 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Objects are Different: Flexible Monocular 3D Object Detection
Apr 06, 2021

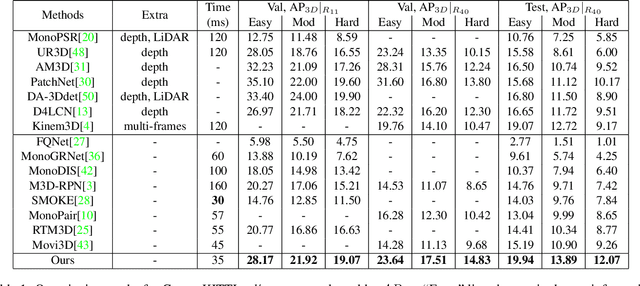
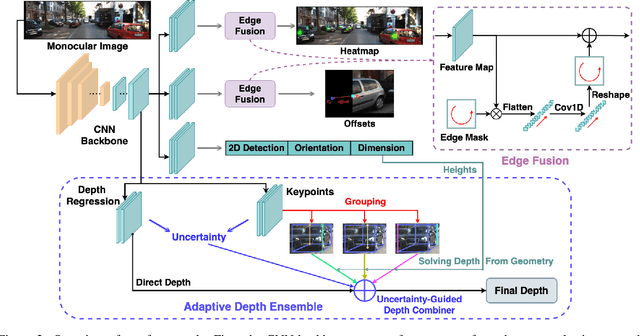
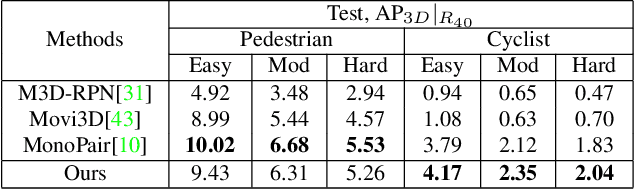
The precise localization of 3D objects from a single image without depth information is a highly challenging problem. Most existing methods adopt the same approach for all objects regardless of their diverse distributions, leading to limited performance for truncated objects. In this paper, we propose a flexible framework for monocular 3D object detection which explicitly decouples the truncated objects and adaptively combines multiple approaches for object depth estimation. Specifically, we decouple the edge of the feature map for predicting long-tail truncated objects so that the optimization of normal objects is not influenced. Furthermore, we formulate the object depth estimation as an uncertainty-guided ensemble of directly regressed object depth and solved depths from different groups of keypoints. Experiments demonstrate that our method outperforms the state-of-the-art method by relatively 27\% for the moderate level and 30\% for the hard level in the test set of KITTI benchmark while maintaining real-time efficiency. Code will be available at \url{https://github.com/zhangyp15/MonoFlex}.
Disentangled Non-Local Network for Hyperspectral and LiDAR Data Classification
Apr 06, 2021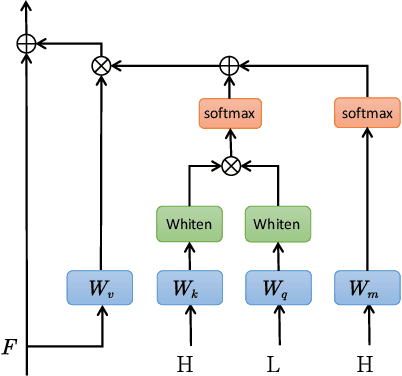
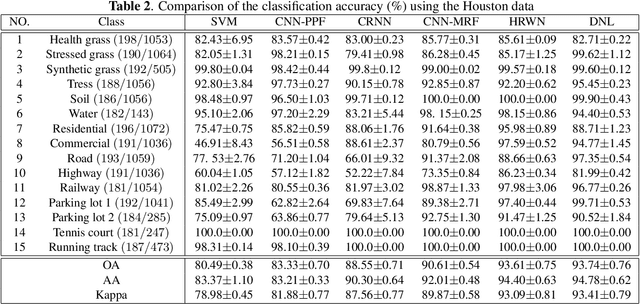

As the ground objects become increasingly complex, the classification results obtained by single source remote sensing data can hardly meet the application requirements. In order to tackle this limitation, we propose a simple yet effective attention fusion model based on Disentangled Non-local (DNL) network for hyperspectral and LiDAR data joint classification task. In this model, according to the spectral and spatial characteristics of HSI and LiDAR, a multiscale module and a convolutional neural network (CNN) are used to capture the spectral and spatial characteristics respectively. In addition, the extracted HSI and LiDAR features are fused through some operations to obtain the feature information more in line with the real situation. Finally, the above three data are fed into different branches of the DNL module, respectively. Extensive experiments on Houston dataset show that the proposed network is superior and more effective compared to several of the most advanced baselines in HSI and LiDAR joint classification missions.
