 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Representation Learning by Ranking under multiple tasks
Mar 28, 2021
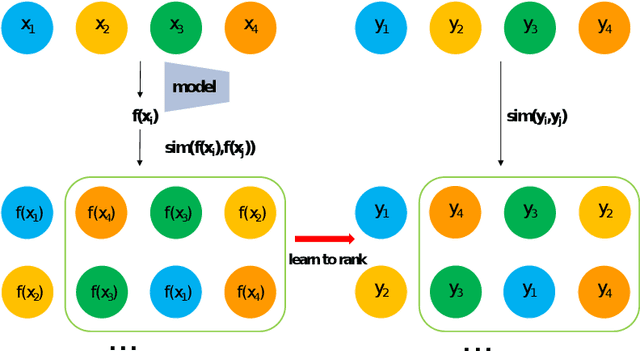

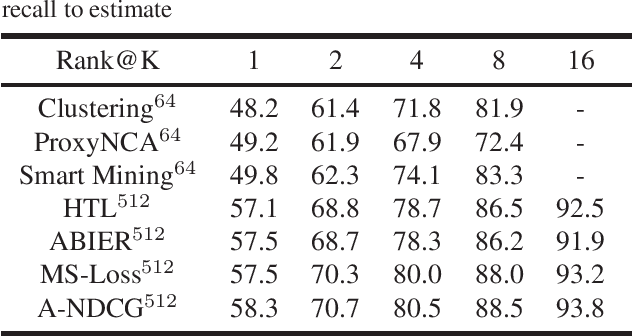
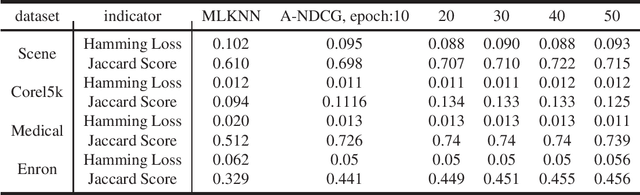
In recent years, representation learning has become the research focus of the machine learning community. Large-scale pre-training neural networks have become the first step to realize general intelligence. The key to the success of neural networks lies in their abstract representation capabilities for data. Several learning fields are actually discussing how to learn representations and there lacks a unified perspective. We convert the representation learning problem under multiple tasks into a ranking problem, taking the ranking problem as a unified perspective, the representation learning under different tasks is solved by optimizing the approximate NDCG loss. Experiments under different learning tasks like classification, retrieval, multi-label learning, regression, self-supervised learning prove the superiority of approximate NDCG loss. Further, under the self-supervised learning task, the training data is transformed by data augmentation method to improve the performance of the approximate NDCG loss, which proves that the approximate NDCG loss can make full use of the information of the unsupervised training data.
Image Inpainting by End-to-End Cascaded Refinement with Mask Awareness
Apr 28, 2021
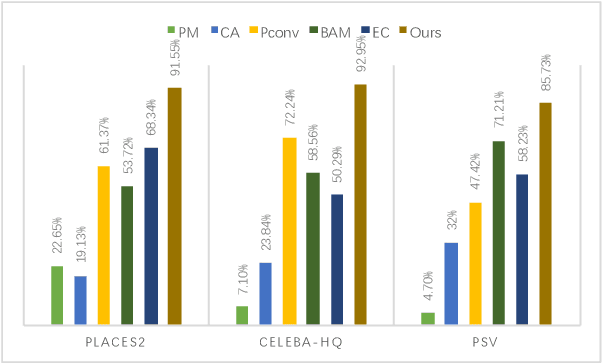


Inpainting arbitrary missing regions is challenging because learning valid features for various masked regions is nontrivial. Though U-shaped encoder-decoder frameworks have been witnessed to be successful, most of them share a common drawback of mask unawareness in feature extraction because all convolution windows (or regions), including those with various shapes of missing pixels, are treated equally and filtered with fixed learned kernels. To this end, we propose our novel mask-aware inpainting solution. Firstly, a Mask-Aware Dynamic Filtering (MADF) module is designed to effectively learn multi-scale features for missing regions in the encoding phase. Specifically, filters for each convolution window are generated from features of the corresponding region of the mask. The second fold of mask awareness is achieved by adopting Point-wise Normalization (PN) in our decoding phase, considering that statistical natures of features at masked points differentiate from those of unmasked points. The proposed PN can tackle this issue by dynamically assigning point-wise scaling factor and bias. Lastly, our model is designed to be an end-to-end cascaded refinement one. Supervision information such as reconstruction loss, perceptual loss and total variation loss is incrementally leveraged to boost the inpainting results from coarse to fine. Effectiveness of the proposed framework is validated both quantitatively and qualitatively via extensive experiments on three public datasets including Places2, CelebA and Paris StreetView.
