and backward NMT models is combined. Experimental evaluations on both autoregressive and non-autoregressive models show that SeqKD in each direction consistently improves the translation performance, and the effectiveness is complementary regardless of the model capacity.
Limited Data Emotional Voice Conversion Leveraging Text-to-Speech: Two-stage Sequence-to-Sequence Training
Mar 31, 2021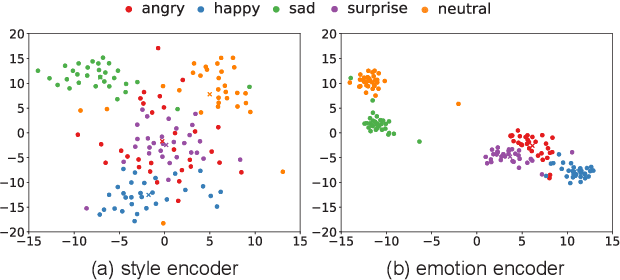
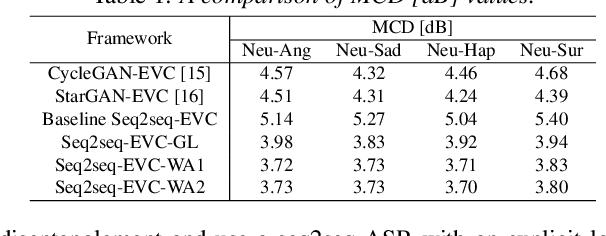
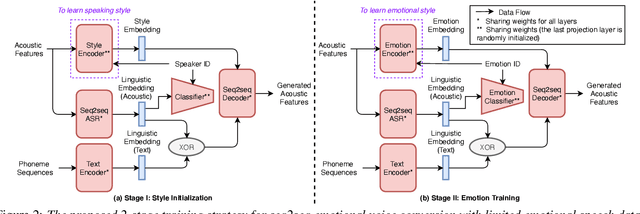
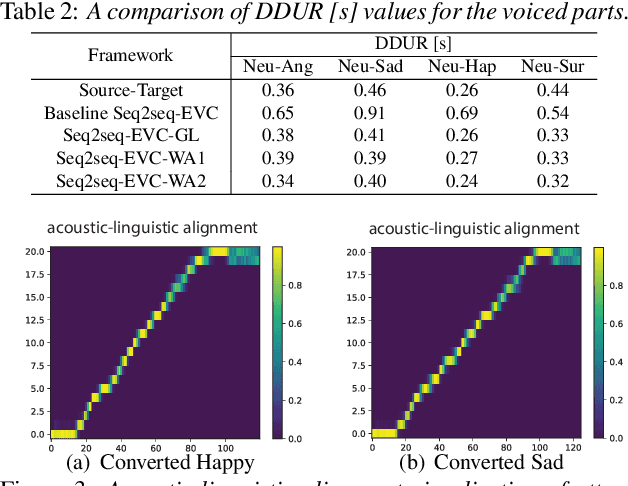
Emotional voice conversion (EVC) aims to change the emotional state of an utterance while preserving the linguistic content and speaker identity. In this paper, we propose a novel 2-stage training strategy for sequence-to-sequence emotional voice conversion with a limited amount of emotional speech data. We note that the proposed EVC framework leverages text-to-speech (TTS) as they share a common goal that is to generate high-quality expressive voice. In stage 1, we perform style initialization with a multi-speaker TTS corpus, to disentangle speaking style and linguistic content. In stage 2, we perform emotion training with a limited amount of emotional speech data, to learn how to disentangle emotional style and linguistic information from the speech. The proposed framework can perform both spectrum and prosody conversion and achieves significant improvement over the state-of-the-art baselines in both objective and subjective evaluation.