The $r$-value: evaluating stability with respect to distributional shifts
May 07, 2021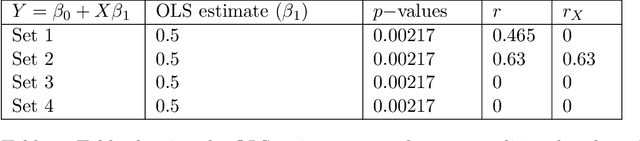
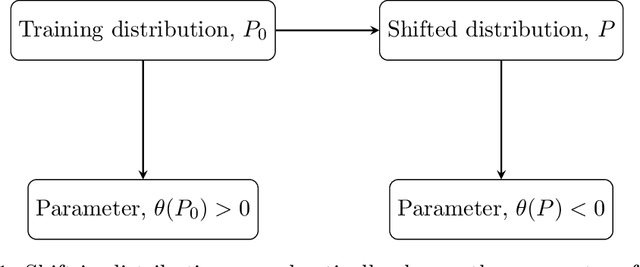

Common statistical measures of uncertainty like $p$-values and confidence intervals quantify the uncertainty due to sampling, that is, the uncertainty due to not observing the full population. In practice, populations change between locations and across time. This makes it difficult to gather knowledge that transfers across data sets. We propose a measure of uncertainty that quantifies the distributional uncertainty of a statistical estimand with respect to Kullback-Liebler divergence, that is, the sensitivity of the parameter under general distributional perturbations within a Kullback-Liebler divergence ball. If the signal-to-noise ratio is small, distributional uncertainty is a monotonous transformation of the signal-to-noise ratio. In general, however, it is a different concept and corresponds to a different research question. Further, we propose measures to estimate the stability of parameters with respect to directional or variable-specific shifts. We also demonstrate how the measure of distributional uncertainty can be used to prioritize data collection for better estimation of statistical parameters under shifted distribution. We evaluate the performance of the proposed measure in simulations and real data and show that it can elucidate the distributional (in-)stability of an estimator with respect to certain shifts and give more accurate estimates of parameters under shifted distribution only requiring to collect limited information from the shifted distribution.