Constrained Radar Waveform Design for Range Profiling
Mar 18, 2021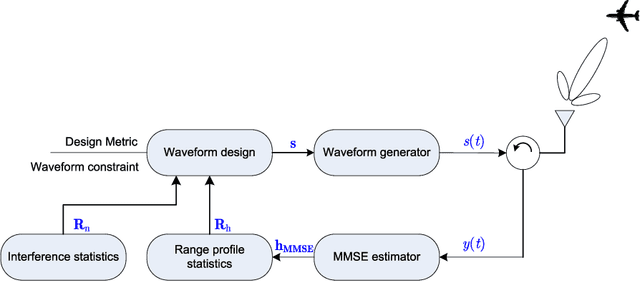
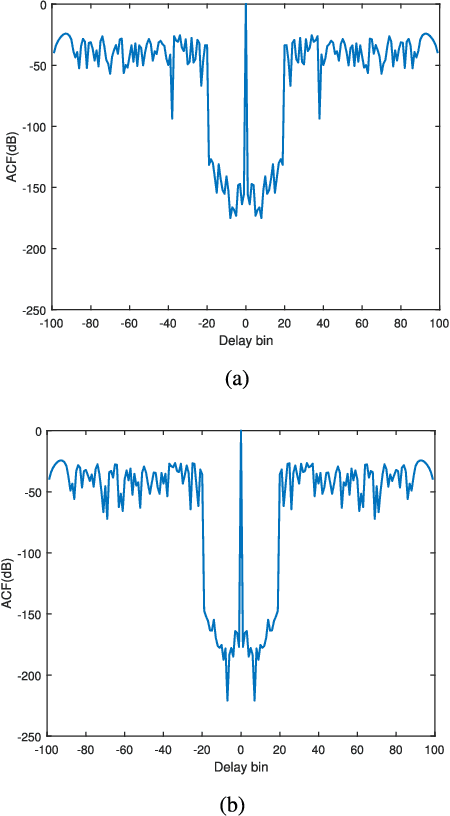
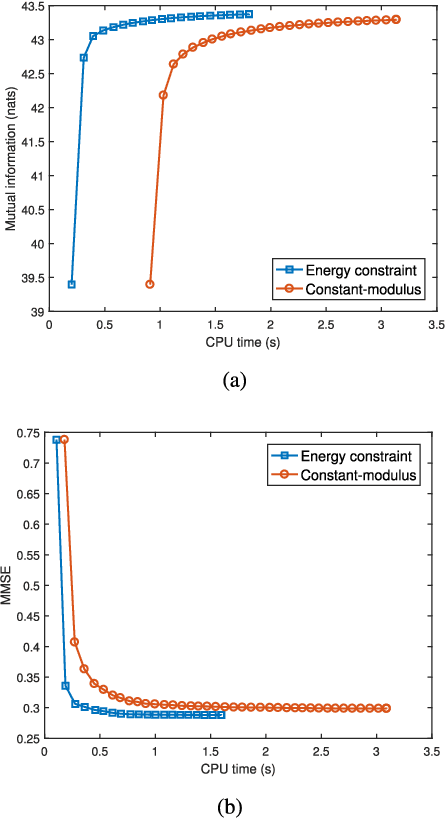
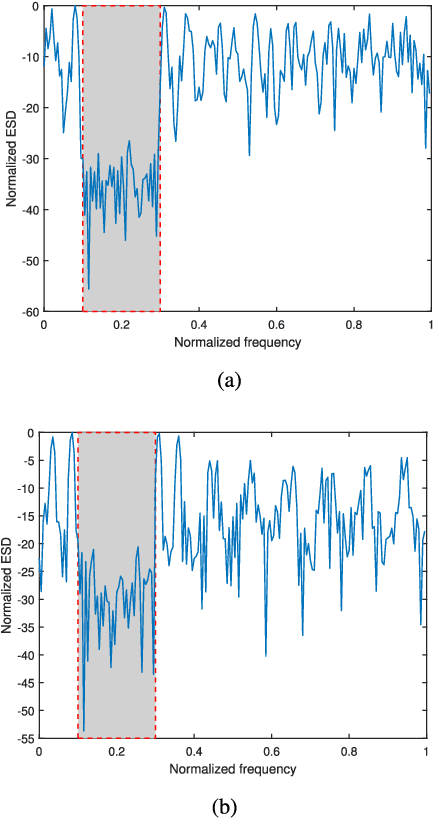
Range profiling refers to the measurement of target response along the radar slant range. It plays an important role in automatic target recognition. In this paper, we consider the design of transmit waveform to improve the range profiling performance of radar systems. Two design metrics are adopted for the waveform optimization problem: one is to maximize the mutual information between the received signal and the target impulse response (TIR); the other is to minimize the minimum mean-square error for estimating the TIR. In addition, practical constraints on the waveforms are considered, including an energy constraint, a peak-to-average-power-ratio constraint, and a spectral constraint. Based on minorization-maximization, we propose a unified optimization framework to tackle the constrained waveform design problem. Numerical examples show the superiority of the waveforms synthesized by the proposed algorithms.