Causal-TGAN: Generating Tabular Data Using Causal Generative Adversarial Networks
Apr 21, 2021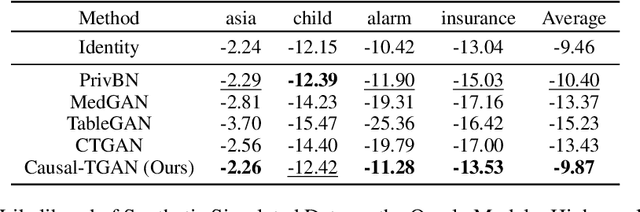
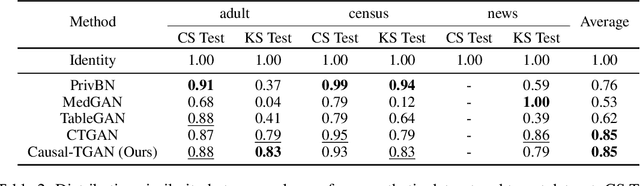
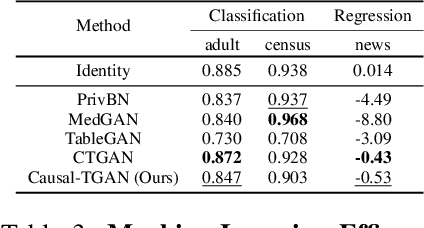
Synthetic data generation becomes prevalent as a solution to privacy leakage and data shortage. Generative models are designed to generate a realistic synthetic dataset, which can precisely express the data distribution for the real dataset. The generative adversarial networks (GAN), which gain great success in the computer vision fields, are doubtlessly used for synthetic data generation. Though there are prior works that have demonstrated great progress, most of them learn the correlations in the data distributions rather than the true processes in which the datasets are naturally generated. Correlation is not reliable for it is a statistical technique that only tells linear dependencies and is easily affected by the dataset's bias. Causality, which encodes all underlying factors of how the real data be naturally generated, is more reliable than correlation. In this work, we propose a causal model named Causal Tabular Generative Neural Network (Causal-TGAN) to generate synthetic tabular data using the tabular data's causal information. Extensive experiments on both simulated datasets and real datasets demonstrate the better performance of our method when given the true causal graph and a comparable performance when using the estimated causal graph.
GAGE: Geometry Preserving Attributed Graph Embeddings
Nov 03, 2020


Node representation learning is the task of extracting concise and informative feature embeddings of certain entities that are connected in a network. Many real world network datasets include information about both node connectivity and certain node attributes, in the form of features or time-series data. Modern representation learning techniques utilize both connectivity and attribute information of the nodes to produce embeddings in an unsupervised manner. In this context, deriving embeddings that preserve the geometry of the network and the attribute vectors would be highly desirable, as they would reflect both the topological neighborhood structure and proximity in feature space. While this is fairly straightforward to maintain when only observing the connectivity or attributed information of the network, preserving the geometry of both types of information is challenging. A novel tensor factorization approach for node embedding in attributed networks that preserves the distances of both the connections and the attributes is proposed in this paper, along with an effective and lightweight algorithm to tackle the learning task. Judicious experiments with multiple state-of-art baselines suggest that the proposed algorithm offers significant performance improvements in node classification and link prediction tasks.