PEMNET: A Transfer Learning-based Modeling Approach of High-Temperature Polymer Electrolyte Membrane Electrochemical Systems
May 07, 2021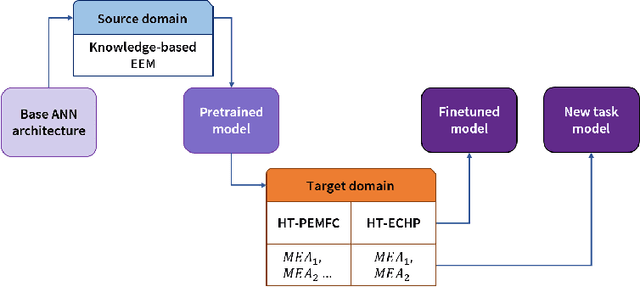
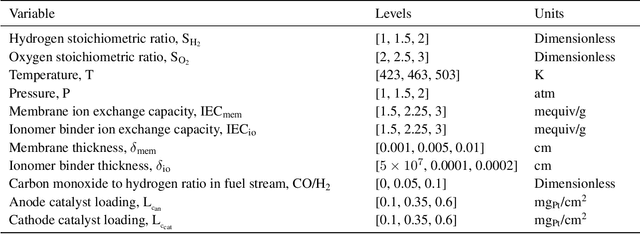
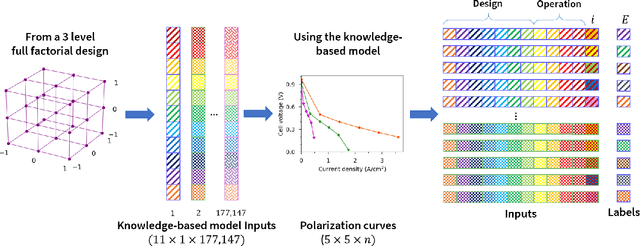
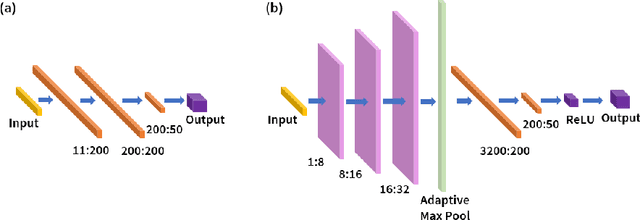
Widespread adoption of high-temperature polymer electrolyte membrane fuel cells (HT-PEMFCs) and HT-PEM electrochemical hydrogen pumps (HT-PEM ECHPs) requires models and computational tools that provide accurate scale-up and optimization. Knowledge-based modeling has limitations as it is time consuming and requires information about the system that is not always available (e.g., material properties and interfacial behavior between different materials). Data-driven modeling on the other hand, is easier to implement, but often necessitates large datasets that could be difficult to obtain. In this contribution, knowledge-based modeling and data-driven modeling are uniquely combined by implementing a Few-Shot Learning (FSL) approach. A knowledge-based model originally developed for a HT-PEMFC was used to generate simulated data (887,735 points) and used to pretrain a neural network source model. Furthermore, the source model developed for HT-PEMFCs was successfully applied to HT-PEM ECHPs - a different electrochemical system that utilizes similar materials to the fuel cell. Experimental datasets from both HT-PEMFCs and HT-PEM ECHPs with different materials and operating conditions (~50 points each) were used to train 8 target models via FSL. Models for the unseen data reached high accuracies in all cases (rRMSE between 1.04 and 3.73% for HT-PEMCs and between 6.38 and 8.46% for HT-PEM ECHPs).