Multimodal Personal Ear Authentication Using Smartphones
Mar 23, 2021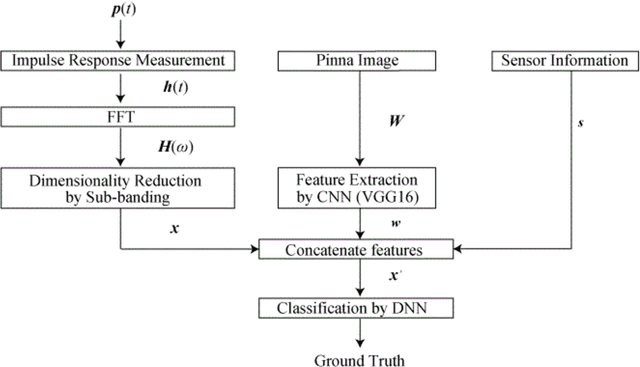


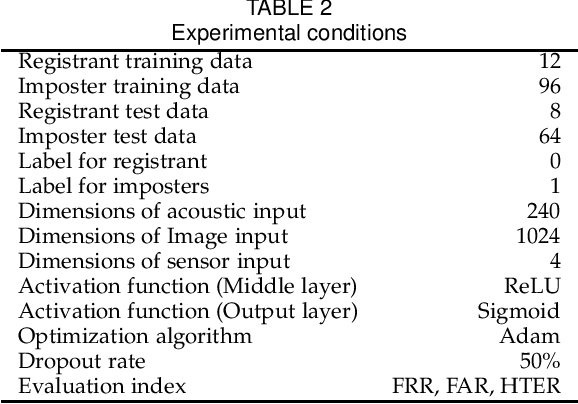
In recent years, biometric authentication technology for smartphones has become widespread, with the mainstream methods being fingerprint authentication and face recognition. However, fingerprint authentication cannot be used when hands are wet, and face recognition cannot be used when a person is wearing a mask. Therefore, we examine a personal authentication system using the pinna as a new approach for biometric authentication on smartphones. Authentication systems based on the acoustic transfer function of the pinna (PRTF: Pinna Related Transfer Function) have been investigated. However, the authentication accuracy decreases due to the positional fluctuation across each measurement. In this paper, we propose multimodal personal authentication on smartphones using PRTF. The pinna image and positional sensor information are used with the PRTF, and the effectiveness of the authentication method is examined. We demonstrate that the proposed authentication system can compensate for the positional changes in each measurement and improve robustness.