The Time-SIFT method : detecting 3-D changes from archival photogrammetric analysis with almost exclusively image information
Jul 25, 2018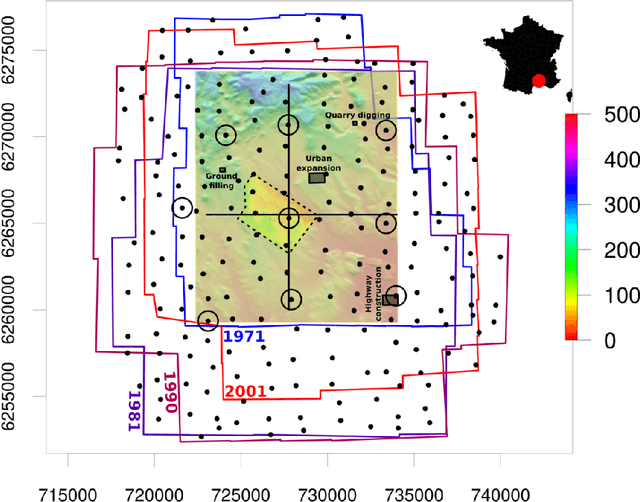
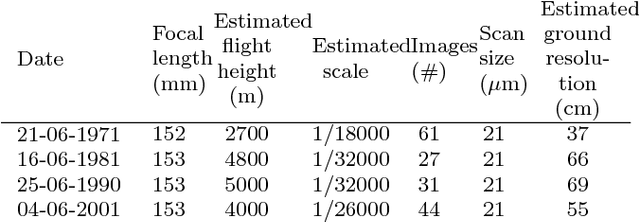
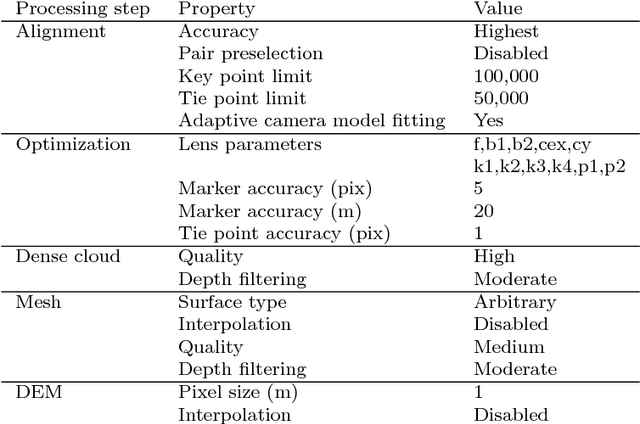
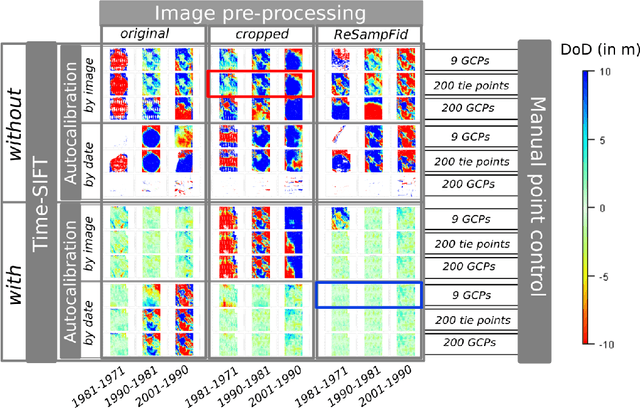
Archival aerial imagery is a source of worldwide very high resolution data for documenting paste 3-D changes. However, external information is required so that accurate 3-D models can be computed from archival aerial imagery. In this research, we propose and test a new method, termed Time-SIFT (Scale Invariant Feature Transform), which allows for computing coherent multi-temporal Digital Elevation Models (DEMs) with almost exclusively image information. This method is based on the invariance properties of the SIFT-like methods which are at the root of the Structure from Motion (SfM) algorithms. On a test site of 170 km2, we applied SfM algorithms to a unique image block with all the images of four different dates covering forty years. We compared this method to more classical methods based on the use of affordable additional data such as ground control points collected in recent orthophotos. We did extensive tests to determine which processing choices were most impacting on the final result. With these tests, we aimed at evaluating the potential of the proposed Time-SIFT method for the detection and mapping of 3-D changes. Our study showed that the Time-SIFT method was the prime criteria that allowed for computing informative DEMs of difference with almost exclusively image information and limited photogrammetric expertise and human intervention. Due to the fact that the proposed Time-SIFT method can be automatically applied with exclusively image information, our results pave the way to a systematic processing of the archival aerial imagery on very large spatio-temporal windows, and should hence greatly help the unlocking of archival aerial imagery for the documenting of past 3-D changes.