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
Apr 01, 2021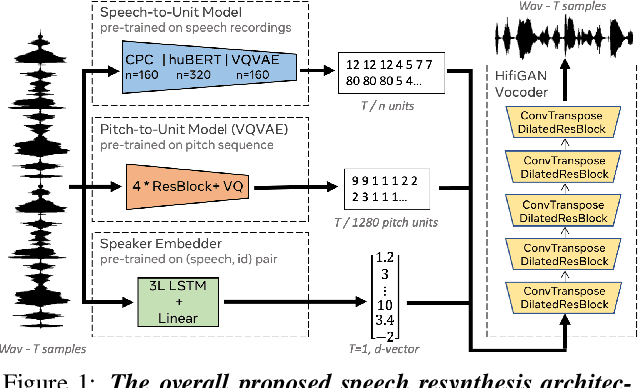
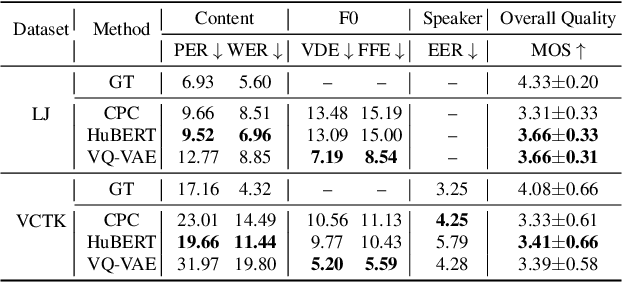
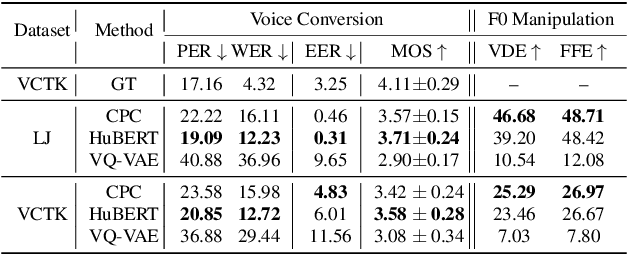
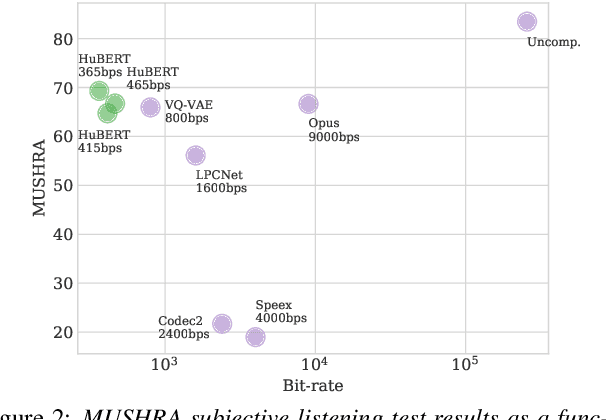
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under the following link: \url{https://resynthesis-ssl.github.io/}.
ORBIT: Ordering Based Information Transfer Across Space and Time for Global Surface Water Monitoring
Nov 15, 2017
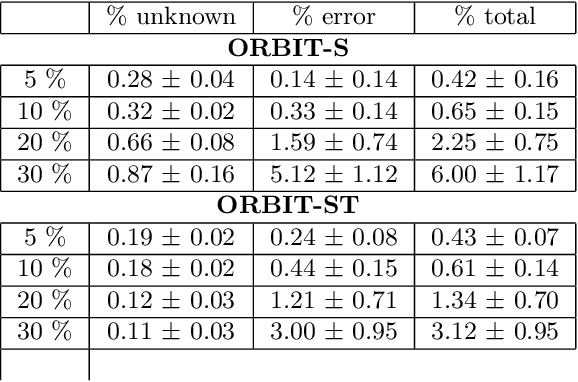
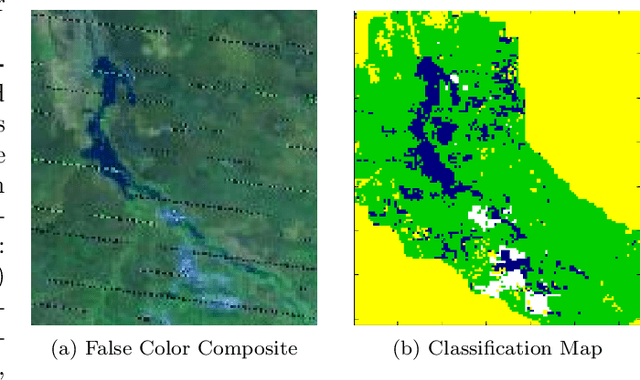
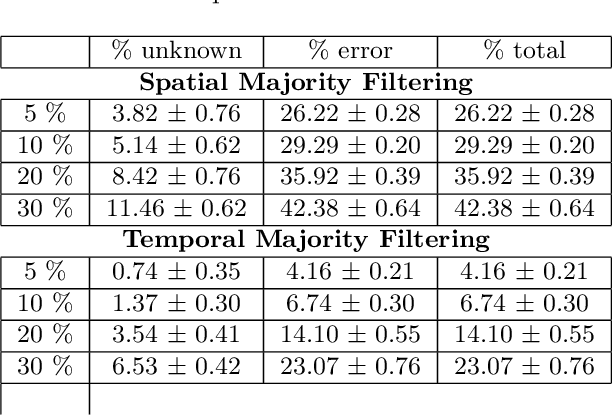
Many earth science applications require data at both high spatial and temporal resolution for effective monitoring of various ecosystem resources. Due to practical limitations in sensor design, there is often a trade-off in different resolutions of spatio-temporal datasets and hence a single sensor alone cannot provide the required information. Various data fusion methods have been proposed in the literature that mainly rely on individual timesteps when both datasets are available to learn a mapping between features values at different resolutions using local relationships between pixels. Earth observation data is often plagued with spatially and temporally correlated noise, outliers and missing data due to atmospheric disturbances which pose a challenge in learning the mapping from a local neighborhood at individual timesteps. In this paper, we aim to exploit time-independent global relationships between pixels for