Indonesian ID Card Extractor Using Optical Character Recognition and Natural Language Post-Processing
Dec 15, 2020
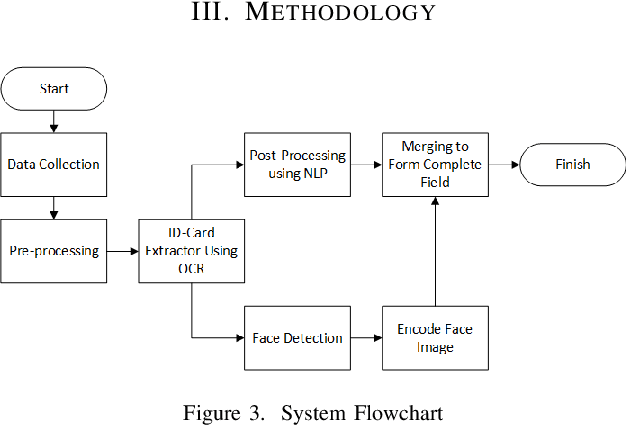

The development of Information Technology has been increasingly changing the means of information exchange leading to the need of digitizing print documents. In the present era, there is a lot of fraud that often occur. To avoid account fraud there was verification using ID card extraction using OCR and NLP. Optical Character Recognition (OCR) is technology that used to generate text from image. With OCR we can extract Indonesian ID card or kartu tanda penduduk (KTP) into text too. This is using to make easier service operator to do data entry. To improve the accuracy we made text correction using Natural language Processing (NLP) method to fixing the text. With 50 Indonesian ID card image we got 0.78 F-score, and we need 4510 milliseconds to extract per ID card.
Methodology for Mining, Discovering and Analyzing Semantic Human Mobility Behaviors
Dec 20, 2020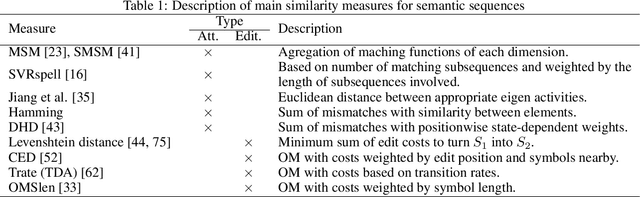
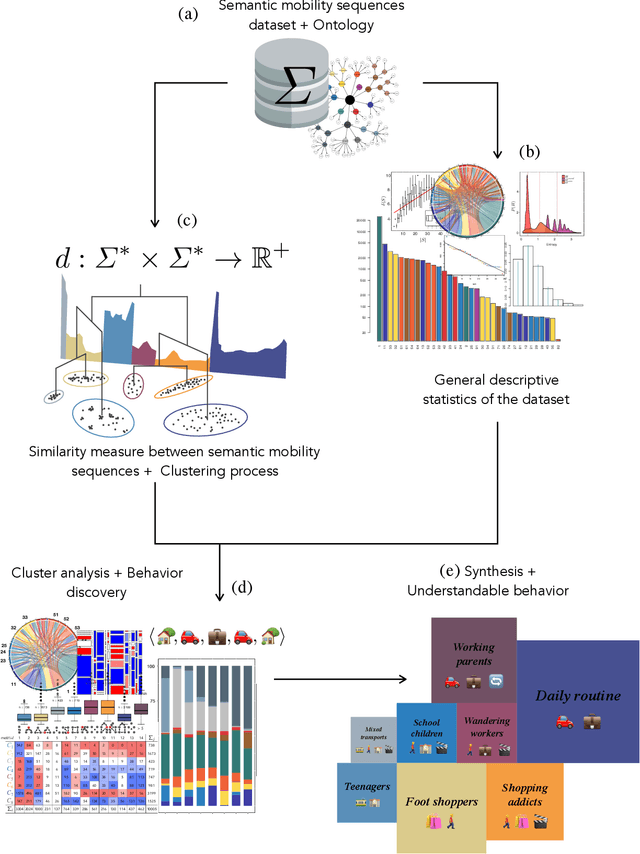
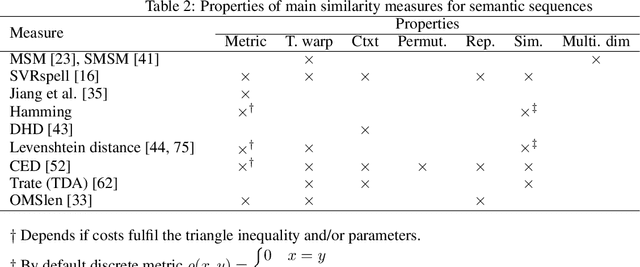
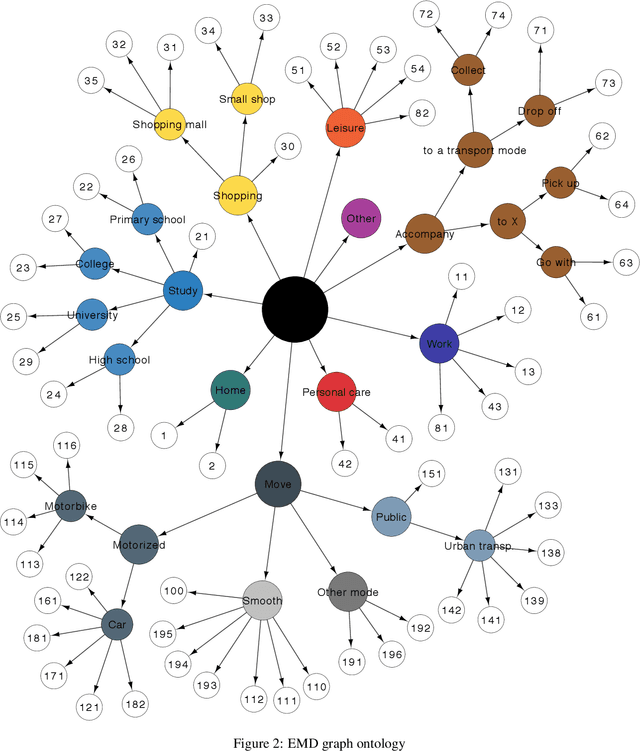
Various institutes produce large semantic datasets containing information regarding daily activities and human mobility. The analysis and understanding of such data are crucial for urban planning, socio-psychology, political sciences, and epidemiology. However, none of the typical data mining processes have been customized for the thorough analysis of semantic mobility sequences to translate data into understandable behaviors. Based on an extended literature review, we propose a novel methodological pipeline called simba (Semantic Indicators for Mobility and Behavior Analysis), for mining and analyzing semantic mobility sequences to identify coherent information and human behaviors. A