A Comparative Study of Using Spatial-Temporal Graph Convolutional Networks for Predicting Availability in Bike Sharing Schemes
Apr 21, 2021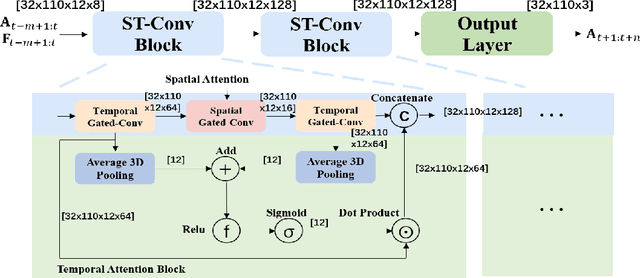
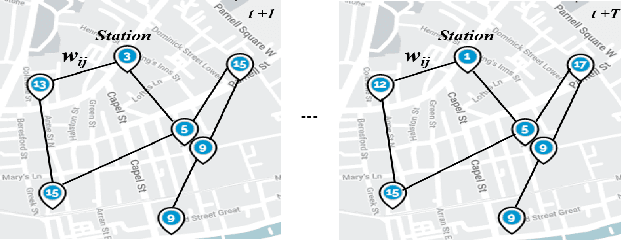
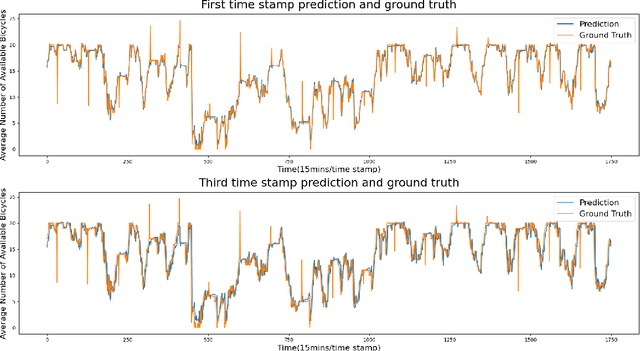
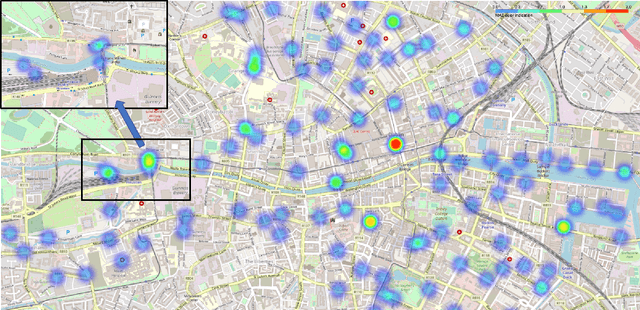
Accurately forecasting transportation demand is crucial for efficient urban traffic guidance, control and management. One solution to enhance the level of prediction accuracy is to leverage graph convolutional networks (GCN), a neural network based modelling approach with the ability to process data contained in graph based structures. As a powerful extension of GCN, a spatial-temporal graph convolutional network (ST-GCN) aims to capture the relationship of data contained in the graphical nodes across both spatial and temporal dimensions, which presents a novel deep learning paradigm for the analysis of complex time-series data that also involves spatial information as present in transportation use cases. In this paper, we present an Attention-based ST-GCN (AST-GCN) for predicting the number of available bikes in bike-sharing systems in cities, where the attention-based mechanism is introduced to further improve the performance of a ST-GCN. Furthermore, we also discuss the impacts of different modelling methods of adjacency matrices on the proposed architecture. Our experimental results are presented using two real-world datasets, Dublinbikes and NYC-Citi Bike, to illustrate the efficacy of our proposed model which outperforms the majority of existing approaches.