robust transfer of information across different scales. Specifically, we propose a new framework, ORBIT (Ordering Based Information Transfer) that uses relative ordering constraint among pixels to transfer information across both time and scales. The effectiveness of the framework is demonstrated for global surface water monitoring using both synthetic and real-world datasets.
Image Captioning with Context-Aware Auxiliary Guidance
Jan 04, 2021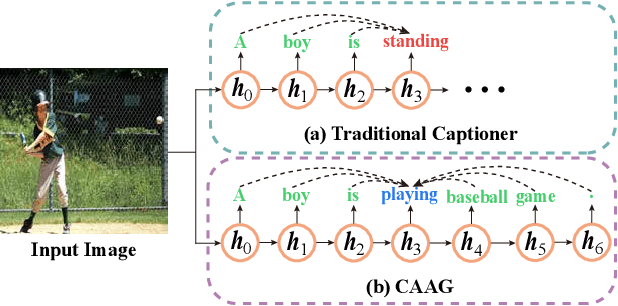
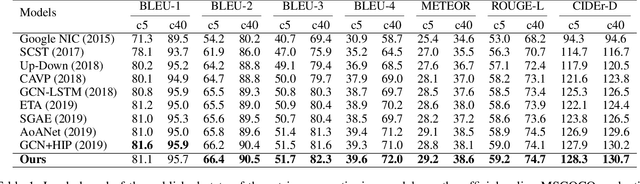
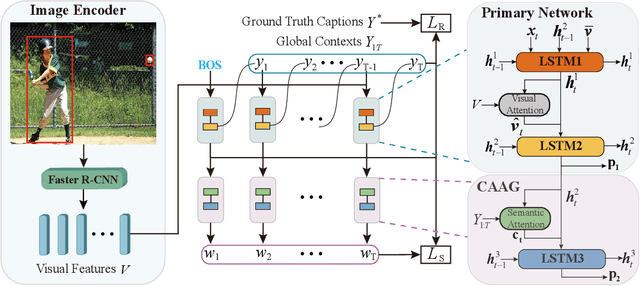
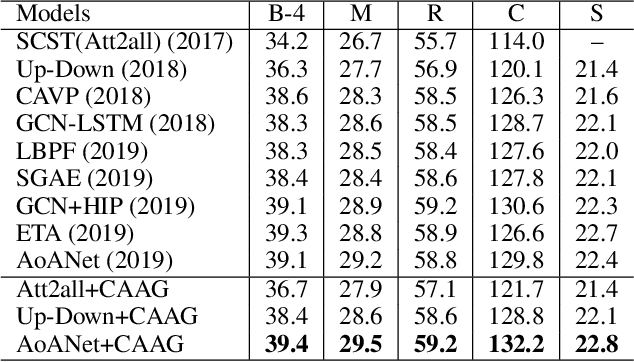
Image captioning is a challenging computer vision task, which aims to generate a natural language description of an image. Most recent researches follow the encoder-decoder framework which depends heavily on the previous generated words for the current prediction. Such methods can not effectively take advantage of the future predicted information to learn complete semantics. In this paper, we propose Context-Aware Auxiliary Guidance (CAAG) mechanism that can guide the captioning model to perceive global contexts. Upon the captioning model, CAAG performs semantic attention that selectively concentrates on useful information of the global predictions to reproduce the current generation. To validate the adaptability of the method, we apply CAAG to three popular captioners and our proposal achieves competitive performance on the challenging Microsoft COCO image captioning benchmark, e.g. 132.2 CIDEr-D score on Karpathy split and 130.7 CIDEr-D (c40) score on official online evaluation server.