framework for semantic sequence mobility analysis and clustering explicability based on integrating different complementary statistical indicators and visual tools is implemented. To validate this methodology, we used a large set of real daily mobility sequences obtained from a household travel survey. Complementary knowledge is automatically discovered in the proposed method.
Learning to Select Bi-Aspect Information for Document-Scale Text Content Manipulation
Feb 24, 2020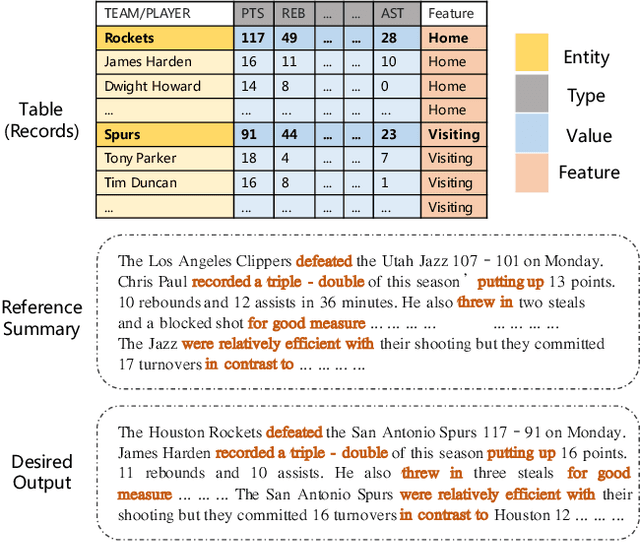
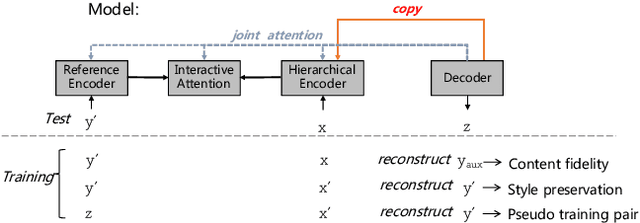
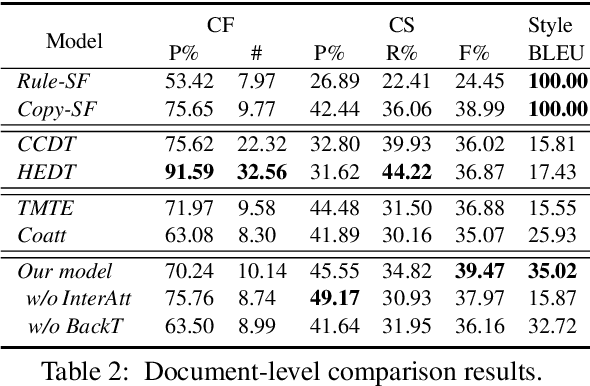
In this paper, we focus on a new practical task, document-scale text content manipulation, which is the opposite of text style transfer and aims to preserve text styles while altering the content. In detail, the input is a set of structured records and a reference text for describing another recordset. The output is a summary that accurately describes the partial content in the source recordset with the same writing style of the reference. The task is unsupervised due to lack of parallel data, and is challenging to select suitable records and style words from bi-aspect inputs respectively and generate a high-fidelity long document. To tackle those problems, we first build a dataset based on a basketball game report corpus as our testbed, and present an unsupervised neural model with interactive attention mechanism, which is used for learning the semantic relationship between records and reference texts to achieve better content transfer and better style preservation. In addition, we also explore the effectiveness of the back-translation in our task for constructing some pseudo-training pairs. Empirical results show superiority of our approaches over competitive methods, and the models also yield a new state-of-the-art result on a sentence-level dataset.