Unsupervised Technical Domain Terms Extraction using Term Extractor
Jan 22, 2021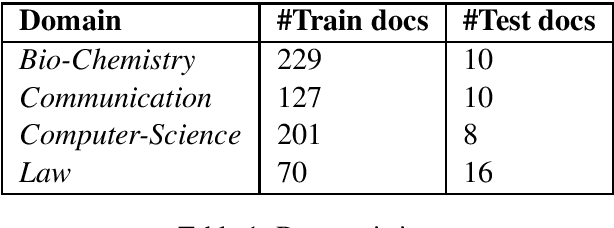
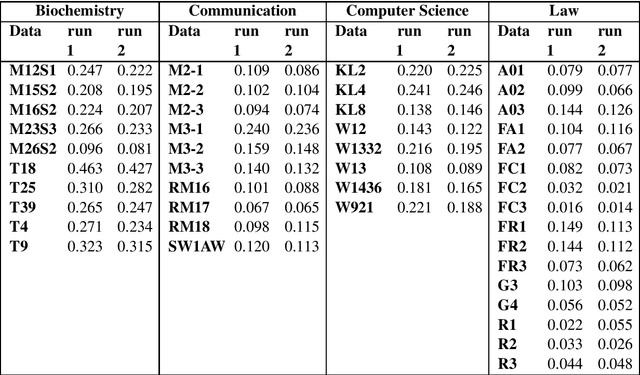

Terminology extraction, also known as term extraction, is a subtask of information extraction. The goal of terminology extraction is to extract relevant words or phrases from a given corpus automatically. This paper focuses on the unsupervised automated domain term extraction method that considers chunking, preprocessing, and ranking domain-specific terms using relevance and cohesion functions for ICON 2020 shared task 2: TermTraction.
Maneuver-Aware Pooling for Vehicle Trajectory Prediction
Apr 29, 2021
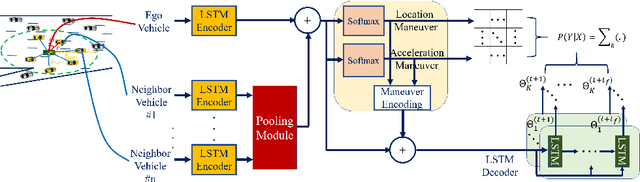
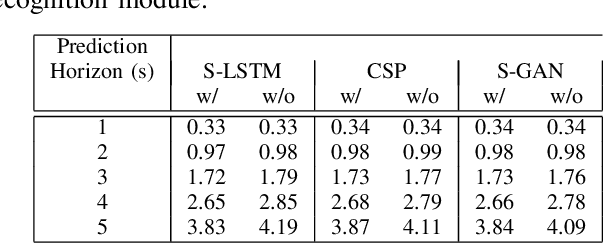
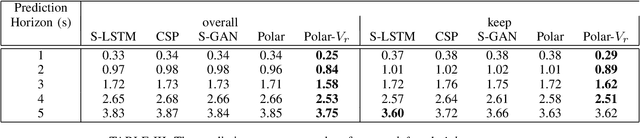
Autonomous vehicles should be able to predict the future states of its environment and respond appropriately. Specifically, predicting the behavior of surrounding human drivers is vital for such platforms to share the same road with humans. Behavior of each of the surrounding vehicles is governed by the motion of its neighbor vehicles. This paper focuses on predicting the behavior of the surrounding vehicles of an autonomous vehicle on highways. We are motivated by improving the prediction accuracy when a surrounding vehicle performs lane change and highway merging maneuvers. We propose a novel pooling strategy to capture the inter-dependencies between the neighbor vehicles. Depending solely on Euclidean trajectory representation, the existing pooling strategies do not model the context information of the maneuvers intended by a surrounding vehicle. In contrast, our pooling mechanism employs polar trajectory representation, vehicles orientation and radial velocity. This results in an implicitly maneuver-aware pooling operation. We incorporated the proposed pooling mechanism into a generative encoder-decoder model, and evaluated our method on the public NGSIM dataset. The results of maneuver-based trajectory predictions demonstrate the effectiveness of the proposed method compared with the state-of-the-art approaches. Our "Pooling Toolbox" code is available at https://github.com/m-hasan-n/pooling.