A Low Cost Modular Radio Tomography System for Bicycle and Vehicle Detection and Classification
Feb 11, 2021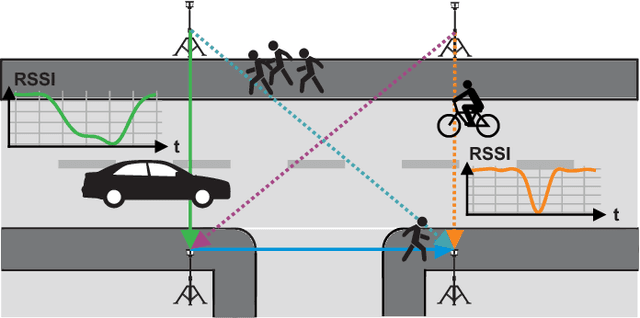
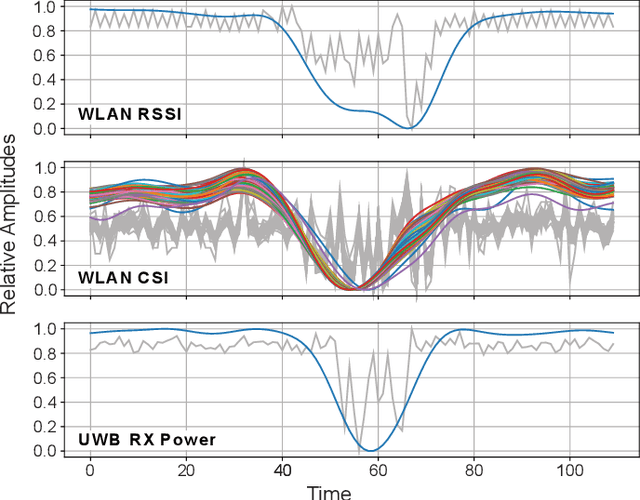
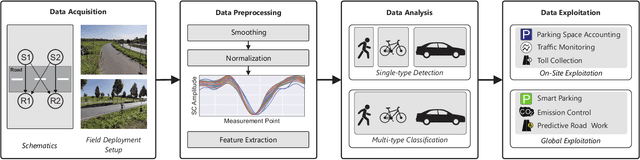

The advancing deployment of ubiquitous Internet of Things (IoT)-powered vehicle detection and classification systems will successively turn the existing road infrastructure into a highly dynamical and interconnected Cyber-physical System (CPS). Though many different sensor systems have been proposed in recent years, these solutions can only meet a subset of requirements, including cost-efficiency, robustness, accuracy, and privacy preservation. This paper provides a modular system approach that exploits radio tomography in terms of attenuation patterns and highly accurate channel information for reliable and robust detection and classification of different road users. Hereto, we use Wireless Local Area Network (WLAN) and Ultra-Wideband (UWB) transceiver modules providing either Channel State Information (CSI) or Channel Impulse Response (CIR) data. Since the proposed system utilizes off-the-shelf and power-efficient embedded systems, it allows for a cost-efficient ad-hoc deployment in existing road infrastructures. We have evaluated the proposed system's performance for cyclists and other motorized vehicles with an experimental live deployment. In this concern, the primary focus has been on the accurate detection of cyclists on a bicycle path. However, we also have conducted preliminary evaluation tests measuring different motorized vehicles using a similar system configuration as for the cyclists. In summary, the system achieves up to 100% accuracy for detecting cyclists and more than 98% classifying cyclists and cars.