InsertGNN: Can Graph Neural Networks Outperform Humans in TOEFL Sentence Insertion Problem?
Mar 28, 2021
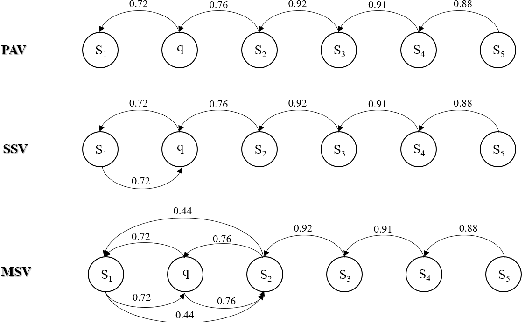
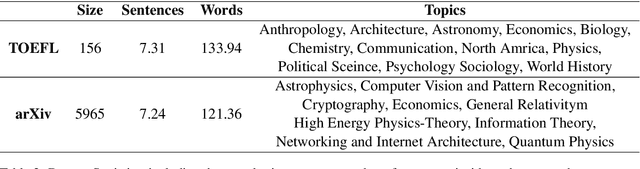
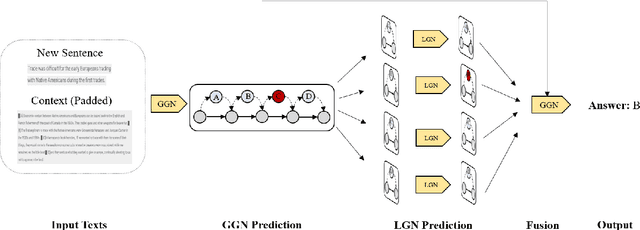
Sentence insertion is a delicate but fundamental NLP problem. Current approaches in sentence ordering, text coherence, and question answering (QA) are neither suitable nor good at solving it. In this paper, We propose InsertGNN, a simple yet effective model that represents the problem as a graph and adopts the graph Neural Network (GNN) to learn the connection between sentences. It is also supervised by both the local and global information that the local interactions of neighboring sentences can be considered. To the best of our knowledge, this is the first recorded attempt to apply a supervised graph-structured model in sentence insertion. We evaluate our method in our newly collected TOEFL dataset and further verify its effectiveness on the larger arXivdataset using cross-domain learning. The experiments show that InsertGNN outperforms the unsupervised text coherence method, the topological sentence ordering approach, and the QA architecture. Specifically, It achieves an accuracy of 70%, rivaling the average human test scores.
Successful Nash Equilibrium Agent for a 3-Player Imperfect-Information Game
Apr 13, 2018
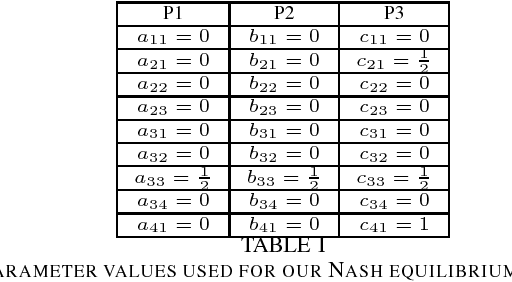
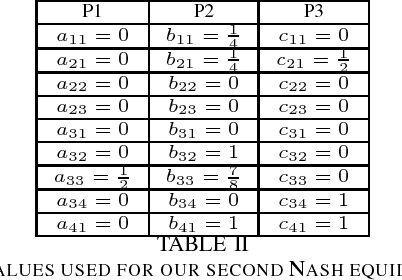
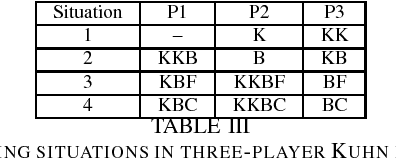
Creating strong agents for games with more than two players is a major open problem in AI. Common approaches are based on approximating game-theoretic solution concepts such as Nash equilibrium, which have strong theoretical guarantees in two-player zero-sum games, but no guarantees in non-zero-sum games or in games with more than two players. We describe an agent that is able to defeat a variety of realistic opponents using an exact Nash equilibrium strategy in a 3-player imperfect-information game. This shows that, despite a lack of theoretical guarantees, agents based on Nash equilibrium strategies can be successful in multiplayer games after all.
CNN Based Segmentation of Infarcted Regions in Acute Cerebral Stroke Patients From Computed Tomography Perfusion Imaging
Apr 21, 2021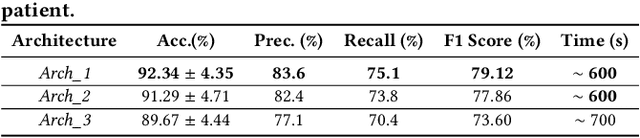
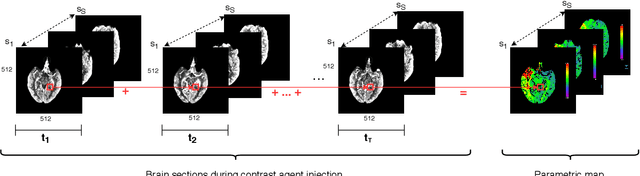
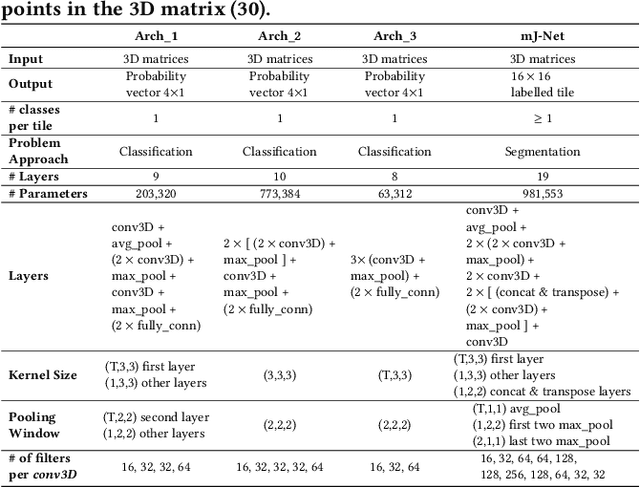
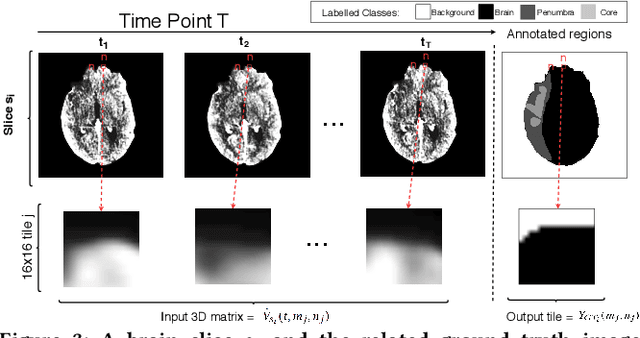
More than 13 million people suffer from ischemic cerebral stroke worldwide each year. Thrombolytic treatment can reduce brain damage but has a narrow treatment window. Computed Tomography Perfusion imaging is a commonly used primary assessment tool for stroke patients, and typically the radiologists will evaluate resulting parametric maps to estimate the affected areas, dead tissue (core), and the surrounding tissue at risk (penumbra), to decide further treatments. Different work has been reported, suggesting thresholds, and semi-automated methods, and in later years deep neural networks, for segmenting infarction areas based on the parametric maps. However, there is no consensus in terms of which thresholds to use, or how to combine the information from the parametric maps, and the presented methods all have limitations in terms of both accuracy and reproducibility. We propose a fully automated convolutional neural network based segmentation method that uses the full four-dimensional computed tomography perfusion dataset as input, rather than the pre-filtered parametric maps. The suggested network is tested on an available dataset as a proof-of-concept, with very encouraging results. Cross-validated results show averaged Dice score of 0.78 and 0.53, and an area under the receiver operating characteristic curve of 0.97 and 0.94 for penumbra and core respectively