Efficient Kernel based Matched Filter Approach for Segmentation of Retinal Blood Vessels
Dec 07, 2020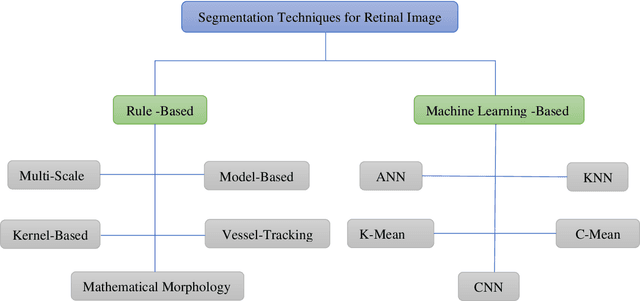
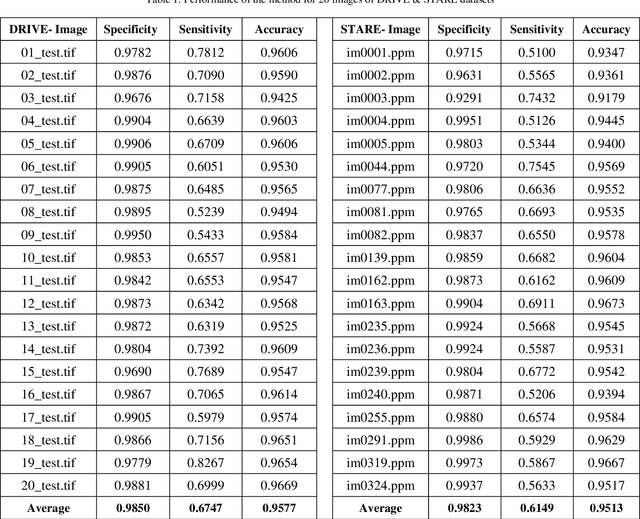
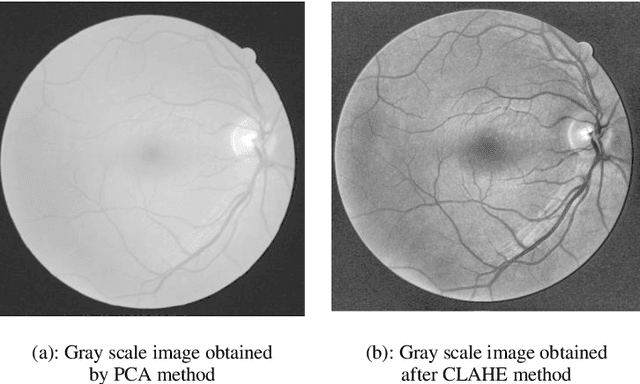
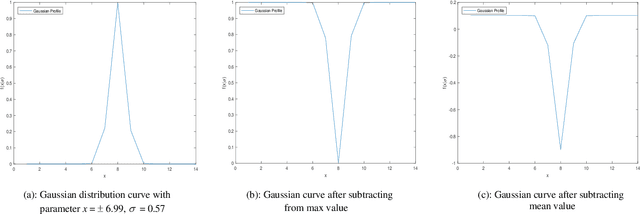
Retinal blood vessels structure contains information about diseases like obesity, diabetes, hypertension and glaucoma. This information is very useful in identification and treatment of these fatal diseases. To obtain this information, there is need to segment these retinal vessels. Many kernel based methods have been given for segmentation of retinal vessels but their kernels are not appropriate to vessel profile cause poor performance. To overcome this, a new and efficient kernel based matched filter approach has been proposed. The new matched filter is used to generate the matched filter response (MFR) image. We have applied Otsu thresholding method on obtained MFR image to extract the vessels. We have conducted extensive experiments to choose best value of parameters for the proposed matched filter kernel. The proposed approach has examined and validated on two online available DRIVE and STARE datasets. The proposed approach has specificity 98.50%, 98.23% and accuracy 95.77 %, 95.13% for DRIVE and STARE dataset respectively. Obtained results confirm that the proposed method has better performance than others. The reason behind increased performance is due to appropriate proposed kernel which matches retinal blood vessel profile more accurately.
Road is Enough! Extrinsic Calibration of Non-overlapping Stereo Camera and LiDAR using Road Information
Mar 06, 2019
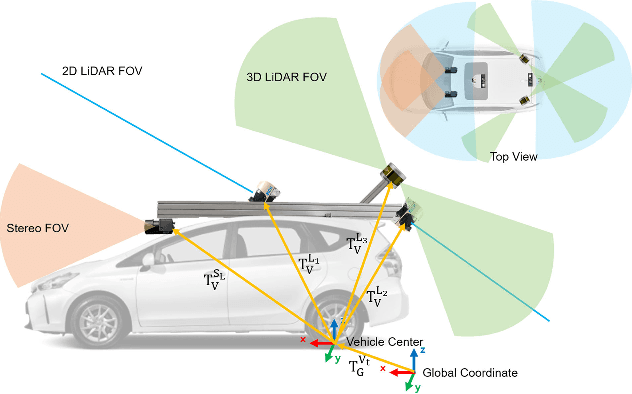
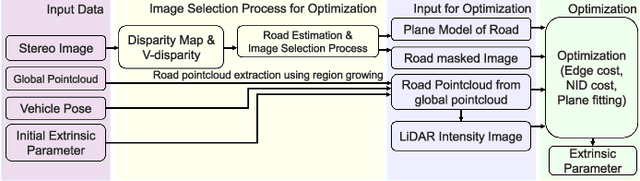
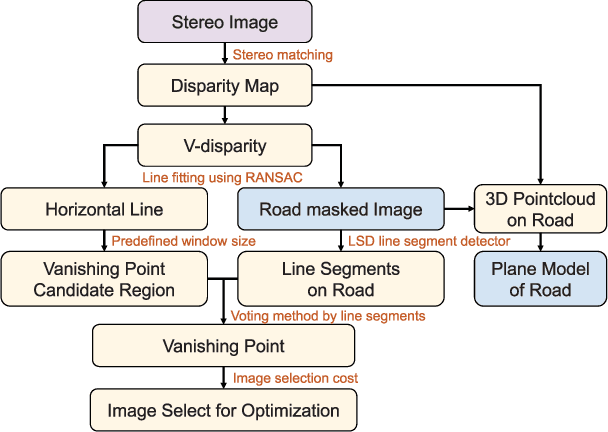
This paper presents a framework for the targetless extrinsic calibration of stereo cameras and Light Detection and Ranging (LiDAR) sensors with a non-overlapping Field of View (FOV). In order to solve the extrinsic calibrations problem under such challenging configuration, the proposed solution exploits road markings as static and robust features among the various dynamic objects that are present in urban environment. First, this study utilizes road markings that are commonly captured by the two sensor modalities to select informative images for estimating the extrinsic parameters. In order to accomplish stable optimization, multiple cost functions are defined, including Normalized Information Distance (NID), edge alignment and, plane fitting cost. Therefore a smooth cost curve is formed for global optimization to prevent convergence to the local optimal point. We further evaluate each cost function by examining parameter sensitivity near the optimal point. Another key characteristic of extrinsic calibration, repeatability, is analyzed by conducting the proposed method multiple times with varying randomly perturbed initial points.